
基于红外图像与可见光图像特征融合的目标检测算法
2022-12-05 06:37:54吴振宇
导弹与航天运载技术 2022年5期
马 野,吴振宇,姜 徐
(1. 东北大学,沈阳,110819;2. 北京宇航系统工程研究所,北京,100076)
0 引 言
目标检测任务是找出图像或视频中人们感兴趣的物体,并检测出位置和大小。基于神经网络的方法又发展出两条技术路线:基于候选框的方法和不使用候选框的方法。基于候选框的方法[1,2]使用滑动窗口在待检测图片上进行扫描,判断窗口内是否有目标和目标具体定位。不使用候选框的方法是直接预测目标的关键点,例如文献[3]预测目标的中心点和大小,以此达到定位的效果。
可见光图像具有丰富的纹理细节信息,是做目标检测的首选数据类型。但是,当遇到天气不佳、夜晚等光线不充足或者光线过强的情况,图片受影响较大,影响物体成像。红外图像根据热辐射信息成像,抗干扰能力强,环境适应能力强,因此可以在夜间和恶劣天气下全天候工作而不依赖于场景特性。但是由于热辐射较弱,红外图像对比度低、边缘模糊,图像整体较暗,没有色彩和阴影,因而分辨能力低。可见光图像在这些方面表现优异,可见光图像可以与红外图像互补,融合后能适用于全天候全时段的目标检测任务。
因此,为了充分利用可见光图像提供的纹理信息和红外图像提供的热辐射信息,提出一种基于特征融合的目标检测方法。在融合时,能够根据特征的不同,自动分配不同权重,得到比使用单一数据更好的效果。
根据融合的阶段不同,可以把融合检测算法分为3类:检测前融合、检测中融合以及检测后融合。检测前融合是指在目标检测前将可见光图像与红外图像融合成一张图像,再经过目标检测算法。这类方法的好处是融合和检测完全分开,可以使用已有的各种图像融合方法,文献[4]介绍了多种图像融合方法,以及融合后的各种应用。但也因为图像融合与目标检测无关,无法保证融合后的图像适用于目标检测任务。检测后融合是指对可见光图像和红外图像分别进行目标检测,再将检测结果融合在一起。这类方法最为简单,但实际上不涉及图像融合,算法效果往往不能得到大的提升。文献[5,6]使用了检测中融合的方法,既可以充分将可见光图像与红外图像进行融合,又可以根据目标检测效果对算法进行优化。这类方法的效果通常优于检测前融合和检测后融合算法。文献[6]提出一种融合-精炼模块,利用可见光图像特征图和红外图像特征图直接融合成新的特征图并进行精炼,新的特征图又重新与可见光图像特征图和红外图像特征图形成残差网络,进行多次循环。融合-精炼模块能够很好地融合及保留特征图特征,但所需计算量较大。文献[5]提出了一种单一加权方法,以原始图片作为输入,计算出单一权重对特征图进行融合。输入尺寸较大,同样需要较大的计算量;单一权重不能很好地应对一张图片不同区域情况不同的问题,也不能很好地解决不同类目标在一张图片中的情况。提出的特征融合模块所需计算量较小,并且通过计算权重图的方式,对一张图片不同位置使用不同权重,提高目标检测精度。
1 特征融合目标检测算法
以经典YOLO目标检测算法为基础,增加可见光图像与红外图像特征融合模块,既能利用可见光图像提供的纹理信息,又能利用红外图像提供的热辐射信息。可见光图像与红外图像差异较大,因此采用两套特征提取网络分别处理得到特征图,保证充分利用二者图像的独特特征。特征融合目标检测算法如图1所示。
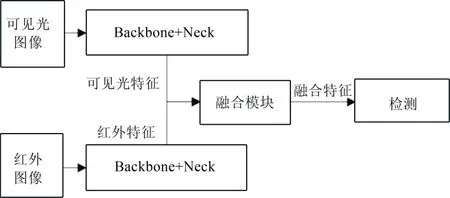
图1 特征融合目标检测算法 Fig.1 Feature Fusion Object Detecion
由图1可知,可见光图像与红外图像分别输入到不同Backbone+Neck中进行特征提取,得到的可见光图像特征图(FRGB)和红外图像特征图(FIR)输入到特征融合模块,经过自动分配权重后,融合成新的特征图(Ffusion)。最后经过Detection模块进行目标预测。
1.1 YOLO目标检测算法
YOLO是一种基于候选框的单阶段目标检测算法,基本思想是将输入图片分成多个网格,然后对每一个网格预测大小不同的多个候选框内存在目标的概率,同时预测目标类别及位置。YOLO算法主要包含Backbone网络、Neck网络以及Detection网络,如图2所示。表1中列出了YOLO v5网络每一层的详细参数。
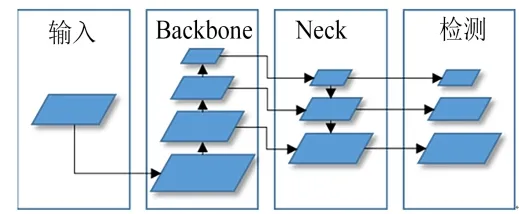
图2 YOLO算法 Fig.2 YOLO Algorithm

