
基于平行注意力机制的对抗样本防御方法
2022-12-10 10:37赵杰,郭东
吉林大学学报(信息科学版) 2022年5期
赵 杰, 郭 东
(吉林大学 计算机科学与技术学院, 长春 130012)
0 引 言
目前兴起的机器学习热潮展示出深度神经网络强大的能力, 极大推动了计算机视觉、 自然语言处理、 推荐系统等领域的发展。图像分类任务是计算机视觉领域中的重要方向, 其目标是训练一个网络模型对图像进行正确分类。卷积神经网络(CNN: Convolutional Neural Networks)受动物视觉系统分层行为启发, 通过建立感受野逐步提取图片特征, 最终收集到高阶特征确定所属类别[1]。CNN作为图像分类任务的主流架构, 目前应用范围最广, 已在图像分类领域上取得了优异成果, 并在许多方面超过了人眼识别的准确度[2]。然而, CNN受到卷积核大小的限制, 每次只能获取较小区域的信息, 偏向于辨识图片中的局部纹理, 难以捕捉物体整体特征[3]。
已有研究表明CNN容易遭受人眼不可见的细小扰动影响并造成分类错误, 这种扰动被称为对抗样本[4]。这表明CNN与人类的视觉系统有本质区别, CNN并不能像人类一样正确识别图片中物体。自对抗样本的思想提出以来, 人们已经提出大量有效的生成方法, 目前甚至可以只改变图片中一个像素即可造成模型分类错误[5-7]。
为抵御日益强大的对抗样本攻击, 目前主要有以下3种防御方式: 对抗训练[4,8], 此方法将对抗样本加入到训练集数据中, 使模型学习对抗样本的分布和正确标签, 提高模型鲁棒性; 输入净化[9], 此方法通过去除输入中的恶意噪音, 将其转换为正常的图片防御对抗样本; 设计新模型[10], 此方法将防御对抗样本纳入到模型设计目标中, 通过改进网络模型结构, 使模型本身具有防御对抗样本的能力。虽然对抗训练和设计新模型取得不错的效果, 但由于一方面训练成本较高, 需要大量的训练资源, 另一方面会影响模型的泛化能力, 降低精度。目前有许多模型已经被部署使用, 对这部分模型进行重新训练会破坏用户的正常使用, 产生潜在的风险。而基于输入净化的防御方法不会对原始模型进行改变, 比上述两种方法更适合此场景, 更加值得研究。
在之前的工作中, 净化方法大多在图片像素上进行操作, 期望通过消除对抗样本中的噪音降低对模型分类结果的影响。然而由于神经网络高维复杂的特性, 对像素的非常小的扰动也会造成模型结果的巨大变化[5]。对像素的修改无法从根本上解决对抗样本问题, 迫使人们寻找提高模型鲁棒性的新方法。根据研究发现[11], 在哺乳动物的视觉系统中, 来自眼睛的信号被分成两个并行信号处理部分。一部分信号用于提取物体的个体信息, 另一部分信号则处理空间和位置信息。笔者从这种工作方式中得到灵感, 将防御重点从像素级别转移到更高维度, 即图片中的物体个体和空间信息两个维度。
笔者提出一种更加新颖的方式净化输入, 降低对抗样本对模型预测精度的影响, 模型命名为PSCAM-GAN(Parallel Spatial and Channel Attention Mechanism Adversarial Generative Network)。具体方法是对一个给定的预训练模型, 在其基础上建立一个生成模型净化输入, 通过注意力机制提取输入的个体和空间特征, 使净化结果具有更强的鲁棒性。为保证模型清除恶意扰动的同时不改变图片原有特征, 在PSCAM-GAN中使用了一种新型的平行注意力机制, 其类似人类视觉系统行为, 会同时处理图片中的个体和空间两部分信息, 提取图片热点区域。将提取结果用于调节模型对图片不同区域的关注程度, 使生成模型的注意力集中于整体的纹理特征和空间信息, 忽略隐藏于像素中的恶意扰动。PSCAM-GAN可在不对模型进行任何修改的情况下防御恶意攻击, 有效提高模型面对对抗样本时的鲁棒性。
