
改进机器学习的软件多类漏洞并行挖掘分析
2022-11-29 13:25冯莹莹
计算机仿真 2022年10期
董 健,冯莹莹
(1. 郑州科技学院信息工程学院,河南 郑州 450064;2. 阜阳师范大学信息工程学院,安徽 阜阳 236041)
1 引言
软件作为一种计算机语言和命令的集合组织,常规情况可分为三种:系统软件、应用软件和处于二者之间的中间件[1]。现阶段计算机普及和发展离不开软件的支持,其安全性和可用性对系统和用户来说是极为重要的,若软件内存在缺陷或漏洞,当非法者进行异常操作攻击授权访问模块时,系统可用性和内部信息机密性会大幅度降低,并产生连锁反应,严重会导致应用网络瘫痪[2]。缺陷或漏洞被总称为软件脆弱性[3],软件开发人员为提高其稳定程度,研究得出一系列严格安全设计准则和操作流程[4],但软件本身组织程序就复杂,在多源应用环境中,漏洞总能从开发人员从未考虑的角度或维度涌出,严重威胁网络系统安全。
为此相关人员提出如下解决方法,例如胡建伟[5]等人提出了一种改进ASTNN网络的PHP代码漏洞挖掘方法。针对漏洞挖掘规则单一问题,通过抽象语法树深度分析软件编码语义,利用子树分类,将分类结果输入至深度神经网络中层层迭代输出挖掘结果;惠子青[6]等人提出了一种动态加权组合神经网络模型的软件测试方法。针对软件程序的多样性,设置动态加权组合模型,明确不同类型软件漏洞所占比重,动态调节神经网络网络输出结果,具有更好的泛化性能。但是这两种方法均过于遵循全面挖掘规则,面对大规模软件系统时系统开销过大,难以实现多个软件并行挖掘。
为此,本文引入机器学习算法,在海量数据中学习软件编程规则,使漏洞挖掘方法能够利用已有规则进行自决策、分类和全局预测,组建漏洞信息资源库,最后根据欧式距离完成多类漏洞的并行挖掘工作。
2 软件漏洞等级和类型
若软件存在漏洞则表示软件系统不再可靠,所能产生的后果为:软件错误,一般由在开发软件过程中产生的人为错误引起;软件差错,描述软件运行结果和设想结果不一致;软件失效,表示软件的部分或全部应用功能无法实现。
这些都会导致软件无法正常运行,降低用户体验。但目前学术界并没有统一定义能完全划分多类漏洞,且软件漏洞本身也跟随科技发展不断变化和细分,常用划分等级和类型如表1所示。

表1 常用软件漏洞等级和类型明细
为此,本文综合表1观点,从软件漏洞的表象和本质出发[7],定义基于机器学习的软件多类漏洞并行挖掘主要面向影响安全使用的部分,且该漏洞能够被非法者攻击和利用,导致系统机密性和用户隐私受到威胁,产生严重非预期危害。以设计、开发、运行角度将软件多类漏洞分为:
1)软件设计漏洞,是指发开人员在软件生成和组织过程中,未考虑到某部分规则或者从错误角度出发建立的规则,而形成的漏洞。
2)软件编码漏洞,是指编码人员撰写程序不规范、逻辑错误引发的安全漏洞,进一步可分为:打破内存漏洞,描述用户能非预期进行访问、执行权限不足的操作页面等行为;混乱逻辑漏洞[8],描述编码存在问题,程序没有按照指令进行工作,部分安全机制和权限被绕过。
3)软件配置漏洞,是指由于存在危险内在配置文件、外在不良硬件环境引发的安全漏洞。攻击者可远距离非法访问和攻击用户隐私信息,导致机密数据被泄露。
3 软件数据归一化处理
基于软件漏洞等级和类型可知,软件多类漏洞定义是抽象意义上的值,无法作为量化数据输入至机器学习算法中进行并行挖掘,为此,采集已有多类漏洞数据集,按序列映射到特征向量空间,明确不同类漏洞对应的属性特征值。考虑到不同开发和编码人员思想和行为的多样性[9],将海量漏洞中代码函数、参数、目标变量等信息进行归一化预处理,凭借统一格式方便计算。
首先过滤样本数据集合中与软件漏洞无联系的非ASⅡ字节,将代码函数、参数、目标变量等信息一一映射到符号名称中,统一编码命名[10,11],经过归一化处理后,投影到特征向量空间中。通过自然文本语言量化不同类型漏洞中关键区域出现频率,即可得到对应特征值。
假设通过扫描系统得到任意软件X存在的代码函数序列为X={x1,x2,…,xn},对应任意源代码文件的关键节点的结合表示为A,且能够组建X词典A={a1,a2,…,am},n、m均表示不为0的整数。映射过程表示为
ψ(x)=λ(x,a)·υa,A
(1)

