
反向梯度深度学习下重复网络数据标注仿真
2022-11-29 13:24:28庞家乐
计算机仿真 2022年10期
庞家乐,张 彦
(北京交通大学,北京 100044)
1 引言
在信息的录入与集成过程中,若含有冗余、异常等属性的数据没有及时被处理,直接影响数据后续处理的准确性。数据清洗作为一种应用非常广泛的、能提高数据质量的方法之一,清洗对象主要以重复数据为主,包括缺失数据、重复数据以及乱码数据等。其中,由于多数据融合而产生的重复数据是数据清洗的重点。标注重复网络数据,一方面可以去除掉空间内重复存储的数据集或者文件,优化存储空间;同时也可以降低网络传输压力,为数据复制节省了部分网络带宽。目前,数据清洗技术已经非常成熟,但如何精准标注网络重复数据仍是相关领域学者的重点分析难题。
文献[1]通过无线传感网络的应用坐标系对数据重新配置,根据配置结果选择其中存在的重复数据节点;然后,计算各个协议点的覆盖面积大小,利用分类数据初始化的方法,使得各个协议点之间实现有效连接,完成无线传感网络重复数据的优化检测。该方法未考虑数据属性和唯一IP之间的关系,检测标记效率过低,对于大规模的数据并不适合;文献[2]提出利用多通道卷积机制,自动化提取和处理公式图片内特征向量,使标记过程更能适应大规模的公式数量;将卷积神经网络的输出模式设置为端到端,降低因步骤过多而出现误差累积的几率;最后,将重复数据检测问题量化为对重复公式的检测,实现冗余数据标记。该方法对于不同质量的公式图片均能实现重复性检测,但是该方法的标注准确率较低。
基于此,本文基于反向梯度深度学习算法,提出一种新的重复网络数据标注方法。首先,利用综合加权法,检测数据库中的重复数据,再利用三区分快速算法对相似度过高的重复数据标注。仿真结果也表明,本文方法具有非常理想的标注效果,与其它方法相比,可在成本最低的前提下实现最高效率的检测与标注。
2 重复网络数据检测
2.1 数据字符串编辑距离的计算
本文利用综合加权法计算各个数据的属性权重值[3],对每个数据字符串之间的编辑距离重新定义[4],得到数据与数据距离之间相似度值。实现过程如下所示:
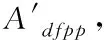
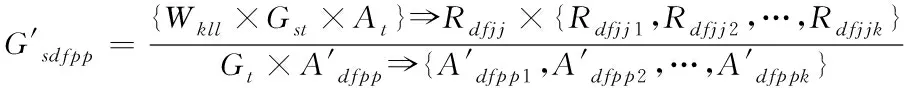
(1)
式中,Gst表示第s个操作者对属性At设定的等级,Gt表示第t个属性的最终统一等级。
通过式(2)计算数据属性取值种数,减少数据因属性取值不同而出现计算复杂情况,在一定程度上提高算法的整体计算效率。
