
基于语义分割的高分辨率场景解析网络
2022-11-24 06:56史健锋王阿川
液晶与显示 2022年12期
史健锋,相 宁,王阿川
(东北林业大学 信息与计算机工程学院,黑龙江 哈尔滨 150040)
1 引 言
基于语义分割的场景解析是计算机视觉的一个热点问题,它对于自动驾驶、机器人传感等实景任务具有广泛的应用[1]。场景解析要求提供对场景的完整理解,它预测整幅图像中每个像素的标签、位置,对其所属物体进行分类和定位[2]。场景解析有两大关键难点:高分辨率的保持和高层语义信息的获取。然而,这两个需求与卷积神经网络的设计是相矛盾的:靠近输入端的特征图拥有高分辨率和高语义信息,但是缺少边缘和细节信息;靠近输出端的特征图分辨率很低,丢失了语义信息,但是获取到了大量的细节信息。因此,如何平衡这两个难题,得到语义正确、细节丰富的场景解析算法,并降低其计算代价,从而应用于生产实践,仍然需要研究者们不断地探索。
目前最先进的语义分割场景解析框架大多是基于chen等人提出的全卷积网络(FCN)[3],去除了全连接层,通过反卷积恢复特征图分辨率成功地将图像分类网络转化为图像分割网络。自FCN之后,研究者们提出了一系列语义分割方法。Ronneberger等 人 提 出 了UNet[4],其利用一个与编码结构完全对称的解码结构逐步恢复特征图的分辨率,以进行像素的稠密估计。Badri⁃narayanan等人[5]提出了SegNet,旨在解决自动驾驶或者智能机器人问题。Yu等人提出了空洞卷积[6],可以在不增加参数的情况下改变卷积核的感受野,其提出的DRNet(Dilated Residual Net⁃works)获得了比普通ResNet[7]更好的结果。随后空洞卷积被广泛应用于其他计算机视觉任务中。Chen等人利用创新性的空洞空间金字塔池化模块(ASPP)和条件随机场(CRF)提出了DeepLab网络[8],取得了良好的效果。随后他们又利用批归一化层(BN)、深度可分离卷积、空洞可分离卷积等方法提出了精度更高的DeepLabV2、Deep⁃LabV3、DeepLabV3+系列版本[9-11],促进了图像语义分割的发展。
为了融合全局特征,Zhao等人[12]提出了金字塔场景解析网络(PSPNet),其以ResNet作 为 特征提取主干,辅以深度监督损失的优化策略,并将像素级特征扩展到特别设计的全局金字塔汇集特征,使得最终预测更加可靠,取得了当时多个数据集的最佳结果。2019年,Sun等人[13]为了解决人体姿态估计任务提出了高分辨率网络(HRNet),其以一个高分辨率子网作为第一个阶段,逐渐增加高分辨率到低分辨率的子网以形成更多的阶段,多个阶段的子网并行连接。随后他们将HRNet应用于语义分割任务,利用上采样方式融合了4条并行通路上的特征图信息,获得了优秀的分割结果。
本文从场景解析任务的两大难题出发,借鉴以往研究,提出了整体性能良好的高分辨率场景解析网络(HRSPNet)。首先,选择HRNet作为基干特征提取网络,利用其并行通路保持4级分辨率,提取不同层次的语义信息和物体细节信息。利用3级空洞率的空洞可分离卷积改进网络中的残差模块,在减少参数数量的同时提升模型分割多尺度目标的能力,进一步获取丰富的细节信息。其次,将输出的4级分辨率的特征图使用类似FPN网络图像金字塔的方式逐级链接[14],充分融合各自的信息。最后,利用改进的金字塔池化模块来汇集特征,其中不同尺寸的平均池化层可以融合不同范围的上下文信息,进一步补充语义信息从而提高分类准确率。
2 高分辨率场景解析网络框架结构
2.1 特征提取网络
