
提高软件定义网络交换机存储能力的流表压缩算法
2022-11-29 02:44:14沈剑良王崇越汤先拓张霞
西安交通大学学报 2022年11期
沈剑良,王崇越,汤先拓,张霞
(1.中国人民解放军战略支援部队信息工程大学,450003,郑州;2.国家数字交换系统工程技术研究中心,450002,郑州)
随着互联网技术与信息技术革命的不断深入,旧有的网络结构无法满足灵活多变的用户需求,以软件定义网络(software defined networking,SDN)为首的新型网络体系具备良好的前景,受到了广泛关注。SDN将控制平面和数据平面解耦分离,控制平面生成流表,数据平面根据流表对数据进行分类、转发等操作[1-3],实现了网络的统一管理。利用流表的数据包分类已经被广泛应用在防火墙过滤、入侵检测、流量计费等领域[4-5],在网络数据安全方面发挥着重要作用。
随着SDN及其南向协议OpenFlow的不断发展,流表内容愈发复杂,流表数不断增加。为了满足低时延的流式处理,三态内容寻址存储器(TCAM)被用于交换机中进行流表存储与匹配,但是TCAM存储空间较小,价格昂贵[6],且无法直接存储具有范围值的流表项,需编码后进行存储,编码后流表项用0,1,*(通配符)表示,给存储空间带来了巨大压力。
针对流表内容耗费存储空间的问题,学术界和工业界已经提出了许多方法来优化存储空间,这些研究主要集中在优化TCAM编码算法[7-18]、修改TCAM硬件结构[19-21]、流表优化[22-25]3个方面。
TCAM的范围编码算法是利用编码过程中流表特性来进行优化,减少编码后流表项数。最直接的前缀编码[7](prefix encoding,PE)算法将每个范围值转化为前缀表示,并独立存储在TCAM表项中,当一条规则同时具有多个范围值时,会导致多组前缀相乘,占用大量空间,最坏情况下一条规则需要900个TCAM表项进行表示,导致范围扩展问题。通常,一个W位的范围最多需要2(W-1)条前缀来表示[7],占用大量存储空间,不满足网络的发展。为了减少编码后表项数,文献[8-13,16]利用额外比特位来提高编码效率。文献[14-15,17]利用规则集本身特性来提高编码效率,修改TCAM硬件结构则是通过修改硬件电路来提高存储空间。Yu等[20]提出了利用静态随机存取存储器(SRAM)来模拟TCAM,可以在保留高效处理速度的前提下降低成本,提高存储空间。Gangadhar等[21]提出了修改TCAM的晶体管结构来优化TCAM构造,实现了容量增加以及功耗降低,但是修改硬件电路的方法都具有较大局限性。
流表优化方法则是根据流表项之间的关系以及流表内部的信息冗余来对流表项进行压缩优化。唐亚哲等[24]结合TCAM和布隆过滤器设计了混合多级流表,有效提高了存储容量。Zhong等[25]在几何空间上对规则集进行分析,将具有重叠特征的不同规则集进行合并转化,实现了规则集的优化,增加了存储空间利用率。
这些技术都是为了提高TCAM存储空间利用率,而范围编码是其中无法绕开的关键环节。针对现有范围编码算法占用额外比特位过多[8,11-13]或支持场景局限性过大[9-10,14-17]的问题,本文提出了一种不占用额外比特位的高效混合编码算法。该算法将任意W位范围[2p,2q-1](其中p≥0,w≥q>p)称为无范围扩展前缀编码(none range expansion prefix encoding,NREPE)范围,对其编码可以实现无范围扩展。对于非NREPE范围采用其他编码方案,由于精力限制,本文对其他范围仍采用了PE算法进行编码,但是在后续工作中,可以采用更高效的编码方案进行混合编码。