表1 YOLO v5 网络结构 Tab.1 YOLO v5 Network Structure
Backbone主要有数个卷积模块和残差模块(resnet)组成。利用多层卷积神经网络对输入图片进行特征提取,随着卷积层的增加,深层网络得到的特征图尺寸越来越小,得到的特征信息越来越复杂。尺寸较小的特征图缩放比例高,具有较深层次的特征信息,因此通常用来预测较大的目标,较大的特征图用来预测较小的目标。
Neck除了少量卷积模块和残差模块还包含上采样层。Neck网络使用上采样将特征图逐渐放大,并与Backbone中的特征图相结合,构成了特征金字塔网络(FPN)[7]结构。通过上述采样得到的特征图来自深层网络,具有较强的语义信息,有利于目标分类;而通过Backbone得到的特征图分辨率较高,具有丰富的空间信息,有利于目标位置的预测。特征金字塔网络使用较少的计算量将二者融合,能够得到更准确的目标分类及位置预测。
Detection网络对不同尺寸的特征图进行处理,每种尺寸的特征图只通过一层卷积层,输出每个点的分类、位置信息及置信度。
利用YOLO算法,将可见光图像与红外图像分别输入到不同的YOLO算法中,利用Backbone网络、Neck网络分别得到可见光图像与红外图像的特征图。再通过特征融合模块得到融合特征图,最后利用Detection网络预测目标。由此建立的神经网络模型,可以实现端到端的训练,同时优化特征提取、特征融合以及目标检测。
1.2 特征融合模块
特征融合模块如图3所示,输入可见光图像特征图(FRGB)和红外图像特征图(FIR),输出融合特征图(Ffusion)。特征融合模块包含特征权重网络(FWN),通过多层卷积神经网络计算出可见光图像特征图权重(WRGB)和红外图像特征图权重(WIR)。Ffusion通过式(1)及式(2)计算所得。
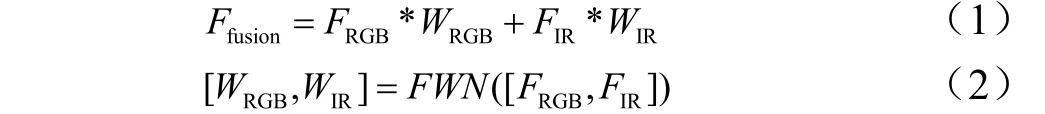
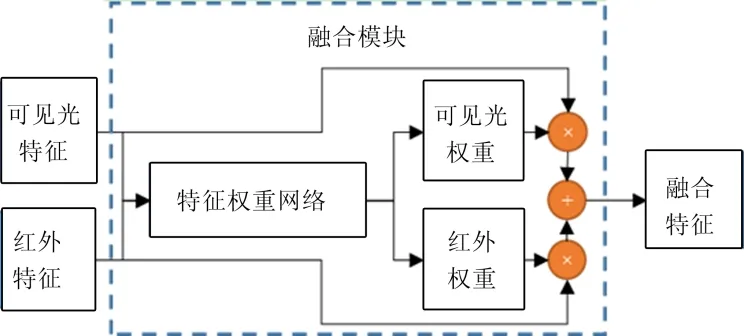
图3 特征融合模块 Fig.3 Feature Fusion Model
Ffusion的尺寸与FRGB和FIR保持一致。特征权重网络如图4所示,输入FRGB与FIR的尺寸为(C×H×W),C表示特征通道数量,H、W分别表示特征图的高度与宽度。首先通过Concat层在通道维度将特征进行合并,然后通过多层卷积的处理得到尺寸为(2×H×W)的权重,每个卷积层后需要批标准化及激活函数处理,最后在通道维度做Softmax处理,得到2个尺寸为(H×W)特征图,分别为WRGB和WIR。WRGB+WIR=1。

