
借款描述对互联网金融信用风险的影响研究
2022-11-28 13:14:14陈为民杨泽俊
财经理论与实践 2022年6期
陈为民,杨泽俊,陈 依
(湖南科技大学 商学院,湖南 湘潭 411201)
一、引言及文献综述
随着互联网技术与金融交易模式的不断发展与融合,互联网金融因其交易方式便利、准入门槛低以及无担保抵押等优势和特点吸引了广大中小企业和中低收入群体参与。同时,由于它的投资收益回报较高,也受到了大量普通投资者的追捧[1]。虽然互联网金融发展迅速,但是问题日益增多。
目前国家正大力加强对互联网金融市场的监管和整改,至2020年助贷业务的监管法规已落地。面对日趋严格的金融监管、股市波动以及市场流动资金紧张的环境,平台运营开销与合规成本持续上升,借款人的逾期率不断上升,造成很多平台运营不良,相继倒闭。显然国内互联网金融的运营在信用风险内控方面有着不可忽视的漏洞。
在借贷平台交易过程中,借贷双方信息不对称的现象十分明显。贷款人的交易操作是十分透明的,而借款人可以通过编造虚假的借款描述来迷惑贷款人,使得贷款人对其进行投资,且贷款人只能看到一个经过平台加工处理后的综合指标——信用评级[2]。正是这种信息不对称导致了贷款人面临极高的风险。平台及投资人会偏向于非客观的、未经信用机构证实的自述文本表露材料[3],即使网络借贷中的借款描述难以验证其真伪[4]。因此深入研究分析借款描述对网贷信用风险的影响,对于减少信息不对称、降低贷款人贷款风险及完善借贷平台的建设有着重要的意义。由此,如何采取有效的方法来判别借款描述的真实性及文本信息怎样影响借款人的信用风险,有着极大的研究价值。
对于借款描述的研究,大多数学者认为借款描述是一种主观性强的非结构化数据,对借贷成功率有着极大的影响[5],特别是自身的“硬信息”难以助力个人的交易活动进行开展时[6],借款人通过借款描述展现出自我认知水平和其社会地位[7,8]。有些学者认为信用风险是网络借贷中贷款人最担心的风险[9]。网络借贷平台内的部分借款人自发披露的个体特征信息有限。由于信息不对称,投资者仍然会通过审查借款描述来获得更有效的信息[10],尽管人们认为未经证实的信息是不可信的[11]。但是已有研究对互联网金融信用风险的探讨主要集中于借款描述本身,较难全面反映借款描述中的不同主题潜在的含义对违约带来的不同影响,通过潜在语义分析(LSA)挖掘借款描述潜在的信息,无须人为操作,即可消除同义词、多义词的影响,确定适当主题及主题个数,能够更准确、全面地对借款违约率的影响因素进行研究。同时,对互联网金融信用风险的研究主要侧重于对借款违约率的均值回归,较难反映在不同水平下借款描述中的不同主题给违约带来的不同影响,而分位数回归能够表示解释变量对不同分位数下的被解释变量的不同影响[12],且分位数回归的方法在所有的分位点条件下都能体现出较好的拟合性,得出的结果更加稳健[13]。因此本文选择分位数回归的方法,以借款人的违约状况为因变量,分析不同信用度的人群在进行借款描述时更偏好哪种描述。
二、研究方法
(一)研究思路
现有的研究表明,投资者在选择大量信息时,集中力和判断力都有限,再加上对词语十分敏感,而且时常仅侧重于“关键词”。经过阐述借款描述在网贷行为里怎样起到相应的影响效用,不仅能够降低借贷行为双方间的信息不对称性,提升借贷的成交量和成功还款量,而且能够防范信用评级处于高层次的不良借款人群,以便提升该平台的风险管控能力水平,最终提高该平台的收益率。
