
基于多智能体强化学习的社交网络舆情增强一致性方法
2022-12-04 07:29谢光强许浩然陈广福
广东工业大学学报 2022年6期
谢光强,许浩然,李 杨,陈广福
(广东工业大学 计算机学院, 广东 广州 510006)
随着无线通信网络和互联网技术的快速发展,人们能够快速地和大规模群体进行实时观点交换,其中,社会网络团体决策(Social Network Group Decision Making,SNGDM)正快速成为解释人类行为的关键工具[1-3],为学术和工程领域带来了潜在的价值,如:供应商选择[4]、公众舆情管理[5-7]、政治选举[8-10]、市场[11]等。SNGDM中包含了一组可以表达自身观点的人(智能体),这些智能体能够和其邻居进行交流并以选择最优候选解为目标。观点(Opinion)是影响和定义行为最关键的因素之一[12-13]。每个智能体通过考虑其邻居的观点来对自身观点进行修正,以此达到一致、两极化、分裂的稳定结构,这种过程被称为观点演化,又称舆情动力学(Opinion Dynamics)[12]。
在SNGDM中最具有挑战性的问题是所有智能体达成观点上的全面一致性[12,14-16]。同时,在舆情动力学中,网络拓扑表示智能体间的交互规则,对舆情的演化起着重要的作用[17-18]。由于社交网络拓扑中常常存在稀疏的网络连接,因此达成全面的一致性更为复杂,相关研究仍然处于初期[1]。目前,大部分上述研究仅考虑了智能体与具有相似观点的邻居之间的一跳连接,而忽略了设计更为高效的通信交流方式,以更好地在大规模场景下增强一致性。此类问题可以通过多智能体强化学习(Multi-agent Reinforcement Learning,MARL)来解决,该方法正成为一种在线解决动态复杂问题的强大技术手段[19-20]。例如,Shou等[21]提出了一种平均场表演者−评论者的MARL算法来解决在竞争场景下多驾驶员重定位的问题。Sun等[22]通过多智能体决定性策略梯度方法来解决合作场景下电压控制问题。
但目前鲜有学者将MARL的优势融入到社交网络增强舆情一致性的研究中,因此本文提出了一种全新的基于MARL的智能感知模型COEIP(Consensus Opinion Enhancement with Intelligent Perception),通过分布式的手段增强系统的舆情一致性。具体来说,在社交网络下舆情动力学模型的马尔科夫决策过程中,由于各智能体感知范围有限,在每个时刻感知到的邻居数量不定,进而导致各智能体获取的邻居状态信息不定长。因此本文设计了基于双向循环神经网络的模型来构建智能体的感知模型,使智能体具备邻域选择的能力;接着通过差分奖励的思想设计了具有3类不同舆情动力学场景目标的奖励函数,并使用基于策略梯度的多智能体探索与协同更新算法来高效训练智能体的感知模型,使智能体具备多目标权衡的邻域选择能力。大量仿真验证了本文提出的COEIP方法和差分奖励函数的有效性。同时在与3类传统方法的对比中验证了本方法可以有效增强所有智能体之间的意见一致性,即减少社交网络最终稳定时形成的簇的数量,具有一定的优越性。
1 基于MARL的增强舆情一致性方法
1.1 社交网络舆情动力学
社交网络中的舆情动力学模型刻画了拥有各自观点的智能体在既定的融合规则下与其邻居进行观点演化的过程,本文针对具有时变切换拓扑的离散多智能体系统[12]进行研究。
