
车路协同条件下智能网联汽车一体化决策模型
2022-12-09 06:58:20熊明强胡文力
汽车工程学报 2022年6期
熊明强,胡文力,谯 杰,夏 芹,张 强,江 萌
(1.汽车噪声振动和安全技术国家重点实验室,重庆 401122;2.中国汽车工程研究院股份有限公司,重庆 401122;3.中国市政工程西南设计研究总院有限公司,成都 610084)
近年来,世界各国对自动驾驶格外关注[1-10],被认为是缓解交通拥堵,减少交通事故和环境污染的重要技术[1,6,11]。目前,一些自动驾驶汽车已经进行了大规模的道路测试,比如谷歌自动驾驶汽车和苹果自动驾驶汽车。据研究[12],在当前的交通事故中,有超过30%的道路事故是不合理的换道和跟驰行为引起的。如图1所示,在一个单向两车道上,主车为SV,PV是与SV当前所在车道的前车,LV和FV分别是SV目标车道的前车与后车。其中,穿过两条车道的线是车辆SV的行驶轨迹,车辆在O点结束对前车的跟驰并开始准备换道,P点开始由跟驰行为转为换道行为,D点完成换道,设换道起点为P(0,0),那么换道终点为D(x(tf),y(tf))。车辆完成换道准备后开始执行换道,SV从当前车道的中心线沿着图中所示的虚线发生移动,一直移动到目标车道的中心线,在此过程中,SV的位置和速度会受到LV、PV、FV三辆车的影响,正常的过程应该是SV在这3辆车的共同影响下安全舒适且高效率地完成换道。
强化学习模型在20世纪已有研究,WATKINS[13]第1次将动态规划和时间异步方法结合在一起,并提出了Q-Learning算法。目前,基于机器学习的方法对自动驾驶决策的研究还比较少[14-20],利用机器学习进行自动驾驶车辆换道轨迹规划的模型需要经过大量已有的换道数据训练来确定。MNIH等[21]在已有研究基础上将Deep-Qlearning应用于自动驾驶换道决策中,用于克服无限场景带来的数据不足和决策安全性问题。但是,对于微观层面的自动驾驶换道轨迹的规划多是基于规则的模型,现实场景的无限化导致该类模型存在维度爆炸等难题。由于深度学习模型没有考虑到车辆决策过程中的安全性和合理性,针对于此,结合基于深度学习的换道和跟驰方法,以及深度强化学习的决策方法,提出了车路协同条件下智能网联汽车一体化决策模型,使用深度强化学习方法对模型进行训练和尝试,最后使用自动驾驶仿真环境highway-env和动力学仿真软件CarSim对本模型输出结果进行了验证。