1 预备知识
1.1 对抗样本
对抗样本是一类针对机器学习的常见攻击, 通常集中于计算机图像处理领域。攻击者向模型的输入中添加扰动, 诱导模型产生错误的输出。在图像分类领域通常表现为分类模型将输入辨认成其他类别。通常对模型f, 假定x是模型输入,y是图片的真实类别,f(x)是模型预测的类别, 则对抗样本为x+α, 能使f(x)≠f(x+α), 且‖α‖p≤ε。其中α是对抗攻击向图像中添加的扰动,ε是攻击强度,p是攻击范数, 一般取1、2或∞。
对抗样本的概念最先由Szegedy等[4]提出, 随后人们提出许多有效的对抗样本生成算法。其中FGSM(Fast Gradient Sign Method)[5]和PGD(Project Gradient Descent)[12]最为有名。FGSM算法可描述为,α=ε·sign(xL(x,y)),L是损失函数, sign是取符号函数。PGD是FGSM的迭代版本, 多次求解梯度寻找最优扰动, 可表示为xt+1=∏x+S(xt+α·sign(xL(x,y))), 其中∏是投影函数, 用于限制PGD每次迭代的攻击范围。上述攻击都基于求解目标模型的梯度, 此外, 还有一类无需使用梯度的方法。SPSA(Simultaneous Perturbation Stochastic Approximation)属于此类攻击, 无需了解目标模型的梯度信息, 可轻松绕过以隐藏梯度为基础的防御方法, 造成更大的威胁。
1.2 对抗样本防御策略
对抗样本是一种对深度学习较为严重的威胁, 目前无法完全消除对抗样本对模型的影响。基于目前的理论研究, 对抗样本防御可分为以下3类。
1) 对抗训练。是指在训练模型过程中加入对抗样本和正确的标签, 使模型学习到对抗样本的分布, 降低对抗样本的效果。目前最常用的方式是向训练集中加入PGD对抗样本[12]。但对抗训练只能防御已知的攻击方式, 当出现未知对抗样本时, 防御能力会大幅下降。
2) 设计新模型。此类防御方法在设计模型结构时就已经考虑到了对抗样本攻击, 其通过设计特殊的网络模型防御对抗样本的威胁。PixelDP[10]在模型中利用差分隐私机制, 限制对抗样本对模型梯度的影响程度。Kiritani等[13]利用带有对数极化感受野的循环注意力模型防御对抗样本。这些模型的鲁棒性只能从理论上证明, 但尚无法有效防御攻击威胁。
3) 预处理。预处理方法也被称为输入净化, 是从实用性角度出发, 通过清除对抗样本中恶意扰动α达成防御效果。之前的工作大多在像素层面上对图片进行处理, 降低对抗样本与正常输入之间的差异。Dai等[14]提出一种与模型无关的生成网络防御方法, 但其依赖于具有重参数化的多次迭代。Xiao等[15]将预处理机制与对抗训练结合, 提出了一种先对抗训练, 后向输入中添加对抗样本的防御方法, 该方法不能正确消除恶意扰动, 并需要对原始模型进行重新训练。李世宝等[16]利用多次迭代的对抗生成网络平滑输入, 消除潜在的对抗样本风险, 但此方法多次迭代会造成效率较低。目前大多基于预处理的防御方法还停留在像素层面, 而HGD(High-Level Representation Guided Denoiser)[17]、 CAP-GAN(Cycle-consistent Attentional Purification Generative Adversarial Network)[9]等部分防御方法注意到图片内部的物体特征层面, 并设计相应的净化方法保留图片特征, 取得较好的防御效果。
1.3 注意力机制
