
基于轻量CNN 模型的MP3 音频隐写分析方法*
2022-12-12 08:22李宗佑高勇
通信技术 2022年10期
李宗佑,高勇
(四川大学,四川 成都 610065)
0 引言
隐写术是一种将秘密信息隐藏在多媒体载体中,并通过公共信道传输给特定接收者的技术。应用该技术时,第三方将难以发现被隐藏的信息。秘密信息的公共载体很多,如MP3、WAV、AAC等。其中,MP3 作为当前社会最流行的压缩域音频编码格式之一,其具有高压缩率和高质量的特点,被广泛应用于大众的日常生活中。然而,目前运用于MP3 隐写分析的传统神经网络模型通常较大且占用资源较多。本文借鉴GoogLeNet 的设计理念,提出一种基于轻量化卷积神经网络模型的隐写分析方案。
1 音频隐写的发展背景
在过去的十几年中,许多基于MP3 的隐写方案陆续被提出,绝大多数是与编码器相结合,例如被人熟知的开源软件MP3stego[1],其具有较好的透明性和编码兼容性。Gao 等人[2]和Yan 等人[3]分别提出了基于哈夫曼码替换的隐写算法(Huffman code Mapping,HCM),由于哈夫曼码字在MP3 压缩数据流中占比高达90%以上,所以可以作为理想的隐写空间。Yang 等人[4]提出了一种使用等长度熵码替换(Equal Length Entropy Codes Substitution,EECS)的自适应MP3 隐写算法。该算法利用了心理学模型,在嵌入过程中引入校验子格编码(Syndrome-Trellis Code,STC)和代价函数,提高了隐写的安全性。
随着时代的进步,深度学习逐渐用于音频的隐写特征分析。Chen 等人[5]首次提出利用CNN 对最低有效位(Least Significant Bit,LSB)隐写术进行检测,而后Wang 等人[6]提出了首个应用于熵码域的MP3 隐写分析CNN 网络(WASDN),该网络对哈夫曼码字映射以及等长熵码字替换隐写算法检测的准确率提高了20%左右。Zhang 等人[7]提出的LMCNN 进一步简化了模型,做到了网络轻量化。前面两者对熵码域隐写分析的研究都是基于MP3 音频的量化修正余弦变换(Quantified Modified Discrete Cosine Transform,QMDCT)系数。
本文在文献[7]的相关研究基础上,对模型进一步改进。在引入残差块优化Inception 结构加速收敛的同时,借鉴图像特征提取网络将子结构中的池化层改为最大池化方式,从而在浅层网络中最大程度滤除无关信息,只保留纹理特征,进一步节约训练成本,做到模型更小,精度相当。结果表明,网络对于熵码域的隐写分析效果较好,在隐写信息嵌入率较高时,其精度能达到90%以上,具有一定的使用价值。
2 隐写术介绍
2.1 MP3 编码原理
MP3 编码原理如图1 所示。QMDCT 系数和哈夫曼码字是MP3 音频中最为重要的两大参数,编码后的音频文件90%以上均为哈夫曼码字。MP3 音频的每个声道包含576 个QMDCT 系数,按照频率大小由低到高分为大值区、小值区和零区,如图2所示。
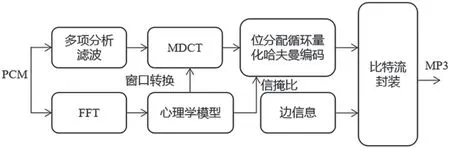
图1 MP3 编码原理

