
基于改进YOLOv3算法的交通场景目标检测
2022-11-24 06:47:02肖雨晴杨慧敏
森林工程 2022年6期
肖雨晴杨慧敏
(东北林业大学 工程技术学院,哈尔滨 150040)
0 引言
在现代交通追求更安全、更智能的背景下,自动驾驶技术发展迅速[1]。深入研究自动驾驶问题,不仅可以促进汽车与人工智能、通信等技术的深度融合,还可以推动自动驾驶生态产业的发展[2]。在自动驾驶技术中,道路交通目标的精准检测是关键的研究问题。传统算法利用哈尔特征(Haar-like feature,Haar)、局部二值模式(Local binary pattern,LBP)和方向梯度直方图(Histogram of oriented gradient,HOG)等特征与机器学习结合的方式检测识别交通场景目标,检测效率低,难以实现不同尺度目标的实时检测定位[3-6]。随着研究的深入,基于深度学习的目标检测算法凭借检测速度快的优点被广泛应用在道路目标检测[7-8]。例如,Xu等[9]利用通道注意力(Squeeze and excitation network,SENet)改进YOLOv3算法,车辆检测的速度和精度均有提升,但算法的参数量增大;Choi等[10]通过高斯建模边界框坐标,实现了检测速度与精度的良好平衡,但对图像尺寸有一定要求;Chen等[11]通过剪枝YOLOv3_tiny算法来检测车辆目标,大幅提升了检测速度,可以实现嵌入式设备应用,但对小目标和遮挡目标检测存在局限性。Cai等[12]利用可变卷积构造新型主干网络并添加特征融合模块,解决了车载计算平台资源有限问题,促进了自动驾驶的研究。
尽管基于深度学习的目标检测算法表现出强大的优越性,但交通场景目标检测仍存在多尺度信息丢失和小目标检测精度低的问题[13]。因此,本文提出一种适应交通场景的YOLOv3_4d目标检测算法。主要解决如下问题:①四尺度检测网络。在检测网络上增加一个检测尺度,获取不同尺度特征信息;②注意力残差单元。设计注意力残差单元构造主干网络(DarkNet_SE),增强特征图中关键信息的权重;③特征增强模块。利用不同卷积核的最大池化对特征图进行增强操作,获取高维融合特征,提高目标检测精度;④损失函数。引入GIoU函数对边界框回归,优化反向传播过程,替换置信度损失函数为Focal函数,平衡正负样本,增强算法的鲁棒性。
1 交通场景目标检测难点
1.1 小目标检测精度低