图4 特征权重网络 Fig.4 Feature Weight Network
特征权重网络(FWN)可以根据预测结果优化权重大小,自动选取可见光图像或红外图像特征。比如在光线较暗的情况下,红外图像的权重就会比较大;而在热辐射信息量少,可见光图像较清晰的情况下,就会更多地使用可见光图像进行目标检测。FWN以图像的特征图作为输入而不使用图像本身,是为了减少图像处理的复杂度。特征图经过多层神经网络的处理,具有更多深层信息,因此在FWN中可以采用较少的卷积层,达到复杂计算的效果。
在实际的可见光图像与红外图像中,不同位置可能会需要不同的权重值。比如图像左侧热辐射信息更丰富,那就应该更多利用红外图像信息;而右侧可能没有热辐射信息,需要依靠高分辨率纹理信息,故应加重可见光图像的权重。单一权重值的方式无法做到分别计算,因此采用了尺寸为(H×W)的权重图来解决这一问题,权重图可以为每一个位置不同的权重,充分利用可见光图像和红外图像提供的不同信息。权重图的方法适用于已经进行像素匹配的可见光图像和红外图像数据。也就是说同一目标在可见光图像和红外图像中的位置相同,才能利用权重图的方法对相同位置的目标计算权重。
这一方法在多类别多目标检测中也有一定作用,比如在对行人检测时,热辐射信息明显,需要加大红外图像权重;对汽车等物体检测时,更多需要依赖可见光图像,需要加大可见光图像权重。当行人和汽车在同一张图片时,就可以利用权重图进行不同权重的融合,更有利于精准的预测。
特征融合模块本质上就是多层卷积神经网络,可以灵活的插入到现有的目标检测算法中。可以跟随目标检测算法一同优化,不需要其他多余的操作。与一般先融合出一张图片再检测的方法比较,特征融合算法可以保留原始图像的特征,并根据目标检测的结果对特征进行挑选及融合,避免先融合图像造成的信息损失。
2 实验及结果
2.1 数据集
通过使用文献[8]的M3FD数据集,如图5所示,该数据集通过一个光学摄像机和一个红外摄像机同步采集数据。共包含4200对可见光与红外图像对,图像大小为1024×768。图像经过手工标注,共有34407个标签,共有6个标签类别:行人、汽车、公交、摩托车、信号灯、卡车。实验使用80%的数据作为训练集,其余20%作为验证集和测试集。

图5 M3FD数据集 Fig.5 M3FD Dataset
2.2 实验方法
为了验证特征融合的有效性,进行了3组实验进行对比。分别为可将光图像目标检测,红外图像目标检测,特征融合目标检测。前两组实验使用传统YOLO算法进行,特征融合算法流程如图1所示。使用2套Backbone+Neck的网络结构分别输入可见光图像及红外图像,使用3个特征融合模块对不同尺寸的特征图进行融合,使用1个Detection网络进行目标预测。Backbone、Neck、Detection均来自YOLO算法v5版本。特征权重网络结构如表2所示。

表2 特征权重网络结构 Tab.2 Feature Weight Network Structure
实验在搭载NVIDIA 3090显卡的服务器上运行,训练数据共有3360对可见光图像和红外图像,训练批次大小为16,共进行了300次迭代。验证集共有840对图片,最终选出在验证集上表现最好的结果进行比较。
2.3 实验结果
使用M3FD数据集分别进行了3组实验,使用平均精度的平均值(mAP)对实验结果进行评价,见表3。IOU取值0.5,表示预测目标范围与实际目标范围相交的面积比合并的面积大于等于0.5。第1组RGB仅使用可见光图像进行目标检测;第2组IR仅使用红外图像进行目标检测;第3组Fusion使用可见光图像和红外图像进行特征融合目标检测。预测结果表示,3组实验均能较好地进行目标检测。

表3 实验结果(0.5mAP) Tab.3 Result(0.5mAP)
从表3中可以看到,使用特征融合模块的0.5mAP值达到0.883,高于单独使用可见光图像或红外图像的目标检测结果。在对摩托车、信号灯的检测中,特征融合方法的结果最优,在其他类目标检测中,特征融合的方法也能接近最好结果。在对行人进行检测时,具有热辐射信息的红外图像抗干扰能力强,行人的特征更加清晰,所以红外图像的检测结果更好。特征融合的结果0.870接近红外图像的检测结果0.874,远高于可见光对应的结果0.815。在对其他目标检测时,热辐射信息较少,所以可见光检测结果高于红外图像检测结果。此时,特征融合算法的结果能够接近甚至超过可见光图像检测结果,说明融合算法能够有效利用可见光图像同时也能够借鉴红外图像。
3 结束语
基于提出的特征融合检测算法,可以同时使用可见光图像和红外图像进行目标检测,建立了一种端到端的神经网络模型。利用目标检测的结果进行优化,自动根据目标计算特征权重,使用权重将可见光图像与红外图像进行融合。当可见光图像效果好时,更多使用可见光图像进行目标检测,反之,更多使用红外图像进行目标检测。实验结果表明特征融合算法结果优于单独使用可见光图像或红外图像,证明此算法达到了预期,可以自动的为可见光图像和红外图像分配权重,更好的进行融合,以达到更优的目标检测效果。
可见光图像和红外图像获取成本较低,二者融合后蕴含大量信息并且抗干扰能力强,在遥感探测、医疗卫生、视频监控等领域有着很好的应用前景。接下来要进一步提高检测结果的准确性,充分利用图像融合的优势。另外还需考虑同时处理两张图片带来的计算量增加,要如何提高计算效率。多目标检测以及有遮挡目标检测同样是值得探究的技术难点,可以作为今后的工作内容。
猜你喜欢
环球时报(2022-05-23)2022-05-23 11:28:37
金桥(2021年4期)2021-05-21 08:19:20
当代陕西(2020年17期)2020-10-28 08:18:18
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
电子制作(2019年7期)2019-04-25 13:17:14
人大建设(2018年5期)2018-08-16 07:09:00
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
电信科学(2017年6期)2017-07-01 15:44:57
光学精密工程(2016年3期)2016-11-07 09:03:43