目前语义分割使用的深度学习方法大多是基于FCN的网络结构,使用去除了全连接层的图像分类网络提取特征,利用一种或多种上采样方法恢复特征图的分辨率,如反卷积和反池化等,以获得预测结果。例如FCN最初使用的基干网络便是VGG,PSPNet和DeepLabV3使用的是ResNet。
ImageNet大规模视觉识别挑战赛历年的冠亚军网络均被广泛地作为特征提取网络使用,在各个领域取得了丰富的成果,如AlexNet[15]、VGG[16]、ResNet[7]等。这些网络有一个共同的特点,即均是线性结构的网络。这些网络被应用于语义分割时,去除了全连接层,此时的中间结果为多次下采样之后得到的多通道、低分辨率的特征图,因此需要使用上采样以恢复至原图像大小得到语义分割的预测结果。在恢复分辨率的过程中,难免会丢失大量的信息,使最后获得的预测结果不够细腻。
不同于目前流行的串行连接的网络,Sun等人提出的HRNet[13]是一种全新的并行体系结构。HRNet通过多个阶段不断地相互融合,全程保持分辨率,避免了下采样带来的信息丢失问题。这样的并行网络有两个优点:(1)并行结构能够保持特征图分辨率,而不是通过从低到高的过程恢复分辨率,因此预测的热图在空间上更加精确。(2)并行结构在相同深度和相似级别的低分辨率的特征表示的帮助下,执行重复的多尺度融合来增强高分辨率的特征表示。将HRNet应用于语义分割任务中的V2版本在未添加额外的模块且经过简单上采样的情况下便取得了良好的性能和预测精度[17]。HRNet的并行结构如图1所示。基于以上分析,本文选择使用HRNet作为基础的特征提取网络。

图1 高分辨率网络结构示意图Fig.1 Schematic diagram of high resolution network structure
2.2 改进HRNet的网络结构
2.2.1残差模块的改进
HRNet的特性使得模型具有很多优点,但是多个阶段之间大量重复的相互融合会产生数倍的计算复杂度和参数量,密集的特征融合也会计算大量冗余和相同的信息。因此本文选择使用空洞可分离卷积改进网络中大量使用的残差模块,在减少参数的同时提高模型性能。改进前后的残差模块如图2所示。
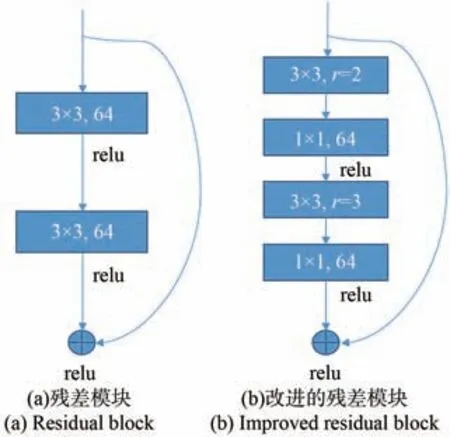
图2 改进前后残差模块示意图Fig.2 Schematic diagram of residual block before and after improvement
空洞可分离卷积使用了空洞卷积的深度可分离卷积,曾在DeepLabV3+中取得了良好的效果。常规卷积是通过控制卷积核的数量来控制输出通道的数量,而深度可分离卷积是先将输入张量的每个通道独立进行卷积运算,然后使用1×1卷积改变通道数量。在输入和输出的张量不变的情况下,深度可分离卷积能减少几倍甚至几十倍的参数数量。对于一般大小的网络结构而言,大量使用深度可分离卷积会降低模型性能。不过对于拥有上百层结构的HRNet来说,我们在CityScapes等数据集上通过多次实验并取平均结果的方式,均以1/4的参数数量实现了相同级别的分割效果。
2.2.2空洞可分离卷积叠加结构
在场景解析任务中,对于数量不均衡的多尺度物体的分割是很困难的。HRNet拥有不同的阶段并全程保持了4种不同的分辨率,在一定程度上提高了多尺度目标分割能力。为了进一步增强模型对于各种大小物体的分割能力,将空洞卷积引入深度可分离卷积中,即空洞可分离卷积。空洞卷积可以在不增加参数数量的基础上成倍扩大感受野,利用不同的空洞率调整感受野的大小。然而空洞卷积存在网格问题:在卷积核之间填充0值会使卷积过于稀疏,导致感受野仅能覆盖类似网格图案的区域,大量信息没有参与计算,在叠加使用多个不适合空洞率的空洞卷积时网格问题更加严重。出现的网格问题如图3所示。