交通场景中小目标覆盖区域较小,检测十分困难。图1中绿色框为未检测出的目标。经过分析,小目标检测困难的原因主要有以下3点[14-15]:①特征信息较少。小目标在图像中占用像素少,标注面积占比小,特征信息不易提取,且易受噪声、遮挡等因素干扰,进而无法精准定位;②卷积神经网络下采样率大,在卷积神经网络下采样提取特征过程中,输出特征图尺度不断缩小,当下采样率大于小目标尺寸时,传递的特征图则不能包含需要的小目标信息;③正负样本分布不均。常用数据集包含的小目标样本数占比少,而中、大样本数居多,在训练过程中,算法会更加关注中、大目标样本而忽略小目标样本,从而使小目标样本不能充分训练,造成小目标检测困难。

图1 小目标检测效果Fig.1 Small targets detection effect
1.2 多尺度目标信息丢失
道路场景中存在车辆由近及远、由远及近的尺度变化情况[16]。图2中,道路目标种类多样,不同目标尺度变化很大,甚至同种类型目标也出现了一定程度变形等情况。车辆在行驶过程中摄像头的视角和高度存在差异,会造成多尺度信息丢失的问题,影响交通目标检测的效果。

图2 不同道路交通场景Fig.2 Different road traffic scenes
2 改进的YOLOv3算法
2.1 算法结构
改进算法由主干网络(Darknet_SE)、特征融合网络和检测网络3部分组成,如图3所示。依据卷积网络在大尺度特征图上检测小目标效果好的特点,在YOLOv3算法原有3个检测尺度的基础上,对特征融合网络和检测网络进行设计,增加1个检测小目标的大尺度特征输出图,设计的算法称为YOLOv3_4d算法。为适应新增特征图的尺度变化,特征融合网络在原先2个拼接模块(Concat)的基础上新增1个拼接模块,同时在主干网络后增加1个特征增强模块。主干网络第3个残差块输出的64×64特征图通过1次上采样与第2个残差块输出的特征图128×128进行拼接,随后交替使用3×3和1×1的卷积操作映射得到张量数据(YOLO_Head)。主干网络输出的4、8、16、32倍下采样的特征向量,经过一系列特征融合形成具有4层检测层的检测网络,分别对小、中、大目标独立检测。
由表1可知,主干网络(DarkNet_SE)由5个残差块组成,每个残差块由多个注意力残差单元构成,注意力残差单元由卷积层(Conv2d)和注意力(SE)模块组成。其中,Conv2d是基本组成构件,包括卷积,批归一化和Leaky Relu激活函数。注意力残差单元可以获取高维信息,在远景小目标的检测上考虑更加充分。
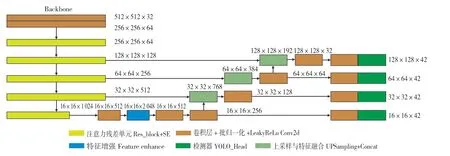
图3 YOLOv3_4d算法Fig.3 YOLOv3_4d algorithm

表1 主干网络Tab.1 Backbone network
2.2 注意力残差单元