利用Python爬虫程序获取网络借贷平台的成交记录以及借款人个人信息。采用 Python 工具对借贷平台借款描述中的内容进行大量文本机器分析,先对借款描述进行文本分词,再利用主题模型应用包Gensim对借款描述进行LSA文本内容归类,提取文本中包含的因素,分析哪些因素会影响借款人最后的违约率,并研究借款描述中的主题分布情况,根据研究结果帮助平台识别基于文本描述的借款人的信用风险。
利用分位数回归分析借款描述中包含的几个主题分别对违约情况有何影响,分析借款人的信用风险,明确有哪些文本因素能够影响借款人信用风险,基于文本挖掘剖析借贷信用风险,提前判断借款人按时还款的概率,最大限度地维护投资人的利益,也为平台后续的良好发展营造一个良好的信用环境。
(二)潜在语义分析
传统的基于关键字的文本处理方法难以辨别自然语言的语义模糊性,其主要依据词频信息来判断两个文档是否相似,相似度主要取决于两个文档中包含的共同词汇量。而潜在语义分析(LSA)能够利用统计方法,提取并且量化这些潜在的语义结构,从而消除同义词、多义词的影响,提高文本表示的准确性[14]。
潜在语义分析的目的是整理文本语句,其利用“矢量语义空间”来归纳文档和词中的“概念”,从而归纳词句和文档的包含关系[15]。
LSA主题模型的首要作用是效仿文本的导出步骤,通过前验分布与多次迭代来计算得到主题的系数及后验概率,推导得出长文本的潜在文本内容归类[16]。运用LSA模型对借款描述中的文本进行主题聚类。
LSA的实施步骤:(1)导出词汇库,(2)导出词语——文档矩阵,(3)奇异值分解。
(三)分位数回归
为研究网络借款描述信息在不同分位数下违约情况的变化,以确定文本信息在借贷过程中的信用风险影响,为P2P网络借贷平台以及投资者进行理性决策提供参考。由于研究的因变量为二元变量,因此利用二元分位数回归研究借款描述信息对借款人的信用风险相关性。
设第i个样本的观测值为(x1i,x2i,…,xki,yi),i=1,2,…,n,其中xi=(x1i,x2i,…,xki)T,当因变量为0,1时,二元分位数回归模型表示为
(1)
(2)

三、实证分析
(一)研究样本
在人人贷平台,借贷双方需要对一些信息进行填写,如表1所示。首先,借款人在借贷平台官方网站注册账号后,必须完善个人基本信息,借款人要补充好“个人资料”“工作资料”“身份证资料”“收入资料”“信用评分”等资料。在个人资料表栏中,“借款描述”是极其特殊的部分。在P2P网贷行为过程中,借贷平台为了促进借款人和投资者双方产生借贷关系,给借款人提供了在发布贷款申请时展示更多额外信息的一个渠道——借款描述。借款人可以通过借款描述披露任何自己想展示给投资者的信息。

表1 借贷平台信用认证体系
先利用爬虫软件分析了借贷平台2016年6月至2018年8月共323190位申请贷款者的个人信息。再筛选出 2016年6月至2018年8月时间段中借贷平台官网给出的所有借款人的借款信息为初始数据,初始数据总共包括259622个观测对象,筛选出的样本其借款状态都是已完成的。然后对初始数据采取以下四个处理步骤:
(1)删除资料不完整 (例如房车认证、信用报告等信息) 的 31621个样本数据。
(2)删除无实际内容的数据(如文本信息为“阿阿阿阿阿”“无”或未填写等)的98368个样本数据。
(3)由于经过实地担保与机构认证的借款人的违约率几乎为0,故将这部分样本删除。此处删除63271个样本数据。
(4)有一部分借款人为了提高自己的借款可能性,会在同一期间在借款平台上申请多个借款,而这些数据都是完全相同的。在对比时发现其借款描述也大多都是完全相同的,共删掉65980个对象值。