注意力机制的作用就是将传统的视觉搜索方法进行优化,重新调整网络对图片的处理,减少了需要处理的样本数据并增加了样本间的特征匹配。在计算机图像处理领域, 注意力机制一般分为通道注意力和空间注意力。通道注意力希望增强关键通道对模型的影响, 重新学习特征图每个通道的权重, 从而提高模型精度; 空间注意力则主要针对图片中不同位置的像素, 提高关键像素的影响力。
2 方法与模型
2.1 总 述
笔者的模型以CycleGan[18]为基础, 添加一个预训练目标模型T和对抗样本攻击方法FA。模型T是被防御的目标模型, 它的输入为x, 输出为x对应的分类标号y′。FA用于生成对抗样本, 当输入为x时, 输出xadv=x+α并满足T(x+α)≠T(x), 其中α是FA向x中添加的恶意扰动, B和A分别是普通数据域和含有对抗样本的数据域。PSCAM-GAN会学习图片如何在B和A之间相互转换。整个网络包含两个生成器GB→A和GA→B以及两个辨别器DB和DA, 生成器GA→B将来自对抗样本数据域A的输入进行净化, 并转换到普通数据域B, 随后净化结果作为模型T输入达到防御对抗样本的目标。生成器GB→A行为方式相似, 不同之处在于它将正常图片转换为对抗样本。辨别器用于判断它的输入是否由相关生成器产生。需要注意的是, 攻击方法FA产生的对抗样本仅作为生成器和辨别器的输入, 辅助生成模型的训练, 并不直接参与模型T的训练, 所以笔者的方法与对抗训练有本质上的区别。
2.2 模型结构与注意力机制
受UGatIt[19]和CapGan[9]的启发, 生成模型将对抗样本输入转换为正常图片, 使目标模型T免于恶意攻击的困扰。PSCAM-GAN的整体架构如图1所示,GA→B负责净化图片,GB→A用于保证数据的循环一致性, 即x顺序经过GB→A和GA→B得到x′, 且x≈x′。循环一致性能限制模型对图片的改变程度, 保证模型输入与输出相似。GB→A仅作为辅助手段提高GA→B精度, 且两者结构相同。下面只描述生成器GA→B的结构。同样, 辨别器DB和DA负责分辨其输入是否由GA→B或GB→A产生,DB和DA之间也高度相似, 以下只描述辨别器DB的结构。

图1 PSCAM-GAN的整体网络架构Fig.1 The overall architecture of PSCAM-GAN
2.2.1 生成器
生成器结构包括3部分: 编码器encoderG、 注意力模块MG以及解码器decoderG。MG包含额外一对辅助分类器ηGc和ηGs, 并根据MG的输出计算输入图片所属域(例如: B)。首先encoderG对输入对抗样本计算对应的编码特征图fG, 并作为注意力模块MG的输入。在MG中将同时进行通道注意力和空间注意力操作。对通道注意力模块, 分别通过全局平均池化层和全局最大池化层得到fGavg和fGmax, 随后通过一个共享参数的全连接层得到通道激活图(CAM: Channel Activation Map), 利用CAM重新调整特征图的权重。对空间注意力模块, 首先对fG分别在通道维度上求得平均值和最大值, 随后将两个结果合并作为一个全连接层的输入, 所得全连接层的参数即为空间激活图(SAM: Spatial Activation Map), 用于表示特征图中每个位置的重要程度。随后, 使用CAM和SAM重新调整特征图得到fMG, 将调整后特征图作为解码器decoderG的输入。在进行decoderG操作的同时, 将用辅助分类器ηGc对SAM进行分类,ηGs对CAM进行分类。分类结果将用于优化注意力机制的参数, 添加辅助分类器ηGc和ηGs可确保注意力机制能正确学习到数据特征的分布权重, 使生成器在不改变对抗样本中原始图片特征的情况下清除噪音。最终decoderG利用特征图FMG重新生成一张属于正常数据域的净化图片xA→B。同时为满足生成器的循环一致性, 生成器GA→B和GB→A分别用xadv和x作为输入, 产生xA→B和xB→A, 再将xA→B和xB→A作为生成器的输入得到xA→B→A和xB→A→B。循环一致性的目标是保证生成的图片xA→B→A和xB→A→B尽量与原始图片xadv和x相似, 从而达到强迫生成器只在数据域B和A之间进行转换。其中xA→B是生成器针对对抗样本输入产生的净化图片, 而xB→A,xA→B→A和xB→A→B则用于保证模型的循环一致性, 确保生成的图片与原始图片相似。具体算法如下。
