
基于机器学习算法的水驱储层相渗曲线仿真预测
2022-11-26 13:05李春雷曹小朋张林凤姜兴兴刘建涛靳彩霞杨河山
油气地质与采收率 2022年6期
李春雷,曹小朋,张林凤,姜兴兴,刘建涛,靳彩霞,王 峰,杨河山
(1.中国石化胜利油田分公司勘探开发研究院,山东东营 257015;2.中国石化胜利油田分公司油气销售中心,山东东营 257000)
相渗曲线能够综合反映流体在多孔介质中的渗流特征,是用于油田开发参数计算、动态分析、油藏数值模拟研究中的重要资料[1]。在油田不断开发的过程中,要了解油藏物性和渗流规律动态变化,需要实时获取储层相对渗透率变化[2]。传统的储层相渗数据的获取主要有3种方法:室内实验法、经验公式法和测井资料解释法[3-9]。室内实验法能获得完整的相渗曲线,但过程比较精细、昂贵且耗时;经验公式法是在缺乏实验数据的情况下进行相关估计,精度低、误差大;测井资料解释法只是得出在某一含水饱和度下的相对渗透率值,无法反映油水的相对渗透率变化情况。近年来,随着大数据、人工智能技术的发展,石油行业已开始利用人工智能方法获取储层物性参数[10-14]。为了获取更高精度的渗透率,开始尝试采用机器学习算法对储层渗透率进行预测。但是从调研结果来看,目前人工智能仅限于某一个状态下的储层渗透率预测,未能实现动态渗透率预测,即储层相渗曲线的预测。
目前,胜利油田已有大量的水驱储层相渗预测样本资料,尤其是能够反映储层状态的测井曲线,每口井都有多条不同类型的测井曲线,这些资料符合大数据技术特点:重复性、差异性和可预测性。因此,基于油田大数据,优选人工智能算法,开展储层相渗曲线仿真成为可能。
笔者提出一种新的水驱储层相渗曲线仿真方法,将测井曲线值作为输入,相渗曲线值作为输出,经过测井曲线敏感参数的优选、训练集的构建、机器学习算法的优选、模型的优化等一系列流程,生成仿真相渗曲线,通过多属性条件约束优化模型,提高相渗曲线预测精度,从而填补了基于机器学习算法预测完整相渗曲线的空白。该方法应用于油藏工程和油藏数值模拟研究中,可有效提升地质研究精度和效率,具有良好的应用前景。
1 相渗曲线样本构建
1.1 数据准备