综上,研究对象筛选得到382个包含有效文本的交易样本量。其中包括191条违约数据,191条未违约数据。研究变量定义见表2。

表2 变量定义表
(二)词云图
通过Python语言内的汉语拆句分词——“Jieba”插件包,机器过滤借款描述内的标点符号,并过滤掉无意义的词语,对文本信息进行关键词调取、汉语分词,最后筛选掉网络上常用的停用词,把常用次数较多的排名靠前的60个主题词导出生成词云图,如图1所示。
由图1可以看出,使用频率最高、最具有代表性的词是“借款”“工作”“装修”等,表明其为文本中使用次数最多的词语;“经营”“收入”,表明借款是与经营有关的活动;“收入”“稳定”“每月”等词体现了文本中同时倾向于重点突出借款人个人的财产状况及营收的稳定来源。与此同时,在出现次数较多的前50个高频词语中,还涉及了许多文本主题,例如借款目的(“装修”“购车”“消费”等)、情感表达(“谢谢”“希望”等)、从事行业(“事业单位”“在编”“教师”等)、拥有资产(“自建房”“房屋”等)。

图1 借款描述词云图
(三)确定文本主题个数
通过LSA主题模型,从全部文档的文本数据中提取出k个适当的主题,连贯性得分值如图2所示。

图2 连贯性得分值
图2中,横轴表示不同的主题数,纵轴表示连贯性得分。可以看出,当主题数为7时,其连贯性得分值最高,效果最显著,因此选取最佳主题数是7。
根据文本挖掘结果,借款描述可归纳为“借款目的”“情感表达”“个人信用”“家庭背景”“财务情况”“从事行业”“表述模糊”七大类。其中第七类比较特殊,这类借款描述大多没有具体突出主题且含义模糊,原因可能是借款人在填写时并未认真对待,借款人仅仅表述了“有借有还”“打卡”“试一试”等,甚至为了凑字数填写了无含义的文字,所以将此类借款描述归为“表述模糊”,不进一步研究。
例如文本为“在借贷平台借过两次款了,无逾期,本人在国企工作,收入稳定,此次借款用于参加在职研究生培训及考试”,其中涉及X1(从事行业)和X3(借款目的)以及X6(个人信用),取X1=1,X2=0,X3=1,X4=0,X5=0,X6=1。
(四)各类主题对违约率的影响
利用R语言中的bayesQR包实现二元分位数回归模型,将上文遴选出的七类指标作为自变量,深入分析不同文本指标对借款人的违约状况在不同分位点上的影响差异。为更加直观和全面地反映出违约情况不同的借款人,其影响因素之间的差异及变化过程,本文将选取0.1~0.9之间,间隔0.05共17个分位点进行实证分析。二元分位数回归部分结果如表3所示。由于因变量为违约情况,当违约时,分位数系数为正,说明自变量与违约情况具有正相关性,即此类借款人信用评估较差。当未违约时,分位数系数为负,说明自变量与违约情况具有负相关性,即此类借款人风险信用评估较好。
由表3可知,当分位点水平取0.1~0.9时,所有X1~X6的系数值均产生了十分明显的波动,因此结合数据做出如下分析。

表3 二元分位数回归结果
X1变量指代从事行业,如图3(a)所示,在分位数为0.1的水平下,可以计算得出其与违约情况呈负相关,即说明信用最好的前10%的人群,在文本描述中,会表明自己所从事的行业。原因在于信用最好的前10%部分借款人,通过详细地介绍自己所从事的行业,向平台及投资者展示一个工作特征明显的个人形象,以此来完善自己的个人信息。而一般倾向于描述个人从事行业的借款人,大多有较好的工作单位。这也说明了这类人具有可以按时还款的个人能力,从而有助于取得投资人的信任。因此文本描述中的从事行业对于信用度最好的前10%人群,具有信用风险参考作用。
