
结合噪声网络的强化学习远程监督关系抽取
2022-12-06 10:31谢斌红王恩慧张英俊
计算机工程与应用 2022年23期
谢斌红,王恩慧,张英俊
太原科技大学 计算机科学与技术学院,太原 030024
随着信息技术的蓬勃发展,网络资源不断涌现,出现了海量半结构化或者非结构化形式的数据,如何从这些复杂、多元分散和冗余异构的数据中提取结构化的、高质量的信息成为学者们研究的热点问题。在这种背景下,关系抽取作为信息抽取重要的子任务之一,吸引了众多学者的关注。关系抽取的目的是从无结构的文本中抽取出实体对之间的语义关系,它的解决有利于一些下游任务的完成,如知识图谱的构建、关系问答系统等,同时关系抽取的研究对文本摘要、机器翻译等研究领域也有着重要意义,因此具有广阔的应用前景。
目前,最常用于实体关系抽取的方法是有监督的关系抽取,并且由于深度学习技术的成功应用,取得了较好的效果,但其代价是依靠人工标注数据,耗时耗力。因此为了获得大规模的标注语料,Mintz等人[1]提出了使用远程监督方法自动标注文本,它基于这样的假设条件:假如两个实体在知识库(knowledge base,KB)中存在某种关系,则包含这两个实体的句子都同样表达这种关系。但真实情况下包含同一实体对的句子并不一定会表达相同的关系,因此错误标注就会引入噪声问题。它的噪声包括假阳性噪声和假阴性噪声,假阳性噪声是指语料库中某一实体对间的关系并非KB所标注的关系,如表1所示,假设(乔布斯,创立者,苹果)三元组是KB中的一个关系事实,远程监督就会把所有包含实体“乔布斯”和“苹果”的句子作为关系“创立者”的训练实例,但对于句子S1“乔布斯吃了一个苹果”来说,它并没有表达“创立者”的关系,远程监督方法依然会将它作为此关系类型的正例,这类噪声问题即为假阳性噪声。假阴性噪声是指由于知识库不足,将语料库中原本表达了某种关系的句子标注为不存在关系(non-relation,NA),如表1的句子S3,“张三结婚后生了两个孩子,定居在北京”中存在着(张三,居住于,北京)的关系事实,但实体对(张三,北京)在KB中并不存在关系,因此S3被错误地标记为NA,这类噪声问题即为假阴性噪声。

表1 远程监督关系抽取中错误标注的例子Table 1 Examples of incorrect annotations in distant supervision relation extraction
为了解决错误标注问题,Zeng等人[2]提出从噪声数据中选择正确的句子来进行关系抽取,但这样无疑会丢失大量有用的句子;Lin等人[3]、Han等人[4]通过运用注意力机制对噪声句子进行抑制来减轻错误标注对关系抽取模型性能的影响。虽然这些方法在一定程度上减少了噪声数据的影响,但它们训练和测试过程都是在包级别上进行的,无法处理包中全部句子都是噪声数据的情况。为了进一步提高模型性能,很多学者将复杂的机制运用到了远程监督关系抽取任务中,如Feng等人[5]、Yang等人[6]引入了强化学习,Qin等人[7]运用对抗学习更好地识别噪声数据,进一步实现了句子级别上的关系分类,从而将每个关系映射到相应的句子,但它们只是简单地运用强化学习的随机策略,在选择状态和策略时会耗费时间。而且这些方法只聚焦于正例中的噪声数据,并未解决在NA集合中被错误标注的实例。