图2 QMDCT 系数矩阵
2.2 隐写算法的介绍
MP3Stego 作为熟知的开源软件原理不过多介绍,下面简单介绍HCM、EECS 隐写算法。
HCM 隐写算法,由于哈夫曼码字在MP3 音频压缩比特流中占比很大,并且隐写不会改变哈夫曼码字结构、长度、符号位以及Linbits 位,通过修改哈夫曼码字来进行数据隐藏具有高容量、高隐蔽性的特点。
EECS 隐写算法是首个自适应MP3 音频隐写算法,在嵌入秘密信息的过程中引入检验子格编码(Syndrome-Trellis Code,STC)和代价函数构造来提升隐写术的安全性。其中代价函数会依据心理声学模型中的映射关系进行隐藏信息代价计算,再通过STC 编码将隐藏信息嵌入在比特流中。
采用国际电信联盟(International Telecommunication Union,ITU)标准的音频质量感知评价方法中的评价参数(Object Difference Grade,ODG),对感知隐写音频质量进行客观测量,结果如表1 所示。表1 中参数值0 为基准,-1 以内表示可察觉性低,-1 至-3 表示存在细微杂音,-3 以下表示质量较差,另外当音频质量较好时可能存在大于0 的现象。
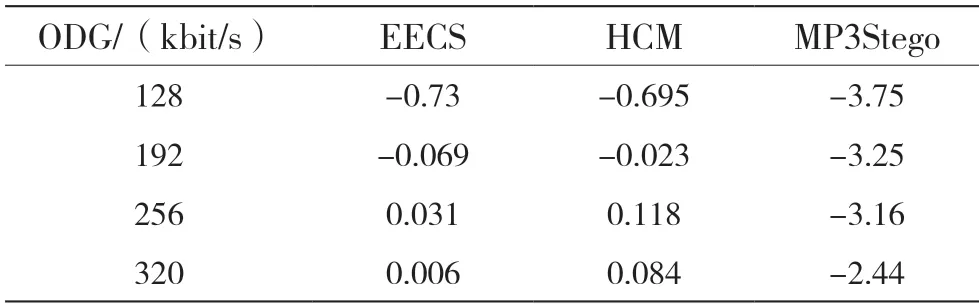
表1 ODG 测量
3 隐写分析算法
本节具体介绍QMDCT 系数矩阵、数据预处理方式和CNN 的主体框架,以及各个模块的作用。算法流程如图3 所示,图中L1 和L2 分别表示步长1 和2。
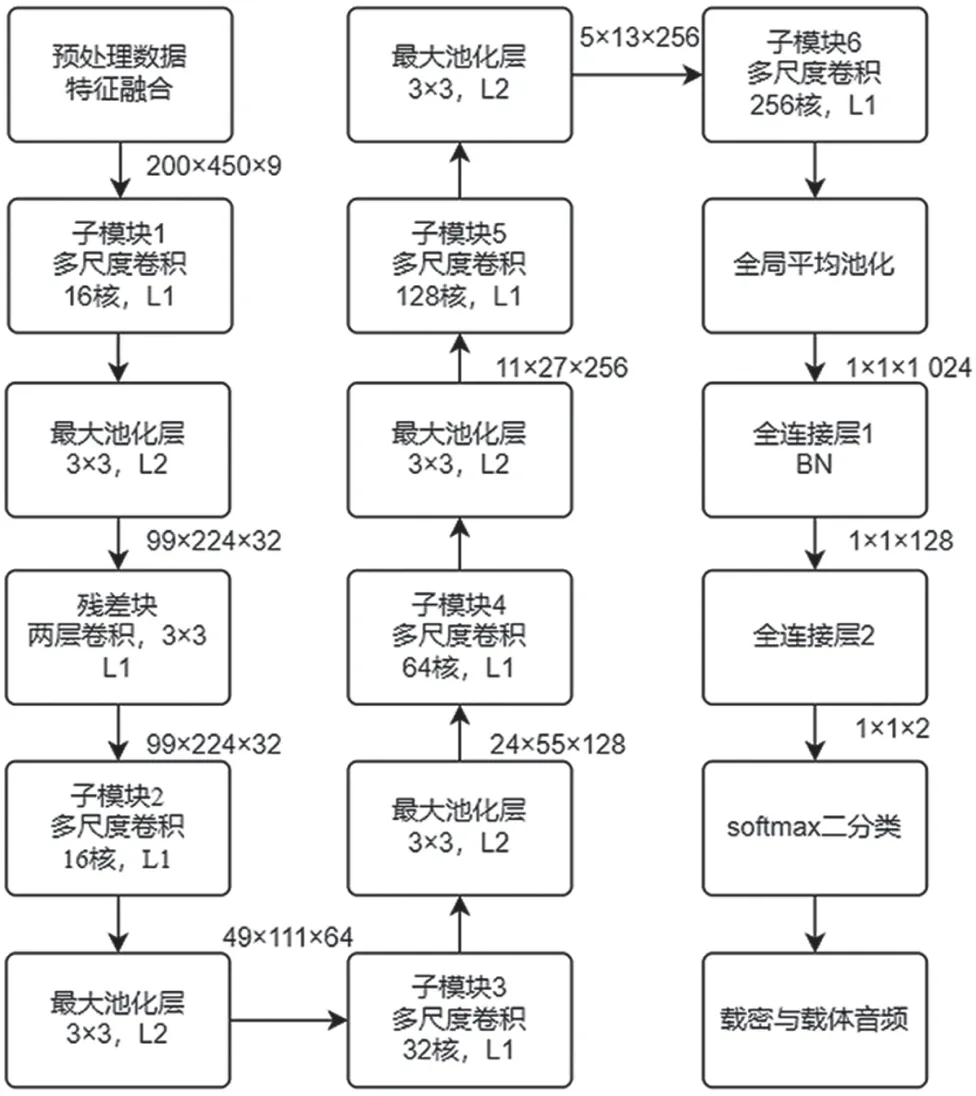
图3 算法流程
整个网络的输入是200×450 的QMDCT 系数矩阵。数据预处理选取高通滤波器提取高频残余信号特征。接着6 个卷积层级联,受Inception_resnetv2[8]的启发,在池化层后引入残差块,激活函数选取tanh,损失函数采用交叉熵损失函数,最后使用全局平均值池化层替换了全连接层。
3.1 网络输入
本文选取QMDCT 系数矩阵作为网络输入,主要的原因是哈夫曼码字与QMDCT 系数之间有着完整的映射关系,表明QMDCT 系数矩阵可以作为良好的隐写分析特征。
为了更加直观地描述,QMDCT 系数矩阵可以表示为:

Qi,j表示QMDCT系数,所选通道数i∈{1,2,…,200},j∈{1,2,…,450}是系数的索引值。
3 种隐写算法对音频进行处理后,QMDCT 系数矩阵的差异如图4、图5 和图6 所示。图中SPR表示隐写负载率,RER表示相对嵌入率,白点表示存在差值。

图4 矩阵差异(EECS(128 kbit/s,SPR=2))

图5 矩阵差异(HCM(128 kbit/s,RER=1))

图6 矩阵差异(MP3Stego(128 kbit/s,RER=1))
3.2 数据预处理
音频隐写有别于图像,其所隐藏的信息基本属于信号的高频部分,所以这里采用高通滤波层来进行数据预处理,目的是为样本增加特征,从而CNN能更好地完成分类任务。此结论在文献[9]中已得到证实。音频隐写会改变原始载体音频的QMDCT系数矩阵,如下式所示:

式中:Ci,j和Si,j分别为正常音频和隐写音频的QMDCT 系数矩阵;Mi,j表示由于秘密信息嵌入引起的扰动;i和j表示系数矩阵的横纵方向上的索引。
基于MP3 的编码原理,QMDCT 系数矩阵的零值不会发生改变,所以只需求取在一阶差分运算下矩阵行、列的非零系数修改比例以及二阶差分运算下矩阵行、列的非零系数修改比例和通过对比矩阵系数的修改比例来选取数据预处理方式。
各预处理滤波器的数学表达式为:

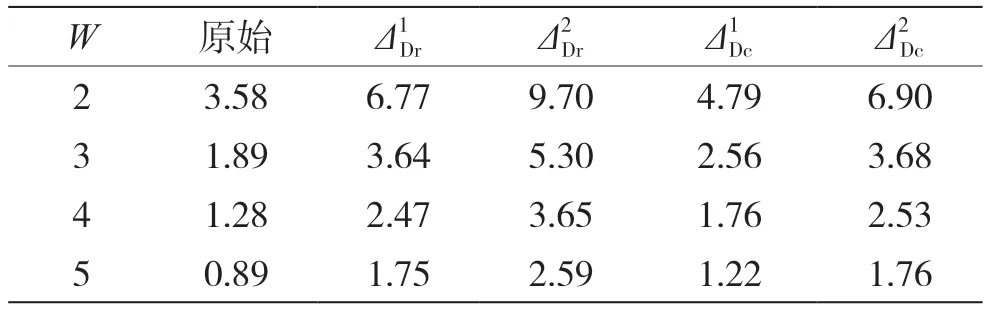
表2 比特率为128 kbit/s 时,不同高通滤波器的滤波效果
3.3 网络设计
子模块结构分为5 个通道Channel1、Channel2、Channel3、Channel4、Channel5,每个通道通过大小不同的卷积核对输入数据进行多尺度特征提取,最后进行特征融合。子模块使用残差连接的方式,防止深层子网络退化,从而出现梯度消失或者爆炸的情况,其结构如图7 所示。
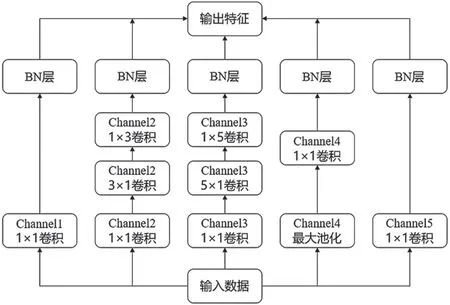
图7 子模块
卷积层作为CNN 的核心部分,网络采用卷积核分解的方式,替换掉3×3 和5×5 的卷积核从而减少计算量,虽然结构更加繁杂,但是参数的个数减少会降低网络过拟合的风险,节约了计算成本。此外,卷积层中频繁使用1×1 卷积核,其作用可以大致分为:
(1)实现跨通道的交互和信息整合;
(2)进行卷积核通道数的降维和升维;
(3)减少网络参数;
(4)可以在feature map 尺度不变的情况下,增强网络非线性,提升网络深度。
其中就减少网络参数做出如下解释:假设3×3卷积层的输入通道为N,输出通道为2N,权重和偏差总数为:

加入1×1 卷积核后参数总和为:

这样参数减少7N2-N,当N较大时,参数减少量相当可观。
池化层的主要作用是减少特征维数,保留数据的主要特征。LV3 在浅层网络中均使用最大池化,最大程度滤除无关特征,在最后的全局池化层采用平均池化,将有效特征进行融合分析。
残差块与浅层网络的池化层相连接,从而对特征残差进行学习,在提高模型收敛速度的同时,避免了特征信息丢失和网络梯度爆炸。残差块结构如图8 所示。
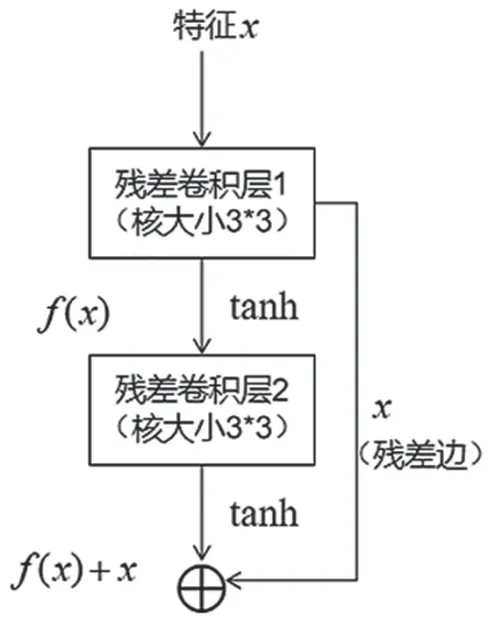
图8 残差块
激活函数选择ReLu 能够加速网络收敛,但是考虑到QMDCT 系数矩阵的数值范围有限,且存在一定的对称性,所以选择tanh 具有更好的分类效果。
批量归一化(Batch Normalization,BN)层实质作用就是对特征数据进行归一化处理,其主要作用是加速收敛速度、防止梯度弥散和提升网络的泛化能力。
模型最后采用全局平均池化替代全连接层,不仅降低了计算量,而且保留了前面各个卷积层和池化层提取到的信息特征,使得整个网络具有更强的分类检测能力。
4 实验
4.1 实验设置
选取采样率为44.1 kHz,持续时间为10 s 的WAV 音频数据集,利用专业MP3 编码器LAME[10]将WAV 文件编码为比特率为128 kbit/s 和192 kbit/s的高质量MP3 文件。实验通过数据集[11]制作隐写音频文件,对于HCM 算法,编码过程中秘密信息以0.1,0.3 和0.5 的相对嵌入率(RER)进行隐藏;EECS算法通过STC编码实现对隐写嵌入率的控制,W和T分别为奇偶检验矩阵的宽度和高度,本实验固定T为7,分别在W为2,3,4,5 处嵌入秘密信息。把得到的10 000 个载体和载密文件对,按照7 ∶2 ∶1 划分并进行训练、验证以及测试。
实验优化方式选用Adam[12],其中β1=0.9,β2=0.999,ε=10−8,训练批次大小为24,初始学习率设置为0.001,为了防止数据过拟合,选取L2 正则化大小为0.001,为保证网络收敛速度,采用学习率下降策略(每5 000 步,下降0.9)。此外参数的随机初始化方法采用Xavier[13],网络以Loss 连续3 个epoch 不下降作为停止训练条件。
两种传统分析方法,一是基于MP3 音频帧内帧间相关性的隐写分析算法[14](Abs Difference One-Step Transfer Probabilities,ADOTP),二 是基于Markov 单步转移概率的音频隐写分析算法(Multiple Difference between Inter and Intra Frames,MDI2)[15],两者均采用机器学习中的支持向量机来训练10 个epoch 求取检测精度的平均值。
4.2 实验结果
为了全面评估实验网络的性能,传统隐写分析方案选择ADOTP、MDI2 进行对比,神经网络选取Googlenet 类型的LMCNN 以及VGG 类型的WASDN进行比较。
本文实验采用的神经网络模型大小和占用显存规模如表3 所示。
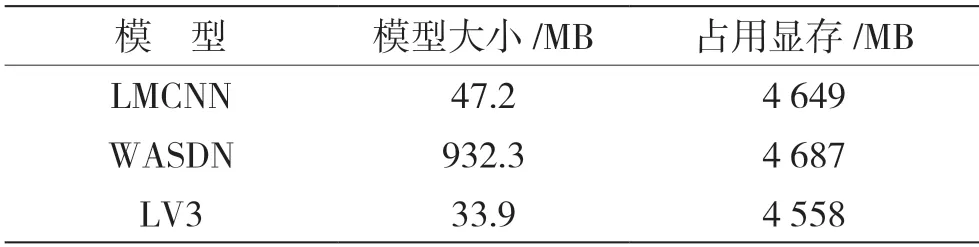
表3 模型参数
表4、表5 展示了各种隐写分析手段对HCM、EECS 两种隐写算法的检测能力。表6 对比了各模型训练的拟合速度。