相渗曲线主要由端点值(即最大油相相渗值、最大水相相渗值、残余油饱和度和束缚水饱和度)和等渗点等参数来表征,而影响相渗曲线形态的因素主要包括饱和历程、润湿性、岩石孔隙几何形态、大小、分布、原油黏度和温度等[15]。影响因素大部分是岩石流体物性参数,需要通过取样并进行岩心分析才能获得。胜利油田共6 万多口井,其中做过岩心分析的井仅4 000 多口,数据来源少。在储层预测研究中,应用测井资料能够间接反映储层的渗透性[16],从而预测储层相渗曲线。研究收集的测井数据几乎每口井都有,占比为100%。因此,将测井曲线值作为主要特征参数输入,相渗曲线数据做标签建立模型预测。
1.2 测井参数敏感性分析
从反映地层特性的全面性以及数据量方面考虑,选取自然伽马(GR)、自然电位(SP)、井径(CAL)、八侧向电阻率(RFOC)、感应电导率(COND)、4 m 底部梯度电阻率(R4)、微电位电阻率(RNML)、微梯度电阻率(RLML)、2.5 m 底部梯度电阻率(R25)、密度(DEN)、中子(CNL)、声波时差(AC)、总孔隙度(PORT)13个测井参数,分别建立各个测井参数与相渗曲线的相关性,在此基础上,排除高度相关的测井参数,最终分析认为GR,CAL,SP,AC,R25,COND,DEN等7个测井参数能够全面反映岩性、电性、孔隙度三方面特征。
选取孔隙度、渗透率、束缚水饱和度、残余油饱和度、束缚水下油相相对渗透率、残余油下水相相对渗透率6 个特征参数,利用K-Means 聚类方法对收集到的水驱储层280多个相渗曲线样品进行编号并自动聚类,通过调参求出K-Means 聚类方法最佳的分类数为5,5类相渗曲线之间的曲线形态差异较大,从中选出具有代表性的样品,对应的样本编号分别为3,105,125,126和228。
利用上述5个相渗曲线样品对应的岩石样品顶深与底深,分别截取对应深度的测井曲线段并求平均值(表1),再对测井曲线进行相对变化率计算,得到对应的7个测井参数的相对变化率(表2)。

表1 相渗曲线对应的测井参数Table1 Logging parameters corresponding to relative permeability curves
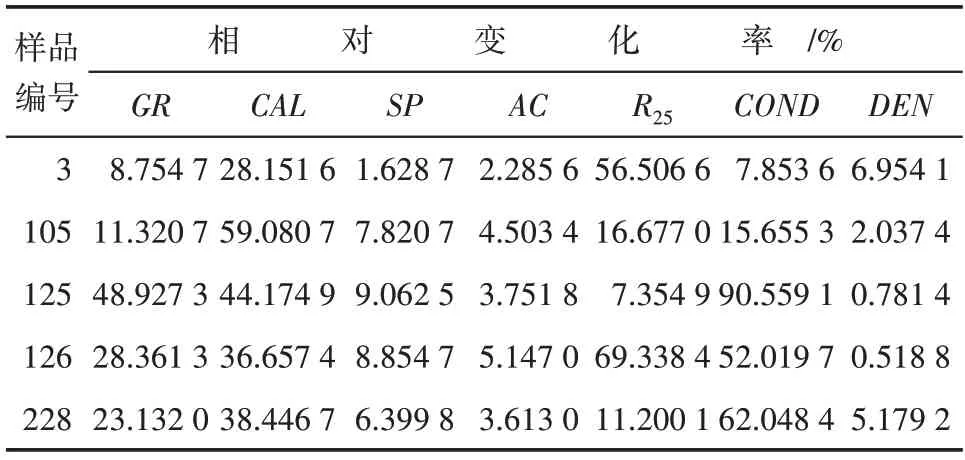
表2 测井参数的相对变化率Table2 Relative change rates of logging parameters
由计算得到的测井参数相对变化率绘制成雷达图(图1),图中5个相渗曲线类型分别用不同颜色代表,雷达图中各测井参数对应轴上的点代表5 个样品各测井参数的相对变化率,同一个样品点相连围成的面积越大,且同一对应轴上的值分布范围越大,表示该测井参数对相渗曲线越敏感。分析认为AC,SP,DEN这3 个测井参数不敏感;GR,CAL,R25,COND这4 个测井参数对于相渗曲线而言是敏感的,将其作为预测模型输入特征参数。