图3 网格问题示意图Fig.3 Schematic diagram of gridding issue
因此不能简单地使用空洞可分离卷积。为了减轻网格问题的影响,我们选择使用Wang等人[18]设计的混合空洞卷积框架以减轻叠加使用空洞卷积时产生的网格问题,扩大接收野以聚合全局信息,设计了一个空洞率为1,2,3的空洞可分离卷积按顺序循环叠加的模型结构。
2.3 多阶段逐级融合的上采样结构
过去的研究者们已经证明了融合不同尺度的特征是提高性能的重要手段。其在网络的低层分辨率更高,包含了更多的空间和位置信息;在网络的高层分辨率低,语义信息更强,对细节感知较差。因此如何高效地融合二者,一直都是计算机视觉领域的重点之一。
一般来说,按照特征融合与预测的先后顺序,特征融合可分为早融合和晚融合。前者使用跳跃链接等操作,在使用融合后的特征继续训练模型,例如FCN等;后者结合不同层的分割结果以改进分割性能,例如UNet等。本文使用的基干网络HRNet的方法最初是用于人体姿态估计,后来也被用于图像分类、检测、分割等计算机视觉任务。本文针对这3种问题对基干HRNet输出的4种分辨率的特征图设计了3种后融合方式,对于语义分割问题使用的融合结构如图4所示,并将使用这种融合方式的HRNet命名为HRNetV2。
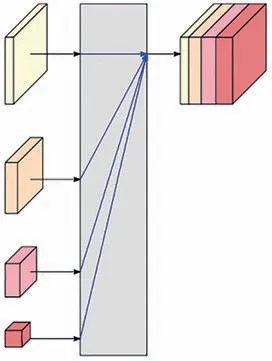
图4 高分辨率网络针对语义分割问题的融合方式Fig.4 Fusion method for semantic segmentation in highresolution networks
HRNet中多个阶段的特征提取已经反复地使用了跳跃链接、特征相加等方式进行特征融合,充分学习到了多维度的特征,但是对于其原本简单的后融合阶段,我们认为还有继续改进的空间。因此,我们重新构建了HRNetV2后融合机制:由尺寸最小的下采样32倍的特征图开始,逐级上采样进行了3次连接并使用1×1卷积调整通道数量,最后再对得到的4组特征图进行连接。
2.4 改进的金字塔池化模块聚合上下文信息
很多物体拥有相似的细节特征,缺乏收集上下文信息的能力,增加了错误分类的机会。上下文关系对于复杂的场景理解尤其重要。
以往有一些方法,例如条件随机场(CRF)等,用以计算像素间关系,补充上下文信息,优化分割结果。但是这类方法存在两点不足:一是概率图模型用于计算大量像素与像素的关系,其计算量过于庞大;二是分步骤的处理模式增加了额外的开销,在实际应用中应尽量通过端到端的方式缩减后续处理,尽可能使模型从原始输入到最终输出。基于以上分析,我们选择添加金字塔池化模块补充全局和局部上下文信息以提升模型性能。
金字塔池化模块最早是在PSPNet中提出的。它融合了4种不同金字塔比例下的特征,其4个级别池化后的特征图尺寸分别是1×1,2×2,3×3,6×6,然后通过1×1卷积将维数缩减到1/4,使用上采样恢复至相同分辨率进行连接得到最终的金字塔池化全局特征,其结构如图5所示。
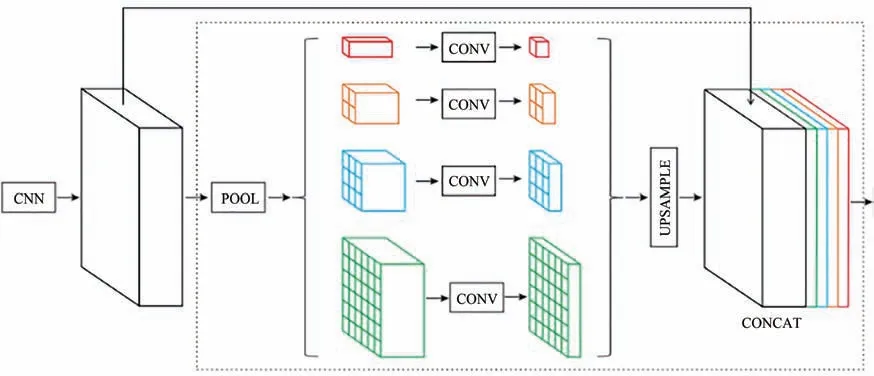
图5 金字塔场景解析网络中的金字塔池化模块结构图Fig.5 Pyramid pooling module structure in pyramid scene parsing network