本文从TCAM的缺点着手,通过分析对比已有的优化算法,查漏补缺,首先对此前办法进行改进,设计新型编码算法,其次设计对应的架构,最后通过实验证明方法有效性。综上所述,本文提出了一种无需修改TCAM结构的混合编码方案,可以灵活有效地对不同类型流表进行优化;提出了一种不占用额外比特位的无范围扩展的编码算法,有效地节省了TCAM存储资源;从更细粒度的层次对算法编码效果进行了分析,证明了本算法高效的编码效率。
1 混合编码策略与算法实现
在本节中,对目前已有的关于TCAM范围编码的算法进行介绍,根据这些编码算法的独立性将其分为两类:规则集无关的范围编码和规则集相关的范围编码。
1.1 规则集无关的范围编码
最直接的独立于规则集的范围编码方式是前缀编码算法PE[7],该算法直接将十进制数据转化为二进制的前缀表示形式,将所有的范围端口转化为前缀表示。算法简单易于部署,但是直接转化的范围值通常需要多条流表项表示,在最初流量规模较小时应用较多。随着网络流量不断增加,流表规模不断膨胀,PE算法已无法满足当下网络流表存储需求。
针对PE算法编码效率较低的问题,文献[8]提出了栅栏编码算法,可以将任意的范围转化为一条前缀表示,但是该算法需要2W-1个额外比特位来表示,在实际的部署中无法提供足够的额外比特位。进而提出的独立于数据库的范围前缀编码(database independent range preencoding,DIRPE)算法针对栅栏算法需要额外比特位过多的问题,对栅栏算法进行了改进,将范围值占用的比特位拆分成为多个块,拆分后得到的各个块利用栅栏编码表示,拆分后得到的块越多,每个块包含的比特位越少,需要的额外比特位也越少,但是相应会增加得到的TCAM表项数。
针对DIRPE需要额外比特位的情况,Bremler-barr等[9]提出了短范围格雷码编码(short range gray encoding,SRGE)方案。SRGE利用了二进制反射格雷码的特性来进行编码,借助二叉树的反射特性和格雷码的邻接特性,确保二叉反射树的任意范围都可以通过一个或多个折叠节点进行压缩。该算法不需要额外的比特位,可以编码不超过1 024位的范围,但是对于更大的范围值,则需要采用混合编码的方式处理。
Bremler-barr等[10]提出无扩展范围编码(range encoding with no expansion,RENE)算法,从全局出发,根据规则集中最大范围值长度对所有范围进行编码,对于较小的范围值,可以实现不需要行扩展的范围编码。该编码算法主要针对于较短的范围字段,范围字段较长时编码效率有所下降。
Demianiuk等[11]提出的范围减少(range reduction,RR)算法,通过将原始规则集分组后得到相互独立的不相交范围,再利用PE算法或SRGE方案进行编码后存储,在范围字段较短时编码效果较好。
文献[12]提出的分割编码结构(divide-and-conquer scheme,DCS),首次提出了分而治之的编码架构。通过对范围值进行分析,将含有范围值的规则分割为多条表项,对不同的表项采用不同的编码算法,可以有效地减少范围扩展,但是该算法需要W位额外比特位,在减少范围扩展的同时也占用一部分TCAM存储空间,在IPV6环境下,存储空间优化效果并不好,仍具有较大的改进空间。
1.2 规则集相关的范围编码
规则集相关的范围编码核心在于利用规则集内部的特征来进行编码,编码效率较高,但是当规则集发生改变时,需要重新计算,代价较大,不能实现规则集的快速更新。
最基本的规则集相关的范围编码算法是比特映射算法(Bit-Map)[16],该算法统计规则集中的所有范围规则,将不同范围用一个比特位表示,利用不同比特位对范围规则进行划分。若存在N个范围规则,则需要N个比特位来进行范围编码。该编码规则较为简单,不产生行扩展,但是缺陷较为明显,无法应用于大规模规则集。
