
K-Means 算法最优聚类数量的确定
2022-12-04 07:39:52何选森樊跃平
电子科技大学学报 2022年6期
何选森,何 帆,徐 丽,樊跃平
(1. 广州商学院信息技术与工程学院 广州 511363;2. 湖南大学信息科学与工程学院 长沙 410082;3. 北京理工大学管理与经济学院 北京 海淀区 100081)
在大数据时代[1],数据分类是数据应用的基础,由于无监督的分类(unsupervised classification)或聚类(clustering)[2]不需要对数据进行训练,因而获得了广泛应用。聚类是采用多元统计方法,依据数据间的相似性或距离测度直接把性质相近的数据归为一类,性质差异较大的样本归属于不同的类。聚类分析中的聚类结构有3 种:分区(partitional)聚类、层次(hierarchical)聚类和单个(individual)集群。层次聚类又分为凝聚层次聚类[3]和分裂层次聚类[4]。常用的聚类法有模糊C 均值聚类[5]、密度基(density-based)聚类[6]以及K-均值(K-Means)类的聚类[7]等。
在无先验知识情况下对数据分析的关键是找出数据中的固有划分(inherent partitions),尽管聚类算法可以划分数据,但不同算法或同一种算法采用不同的参数将产生出不同的数据划分或揭示不同的聚类结构(clustering structures)。因此,客观、定量地评价算法的聚类结果就显得十分重要。换句话说,由一种聚类算法得到的聚类结构是否有意义,即聚类验证(cluster validation)非常重要。层次聚类是基于邻近矩阵(proximity matrix)将数据组织到层次结构中,其结果通常用树状图[8]表示。与层次聚类相比,分区聚类将一组数据对象分配到没有任何层次结构的k个聚类中[9],而且这个过程通常伴随着对一个准则函数的不断优化。在分区聚类算法中,应用最广泛的一种准则函数是平方误差和准则(sum-of-squared-error criterion)[2]。使得平方误差和为最小的划分被认为是最优的,一般称其为最小方差(minimum variance)划分[7]。数据的聚类是指:在同一类中数据对象具有很高的相似度(similarity),而不同聚类之间的数据则具有较高的相异性(dissimilarity)[10]。显然,相似性与相异性(或称距离)可概括为邻近性,它既可以描述数据点之间、数据类之间的远近关系,又可以描述数据点与数据类之间的远近关系。对于聚类分析,常用的距离是欧几里得(欧氏)距离,利用欧氏距离形成的聚类对特征空间中的平移和旋转变换具有不变性[11]。
1 K-均值算法与聚类有效性分析
K-均值属于分区聚类的结构,目标是将数据组织成若干类,并且任一数据点只能属于一个类而不能同时属于多个类,这就意味着K-均值算法生成的是特定数量、互不相交、非层次的聚类。K-均值算法通过迭代优化步骤,利用最小化平方误差和准则来寻求数据的最佳划分,属于爬山(hill-climbing)类算法的范畴[7]。本质上,K-均值就是期望最大化(expectation maximization, EM)算法的经典范例。EM 算法的第一步是寻找与聚类相关的期望点,第二步是利用第一步的知识改进对聚类的估计,重复这两个步骤直到算法收敛。
K-均值算法中,数据对象之间采用欧氏距离来度量相异性。设数据集有n个样本,它的p维观测为:
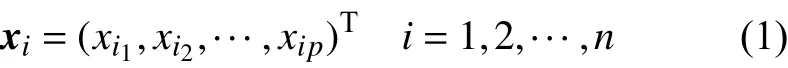
任意两个样本点xi,xj(i,j=1, 2, ···,n)之间的欧氏距离表示为dij=d(xi,xj)。如果将n个样本分成k个聚类,则选择全部数据之间距离最远的两个(序号为i1,i2)样本作为初始聚类中心(聚点):
然后再确定下一个聚点(序号i3),使得i3与i1,i2距离最小者等于所有其他点与i1,i2较小距离中的最大者:
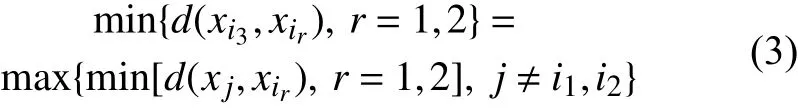
不断重复以上过程,即可确定全部k个初始聚点。因此,K-均值算法的基本过程可以归纳如下。
1) 设随机选取的k个初始聚点的集合为:
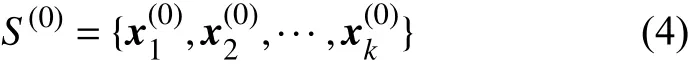
对于任意的数据点x,对它的划分原则为:
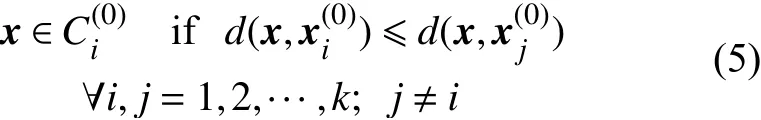
即将所有样本分成不相交的k个类,得到初始分类:



显然,K-均值聚类算法的基本思想是将数据空间首先随机地划分为事先指定的k个类,然后通过迭代计算不断更新每个类的质心。当相邻两次迭代计算的结果基本相同时,则算法收敛。尽管K-均值算法被证明是收敛的[12],然而困扰K-均值聚类的第一个问题是它的迭代优化过程不能保证算法收敛到全局最优。由于K-均值算法可以收敛到局部最优[7],不同的初始划分将导致不同的收敛质心。第二个问题是K-均值算法对数据中的异常值也即野值(outliers)以及噪声(noise)很敏感[2,7],在迭代计算聚点的过程中算法却是考虑了所有的样本。即使某个样本点离质心很远,但K-均值算法仍然将该点强行纳入最邻近的类中用于计算其质心,这样就造成了聚类形状的扭曲。另外,K-均值类算法要求用户事先指定聚类数量,这在实际中很难做到。聚类数量是否正确将直接影响聚类效果,确定最优的聚类数量也称为聚类有效性分析(clustering validity analysis)[13]。因此,在聚类分析中,一个必不可少的步骤是验证聚类结果并确保它能正确地反映数据的本质结构。基于统计理论对算法生成的聚类结构进行评估,强调以客观和定量的方式对聚类结果进行评价,这就是聚类趋势分析(clustering tendency analysis)[14]。
分区聚类、层次聚类和单个集群的结构所对应的聚类有效性测试标准分别为外部的(external)、内部的(internal)和相对的标准(relative criteria)[15],这3 种标准的适用范围不同。外部与内部标准都涉及到统计方法和假设检验[16],这将导致计算开销增加。而相对标准则无须进行统计检验,它致力于比较不同的聚类结果。因此,相对标准可用于比较K-均值类算法一系列不同聚类数量k的聚类效果,以便找出数据划分最适合的k值,这个问题也被称为聚类有效性的基本问题(fundamental problem)[17]。