不同于PSPNet最后使用的ResNet输出的1/8原图像大小的特征图,本文方法在经过逐级上采样之后输出的是1/4原图像大小的特征图。因此在一定程度上,重构了常规的金字塔池化模块:将池化核大小分别设置为输入特征图大小的1/8,1/16,1/32,1/64四个级别,形成倍数比例的金字塔池化模块,使对于不同尺寸的输入图像处理更加灵活。在本文使用的尺寸为512×512图像的输入下,4个级别的尺寸分别为8×8,16×16,32×32,64×64。对于不同大小的输入,4个级别的尺寸会有所不同。改进后的金字塔池化模块更加细腻且灵活,对于大尺寸的图像也能够较好地计算全局信息。
2.5 高分辨率场景解析网络模型结构
综上所述,高分辨率场景解析网络(HRSPNet)模型结构示意图如图6所示。网络主要由3部分组成:(1)添加了空洞率分级的空洞可分离卷积的高分辨率网络;(2)多阶段融合的上采样结构,得到一组特征图,其有不同尺度的语义信息;(3)使用改变了池化层尺寸的金字塔池化模块聚合信息,使网络对于不同尺寸的图像处理更加灵活。

图6 高分辨率场景解析网络模型结构示意图Fig.6 Structure diagram of high resolution scene parsing network
3 实 验
3.1 数据集
本文使用CityScapes[19]和Camvid[20]公开数据集进行实验。前者记录了欧洲50多个城市的城市景观,拥有30个类别,5 000张精标注图像。后者是剑桥大学自动驾驶数据集,拥有32个类别,701张图像。
3.2 评价标准
本文主要使用平均交并比MIOU来评价HRSPNet的分割效果,使用像素精度和模型参数大小来综合验证模型的优势。平均交并比的计算公式如式(1)所示:
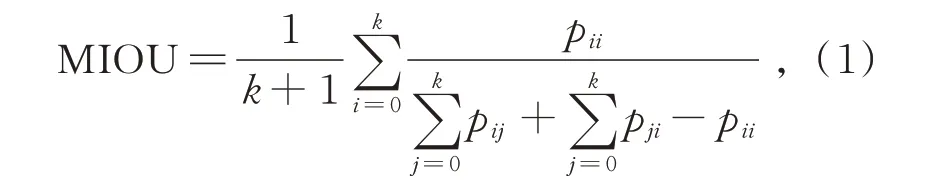
其中k代表物体类别数量,k+1为物体加背景的类别数,pij表示实际类别为i类且预测为j类的像素数目。
3.3 模型训练
实验基于英特尔i5-10400F CPU,NVIDIA GeForce RTX 2070SUPER 8 GB显卡,编程语言为python,使用tensorflow和keras进行实验。对于数据增强,所有数据集采用0.5~2之间的随机镜像和随机调整大小,并在-15°~15°之间添加随机旋转,对数据集添加随机高斯模糊。这种全面的数据增强方案使网络能够抵抗过拟合,并且在一定程度上提高了精度。在实验过程中,批归一化是十分有效的手段,提升批次大小可以产生良好的性能。由于显卡的物理内存有限,因此将经过数据增强后的数据切割为512×512大小,并在训练时将批尺寸(Batchsize)设置为4。
模型使用交叉熵损失函数和可以自适应学习率并加以约束的adam优化器。由于使用的数据集类别较多,且各类别像素分布不均衡,我们调整了各类别在损失函数上的权重,使得数量少的类别可以更加准确地预测。
3.4 实验设计
为了评估HRSPNet,本文在CityScapes数据集设置了大量对比实验,并展示了Camvid数据集上的实验结果。基线网络为HRNetV2-w48,下面将简写为HRNetV2。实验包括空洞可分离卷积和HDC结合带来的影响、使用多级融合特征的作用、添加PPM的效果等多个方面。
如表1所示,使用任何深度可分离卷积均可减少大量的模型参数,可是未使用空洞卷积或者使用固定空洞率的空洞卷积大量减少参数时,会对模型精度造成影响,后者还可能发生严重的网格效应。在所有设置中,整体使用以HDC方式组合的空洞可分离卷积可以获得最佳的性能。我们将以HRNetV2-3代表此模型,并在此基础上进行后续实验。

