
语音特征参数提取算法的研究与硬件实现
2022-12-01 06:00刘泽琛焦继业崔智恒安超
电子设计工程 2022年23期
刘泽琛,焦继业,崔智恒,安超
(1.西安邮电大学电子工程学院,陕西 西安 710121;2.西安邮电大学计算机学院,陕西 西安 710121)
在离线语音产品中,由于其系统脱离了云端的服务器,语音模板库的训练只能通过自身系统来建立[1],所以合理的使用人体模型作为参考,选用合适的语音特征参数对于语音识别系统非常重要[2],也是离线语音识别技术的研究重点[3]。对于离线语音识别产品,不是越先进的算法就越适用[4],需合理地选用算法结构和运算以达到提取特征参数的效果[5],既可以降低系统的成本又可以很快地应用到产品中去[6]。该文面向离线语音产品的设计,对MFCC 参数的提取阶段进行了重点学习和研究,使用合理的算法结构来降低系统运算成本,并针对软件实现MFCC 参数提取过程中产生的大量且重复性计算问题,对MFCC 参数的提取进行了算法优化设计,并给出硬件设计方案以提高运算效率。
1 MFCC原理分析
MFCC 参数由Davis[7]等人在二十世纪八十年代提出,具有良好的识别性能和抗噪能力[8-9]。MFCC参数的提取过程充分考虑了人耳听觉特性,而且没有任何前提假设[10],该参数通过将线性频谱转换到Mel 频谱中,再将信号的对数能量转换在倒谱上而得到。MFCC 特征参数提取流程如图1 所示。
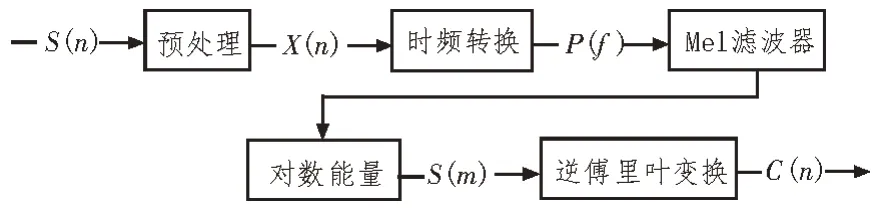
图1 MFCC参数提取流程图
1)语音信号在经过预处理(预加重、分帧、加窗)后变为短时信号,使用傅里叶变换将这些时域信号X(n)转化为频域信号X(m),并由此计算它的短时能量谱P(f)。

2)求出的每一帧能量谱P(f)通过Mel 滤波器,计算在该Mel 滤波器中的能量。在频域中相当于把每帧的能量谱P(f)与Mel 滤波器的频域响应Hm(k)相乘并相加,最后求其对数能量S(m)。
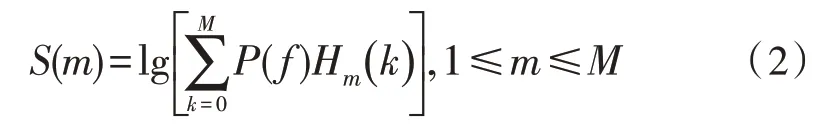
式中,k表示第k个滤波器,M表示滤波器总个数。
3)S(m)表示第k个滤波器的输出能量,则C(n)为输出的MFCC 参数。
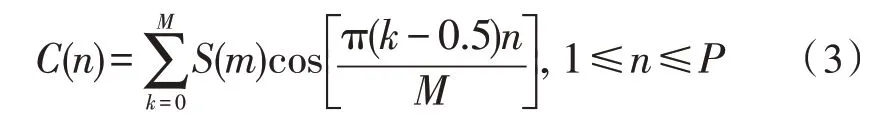
式中,P为MFCC 参数的阶数。
2 算法优化设计
2.1 语音时频转换设计与优化
在时域上,提取出语音信号的信息特征非常困难[11],通常会把时域的语音信号转换至频域上来分析,该设计采用快速傅里叶变换FFT 进行时频转换,作为离散傅里叶变换DFT 的快速算法,其函数表达式如下:

其中,原始的语音信号表示为x(n)。在该设计中,由于语音信号都是实数计算,所以直接将x(n)作为一个虚部为0 的复数序列进行计算。