(2)
式中,υa,A表示逆文档的术语频率参数,可消除一部分软件漏洞序列的相似度,降低非发生漏洞的关键节点对漏洞特征提取影响。计算公式为
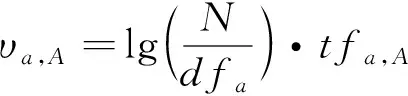
(3)
式中,dfa表示为节点a出现的文件次数,tfa,A描述在集合A中出现次数dfa与节点总数之间的比值。
4 算法设计
4.1 基于机器学习的软件特征分类
以软件漏洞信息的归一化处理结果为基础,引入机器学习,完成软件数据特征的分类。软件数据涵盖了漏洞并行挖掘所需全部信息,但软件编程复杂、信息维度高,为提高挖掘算法性能,使用机器学习中KNN(K-NearestNeighbor)深度聚类算法[12,13],明确样本数据的邻近函数域,融合自动编码器压缩特征。
深度聚类过程主要包括软件特征提取、特征降维、特征聚类三步骤。特征提取的同时还要去除干扰噪声和重复、缺失数据。若待挖掘软件样本数量是M,集合中第α个特征的值表示为Q=(qα1,qα2,…,qαM),样本规范化表示为
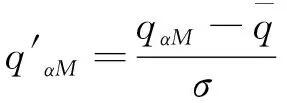
(4)
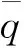
深度学习规范化后特征内抽象信息,将高维数据重构到低维空间内,提高挖掘算法性能。这步骤分为:输入层、输出层、隐含层,降维过程为
z=fθ(q)=ϖ(Wq+b)
(5)
p=gθ′(z)=ϖ′(Wz+b′)
(6)
式中,q表示输入特征,p表示降维后特征,fθ(q)表示输入至隐含层中的非线性函数,用来处理输入的无关联特征,z表示输入至隐含层的中间结果,gθ′(z)表示输入至输出层中的非线性函数,用来处理隐含层输入的无关联特征。ϖ、ϖ′描述不同层激活函数,W、W′描述特征编码、解码权重,b、b′描述不同层偏移向量。
考虑到本文为基于多类漏洞的并行挖掘算法,将低维特征以不同“特征源”进行深度聚类,以软件代码片段间的差异特征作为聚类指标。j为待挖掘样本q中的任意特征种类集合,o表示聚类中心,深度聚类可描述为
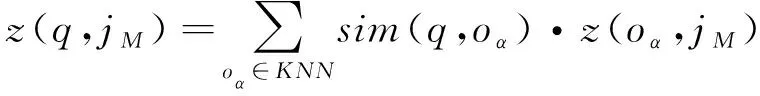
(7)
式中,sim(q,oα)表示q和oα之间的余弦距离。
利用分类挖掘算法能够分类并识别不同“特征源”的最近邻居特征集合。
4.2 软件漏洞挖掘
将软件划分为不同特征源后,使用相似性度量方法比较计算特征源和多类漏洞信息资源库相似程度,即度量二者中任意数据pl和xk间欧式距离[14]为

(8)
式中,r=(1,2,…,j)。
由于不同特征源之间的量纲是一致的,所以难以度量出不同特征间细微差距,为此,使用式(4)规范化处理去除其量纲限制,并行挖掘出准确软件漏洞问题解[15]。此时不同特征源间规范化欧式距离为

(9)
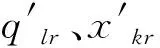

5 仿真研究
5.1 初始参数设置
为验证基于机器学习的软件多类漏洞并行挖掘方法的有效性,进行仿真。选取来自开源数据库Tera-PROMISE的4组NASA软件多类漏洞数据集作为实验样本,任意数据集包含漏洞常量、干扰、重复等特征都不一致。具体如表2所示。