通道注意力(SENet)模块易于实现,并且很容易引入现有的算法框架中,不仅如此,SENet模块能够显著改善网络的特征提取能力,并且对算法的负面影响较小[17-19]。SENet结构如图4(a)所示,将SENet模块改进,提取深层次图像语义信息。
注意力残差单元结构如图4(b)所示,具体实现如下内容:①输入为特征图H×W×C,经过2层卷积(Conv2d)处理,特征图的尺寸与通道数保持不变;②处理后的特征图通过全局平均池化层生成特征图1×1×C,然后输入第1层全连接层后特征图变为1×1×C/r,利用激活函数ReLU非线性变换后输入第2层全连接层恢复为1×1×C,r为缩放系数,取值为16;③全连接层处理后的1×1×C特征图通过Sigmoid函数生成权重系数矩阵,再将权重系数乘以对应的通道数生成H×W×C特征图。④将卷积(Conv2d)输出特征图与H×W×C特征图进行相加操作获取融合特征图。
2.3 特征增强模块
交通场景图像中含有丰富的空间与位置信息,应该充分提取其特征,提高目标检测效果。而对于目标检测任务,网络的层数达到一定数量时再继续增加,会发生精度下降等情况[20]。所以算法设计特征增强模块,利用不同卷积核的最大池化对主干网络输出的特征图进行深度提取,增强特征图的表现性能,并通过跳跃连接实现深层特征与增强特征的融合[21-22]。
特征增强模块如图5所示,输入尺度为H×W×C的特征图,使用卷积核为5、9、13的3个最大池化对特征图进行特征增强并利用Concat模块拼接不同尺度增强特征图,融合特征图尺度不变,但通道数由C扩大为4×C,再经过卷积(Conv2d)降维通道数为C进行目标预测。

图4 注意力残差单元Fig.4 Res_block_SE unite

图5 特征增强模块Fig.5 Feature enhance module
2.4 损失函数
YOLOv3算法的边界框损失采用均方差损失函数,该函数主要有2方面不足:一是4个坐标的预测是独立的,与实际情况不符;二是4个坐标没有实现正则化[23]。在此基础上,旷世科技提出IoU损失函数(公式中用IoU表示),将4个坐标看作整体进行预测,使预测更为精确。但IoU仍然有一定局限性,当2框之间没有重叠面积时,不能预测目标[24]。因此,算法引入GIoU函数(公式中用LossGIoU表示),如公式(1)和(2)所示[25]。
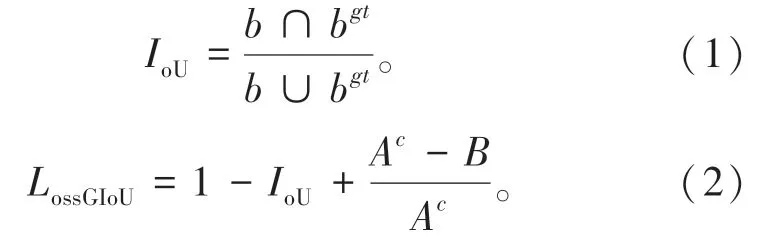
式中:IoU为预测框(b)与真实框(bgt)的交并比;B为真实框与预测框相并的面积;Ac为包含真实框与预测框的最小包闭区域面积。
此外,在训练过程中一些难以检测的正样本不能充分学习,制约交通目标检测效果。所以,算法引入Focal函数(公式中用LossFocol表示)作为置信度损失函数,如公式(3)所示。该函数是在交叉熵函数中添加动态因子,减少易分样本损失,增大难分样本损失,加强网络对难样本的学习和挖掘[26]。