因此,现有方法还存在着两种挑战。(1)只关注假正例问题,而忽略了可能表达了某种关系的假负例,没有有效利用语料库资源,而且混淆了关系分类器识别相应关系特征的能力。(2)基于强化学习的方法忽略了策略的探索和利用之间的平衡问题。使用随机策略虽然可以帮助Agent遍历各种状态,避免陷入局部最优解,但是盲目尝试会使Agent由于来回探索许多不必要的状态和策略而浪费很多时间,降低了学习效率。
针对上述不足,本文提出采用带有噪声网络的强化学习方法设计噪声指示器,为噪声数据分配正确的标签,既可以减少噪声数据的影响,又可以增加有用的训练数据。具体来说,首先在Qin等人[8]提出使用假正例指示器解决假正例问题的基础上,设计了假负例指示器,它根据关系分类器的性能变化移除或保留噪声句子,从而识别每种关系的假负例,并为其分配正确的标签,不仅可以移除正例中的噪声数据,而且可以增多目标关系的训练样本。此外,考虑了策略的探索与利用的平衡问题。通过在策略网络的权重上增加噪声,使噪声指示器在策略执行过程中既可以尝试新的策略,发现能使奖励最大化的行为,而且还可以利用已经学到的策略,提高强化学习的效率,更好地利用标注数据。
1 相关工作
许多学者致力于研究基于有监督的实体关系抽取,如利用基于卷积神经网络[9-10]、递归神经网络[11-12]和长短期记忆网络[13-14]的模型来进行句子特征的自动学习,实现了良好的关系抽取性能。但其缺点是需要依赖大量标注数据,不仅耗费成本高,而且学习到的关系抽取模型跨领域泛化性低,无法迁移到其他领域。因此,为了解决上述问题,Mintz等人[1]提出一种知识库与语料库启发式对齐的远程监督方法来进行大规模关系抽取,但由于它并非由人工直接标注,因此产生了错误标注的问题。
为了缓解错误标注带来的噪声问题,许多研究者将关系分类建模为一个多实例学习问题。Zeng等人[2]采用分段卷积神经网络(PCNN)与多实例学习(MIL)相结合的方法,选择最可靠的句子作为训练数据。Lin等人[3]提出了基于注意力的方法,通过给噪声数据分配较小的权重来抑制其对关系分类器的影响。Ji等人[15]还加入了实体描述信息来丰富句子的特征表示,使得对包中句子权重的分配更加准确。为了强化注意力机制,Han等人[4]引入关系之间的分层信息来识别有效的实例。Ye等人[16]同时考虑了包内和包间的注意力,分别处理句子级和包级噪声。Feng等人[5]和Zeng等人[17]运用强化学习方法显式地识别并移除假正例,进一步提高了关系分类器的性能。
很多学者认为,只通过简单地抑制或移除噪声数据会丢失数据本身所包含的有用信息,可以通过为噪声句子分配可靠的标签进一步丰富训练数据。Wu等人[18]提出利用神经噪声转换器来减轻噪声数据影响的方法,并且引入条件最优选择器来对其进行正确的预测。Shang等人[19]引入无监督聚类方法为噪声数据选择合适的关系标签。而且Qin等人[8]利用强化学习方法设计了可以应用到任何远程监督关系抽取模型上的假正例指示器,可移植性比较强。Chen等人[20]致力于采用强化学习方法进行标签去噪,从远程监督方法标注的多个关系标签中选取最可靠的一个,用新的关系标签训练关系分类器,使其性能得以提高。
然而,这些方法旨在通过处理假正例问题或噪声标签问题提高关系分类器的效果,忽视了同样表达了目标关系的假负例,而在Riedel等人[21]对数据集的介绍中统计,有将近80%的数据都被标注为NA,因此如果在训练时保持假负例的错误标签,就会丢失大量有用的句子信息。另外这些方法并没有考虑策略的探索度问题,当策略探索不充分时,使用采集到的样本进行策略优化时就会陷入局部最优;而当策略探索太强,使用收集到的样本进行策略优化时对于策略的改进并没有帮助,反而降低了学习效率。