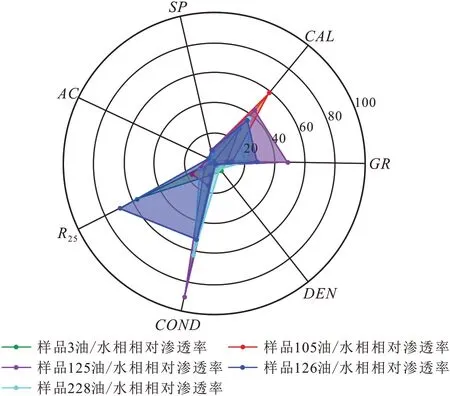
图1 基于测井曲线的储层相渗曲线影响因素敏感性分析Fig.1 Sensitive analysis of factors affecting reservoir relative permeability curves based on logging curves
1.3 样本构建
选取GR,CAL,R25,COND和相渗实验中的储层含水饱和度(Sw)共5 个参数作为预测相渗曲线的特征输入,将油相相对渗透率(Kro)和水相相对渗透率(Krw)作为预测相渗曲线的特征输出。
基于原始的样本数据,进行数据分析、数据量及分布情况统计等数据预处理;采用分箱法处理异常值;采取去重处理、噪音数据处理等,对缺失的测井曲线值采用XGBoost 算法进行补全;将岩心相渗数据与岩心深度段相对应的测井参数融合构建相渗曲线预测样本集(表3)。
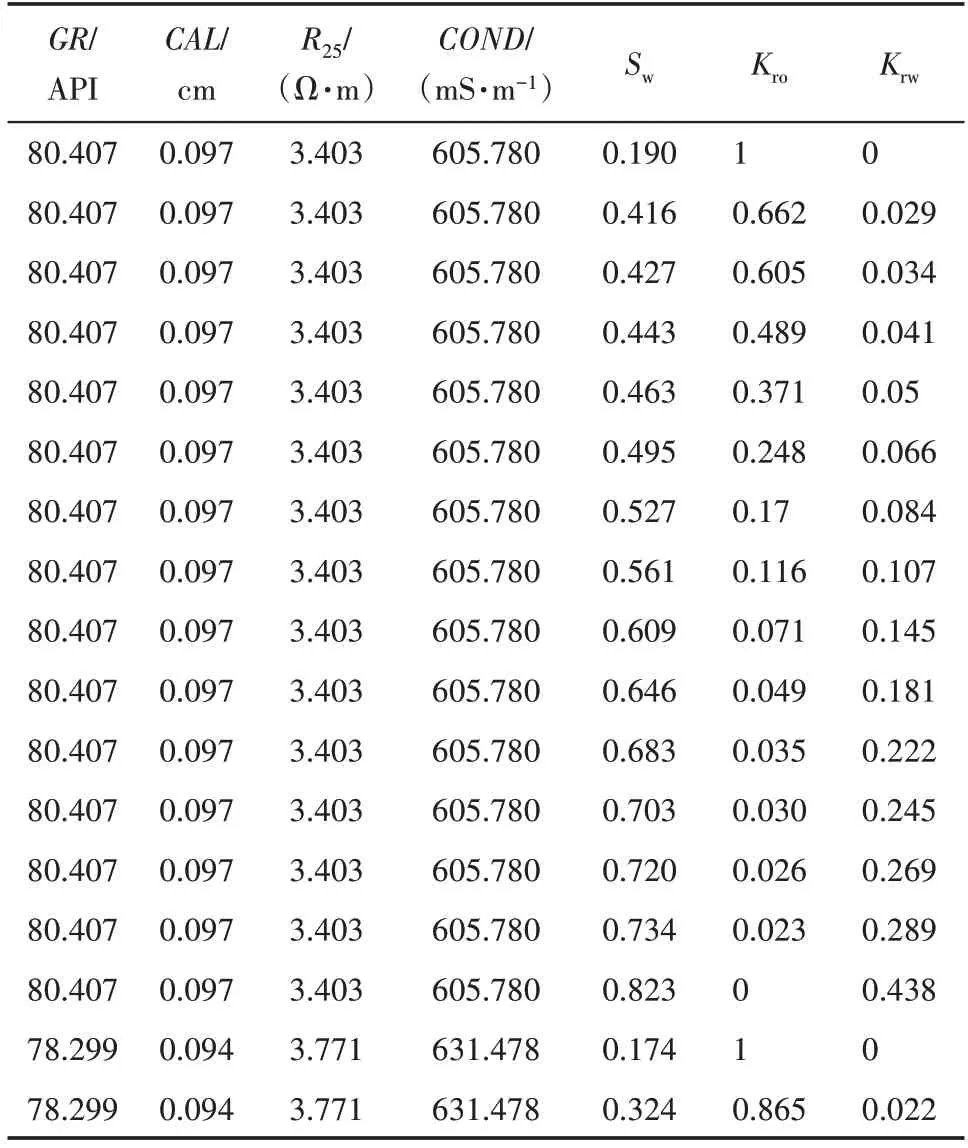
表3 部分相渗曲线预测样本集Table3 Prediction sample sets of some relative permeability curves
2 模型训练与优化
2.1 模型训练结果对比
采用机器学习算法对胜坨区块的相渗曲线进行预测,使用样本数量为278 个。样本数据的90%作为训练数据,10%作为测试数据;其中训练数据的90%用于模型的训练,10%用于模型的交叉验证。分别选用随机森林,AdaBoost,GBDT和XGBoost这4种机器学习算法对油相相对渗透率和水相相对渗透率进行预测,并对预测精度进行分析对比。
预测结果表明,4 种算法预测精度均在85%以上,其中XGBoost算法预测效果最好,油相相对渗透率预测精度达90.4%,水相相对渗透率预测精度达93.8%;其次为GBDT 算法,油相相对渗透率预测精度为90.0%,水相相对渗透率预测精度为92.1%;随机森林与AdaBoost 算法的油相相对渗透率预测精度分别为86.0%和87.2%,水相相对渗透率预测精度分别为90.2%和92.1%。XGBoost 算法优于其他算法的原因是:①应用正则化项防止过拟合。②不仅使用了一阶导数,还使用二阶导数,损失更精确。③可并行优化。④考虑了训练数据为稀疏值的情况,大大提升算法效率。⑤支持列抽样,不仅能降低过拟合,还能减少计算时间。