算法1 平行注意力模块。
输入: 生成器的特征图f
输出: CAM,SAM,logit of the auxiliary discriminator
1) GAP_c=average poolf
2) GMP_c=max poolf
3) GAP_c_logit=eta_gc(GAP_c+GMP_c)
4) GAP_s=average f on the channel dimension
5) GMP_s=max f on the channel dimension
6) GAP_s_logit=eta_gs(GAP_s+GMP_s)
7) CAM=the weight of eta_gc
8) SAM=the weight of eta_gs
9) return CAM, SAM, GAP_c_logit , GAP_s_logit
2.2.2 辨别器
本架构中包含两个辨别器, 每个辨别器由4部分组成: 编码器encoderD、 注意力模块MD、 卷积分类器以及一对辅助分类器ηDc和ηDs。辨别器将会判断其输入是原始图片还是由生成器生成的图片。如前所述, 因为两个辨别器的结构相同, 差异仅在于对应辨别的生成器不同, 因此只描述一个辨别器的结构。当x或xA→B作为输入时, 首先经过编码器encoderD生成特征图, 随后进入注意力模块MD。辨别器中的MD结构与生成器中的MG类似, 唯一的区别在于全连接层之后需要额外添加谱归一化层。特征图经过平行的通道注意力模块和空间注意力模块后得到CAM和SAM, 随后同时进行两个方面操作: 1) 特征图经CAM和SAM调整, 得到FMD作为卷积分类器的输入, 用于判断图片是否由生成器生成; 2) CAM和SAM又作为辅助分类器ηDc和ηDs的输入,ηDc和ηDs通过判断输入图片来自于A还是B, 使注意力机制能区别对抗样本和普通图片的特征, 辅助提高辨别器的精度。辨别器的提高将会指导生成器找到更好的图片生成方法。
2.3 损失函数
为保证模型在净化对抗样本时能维持原始图片的特征, 参考CycleGan[18]和CapGan[9]的策略, 使用了一系列损失函数约束模型的行为。损失函数包括:对抗损失函数LGAN, 循环一致性损失函数Lcycle, 注意力模块损失函数Lscam以及知识蒸馏损失函数Lsem。其中LGAN,Lcycle主要用于确保生成模型在像素层面的一致性。Lsem通过知识蒸馏提取预训练模型T中关于图片分类的信息, 帮助PSCAM-GAN获得正常图片的分布, 有效辨识对抗样本。笔者根据注意力模块的行为提出Lscam, 使模型提取图像中个体和空间信息的分布, 提高模型生成图片的质量。下面将解释每个损失函数的具体意义并着重叙述Lscam损失函数。
2.3.1 对抗损失函数
笔者目标是利用对抗生成网络的方式净化含有恶意扰动的输入, 生成一张正常的图片。因此使用对抗损失函数LGAN建立辨别器与生成器之间的对抗关系, 使两个生成器分别产生正常图片或对抗样本, 并通过辨别器判断图片是否由生成器产生, 以保证生成的图片能符合数据域的分布。采用均方误差损失函数计算生成结果与其对应分布之间的差距
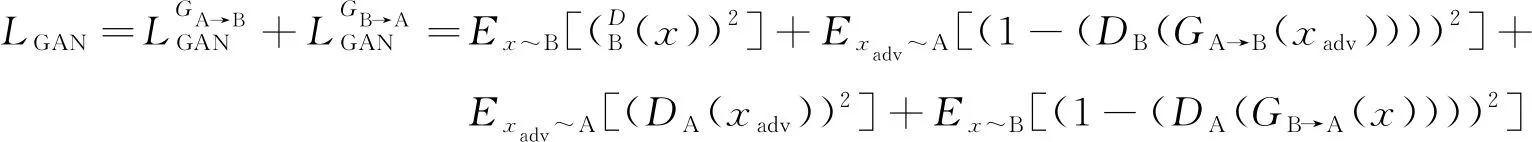
(1)
2.3.2 循环一致性损失函数