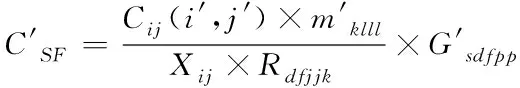
(2)
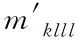
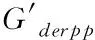
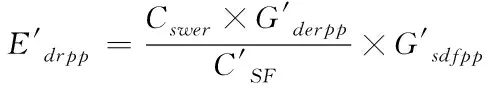
(3)
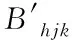
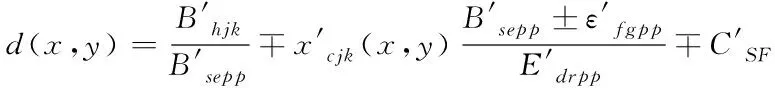
(4)
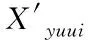
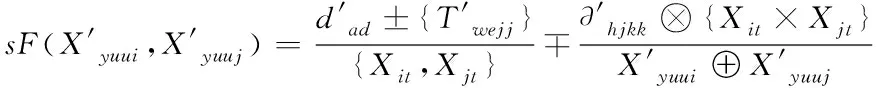
(5)

综上所述,网络中的重复数据利用综合加权法计算各个数据属性的权重值后,重新定义每个数据字符串之间的编辑距离,得到各个数据距离之间的相似度值,为后续进行重复数据的检测做好准备工作。
2.2 重复数据检测
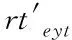
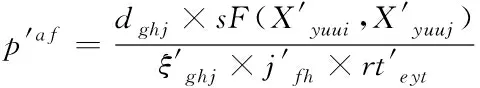
(6)

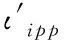
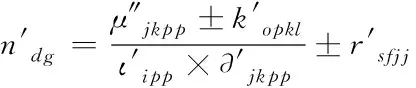
(7)
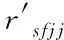
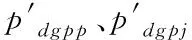
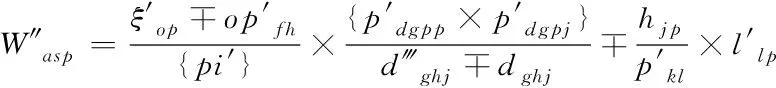
(8)
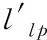
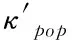
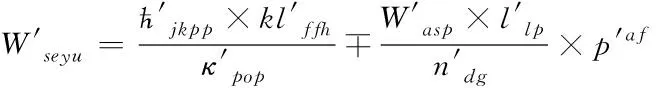
(9)
3 反向梯度深度学习下重复网络数据标注
在实际的应用网络中,流动数据量是非常巨大的,要对所有数据逐一检测和重复数据标记是非常困难的。因此,本文引入反向梯度学习算法,实现过程如下所示:
1)由于网络数据库中记录的数据并不只有一个关键字,所以可以通过设置ID编号形式对其重新设定[9]。ID编号的权重值为0,不影响后续的计算过程中,可忽略不计。