K-均值类算法包括一系列聚类方法,如Kmedoids 算法[18]和K-均值算法,它们的适用范围和特点各不相同。K-均值的时间复杂度为O(nkpT),其中,n为样本数量,k为聚类数量,p为数据维数,T为算法迭代次数,由于k,p,T通常都比n小很多,因此K-均值的时间复杂度为近似的线性关系[2,7],因而它以低计算复杂度体现出高效率[18],但它的聚类结果很大程度上受数据中噪声与异常值的影响。为了解决K-均值算法的这个缺陷,Kmedoids 算法以中心点(medoids)作为聚类中心,对噪声及异常点处理能力优秀且具有较强的鲁棒性。然而它的缺点是计算复杂度较高,因此学者们致力于改进K-medoids 算法,以期在计算效率上追赶K-均值算法[18]。在众多改进的K-medoids 方法中,围绕中心点划分(partitioning around medoids,PAM)算法[19]被认为是最有效的K-medoids 算法之一。但PAM 算法的迭代次数较多,时间效率低[19]。在不考虑迭代次数的情况下,K-medoids 和PAM算法的时间复杂度都为O(k(n-k)2)[18],即为二次函数。对于这3 种经典的K-均值类聚类算法,仅从时间开销的角度来看,K-均值算法的计算速度是最快的。另外,这3 种算法的共同缺点仍是聚类数量k作为算法的参数必须事先指定。聚类数量k过大或过小的估计都将严重影响最终的聚类质量。过多的聚类数量造成真正的数据聚类结构变得复杂,使得对聚类结果的解释和分析变得困难,而过少的聚类数量将损失信息并造成错误的聚类结果。
本文主要研究经典K-均值聚类算法中最佳聚类数量的确定问题,因此,其基本的思路为:对于具体的数据集,首先在聚类数量的可能范围内,采用不同的聚类数量来运行K-均值算法以获得相应的聚类结果;然后以聚类数量k为自变量构造一种聚类有效性函数(指标)对K-均值的聚类结果进行评估,通过优化聚类有效性函数来确定最优的聚类数量。
2 聚类有效性评价函数
对于理想的聚类效果,从相似性角度要求类内样本点之间尽可能相似,同时类与类之间的样本点尽可能相异。从距离的角度则要求类内样本点之间距离的代数和应尽量小,而在不同类之间样本点距离的代数和应尽量大。在整个数据空间中,样本点与它所在类的聚点之间的距离,要比它与其他类的聚点间的距离都要小。满足这个条件的聚类就是有效的数据划分。
对于全部的n个数据点,其样本均值(质心)为:

在所有的数据中,假设第i个聚类Ci中有ni个数据对象,则定义该类的样本质心(中心)为:

从定义1 的表达式可看出,当所有样本都属于同一个类(即聚类数量k=1)时,则这个类的中心就是全体数据的质心x¯。在这种情况下,类间质心距离之和Dbetw取值为0,即取Dbetw(k)的极小值。随着聚类数量k的增加,类间质心距离之和函数Dbetw(k)是递增的。
定义2 类内距离之和 在聚类空间I 上,由每个类中的各样本到该类中心的欧氏距离之和为同一类的内部距离,而所有k个聚类的内部距离之和则定义为类内距离之和:
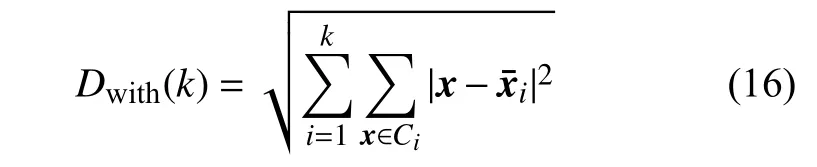
从定义2 可知,当整个数据集的样本属于同一个类(聚类数量k=1)时,Dwith就是所有数据点与其质心x¯的距离之和,即取Dwith(k)的极大值。随着聚类数量k的增加,类内距离之和函数Dwith(k)是递减的。
定义3 聚类有效性评价函数 在聚类空间I上,基于类间质心距离之和Dbetw与类内距离之和Dwith,定义一种综合评价函数(指标):
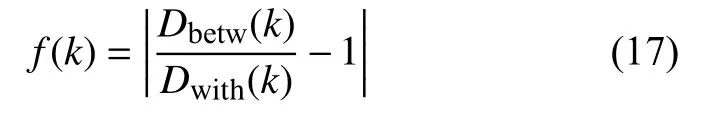
式中,|⋅|表示取绝对值。当所有数据样本点都属于同一类(聚类数量k=1)时,由于Dbetw(k)=0,则f(k)=1。显然,随着聚类数量k的变化,函数f(k)的值也发生相应变化,即f(k)是以聚类数量k为自变量的函数。对于K-均值算法,最好的聚类效果意味着聚类数量k是最优的,因此将f(k)称为聚类有效性评价函数(指标)。