当正常图片x通过GB→A被转换为对抗样本x′后, 可通过GA→B重新转换为原始图片x, 将这种行为称为循环一致性。循环一致性损失函数Lcycle强制生成器在两个不同领域之间进行转换, 从而确保生成的净化图片包含足够多的原始图片信息, 使图片的关键特征得以保存。其表述为

(2)
2.3.3 注意力模块损失函数
笔者在模型中加入注意力机制, 调整编码器产生的特征图的权重, 使模型能像人类视觉系统一样, 提取图片中个体和空间信息分布, 从而降低对抗样本中噪音的影响。为有效提取特征图中的重点区域, 向网络中添加通道注意力机制和空间注意力机制, 引导生成器从对抗样本中提取原始图片中的有效特征, 净化恶意噪音。除注意力机制外, 笔者还使用两对辅助分类器:ηGc和ηGs,ηDc和ηDs。辅助分类器接收注意力机制产生的CAM和SAM判断其输入的所属数据域, 并反过来影响注意力模块, 使注意力模块能获取相关的领域特征信息。每对辅助分类器的结果将在通道维度上进行合并, 并通过均方误差方法计算。其表述为

(5)
Lscam不仅能使模型学习到对抗样本数据与净化数据之间的转换关系, 还能提高辨别器对生成器的指导能力, 保证生成的图片与原始图片差异不大。
2.3.4 知识蒸馏损失函数
由于CycleGan最初的目的是用于图像风格转换, 只在像素级别上保持图片一致, 并没有应用于对抗样本防御, 所以额外添加一个预训练目标模型T, 希望防御模型能提取预训练模型中关于正常图像识别的信息。为保证生成器模型能学习到预训练模型中的分类能力, 确保生成图片符合分类标准, 借鉴CapGan中的思想, 利用损失函数Lsem使生成器产生的图片与预训练模型T具有相同的特征。具体讲就是希望生成器G能获取目标模型T中有关分类的知识。为达到这一目的, 利用Lsem使生成器与目标模型之间保持特征一致性
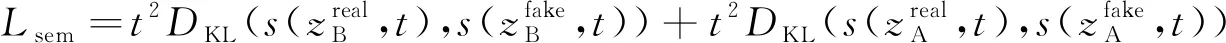
(6)
其中DKL(·)是KL散度,z是向目标模型输入x得到的结果,t是知识蒸馏时的温度,s(z,t)是通过softmax计算得到的分类得分, 即
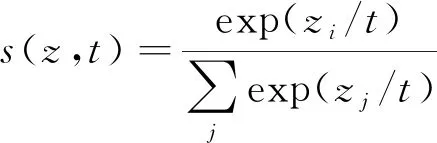
(7)
2.3.5 整体损失函数
净化对抗样本不仅需要保证在像素层面得到与输入相似的图片, 同时还要保证图片高层次的个体特征和位置信息不被改变, 笔者将组合上述损失函数使生成网络产生更好的效果。LGAN,Lcycle均由CycleGan结构改变得到的, 在像素层面限制生成器的能力, 完成图片到图片之间的转换, 因此称为图片转换损失函数Ltrans; 而Lscam,Lsem控制生成器从图片和预训练模型中提取物体特征, 保证生成图片从特征层面与输入保持一致, 因此称为特征图片损失函数Lfeature。由于图像转换将保持图片像素之间的相似关系, 而清除对抗样本需要在保留图片特征的情况下修改像素, 所以整个损失函数描述为
Lloss=αLtrans+(1-α)Lfeatrue=α(LGAN+Lcycle)+(1-α)(Lscam+Lsem)
(8)
其中α用于平衡Ltrans与Lfeature之间对模型的影响。
3 实验结果
3.1 实验环境
笔者使用CIFAR-10和MNIST作为数据集。CIFAR-10共包含60 000张彩色RGB(Red Green Blue)图片, 被分为10个类别, 每张图片大小为32×32×3像素。MNIST是手写数字黑白图片数据集, 共包含10个种类, 每张图片大小为28×28像素。所有的模型都训练在一块Nvidia GeForce GTX 1080 Ti上。笔者将一个简易的ResNet预训练模型作为目标模型T, 在训练时, 采用Adam优化器进行200轮训练, 批量大小为80。起始学习率为0.000 1, 采用余弦退火衰减调整学习率。在训练过程中, 使用FGSM产生辅助对抗样本。参数设置:α=0.7平衡不同损失函数之间的关系, 蒸馏温度T=10.0确保生成器能学习到目标模型中知识。