1 算法框架
提出的模型框架如图2所示,主要包括环境信息模块、强化学习动作选择模块和深度学习动作执行模块。环境信息模块主要为强化学习动作选择模块,以及为动作执行模块搜集所需的信息,包括当前时刻周边车辆信息、当前时刻周边道路信息、下一时刻周边道路信息、下一时刻周边车辆信息和本车车辆信息,其中包含的内容有本车状态信息、周围车辆状态信息、障碍物状态信息和环境状态信息。在强化学习动作选择模块中,基于长短期记忆(Long Short-Term Memory,LSTM)神经网络使用了A2C算法,根据环境信息决策车辆下一时刻的行为(是否变化速度、是否换道),如果该行为没有碰撞或者使行程时间变短,则进行奖励,反之则进行惩罚。奖励函数包括两个方面:车辆的安全性和车辆行驶效率,并以此为衡量标准来获取车辆在环境中动作时可以获取的最大累计奖励,通过接受环境对动作的奖励(反馈)获得学习信息并更新模型参数,最后达到模型的奖励收敛,实现模型在交通环境中的应用。在动作执行模块中,同样基于LSTM神经网络对强化学习输出的动作进行执行,其原理是当强化学习模块输出的车辆动作为换道时,执行模块自动切换到换道模型,当强化学习模块输出的车辆动作为跟驰时,执行模块自动切换到跟驰模型。最后,根据highway-env中自带的控制模型进行动作执行,从而更新状态信息。
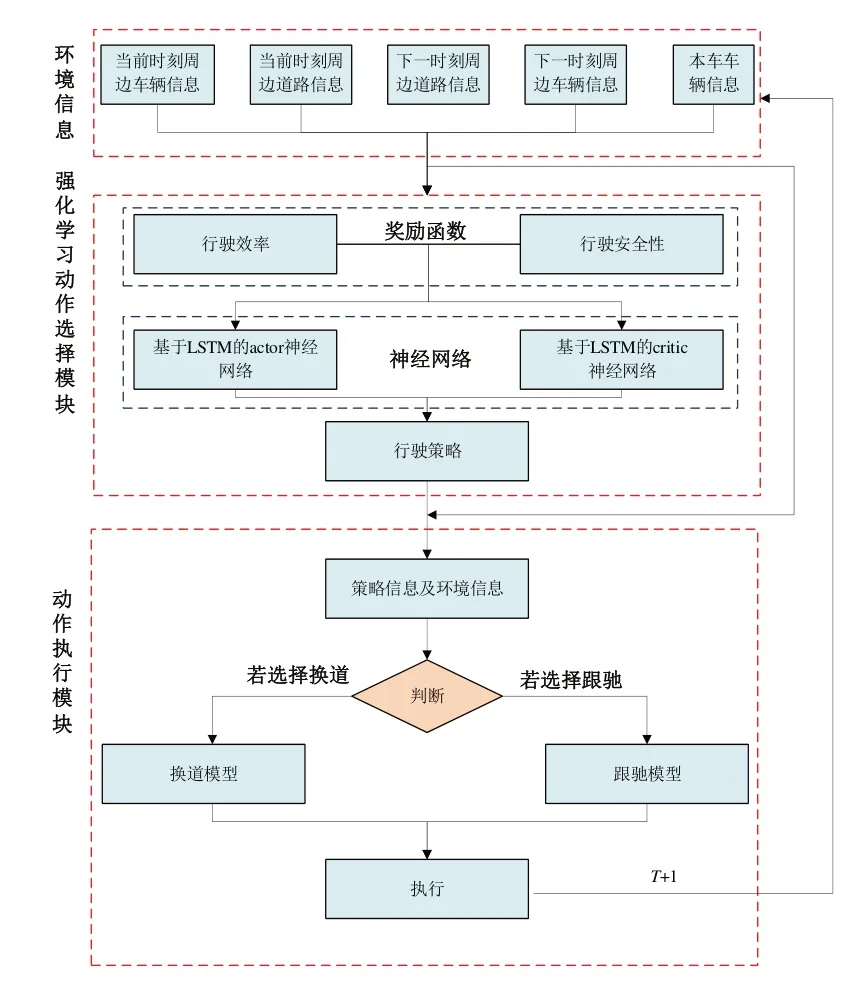
图2 模型框架
1.1 环境信息模块
车路协同是使用无线通信和传感技术,实现交通参与者之间动态信息的交互和共享。车路协同环境下,汽车主要获取当前时刻周边车辆信息、当前时刻周边道路信息、上一时刻周边道路信息、上一时刻周边车辆信息和本车车辆信息。主要通过两种方式取得此类消息,一种是车-车通信,另一种是车-路通信。车辆间彼此通过安装的车载单元(On Board Unit,OBU)进行信息传递和交互,主要包括车辆的姿态信息、速度信息、位置信息以及CAN信号。路侧单元(Road Side Unit,RSU)是物理位置上固定的交通状态监测设备,以及连接人-车-路的通信设备。它的主要功能是收集路侧传感单元感知的道路环境信息(如交通流量、车辆行驶状态、道路交叉口状态、信号灯控制信息等)。车路协同通信模组,如图3所示。