2)建立数据关系记录属性表。遍历所有数据,根据数据的属性建立不同的属性记录库,在属性记录库中根据每个属性建立属性值记录表。该表中记录了各个数据不同的属性值,以及属性值相同的数据信息。这里所做的工作与倒排索引的思想类似,将“单词”与“文本”按照倒排索引链表的结构进行排列,其中的记录就用ID编号来表示。
3)将数据记录设定为R={R1,R2,…,Rl},用l来表示数据记录的数量,与之对应的某个数据记录为Ri(1≤i≤l)。这两个数据记录的任意一个属性p间关系用公式表示为:
M=A(Rip,Rjp)={0,1}(1≤i≤l,1≤j≤l,1≤p≤n)
(10)
式中,Rip=(ID1,ID2,…,IDm),IDm表示某个数据属性值出现相似或重复的记录次数,n表示任意一个数据记录具有n个属性值的长度值,p表示某个属性的第p个属性值。
当M=1时,可以判定这两个数据记录在p属性下具有非常相似甚至重复部分;当M=0时,则可以判定这两个数据在p属性下相似程度较低、不存在重复的情况。按照这种思路,对数据库中的所有数据在某属性下进行计算比较。经过比较,还可以得到数据记录属性值的具体值。对数据记录之间的相似度定义过程如(11)所示
Qi,j,p=M*Wp
(11)

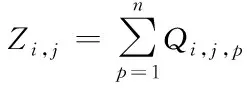
(12)
式中,Zi,j表示数据记录i与数据记录j之间的相似程度高低。
4)给定相似阈值U,用来判定二者之间是否存在重复。
Zi,j≫U
(13)
5)在比较属性值记录表中的数据属性时,如果按照顺序逐个比较会花费大量的时间。因此,本文引入快速排序算法,按照从大到小的顺序排列,当出现了相等的两个属性值后,把该数据挑选出来,后续不再进行比较,减少计算时间。本文采用的是三区间比较方法,使得挑选出来的数据不再进行排列比较,只允许大于或者小于选定的数再进行排列比较。假设选定的数值为x,那么只针对大于x或者小于x的数值进行排列比较即可,如图1所示。
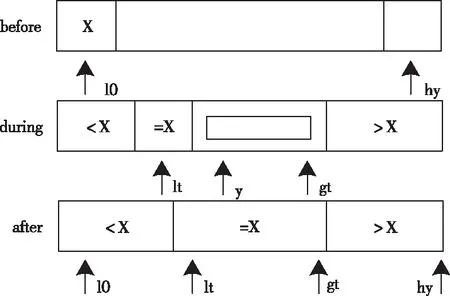
图1 三区间数值排序示意图
从图1中可以看出,按照从左到右的扫描顺序,指针lt始终保持[lo…lt]中的数字比x小,其它指针gt保持[g(t+1)…hy]中的数字比x大,指针y保持[lt…(y-1)]中的数字与x相等。[y…gt]之间的数字表示没有进行排列比较的数字,y从lo处开始进行扫描:
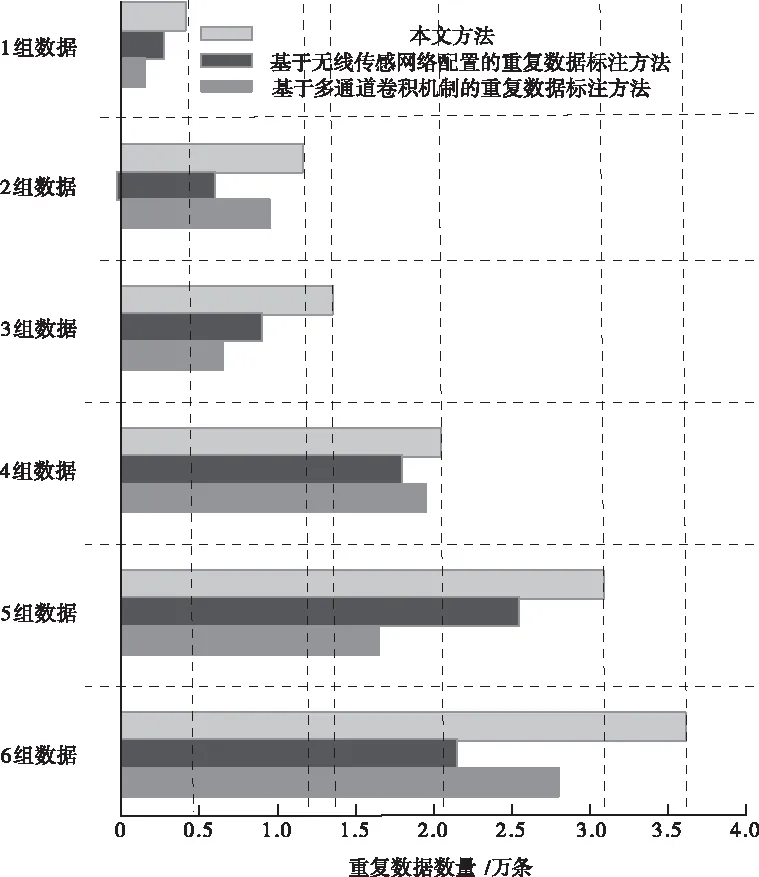