在统计学中,经验规则(empirical rules)[20]常用来预测最终的结果,它也称为3σ 规则或68-95-99.7 规则。经验规则表明:对于正态分布,几乎所有的观测数据X都将落在平均值E[X]的3 个标准差σ 之内。具体地说,68%的数据落在平均值的1 个σ 之内,95%的数据落在平均值的2 个σ 之内,99.7%的数据落在平均值的3 个σ 之内[21]。在某些情况下,获取数据的分布可能很耗时,甚至是不可能的,因此正态概率分布可以作为一种临时启发式(heuristic)方法,如当一家公司正在审查其质量控制措施或评估其风险暴露(risk exposure)时,风险价值(value-at-risk)作为常用的风险工具,假设风险事件的概率服从正态分布,对于服从其他分布的观测数据来说,将经验规则推广为经验贝叶斯规则(empirical Bayes rules)[22-23],则可实现对具有k类的观测数据总体进行推断。因此,在计算出数据的均值和标准偏差之后,经验规则可用于粗略地估计观测数据总体中所隐含的数据类k的数量范围。
定理 最佳聚类数量准则 在聚类空间I 上,根据经验规则,可以估计出聚类数量k可能的最小值kmin和最大值kmax,因而获得k的取值范围[kmin,kmax]。当k在[kmin,kmax]变化时,如果聚类有效性评价函数f(k)获得最小值,则K-均值算法的聚类效果为最优,即对应的最佳聚类数量k为:
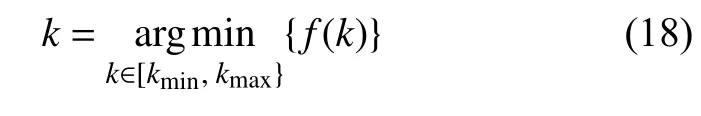
证明:由定义1 可知,类间质心距离之和Dbetw(k)是聚类数量k的单调增函数,由定义2 可知,类内距离之和Dwith(k)是k的单调减函数。因此随着k取值的变化,由定义3 可知,聚类有效性评价函数f(k)存在极小值,但并不存在有限的极大值。换句话说,函数f(k)可能取值为无穷大,此时对应的聚类数量k是不合理的。
在实际应用中,聚类数量k只能取正整数,而且函数Dbetw(k)和Dwith(k)也都只能取正实数值(非负值)。在k的有限取值范围[kmin,kmax]内,函数f(k)一定存在有全局的极小值,即最小值。显然,聚类有效性评价函数的最小值所对应的k值就是数据集的最优聚类数量。由定义3 可知,只有当Dbetw(k)和Dwith(k)的取值相等或二者非常接近时,函数f(k)才能取得最小值。换句话说,通过调整聚类数量k的取值使得Dbetw(k)和Dwith(k)达到最接近的程度,K-均值聚类的效果才是最佳的,此时对应的聚类数量k值就使得数据的分类达到最优。因此,利用聚类有效性评价函数f(k)作为确定最佳聚类数量k的准则,也就是确定f(k)的最小值准则。
为了找到K-均值算法的最佳聚类数量k,从可视化的角度,在k值的可能变化范围[kmin,kmax]内,通过绘制聚类有效性评价函数f(k)随聚类数量k的变化曲线,直观地搜寻函数f(k)的最小值点所对应的聚类数量k,即为最佳的聚类数量。
3 验证与分析
为了验证本文提出的聚类有效性评价函数的性能以及由此获得的最佳聚类数k是否符合数据本身内在的分类结构,利用加州大学欧文分校的机器学习库(UC Irvine machine learning repository)中的多个数据集进行仿真实验。