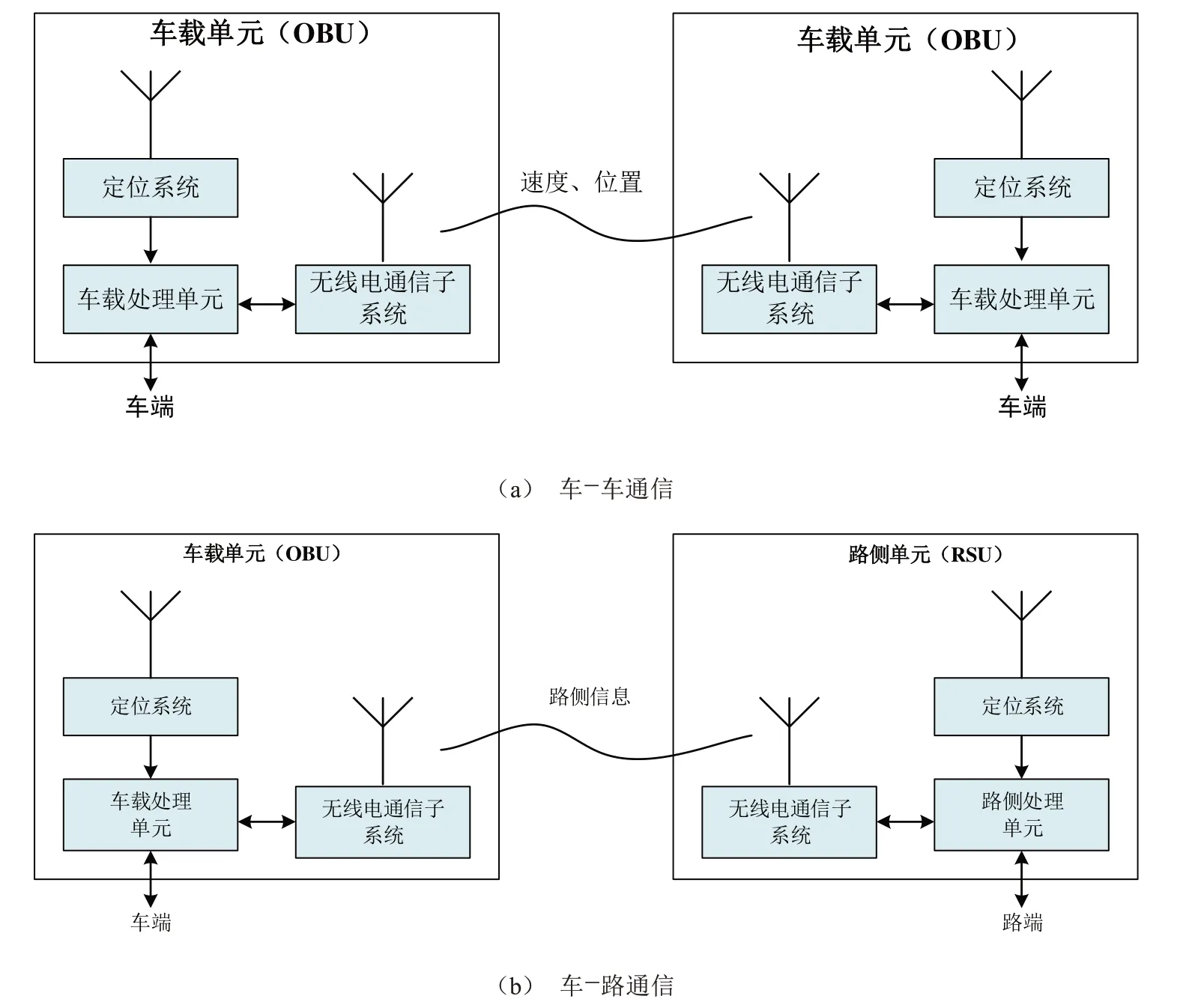
图3 车路协同通信模组
1.2 动作选择模块
1.2.1 神经网络
Actor-Critic算法流程,如图4所示。首先系统会提供一个仿真的交通环境以及一个主车(SV),主车行驶在交通环境中,在行驶过程中不断采取各种动作,并观察交通环境中其他交通参与者以及自身的状态,同时记录所观察的数据供主车学习,主要学习应对各种交通状况下的动作策略,从而让车辆更加安全高效地完成行驶。主车学习的方法即为Actor-Critic算法,该算法包含两个网络:一个网络为Actor网络,采用对时间序列数据更敏感的LSTM神经网络,输出车辆下一时刻的某个动作(是否换道、下一时刻目标速度),另一个网络为Critic网络,同样也采用对时间序列数据更敏感的LSTM神经网络,负责对Actor网络输出的动作进行评价,如果该动作是有益的,Critic网络则增加下次遇到该种环境状态时选择该动作的概率,如果该动作是有害的,Critic网络则减小该种环境状态下采用该动作的概率。交通环境瞬息万变,深度强化学习方法在与环境交互的过程中学习,可以更好地捕捉到影响驾驶行为的隐性因素,弥补传统机器学习时单纯复刻已有数据的不足。
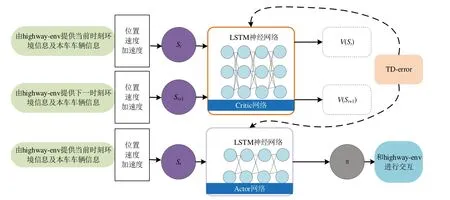
图4 Actor-Critic算法流程
由于车辆在行驶过程中产生的是时间序列数据,此类数据通常符合马尔科夫决策过程,而强化学习恰好是基于该过程进行的。将马尔可夫决策过程定义为:
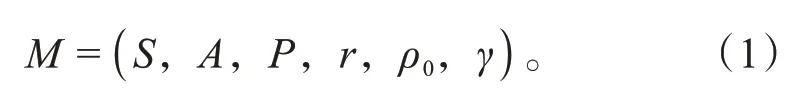