3.2 对白盒攻击的测试
白盒攻击是指攻击者了解目标模型的全部信息, 包括模型的训练集、 网络架构以及具体参数, 而且攻击者对目标模型可以无限制访问。白盒攻击是对抗样本最先发展的攻击方式, 也是最常见的攻击方式, 因此首先在白盒攻击背景下对模型的防御能力进行测试。本次测试主要使用两种攻击方式: FGSM和PGDn。PGD攻击是一种迭代的攻击方式, 笔者通过改变n确定攻击迭代次数, 迭代次数越多, 对抗样本使模型分类错误的概率越大。
如表1、 表2所示, 原始目标模型T在原始数据下精度最高, 但在遭受攻击时, 精度大幅下降, 导致分类模型无法使用。防御模型虽然会导致分类精度下降, 但在面对对抗样本攻击时, 能保持模型的可用性。在MNIST数据集上, 笔者的防御方法最接近原始模型精度, 同时在遭受对抗样本攻击时, 模型的精度几乎不会发生变化。在CIFAR-10数据集上, 虽然本防御方法相对原始模型精度有较大的下降, 但与其他模型相比, 仍能提供相对较好的预测效果。综合2种数据集上的结果可知, PSCAM-GAN不仅能在面对攻击时拥有优秀的防御效果, 还能在正常情况下提供相对较好的分类精度。同时, HGD与CAP-GAN也能提供较好的防御效果, 是因为其采用了与笔者类似的防御理念, 即不仅考虑图片中离散的像素, 还考虑图片的整体特征。由于额外添加的平行注意力机制能指导生成器获取图片个体特征和空间信息, 使模型更加准确地把握住图片中重要特征所处的位置, 所以笔者的模型能取得较好的防御效果。

表1 在数据集MNIST上白盒攻击的模型精度

表2 在数据集CIFAR-10上白盒攻击的模型精度
3.3 对黑盒攻击的测试
黑盒攻击与白盒攻击不同在于, 攻击者对目标模型的信息掌握较少, 或只能以受限制的方式访问模型。根据攻击者对模型的了解程度, 笔者总结出两种不同的黑盒攻击方式: 一种称为迁移攻击, 攻击者了解模型的具体结构, 训练数据集分布, 但不清楚模型的具体参数和一些训练超参数, 攻击者用相同分布的数据重新训练一个替代模型, 再使用FGSM, PGD等攻击方式进行攻击; 另一种称为无梯度攻击, 这种攻击方式对模型背景知识的要求更少, 通常攻击者只需要知道目标模型的一部分结构, 另一部分被隐藏或无法求导, 因此不能训练替代模型, 无梯度攻击不依赖于局部梯度信息, 对模型的威胁更大。
对替代攻击, 笔者使用原始模型相同的数据集训练一个代替模型f′, 其网络结构与目标模型一致。攻击者可在此基础上进行迁移攻击, 利用FGSM和PGD等攻击方式在f′产生对抗样本, 随后作为目标模型的输入进行攻击。如表3、 表4所示, 笔者的模型与白盒模式下相比精度几乎没有变化, 这是因为笔者的模型仿照人类视觉系统的行为, 能抓住输入图片的特征重点, 重新生成图片, 提供较高的鲁棒性。可以看到, 对抗训练(AT: Adversarial Training)的防御方式虽然花费大量的计算资源, 但仍然不能有效抵御不同的迁移攻击, 这是因为对抗训练只能学习到对抗样本潜在的分布, 没有真正的改变模型行为逻辑, 不能像视觉系统那样处理图片, 使对抗样本的威胁无法从根源上解决。THM在FGSM攻击中取得了很好的效果, 但对迭代攻击防御有些脆弱。防御模型在CIFAR-10数据集上的效果远不如MNIST数据集上理想, 是因为CIFAR-10数据集中的图片更复杂, 拥有更多的特征, 防御难度更大。相对仅考虑像素噪音的防御方法, 通过关注图片中的高维特征可提高模型面对对抗样本的鲁棒性, 因此HGD与CAP-GAN与PSCAM-GAN效果相似。但笔者的平行注意力模块同时考虑到图片内部空间与通道两个层面的特征, 拥有更强的防御能力。