仿真PC 机的CPU 为:Intel(R) Celeron(R)1007U-1.5 GHz,内存4 GB,操作系统为Windows 10,仿真是在MATLAB 9 (R2016a)上运行。
对于数据的分类与聚类问题,最常用的UCI数据集有Iris、Seeds 和Wind 数据集。这3 种数据集的数据样本数量、属性(特征)数量以及数据真实的聚类数量如表1 所示。
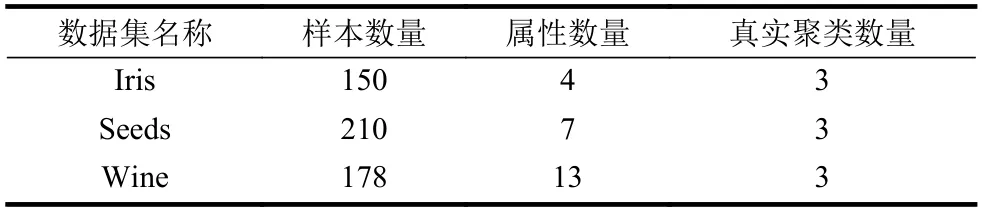
表1 3 种UCI 数据集的有关信息
仿真的基本过程为:对于每一种数据集,根据经验规则估计数据的可能聚类数量范围[kmin,kmax]。在这个范围内的每个k值,首先分别运行K-均值算法一次,并计算相对应的聚类有效性评价函数f(k)。然后多次运行K-均值算法以观察函数f(k)的变化趋势,从而对聚类有效性评价指标f(k)的平均性能进行测试。
3.1 数据集Iris 的仿真
鸢尾花Iris 数据集记录了3 种花setosa、versicolor 和virginica 的4 种属性,即萼片长(sepal length)表示为x1、萼片宽(sepal width)表示为x2、花瓣长(petal length)表示为x3、花瓣宽(petal width)表示为x4。3 种花各记录了50 组特征(即属性)的数据,按照setosa、versicolor 和virginica 的顺序存放。
为了观察Iris 数据集对应特征的统计中心位置,即不同属性值的分布范围所围绕的大致中心,首先计算出每种鸢尾花的4 个属性,即变量x1,x2,x3,x4的均值,如表2 和图1 所示。
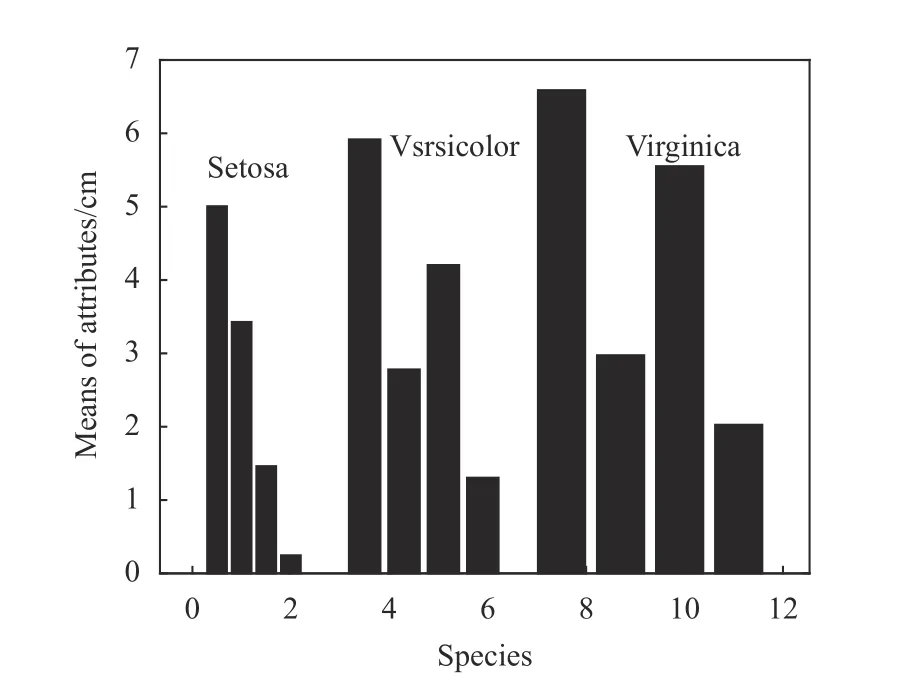
图1 3 种鸢尾花特征变量均值的条形图
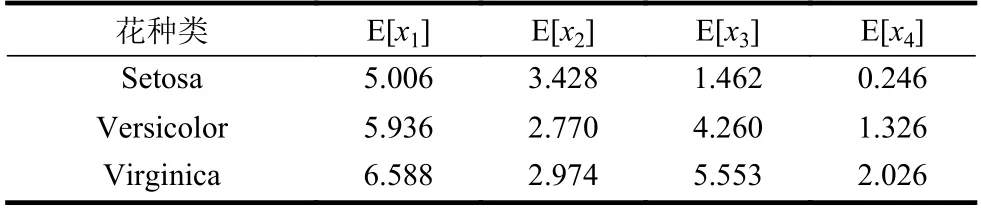
表2 3 种花4 个属性的均值 cm
根据数据样本数量以及经验规则,设Iris 数据可能的聚类数量范围为[kmin,kmax],其中kmin=2,kmax=12。对于[kmin,kmax]中的每个k值,运行K-均值算法一次,并计算出相对应的聚类有效性评价函数f(k)的值,其结果如表3 和图2 所示。
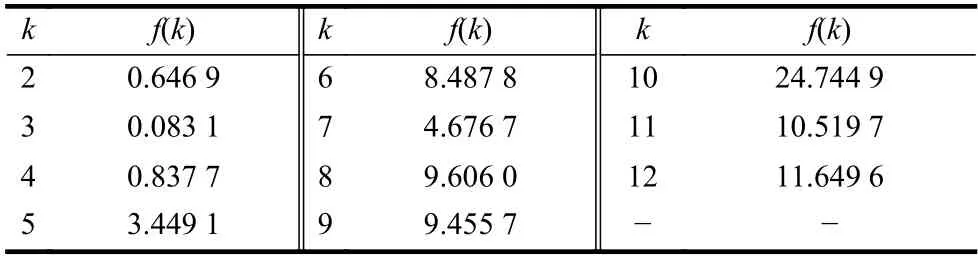
表3 Iris 数据的f(k)与k 的对应表
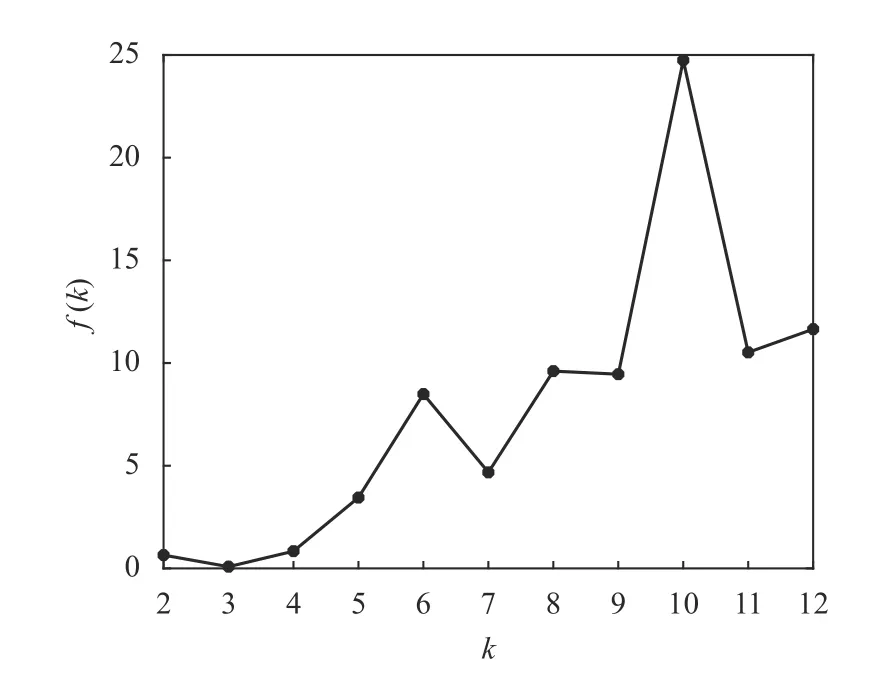
图2 Iris 数据的f(k)随聚类数量k 的变化曲线
从图2 和表3 可以看出:1)函数f(k)随着k值做相应变化,这就说明聚类有效性评价函数f(k)用来对聚类数量k的选择进行评价是有效的;2)当k=3 时,f(k)取得最小值,即最佳的聚类数量为3。这个结果证明聚类有效性评价函数f(k)能够从Iris 数据集中找出最佳的聚类数量,即真实的鸢尾花所包含的种类。
这里需要说明,K-均值算法的另一个缺陷是它可以收敛到局部最优,而且每次运行K-均值算法时,初始的聚类中心是从所有数据中随机选取的。因此算法要求必须有一个合理的初始化,在实际应用中这是不现实的。对于不同的初始划分,将导致K-均值算法收敛到不同的质心位置。一种解决方案是通过重复运行K-均值算法多次,并以多次运行的平均结果来降低随机初始化的影响。为此,将K-均值算法按照上述的仿真条件重复运行10次,每次分别记录下对应的聚类有效性评价函数f(k)的值。为观察方便,这里仅绘制出每次运行中函数f(k)随聚类数量k的变化曲线,其结果如图3所示。