表2 实验数据集
5.2 指标设置
在软件漏洞挖掘实现过程中,必须挑选指标来验证所提方法挖掘性能。评价挖掘结果可描述为一个二分类问题,即挖掘无错误为正例、有错误为负例,各个指标的具体计算公式为:
1)精准度描述软件漏洞被正确挖掘出的数量与所有被挖掘的数量的比值,计算公式为
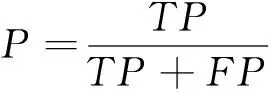
(10)
2)召回率描述软件漏洞被正确挖掘出的数量与真实软件漏洞数量的比值,计算公式为

(11)
3)F1值描述召回率与精准度间的调和平均值,因为二者间存在非线性关系,会存在召回率高但精准度低的情况。这样F1值越大,表示二者值不一致情况越小,计算过程为
(12)
式中,真正例TP(实际结果为漏洞且被挖掘出的数据)、真负例TN(实际结果为漏洞未被挖掘出的数据)、假正例FP(实际结果不是漏洞却被挖掘出的数据)、假负例FN(实际结果不是漏洞也没被挖掘出的数据)。
5.3 软件特征聚类效果对比
将4组实验数据集内数据放置在低维空间内,完成特征深度聚类,文献[5]提出的基于改进ASTNN网络的软件漏洞挖掘方法、文献[6]提出的基于加权组合模型的软件漏洞挖掘方法、研究方法分类结果如图1所示。图中,黑点为CM1数据集、白点为CM2数据集、黑矩形为KC2数据集、黑三角为MW1数据集。
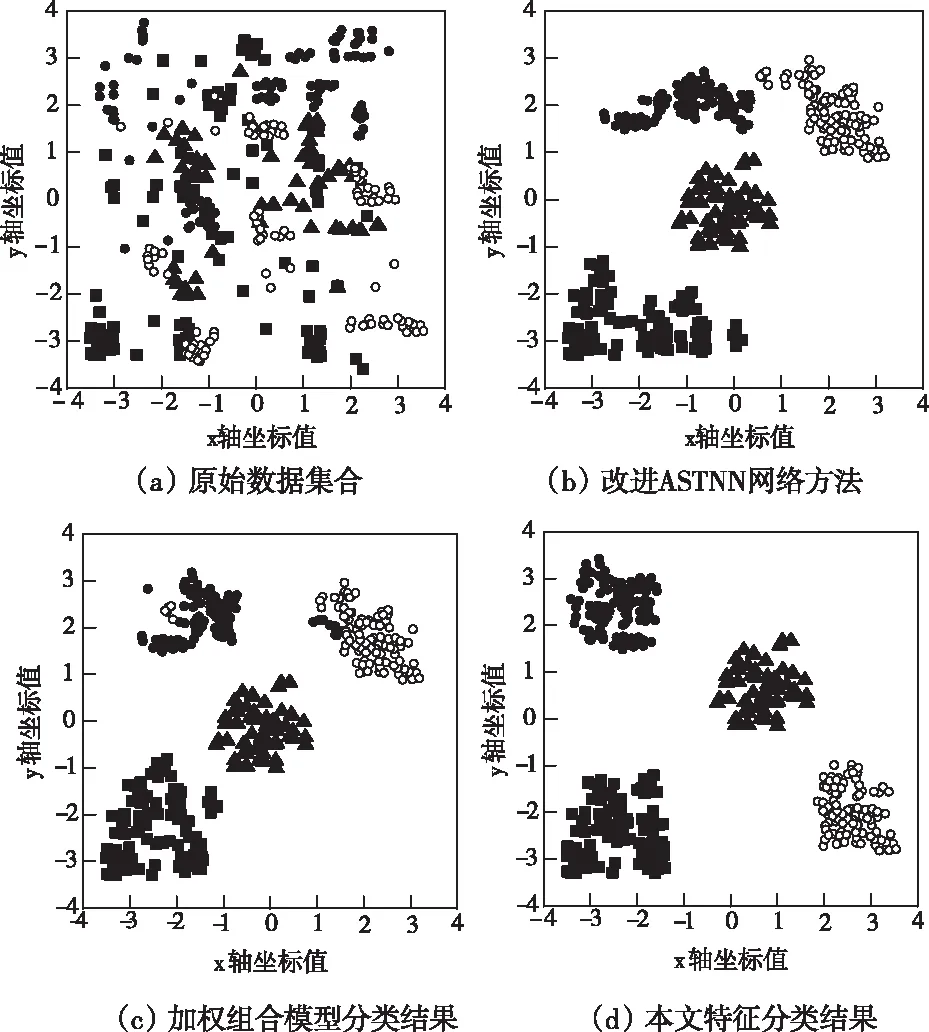
图1 不同方法的软件特征聚类结果对比
观察图1可知,CM1、CM2软件数据相似程度高,加权组合模型在分类过程中出现错分情况,改进ASTNN网络方法未发生错分但二者聚类中心聚类过近,在后续多类漏洞挖掘中很难提供明确特征信息。相比之下,所提方法,不仅分类边界清晰、聚集,CM1、CM2聚类中心距离最远,最大程度避免了后期错误漏洞挖掘情况发生。
5.4 F1值和AUC值对比
三种方法挖掘结果的F1值如图2所示。