X2变量指代情感表达,如图3(b)所示,分位数系数均小于0,说明情感表达与违约情况为负相关,即表明当文本中涵盖情感表达这一变量时,借款人的信用度相较更好。尽管在两端分位数处系数并不显著,但在分位点取中间部分0.3~0.8时,即信用度处于中间段位的借款人中,描述情感表达的力度相比于其他分位点来说更大,因此,处于这段区间的借款人更值得相信,其违约率更低、信用度更好。造成这种现象的原因可能是处于信用度中间段位的人没有很高的信用评分来帮助自己获取贷款,也没有很低的信用评分来阻碍借款行为,因而采用真诚的语言来打动平台。而对于在困难时期被施予援手的人,会维持自己良好的信用,从而按时还款。可以看出情感态度积极且真诚的借款人,其诚信度更良好。借款人表达情感态度更能说明他态度诚恳,急需帮助。综合来说,情感表达整体与信用评估呈正相关关系。

图3 从事行业、情感表达系数变化趋势图
X3变量指代借款目的,如图4(a) 所示,在分位点取0.1时,其系数绝对值达到最大,说明在信用度为前10%的人群中,借款目的对此类借款人影响力度最大,原因可能是这部分信用度处于10%的借款人,描述借款目的可说明其对个人借贷行为有明显的规划性,从而体现其是具有一定还款能力的社会工作者。借款目的中大部分是用于资金周转、创业、投资等,此类借款人自身拥有一定物质财富基础。与此同时,借款用来投资创业的这类借款人往往都有长期性资金需要,他们需要及时还款以维持自己的高信用度,持续性的及时还款也会增加该类借款人对网贷平台的信誉评分,因而也促使平台能够长久地认可这类交易。然而从整体上来看,随着分位点增大,其分位数系数呈增大的趋势,其显著效果并不明显,可能原因是借款目的中除了大部分为资金周转、投资,等等,也有小部分目的是消费等,描述此类借款目的的借款人可能还款能力弱,从而拉低了借款目的对信用风险的影响力度。
X4变量指代家庭背景,如图4(b) 所示,不同分位点下对借款违约的影响系数总体类似“U”形,体现出明显的异质性。家庭背景指标对应的各个分位点上的回归系数先减小后增加,这意味着在违约率较高和较低的人群中,描述家庭背景的文本会增大个人的违约率。尽管在中间段位的分位数处系数并不显著,但在两端的分位点处,尤其在分位数取0.1及0.9时,分别是前半部分和后半部分的最大值,参数估计表明家庭背景描述在信用评估最好和最差的借款人中,会显著增大违约率。原因可能在于信用最好的人群,不会提及自己的家庭情况,而信用最差的部分人群更偏好讲述自己的父母、爱人的收入职业等情况,来赢得平台的信任。在描述家庭背景时,相当一部分是讲述自己亲人的良好工作单位及收入,来塑造一个可以按时还贷的形象,然而这一信息很难得到确认,因此,信用最差的人群利用这一点来提升自己借款成功率,并给平台造成违约损失。综上,可以得出家庭背景对于信用处于最好和最差水平的人群影响力度最大,平台应该加强处于该部分信用层次的借款人的家庭背景审核。
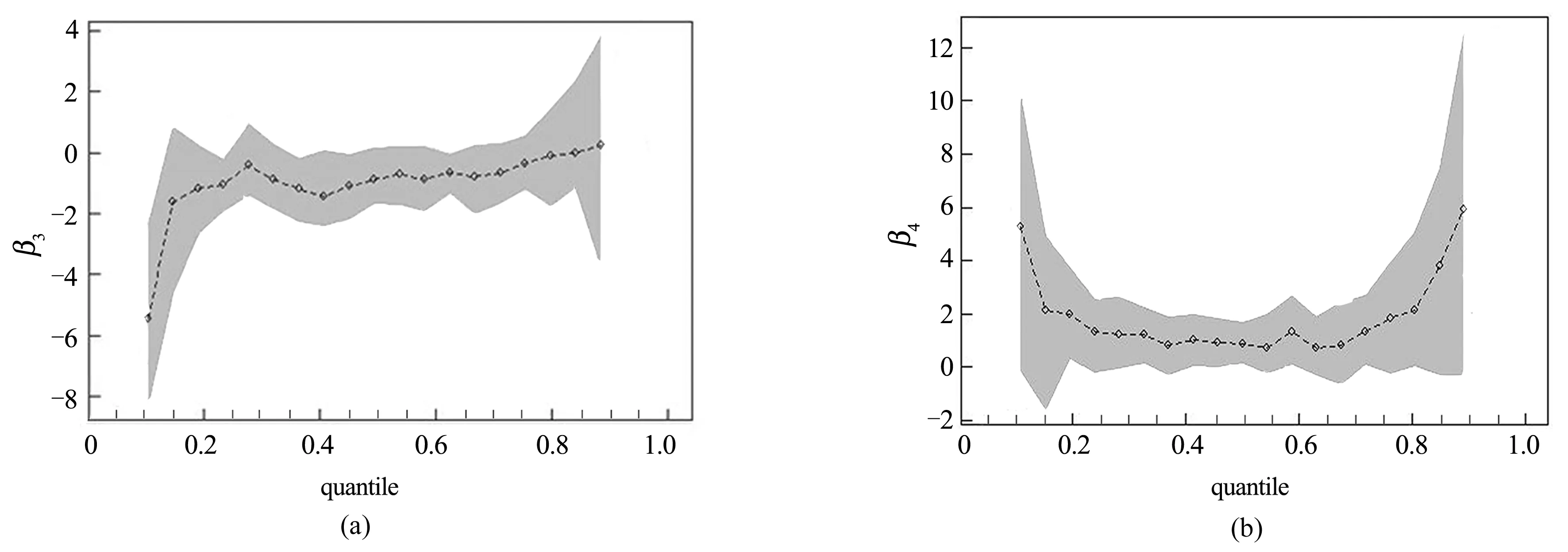
图4 借款目的、家庭背景系数变化趋势图