但是在语音分帧时相邻帧之间需要相互重叠来弥补加窗时的信号消弱,相邻两帧起始位置的时间间隔就是帧移[12],在本设计中让帧移等于帧长的一半,也就是每相邻的两帧语音信号就会重叠50%,以此保证语音信号的连续性[13-14]。由于语音信号有50%的帧重叠段,所以在对语音信号做FFT 计算时,每两帧信号就会产生一次重复计算,但是两帧重叠部分的计算结果是相同的。为了节省运算时间,该设计提出优化的时频转换方法,重复利用这半帧的数据,节省了FFT 计算时间。假设一帧语音信号中有样本点N,并且带有50%的帧移,每帧的计算公式可用式(5)表示:
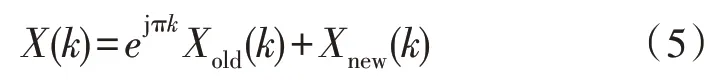
其中,k=0,1,…,N-1,Xold(k)和Xnew(k) 又都可以用式(6)表示:

在计算过程中,Xold(k) 就是在帧移N/2 的基础上,上一帧语音信号计算过的后半重叠部分,Xnew(k)是在帧移N/2 的基础上,下一帧语音信号计算过的前半重叠部分,又将在下一帧计算中变为Xold(k)。使用Matlab 对改进后的优化设计与直接进行时频转换的结果进行了比较,输出结果相同。在此算法改进的基础上,下文给出了硬件结构图,避免了由于帧移而产生的重复计算,进而节省了运算时间。
2.2 MFCC参数输出设计与优化
该设计使用一组三角形滤波器形成滤波器组,为了更好地提取出语音低频信息,这些滤波器在频率坐标轴上不是均匀分布的,在低频区域有很多的滤波器,它们分布比较密集,但在高频区域,滤波器的数目就变得比较少,分布很稀疏。此过程中,滤波器参数的计算过程复杂,如果每次都直接计算,会存在很大的计算量。通过分析算法可知,滤波器中心频率f(m)、对应的线性频率f和线性频率对应的FFT点数等参数的计算都可以脱离中间参数进行提前计算。该设计的每一个三角滤波器的中心频率f(m)可以使用式(7)进行转换,假设在采样率为fs的情况下,语音经过N点FFT 计算之后得到三角滤波器中心频率f(m)的计算公式为:
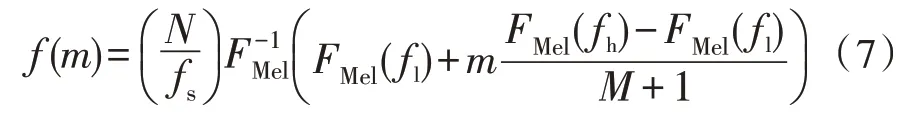
其中,fl为滤波器频率范围的最低频率;fh为滤波器频率范围的最高频率;N为FFT 时的长度;fs为采样频率。fMel函数为:

根据式(8)可以得出最大的Mel频率为2 146 mel,由于在Mel 频率刻度范围内,各个滤波器的中心频率是相等间隔的线性分布。由此可以计算出两个相邻三角滤波器中心频率的间距为ΔMel=fmax/(k+1)=93.3 mel。各三角滤波器在Mel频率刻度的中心频率可以由Mel频率与线性频率的关系式求出,由中心频率计算出对应的线性刻度的频率。该设计中Mel 滤波器共有24 组,FFT 计算点数为256,所以此过程的计算,提前使用Matlab 工具计算产生24×128 的bank系数矩阵,将bank 系数矩阵存入系统中,需要时直接读取使用,大幅减少了计算量和时间。同时该设计采用DCT 进行傅里叶逆变换,输出12 阶的MFCC 参数,式(3)为DCT 变换公式。由于这部分计算大多是重复性计算,而且三角函数的计算会引入CORDIC 算法,使得MFCC 参数的输出精度变低,准确性将被影响,所以可以提前计算好nπ/M、(m-0.5)、余弦值等参数,产生一个12×24 的DCT 的变换系数矩阵,将DCT 的变换系数矩阵存入系统,使用时直接读取。
3 硬件设计实现
语音特征参数提取阶段系统的硬件实现流程框图如图2所示。整个语音特征参数提取系统分为定点计算部分和浮点计算部分,原始语音信号使用Matlab将wav格式文件转换为coe格式文件,保存在原始语音存储ROM 中。语音特征参数提取系统先从原始语音数据存储的ROM 中读取出一帧的音频数据传送给预加重模块,然后开始计算该帧数据的MFCC 参数。等待该帧的MFCC 参数计算结束后,再读取下一帧音频数据,以此类推,直到检测完语音最后一帧数据为止。将处理后得到的MFCC 参数使用在线抓取的方式存储于ILA 中,然后导出至本地文件。

图2 硬件实现流程框图
3.1 顶层控制模块设计
输入语音信号以后,进行语音信号预处理,语音被分为很多帧数据等待处理。该设计中一段语音的MFCC 参数计算是以帧为单位进行的,计算每帧信号会产生12 个特征参数,测试语音共127 帧数据,使用全局状态机进行控制。如图3 所示,特征参数提取模块空闲状态为IDLE 状态,等待触发起始条件进行数据处理。

图3 全局状态机转移图
当启动计算信号Start 有效时,由IDLE 状态进入COMUTEMFCC 状态,开始对第一帧数据的MFCC 进行计算。当第一帧数据计算完成时,将计算结果存储在FIFO 中等待COMPUTEEND 状态对其数据进行读取,当触发计算结束的信号MFCC_ValidEnd 有效时,模块进入COMPUTETAP 状态,对部分相关的变量进行复位,取数地址减128,这个位置就是前一帧数据地址的中间位置,这样进行取地址操作,就可以实现两帧数据重叠50%。Cnt计数至127时,127帧数据的MFCC 全部计算完成,模块进入COMPUTEEND状态,对COMUTEMFCC 状态下存储在FIFO 中的MFCC 参数进行读取,Cnt1 计数到1 525,证明127 帧数据的MFCC 系数被全部读取完成,读取结束后系统回到IDLE 状态等待Start信号再次启动计算。
3.2 时频转换模块设计
时频转换模块的硬件设计结构图如图4 所示。
