
深度学习在苹果产业链中的应用与研究进展
2022-12-03 03:10黄昊谢圣桥陈度王恒
中国农业科技导报 2022年10期
黄昊,谢圣桥,陈度,王恒
(1.中国农业大学工学院,北京 100083;2.中国农业大学现代农业装备优化设计北京市重点实验室,北京 100083;3.洛阳智能农业装备研究院有限公司,河南洛阳 471934)
随着人工智能的兴起,各个传统产业都在尝试与其进行结合,以实现产业的智能化升级与革新。我国的苹果产业机械化和自动化生产水平不高,影响了产业的发展和市场竞争力,亟需探索人工智能技术的产业落地。
在人工智能领域中,深度学习是研究的热点,其开端可以追溯到2006 年,Hinton 等[1]使用神经网络进行数据降维研究。深度学习是由输入层(input layer)、隐藏层(hidden layer)和输出层(output layer)组成的多层结构的神经网络,使用多阶段非线性信息处理单元处理复杂的非线性问题,进而实现特征学习和模式分类[2-3]。
深度学习的过程由推理阶段和训练阶段[4]组成。深度学习模型的每层节点(处理单元)都会连接到相邻层的节点,每个连接都有相应的权重值,输入乘以权重后在节点处进行求和,再将总和进行非线性变换(激活函数)后得到输出,经过多次上述操作后实现对原始输入的转换或特征提取[5],该过程为推理阶段也叫前向传播;训练阶段基于推理阶段,在大量标注数据下通过反向传播、损失函数与优化器等共同作用实现参数的优化[6]。
从2006 年发展至今,典型的深度学习模型有卷积神经网络(convolutional neural network,CNN)、深度置信网络(deep belief network,DBN)和堆栈自编码网络(stacked auto-encoder network)模型等[7],对于苹果产业链来说,将机器视觉与卷积神经网络相结合是深度学习在该领域的重要应用,
VGG(visual geometry group)、FCN(fully convolutional networks)、YOLO(you only look once)和Faster R-CNN(region-convolutional neural network)等经典卷积神经网络模型在苹果种植、采摘收获和产后检测中的应用逐渐增多,也表明该技术与苹果产业链具有较高契合度和研究价值。
本研究聚焦近几年深度学习在苹果产业链中的应用案例和研究进展,对相关研究进展进行归纳总结,在苹果种植阶段着重于病害识别、果树疏花、长势监测和品类识别方向的应用;在采摘收获阶段着重于采摘机器人对果树与果实的辨识应用;在产后阶段着重于基于颜色、大小和品质无损检测的应用。
1 深度学习在苹果种植阶段中的应用
苹果种植阶段是果园管理的核心阶段,其管理方法的科学性、合理性与先进性将对苹果的品质、产量和质量具有最直接的影响,因此该阶段也是深度学习发挥作用的最有价值的阶段,由于深度学习强大的特征自动提取能力,其在病虫害识别、果树疏花、长势监测与品类识别中的研究和应用相当广泛。
1.1 苹果树病虫害的识别
虫害对苹果产量和质量的影响巨大,因此,果树病虫害防治是苹果在种植生产和果园管理过程中的重要工作,对于不同的病虫害要采取不同的防治手段,苹果果树的病虫害识别往往需要专业人士的帮助,但由于果园种植的人力成本限制,很少有苹果园能配备专业的病虫害防治专家。因此,运用深度学习对图像深层信息的获取能力,实现苹果果树病虫害的自动化和智能化识别,已经成为苹果病虫害防治领域技术发展的重要方向。
苹果树叶片状态最能直观反映苹果树病虫害类别的性状表征,通过叶片表征信息快速准确地获取苹果树病害类别将为苹果病虫害防治提供技术支持。但苹果树叶片的纹理形状和病虫害种类多样,且不同种类的病虫害又具有相似的叶部表征,故传统的计算机视觉与识别算法在苹果叶片病虫害识别任务中的综合性能相对不佳。