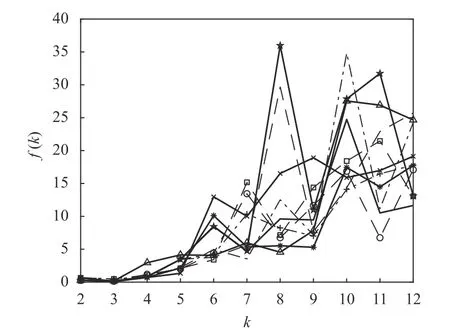
图3 10 次运行中Iris 数据的f(k)随k 变化的曲线
从图3 可以看出,虽然K-均值算法的10 次运行结果各不相同,但在每次运行中,聚类有效性评价函数f(k)的最小值都是在k=3 时取得的,这是不变的。图3 的结果说明f(k)对于确定最佳聚类数量是有效的。
在多次运行K-均值算法的基础上,再考虑聚类有效性评价函数f(k)的平均性能。对于每个可能的k值,将10 次运行的f(k)求平均值可得到E[f(k)],其结果如表4 和图4 所示。可以看出,聚类有效性评价函数f(k)在K-均值算法10 次运行中的平均值E[f(k)]仍然在k=3 时取得最小值,这也反映了Iris 数据集中真实的鸢尾花品种为k=3。另外,由于K-均值算法对数据采用随机的初始划分,使得每次运行获得的聚类中心位置并不相同,但从多次运行的结果来看,E[f(k)]仍然能够准确地反映Iris 数据集的本质结构。即聚类有效性评价函数对K-均值的随机初始化具有鲁棒性(robustness)。
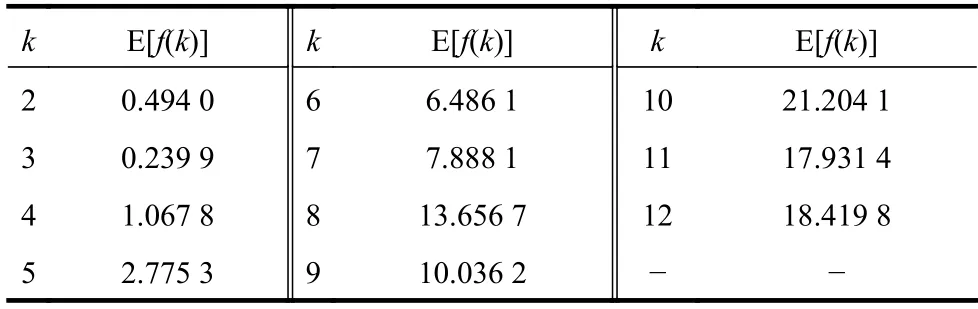
表4 Iris 数据的E[f(k)]值与k 的对应表
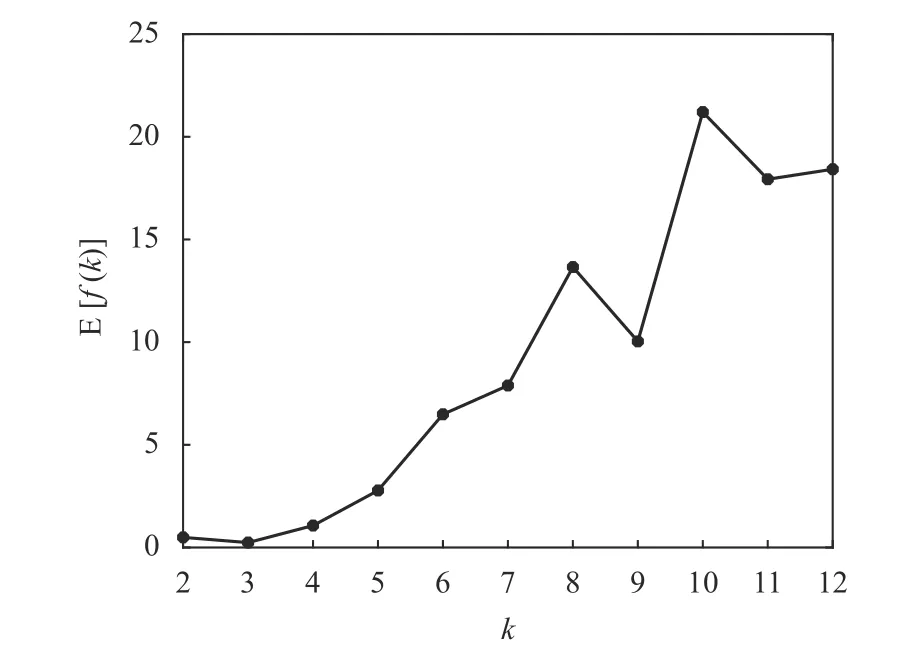
图4 10 次运行中Iris 数据的E[f(k)]随k 变化的曲线
3.2 数据集Seeds 的仿真
种子(Seeds)数据包括3 种小麦粒(wheat kernels)的7 个几何参数(属性):面积(area)x1、周长(perimeter)x2、密度(compactness)x3、长度(length)x4、宽度(width)x5、不对称系数(asymmetry coefficient)x6、沟槽长度(length of kernel groove)x7。显然,这些属性的度量单位是不相同的。Seeds 数据集对每一类小麦分别记录了70 组特征的数据,按照类标签1、2、3 的顺序存放。
对于Seeds 数据,分别计算3 类(class 1, 2,3)小 麦7 个 属 性x1,x2, ···,x7的 均 值,如 图5 所示。以上均值给出的是3 类小麦所有样本几何参数的分布中心。根据数据集的样本数量以及经验规则,设Seeds 数据集中可能的聚类数量范围为[kmin,kmax],其中kmin=2,kmax=13。对于[kmin,kmax]中的每个k值,运行K-均值算法一次,并计算出相对应的聚类有效性评价函数f(k),其结果如图6所示。
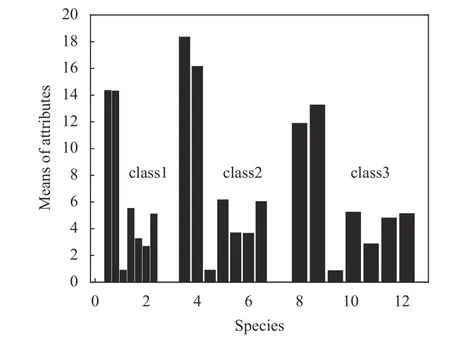
图5 3 种小麦特征变量均值的条形图
由聚类有效性评价函数(指标)的定义可知,若所有数据都属于同一类(即k=1),则指标f(k)=1。为了便于观察和比较,在图6 中还给出了k=1 的波形。可以看出,当k=3 时,聚类有效性评价指标f(k)取得一个最小值0.327 1,即给出了K-均值算法的最佳聚类数量为3。这一结果与Seeds 数据集的实际情况是一致的。
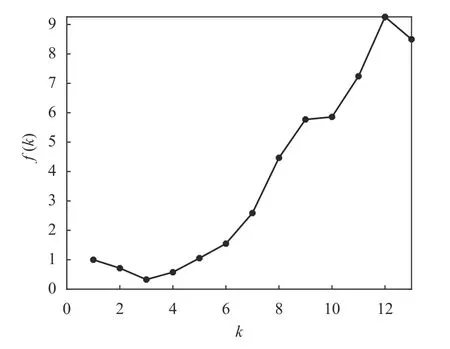
图6 Seeds 数据的f(k)随聚类数量k 的变化曲线