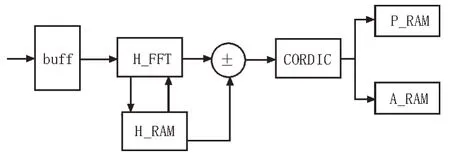
图4 时频转换模块
当语音信号进入到输入缓冲区buff 后,语音数据被分为N/2 个采样样本,每两个连续语言段将形成一个重叠帧,每一段语音帧都要经过式(6)的计算,然后将当前语音段的计算结果Xnew(k)又存储在输入缓冲区H_RAM 中的K 地址处(又在下一帧计算中被重新用作Xold(k),同时Xold(k)在输入缓冲区H_RAM 中的K 地址被读取,并与Xnew(k)又一起产生如式(5)所示的当前帧的快速傅里叶变换结果。经过FFT 之后,产生的数据格式是复数,为了给FFT 产生的频谱求模值,该设计使用CORDIC 算法计算复数模值,使用简单的移位,加减操作减少计算量。
3.3 MFCC参数输出模块设计
该模块用于实现MFCC 参数的输出并通过状态机来控制。CORDIC 算法计算结束之后,使用全浮点运算来提升运算精确度。该模块可以分为缓存模块和计算模块两个部分,缓存模块部分包括常数的存储和计算结果的缓存。Mel 滤波器的中心频率、对应的线性频率和特征提取流程中的中间参数可脱离中间参数,提前使用Matlab 工具计算并产生bank 系数矩阵,将bank 系数矩阵存放在Mel 滤波器组参数ROM 中,等待计算时直接提取。再将离散余弦变换中的DCT 系数矩阵存入bank ROM 等待使用。该模块MFCC 参数的输出计算使用如图5 所示。
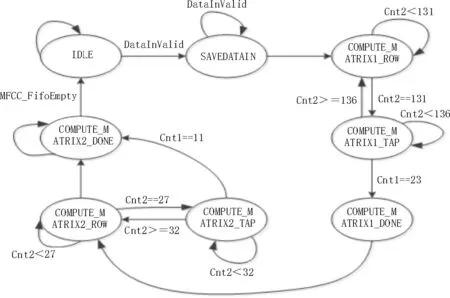
图5 该模块状态机转移图
具体计算实现的过程:将待处理的功率数据向量t存储于ROM 中。bank 系数矩阵中每一行向量都要与t向量相乘,即128 个元素的相乘再相加的运算。按顺序每次读取bank ROM 的128 个数和t进行乘累加运算,得到一个数,对bank ROM 中所有数计算完后,即完成bank 系数矩阵和t向量的相乘,就会得到24 个数,分别对其取自然对数后存于RAM 中。同理,计算DCT 的变换系数矩阵和自然对数向量的乘积向量c1;不同之处在于每得到c1 的一个元素,就利用浮点乘法器计算其与对应归一化倒谱提升窗口w元素的乘积,然后存于MFCC_FIFO 中。
4 实验与结果分析
4.1 准确率测试
该设计在使用Matlab 测试之前,提前录制好一段测试语音,保存为wav 格式,等待测试时使用,测试时使用Matlab 工具直接读取wav 格式的语音数据进行处理,测试所使用的语音时长为2 s,共有127帧,每帧经过特征参数提取系统都会产生一组12 阶的MFCC 参数,从而形成一个12×127 的MFCC 参数矩阵,将其作为语音特征参数矩阵,以便语音识别阶段使用,测试使用Matlab 和Vivado 分别对测试语音的MFCC参数矩阵输出进行仿真,波形结果如图6所示。
