
密度偏差抽样在近邻传播聚类中的应用
2022-12-07 05:24:26潘春燕张仁崇杨忠保
商丘师范学院学报 2022年12期
潘春燕,张仁崇,杨忠保
(1.黔南民族师范学院 数学与统计学院,贵州 都匀 558000,2.贵州商学院 计算机与信息工程学院,贵州 贵阳 550014)
聚类分析是数据挖掘中的一项技术,通过聚类分析不仅可获得数据内部结构还可作为其他数据挖掘方法的预处理步骤以及对数据噪声点、孤立点的检测,在数据挖掘中占有较高地位.因此寻求一种适用性较强、能高效解决任意分布数据和应用场景的聚类方法尤为重要.近年来,根据数据规模、数据分布特征以及应用场景,研究聚类的方向主要有:一是提出新的聚类算法,二是根据实际需要优化传统聚类算法.
AP聚类算法被学者Frey和Dueck在2007年提出[1],该聚类算法无需人为设定类别和指定初始类中心、稳定性好能高效处理数据分类问题,但算法仍存在不足[2],如偏向参数会直接影响最终聚类数,选择不当会导致聚类结果不优;时间复杂度高,无法满足大规模数据的应用需求.针对AP聚类算法选择偏向参数问题,2014年,Chen等人通过提出的稳定性来设置偏向参数[3],2017年,唐丹基于其它所有点到某点的隶属度之和越大则假设该点成为类代表可能性越大来选择偏向参数[4];针对AP聚类算法计算时间复杂度高问题已有学者引入抽样技术,通过减少数据输入来提高聚类效率[5,6],但算法处理大规模数据其效率有待提高[7].2014年刘晓楠等人提出分层近邻传播聚类算法来解决大规模数据的应用需求,该算法聚类效果较好也极大降低聚类时间[8];2017年,孙劲光等人采用随机采样思想并通过引入Nyström逼近策略求解相似度矩阵,降低算法的时间复杂度[9].2019年,刘槿通过简单随机抽样、密度偏差抽样对数据进行约简,降低AP聚类的时间复杂度,对分布偏斜的数据引用密度偏差抽样,样本聚类得到较好的结果[10],但数据规模较小,针对分布偏斜的大规模数据,AP聚类算法如何在保证原始数据信息的分布特征、类不丢失条件下对数据进行约简、合理减少数据输入来提高算法的效率极为重要.
针对分布偏斜的大规模数据,借助简单随机抽样和基于网格的密度偏差抽样对进行数据约简,再对样本数据执行AP聚类,通过减少数据输入来降低算法时间复杂度,探讨适用于分布偏斜的大规模数据进行AP聚类时的约简技术.
1 算法
1.1 AP聚类算法
AP聚类算法是引入因子图理论、是基于数据点间“信息传递”的一种聚类算法,算法在聚类开始时把所有数据点都认为是潜在的类代表点,实现步骤如下[10]:
步骤1 根据包含m维、n个数据点的原始数据集N={xi1,xi2,…,xim},i=1,2,…,n,首先计算相似度矩阵Sn×n,式(1)为第i个、第k个数据点的相似性,其中S的均值为对角线元素偏向参数初始值,此时支持度矩阵R和归属度矩阵A都为0.
S(i,k)=-‖xi-xk‖2
(1)
步骤2 计算支持度R和归属度A,计算公式为式(2)、(3).