同样地,为了考察K-均值算法在重复多次运行情况下的整体性能。对于Seeds 数据集,在k的可能取值范围[kmin,kmax]内重复运行K-均值算法15 次,每次运行记录和保存聚类有效性评价函数f(k)的对应值,其结果如图7 所示。可以看到,在K-means 算法的15 次运行中,尽管每次运行f(k)的取值以及取值的分布情况都不相同,但是指标f(k)的最小值毫无例外地在k=3 时获得。这表明聚类有效性评价函数f(k)在确定最优聚类数量方面的性能是非常稳定的。
对于每个可能的k值,把上述15 次K-均值算法运行所得到的f(k)值取平均得到E[f(k)],绘制出E[f(k)]随k值变化的曲线如图8 所示。
由图8 可以看出,从聚类有效性评价函数的平均性能E[f(k)]仍然可以清晰地识别出Seeds 数据集的真实聚类结构(k=3)。另外,从图7 和图8 的结果可知,在最优聚类数量的确定方面,指标f(k)以及其平均值E[f(k)]的性能不会受到K-均值算法随机初始化的影响。

图7 15 次运行中Seeds 数据的f(k)随k 变化的曲线
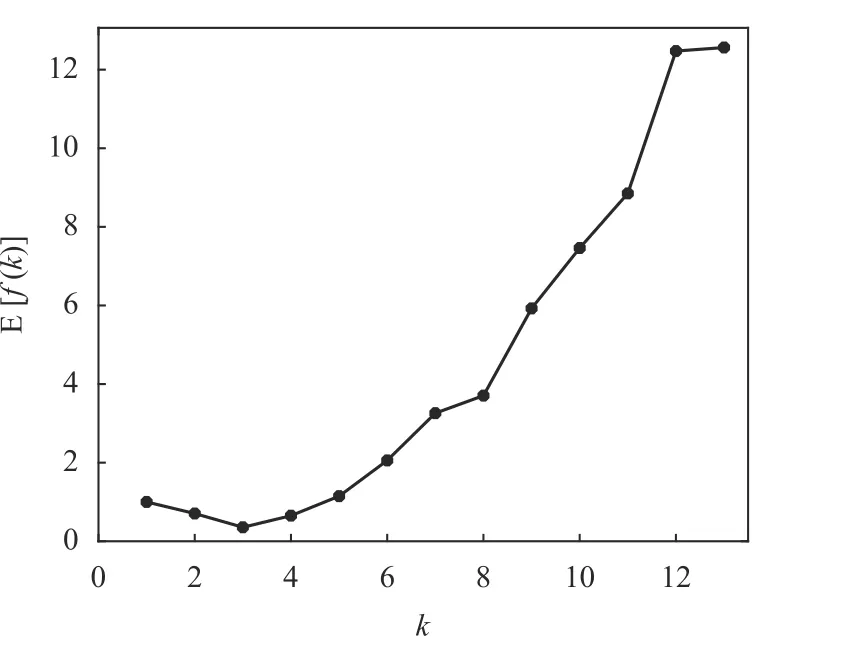
图8 15 次运行中Seeds 数据的E[f(k)]随k 变化的曲线
3.3 数据集Wine 的仿真
葡萄酒(Wine)数据是对在意大利同一地区种植,但来自3 个不同品种的葡萄酒进行化学分析的结果。这种分析确定了3 种类型的葡萄酒中所含13 种成分(属性、特征)的含量。这些属性分别为酒精(x1)、苹果酸(x2)、灰(x3)、灰分碱度(x4)、镁(x5)、总酚(x6)、黄酮素类化合物(x7)、非黄酮类酚类(x8)、原花青素(x9)、颜色强度(x10)、色调(x11)、稀释葡萄酒的OD280/OD315(x12)和脯氨酸(x13)。这些特征值的度量单位是不相同的。Wine数据集中共记录了178 组数据,3 种类型葡萄酒的类标签分别为1, 2, 3,它们各自的样本数分别为59, 71, 48。对于Wine 数据集,由于不同属性(变量)的取值之间差距太大(相差3 720 倍),无法用图形表示变量的均值。这里仅给出全部13 个变量的平均值(包括所有葡萄酒的种类),其结果如表5所示。
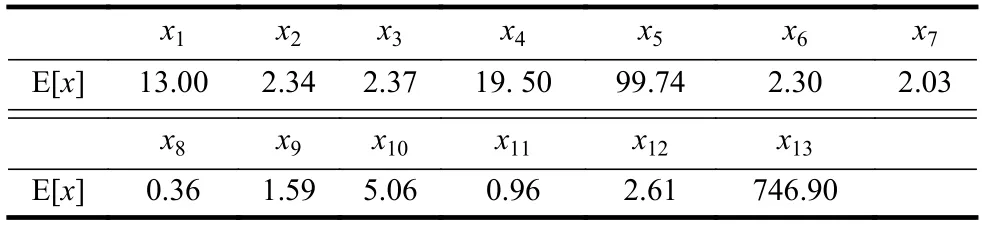
表5 Wine(全部种类)数据各属性的平均值
Wine 数据的均值给出了各属性值分布的大致统计中心。考虑到Wine 数据集的属性较多,根据经验规则将数据可能的聚类数量设置为kmin=2,kmax=16。首先对于区间[kmin,kmax]中的每个k值,运行K-均值算法一次,并计算出相对应的聚类有效性评价函数f(k)的值,其结果如表6 和图9 所示。

表6 Wine 数据的f(k)与k 的对应表
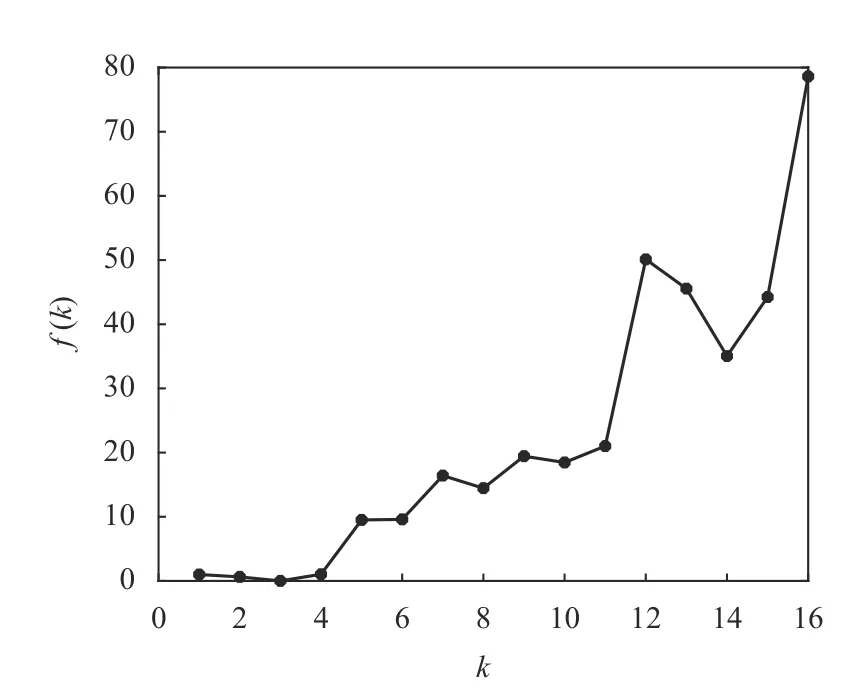
图9 Wine 数据的f(k)随聚类数量k 的变化曲线
为观察方便,图9 也给出了k=1 对应的数据。由于f(k)取值的范围较大,最小值附近其差别不易区分,为此把图9 中的数据列在表6 中。从表6 中的数据可知,f(2)是f(3)的143 倍,f(4)是f(3)的236 倍。显然,k=3 是指标f(k)的最小值点,即k=3 是最优的聚类数量,这与Wine 数据本质结构是一致的。
类似地,对于Wine 数据集,在可能的聚类数量范围[kmin,kmax]内重复运行K-均值算法15 次,计算并记录每次运行中指标f(k)的取值,其结果如图10 所示。