因此本文利用强化学习方法学习一个噪声指示器来识别目标关系的假正例与假负例,充分利用远程监督自动标注过程中两种噪声数据所包含的信息,同时采用Deepmind[22]在2017年提出的噪声网络,平衡策略的探索与利用问题,使噪声指示器既可以尝试新的策略,发现能使奖励最大化的行为,而且还可以利用已经学到的策略,进行更有效的学习。
2 基于噪声网络强化学习方法的远程监督关系抽取模型
本文提出的基于噪声网络的强化学习远程监督关系抽取模型由噪声指示器和关系分类器两部分组成。添加噪声网络的噪声指示器根据策略网络对当前给定的句子进行决策,识别当前句子标签是否正确。关系分类器根据噪声网络的决策结果重分配噪声数据,利用重分配的数据训练网络。同时,关系分类器反馈奖励给噪声指示器,优化噪声指示器的策略功能。图1描述了模型动态重分配噪声数据的过程,首先利用噪声指示器识别远程监督数据集中的假正例(false positive instances,FP)与假负例(false negative instances,FN),同时为了提高强化学习模型的探索能力,在指示器的网络空间中加入噪声,对一个远程监督句子做出移除或保留的决策,根据决策结果将FP从正例集中移出到负例集中,将FN从负例集中移出到正例集中;在对整个噪声数据集进行决策之后,再利用重新生成的数据集训练关系分类器,最后,利用关系分类器提供的奖励指导噪声指示器更新其策略网络的参数。这两部分在彼此动态交互中进行训练。
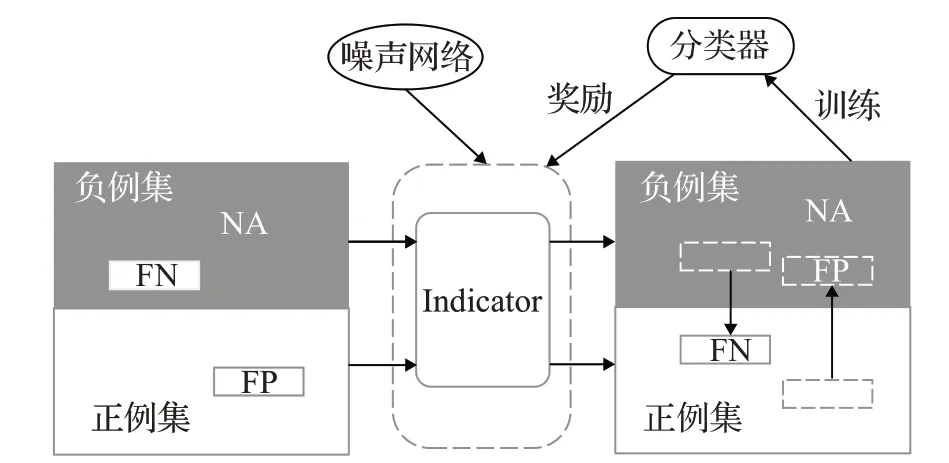
图1 动态重分配噪声数据过程Fig.1 Dynamic redistribution of noisy data
2.1 噪声指示器
本文将错误标注数据的识别建模为强化学习问题,其中,Agent即为噪声指示器,Environment由分类器和噪声数据组成,通过二者动态交互获得鲁棒的噪声指示器,使其能够采取更准确的行为。另外,利用策略网络π(a|s;θ)对噪声指示器进行参数化,即在状态s下给出行为a的概率分布,并且根据关系分类器反馈的奖励更新参数θ。由于强化学习的奖励有延迟特性,噪声指示器只有在每种关系的数据都处理完成后才能得到奖励,从而更新其参数。本文的假正例指示器与Qin等人[8]的结构相同,下面重点介绍假负例指示器结构。
首先对假负例指示器中状态、行为与奖励等基本组件进行定义。
状态。在强化学习中,一个最主要的前提是Environment必须满足马尔可夫决策过程(MDP),即当前的状态转移概率仅与前一状态和行为相关,但远程监督自动标注的数据集中每个句子彼此独立,因此,为了将其构建为MDP,状态s不仅需要包含当前句子信息,并且还要添加前一状态下移除的句子信息。本文用当前输入句子与早期状态下被移除句子的特征相连接的实值向量来表示状态,它包括:(1)由分类器的非线性层得到当前要处理的句子的向量表示repj;(2)早期状态下被移除句子的平均向量表示repmean。
