
声景生态学数据分析与应用
2022-11-26 08:18王静怡李春明林婴伦李大锋
生态学报 2022年21期
王静怡,李春明,林婴伦,李大锋
1 中国科学院城市环境研究所,福建省流域生态学重点实验室,城市环境与健康重点实验室,厦门 361021
2 中国科学院大学,北京 100049
3 福建农林大学资源与环境学院,福州 350002
4 广东省林业科学研究院,广州 510520
声景生态学是研究景观中生物与非生物声音在多种时空尺度下的声学格局与过程,揭示声音与人类,以及声音与自然之间关系的学科[1],由Pijanowski和Farina开创,吸纳了景观生态学、生物地理学、声学生态学及生物声学的内涵,具有多学科交叉融合的特征(图1)。Pijanowski认为对声景的研究可参考景观生态学中不同尺度上格局与过程的交互,以及生物地理学中不同生物物理梯度中物种分布和多样性的变化来进行,声景生态学还吸收了声学生态学[2]中人对环境声音感知为核心的研究,并拓展了聚焦于单个物种或物种间对比的生物声学[3]的研究范围。采用社会生态系统的研究方法,更关注宏观群落声学,并且更强调景观中声音的生态特征及其呈现的生态环境的多维时空格局与动态变化。
Pijanowski基于景观生态学[4—5],结合“人与自然耦合系统”[6]理论,提出了声景生态学的概念性框架(图1),指出生物声、地理声和人类声共同组成了完整的声景(图1-层次Ⅱ),且三者之间相互作用(图1-层次Ⅲ)。同时,还提出了6个研究领域:(1)声音的测量和量化,(2)不同尺度的时空动态分析,(3)揭示声景与环境协变量的联系,(4)评估声景对生态系统的影响,(5)评估声景对人类的影响,(6)评估人类对声景的影响[1](图1-层次Ⅳ及①、②及③)。
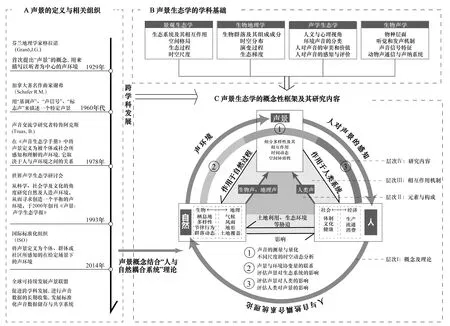
图1 声景生态学的产生、概念性框架及其研究内容
随着存储介质成本的降低及网络传输技术的进步,声景大数据逐渐形成。尽管Pijanowski所提的6个研究领域已为声景生态学数据的应用指明了方向,但由于对声音这类非结构化数据的分析存在困难,目前有关声景生态学研究内容和技术方法的研究案例仍然较少。本文从声景生态学的研究内容出发,详细介绍了声景生态学数据在声景元素解析、生物多样性评估、人类身心健康三大应用领域的前沿分析方法;梳理了从各类传统方法到新兴的机器学习方法的技术细节与优劣势对比;并从数据分析技术的优化与标准化以及与多学科融合的方面对声景生态学数据分析方法的发展进行了展望,以期为声景生态学数据分析方法的完善和应用领域的拓展提供参考。
1 声景元素解析
1.1 人工识别
声景元素的解析是声景生态学研究中的基本内容。传统的方法主要依靠人工识别,除了由动物学专家根据鸣声频率高低、时长、婉转程度等显性特征进行具体物种的识别之外,在实际研究中应用更为广泛的是通过直观的听觉感知进行声源识别和分类。包括研究者基于其声景专业知识事先进行研究空间内声源类别的定义与划分,进一步将其用于声景感知的问卷调查或实验室模拟感知等研究中。如侯建鑫等[7]在城市公共开放空间中,通过实地考察、网上查阅及居民访问确定城市公共开放空间中存在的42种主要声音,进一步进行各类声音愉悦程度和烦恼程度的问卷调查;甘永洪等[8]在厦门市集美区的城乡视听景观研究中,通过实地声景观调查记录样点的声音类型,将其划分为地质声、生物声和人工声三大声景元素,并基于此开展实验室声景观认知评价;周武忠等[9]将城市公园声景观区分为人工声、自然声、生活声和历史文化声四大类别,选取江阴市的市中心公园进行城市公园各类声景观的调查与评价分析;刘江等[10]在德国瓦尔内明德区的城市多功能区中进行声景信息的标准化主观记录,识别出人工声、生物声、地理声三大类具体27种通俗可辨识的声源,并绘制出反映声景组成时空动态的声源地图。也有学者强调公众对于声源的感知,利用问卷直接获取特定场地中常见的声景类型。如马蕙等[11]在城市公园声景观要素定量分析中,通过在问卷中设计“在公园中常常能被感知到的声音是什么?”这一问题,引导公众对声源类别进行识别,由此确定了交通噪声、流水声、喷泉声、鸟鸣声、风声、波浪声和海鸟声7种用作声学心理实验的声音刺激。