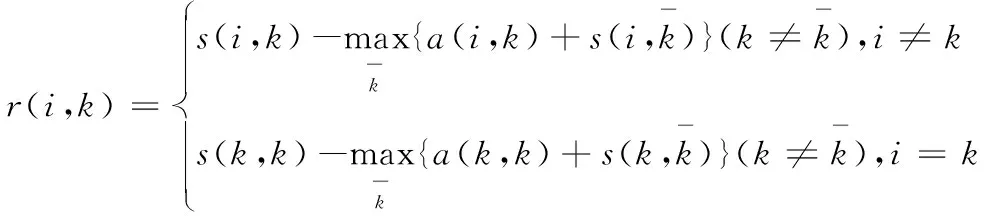
(2)
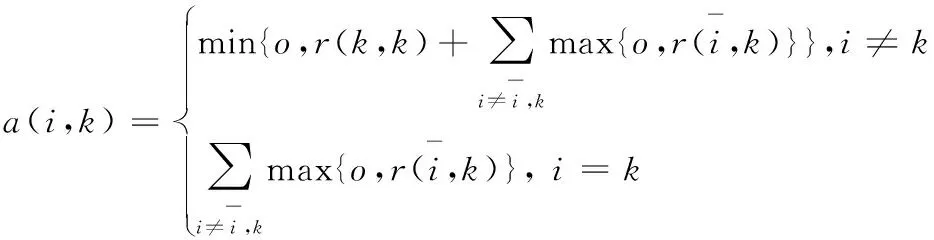
(3)
步骤3 更新支持度R和归属度A的消息.
步骤4 判断是否继续迭代:若聚类结果保持不变或是迭代次数达到最大值则迭代结束,进行下一步,否则转步骤2.
步骤5 根据式(4)计算决策矩阵E.其中对角线元素若E(k,k)>0,则k为最终类代表点,剩余点分配时,观察每一行的最大值,若第k行的最大值为E(k,j),则表示点j为点k的类代表点.
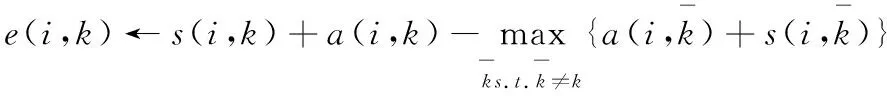
(4)
1.2 基于网格的密度偏差抽样AP聚类算法
根据不同网格划分方法获得的网格空间不同,实现相异的基于网格划分的密度偏差抽样算法.首先对原始数据集进行抽样约简数据,再对样本数据集执行AP聚类,从而实现基于网格的密度偏差抽样AP聚类算法,算法实现步骤如下:
输入:原始数据集N,样本量n.
输出:样本数据集Sn聚类结果.
步骤1 对原始数据集完整扫描一次,输入不同网格划分方法所构成的网格空间.
步骤2 统计网格空间包含的网格总个数g、各个网格总数据点个数ni,i=1,2,…,g.

步骤4 针对第i个网格,若ni=0,则令i=i+1.
步骤5 对网格空间的每个网格单元执行第2步到第3步.
步骤6 整合样本点构成样本数据集,对样本数据集上执行AP聚类,其中算法使用欧氏距离计算相似度矩阵,偏向参数值为原始AP算法的默认值.
步骤7 输出样本数据集Sn聚类结果.
从实现步骤可知,步骤3在同一个网格里各个数据点被抽取的概率一样,抽样概率函数f(ni)是递减函数,网格包含的数据量ni越大f(ni)越小,反之f(ni)越大,在各个网格实现密度偏差抽样从而获得样本数据集,其中e值常设为0.5.
2 评价标准与数值实验
2.1 评价标准
(1)聚类精度(AC):本文用外部评价方式精度[15]来评估聚类结果,计算公式为式(5),其中TC是聚类结果中类别正确的样例总数,FC是聚类结果误判的样例总数,AC∈[0,1],若AC越大,聚类精度越高.
(5)
(2)聚类个数(NC):此度量数据集进行AP聚类时自动聚类的类数,若NC与原始数据的类越接近聚类效果越好.
(3)迭代次数(NI):此度量各样本数据集在进行AP聚类时的迭代次数,若NI越小,聚类算法的效率越高.
(4)聚类耗时(AR):此度量数据聚类的运行效率,若AR越小,算法的效率越高.