(1) 舆情动力学模型的环境:考虑系统中的一组智能体V={1,2,···,i,···,n} ,其中每一个智能体i∈V均能够在离散时刻k∈{0,1,2,···}与其邻居进行舆情观点的通信交流。整个多智能体系统在时刻k的通信网络拓扑使用无向图G(k)={V,E(k)}来表示,其中一条边(i,j)∈E(k)为 从智能体i到j的通信流。
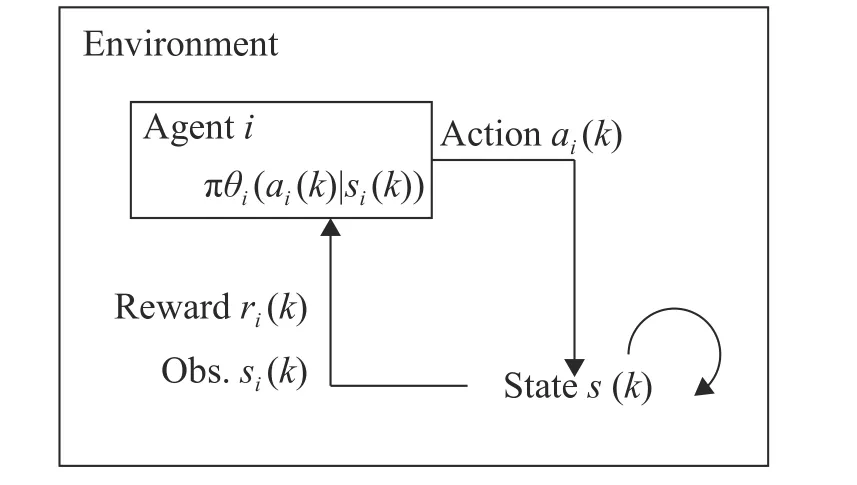
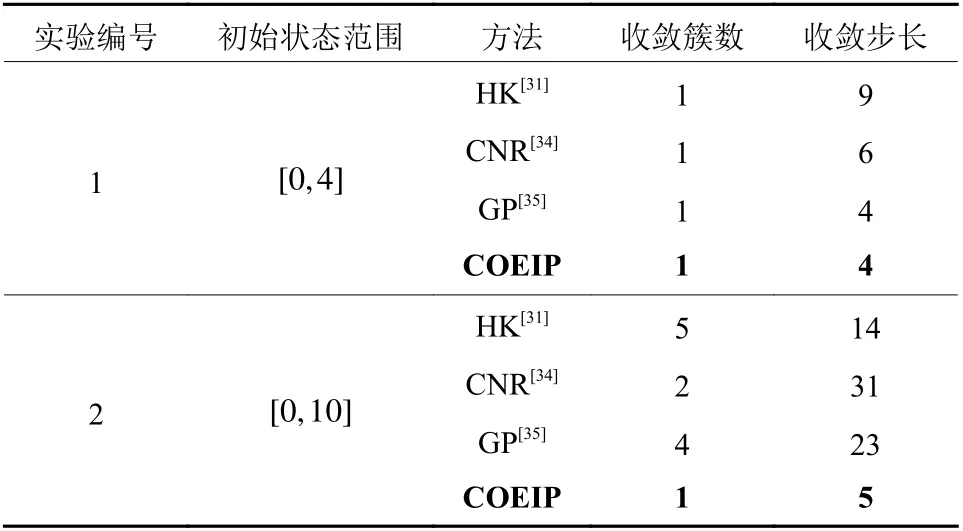
(2) 舆情动力学模型演化的融合规则:2个智能体Vi和Vj如 果满足|xi(k)−xj(k)| 根据式(1) 的定义,一个智能体永远是其自身的邻居,用|Ni(k)|表示邻居的数量。接着,智能体同步根据式(2) 的动力学模型进行舆情观点的演化。 式(2) 所定义的舆情动力学的融合规则表明,每个智能体通过计算可信任邻居观点的平均值来更新自身的观点。 (3) 舆情观点的表示形式:在系统中的每一个智能体Vi∈V在时刻k针对同一个问题均持有一个实数舆情观点值xi(k)。 定义系统在时刻k整体的舆情值为矩阵X(k)=[x1(k),x2(k),···,xn(k)]T。因此,动力学模型(2) 可以重写为式(3) 的矩阵形式。 式中:L(k)=[lij(k)]矩阵为网络的通信拓扑关系,元素lij(k)的定义为 在传统舆情动力学模型(3) 的演化过程中,舆情观点的一致和网络通信拓扑有着紧密的联系,但传统模型中代表网络通信拓扑的L(k)矩阵是根据邻居的定义(1) 计算得来的,过于单一,忽视了智能体在舆情演化过程中的辨别能力和自主选择能力,进而导致了系统最终稳定时分裂为多个簇。因此,本文旨在赋予智能体更为智能的感知能力,让智能体通过综合考量感知到的局部邻居舆情值,自适应地选择利于达成一致的邻居做舆情演化,从而达到增强系统整体一致性的效果。 马尔科夫决策过程(Markov Decision Processes,MDPs)是MARL中系统建模分析的基础。根据上节的分析,扩展了Zhang等[23]提出的MARL下的马尔科夫决策过程,通过式(5) 所示的五元组来定义本文针对社交网络下舆情动力学模型的马尔科夫决策过程。 如图1所示,本文定义的马尔科夫决策过程的运作流程可以表述为:在时刻k,每个智能体i根据通信拓扑G(k) 获取全局状态s(k) 中的局部观测状态si(k),并根据自身的策略函数 πθi做出自身的动作ai(k),进而转移到新的状态si(k+1), 同时智能体i根据奖励函数Ri获得即时奖励ri(k),如此往复,智能体在与环境交互的过程中不断学习调整策略函数πθi(ai(k)|si(k))来最大化未来的期望累计回报,如式(6)所示。 图1 社交网络下舆情动力学模型的马尔科夫决策过程示意图Fig.1 Markov decision processes in social network 接下来针对智能体i的策略进行建模。由于在舆情一致性演化过程中每个智能体感知到的邻居数不确定,且决策时需对每个局部邻居进行评判,因此本文采用循环神经网络来解决局部感知输入不定长和决策不定长的问题。由于循环神经网络是一种按时间序列进行分析的模型,智能体还需要将感知到的所有邻居的整体上下文信息综合起来做判断。故本文设计了基于双向循环神经网络中BGRU(Bidirectional Gated Recurrent Unit)[24]的决策网络模型,如图2所示。 