式中:S为所有状态(state)的集合,也称为状态空间,状态空间的大小可以是有限的,也可以是无限的。ρ0(s0)为初始状态s0的分布。A为所有动作(action)的集合,也称为动作空间,模型确定的动作空间主要包括3个:换道、跟驰和目标速度。P∈R(|S|×|A|)×|S|为状态转移概率(state transition probability)。具体来说,P(s′|s,a)为在s的环境下车辆采取动作a从而环境产生状态s′的概率。显然,对于任意(s,a,s′)而言,都有0≤P(s′|s,a)≤1,并且∑s′P(s′|s,a)=1。r∈R||S×|A|为状态转移过程的奖励函数(reward function)。r(s,a)为环境状态为s时车辆采取动作a所得到的奖励。奖励函数也有其他定义方式,r:S→R或者r:S×A×S→R。这3种的主要区别在于奖励函数和状态转移过程中的哪些元素相关。γ为状态转移过程中的折扣系数(discount coeきcient),通常在区间(0,1)中。
通常会定义离散时间步t=0,1,2,...,用来描述交互过程中的状态和动作。一般而言,马尔科夫过程服从,如式(2)所示。
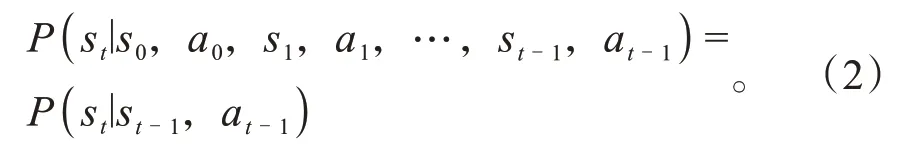
A2C算法通过计算V值来确定Critic网络的损失值,其表示方法如式(3)所示。
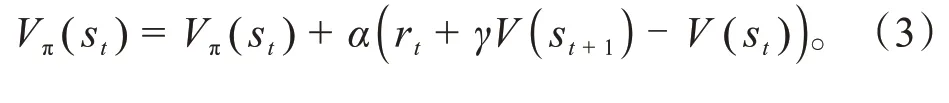
式中:V为状态值函数,即车辆达到某个状态所能够获取的奖励值;st为当前时刻状态;st+1为下一时刻状态;α为学习率;γ为折扣因子;rt为当前环境下做出该动作的奖励值。
Actor网络的更新方式,如式(4)所示。
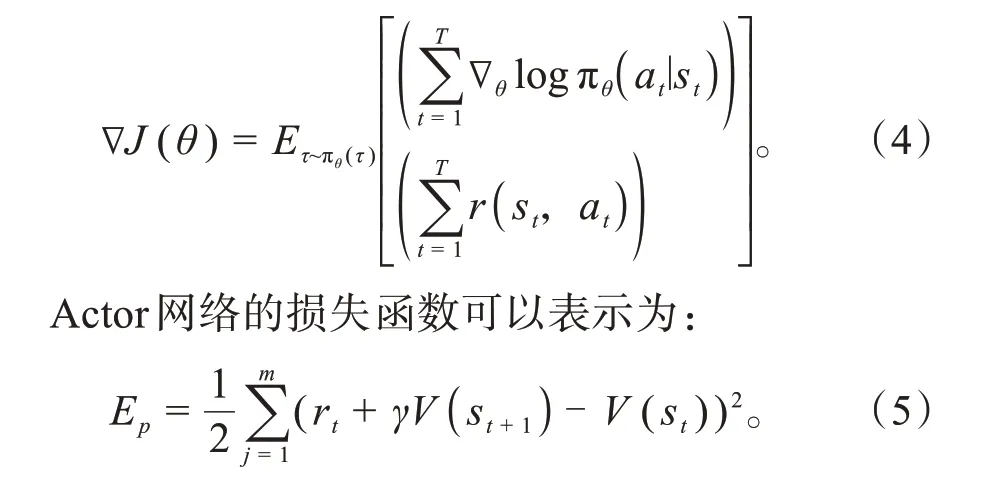
通过梯度下降更新Actor神经网络,如式(6)所示。
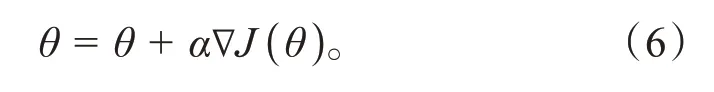
1.2.2 奖励函数
根据对智能网联汽车行驶过程中的效率和安全性要求,将奖励函数设置为:
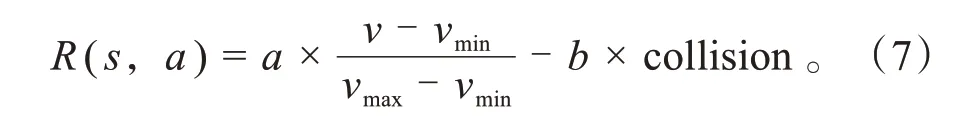
式中:v为车辆实时速度;vmin为车辆训练过程中采用的最小速度;vmax为车辆训练过程中采用的最大速度;a为对于换道过程中的速度奖励值;b为对车辆发生碰撞时的碰撞惩罚值;collision为仿真环境对于车辆发生碰撞的反馈结果。
在跟驰和换道过程中,如果发生碰撞,则collision值为1,反之则为0;速度奖励是关于最大速度和最小速度的线性函数。