表4 HCM 算法隐写检测准确率 %
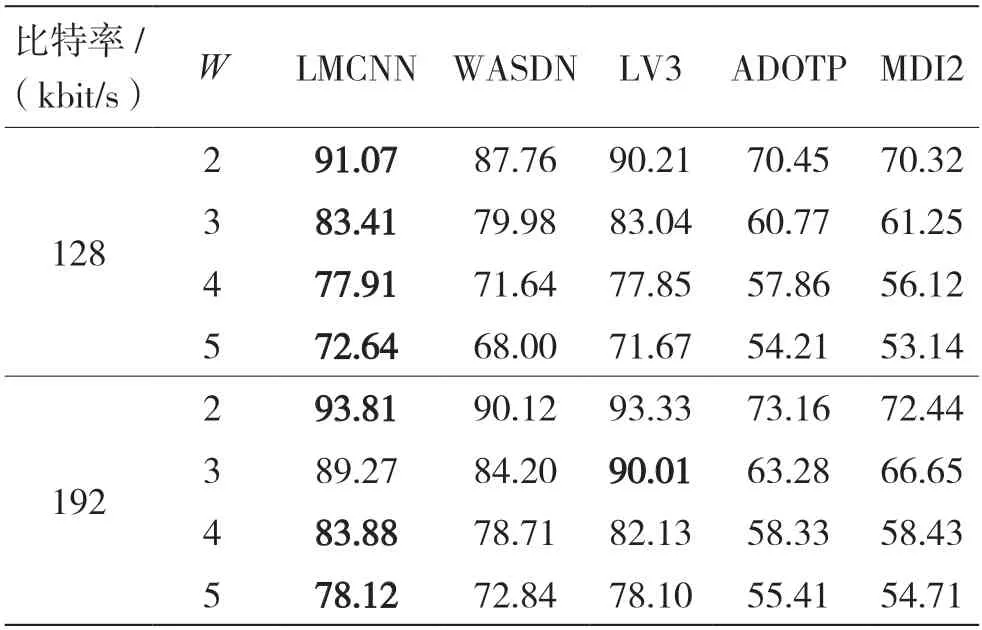
表5 EECS 算法隐写分析检测准确率 %