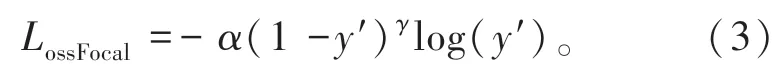
式中:α代表平衡参数,取值为0.25;γ代表聚焦参数,取值为1.5;y′为预测标签概率。
至于目标分类损失仍采用交叉熵函数(公式中用LLosscls表示),如公式(4)所示,y为真实标签概率。所以,改进算法的损失函数(公式用Loss表示)如式(5)所示。
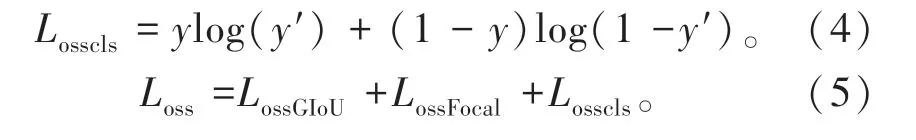
3 结果与分析
3.1 实验数据集
(1)BDD 100K数据集[27]。该数据集是目前内容最具多样性的自动驾驶数据集,共有70 000张训练图像,10 000张测试图像,包含公交汽车、交通标志和骑行人等10类目标。数据集标签采用json格式,训练前将格式转为符合YOLO算法的txt格式。为平衡不同类别样本的数量,将Train类目标去除,构建包含9类目标的交通场景数据集。
(2)VOC 2012数据集[28]。该数据集是目标检测任务的基准数据集,来自Pascal VOC计算机视觉挑战赛,共有11 540张图像,训练图像5 717张,测试图像5 823张。包含车辆、行人和自行车等20个类别,标签统一采用xml格式,需要进一步转换为txt格式。
3.2 实验环境
实验软件平台为Ubuntu 18.04系统,Cuda 10.2,硬件平台为Intel (R) Xeon (R) CPU E5-2678 v3
处理器和RTX 2080Ti显卡,内存11 G。编程语言为Python 3.6,使用Pytorch 1.6.0框架训练算法。训练时采用随机梯度下降法优化损失函数,初始学习率为0.001,批量大小为8。
3.3 评价指标
算法采用平均精度均值(mean Average Precision,mAP)作为评价指标,如公式(6)—(9)所示。其中,大(大于96×96像素)、中(小于96×96像素,大于32×32像素)、小(小于32×32像素)目标按照COCO数据集划分[29]。
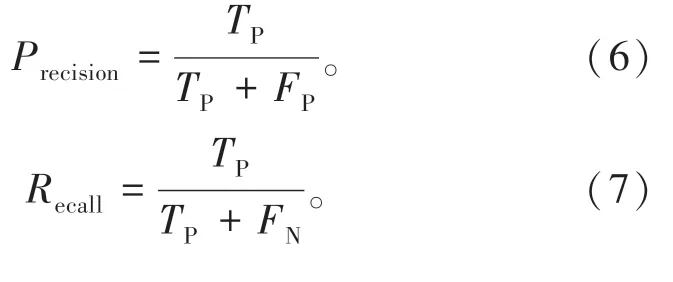
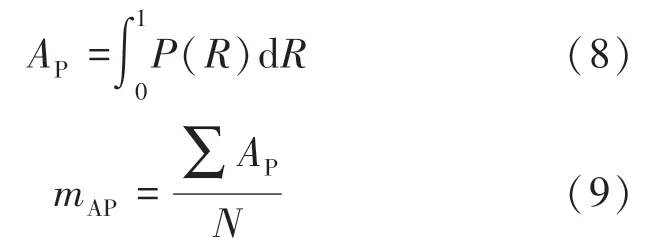
式中:TP为真正例;FP为假正例;FN为假负例;Precision为准确率;Recall为召回率;AP为准确率与召回率下的面积;mAP值越高表示算法在全部目标检测中的综合性能越高。
另一个重要的评价指标是算法的检测速度,单位为每秒帧率(Frames per second,FPS),即每秒内检测的图像数量。每秒内处理的图像越多,表示算法的实行性越好。