1.2 机器识别
机器学习算法可根据声音特征进行分类,实现声景元素的解析。首先,采用等长向量计算其特征,其中关键是找到特征向量的表示形式,使其成为某物种某一特定类型鸣声的参考向量。然后,根据提取的特征向量进行分类,可采用无监督方式[12](如自组织映射网络),或有监督学习方式(如支持向量机[13],决策树[14])来实现声元素的识别。
机器学习算法尤其是深度学习虽能快速和批量地实现物种识别,但和人工识别结果仍然存在差距。Priyadarshani等[15]对自动鸟类识别技术进行了综述,介绍了当前常见的鸟鸣识别软件,包括SoundID、Raven Pro、Song Scope、Sound Analysis Pro 2011、Avisoft-SASLab Pro、Arbimon、Kaleidoscope Pro,以及R语言中的monitoR包。然而,总体而言这些工具仍不能满足物种识别的需求,背景噪声及鸣声微弱的问题仍然是应用时的主要挑战,导致识别结果存在假阳性及假阴性。假阴性主要由于目标物种发声微弱或检测阈值设置而造成;假阳性的原因则有很多,如自然地理或人工机械噪声的影响或物种之间高相似度造成误判等。另一方面,机器学习算法的输入也会影响精确度,如以频谱图作为输入时,一些短促的鸟鸣声和雨滴声的频谱图相似,导致声源的可观测属性重叠,此时机器将难以识别,但人类可以通过听觉有效区分。实际上,频谱图作为算法输入会导致许多时间精细结构信息的丢失,应该进一步改进算法,以完整的音频数据作为输入实现聚类和鸣声识别[16]。
一些优化策略也可以用作机器学习算法的改进,包括进行相关知识的迁移学习或综合人工识别与机器识别的优势。比如可以结合监测对象的相关知识,进行迁移学习或多任务学习。如Chen等[17]在热带蝙蝠的识别任务中,开发的Waveman软件,通过绘制物种的系统发育树来说明种群之间的遗传关系,并将其嵌入到蝙蝠网络(BatNet)网络中,最终实现36种热带蝙蝠物种的自动识别,各物种的识别准确率均在86%以上,总体精度超过90%。也有研究采取自动聚类和人工验证相结合的半自动化方法。其中,自动聚类方法可以过滤噪声,减少后期人工审查的工作量,而通过回放音频或目视解译频谱图进行人工审查可以减少假阳性,二者结合可以一定程度上提高识别结果的准确度[18]。
总体而言,进行声源分类的人工识别方式不需要过于专业的专家知识,常结合问卷调查用于城市开放空间的声景研究或实验室声景模拟研究,但这种方法无法进行具体的物种识别。基于专家知识的人工识别可以实现物种识别,准确度高,但耗时长,可推广性差。而机器学习的方法基于大量音频数据库自动提取数百万个特征,从而有效捕捉物种内的特定变异,实现更准确的自动识别。
2 生物多样性评估
声学生态位假说[19]、形态学适应假说[20],与声学适应性假说(Acoustic Adaptation Hypothesis)[21—22]为通过声音来反映生物多样性的合理性提供了理论基础。目前通过声音进行生物多样性评估的方法主要有基于声音能量和频率的声学指数法,以及基于声音特征的语谱图和机器学习法。
2.1 声学指数法