运用卷积神经网络对图像深层抽象特征的自动提取能力,使得叶片病虫害识别的精度和效率都有了显著提高。卷积神经网络主要由输入层(input layer)、卷积层(convolutional layer)、池化层(pooling layer)和全连接层(fully connected layer)组成(图1),通过卷积块的堆叠实现对苹果叶片图像深层信息的提取,再通过全连接层整合卷积层或者池化层中具有类别区分性的局部信息,最终实现病虫害的识别分类。
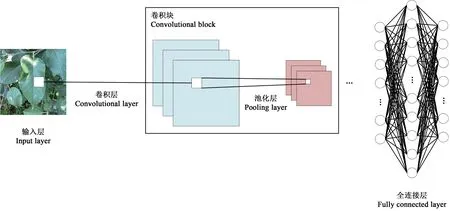
图1 卷积神经网络Fig.1 Convolutional neural network structure
近年来,国内外科研人员围绕卷积神经网络识别苹果叶片病虫害开展了大量的研究工作。邸洁等[8]将Tiny-YOLO 运用于苹果叶片病害的识别检测中,将苹果叶片病害识别检测问题转换成回归问题,并在Darenet-19 的结构基础上优化网络模型结构,使得叶片病害的识别速度和准确率都得以提升。Francis 等[9]基于内存大小与综合性能的比较,提出一种由4个卷积层与2个全连接层组成的自建神经网络,发现小尺寸神经网络在叶片病害识别中具有较好的识别精度;Zheng等[10]采用穷举试验设计方法,进一步分析索贝尔算子(Sobel operator)、数据增强、不同池化方法和不同网络结构(包含卷积核尺寸、特征图数量和卷积层的深度)对苹果叶片病害识别精度的影响,并通过对比实验找到了合适的网络用于叶片病害识别;Agarwal 等[11]针对苹果叶片病害识别提出了一种新的卷积神经网络,该网络主要由3个卷积层和3个最大池化层组成,其中还含有dropout 层用于防止过拟合,另外该模型的超参数由多次组合实验比对得出,最终所得网络模型性能优于传统机器学习模型和部分预训练的深度学习模型(VGG16、InceptionV3),并且该模型的参数和运行时间都明显低于部分预训练模型。上述研究的重要共性是在叶片病害识别任务中对于低内存与低延时的追求,高效能运算已逐渐成为该领域的研究重点。
在苹果叶片病虫害自动识别过程中发现,大多数叶片病虫害的表征以叶片斑点的形式呈现,为了高效识别叶片病害,Son等[12]提出一种新的叶片病害斑点注意网络(LSA-Net)用于叶片病害识别,如图2 所示。该研究与以往的叶片病害区域分割不同,通过FS-SubNet(feature segmentation subnetwork,特征分割子网络)和SAC-SubNet(spot-aware classification subnetwork,病害斑点区域分类子网络)组成的LSA-Net 实现对苹果叶片病害的高效准确识别,FS-SubNet将输入图像分割成背景、叶片区域和病害斑点区域,由于引入了病害斑点注意机制,使得LSA-Net 的分割网络可以专注于特定病害表征区域的特征提取。
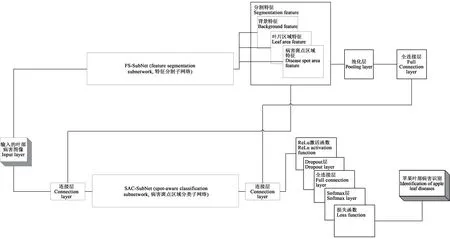
图2 用于苹果叶片病害识别的叶部病害斑点注意网络(LSA-Net)结构Fig.2 Leaf spot attention network(LSA-Net)for apple leaf disease identification
迁移学习也是苹果叶片病害识别的重要手段。Nagaraju 等[13]通过去除VGG16 最后1 层并添加1 个新的输出层,得到微调后的VGG16 网络用于叶片病害识别。得益于迁移学习的优势,使得该团队所得网络的训练参数相对于VGG16 减少了98.9%,从而减少了计算量,识别准确率到达97.87%,这对于追求高效训练网络以应对模型训练计算力不足的场景具有参考价值;同样采用VGG16 迁移学习,鲍文霞等[14]选择在VGG16 网络的瓶颈层后添加1 个选择性核(selective kernel,SK)卷积模块以提高多尺度特征提取的水平,并采用全局平均池化代替最大池化,以提高模型的收敛速度和抗过拟合能力。以上研究结果表明,运用迁移学习解决苹果叶片病害识别问题的范式思路是在有先验知识的神经网络后部进行结构优化,以提升现有网络对特定问题的处理能力。