3.4 实验结果与分析
3.4.1 损失函数实验结果
改进算法的Loss值为组合损失函数值,由边界框损失、置信度损失与分类损失获得。实验采用迁移学习手段,在获得预训练权重下迭代10个Epoch(BDD 100K)和30个Epoch(VOC 2012),在第3个Epoch和第4个Epoch后损失函数逐渐趋于稳定。由图6可知,YOLOv3_Loss算法的损失值明显低于YOLOv3算法,并且拟合过程平稳,收敛效果好。

图6 损失函数实验结果Fig.6 Experimental results of loss function
3.4.2 BDD 100K实验结果
实验依次改进四尺度网络、注意力残差单元、特征增强模块和损失函数4个部分进行消融实验。由表2可知,当对所有模块进行改进时,算法的检测性能提升显著。相对YOLOv3算法,Ours算法的mAPS值增加了2.3%,mAPM和mAPL值分别增加了4.7%和5.4%。此外,实验结果显示注意力残差单元和四尺度检测网络对检测效果的提升更为重要。当改进四尺度检测网络时,YOLOv3_FD算法的mAP50值增加了2.2%,mAPS值增加了1.6%;而当网络添加注意力残差单元时,YOLOv3_SE算法的mAP50值大幅增加了8.6%,mAPS值增加了2.2%。虽然改进算法利用GIoU函数和Focal函数对于mAP50值来说仅仅增加了1.8%,但在网络收敛方面发挥了自身的作用。另外,YOLOv3_FE算法添加特征增强模块的mAP50值增加了1.5%。
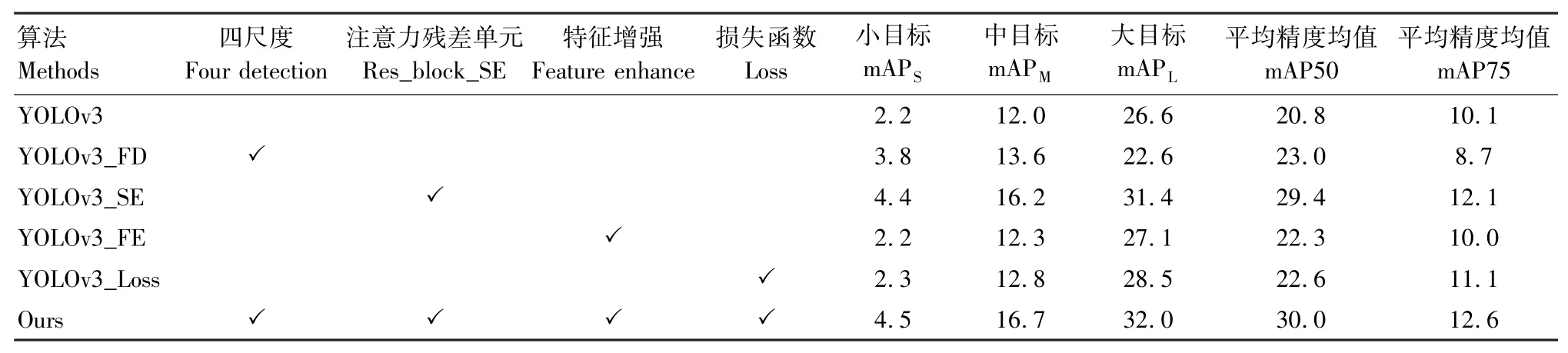
表2 BDD 100K实验结果Tab.2 BDD 100K experimental results %
3.4.3 VOC 2012实验结果
实验进一步验证改进算法的检测效果。由表3可知,算法改进四尺度检测网络、注意力残差单元、特征增强模块和损失函数4个部分的mAP50值分别为81.1%、82.3%、81.2%和81.1%。在经过多次训练后,实验发现替换注意力残差单元,YOLOv3_SE算法的mAPS值、mAPM值、mAPL值分别增加了2.7%、4.6%、2.7%,优化效果较明显。其次为增加特征增强模块,YOLOv3_FE算法的mAPS值、mAPM值、mAPL值分别增加了2.5%、4.6%、2.3%。算法增加四尺度检测对mAP值提升不大,YOLOv3_FD算法的mAPS值、mAPM值、mAPL值分别增加了2.3%、4.6%、2.2%。当对4种模块进行改进时, Ours算法的mAPS值增加了3.2%,mAPM值、mAPL值分别增加了5.1%、3.0%。改进算法的mAP50值与MAP75值分别增加了4.0%和3.1%,算法的检测精度有明显提升。