文献[17]给出了动态范围编码算法(dynamic range encoding scheme,DRES),该算法首先对规则集中范围规则进行统计,得到每条规则的编码增益(该规则编码后可以消除的表项数)。进而按照编码增益排序,依次选择编码增益最大的规则进行编码,编码方式可以任意选择。文献[17]提供了一个系统的解决方案,虽然给出了规则集更新的方法,但是过于繁琐,更新困难。
文献[18]提出了范围特征码编码算法(RFC),该算法首先将规则集中所有范围分为多组,其次将每组范围划分为多个正交范围,最后对各组中的正交范围进行编码,通过利用额外比特位对不同范围值进行区分,从而减少了范围扩展的问题。
2 无范围扩展前缀编码
目前大多数编码算法存在占用额外比特位、编码后流表项过多等情况,针对这个问题,本文在PE算法和DCS算法的基础上提出了无范围扩展前缀编码算法,不需要占用额外比特位,对于本文提出的NREPE范围,可以实现无范围扩展。
2.1 无范围扩展前缀编码的基本思想
TCAM的范围编码算法一直是研究热点,目前许多算法利用TCAM中的额外比特位来对范围值进行编码,但是由于空间制约,无法适应新型网络体系结构的发展。经典的PE算法在不需要额外比特位的基础上则会带来范围扩展问题。
本文针对PE算法带来的范围扩展问题,结合PE算法以及DCS算法的优点,提出了无范围扩展前缀编码,通过设计独特的编码方式可以对范围值实现不占用额外比特位的单条编码,解决了PE算法和DCS算法的缺点。通过表1简要描述无范围扩展编码的思想。
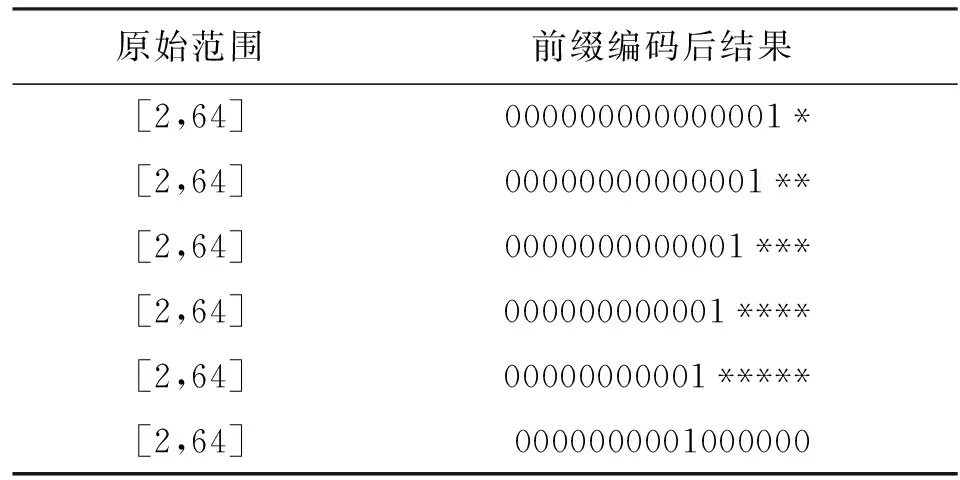
表1 范围[2,64]的PE编码结果
由表1知,对范围[2,64]使用前缀编码后,自上而下每条表项的最高有效位依次递进,且最高位后的比特位均使用*(通配符)代替。针对规则集编码的特性,给出了定理1如下。
定理1对于任意的W位范围[2p,2q-1],其中p≥0,W≥q>p,可以使用最高有效位递进的q-p个向量将该W位范围表示。为便于表示,本文将该类型范围称为NREPE范围。
证明对于任意的W位范围[2p,2q-1],由于q>p,因此该W位范围必定存在区间[2p,2p+1-1],可以用一条前缀表示为0W-p-11*p,此时剩余区间为[2p+1,2q-1](q>p+1),仍可重复分割后编码过程,最终可使用最高有效位递进的q-p个前缀向量将该W位范围表示。证明完毕。
根据定理1知,任意NREPE范围的前缀表示是有规律的,仅利用一条表项将其编码,即可解决PE算法范围扩展的问题,节省存储资源。
2.2 无范围扩展前缀编码流程
本文已经在2.1节中提出了NREPE范围的概念,通过分析可知,若仅利用一条表项表示NREPE范围,即可实现无范围扩展范围编码。规则集中的范围值,并不都是NREPE范围,针对该问题,本文提出一种编码架构,首先将范围值进行分割,得到NREPE范围和其他范围字段,对于NREPE范围采用无范围扩展编码,而其他类型的范围值采用前缀编码。通过混合编码技术,即可最高效率地进行编码,通过这种编码架构,可以灵活有效地支持不同的应用场景,具备良好的发展前景。
2.2.1 范围值的分割