如图5(a)所示,对于X5这一反映财务情况的自变量中,不同分位点下对借款违约的影响系数总体类似“U”形。由图中分位数回归系数变化可以知道X5与违约情况呈现两端高中间趋于平缓的特点,这说明财务情况在信用最差的人群中相关性特征最明显,其次是在信用最好的人群中相关性特征次明显。对于信用最好的人群,他们在文本描述中不会提及个人财务情况,原因可能是在硬信息中,财务情况属于必填写项,并且必填写项需要得到平台的审核,必须如实填写,信用最好的借款人因此并未再次提及财务情况。而信用最差的部分人群,同样已经在平台上填写了财务状况,但从心理学的过度补偿机制来看,很可能会在文本描述里刻意描述平台难以核实的财务状况。一方面可能有作假的嫌疑,另一方面有特意强调的可能,这说明借款人想要刻意增加自己的信任度,来获得贷款,从而导致其违约率也更高。平台可以重点关注文本描述中财务情况这一特征变量。当分位点为0.9时,分位数系数最大,为0.1时次之,即信用度为前10%的借款人不会描述自己的财务情况,在0.9分位点上的信用度差的人群中,也会随着财务情况的描述越多,其违约率越大,在较高分位点上则增加了其违约可能性。
X6为个人信用变量,其分位数系数如图5(b)所示,呈现出倒“U”形的特点,在分位数两端系数取极值,在分位点为0.1以及0.9左右时最小,系数值为负且呈先增大后减小的趋势,分位数系数在后半段,显著性最明显,表明个人信用对违约率低、信用度为前10%以及信用度为后10%的借款人,影响力度最大,即当信用度为前10%的借款人的文本描述中包含个人信用时,会增加其信用评分;当信用度为后10%的借款人的文本描述中不包含个人信用时,会增加其信用评分。由图5(b)中折线的变化可以看出,随着分位点不断增大,其回归系数先增大后减小,可能是信用度高的借款人,会表明自己的信用良好,易获得平台的信任,而信用度低的借款人扰乱了互联网金融市场的有序运转,严重阻碍了信贷市场的发展。因此,当文本中涉及“本人信誉良好”“无不良记录”此类关键词句时,可以增强该借款人的诚信可靠度。平台可以重点关注文本描述中个人信用这一特征变量。

图5 财务情况、个人信用变量系数变化趋势图
四、结论与建议
通过分析借款描述的文本信息和分位数回归,主要的研究结论有:
(1)借款描述能够为评判网贷信用风险提供一定程度的贡献。借款描述中有关情感表达、个人信用和借款目的的描述与违约情况负相关,其信用评估良好。有关财务情况的描述与违约情况正相关,此类人信用评估较差。
(2)通过二元分位数回归实证分析,得出不同分位数下借款描述对P2P网贷信用风险具有不同的影响效果。研究得出,网贷平台中信用度为前10%人群,倾向于在文本中描述其从事行业、个人信用及借款目的并且不涉及其家庭背景和财务情况因素。
根据研究结果,建议借款人和平台方在已有信用评估指标的基础上关注借款描述,尤其是关于财务状况和家庭背景的描述,平台方应加强对描述内容的审核。借款描述是一种信息披露形式,监管方可以要求平台尽可能披露这些非结构化数据,供投资者参考。
猜你喜欢
意林(2023年7期)2023-06-13 13:00:55
数学年刊A辑(中文版)(2021年4期)2021-02-12 01:20:44
上海财经大学学报(2019年3期)2019-06-04 08:05:24
浙江工业大学学报(2018年5期)2018-10-08 12:33:42
瞭望东方周刊(2018年4期)2018-02-01 16:56:21
商场现代化(2016年8期)2016-05-10 16:43:43
黑龙江科学(2016年22期)2016-03-16 00:47:40
金融法苑(2014年2期)2014-10-17 02:53:27
航天返回与遥感(2014年4期)2014-07-31 17:47:33
河南科技(2014年11期)2014-02-27 14:09:41