行为。假负例指示器是用来对NA集合中的句子是否为目标关系的假负例做出决策,因此每类关系都需要构建一个假负例指示器,并用行为aj∈{0,1}表示假负例指示器是否移除第j个句子。0表示当前句子未能表达目标关系,保留在NA集合中;1表示当前句子属于目标关系,需要移除到目标关系的正例集合中。aj的值由假负例指示器的策略网络π(a|s;θ)得到,其中θ是可以学习的参数。策略网络的作用是判断输入句子是否具有目标关系的特征,从而采取移除或保留的决策,类似于二元关系分类问题。为了更好地捕捉文本的局部相关性,本文基于Kim[23]所提出的TextCNN网络,并采用多个大小不同的核对句子关键特征进行提取,如图2所示,经过TextCNN网络的输入层、卷积层、最大池化层和非线性层,最后进行二元决策分类。
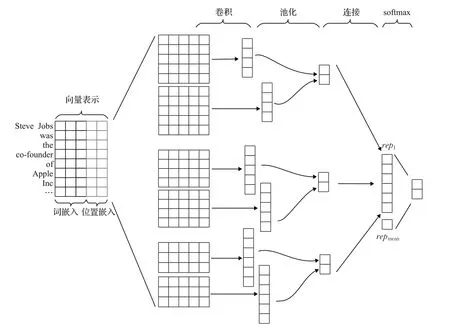
图2 噪声指示器结构Fig.2 Noisy indicator structure
奖励。奖励函数用来衡量噪声数据重新分配的好坏。从NA数据集中随机分配样本数为该目标关系正例的2倍的负例样本R={x1,x2,…,x|R|},对每个句子进行决策,以判断是否应该移除当前的句子。当假负例指示器把某个错误标注的句子移除到目标关系的正例样本集合中时,关系分类器即可学到更多特征,从而实现更好的性能。本文假设当模型完成所有的决策,即到达最终状态s|R|+1时会获得一个最终的延迟奖励:
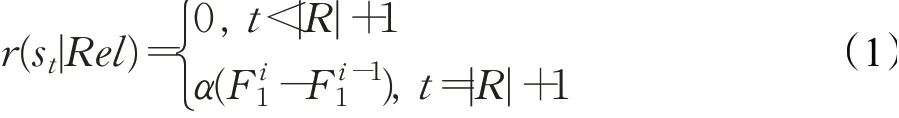
其中,Rel表示当前处理的实体关系,表示在第i个epoch时分类器所计算的F1值表示在第i-1个epoch时分类器所计算的F1值,当F1值升高时分类器为假负例指示器反馈一个正奖励,否则,给假负例指示器反馈一个负奖励。α将F1值的差异转化到一个合理的数值范围内。
其中,F1的计算公式为:
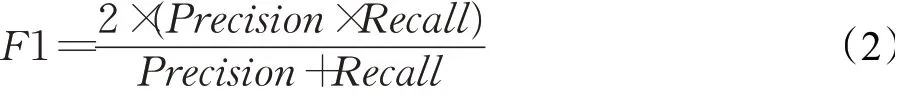
Precision与Recall的计算公式如下:
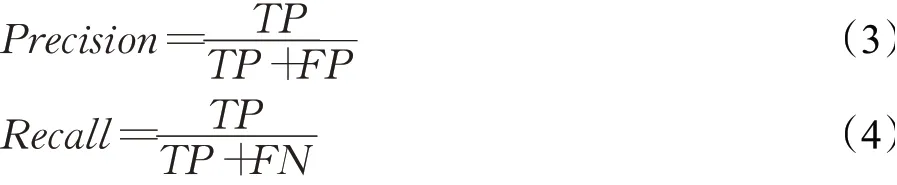
TP表示真正例。
噪声网络。由于强化学习中基于策略的方法具有随机性,很容易因盲目尝试各种行为而浪费时间,因此本文通过在策略网络参数中加入噪声,帮助策略网络将正确表达目标关系的句子移除到正例集合中,从而提高强化学习的效率。

其中f(·)取f(x)=sgn(x)||x,将该噪声添加到策略网络的全连接层即可表示为:
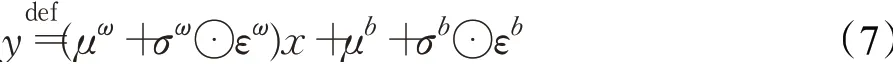
因此网络的目标函数定义为J(ξ)=E[J(θ)],即只计算集合ξ中参数的梯度,但是计算损失时,将θ当作参数参加运算。
训练基于策略的假负例指示器。
假负例指示器需要弱监督信息判断表达了目标关系的句子是否被错误标注为NA,因此利用关系分类器提供的奖励来调整参数。由上述可知,只有当一个关系中的所有负例都处理完成才能得到奖励,如果随机初始化策略网络的参数,通过不断地试错来训练模型,会浪费大量时间,因此先利用原始数据及标签预训练策略网络和关系分类器,从而为假负例指示器的学习提供方向,节省训练模型时间。
如图3所示,在训练过程中,对于第i个epoch,假负例指示器根据策略π(a|s;θ),从NA数据集Nori中将表达了目标关系的正例Hi移出,对应的该关系的负例集变为Ni=Nori-Hi,正例集变为Pi=Pori+Hi,因此该关系的数据集总量并未改变,实现了噪声数据的充分利用。然后将新得到的数据集划分为用于训练关系分类器的训练集和用来计算当前分类器的F1值的验证集如上所述,利用相邻两个epoch分类器所计算得到的F1值的差异作为奖励。