声学指数是通过统计声学能量分布,得出关于声音时频或振幅的复杂程度、异质性等信息[23],从而间接用于反映生物的多样性。声学指数种类繁多,典型的包括时间熵(H[t])、频谱熵(H[s])、声学复杂指数(ACI)、声学丰富度指数(AR)、声学均匀度指数(AEI)、标准差异声景指数(NDSI)、声学多样性指数(ADI)等[24]。当前使用较广泛的声学指数计算软件包括MATLAB、SoundscapeMeter2.0[25],及R语言中的Tune R、Seewave、Soundecology程序包[26—27]。
随着研究者对各类声学指数的深入理解以及计算软件的发展,声学指数广泛应用于生物多样性评估领域。同时,越来越多的学者针对声学指数的指标性能展开研究。然而由于研究对象和所使用的数据集存在差异,难以从各类研究得到的声学指数评价中总结一致的结论。Gasc等[28]提出声学指数代表物种丰富度的三个标准:(1)在衡量生物多样性时对噪声不敏感;(2)在指示物种多样性时对同一物种的不同个体识别不敏感;(3)在指示物种丰富度时受物种均匀度和鸣声之间的重叠影响小。然而他的实验研究表明,没有一个声学指数可以同时满足三个标准。
另一方面,使用声学指数进行生物多样性评估还存在其他局限性:(1)绝大多数指数对噪音敏感,需要在分析前对音频进行降噪处理,预处理步骤更复杂且会造成一定程度的信息丢失[29];(2)实际应用较复杂,需要综合考虑数学与生态意义,即单一的声学指数往往难以说明问题,需要进行加权组合才更加适用,此外,指数需要进行归一化处理,或当其最大值、最小值具有生态意义时,才便于使用[24,30];(3)声学指数存在阈值问题,难以检测微弱的或是超过阈值的鸣声,当声学特征存在冗余或存在高频声音的重叠时,声学指数对生物声音的预测也会达到阈值,使得指数只能在低于这一阈值所代表的生物多样性的群落中有效地应用[28, 31];(4)声学指数虽然能在局部环境下预测关键的生态指标,但无法在更大的生态梯度上发挥作用[32],也无法转换并适用于新环境[33],即相同或相近的声学指数数值在不同的生态系统下的生态内涵可能具有较大的差异,难以反映大尺度下时空格局的过程演变。
总体而言,声学指数的信息特征有限,对指数的生态学解释也仅适用于特定区域,且需要结合目标物种的声学特征,进行有针对性的指数选择。另外,还需进一步分析不同鸣声类型(强/软,持续/零星)、不同植被结构、采样半径等对指数分析的影响。
2.2 语谱图分割法
语谱图用于生物多样性评估,包括基于语谱图的鸣声识别以及识别特定鸣声后的声音特征分析。鸣声识别可以结合频率进行阈值设定,采用中值剪切方法,即当频率超过了语谱图相关列和行的中位数的预定义倍数时,这些信号会被识别为鸟鸣,相关的图像处理技术如基本形状形态学方法可用于改进这一过程[34—36]。另外,可以选取合适的滤波器剔除非目标音频信号,以便进行后续特征分析。
通过鸣声识别提取目标物种音频后,基于语谱图进一步进行声音特征的分析。蒋锦刚等[37]认为声学指数针对的通常是声景结构或功能的某一方面,具有一定的局限性。另一方面,传统的频谱分析主要应用统计分析方法评估频谱特征的复杂性和差异性,缺少图像时频结构特征的分析。基于此,他将遥感领域的面向对象图像分割技术引入语谱图分割,在完成鸣声识别后,进行图像纹理和几何结构信息的提取,最终提出适合于自然界鸟类生物多样性提取的知识规则和斑块统计分析聚类方法,充分挖掘了音频文件中的时间-频率结构特征,提供了多维度的生物叫声综合特征分析,包括频谱图中斑块数目反映的鸟类生物叫声和多样特性、斑块面积周长比反映的鸟类叫声婉转度,以及斑块时长反映的鸣声长短等丰富的生态信息参数。
语谱图分割的方法不需要对音频文件进行降噪处理,能够反映声音频率随时间的变化特征,但处理过程中人为参与较多,如阈值和分割尺寸的设定,主观的经验性因素会对结果造成影响。且此方法不适用于缺乏清晰度的微弱鸣声,在长时间的声景监测数据中的应用效果也未得到验证。另外,如何将语谱图中提取的斑块属性与生物鸣声特征联系起来进行定量分析仍是需要解决的问题。