图2 基于双向循环神经网络的决策模型示意图Fig.2 Decision making model based on BGRU 在该网络模型中,输入为智能体i所有邻居的状态值集合{xj(k):j∈Ni(k)},即所有邻居的舆情观点值经过BGRU网络后,通过全连接层和Sigmoid激活函数输出针对每一个邻居观点值的动作,动作ai(k)表示选择每个邻居的概率。那么,动作ai(k)的维度与输入状态集合的维度是一致的,即维度均为 [Ni(k),1]。同时,为了让智能体具有探索能力以提高学习过程的鲁棒性,在最后动作的全连接层权重处增加了标准正态分布N的噪声。最终该模型输出的动作为选取每个邻居的概率,其值所属范围为( 0,1)。规定智能体i选取某个邻居j的概率用i表示,如果>0.5,则认为智能体i选 取j作为舆情演化的依据。最终,将所有大于0.5的邻居汇总为式(7) 所示的集合,即经过决策模型后选取的新邻居集合。 作为一种以目标为导向的智能方法,强化学习中的目标通常采用累计奖励来表示,因此奖励函数的设计对智能体能力的学习起着至关重要的作用[25-26]。同时,奖励函数的设计需要综合考量指标系数和可学习力之间的平衡[27-28]。因此本文在文献的基础上,设计了舆情动力学环境下的差分奖励(Difference Reward)函数式。 式中:s(k) 为 全局状态,s−i(k)为全局状态去除智能体i状态后的剩余状态,g(·)函数为舆情动力学环境中的量化目标。那么,式(8) 所示的差分奖励函数能够更具区分度地表征智能体i对于特定目标g(·)的贡献度。为此,本文归纳出了3类舆情动力学场景中的目标,并通过加权组合的方式表示。 式中:g1(·)、g2(·)和g3(·) 分别为3类不同的目标;α 、β 和γ分别为3类不同目标的加权系数。需要注意的是,式(8) 中的g(s(k))和g(s−i(k))均使用式(9) 来计算,这两者的区别只在于传入状态值不同。同时,为了方便表述,在下文的奖励函数中用s(k)表示抽象的全局状态输入参数,实际计算中会发生变化。 (1)g1(·)目标:旨在让智能体学会提高收敛效率,该目标采用CD(Consensus Degree)表示,CD通过系统中所有智能体舆情观点值的标准差来量化收敛程度,同时为了让智能体能够快速收敛,在标准差的基础上减去每一步的时间惩罚,即 式中:X(k) 为在k时刻全局状态s(k)中的智能体整体舆情值列表, s td(·)为标准差操作。那么,该量化目标的取值范围为[ 0,+∞),该值越接近0表示系统的收敛性能越好。 (2)g2(·)目标:旨在让智能体学会提高系统的连通密度,该目标采用Graph Density(GD)表示,GD通过系统网络拓扑的密度来量化连通密度,即 (3)g3(·)目标:旨在让智能体学会降低系统的通信代价,该目标采用Neighbor Degree(ND)表示,ND通过系统中智能体的平均邻居度[29]来量化通信代价,即 式中:dj(k)为 智能体j在时刻k时的出度数,dnn,i(k)为智能体i选择邻居的平均出度数。那么,该量化目标的取值范围为 [ 0,1],该值越小表示系统的通信代价越低,当该值为1 /(n−1)时,表示此时系统处在最优的通信拓扑,即平均每个智能体选择了一个邻居作为舆情动力学演化的基准。 值得注意的是,g2(·) 目 标与g3(·)目标存在明显的对立关系,即通信代价越高,连通密度越大,反之亦然。在智能体学习过程中可以通过调整权重 β 和γ 的值来权衡不同目标之间的影响。 