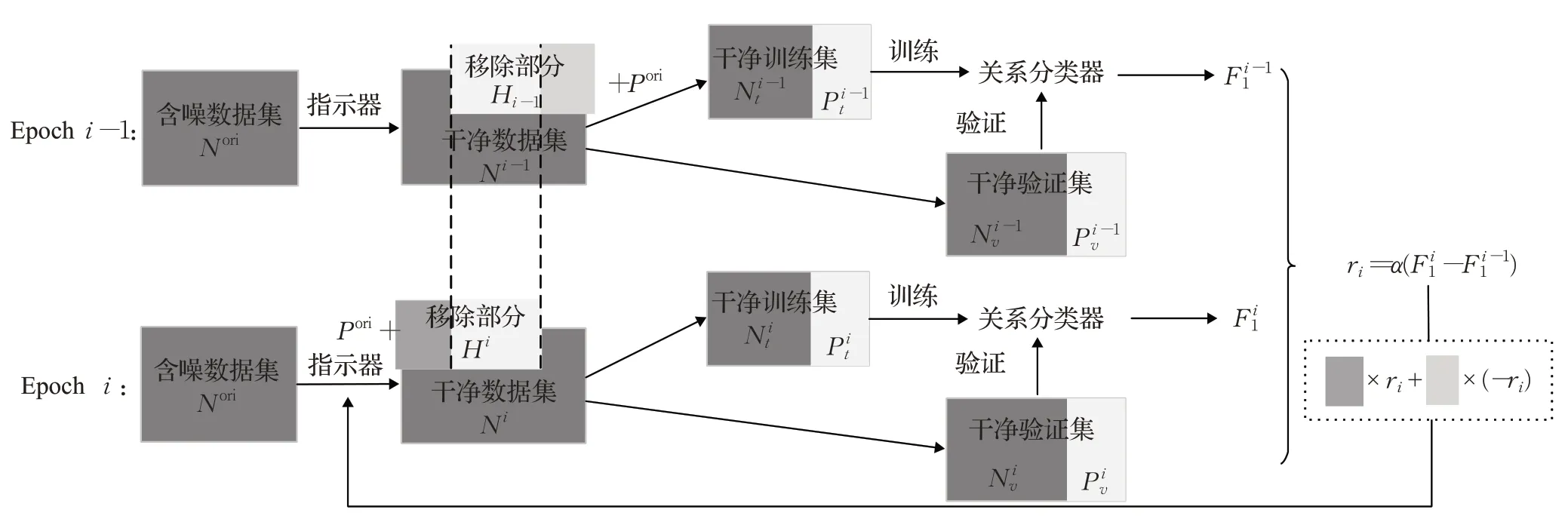
图3 假负例指示器训练过程Fig.3 Training process of false negative instances indicator
假负例指示器的目标是将概率分布取样的行为期望回报最大化。而实际上,在相邻两个epoch中,由于强化学习的预训练策略,假负例指示器已经拥有了一定的识别目标关系句子特征的能力,因此所过滤的句子并非完全不同的,则F1的差异主要体现在不同的移除部分。定义以下两个集合:
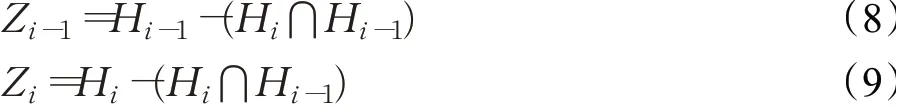
其中,Zi-1表示移除的集合中第i-1个epoch不同于第i个epoch的部分,Zi则表示移除的集合中第i个epoch不同于第i-1个epoch的部分。因此,若第i-1个epoch所移除的句子质量更好,假负例指示器则会得到负的奖励,相反,若第i个epoch所移除的句子质量更好,假负例指示器则会得到正的奖励。因此其目标函数可定义为:
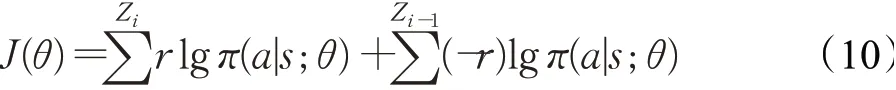
对于每一个关系Rel,根据当前策略为每个状态依次取样一个动作,然后得到一个采样的轨迹{s1,a1,s2,a2,…,s|R|,a|R|,s|R|+1}以及对应的最终的奖励r(s|R|+1|Rel),且只有s|R|+1处奖励非零,因此对于t=1,2,…,|R|,r=r(st|Rel)=r(s|R|+1|Rel)。
根据策略梯度理论和REINFORCE[24]算法,本文使用策略梯度算法计算梯度并更新假负例指示器中策略网络的参数:
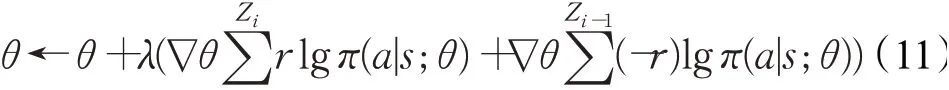
2.2 关系分类器
本文使用关系分类器评价假负例指示器所采取的一系列行为的好坏,也是一个二元分类问题,因此同样采用TextCNN架构。
算法1噪声指示器和关系分类器的强化学习算法

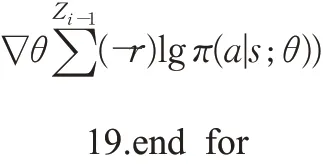
输入层:对每一个输入句子,将其表示为向量列表x={v1,v2,…,vm},每个表示向量由词嵌入和位置嵌入两部分组成,维度分别为dw与dp,其中词嵌入由word2vec[25]训练获得,位置嵌入通过计算该单词距离头实体与尾实体的相对距离得到。每个单词的表示向量vk由该词的词嵌入及位置嵌入连接而得(vk∈Rd,d=dw+2×dp),然后将每个单词的向量输入到TextCNN中。
网络模型:本文采用可以更好捕捉文本局部相关性的TextCNN架构将输入语句编码为低维向量,并预测对应的关系标签,负标签表示输入语句不属于此目标关系,对应于保留操作;正标签表示输入语句表达了此目标关系,对应于移除操作。

其中,x表示为输入句子的向量,L∈Rds为经过卷积、池化的一系列计算后的输出,ds为特征映射的数量。卷积层利用窗口大小为l的核滑动输入句子向量x,得到的隐藏嵌入进入最大池化层得到最终的输出L。
关系预测的概率如下:
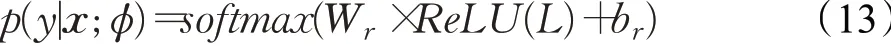
其中,全连接层的参数Wr∈Rnr×ds是每个关系的类别嵌入,br∈Rnr是一个偏置向量,nr为总的类别数量。