表1 使用可分离卷积对参数数量和平均交并比的影响Tab.1 Influence of using separable convolution on the number of parameters and MIOU
本文在HRNetV2-3的基础上添加了金字塔池化模块,进一步改善了模型的分割效果。借鉴PSPNet的实验过程,平均池化比最大池化效果更好,经过池化之后利用1×1卷积改变通道数量也会获得不同的结果。表2展示了上述实验,其中MAX表示最大池化,AVE表示平均池化,随后的数字表示池化后的通道数量。
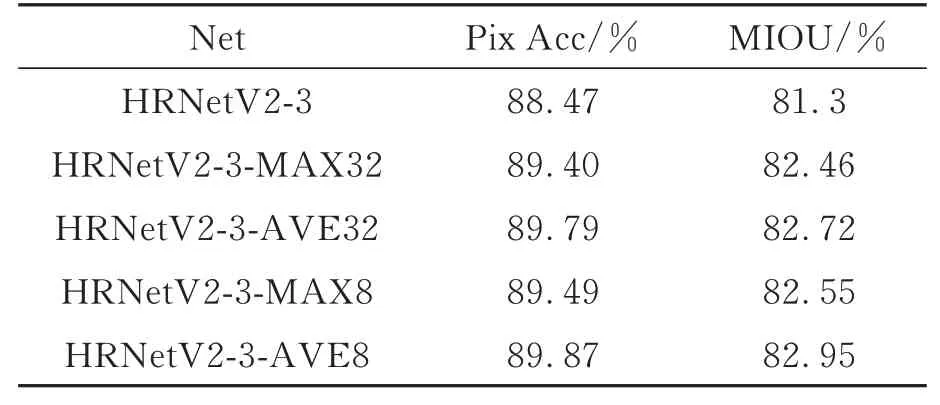
表2 金字塔池化模块对准确率和平均交并比的影响Tab.2 Influence of pyramid pooling module on accuracy and MIOU
原始的HRNetV2-w48通过直接连接4种尺寸的特征图,后接上采样的方式得到最终的语义分割结果。本文将逐级融合后输出的1/4原图像大小的特征图通过PPM取得了最高性能,如表3所示,得到了高分辨率场景解析网络HRSPNet。

表3 逐级特征融合方式的影响Tab.3 Influence of level by level feature fusion method
为了验证本文提出的HRSPNet的实际效果,选择与当前主流语义分割算法(FCN-2S、BlitzNet、PSPNet、DeepLabv3、HRNetV2-w48)进行对比实验。不同模型对于CityScapes的参数数量、平均交并比如表4所示,验证了本文方法的优势。
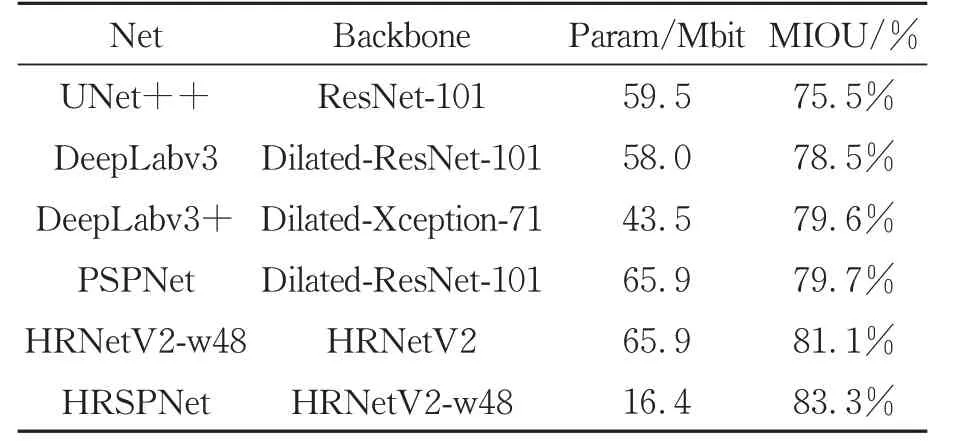
表4 不同模型的参数数量和平均交并比Tab.4 Number of parameters and the MIOU of different models
3.5 实验结果及分析
本文方法在CityScapes数据集上的实验结果如图7所示,在Camvid数据集上的效果如图8所示。

图7 CityScapes数据集上的实验结果Fig.7 Experimental results on Cityscapes dataset

图8 Camvid数据集上的实验结果Fig.8 Experimental results on Camvid dataset
实验表明:数据增强和预训练均可以加速训练,提升性能;可分离卷积可以大量减少模型参数,并且对于复杂网络模型来说,一般不会显著降低精度;目前深度学习的特征提取网络能力已经十分强大,这一点在图像分类领域已经证实,但是上采样的结构和方法仍有许多不足;金字塔池化模块可以显著改进网络性能,可以改善分割结果包含噪点的模型,在使用时,可以根据任务和任务量的不同,调整池化层的大小、池化层的类型等。
由于实验设备显存不足的原因,使用了过小的批次大小,在一定程度上会影响训练过程和精度。批归一化层文献中给出的批次大小的一般性下限为32,实验表明,在可以增加显卡数量或者显存容量的条件下,本文模型的性能还可以继续提升。
3.6 失败案例分析
本文方法在CityScapes数据集上一些失败的实验结果如图9所示。尽管相比于其他主流方法,HRSPNet在整体精度、参数数量上均有一定优势,可仍然存在一些分类失败等问题。

图9 失败案例Fig.9 Result of failure on Cityscapes dataset