1.2 苹果树疏花中的应用
苹果树的花果管理对于控制果树产量、保障果品质量具有重要作用,在疏花过程中运用深度学习实现目标花朵的识别与定位是该研究领域的热点。Wang等[15]在FCN8s的基础上提出了FCNs-Edge的全卷积神经网络(fully convolutional network,简称FCN),通过将另外2 个池化层与反卷积层组合,以及添加边缘类的方式提高网络的综合性能,将包含更多局部特征和低维度特征的池化层和反卷积层相连接能够强化对目标边缘的检测,因此所提出的FCNs-Edge 网络无论是在白天还是夜晚,其模型的预测精度和召回率都明显提升;Bhattarai 等[16]运用Mask R-CNN 实现苹果花朵的分割,并开展了不同数据强化方案对目标检测影响效果的对比研究。上述研究重心都在苹果花朵的目标检测上,这也是该研究领域的主流方向,但苹果树的疏花难点在于疏花策略的自动化生成,这将成为深度学习在苹果树疏花领域的新方向。
1.3 苹果树长势监测中的应用
在种植过程中,对苹果树体及果实的生长状态进行自动监测是智能化果园生产及果树管理的重要基础,将为果园的水-肥-药管理、果树修剪、产量预估等提供支撑。
果实监测是深度学习在种植监测中的主要应用。例如Mazzia 等[17]在Raspberry Pi 3 B+上部署YOLOv3-tiny 的果实长势检测模型用于苹果种植监测系统的嵌入式硬件开发,为保障硬件的运算性能,该团队采用Intel Movidius Neural Computing Stick (NCS)、Nvidia 的Jetson Nano 和Jetson AGX Xavier 为该硬件提供边缘算力支持,并且比较各种设备之间的综合性能差异,值得一提的是该团队对用于苹果检测的YOLOv3-tiny 进行了针对性优化,选取了合适的网格尺寸,优化了小目标检测的性能,整个研究对于小功耗下的苹果目标检测的边缘计算具有参考价值;Wang 等[18]基于深度学习边缘检测网络开发了果园苹果生长监测系统,用于整个生长期内的苹果大小尺寸远程监测,该团队在ResNet-50 的基础上融合了多段其所提出的融合卷积特征(fused convolutional features,FCF)来实现苹果边缘检测,此外为了实现对苹果尺寸大小的视觉度量,该团队使用区域生长的方法进行苹果与校准球的分割,整项研究对于去除复杂背景检测苹果生长的分割具有参考价值。
在苹果种植中除了果实监测外,树体监测也是重要方向,其中对于被遮挡部分的果树分割一直都是该方向的难题之一。Chen 等[19]就遮挡的果树分割问题提出了遮挡难度指数(occlusion difficulty index)和深度难度指数(depth difficulty index),并运用于U-Net 和DeepLabv3 这两种流行的语义分割模型、原始的Pix2Pix(生成式对抗网络,GAN)和优化后的Pix2Pix 之间的对比性研究,结果表明在有遮挡的苹果树体分割任务中,传统的用于无遮挡分割任务中的评价指标不能准确反映模型的性能。
1.4 苹果种类识别中的应用
随着育种技术的进步与分子生物技术的发展,苹果种类繁多,能够快速准确地识别出苹果种类对于苹果种植的精确管理具有重要意义。Liu等[20]提出了一种以苹果叶片图像为输入的深度卷积神经网络,实现了对14 种苹果种类的自动识别,平均识别准确率可达97.11%。从该研究的对比实验中可以看出,深度学习在苹果品类识别任务中具有明显优势,相比于传统的机器学习,其提出的卷积神经网络在该任务上具有较高的泛化精度、稳定的收敛性和良好的特异性。