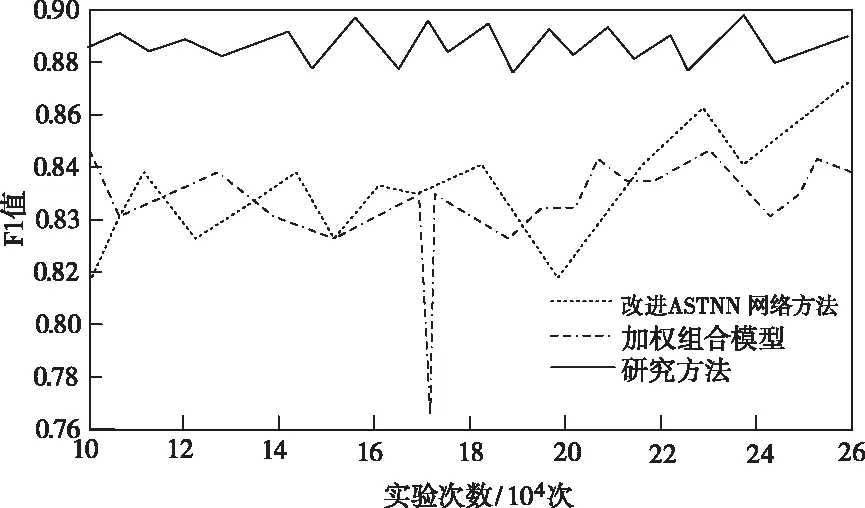
图2 不同方法的F1值对比
根据图2能够看出,研究方法F1值随着实验次数增加出现了一定震荡,总体稳定在[0.86,0.89]之间,文献方法相比F1值低且更加稳定。说明所提方法召回率高且挖掘精准,二者值相差较小、均匀调和。
ROC曲线下面积为AUC,取值范围在为比较挖掘方法在[0,1]之间,通常会大于0.5,值越大表示挖掘算法的错误负例越少,性能越好。三种方法挖掘结果AUC值如图3所示。
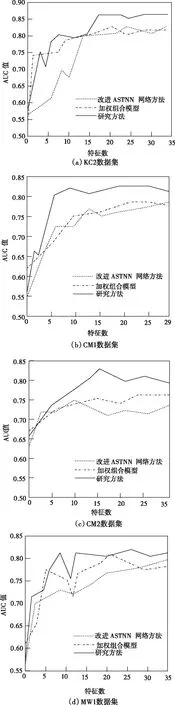
图3 不同方法的AUC值对比
根据图3可知,能够看出对于不同数据集,研究方法最终AUC值均高于文献方法,且在特征数初期上升趋势明显,随着特征数增加曲线趋于平稳,本次实验结果可证明所提方法错误负例少、误报率低。
6 结论
提出一种基于机器学习的软件多类漏洞并行挖掘方法。建立多类漏洞资源数据库,通过深度聚类和欧式距离加快挖掘方法自学习速度,经过仿真证明所提方法面向大规模多类型软件系统时,也能精准、快速挖掘出漏洞信息。可将研究方法应用于软件开发设计、编码程序、仿真测试以及发布使用等多个环节,全面考虑不同阶段可能出现的漏洞问题。
猜你喜欢
今日农业(2022年13期)2022-09-15
英语文摘(2021年10期)2021-11-22
电子制作(2019年11期)2019-07-04
摄影之友(影像视觉)(2019年3期)2019-03-30
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
儿童时代(2016年6期)2016-09-14
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
CHIP新电脑(2015年10期)2015-10-15