2.3 机器学习法
利用特定的机器学习算法实现鸣声识别或分类之后,可采取一定的数据处理技术实现生物多样性的评估。包括直接以聚类结果的个数指示生物多样性,或对聚类结果进行一定的数学运算作为物种生物多样性评估的预测数据。也可以通过可视化聚类结果,呈现生物多样性的时间、空间特征。
Xie等[38]基于声学事件检测(AED)技术和多标签学习方法,提出了一种估算青蛙群落鸣声活动和物种丰富度的智能系统。具体而言,使用随机森林进行声学事件检测,以过滤掉未包含蛙鸣的音频,而对于丰富度计算,则是使用线性预测编码系数(LPCs)、梅尔倒谱系数(MFCCs)、线性倒谱系数(LFCCs)、声学复杂度指数(ACI)、声学多样性指数(ADI)和声学均匀度指数(AEI)六个声学特征训练三个多标签分类模型并进行音频的分类,最后分别通过AED和多标签学习的结果进行累积计算,从而预测青蛙群落鸣声活动丰富度和物种丰富度。 Ulloa等[39]设计了一种新的方法用以自动检测音频结构,称为声学多样性多分辨率分析,其目的是基于音频特征将声学群落分解为若干基本成分(即声学类型)。首先通过短时傅里叶变换检测感兴趣区域(ROIs),然后通过频率中值估算和二维小波分析来表征这些ROIs,最后使用基于模型的子空间聚类技术对ROIs进行分组,使ROIs自动注释并聚类为特定的声音类型,声音类型的个数即作为该环境的声学类型丰富度。 Sethi等[33]采取VGGish(一种类视觉几何组模型)的卷积神经网络(CNN),将音频样本逐个输入具有11个权重层的视觉几何组(VGG)模型,生成128维的特征,进一步通过“统一流形逼近与投影(UMAP)”降维工具,将聚类结果降至二维以此可视化,揭示了其声景数据在生态(不同生境质量)、时间(季节与昼夜)、空间(不同地理位置)三方面的结构,以此反映生物多样性的时空信息。与传统的反映低维度特征的声学指数方法相比,将音频样本置入共同的高维特征空间能够避免特定生态系统产生的偏差,从而准确地量化大尺度下生境质量的时空变化,并实现异常声音事件的监测。
机器学习的方法在声景监测的鸣声识别和分类中具有广泛前景,目前受限于训练数据集的缺乏,机器学习方法的有效性仍待验证和发展。但其在生物多样性评估中的应用将随着声景监测网络的建设、声音标签库的丰富、神经网络等深度学习方法的改进,可能成为生物多样性实时评价技术的突破口。
3 人类身心健康评价
在声景研究的发展进程中,众多学者利用声景数据,结合社会学、心理学或生理学的理论与方法进行声景评价。如采取愉悦度、丰富度等反映声景感知的心理学指标,或反映压力水平的皮质醇等生理学指标,或利用脑成像、神经成像等生理医学领域的方法进行声景认知的研究,并进一步揭示评价结果与人类身心健康的关系。研究表明,积极的声景对健康及生活质量存在潜在的正效益。如Hunter等[40]通过实验研究创造性地提出“自然药丸”的处方,实验结果表明每天20—30分钟置身自然环境可以大大降低应激激素皮质醇水平,从而提高工作效率和生活质量。Liu等[41]结合眼动追踪实验与传统主观心理测量,指出鸟鸣伴虫声、流水或轻音乐伴古刹钟声可以显著降低脑力负荷,积极的自然声音和山顶景观有利于缓解游客心理压力;Erfanian等[42]研究了心理健康和人口统计学因素对人类声景感知的影响,研究数据结果显示以自然声音为主导的地点,声景的愉悦度最高;Jo等[43]基于视听交互视角,研究人类行为特征对城市公园声景感知的影响,指出自然声音可以减少听者困惑和不愉快的感觉,人发出的声音在降低公园平静感的同时增加了对公园活力的体验感;Buxton等[44]通过文献综述及荟萃分析方法,研究国家公园中自然声音及其分布的健康效益,他结合心理学上的注意力恢复理论与压力恢复理论,指出自然界的流水声和鸟鸣声对身心治愈和压力纾解的作用最大。