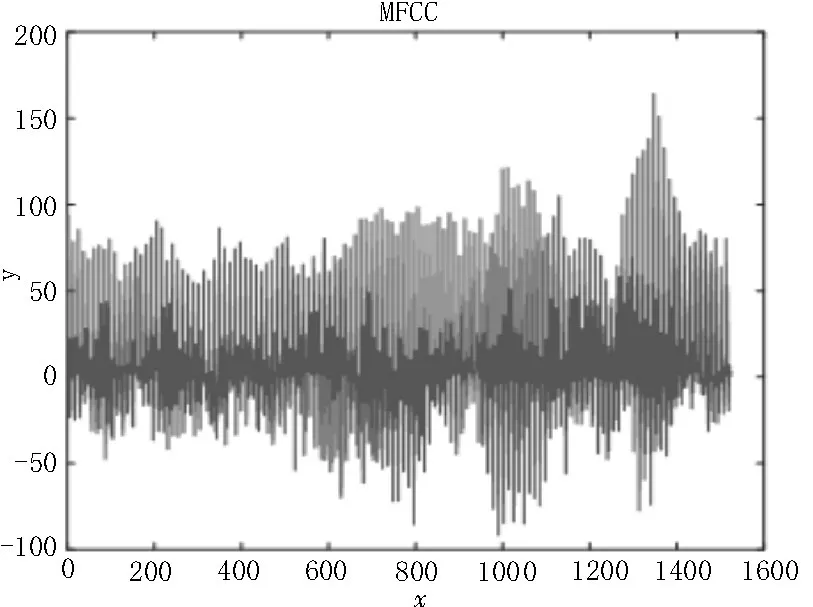
图6 特征参数矩阵Matlab仿真图
将bit 文件下载至FPGA 开发板。随机选取一帧语音的12 阶MFCC 参数,将该帧的Matlab 仿真计算结果与ILA 抓取到的MFCC 参数做对比,数据结果显示平均误差仅为0.92%,可以满足设计的准确率要求,数据结果如表1 所示。
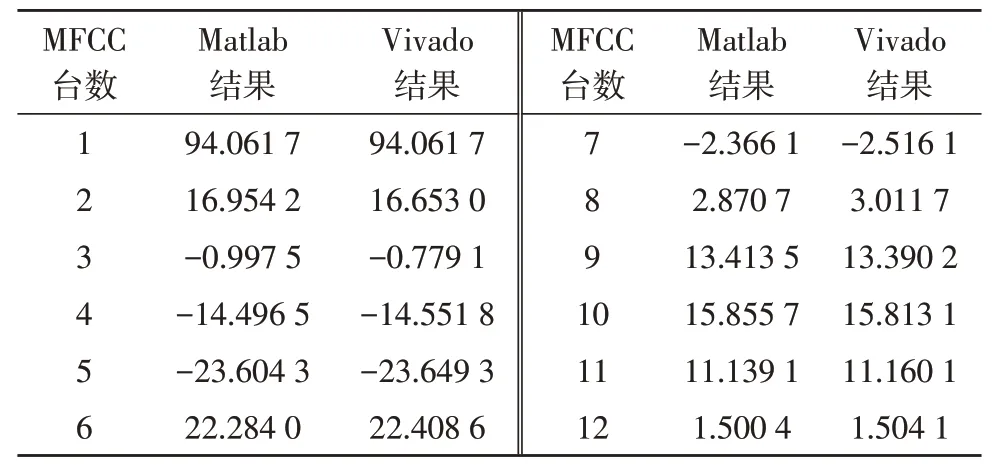
表1 误差对比表
4.2 实时性测试
测试使用的示例语音总计127 帧数据,每当系统计算出一帧语音数据的MFCC 参数,MFCC_ValidEnd标志位信号就有效一次,语音有效次数为127 次,总计提取出127 帧语音信号的MFCC 参数,总计用时为22.71 ms,该设计中特征参数提取模块计算一帧MFCC 参数的时间为0.18 ms。
文中对MFCC参数提取系统的性能参数进行了对比,性能参数对比如表2 所示。相较于ARM Cortex-M4、TMS320 DSP 平台使用软件实现MFCC 参数提取,该设计采用硬件设计进行语音特征参数提取加速,在运行速度上有了大幅度提升,提取一帧语音数据的MFCC 参数运算速度分别提升了51 倍和67 倍。相较于其他硬件实现方案,该设计在时频转换模块,节省了FFT 的重复计算并将MFCC 输出阶段做了优化,将Mel 滤波器和DCT 计算的相关参数脱离系统计算形成稀疏矩阵,保存在参数ROM 中,供直接访存使用,省去每次计算的耗时,较少硬件资源利用率,换来了计算速度近3 倍的提升,系统功耗也得到了降低,可以满足实时性较高的离线语音识别产品设计要求。
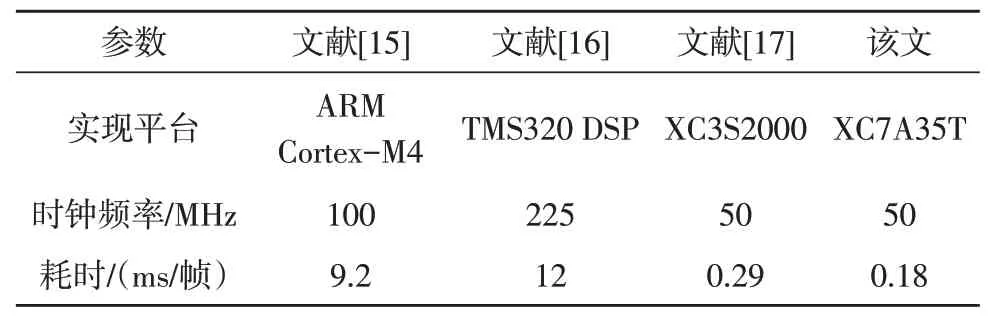
表2 性能参数对比表
5 结论
该文提出优化的语音MFCC 参数提取方案,节省了由于帧移而产生的FFT 重复计算,同时省去了Mel 滤波器和DCT 计算带来的耗时,平均误差为0.92%,提取一帧MFCC 参数的耗时为0.18 ms,可以满足离线语音识别产品设计的实时性要求。
猜你喜欢
舰船科学技术(2022年10期)2022-06-17
杭州电子科技大学学报(自然科学版)(2020年6期)2020-12-03
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年11期)2019-07-04
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
电子制作(2018年16期)2018-09-26
电子制作(2018年1期)2018-04-04