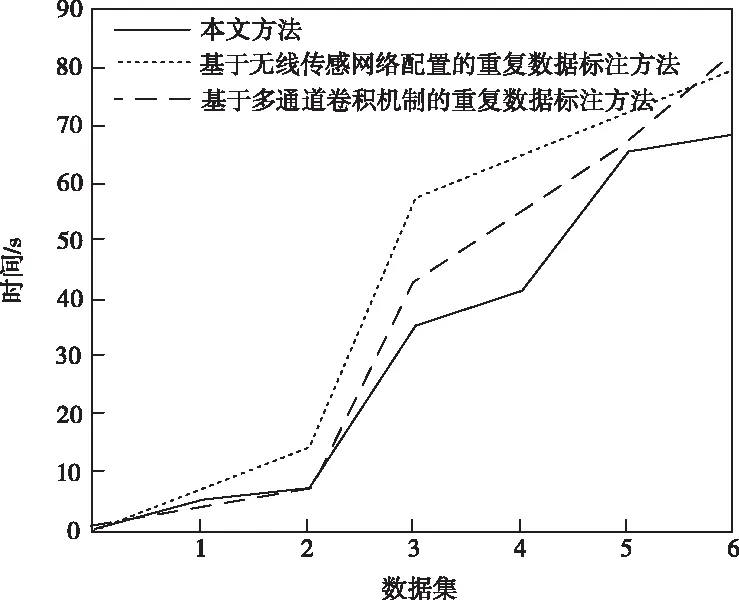
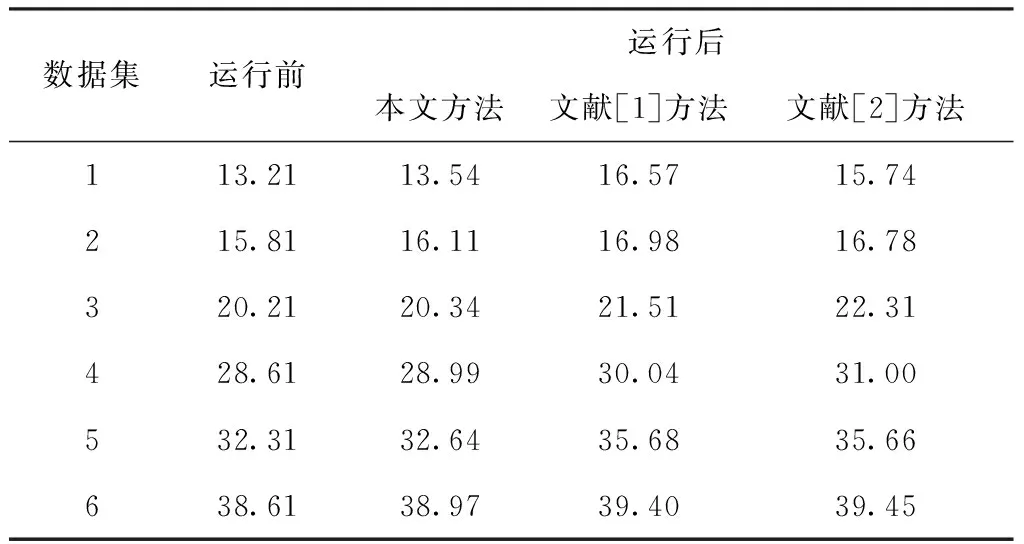
当a[y] 当a[y]>v时,交换a[y]和a[gt],gt指针会出现自减的情况; 当a[y]=v时,y指针出现自增的情况。 1)为网络数据库中的数据记录设置唯一的ID编号,同时构建属性记录库,在记录库中为每个属性设置专属的属性值记录表。 2)为数据库中的每个数据都构建一个单独的属性值记录表,将数据的属性值与ID编号存入到数据库中,形成数据关系表,后续进行排列与比较时直接参考该表即可。 3)完成以上操作后,根据属性值记录表和数据关系表,从属性记录库中挑选数据,利用三区分快速算法按照数据属性值从大到小的顺序排列,与读取的属性值比较,以此来判断数据之间是否存在相似度过高或者重复的情况。 当出现相似度过高或者重复的情况时,用相应的权重值乘以1,挑选出来,当相似度过低时,结果直接等于0,不做任何计算。 将数据记录与属性值记录表中的数据逐一进行比较,最后的比较结果整合为数据之间的相似度值。 4)根据上述数据之间的相似度值以及预先设定的阈值大小,来判断数据之间是否存在相似度过高或者重复的情况。 5)当网络数据库中录入了新的数据后,重复以上操作步骤,实现新数据与数据库内其它数据之间的相似度比较,以此实现对相似度过高或者重复数据的有效检测与标注。 仿真用到的计算机为Inter 133702.40GHzCPU,编程选择的是JAVA语言。实验中用到是Oraclellg数据库中随机选取的6组数据,6组数据的数据量分别为45.6万、53.6万、184.7万、207.9万、294.5万、315.5万,运用相关技术对数据进行处理,使其分别包含0.48万、1.21万、1.35万、2.15万、3.12万、3.66万条重复数据。为了进一步验证本文方法的性能,与文献[1]提出的基于无线传感网络配置的重复数据标注方法以及文献[2]提出的基于多通道卷积机制的重复数据标注方法展开了对比实验。 将本文方法与其它两种方法在重复数据检测与标注数量方面进行对比实验,实验结果如图2所示。 图2 三种方法重复数据检测与标注数量对比 从图2中可以看出,当面对数据量跨度较大的数据集时,本文方法始终展现出了较高的检测精度与标注能力。文献两种算法检测精度波动起伏较大,且偏离正确值较远。这是由于这两种方法没有对数据记录的属性计算赋值,只考虑了主观因素,而没有将客观因素考虑在内,由此导致了较大的误差。而本文方法可以深入挖掘数据之间的内在联系,对相似度过高或者重复的数据可以实现精准的检测与标注。 