声景在生态保护、公共健康等方面发挥着积极的作用,反映生物多样性的自然声音对民众身心健康具有重要的服务功能。随着近年来公共卫生事件的爆发,城市人居环境与公众健康研究快速发展[45],应进一步加强声景与人类生理、心理健康的相关性研究,从而为声景促进人类健康、缓解公共医疗压力的研究提供理论依据。
4 结论与展望
4.1 技术进步下的声景研究发展趋势
随着声元素标签库的丰富、人工智能技术的发展,以及声景大数据的形成,声景生态学数据分析技术得到了快速发展。目前已在声景元素解析、生物多样性评估、人类身心健康评价等方面得到了应用,充实了声景生态学的研究内容。声景生态学数据分析技术的发展正在经历从人工到机器、从单一特征计算到多维特征提取、从单学科研究到多学科联合分析的状态,并不断拓展着声景生态学的研究深度与广度。
4.2 加强分析技术的优化与标准化
目前,神经网络算法与深度学习在自动识别与聚类分析方面的优势得到显著体现,但需要进一步优化和标准化,以此提高方法的通用性和研究结果的可比性。各种途径的分析技术也存在一定的局限性,如声学指数法存在阈值和通用性差等问题,语谱图分割法则面临不同设备频谱图的差异问题,机器学习的方法在神经网络的超参数设置中也存在标准化问题。这意味着要实现标准化及可比性,应开发移植性更强的声学指数,统一语谱图分析中频谱图规格和提取方法,或优化神经网络模型结构和参数设置。逐渐形成声景生态学自身的技术方法体系,进而基于标准化的声景数据分析方法实现研究结果之间的可比性。
4.3 推动声景生态学的多学科融合
从声景生态学的发展以及声景数据的综合性特征来看,注重多学科交叉融合是声景领域研究的重中之重。尽管Pijanowski已明确提出声景生态学的6个研究领域,但仍然缺乏针对6项内容的共识性结论和具体分析方法的研究,需要借助其他学科的理论体系及技术手段进行声景生态学的理论突破与深入剖析。声景作为一种重要的听觉景观,同样具有显著的时空异质性,因此,声景监测可以参考景观生态学的研究方法,从大区域尺度采样,采取多尺度分析方法,充分量化其空间异质性格局,在此基础上结合时间维度,反映声景的时空格局变化。另一方面,声景监测在应用于物种识别及其生物多样性评估时,需要进一步结合物种生态学、生物声学的相关理论,明确各类物种在环境中的发声特性和相互关系,如鸟类发声存在伦巴第效应[27]。而关注人类身心健康的声景生态学研究则需要结合心理学、生理学及其相关指标,进行二者相互作用机制的研究,以此揭示声景对人类健康正向效益的定性或定量结果。还可以结合声学领域从物理、工程的角度研制灵敏度更高,频率响应范围更广,环境适应性更强的声学传感器,从而采集涵盖更多种群与生态系统的数据信息。同时结合计算机学科,进一步挖掘有针对性的机器学习方法,提高物种识别和生物多样性评估的精度。总而言之,未来的声景生态学应当灵活借鉴其他学科的智慧,进一步丰富其研究内容,并完善其自身技术体系。
猜你喜欢
诗歌月刊(2021年8期)2021-08-25
小天使·二年级语数英综合(2021年6期)2021-08-09
煤气与热力(2021年5期)2021-07-22
家庭影院技术(2020年11期)2020-12-28
家庭影院技术(2020年5期)2020-08-24
家庭影院技术(2020年6期)2020-07-27
科学大众(中学)(2019年3期)2019-05-17
汽车观察(2018年10期)2018-11-06
科技知识动漫(2017年1期)2017-02-06
少儿科学周刊·少年版(2015年1期)2015-07-07