损失函数:给定由假负例指示器重新分配的数据集,训练关系分类器的目标函数定义如下:
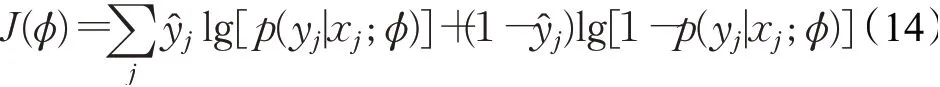
经过上述强化学习过程后,假负例指示器具有了对假负例FN进行分类的能力。如果包含同一对实体的全部句子都被识别为假负例,这个实体对才被划分到对应关系的正例集中。
2.3 模型训练
由于噪声指示器与包含噪声数据和关系分类器的环境动态交互,因此需要联合训练这两部分,而且在联合训练之前,为了节省时间,对噪声指示器中的策略网络和关系分类器中TextCNN进行了预训练。噪声指示器中的策略网络使用策略梯度理论来优化,关系分类器中目标函数利用梯度下降法进行最小化。
算法1详细描述了噪声指示器和关系分类器的强化学习过程,噪声指示器识别训练集中的噪声数据并进行重新分配,并对关系分类器进行训练;关系分类器对新生成的数据进行预测从而计算F1值,并且相邻epoch的F1值的差异作为奖励反馈给噪声指示器。
3 实验
3.1 数据集和评估指标
本文采用广泛用于远程监督关系抽取任务的Riedel[21]数据集,该数据集是通过将New York Times语料库中的文本与Freebase知识库中的实体对对齐得到的,New York Times语料库中提及的实体由斯坦福命名实体识别器[26]识别。其中2005—2006年的文本用来进行训练,2007年的文本用来进行测试。训练数据集包括522 611个句子,281 270个实体对和18 252个关系事实。测试数据集包括172 448个句子,96 678个实体对和1 950个关系事实。共有53种关系,其中包括一个“NA”特殊标签,用于表示实体对之间不存在关系。
本文采用留出法对模型进行了评价,将从测试语料库中提取的关系事实和Freebase中的关系事实进行了对比,该方法在可以提供分类能力的近似测量的基础上避免昂贵的人工评估。本文采用精度/召回率曲线来对模型的性能进行评估,除了精度/召回率曲线,还展示了特定召回率下的精度值,以便进行更直接的比较,并对模型的AUC值进行计算,以显示不同模型的整体效果。AUC即Roc曲线与坐标轴形成的面积,表示随机从正样本集中抽取一个正样本,负样本集中抽取一个负样本,正样本的预测值大于负样本的概率。其计算公式如下:
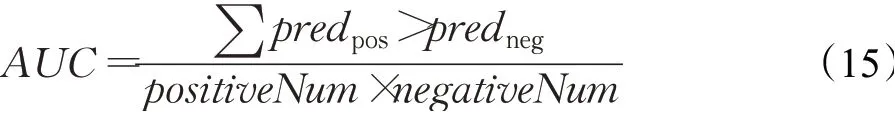
3.2 参数设置
与之前的工作相同,本文直接使用Lin等人[3]给定的词嵌入文件,只保留NYT中出现100次以上的词。另外,对位置嵌入设置相同的尺寸,相对距离的最大长度为-30和+30(-和+表示实体的左右两侧),使用RMSprop优化器对噪声指示器的参数进行优化,学习率为2E-5;使用Adam优化器对关系分类器的参数进行优化,学习率设为1E-3。具体超参数设置如表2所示。
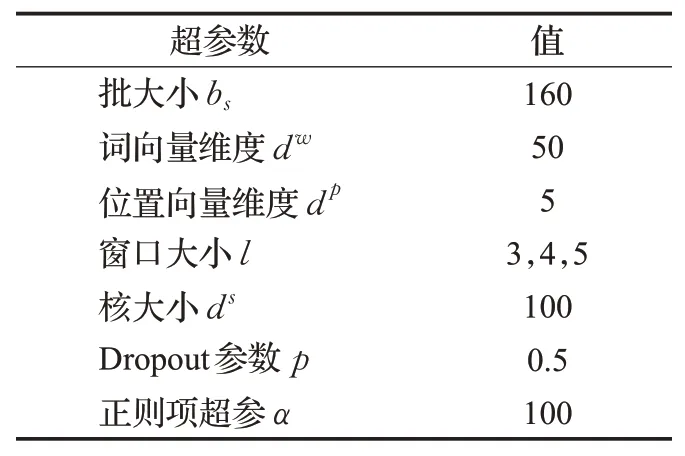
表2 超参数设置Table 2 Hyperparameter settings
3.3 整体评估结果