接下来利用三种方法从检测与标注所需时间方面展开对比仿真,结果如图3所示。 图3 三种方法检测与标注所需时间对比 从图3中可以看出,本文方法检测与标注所花费的时间最少,并且随着数据量的不断增加,文献方法所花费的时间增长幅度越来越大。这是由于本文方法在进行重复数据检测与标注的同时,利用三区分快速算法,将已经完成比较的数据不再重复计算,只针对大于或小于特定数值的数据进行排列比较,在一定程度上提高了算法整体的运算效率。 接下来对三种算法在进行重复数据的检测与标注时,本地服务器吞吐量情况进行对比,实验结果如图4所示。 图4 三种方法本地服务器吞吐量对比 从图4中可以看出,三种方法中本文方法本地服务器吞吐量下降幅度最大,说明运用本文方法不会对服务器性能产生较大的影响。其它两种方法均占用了大量的本地服务器存储空间。这是由于本文方法将经过比较的数据挑选出来,不再重复进行计算,在提高了算法计算效率的同时减少了计算成本。 本地服务器CPU占用情况如表1所示。 表1 本地服务器CPU占用情况对比/% 从表1中可以看出,相较于其它两种方法来说,运行本文方法占用的CPU内存最少。这说明在运行本文方法时,对服务器内其它程序的运行不会产生较大的影响。 本文利用反向梯度深度学习算法实现对网络数据库中重复数据的检测与标注,并与无线传感网络和深度卷积神经网络两种方法展开对比实验,结果表明本文方法可以在花费时间最少的前提下可实现最高精度的检测与标注,并且不限制数据集中数据量的多少。4 算法实现步骤
5 仿真研究
5.1 仿真环境
5.2 重复数据检测与标注数量对比
5.3 重复数据检测与标注时间对比
5.4 本地服务器吞吐量及CPU占用率对比

6 结论
猜你喜欢
太空探索(2022年6期)2022-06-23 06:25:26
太空探索(2022年3期)2022-03-28 08:21:52
太空探索(2021年3期)2021-03-19 09:14:00
太空探索(2020年9期)2020-09-16 10:56:16
铁道通信信号(2019年9期)2019-11-25 01:44:58
财经(2017年2期)2017-03-10 14:35:35
知识产权(2016年8期)2016-12-01 07:01:13
网络空间安全(2016年3期)2016-06-15 20:27:10
财经(2016年15期)2016-06-03 07:38:02
财经(2016年3期)2016-03-07 07:44:46