目前网络应用向智能化、精细化发展,对数据处理有更高的要求,因此在数据包分类中端口号等范围字段也发挥着越来越重要的作用。目前数据包包头中含有的端口范围种类繁多,并不完全满足编码要求,因此对于这些范围字段,首先需要对其进行加工处理,使其满足编码算法的要求。本文所提算法是在PE算法和DCS算法的基础上进行改进,借鉴了DCS算法对范围值分割的方法。即对于任意给定的范围[l,h](0≤l (1)不需要进行分割。该范围被某个NREPE范围覆盖(2p (2)分割为两段范围。分割后均为非NREPE范围[l,2p-1],[2p,h](2p-1≤l (3)分割为3段范围。[l,2p-1],[2p,2q-1],[2q,h](2p-1 通过对原始范围值的分割处理,可以得到NREPE范围和其他范围字段,为后续打下基础。 2.2.2 规则集编码算法 对范围值进行分割后可以得到不同的范围字段,对不同的范围采用针对性编码算法,可以提高编码效率。对于NREPE范围,本文给出了算法1来进行编码,而对于其他范围字段,本文采用前缀编码来进行表示。 算法1NREPE范围编码算法 输入 范围值的最高位与最低位p、q以及位宽W(p+1 输出 字符串向量s 1.初始化一个空的W位字符串向量s 2.利用q设置字符串向量的最高位 3.从字符串最高位W-1到q-1进行遍历填充,对第q-1位填充为*,其余高位填充为0 4.for allifromW-1 toq-1 do 5.ifi=q-1 then 6.s.append(‘*’) {‘*’为通配符} 7.else 8.s.append(‘0’); 9.i--; 10.利用p设置字符串向量的最低位 11.从字符串q-2位到0进行遍历填充,对第p位填充为1,其余位填充为* 12.for allifromq-2 to 0 do 13.ifi=pthen 14.s.append(‘1’) 15.else 16.s.append(‘*’); 17.i--; 18.returns; 通过对规则集中的范围值进行分割编码后,可以实现不占用额外比特位的目的。由于对范围值采用了独特的编码方式,为了实现流表项的匹配,同样需要对包头向量进行对应的搜索秘钥编码,下面给出搜索秘钥算法的伪代码。 算法2NREPE搜索秘钥编码算法 输入 端口值v以及位宽W 输出 字符串向量k 1.初始化一个空的W位字符串向量k 2.将端口值使用二进制表示,最高有效位设为y 3.从k的最高位开始遍历填充,y左侧填充为0,y位填充为1,其余填充为* 4.for allifromW-1 to 0 do 5.ifi=ythen 6.k.append(‘1’) 7.for alljfromy-1 to 0 do 8.k.append(‘*’) 9.j-- 10.break 11.else 12.k.append(‘0’) 13.i-- 14.returnk; 通过设计范围编码算法以及秘钥算法,可以有效地减少范围扩展问题。本文所提出算法的核心在于利用p和q对范围规则进行表示,使用p表示范围下限,q表示范围上限。在搜索秘钥编码算法中,则利用端口值的最高有效位进行编码,可以实现精确匹配,本文在图1中使用了范围值[5,71]作为例子,完整地展示了如何进行范围分割,范围编码以及搜索秘钥编码。 在图1(a)中,对范围值进行了分割,将其分为3个范围字段,其中[8,63]是NREPE范围。在图1(b)中,针对其中的NREPE范围进行了编码,在图1(c)中,分别使用15和7进行了测试,结果显示15被编码后符合规则,7因最高有效位不匹配而不符合规则。 在2.2节中已经介绍了NREPE编码的基本流程,即通过对范围值分割后进行针对性编码来减少范围扩展,不同的类型范围值采用不同的编码方式。为了更好地部署本文提出的算法并保留未来支持新型算法的能力,本文提出了一个开放和灵活的架构,可以使TCAM获得更高效的存储效率。该框架无需对交换机硬件进行改造,通过软件方法对规则进行压缩。 图2展示了NREPE编码在数据平面的结构,当数据包进入后,首先被数据包处理器所解析,提取特定字段组合后形成包头字段;其次将包头字段输入编码模块,通过搜索关键字编码算法进行编码,进而将编码结果传输至匹配模块(TCAM块)匹配,最终输出匹配结果。