1.3 动作执行模块
动作选择模块输出车辆是否换道,本节利用深度学习方法进行规划执行,跟驰模型和换道模型各为一个LSTM神经网络,具体输入参数选择本车以及环境中其他交通参与者的横向位置、纵向位置、速度作为神经网络的输出,输出下一时刻本车的位置和速度。LSTM数据流程,如图5所示。
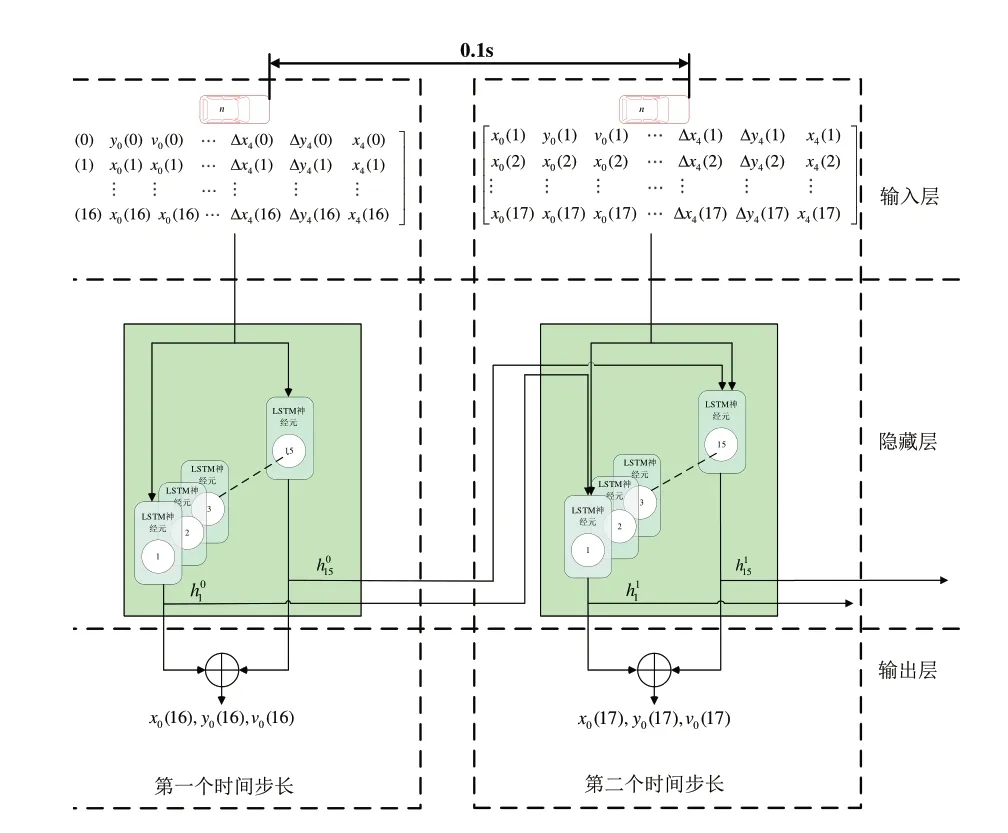
图5 LSTM数据流程
由于车辆跟驰和换道数据均属于时间序列数,LSTM神经网络是对时间序列量身定制的,其独特的“门”结构和“状态”结构可以对智能网联汽车观测的历史数据进行去粗取精,深度挖掘对目标行为有关联的数据。
LSTM神经网络结构如图6所示,主要由输入层、隐藏层、输出层神经元构成[23]。其中,隐藏层神经元主要由3个门结构以及一个状态构成:遗忘门、输入门、输出门、细胞状态。
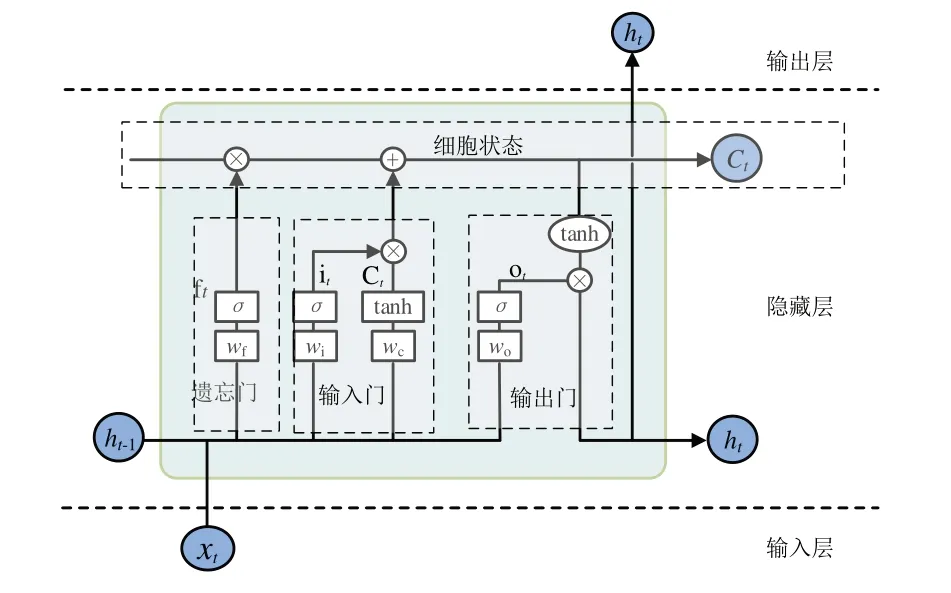
图6 LSTM神经网络结构
首先,在新数据传入LSTM神经网络时要决定哪些和车辆决策无关的特征数据需要从细胞状态ht-1中删除,如式(8)~(9)所示。
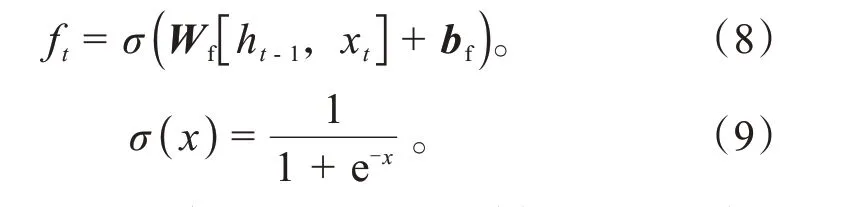
式中:Wf为权重矩阵;ht-1为上一时刻的细胞状态;xt为输入数据;bf为偏置矩阵。
其次,由输入门通过一个sigmoid函数层决定被更新的数据,再由一个tanh函数层将车辆决策所需的特征数据加入到细胞状态,如式(10)所示。
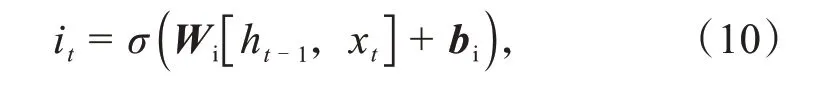
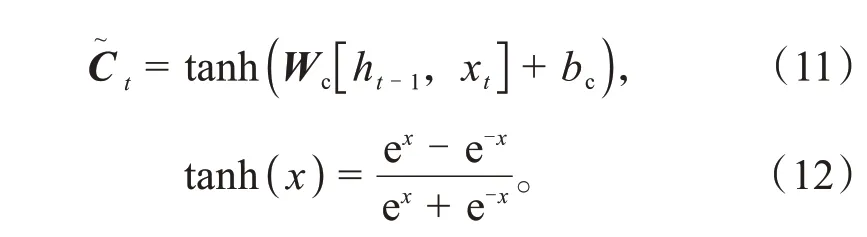
式中:bi为输入门的偏置矩阵;为准备用以更新的数据矩阵;Wc为准备用以更新的数据的权重矩阵。
第3步是更新上一时刻细胞状态,首先从细胞状态移除掉在忘记门删除的数据;然后将该数据乘以一个权值从而将加权的数据也加入细胞状态,如式(13)所示。
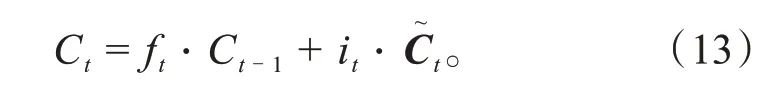