基于策略梯度(Policy Gradient)的强化学习算法将智能体策略参数化,通过最大化期望累计回报来直接优化自身策略[30]。该方法能够有效地优化智能体探索过程中的迭代策略,而且可以解决动作空间连续等问题。本节在状态、动作和奖励函数的建模分析基础上,给出了完整的智能体探索和学习自身策略πθi的算法,如下所示。 为了方便后文的推导,使用 τi表示智能体i在环境中运行的一组状态/动作序列(si(0),ai(0),···,si(H),ai(H)), 其中H为该序列的长度。本算法属于分布式运行、集中式训练的模式,主要包含“多智能体探索阶段”和“更新策略阶段”两部分,下面将分别详细介绍各自的运作流程。 多智能体探索阶段:如算法中的(3) ~(14) 所示,每个智能体i在环境探索过程中,只根据式(1) 获取其感知半径内邻域的状态值si(k)。接着通过如图2所示的基于BGRU的决策网络模型计算智能体i选取每个邻居的概率动作,进而通过式(7) 得到新的邻域N︿i(k)。同时,为了让智能体能够根据episode变化自动调节不同目标的奖励,给出了式(14) 的奖励目标切换方案。 那么,根据式(14) 的奖励目标切换方案以及式(8) 和式(9) 所定义的差分奖励函数,即可计算出每一个时刻智能体所获取到的差分奖励ri(k)。值得注意的是,式(14) 仅给出了奖励目标切换的一个案例,在实验部分将详细分析不同目标切换下的效果。 为了能够在“更新策略阶段”有效地学习更新智能体的策略参数,在本阶段中每个智能体在最长时间跨度为T的探索基础上,将每一步的局部感知状态si(k)、 局部动作ai(k)、 即时奖励ri(k),按时间顺序存储进经验缓冲池D中。在每一回合结束时,通过均匀随机采样,从D中选取B个智能体的轨迹进行学习。 更新策略阶段:如算法中的(15) ~(17) 所示,在每一回合结束时,通过均匀随机采样,从D中选取B个智能体的估计进行学习。在更新策略参数时,通过状态/动作序列进一步将强化学习中的目标函数(式(6) )简化为 那么,针对目标函数U(θ),通过梯度下降方法求出U(θ)的 梯度∇θ∑U(θ) 为 从式(17) 的梯度可以发现,最终求出的U(θ)的梯度中包含P(τi|θi)和 ∇θlnP(τi|θi)Ri(τi)这两部分,由于P(τi|θi) 为 轨迹Ti出现的概率,那么该梯度可以等价理解为求 ∇θlnP(τi|θi)Ri(τi)的期望。因此,可以通过采样m条轨迹的经验以平均逼近的方式估算该梯度,即 此时,式(18) 所求出的梯度可以直观地理解为算法将提高出现高奖励回报轨迹的概率,降低出现低回报轨迹的概率。接着,对式(18) 中唯一的不确定量∇θlnP(τi|θi)进行求解 在式(19) 的推导过程中,状态动作转移概率P(si(k+1)|si(k),ai(k))为式(3) 所示的系统动力学模型,在推导过程中由于不存在策略参数θ,故可以直接删去。因此,策略梯度可以整理为 式中:ζ 为学习率。 通过以上算法流程,智能体能够在舆情动力学演化的环境中学习到在保持较低通信代价的前提下促进舆情观点一致的策略。值得注意的是,在本文的研究背景中,每个智能体在演化的过程中需要进行时间的同步,同时智能体感知到的状态、做出的动作都是局部的,这有利于模型的部署和扩展。 本文实验通过Python3.6.2构建了舆情动力学的仿真环境,使用PyTorch1.6.0搭建了智能体基于BGRU的策略梯度网络。实验中涉及的相关参数如表1所示。