苹果种类识别的另一大输入类型为果实图像输入。例如,为了实现对红富士、国光、红元帅、黄元帅、嘎啦和青苹果6 种苹果的种类识别,Li 等[21]提出了一种由7 个卷积层、3 个最大池化层和2 个全连接层组成的浅层卷积神经网络模型,实现了在无遮挡下92%左右的识别准确度。此外,在自然环境中存在树叶和树枝遮挡、苹果表面腐烂或被其他苹果遮挡等复杂情况,该研究引入分块投票法以提升模型的识别精度和泛化能力,并在不同程度的遮挡实验中取得了较好的效果。在与SVM、ResNet-18 和ResNet-50 等方法的对比实验中发现:上述苹果种类识别任务中ResNet-18的性能优于SVM,这说明深度学习的深层信息提取能力在图像识别任务中相对于机器学习有一定优势;但ResNet-50 的性能却低于SVM,这证明当数据集的样本量远小于深度学习模型的学习能力时必然发生过拟合;所提出的浅层卷积神经网络明显优于所有对照模型,研究结果表明在特定任务中降低深度学习模型的复杂度依然可以有效保障模型性能。
张力超等[22]基于LeNet-5 提出了一种以果实图像为输入的改进神经网络模型,以实现对红富士和红元帅这些具有相似外观的苹果种类识别。如图3 所示,改进神经网络模型在原始LeNet-5 的全连接层之前添加了展平层(flatten)用于数据的降维;将全连接层的激活函数由Sigmoid 换成了LeakyReLU,以防止反向传播时的梯度消失以及神经元出现“凋亡”的情况;在全连接层之后添加Dropout层缓解模型的过拟合以便增强泛化能力。在与SVM+HOG 和SVM+G 的对比实验中发现,提出模型的识别平均准确率和平均总耗时都显著优于SVM方法。

图3 LeNet-5模型的改进前后对比Fig.3 Comparison before and after improvement of LeNet-5
2 深度学习在苹果采摘收获中的应用
对果实进行精准、快速的识别是实现苹果自动化采摘的关键技术之一。由于自然环境下苹果果实辨识与定位受枝叶遮挡、光照强度以及高斯噪声的影响,使得苹果果实的自动化识别具有较大的难度[23]。
传统果实检测主要是依据果实的颜色、纹理和形状等特征。冯娟等[24]采用随机圆法和(RG)∕(R+G)颜色特征对230 幅苹果图像进行测试,识别准确率达92%。宋怀波等[25]利用K-means 聚类算法对苹果图像进行分割,进而获得果实边缘信息,实现果实目标的识别。刘晓洋等[26]利用改进的R-G 色差分割算法对70 幅苹果图像进行测试,识别准确率达83.7%。孙飒爽[27]利用流形排序法解决了在相似背景中青苹果识别困难的问题,测试了120 幅青苹果图像,识别准确率达90.8%。传统果实检测方法受自然环境下天气、光照强度和背景遮挡等因素的影响,难以具有通用性。
基于深度学习的苹果识别能自动提取果实的特征参数,从而避免了传统识别算法中复杂特征和数据的提取,目标识别的速度快、精度高,应用场景广阔。张亚静等[28]采用RGB颜色特征输入神经网络训练模型,利用包含1 506个苹果的图像对模型进行了测试,识别准确率达86.7%。王津京等[29]将SVM 用于苹果果实颜色和形状等特征的训练,把采集的特征信息输入到由支持向量机构成的分类器中,代替CNN中的softmax层,通过200幅图像的验证性试验测试,识别准确率可以达到93.3%。以上研究表明,使用SVM 分类器和CNN 融合的模型比单独使用K-最邻近算法的识别准确率高,可应用于采摘机器人作业过程中对果实目标的识别。