2.2 数值实验
数值实验在同一台版本为Windows10_64位、CPU/2.6 GHz、RAM/8.0 GB的计算机,实验工具为VC++和RStudio的平台上展开,其中抽样算法在C++上进行,AP聚类直接调用R的apcluster函数包.测试事例包括来自文献[13]的人工数据集类型Data和UCI标准数据集,数据Data、Page-blocks分布偏斜较大,Waveform3分布较均匀,测试事例详细信息如表1所示.分别比较分析SRS算法[11]、G_DBS算法[12]、VG_DBS算法[13]以及AVVG_DBS算法[14]按相同抽样比例所获得的样本数据执行AP聚类的结果.

表1 测试数据集的数据信息
2.2.1 抽样效果分析
抽样效果分析测试事例是Data,该数据总有100万个数据点,数据分布不均匀,最大的类含有78万个数据点,最小的类仅含有1000个数据点,分别对Data按0.1%、0.01%抽样比例抽取1000、100个样本点,各抽样算法所获得的样本数据集详细信息如表2所示、分布特征见图1.
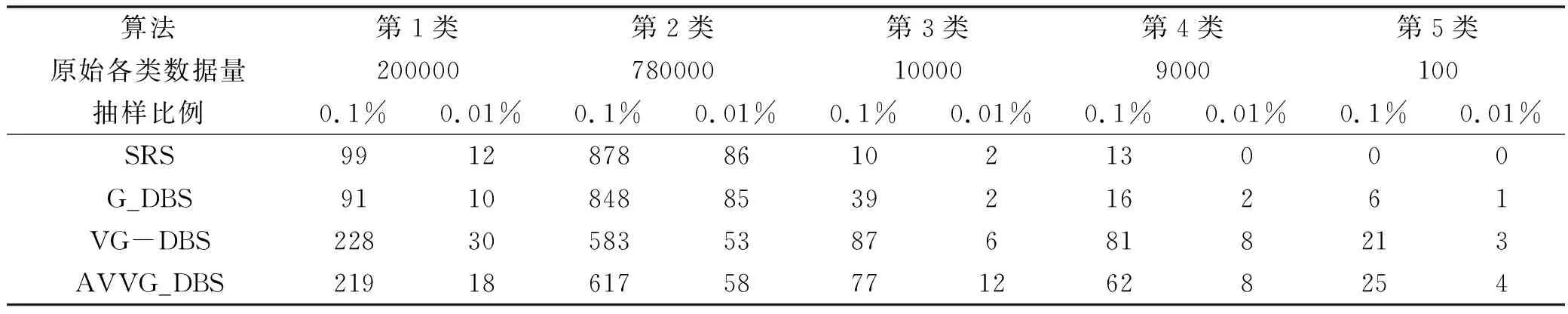
表2 原始数据集及各抽样算法样本数据集详细信息
根据表2获知,按0.1%抽取1000个数据点,SRS算法丢失第5类,按0.01%抽取100个数据点,SRS算法丢失第4、5类,在数据量为1000个数据点的第5类G_DBS算法分别取得6、1个数据点,VG_DBS算法分别取得21、3个数据点,AVVG_DBS算法分别取得25、4个数据点.由此可知,当抽样比例低样本量少时,SRS算法易造成类的丢失,其他三种算法均无类丢失,AVVG_DBS算法在数据量最小的类所获得的样本量较多,不易丢失类,结合图1知AVVG_DBS算法的样本数据较好的保留原始数据集分布特征.

图1 各抽样算法不同比例样本分布
2.2.2 样本集AP聚类效果分析
首先对UCI标准数据集Page-blocks、Waveform3进行AP聚类,其聚类结果统计的类数、迭代次数和聚类执行时间见表3.

表3 AP聚类算法在UCI标准数据集上聚类结果
由表3获知,对数据量为5473、10维的数据Page-blocks,AP聚类自动聚类个数为188个,与原始数据类个数5相差较大,迭代443次,耗时2069.98 s;对数据量为5000、21维的数据Waveform3,自动聚类个数为139个,与原始数据类个数3相差较大,迭代260次,耗时546.87 s.由此可知对原始数据直接执行AP聚类迭代次数较多、耗时较高且自动聚类个数与原始数据的类个数相差较大,下面对各抽样算法的样本数据进行AP聚类.