表6 模型收敛轮数
实验结果表明,提出的LV3 网络相比于LMCNN不仅更加轻量化、收敛速度更快而且检测精度相当。对比于WASDN 以及传统分析手段,LV3 模型具有更高的隐写分析价值。
4.3 迁移学习
迁移学习[16]是深度学习中最强大的理念之一。深度学习受限于训练资源,迁移学习可以较好实现特征迁移,做到从一个任务中学习知识,并运用到另外一个相关任务中去。其相较于从零学习大大降低了对数据集本身的依赖,能更好地体现网络的泛化能力。迁移学习的分类如图9 所示。
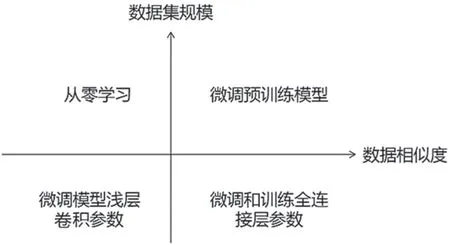
图9 迁移学习类型
由于MP3Stego 编码器在低码率下工作时容易崩溃,大数据集制作困难,所以采用EECS 隐写算法的分析检测模型进行迁移学习。由于MP3Stego隐写算法对QMDCT 系数矩阵的改变明显高于EECS算法,所以网络学习难度降低,适当提高学习率,微调参数进行实验,数据如表7 所示。结果表明LV3 模型具有良好的泛化能力,迁移学习运用在小数据集上不仅能加速网络收敛,还能提高检测精度。
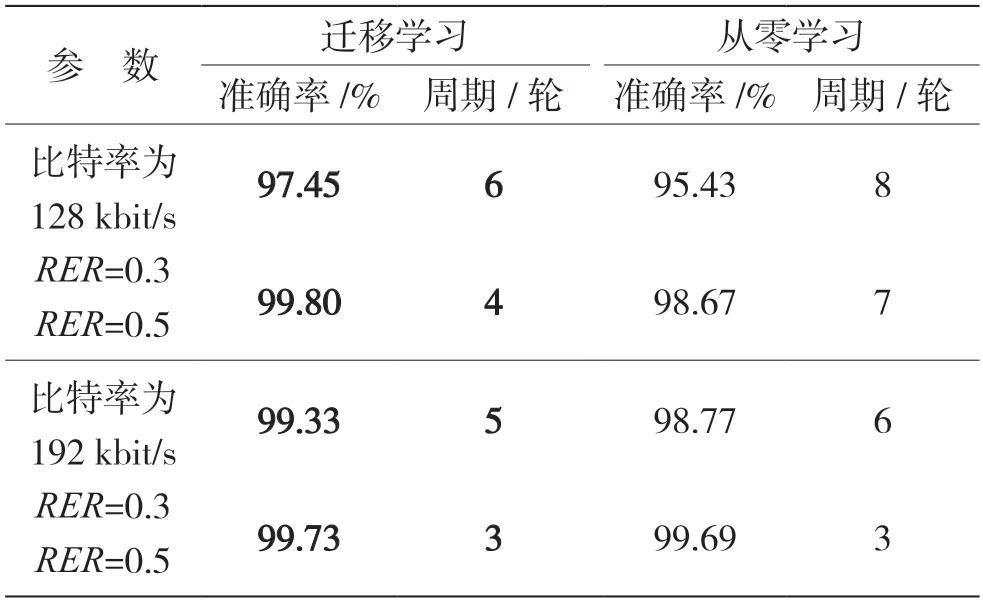
表7 MP3stego 算法隐写分析
5 结语
本文提出了一种高效、轻量化CNN 的MP3 隐写分析模型。网络通过对池化层设计,先利用最大池化层过滤较多的无用特征信息,再使用全局平均池化进行特征整合,在尽可能降低计算量的同时还保证了较高的准确率。为了确保浅层网络小部分特征不丢失,模型引入残差模块。残差学习在弥补了模型收敛速度的同时,最大限度上确保深层网络不会出现梯度消失或者爆炸。结果表明,提出的LV3网络相比于LMCNN 不仅更加轻量化、收敛速度更快而且检测精度相当。同时,其隐写分析能力也优于WASDN 以及ADOTP、MDI2 等优秀的传统分析手段,此外该模型在熵码域的隐写分析中泛化能力强,适用于各种比特率以及隐写负载率。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
扬子江诗刊(2018年1期)2018-11-13
舰船电子对抗(2018年3期)2018-08-28
北京航空航天大学学报(2018年1期)2018-04-20
扬子江(2018年1期)2018-01-26
电子制作(2017年9期)2017-04-17
人间(2015年8期)2016-01-09