Faster R-CNN 方法可以依赖不同的CNN 架构实现快速的目标检测,因而在苹果收获采摘过程中受到广泛关注,例如Gené-Mola等[30]采用多模态Faster R-CNN 进行苹果的检测,并在其所提出的KFuji RGB-DS 数据库(其中包含了真实果园中富士苹果的多模态图像)上进行评估实验,结果表明,使用色彩与深度感知摄像头作为果实识别的传感器,能够额外获取被检测目标的空间距离,在多模态Faster R-CNN 果实识别中提升准确率,但该方法的主要限制是深度传感器的距离检测精度受光照强度影响较大;Lfabc 等[31]采用3D 体感摄像头Kinect V2 构建采摘机器人的室外机器视觉系统,并使用2 种基于Faster R-CNN 架构的ZFNet(Zeiler&Fergus Net)和VGG16 来进行对比实验,结果表明,VGG16 在给定数据集下的识别准确率更高,并且通过结合景深信息来去除不需要的背景(包括目标果树旁其他果树上的树叶和果实)能够提升2.5%的苹果识别准确率;Chu 等[32]提出了名为Suppression Mask R-CNN 的新型苹果检测模型,通过在标准的Mask R-CNN 中添加用来抑制网络生成非苹果特征的抑制分支来提升网络的检测精度,在嘎拉和Blondee苹果的综合果园数据集上进行实验发现,该方法的检测准确率高达88%,明显高于YOLO v3、Faster R-CNN 和Mask R-CNN等早期的目标检测模型。
虽然Faster R-CNN 是苹果目标检测中的主流算法之一[33],但在较看重实时性的苹果采摘收获过程中,YOLO 和SSD 等运行效率更高的深度学习算法逐渐在该领域兴起。例如Kuznetsova 等[34]使用YOLOv3 算法开发了一种用于苹果采摘收获机器人上的计算机视觉系统,通过增强对比度、采用中值滤波器进行轻微模糊、加厚检测边缘等预处理方法来减轻阴影、眩光、苹果轻微损害和薄树枝重叠苹果对YOLOv3 果实检测的负面影响,同时采用黄色像素[RGB 值为(248,228,115)]替代在图像上呈现棕色阴影[RGB值从(70,30,0)到(255,1 540,0)]的苹果上斑点、花被和细枝条的后处理方法来提升的果实识别准确率,通过上述的预处理和后处理方法能使YOLOv3 的苹果识别准确率达到92%以上;武星等[35]设计的Tiny-yolo网络,用输入和优化策略对苹果进行识别,精简了网络结构,提升了苹果识别的精确度和速度;彭红星等[36]以苹果为研究目标,将ResNet-101 网络作为SSD的目标特征提取网络,并用迁移学习微调SSD 模型,采用梯度下降法进行模型训练,辨识率为95.2%,检测速度为0.125 s·幅-1,取得了较高的识别精度和较快的识别速度。
3 深度学习在苹果产后无损检测中的应用
产后无损检测属于苹果产业链中的采后处理,随着苹果产量的逐年升高,实现大规模、自动化、高准确度的苹果品质检测和质量筛选是亟需解决的问题。深度学习在苹果外部品质检测和内部质量筛选中的应用,有望加快苹果自动化分级的进程。
3.1 外部品质检测中的应用
由GB∕T10651—2008中鲜苹果质量等级(表1)要求可知[37],基于外部品质检测的苹果产后分级指标主要包括苹果颜色、大小和完整度等。

表1 鲜苹果质量等级要求[37]Table 1 Fresh apple quality grade requirements[37]
何进荣等[38]用DXNet 模型对红富士苹果颜色、大小和果形等外观品质进行分级,与VGG16、Xception、ResNet50、DenseNet121、Inception_V3 进行比较发现该模型的性能较优,准确率可以达到97.84%。薛勇等[39]用GoogLeNet 对苹果进行表面缺陷检测,并与AleNet 和LeNet-5 网络进行对比,识别准确率最高,为91.91%,实现了小样本数据训练获得较好的分类模型。Fan 等[40]使用4 层的卷积神经网络在苹果分拣机(每秒5 个苹果的速度)上实现了苹果外部缺陷的检测,识别准确率能达到96.5%,且在每6 张苹果图像72 ms 处理时间下的验证实验中也能达到92%的识别准确率;Ohali 等[41]利用VGG16 特征提取模型对苹果按颜色、纹理等特征,将苹果分为3 个等级(1,2,3),系统的识别准确率为84.6%。Sofu等[42]利用MobileNet模型设计的苹果检测系统对3 个不同品种的苹果同时进行检测分级,以重量、大小和颜色为特征将苹果划分为不同类别,用238 个样品进行检测,分类准确率达到96.8%。