2.2 模型优化
2.2.1 地质因素约束优化
考虑油藏的地质特征,在原有预测模型的基础上添加、融合油藏地质特征参数进行模型约束,主要包括:①坐标数据作为沉积相类型的反映与约束,结合井斜数据,计算出每个井层的坐标数据,间接反映油藏沉积类型。②地质分层数据作为测井数据离散标准化的深度约束,为了消除由于非地质因素造成的误差,需要对测井资料进行标准化处理。③通过查阅岩心综合录井资料,将岩心样品进行归位。
水驱储层相渗曲线预测模型地质因素约束优化后,预测精度有所提升,其中XGBoost算法油相相对渗透率预测精度达93.0%,水相相对渗透率预测精度达96.3%,优化后精度提升超过2%。
2.2.2 曲线端点约束优化
束缚水饱和度(Sw1)和残余油饱和度(Sw2)端点值决定了相渗曲线的区间范围(图2)。基于相渗曲线的预测样本中输入特征除了测井曲线值外,还包括含水饱和度数据。在模型的应用过程中,测井资料充足,但相渗实验中的含水饱和度资料缺乏。因此必须把含水饱和度的端点值预测出来,才能更好地应用模型。
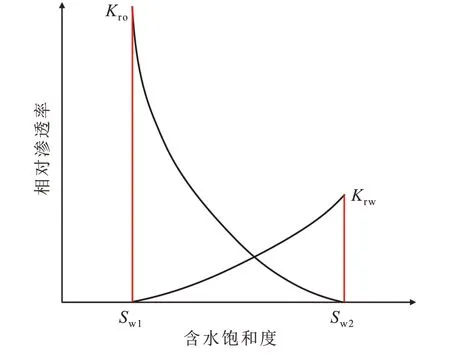
图2 相渗曲线Fig.2 Relative permeability curve
在原样本集的基础上,输入特征为GR,CAL,R25和COND,输出特征为含水饱和度,采用XGBoost 算法的结果可多输出的特点同时预测束缚水饱和度和残余油饱和度。其中,束缚水饱和度的预测精度为93%,残余油饱和度的预测精度为94.9%。
在模型预测相渗曲线的应用过程中,结合饱和度端点值预测,以预测的2个端点值为边界,等间隔划分相渗曲线的含水饱和度,将含水饱和度和测井曲线值共同作为输入,经过模型预测后,即可得到不同含水饱和度下的油水相对渗透率,绘制完整的相渗曲线。
3 模型验证及应用
3.1 模型验证
利用验证集中的样本进行相渗曲线预测,并与其真实值做比较,由相渗曲线模型的预测结果(图3)可以看出,油相相对渗透率与水相相对渗透率的预测值与真实值曲线几乎重合,计算得到油相相对渗透率与水相相对渗透率的绝对误差均小于10%。说明该模型预测效果较好。
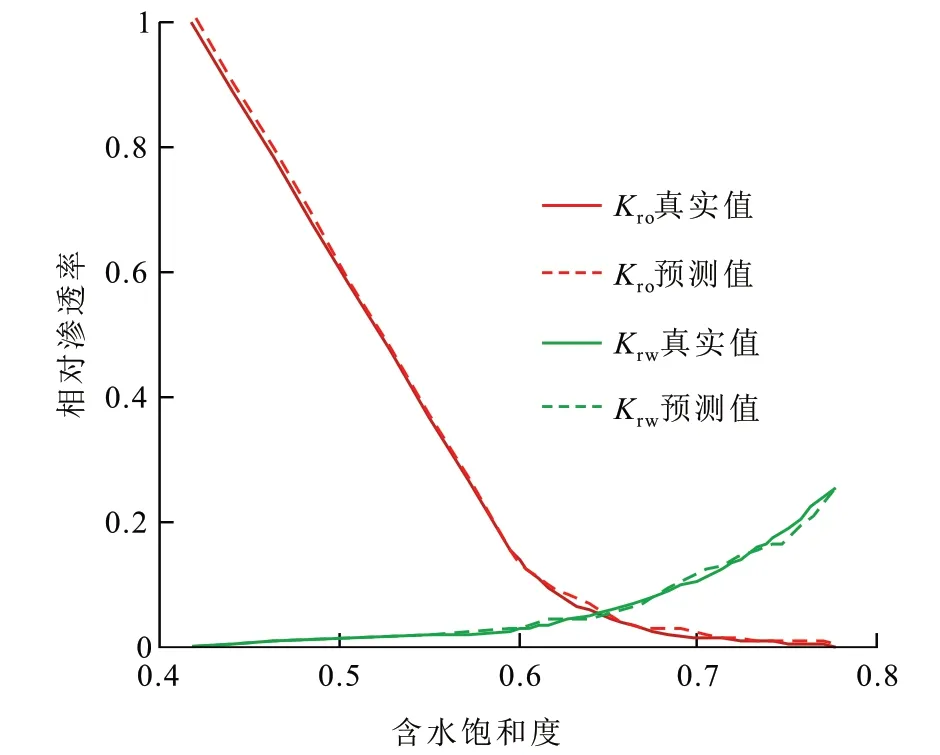