值得注意的是,在2.2中首先验证了n=5时COEIP模型的有效性,然后将COEIP模型泛化至n=100的场景下,并与3个传统模型进行了对比验证。在所有实验中,式(1)的智能体感知半径rc设置为1[31],系统一致性稳定的判断阈值设置为0 .01。同时智能体的初始舆情状态在指定范围内均匀分布[31],其中n=5 的实验中初始舆情状态范围为[ 0,10],n=100的实验中包含初始范围[ 0,4]和[0,10]的两组实验。 表1 实验参数设定Table 1 Parameter setting of simulations 为了全面分析本文所提出的算法和模型,除了使用CD、GD和ND 3个指标外,本文还采用了代数连通度AC(Algebraic Connectivity)[32]和边连通度EC(Edge Connectivity)[33]两个指标,它们分别表示系统的连通程度和网络鲁棒性。在图3~5中验证了单独使用某个目标奖励时模型的有效性。 图3展示了单独使用目标1的差分奖励函数后的效果,即 α =1;β=0;γ=0。目标1旨在提高收敛效率,即舆情观点值的方差趋向于0,从图3可以看出AC在0.2左右,CD逐渐稳定在0,而其他指标收敛稳定的地方都大于0.5,说明系统保持了一定连通性,让舆情观点值收敛变快,但稳定的地方不明确。 图3 仅使用目标1差分奖励函数时的指标曲线Fig.3 Indicator curve with difference reward function (g 1(·)) 图4展示了单独使用目标2的差分奖励函数后的效果,即 α =0;β=1;γ=0。目标2旨在提高系统的连通密度,即GD、ND和EC趋向于1,可以发现所有指标均按预期收敛稳定,即CD逐渐变小且稳定在最低位,GD、ND和EC都向1收敛稳定。 图4 仅使用目标2差分奖励函数时的指标曲线Fig.4 Indicator curve with difference reward function (g 2(·)) 图5展示了单独使用目标3的差分奖励函数后的效果,即 α =0;β=0;γ=1。目标3旨在降低系统的通信代价,即GD、ND和EC趋向于1 /(n−1)。可以发现,最终只有GD趋向于期望值,而ND和EC均低于理想值。且大约500回合后,通过AC和CD可以发现系统已断开连接,已形成多个簇。 图5 仅使用目标3差分奖励函数时的指标曲线Fig.5 Indicator curve with difference reward function (g 3(·)) 从图3~5的实验仿真可以总结出,智能体能够根据给定目标的奖励函数使用Policy Gradient算法优化自己的决策能力,但单个目标所设定的奖励存在一定的局限性。 因此,下面将采用渐进学习的思想,先让智能体学习较为简单的策略,然后不断叠加更多的目标奖励。以式(14) 的奖励目标切换为例,给出了其对应的指标曲线,如图6所示,其中横坐标为回合数,纵坐标为目标值。 从图6可以发现指标曲线中有明显的分界线,且分界线与目标切换点是带有一定的滞后性的,但总体上呈现一致性的特点。同时可以看出混合使用目标2和3,即在800回合后,各个指标趋向稳定的值可以理解为强化学习对两个目标的权衡。因此,可以总结为:通过渐进学习混合目标奖励可以自适应学习到更好的组合策略,达到各目标间的权衡。 