最后,LSTM神经网络决定车辆每个时刻的速度值。输出是在细胞状态Ct的基础上进行适当的处理。通过一个sigmoid函数层决定细胞状态Ct中被更新的数据,并将其数据进行归一化。
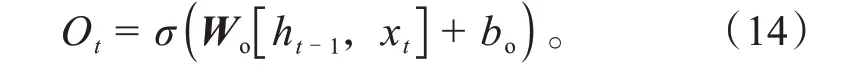
式中:Wo为输出门的权重矩阵;bo为输出门的偏置项。
LSTM神经网络最终输出为:
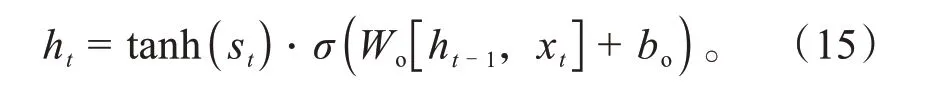
2 模型验证
主要包括两部分:一是通过动作选择模块输出的换道决策信息验证是否可以有效降低车辆在行驶过程中的各种碰撞风险;二是动作执行模块输出的轨迹是否符合动力学特性,分别通过highway-env和CarSim仿真软件进行分析。
2.1 仿真环境介绍
OpenAI旗下的GYM提供了一种支持车路协同的仿真环境highway-env[24],highway-env是一个可交互、可定制的仿真环境,包括高速公路直道、匝道汇入、环形路口、停车场等场景。该模拟器允许在10 Hz下模拟40 s,支持参数调整,且可接入不同动力学模型,深度学习框架可接入该模型,支持车路协同条件仿真将使用高速公路场景。
车辆行驶过程中可能发生各类风险,如图7所示,车辆在行驶过程中发生了追尾、侧撞等交通事故,图7 a~c展示了因主车不安全的换道行为导致和周边车辆发生碰撞,图7 d展示了主车不安全的跟驰行为和前车发生碰撞。
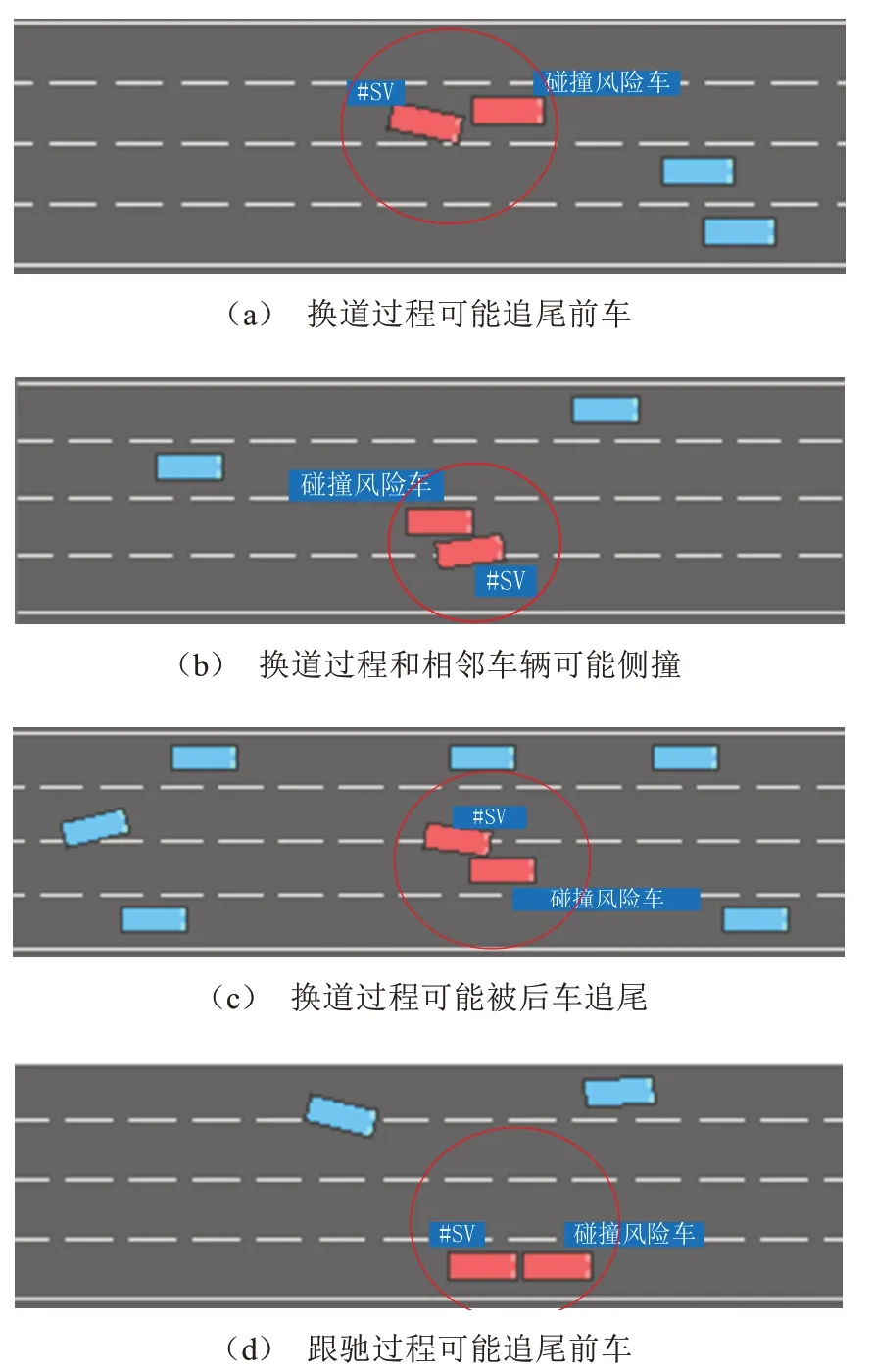
图7 车辆行驶过程中可能发生各类风险
2.2 结果分析
对模型训练输出的执行数据进行验证,主要验证对象包括车辆规划的速度与实际速度的误差,以及车辆规划的位置与实际位置的误差。主要的验证指标有:平均绝对误差(Mean Absolute Error,MAE)以及平均绝对相对误差(Average Absolute Relative Error,MARE)。
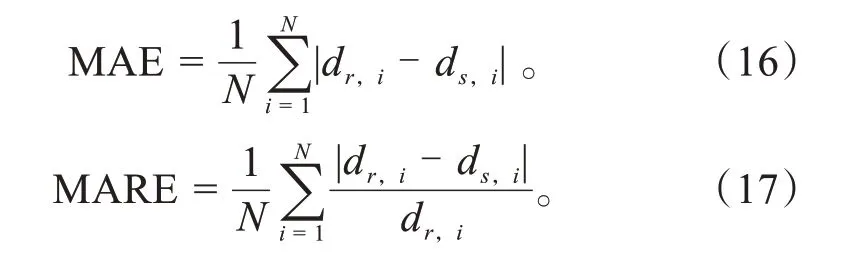
式中:N为测试数据样本数;dr,i为第i辆车的实际值;ds,i为第i辆车的规划值。
由表1可以看出,规划值和实际值偏差较小,执行模块有效。
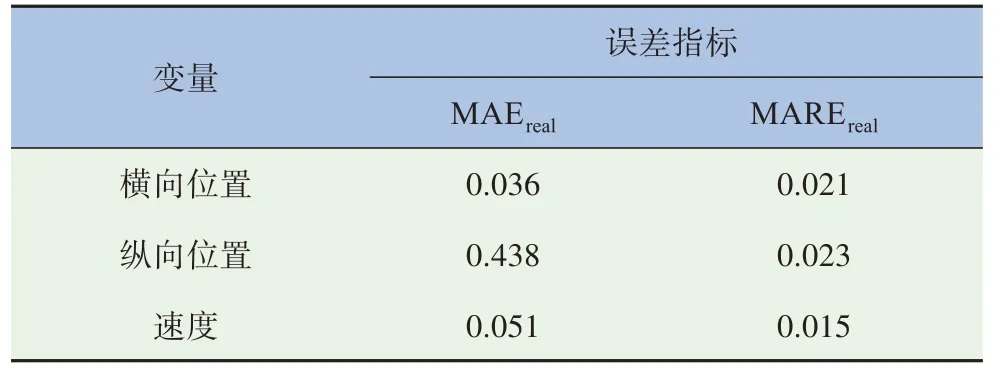