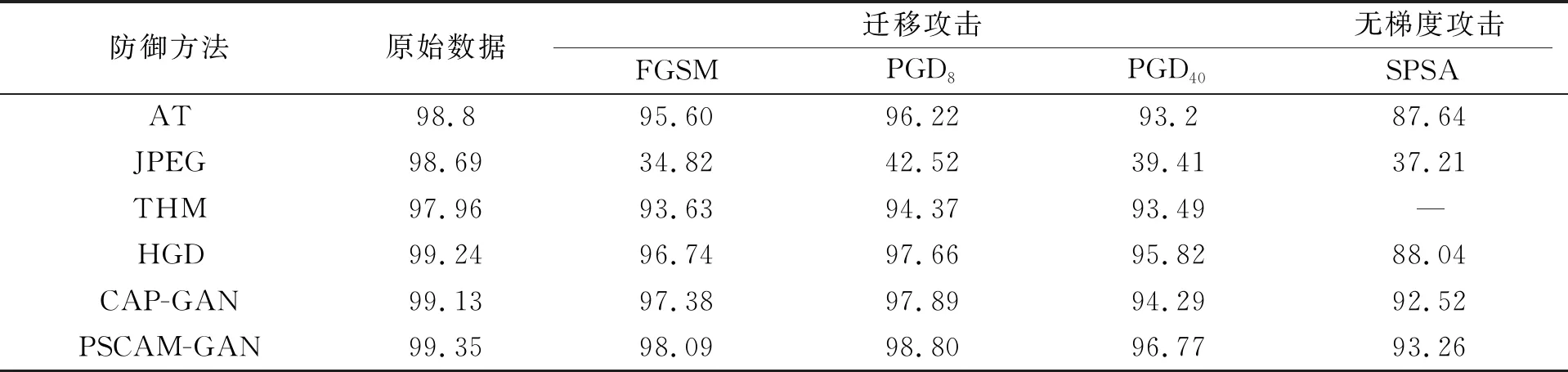
表3 在数据集MNIST上黑盒攻击的模型精度

表4 在数据集CIFAR-10上黑盒攻击的模型精度
对无梯度攻击, 笔者试验了最常见的SPSA黑盒攻击。在SPSA攻击背景下, 攻击者可直接获得防御模型的输出, 不需要求梯度仍能产生针对性的攻击。如表3、 表4所示, 笔者模型在面对SPSA攻击时拥有最好的防御能力, 全面优于其他防御算法。这主要是因为该模型能在保证图片关键特征的同时, 去除不相干的信息, 重新生成具有鲁棒性的图片。
3.4 消融实验
3.4.1 注意力模块
笔者通过组合不同注意力模块中的组件测试注意力模块对模型净化能力的影响。如表5所示, 当不包含任何注意力组件时, 整个模型的防御能力最低。单独使用通道注意力模块或空间注意力模块均能提高模型的净化能力, 空间注意力模块提高幅度远小于通道注意力。

表5 不同注意力机制组合下的防御精度
从表5中还可以看出, 当尝试将注意力模块串联时, 生成图片的鲁棒性将下降, 而并行使用注意力模块则将使模型鲁棒性提高。这说明不同注意力模块对特征图学习到的权重可以相互促进, 而串行使用则会提前修改特征图, 使注意力机制不在能准确提取信息。
3.4.2 损失函数Lscam
损失函数Lscam不仅能使生成器准确净化对抗样本, 而且在保持净化图片与原始图片一致性上也有重要作用。调整Lscam的使用位置, 共有4种情况:不使用Lscam, 只在生成器中使用Lscam, 只在辨别器中使用Lscam, 以及将Lscam应用于整个训练过程中。需要注意的是,Lscam需要用到辅助分类器ηGc,ηGs,ηDc和ηDs的结果, 不使用Lscam也表示对应辅助分类器的失效。不同损失函数情况下的防御精度如表6所示。由表6可知, 在生成器中使用并行注意模块在一定程度上提高了模型的鲁棒性, 但在辨别器中单独使用该模块会降低模型受到攻击时的精度。这可能是如果在对抗过程中, 辨别器的能力比生成器强得多, 则生成器就不能在对抗过程中增长。因此在整个训练中使用注意力模块时, 辨别器和生成器的能力被同时增强, 能更准确地提取图像中的个体特征和空间信息。

表6 不同损失函数情况下的防御精度
4 结 语
笔者提出基于平行注意力机制净化对抗样本的预处理生成模型, 其内部通过并行注意力机制模拟视觉行为, 综合图片的个体特征和空间信息, 清除输入中可能包含的恶意扰动, 给出净化后的图片, 有效防御对抗样本攻击。在黑盒或白盒背景下, 该方法在面对多种攻击时都表现出最好的防御能力。由于防御模型的训练无需改动原始模型, 因此即使已经部署使用的机器学习模型, 该防御方法仍然对其有防御效果。由于设备的限制, 笔者只在较小的数据集上进行了实验, 而如何应对大规模数据集的对抗样本攻击将是以后研究的重点。笔者提出的防御具有一些独特的特性, 包括广泛的适用性和丰富的设计空间, 对其进一步探索可能会带来更多有效的防御。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
小雪花·成长指南(2022年1期)2022-04-09
红领巾·萌芽(2019年8期)2019-08-27
当代水产(2019年3期)2019-05-14
中国与非洲(法文版)(2017年10期)2017-11-23
Coco薇(2017年7期)2017-07-21
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
金色年华(2016年23期)2016-06-15
CHIP新电脑(2016年3期)2016-03-10