本文采用强化学习的方法解决上述PCNN+ONE/ATT只能处理假正例的问题,并且考虑了强化学习的探索与利用的平衡问题,利用添加了噪声的指示器识别每一种关系的NA句子,将表达目标关系的句子重新分配到正例集合中,从而构建一个新的数据集。虽然Riedel[25]数据集中包含52种关系,但由于强化学习的训练需要大规模数据,因此只选择了正例数大于1 000的10种关系进行训练。最后利用新构建的数据集分别训练PCNN+ONE与PCNN+ATT模型,并且与使用原始数据集训练后的模型进行比较。Original表示利用原始远程监督数据集训练PCNN+ONE/ATT模型;+FP表示利用Qin等人[8]基于强化学习方法设计的假正例指示器,将假阳性样本移到负样本集后得到新的数据集,用其训练PCNN+ONE/ATT模型;+OURS表示利用本文方法对假阳性样本及假阴性样本进行重新分配,使用处理后的数据集训练PCNN+ONE/ATT模型。实验结果如图4、图5所示,将这三种方法的精确率-召回率曲线进行对比可知,由本文方法重新分配后获得的数据集更加合理,同样的模型其性能可以得到明显的提升,这说明充分利用噪声数据,以及添加噪声网络可以有效提高关系分类器的能力。
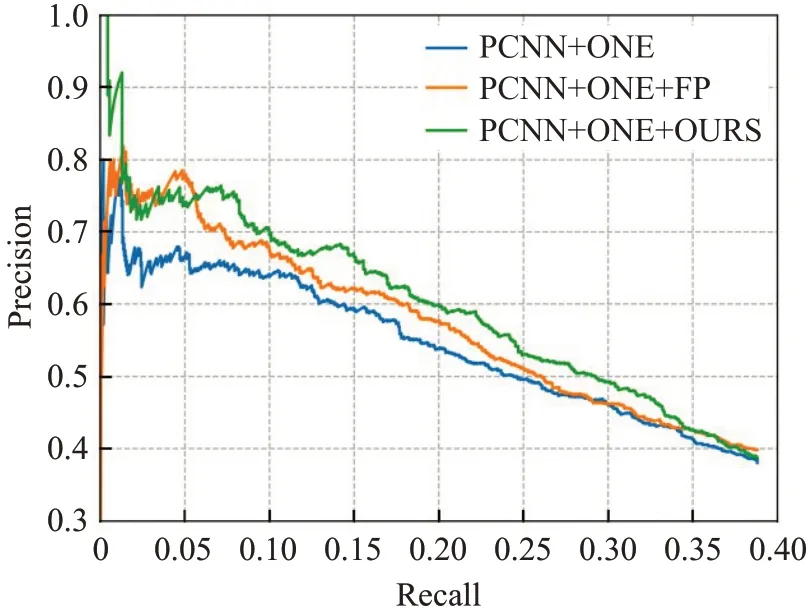
图4 基于PCNN+ONE模型的PR曲线对比图Fig.4 Comparison diagram of PR curve based on PCNN+ONE model
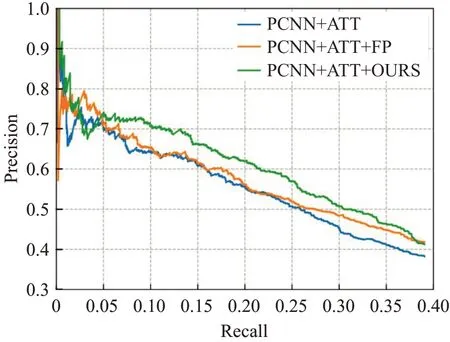
图5 基于PCNN+ATT模型的PR曲线对比图Fig.5 Comparison diagram of PR curve based on PCNN+ATT model
由于在召回率大于0.05时,模型的精确率-召回率曲线波动不明显,为了更具体地解释,将不同召回率(0.1/0.2/0.3/0.4)下的最高的精度及其平均值记录在表3中。从结果中可以看出,相对比原始数据集以及仅处理假正例的数据集,本文方法提高了远程监督关系抽取的准确性。为了更加直观地比较,计算了每条PR曲线的AUC值,如表4所示,它反映了这些曲线下的面积大小。这些比较结果也表明了本文方法的有效性。
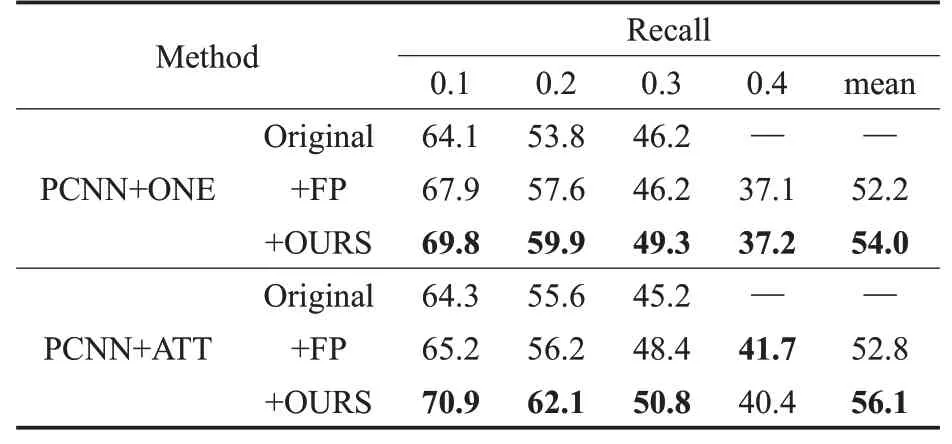
表3 各种神经网络模型在不同召回率下的最大精度Table 3 Maximum precision of various neural network models at different recall 单位:%

表4 本文方法与以往研究的AUC值Table 4 AUC values of method in this paper and previous studies
3.4 噪声数据及噪声网络的影响
本文对处理不同噪声数据及添加噪声网络的有效性进行了实验,结果如图6、图7所示,其中PCNN+ONE/ATT+ALL是将处理假正例与假负例的这两种模型进行结合,可以充分利用对齐过程中产生的噪声数据进行关系分类,相比于只处理假正例一种噪声,其性能提升3%左右,因为重分配假负例,可以增多正确的训练样本,从而更好地学习关系特征。PCNN+ONE/ATT+ALL+Noisy是在策略网络权值中加入参数噪声,与PCNN+ONE/ATT+ALL相比,模型的分类效果进一步提升,说明参数噪声的添加确实增强了强化学习探索的能力,帮助噪声指示器更准确地重新分配噪声数据,增多了正确表达实体-关系的句子。
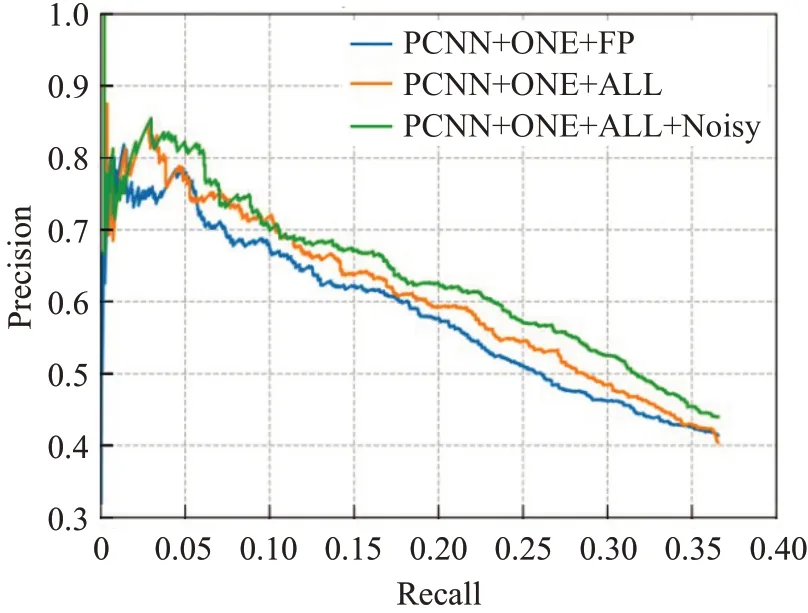