表1 规划值和执行值的误差指标
2.2.1 训练结果
LSTM神经网络,在单向三车道条件下模型训练收敛后,将训练好的模型在单向双车道、单向三车道、单向四车道条件下对模型进行验证。训练过程收益如图8所示。由图可知,训练收益随着训练时间增加快速上升,训练超过2 000次时,收益值稳定并且趋于收敛。仿真环境highway-env环境参数主要分为3类,第1类是道路参数,主要包括车道数、道路宽度等;第2类是车辆参数,主要包括车辆动力学参数及车辆属性等;第3类是强化学习参数,主要包括碰撞惩罚值及加速奖励等,具体设置见表2。
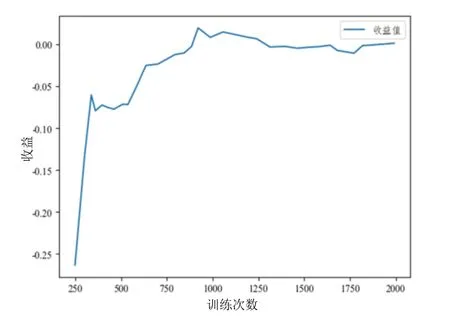
图8 训练过程收益
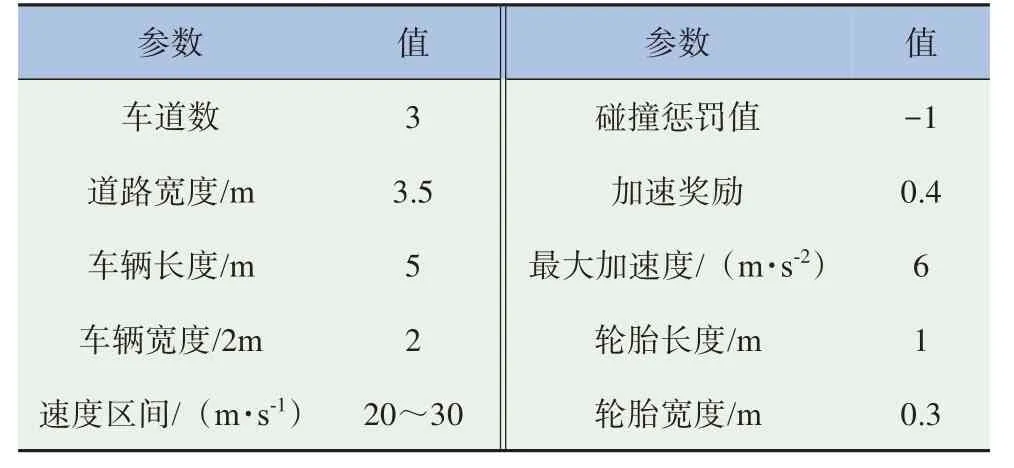
表2 highway-env环境参数
2.2.2 和已有模型对比分析
由图9可知,车辆换道和跟驰过程中,为避免换道过程中发生碰撞以及争取减少行程时间,将单向双车道、单向三车道、单向四车道和传统模型[25]进行对比,换道环境中每辆车后部淡色的方框表示在过去5个时间步长的历史轨迹。图9 a为训练前车辆在双车道换道过程中发生碰撞;图9 b为训练后车辆在双车道换道过程中成功实现换道的场景,在三车道及以上的车道环境下,车辆如果处于中间车道,会面临更复杂的换道决策问题;图9 c为训练前车辆在三车道换道后和前车发生碰撞;图9 d为训练后车辆在三车道成功换道的场景;图9 e为训练前车辆在四车道发生碰撞;图9 f为训练后车辆在四车道成功换道的场景。总的来说,本模型在验证过程中,行程时间减少21.2%,碰撞概率减少26.3%,见表3。
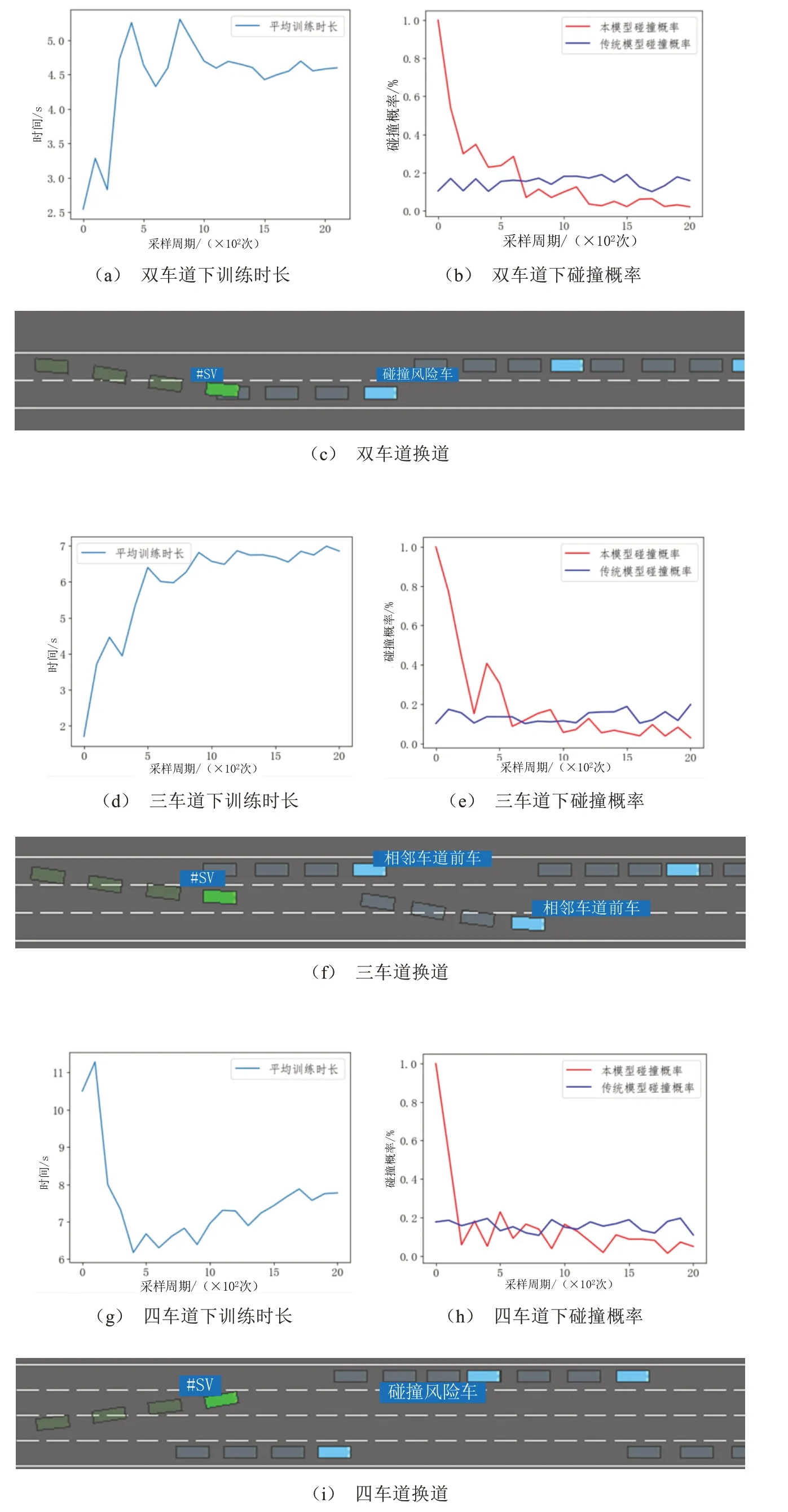
图9 自动驾驶车辆在不同车道数下的行驶状况
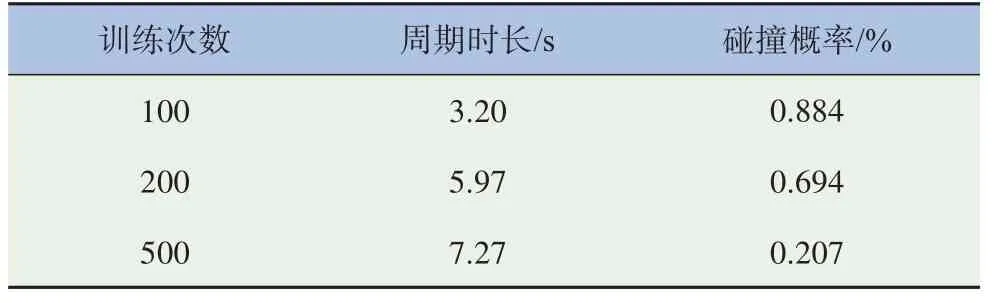
表3 碰撞概率统计
2.3 基于CarSim的仿真验证
将模型输出的车辆轨迹数据作为CarSim输入,对模型轨迹的可跟踪性、平稳性等参数进行评估。