王立扬等[43]利用改进LeNet-5 对苹果按照颜色、形状及大小等指标进行分级,识别精确度达98.37%,并将模型移植到分级系统中,在实际应用中取得了良好的进展。石瑞瑶[44]用最小外接矩形法计算苹果大小,结合卷积神经网络对苹果大小进行分级,准确率为89.75%。凌强[45]利用RGB模型进行苹果颜色分选,用最小外接圆法对苹果进行大小分选,识别准确率为91.32%;用CNN 对苹果缺陷进行识别,准确率为96.89%,取得了较好的效果。
3.2 内部质量筛选中的应用
由GB∕T 10651—2008 中苹果主要品种的理化指标参考值(表2)可知[37],不同品种的苹果其果实硬度和可溶性固形物含量(soluble solid content,SSC)都有不同的推荐范围,即该品种苹果成熟时应符合的基本内在质量要求,因此对收获后的苹果进行内部质量的筛选主要是对苹果的粉质化、糖度和其他SSC进行检测,基于人工品尝和破坏性仪器测量的传统内部筛选方法不能满足苹果产后无损检测和果品快速分级的需求[46],而现阶段较为成熟的光谱分析、电特性检测、CT(computed tomography)和电子嗅觉传感器检测等无损检测方法虽然在苹果内部质量筛选中取得了广泛的运用,但模型建立过程复杂且繁琐、检测设备昂贵、针对性差等问题依然存在[47],因此深度学习技术的引入将成为该领域的研究热点。
Lashgari 等[48]提出采用声波传感技术与深度学习相结合的方式进行苹果粉质化检测,在该研究中,实验人员以塑料球作为冲击装置产生声波,并使用BSWA 设备记录穿过样本苹果的声波信号,之后利用短时傅里叶变换(short time Fourier transform,STFT)将每个声波冲击信号转换为具有纹理的频普图像来获取数据集,需要说明的是,该研究使用的苹果样本是在室温(21 ℃)、低温(6 ℃)和储藏时间的组合条件下产生的,即通过不同温度和不同储藏时间的组合诱导不同程度的苹果粉质化。最后在预训练的AlexNet 和VGGNet 上进行模型微调,结果表明,上述2 种网络在该方法下区分苹果粉质化和非粉质化的准确率能够分别达到91.11%和86.94%,并且AlexNet 的识别速度更快,该研究证明了在苹果粉质化检测中声学信号与深度学习相结合的可行性。
Bai 等[49]基于光谱指纹特征和深度学习成功地建立了具有良好可靠性和准确性的苹果SSC多元预测模型并准确检测了多个产地的苹果SSC。该团队以光谱指纹特征作为输入,通过深度学习识别苹果的种类和产地并用其搜索专属单源SSC检测模型,最终实现苹果多元SSC检测模型的性能提升,与单源和杂交源模型相比,多元模型具有更稳定且准确的检测性能,其原因在于该模型结合了种类和产地识别,以至于其能够抵抗苹果产地变化时对SSC检测产生的干扰。
除了上述单一指标内部检测外,苹果糖度和硬度的同时检测也逐渐兴起,例如徐焕良等[50]提出一种基于光子传输模拟的苹果品质检测方法。该团队为了解决样本数量不足且较难获取的问题,采用蒙特卡洛方法获取2 万张面光源下的苹果表面光亮度分布图,并用其作为样本输入到卷积神经网络中进行预训练,再以少量实测光谱苹果图像为样本使用迁移学习进行模型微调,最终实现光谱信息和光学参数信息的结合预测。结果表明,该方法对苹果糖度和硬度的检测准确率为92.22%和86.97%,都明显高于高光谱数据和光学参数数据的品种检测模型,也略高于通过迁移学习得到的点光源条件下的模型。
4 深度学习在苹果产业链中存在的问题与发展建议