图6 不同设置下PCNN+ONE模型的PR曲线图Fig.6 PR curve of PCNN+ONE model under different setting
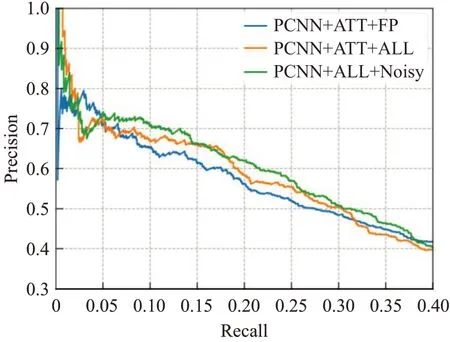
图7 不同设置下PCNN+ATT模型的PR曲线图Fig.7 PR curve of PCNN+ATT model under different setting
3.5 案例研究
为了验证模型对于识别假负例数据的有效性,本文分别对模型识别出的每种关系的假负例数据进行统计,其结果如表5所示,表明本文所提出的模型可以用于纠正假负例标签,而且本文对一些标记错误的数据进行了采样,如表6所示,以S2为例,由于知识库的不完整,因此认为实体对(kathleen,new_york_city)之间不存在关系,但其语句表达了二者之间存在/peo-ple/person/place_of_birth的关系,具有目标关系的特征。另外,S3虽然没有表达任何关系,但因为在Freebase中存在关系事实(New Yorkcity,/people/deceased_person/place_of_death,William O’Dwyer),所以它被错误地标记为/people/deceased_person/place_of_death。从中可以看出,对于每种关系,本文的关系分类器对噪声数据进行了准确的识别,表明本文的模型确实捕获了噪声数据的有效信息,并利用这些信息提高了远程监督关系抽取模型的能力。
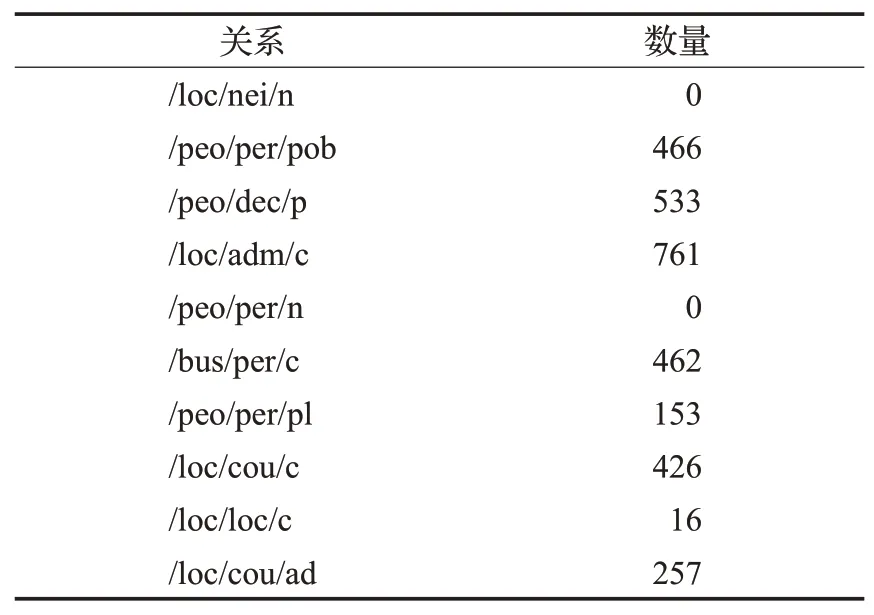
表5 每种关系重新分配假负例数量统计Table 5 Statistics on number of false negative cases of reallocation for each relationship
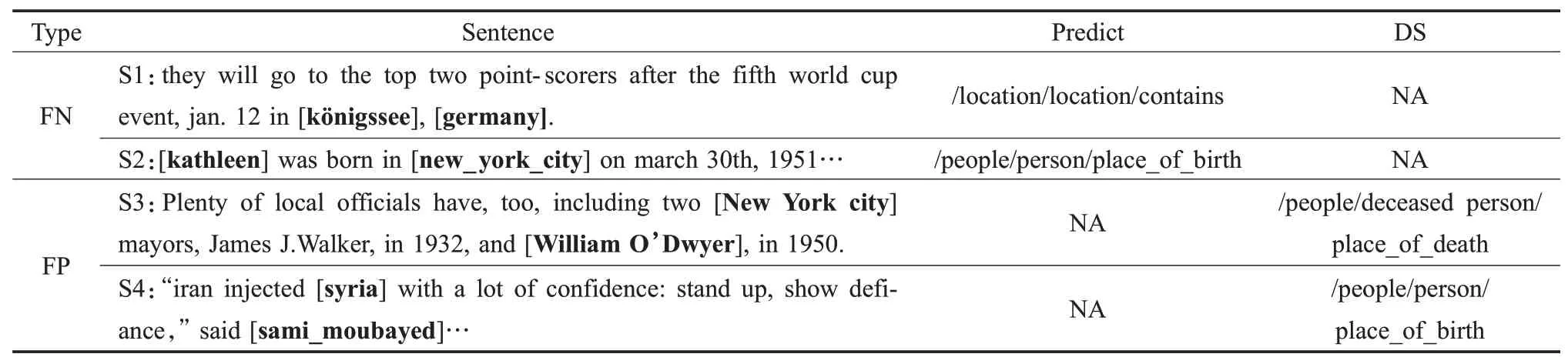
表6 案例研究实例(前两个句子为假阴性实例,后两个句子为假阳性实例)Table 6 Case study examples
4 结论
本文提出了一个带有噪声网络的强化学习模型,将本文模型与识别假正例的模型相结合,可用于识别并重新分配远程监督关系分类中被错误标注的句子。通过利用基于策略的强化学习方法,最大化由关系分类器得到的奖励从而训练噪声指示器识别、分配噪声数据的能力,其中在策略网络权值中加入参数噪声,增加强化学习的探索。这样,本文的模型不仅减少了错误标签带来的负面影响,而且可以利用噪声数据所包含的关系特征。实验结果表明,本文的框架提高了各种深度学习模型在Freebase对齐NYT公共数据集上提取远程监督关系的性能。
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
包装工程(2022年9期)2022-05-14
电子产品世界(2022年4期)2022-04-21
环球时报(2021-07-13)2021-07-13
计算机系统应用(2021年2期)2021-02-23
电子技术与软件工程(2019年18期)2019-11-18
劳动保护(2019年3期)2019-05-16
电子技术与软件工程(2017年14期)2017-09-08
企业技术开发·下旬刊(2016年11期)2016-12-27
中国新技术新产品(2015年9期)2015-07-18