从图10 也可看出,在运行K-均值算法的过程中,由于指标f(k)的取值范围较大,在它的最小值点附近的指标f(k)取值也不易区分。为此,考虑15 次运行K-均值算法得到的平均性能E[f(k)],其结果如图11所示。

图10 15 次运行中Wine 数据的f(k)随k 变化的曲线
从图11 可以看出,对于Wine 数据,随着聚类数量k值的增加,指标的平均值E[f(k)]曲线变化的大致趋势是:当k<3 时,E[f(k)]曲线是递减的;当k>3 时,E[f(k)]曲线是递增的,因此在k=3 时取得E[f(k)]的最小值。为了更清楚地比较在E[f(k)]最小值附近数值上的差别,将图11 中的E[f(k)]值列在表7 中。可以看出,E[f(2)]大约是E[f(3)]的3.65 倍,而E[f(4)]大约是E[f(3)]的6.8 倍。
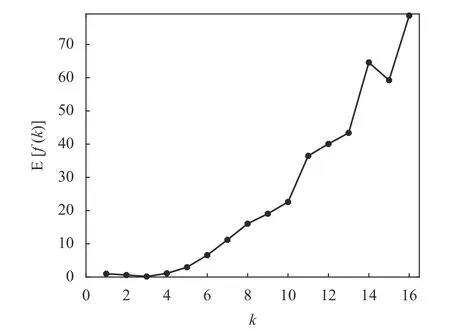
图11 15 次运行中Wine 数据的E[f(k)]随k 变化的曲线
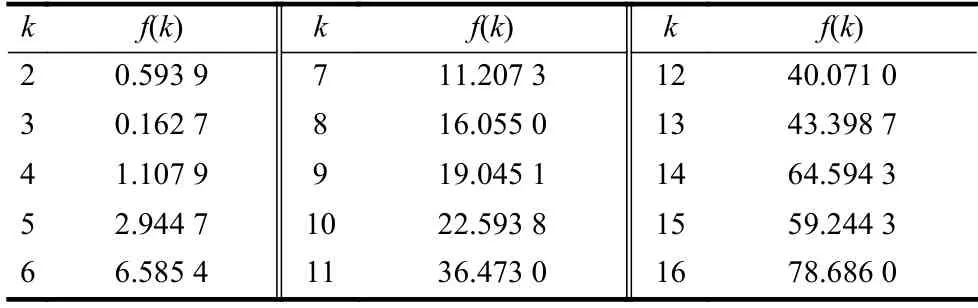
表7 Wine 数据的E[f(k)]值与k 的对应表
尽管Wine 数据集的平均性能E[f(k)]的取值范围相当大,但从它的全局极小值即最小值来说,仍然能辨别出k=3 是Wine 数据集最优的聚类数量。
从以上对3 个UCI 数据集(Iris, Seeds, Wine)的仿真结果可知,利用聚类有效性评价函数f(k),不仅能够对原始数据集提供最优的聚类数量,而且从多次重复运行K-均值算法的效果来看,函数f(k)还能够对随机初始化提供很强的鲁棒性。
4 结 束 语
为了克服K-均值聚类算法需要用户预先指定聚类数量的缺陷,本文对K-均值算法的基本迭代步骤和聚类有效性进行了分析;然后,基于数据点的欧几里得距离,给出了类间质心距离之和、类内距离之和的定义,用于度量不同聚类间和同一聚类的数据距离;最后,提出了一种由类间质心距离之和与类内距离之和构造而成的聚类有效性评价函数,用以确定数据最优的聚类数量。在数据可能的聚类数量范围内,利用求解聚类有效性评价函数的最小值来确定K-均值算法的最佳聚类数量。通过对UCI 中Iris、Seeds 和Wine 数据集的仿真,证明了所提出的聚类有效性评价函数不仅能够准确地反映原始数据的真实聚类结构,而且还能有效地降低K-均值算法对随机初始化的敏感性。
猜你喜欢
小学生学习指导(低年级)(2019年3期)2019-04-22 03:34:42
电子测试(2017年15期)2017-12-18 07:19:27
高中生学习·高三版(2016年1期)2016-05-30 05:45:06
小猕猴智力画刊(2016年6期)2016-05-14 21:40:48
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01 03:46:20
智能系统学报(2015年4期)2015-12-27 09:38:39
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01 02:54:01
现代企业(2015年5期)2015-02-28 18:51:08
电子设计工程(2015年6期)2015-02-27 12:04:53
数学年刊A辑(中文版)(2014年4期)2014-10-30 01:50:38