本文以苹果产业链中的果树种植、收获采摘和产后检测3 个关键时期为主线,将近几年深度学习在该领域的研究进行分类总结,并着重介绍了苹果叶片病害识别、果实与树体长势监测、果实内外部无损检测等相关方向的成功案例,但该领域的研究仍然面临着困难和挑战。
4.1 深度学习在苹果产业链中的困难和挑战
专业样本数据集较少且获取难度大。深度学习对数据具有“贪婪性”[51],需要大量标注良好的数据集作为样本进行训练,在苹果种植过程中获取样本的周期较长,且在苹果的生长周期内不一定能够获取完整的数据集,以叶片病害为例,同一果园内难以完整采集系统性的病害样本,故要实现较多种类病害样本的采集就需要在同一地区的多片果园进行多年的图片采集,并且同种病害在不同阶段或不同品种上也会表现不同特征,从而提升样本标签化的难度,这些都将使深度学习在该领域的研究与应用成本陡升。
算法精度、计算开销与模型尺寸之间具有不易调和性。为了提高模型的识别精度和鲁棒性,需要模型算法能获取样本更多的深层信息和局部空间信息,实现样本向高纬度抽象性信息更有效的映射,这将增加深度学习算法模型的复杂程度,使权重矩阵变大,最直观的感受是模型的尺寸变大和模型预测的召回时间增长。在计算资源有限并且注重响应时间的边缘场景中,寻找到算法精度与模型尺寸之间的平衡点或者探索合适的模型压缩方法都是极具挑战性的任务。
4.2 深度学习在苹果产业链中的发展建议
面对数据集构建难度大、构建周期长的问题,可以从以下3 个方面探讨解决思路:一是需要高校与研究机构牵头,组建公共的、开源的大型苹果果园数据集,弥补各研究团队在数据集构建上的资源不足或不均的问题;二是优化样本预处理方案,对获取的样本进行合适的预处理,减小样本噪声、突出样本的特性,使所用样本具有良好的特征代表性;三是探索合理且有效的数据增广策略,实现在从有限的数据中提炼出更多有用的信息从而产生等价于更多数据的价值[52]。
对于大模型的使用,可以考虑压缩模型尺寸和增大边缘计算能力的2 条研究路线:一是可以考虑模型剪枝、知识蒸馏、网络量化等模型压缩与计算加速策略[53-54],实现在精度影响可接受范围内(或模型压缩后再微调网络)的模型尺寸优化,从而减小计算开销;二是可以考虑匹配合适边缘计算能力,例如NVIDIA的Jetson系列、Intel 的Movidius Myriad X 等先进的边缘算力,可以为不同尺寸的模型部署提供合适的选择。
5 展望
深度学习在图像领域取的成功使得研究者们热衷于用其解决各行各业中的难题,尽管现阶段深度学习在苹果产业链中的优势与挑战共存,但这并不妨碍深度学习在该领域会取得进一步的发展,因此,作如下展望。
①将深度学习运用于更多的苹果产业链环节中。现阶段的深度学习主要集中在果树种植、采摘收获和产后检测中,未来应该继续探索在木苗繁育、果汁加工和销售运输中的深度学习应用,最终实现苹果全产业链的深度学习应用落地。
②多信息融合促进模型综合能力提升。目前深度学习多以机器视觉为载体,未来的研究应采用更加多元的信息进行融合,例如机器嗅觉、机器触觉以及天气信息等,数据种类的增多固然会提高模型的训练难度,但多源信息的融合会使深度学习在苹果产业链的应用中创造更多的可能性,使得深度学习对于该行业的技术革新产生更大助力。
③完整数据链推动果园的智慧化管理。之前的研究多注重于单一领域或单一阶段,未能聚焦苹果产业链的全数据,若能尝试将深度学习运用于全数据链(例如苹果从木苗选育到苹果销售之间的所有数据),这将对苹果果园的智慧管理产生重大影响。
猜你喜欢
今日农业(2022年3期)2022-06-05
今日农业(2021年8期)2021-11-28
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
烟台果树(2021年2期)2021-07-21
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
今日农业(2020年19期)2020-11-06