当规则集或编码方式改变时,可以通过控制平面下达修改指令,并对TCAM块中的流表项进行重配置,实现动态更新。由于本算法仅针对范围值本身,对于未来可能出现的其他字段的范围值,该编码算法仍然有效,因此所提出的结构仍保留广阔的发展空间,适应未来网络发展。 由于TCAM匹配的目的是对输入的数据包进行转发、丢弃、分类等处理。与TCAM进行匹配的是从数据包中提取的多元组,编码算法也是仅针对多元组,并不影响数据包本身结构,因此并不存在解码这一环节。 由于本文将范围值分割为NREPE范围和非NREPE范围,二者编码方式不同,因此存储后的TCAM分为两种类型,分别存储NREPE和PE编码的范围值,两两组合后共存在4种不同类型的TCAM块。 在本节中测试了本文提出算法的性能,由于真实的分类数据集数据难以得到,本文数据是通过ClassBench[26]生成的模拟真实分类数据集。ClassBench是由华盛顿大学开发的实验平台,它是一套对数据包分类算法和设备进行测试的工具,可以生成精确模拟真实数据集的实验规则库,主要有ACL(访问控制列表)、FW(防火墙规则)、IPC(IP链)3种规则。本文通过ClassBench生成了10组300 000规模的规则集,并在个人PC上利用Matlab对数据进行了模拟仿真,由于生成的规则集存在冗余情况,因此消除冗余后部分规则集数小于300 000,但是并不影响后续的测试。对生成的数据集进行统计后,结果如表2所示。 表2 ClassBench产生的规则集 对规则集统计后得到,FW类型的规则集在源和目的端口中均含有范围类型,然而其范围种类较少。ACL类型的规则集仅在目的端口具有范围,这些范围字段种类相较于FW和IPC更多。IPC类型的规则集虽然在源和目的端口都具有范围字段,但源和目的端口并不同时具备。 为了更好地展示本文提出方法的优势,本文选择了PE算法、DIRPE算法和DCS进行比较。比较时使用占用额外比特位数、更新速度、最坏情况扩展比ER(expansion ratio)作为依据,扩展比ER定义为具有范围的规则经过范围编码后所得的规则数ne比编码前的规则数nd。 由于本算法不改变TCAM结构以及芯片设计,仅利用软件对规则集以及提取的包头向量进行编码,因此所造成的额外功耗相比于TCAM本身功耗几乎可以忽略,而算法在对原始规则集进行编码并存储后重点在于规则集发生改变时的更新速度,对于更新速度以及其他指标在表3中进行了对比。 为了能够清楚地表示本文所提出方法针对不同规则集源和目的端口范围的编码能力,在本节中分别针对源端口和目的端口进行了编码。图3展示了仅在源端口进行编码的结果,从图3中可以看出,当仅对源端口的范围进行编码的时候,所提出的NREPE算法相较于PE、DIRPE以及RENE算法可以有效地降低扩展比,在FW和IPC类型的规则集中扩展比基本都为1,这是因为在FW和IPC规则集中包含了大量[1 024,65 535]范围值,而NREPE对此种类型的数据可以进行无范围扩展编码。ACL规则集中并不包含源端口具有范围的规则,因此并未在图3中出现。 表3 各编码算法比较 图4展示了仅在目的端口进行范围编码的结果。可以看出,NREPE算法在各种规则集下都优于传统的PE算法,并且都有较大幅度的领先,但在ACL2数据集下优化效果并不十分突出,这是因为在该规则集中包含大量[1 025,65 535]范围值,对于[1 025,65 535]范围值,需要将其分割为[1 025,2 047]、[2 048,65 535]两种情况,其中[2 048,65 535]仅需要一条表项表示,而[1 025,2 047]需要多条表项表示,因此最终仍需要多条表项,但相较于PE算法依然提升了40%的空间利用率。RENE算法则表现不佳,因为其适用于较短范围的范围编码,当存在大量较长范围时表现较差。 