通过观察、实验,我们认为失败主要有3点原因:(1)原始数据集图像分辨率为2 048×1 024像素,可以较为清楚地分辨物体细节。由于实验设备显存不足,我们将原图像使用线性插值将尺寸调整为512×512像素,数据量减少至1/8,即小于8像素的物体细节被大量舍去。原图像中分类明确的部分,在真实实验中语义可能变得模棱两可,增加了失败的可能性。例如图9中的第一张图片,圈中的自行车已经降维到肉眼难以分辨的程度,其特征接近消失,本文算法对其分割失败。(2)不同的数据集,其对于标注的处理是不同的,例如在Pascal Voc2012数据集中,海报中的人、动物会被标注为相应的类别,而不是海报标签。在本文使用的CityScapes数据集中,却与此相反。例如图9中的第二张图片,红框中的人行道的下半部分已经损坏,失去了原有的绝大多数特征,即便使用金字塔池化模块补充局部的语义信息,也难以将其分类为正确的类别。加上此处类似的照片较少,无法训练充分,造成了解析失败。(3)卷积神经网络的结构主要由卷积核来记录特征参数,这使得其处理图像分类问题取得了超越人类的正确率。但是我们认为这种结构缺少存储知识的能力。人类识别环境并不仅是依靠物体的特征与形状,更是通过物质的本身抽象出来共性。这就导致对于不同国家地区的建筑、汽车等,卷积网络在未经过相应数据集训练时,无法做到准确分类,而人类对于从未见过的风格的建筑物,仍可以做到识别。即便使用目前的补充全局、局部上下文信息的方法,本质上也是利用了训练数据中不同位置像素的位置关系,进而增加准确率。因此,对于图9中的第三张图片中生长了草坪的路台,本文方法将其分类为植物。一是由于其特征和植物几乎完全一样,二是由于其与公路的相对位置与一般植物、树木基本类似,金字塔池化模块补充的全局信息仍未将其分类正确。
3.7 展望
尽管本文方法以较少的参数数量实现了较高的精度,但仍然存在一定的问题:(1)并行通路会同时保留大量特征图,使用大量显存,难以达成训练速度和训练精度的平衡;(2)通过金字塔池化模块补充全局、局部上下文信息,在相当程度上提升了分类准确率,尤其减少了物体内部一部分分类错误的可能性,但是由于池化操作的存在,也相应增加了将包含在大物体中的小物体错判为大物体一部分的可能性。
未来的研究将专注于解决这两个问题:(1)优化主干网络结构,降低显存的实时消耗,以使用更高分辨率的输入数据、增大批尺寸(Batchsize)的大小;(2)通过额外的信息输入方式,改善当前根据特征分类、利用数据集中的上下文信息提高准确率两种方式的不足之处。进而实现更加准确、高效、低耗的场景解析方法。
4 结 论
为了能够更好地对复杂环境进行分割和场景解析,本文利用分级的空洞可分离卷积和金字塔池化模块提出了高分辨率场景解析网络。实验结果证明了结合空洞卷积和深度可分离卷积的空洞可分离卷积在多尺度目标分割和参数数量上的优势。此外,使用了金字塔池化模块的高分辨率网络可以得到良好的性能,在城市景观数据集(CityScapes)上仅以16.4Mbit的参数数量实现了83.3% MIOU的精度,在Camvid数据集也取得了良好的效果,实现了更加可靠、准确、低计算量的基于语义分割的场景解析方法。
猜你喜欢
计算机应用(2022年9期)2022-09-25
环球时报(2022-09-19)2022-09-19
软件导刊(2022年3期)2022-03-25
考试与评价·七年级版(2020年4期)2020-10-23
雷达学报(2020年3期)2020-07-13
少儿美术(快乐历史地理)(2019年2期)2019-06-12
计算机技术与发展(2019年1期)2019-01-21
智能计算机与应用(2018年2期)2018-05-23
小学教学研究·新小读者(2017年9期)2017-10-25
太空探索(2015年8期)2015-07-18