图6 渐进学习混合目标差分奖励函数时的指标曲线Fig.6 Indicator curve of progressive learning with mixed difference reward function 最后,通过系统稳定时的收敛簇数、收敛步长这两类指标来衡量模型的效果,其中收敛簇数用来衡量模型增强一致性的效果,收敛步长用来衡量模型的运行步数。同时将本文所提出的COEIP模型和传统的三类模型进行了综合对比实验分析,其中包含有经典的HK模型[31]、基于共同邻居规则(Common-Neighbor Rule,CNR)模型[34]和基于组压力(Group Pressure,GP)模型[35]。由于本文研究的目标是增强一致性,换言之希望以更短的收敛步长收敛至更少的簇数。为了控制变量,CNR和GP模型中相关的参数统一设置为β =0,m=1和pi=λ=0.5。 实验的统计数据如表2所示。该实验场景有100个智能体,这些智能体的舆情值分别均匀分布于[0,4]和[0,10]范围内,分别对应实验编号1和2。通过表2的数据可以发现:在较小的[ 0,4]初始范围内,3类传统方法和COEIP均可以收敛至一个簇,但COEIP可以在更短的步数内收敛;在较大的 [0,10]初始范围内,传统的HK、CNR和GP模型均会出现舆情观点分裂的情况,最终分别收敛至5、2、4个簇,而COEIP可以在更短的步长内稳定至1个簇。 表2 对比实验的统计数据Table 2 Statistics of comparison simulations 因此,可以总结为:COEIP模型通过选择适当的邻居进行舆情演化,可以有效地调和智能体间相互矛盾的观点。 本文研究了社交网络领域下舆情动力学增强一致性的问题,提出了一种基于多智能体强化学习的智能感知模型。在舆情动力学场景下的马尔科夫决策过程中,首先设计了基于双向循环神经网络来建立智能体的决策模型,接着根据舆情动力学场景中的3类目标设计了对应的差分奖励函数。最后通过基于策略梯度的多智能体探索和协同更新算法让智能体在彼此交互的过程中能够自适应地学习到高效的邻域选择策略。实验结果验证了COEIP能够让智能体决策具备多目标权衡的能力,在社交网络舆情动力学中能够高效地调和系统中差异较大的观点,以减少系统收敛稳定时簇的数量,从而促进系统一致性。未来将在本文的基础上继续研究社交网络中具有注意力机制的增强一致性方法,并验证该方法在现实场景中的有效性和泛化能力。



1.2 马尔科夫决策过程

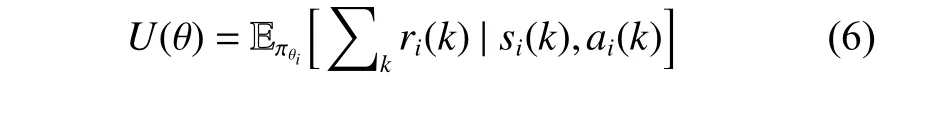







1.3 基于策略梯度的MARL算法

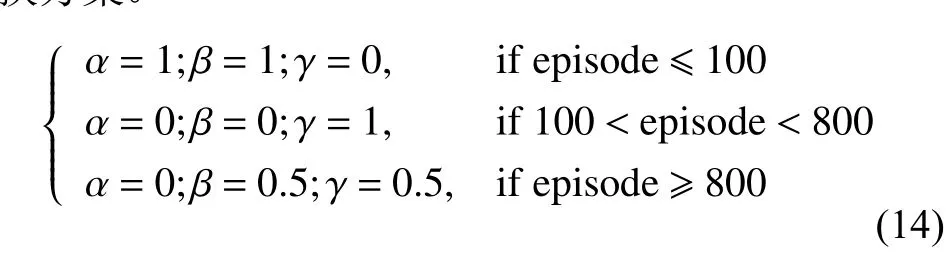



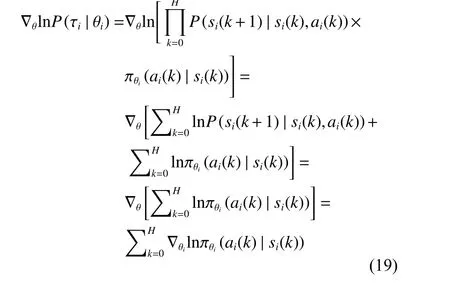

2 实验结果与分析
2.1 实验环境与参数设置

2.2 实验结果与分析




3 总结
猜你喜欢
数学杂志(2022年5期)2022-12-02
公民与法治(2022年5期)2022-07-29
教学考试(高考物理)(2021年5期)2021-11-08
新世纪智能(数学备考)(2021年5期)2021-07-28
中医眼耳鼻喉杂志(2021年1期)2021-07-22
消费电子(2016年12期)2017-01-19
中国民政(2016年16期)2016-09-19
中国民政(2016年10期)2016-06-05
中国民政(2016年24期)2016-02-11
燕山大学学报(2015年4期)2015-12-25