由于SRS算法丢失类不用于聚类效果分析,对G_DBS算法、VG_DBS算法、AVVG_DBS算法所获得的样本执行AP聚类分别记为G_DB_AP算法、VG_DBS_AP算法、AVVG_DBS_AP算法,实验数据为表1的测试实例.图2的(b3)-(d3)、(b4)-(d4)分别为人工数据Data按抽样比例为0.1%、0.01%抽样所获得的样本数据运行cutree(aggres,k)聚类的结果,其中k为样本数据集信息包含的原始数据类的个数.
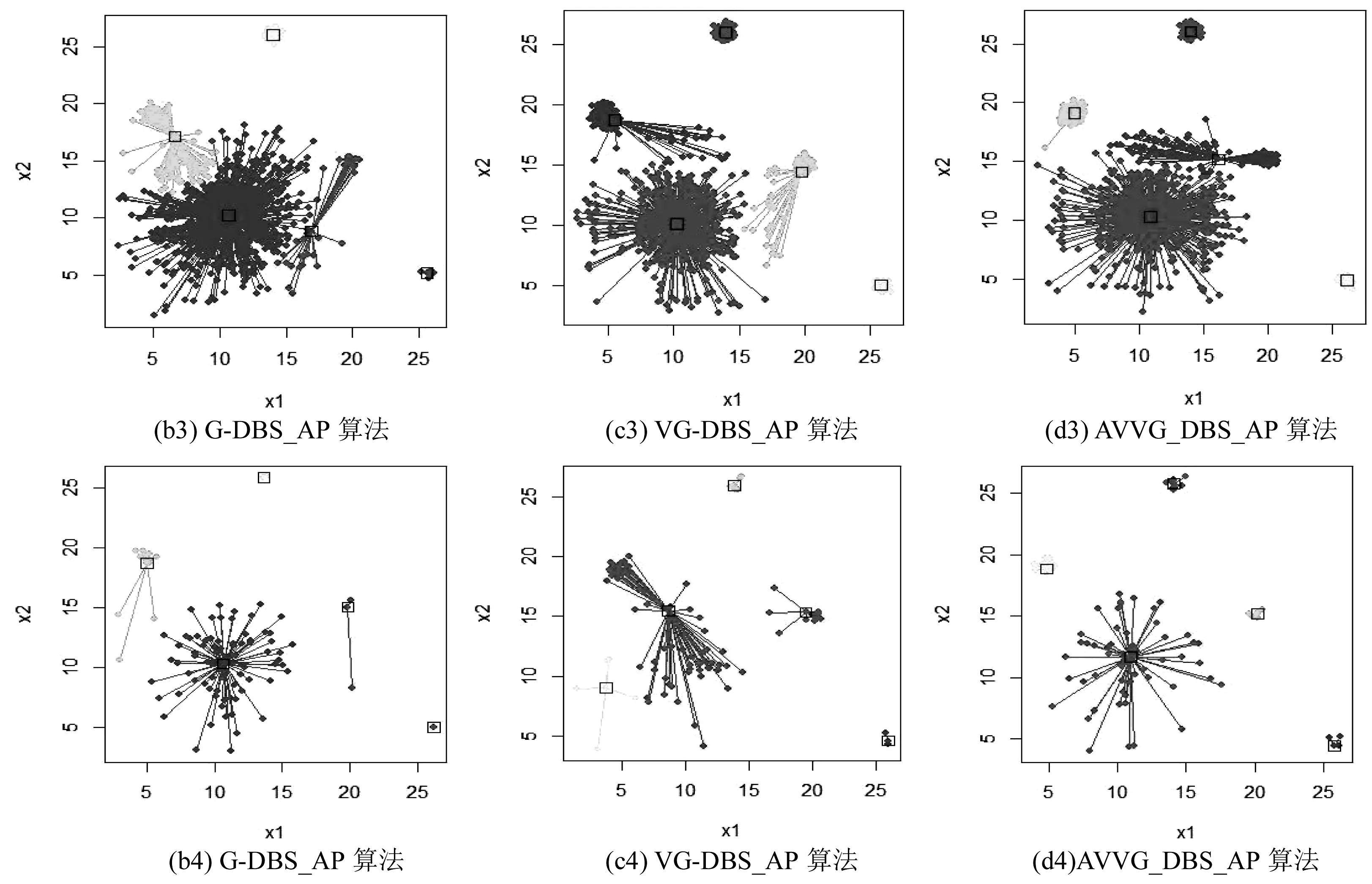
图2 各抽样算法样本数据集AP聚类效果
由图2获知,各样本数据在给出正确类个数下聚类效果较好,按抽样比例0.1%抽取1000个样本点各聚类算法都有误判情况,按0.01%抽取100个样本点各算法聚类效果更好,其中各算法中AVVG_DBS_AP算法聚类效果最好.表4为各算法在样本数据上聚类评价指标的统计结果.