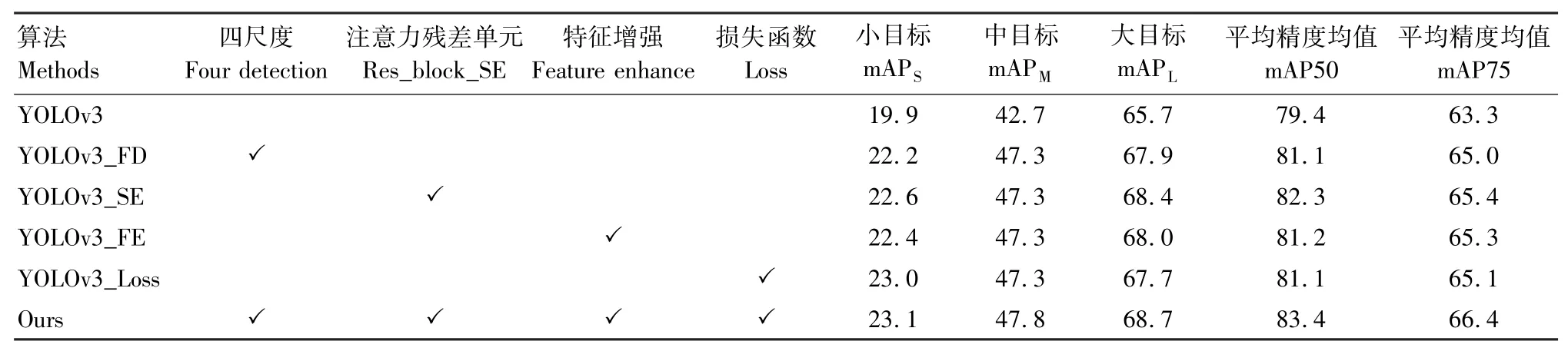
表3 VOC 2012实验结果Tab.3 VOC 2012 experimental results %
3.4.4 对比实验结果
实验将改进算法与其他算法比较,验证改进算法的有效性。由表4可知,BDD 100K数据集上,改进算法的mAP50值为30.0%,相比YOLOv3、YOLOv4_tiny[30]、CenterNet算法,mAP50值分别增加了9.2%、2.0%、21.7%。改进算法的检测速度为11帧/s,检测速度一般。VOC 2012数据集上,改进算法的mAP值相对SSD[31]、YOLOv3、YOLOv5s[32]算法增加了9.1%、4.0%、4.0%,检测速度需要进一步提高。
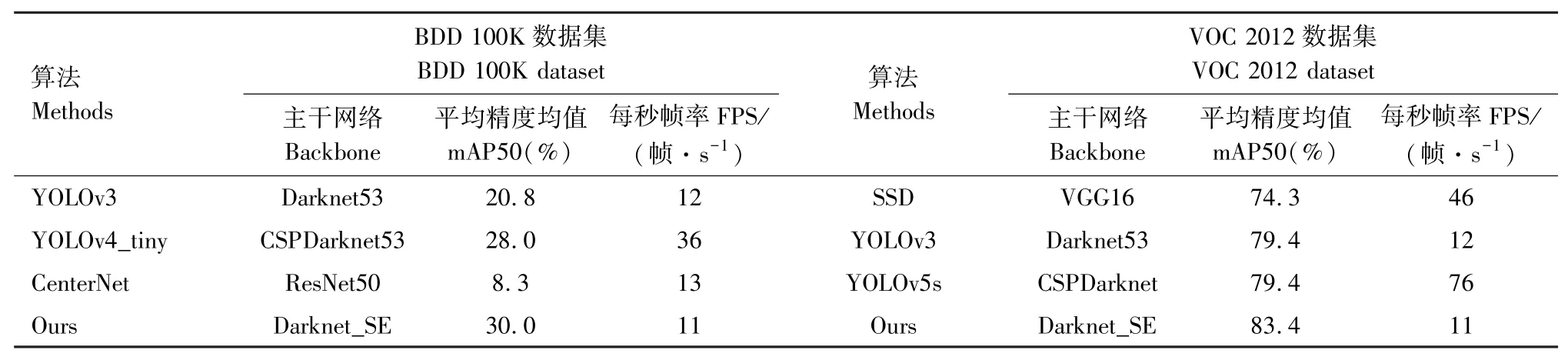
表4 对比实验结果Tab.4 Experimental results of comparison
3.4.5 算法测试
实验选取部分图像进行可视化。由图7可以明显看出,YOLOv3算法出现了部分漏检和误检现象,且对小目标检测效果较差。改进算法可以全面检测出恶劣天气环境下道路交通场景目标,鲁棒性较高,能够定位出中心点和目标框的精确位置,并且小目标的检测效果优良。但也出现了误检现象,可以进一步深入研究后处理算法等方面[33-34]。

图7 算法测试Fig.7 Algorithm demo
4 结论
针对道路小目标检测精度低和多尺度信息丢失的问题,本文提出改进的YOLOv3_4d算法。算法首先设计四尺度检测网络,有效检测不同尺度目标,缓解了不同目标尺度差异带来的信息丢失等负面影响。其次,算法设计注意力残差单元构造主干网络,添加特征增强模块,获取深层次特征信息。另外,算法引入GIoU和Focal设计损失函数,加快收敛速度,平衡正负样本。实验选用BDD 100K和VOC 2012数据集,结果表明改进算法的mAP50值分别增加了9.2%和4.0%,对小目标检测效果良好,符合交通场景目标检测应用需求。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
自动化学报(2019年6期)2019-07-23 01:18:32
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
太空探索(2016年5期)2016-07-12 15:17:55
河南科技(2015年8期)2015-03-11 16:23:52
时代英语·高三(2014年5期)2014-08-26 17:01:17