图3 相渗曲线预测值与真实值对比Fig.3 Comparison between predicted values and true values of relative permeability curves
3.2 实例应用
为便于水驱储层预测模型的应用,研发可视化展示功能,通过确定区块及预测层段,自动提取测井资料,即可实现油水相渗曲线的动态生成。基于本文得到的预测模型,生成1 543 口井的相渗曲线数据,应用于孤东七区西馆上段63+4、孤东油田七区西馆上段52+3、孤岛油田中一区馆陶组3-6、孤岛油田西区馆陶组3-4、坨21块沙二段9等5个水驱储层区块单元的数值模型建立。相渗数据主要用于模型中剩余油分布和高耗水条带判识方面,采用不同层段相渗曲线赋值代替使用平均值,充分反映层间及层内的非均质性,提升建模准确度。以孤东油田七区西馆上段52+3含油饱和度分布为例,常规做法是取该单元或相似单元的残余油饱和度,取值为0.21,但利用模型预测结果,获得129 个不同井层相渗曲线,残余油饱和度为0.15~0.37,充分体现油藏模型的非均质性,该区块建模精度提升0.056。该成果实现油藏不同空间位置相渗曲线的赋值,广泛应用于区块研究中,大大提升油藏区块或单元相渗曲线的获取效率。
4 结论
基于机器学习算法的水驱储层相渗曲线仿真预测优势在于能够实现每口井每个层段的相渗曲线预测,利用储层相渗预测模型,预测精度大于90%,能够达到矿场应用精度。该方法不受实验条件、油田开发阶段等限制,充分利用油田测井资料,实时生成井层相渗曲线,准确反映油藏渗流特征和储层渗透率变化规律,为油藏工程研究中油田、区块、井组等不同层级提供相渗数据,并解决油藏工程数值模拟时目标块都用同一条相渗曲线的问题,使数值模拟更准确。
猜你喜欢
测井技术(2022年3期)2022-11-25
小资CHIC!ELEGANCE(2021年25期)2021-07-29
西南石油大学学报(自然科学版)(2018年6期)2018-12-26
西南石油大学学报(自然科学版)(2018年2期)2018-06-26
西南石油大学学报(自然科学版)(2018年1期)2018-02-10
电测与仪表(2016年12期)2016-04-11
少儿科学周刊·儿童版(2015年7期)2015-11-24
中国煤层气(2015年4期)2015-08-22
西南石油大学学报(自然科学版)(2015年4期)2015-08-20
中国质量与标准导报(2015年2期)2015-02-28