本节对验证过程中产生的轨迹随机选择一组输入到CarSim仿真软件中进行动力学仿真,图10所示车辆SV在成功换道场景下预测本模型的仿真结果。图10a所示车辆SV在成功换道场景下,本模型输出轨迹的仿真结果,其中蓝色曲线为本模型输出的轨迹,即目标轨迹,红色轨迹是CarSim仿真条件下的跟踪轨迹,由图可知,本模型输出的轨迹在动力学仿真中变化平稳,可以在和目标轨迹保持较小误差的条件下被跟踪。图10 b所示车辆SV在成功换道场景下,车辆轮胎的侧向滑移角,4个车轮的变化保持一致,变化的数值较小。图10 c所示换道条件下的车辆质心偏移角,整个换道过程中的角度偏移在±0.3°以内且变化均匀。图10 d所示车辆换道过程中的车辆横摆角速度,在换道中途发生速度变化且变化均匀,满足平滑性需求。
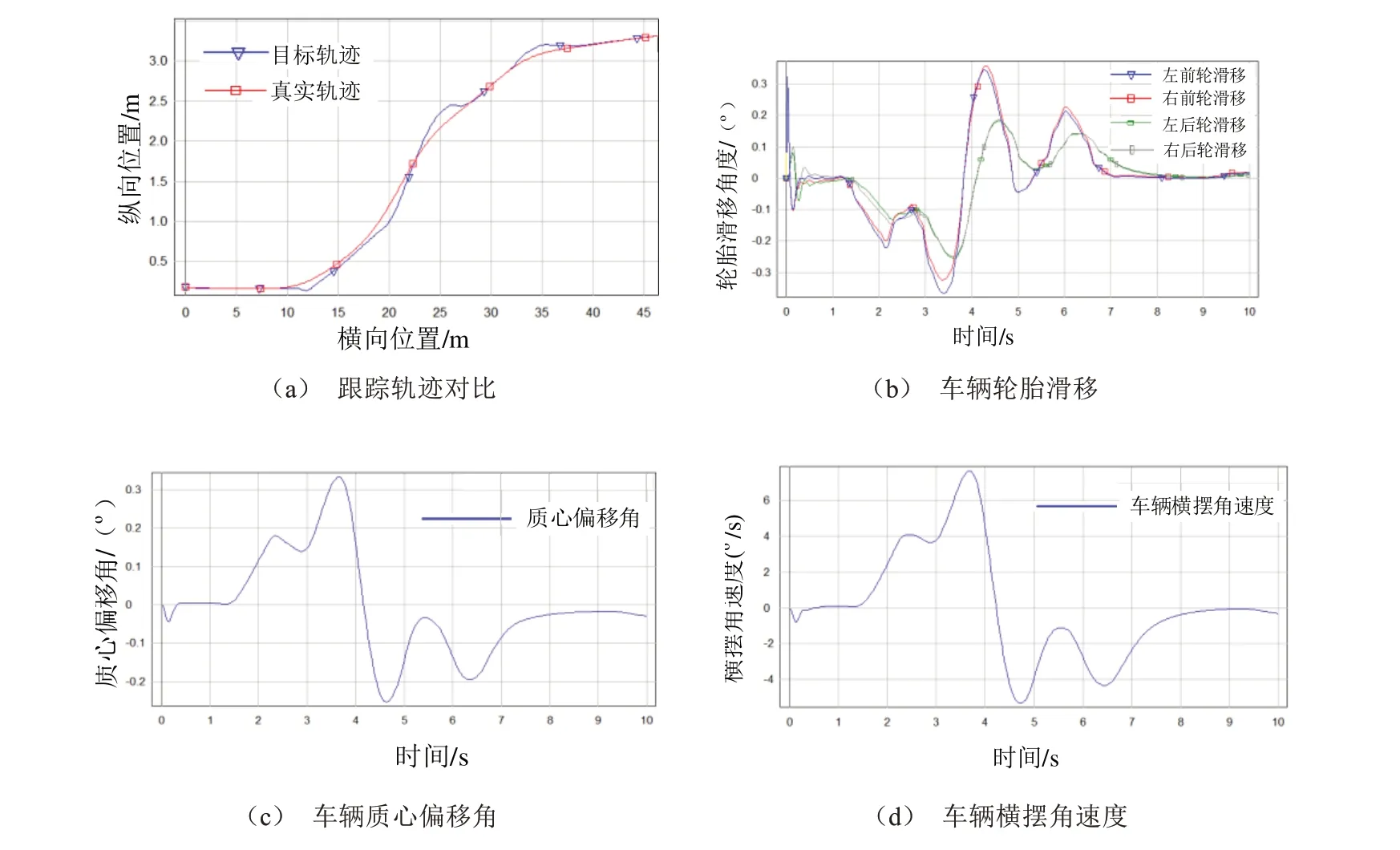
图10 换道场景各参数曲线
3 结论
提出的基于深度强化学习的智能网联汽车一体化决策模型,综合考虑了已有决策模型的不足,对于有限数据下神经网络如何能适应和学习到更多驾驶技巧的问题进行探索,得出以下结论:
(1)利用本模型可以规划出一条合适的智能网联汽车行驶轨迹,且能保证车辆能够更安全、更高效地完成跟驰和换道。
(2)仿真发现,构建的换道轨迹规划模型可以用于自动驾驶车辆换道的场景。车辆可以在有限的数据量条件下对新的交通场景做出合理的反应。
(3)CarSim的仿真显示,提出的模型所规划出的换道的轨迹和速度能够被智能网联汽车跟踪,车辆行驶稳定性良好。
猜你喜欢
卫星应用(2021年11期)2022-01-19 05:13:02
科学大众(2021年9期)2021-07-16 07:02:50
中国交通信息化(2020年11期)2021-01-14 03:30:34
电子制作(2019年19期)2019-11-23 08:42:00
小太阳画报(2018年3期)2018-05-14 17:19:26
阅读与作文(小学低年级版)(2016年12期)2016-12-22 19:35:04
少年博览·小学低年级(2016年9期)2016-11-24 06:21:37
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
汽车文摘(2015年11期)2015-12-02 03:02:53