表4 聚类算法评价指标统计结果
由表4知,人工数据集Data按抽样比例为0.1%、0.01%获得的样本数据,各算法聚类精度都在91%以上,按0.1%抽样VG_DBS_AP算法精度最高,为94.6%,按0.01%抽样,AVVG_DBS_AP算法精度最高,为100%.各算法自动聚类个数都较小,三种算法按0.1%抽样样本聚类NC分别为28、17、19个,按0.01%抽样样本聚类NC分别为14、8、7个,与原始数据类个数5接近,由此可知随着样本量减少,聚类个数与原始数据聚类个数越接近.AVVG_DBS_AP算法消耗时间最低,聚类耗时分别为8.16 s,0.02 s.UCI标准数据Page-blocks、Waveform3按5%进行抽样,数据Page-blocks三种算法精度相当,均在83%以上;对分布较均匀的Waveform3,三种算法精度较低,最高是AVVG_DBS_AP算法,为64%.三种算法自动聚类的类数与原始数据类数较相近;与表3相比,各算法对Page-blocks的样本聚类迭代次数有所降低,Waveform3却有所升高.Page-blocks、Waveform3样本聚类耗时分别为0.48 s、0.31 s,根据表3原始数据聚类耗时分别为2069.98 s、546.87 s,约是样本聚类耗时的4312倍、1764倍.
综上可知,对偏斜较大的数据集先借助基于网格的密度偏差抽样算法进行数据约简,再对样本数据集执行AP聚类,各算法在损失小部分精度的基础上,样本自动聚类个数与原始数据类数较接近,耗时较低,可提高聚类的效率,其中AVVG_DBS_AP算法在保证聚类精度较高的基础上耗时最小、效率最高.
3 结 语
针对偏斜的大规模数据,探讨基于网格划分的密度偏差抽样算法在AP聚类中的应用,根据3种抽样算法在偏斜较大的人工数据集和UCI数据集上所获得的样本数据执行AP聚类的效果可知,样本数据集进行AP聚类在损失小部分精度基础上,大大提高聚类效率,其中AVVG_DBS_AP算法聚类的纯度较高、自动聚类个数与原始数据类个数较接近、迭代次数较低以及聚类执行时间耗时少.面对分布偏斜的大规模数据,在进行AP聚类之前可先借助AVVG_DBS算法进行数据约简,再执行聚类,以此通过减少数据输入降低算法的时间复杂度,提高算法效率.
猜你喜欢
China Report Asean(2022年8期)2022-09-02 05:31:26
小学生学习指导(低年级)(2021年9期)2021-10-14 07:57:00
物联网技术(2020年12期)2021-01-27 03:34:08
中学生数理化·七年级数学人教版(2019年10期)2019-11-25 07:34:00
小学生学习指导(低年级)(2019年9期)2019-09-25 07:43:28
成都信息工程大学学报(2019年2期)2019-08-28 10:00:46
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:46
自动化学报(2018年2期)2018-04-12 05:46:01
成都信息工程大学学报(2017年1期)2017-07-21 14:14:11
汽车零部件(2017年4期)2017-07-12 17:05:53