图5给出了同时对源和目的端口进行范围编码的结果。在两个端口均为范围的情况下,需要根据范围是否可以分割为NREPE范围进行分块存储。对于只有一个端口为范围的规则集,编码后所需的TCAM表项和针对该端口进行范围编码所得到的结果一致。例如在ACL规则集中,源端口均不包含范围,因此同时对源端口和目的端口编码的结果与针对目的端口编码得到的结果一致,但在FW规则集中,同时对源和目的端口编码后结果会发生巨大变化。在FW类型的规则集中,使用NREPE算法进行编码所得到的扩展比相较PE算法平均降低了86%,相较于DIRPE算法降低了83%,效果十分明显。 这是由于FW中包含了大量的[1 024,65 535]范围值,扩展比近似为1,并且源和目的端口均包含范围规则。如果采用其他方法,会导致大量的范围扩展,在ACL规则集中,NREPE编码后所需的TCAM表项相较PE和DIRPE算法平均降低了37%和4%,这是因为在ACL1数据集中包含了大量的范围长度较小的规则,3种算法编码效果较为相似,而在ACL2中3种算法效果都不十分理想。在IPC数据集中,NREPE算法相较于PE和DIRPE可以分别降低11%和71%的表项数。由于RENE算法在FW类型中表现不佳,通过实验知其在源和目的端口同时编码时扩展比远超其他类型算法,扩展比基本均在100以上,因此并未在图中展示。 NREPE算法相较于其他算法可以有效地降低扩展比ER,但相比于DCS算法,仅分析扩展比并无明显优势。本文所提出算法并不需要额外比特位,而规则集在TCAM中的存储在更细粒度上是对比特位进行存储,仅利用ER并不能突出本算法的优势,因此本文提出了比特位数比(bit number ratio,BNR)作为补充比较指标,从更细粒度的层次评价算法的编码效果。BNR定义为编码后所需要的比特位数ne,b比编码前占用的比特位数nd,b。由于篇幅限制,本文仅给出了对同时从源和目的端口进行编码后的比特位数分析,结果如图6所示。 根据实验结果可知,本文所提出的NREPE编码算法占用的比特位数远小于其他算法,即使相比效果最好的DCS算法,平均占据的比特位也减少了50%。通过综合比较,本文所提出的算法对存储空间优化效果最好。 本文提出了一种提高软件定义网络交换机存储能力的流表压缩算法。该算法针对SDN交换机的流表存储模块,对流表项进行分割后混合编码,实现了不占用额外比特位的低开销无范围扩展编码,有效提高了存储能力,且是一种通用算法,可以针对任意类型范围值,适用性广。从更细粒度利用存储资源,易于部署。实验结果表明,本文提出的流表压缩算法在各种规则集下,均可有效地优化存储空间,具备良好的扩展性,且是一种完整的编码架构,能够有效地适应网络流量的变化与发展。2.3 NREPE的结构体系

3 实验评价

3.1 拓展比性能比较

3.2 比特位数性能比较
4 结束语
猜你喜欢
通信技术(2022年5期)2022-06-11 00:47:44智能计算机与应用(2021年6期)2021-12-17 00:56:36综艺报(2020年21期)2020-11-30 08:36:49河北大学学报(自然科学版)(2020年4期)2020-09-02 14:23:38计算机工程与应用(2020年7期)2020-04-07 10:48:54电脑爱好者(2019年17期)2019-10-30 03:34:48电子测试(2018年21期)2018-11-08 03:09:34网络安全和信息化(2018年3期)2018-11-07 03:02:44西安电子科技大学学报(2018年5期)2018-10-11 12:32:08中南民族大学学报(自然科学版)(2017年3期)2017-10-18 01:04:38
