
基于改进Faster RCNN的多尺度人脸检测网络研究
2022-11-24 05:08宋梦媛
自动化仪表 2022年11期
宋梦媛
(上海工艺美术职业学院信息管理处,上海 201800)
0 引言
计算机、网络、大数据、物联网、通信等技术[1-2]的不断发展为社会发展与人们生活带来了便利,特别是为智慧校园[3]的发展奠定了基础。智慧校园中的1个典型应用就是智能人脸检测[4]。人脸检测是计算机视觉和模式识别中的1个基本而重要的问题,是许多后续相关人脸应用的重要关键步骤之一,如人脸验证[5]、人脸识别[6]和人脸聚类[7]等。
近年来,深度卷积神经网络[8](convolution neural network,CNN)在各种计算机视觉任务中取得了显著成功。一般而言,人脸检测是计算机视觉任务中1种特殊的目标检测任务。因此,研究人员试图通过探索一些成熟的深度学习技术来解决人脸检测问题。文献[9]提出1种基于特征图融合的小尺寸人脸检测方法,解决了尺度多样性特别是小尺寸人脸给人脸检测任务带来的挑战。文献[10]提出了多尺度注意力学习的快速区域卷积神经网络(faster region convolutional neural network,Faster RCNN)人脸检测模型,用于佩戴口罩条件下人脸检测。文献[11]提出了1种基于多模型融合的可见光人脸活体检测方法。上述方法对各自领域人脸检测应用进行了研究,并取得了一定进展。然而,针对大量遮挡、低分辨率和失真图像等小样本,人脸检测仍存在一定困难。而且,大部分研究采用矩形框进行人脸检测,人脸轮廓包围不紧密。
为改善上述问题,本文提出了1种改进Faster RCNN的多尺度人脸检测网络。该网络通过预训练与多尺度训练,增强了网络鲁棒性。同时,将传统矩形回归框改进为椭圆回归框,能够更加紧密地包围脸部轮廓。
1 模型结构
本文所提基于改进Faster RCNN的多尺度人脸检测网络结构如图1所示。
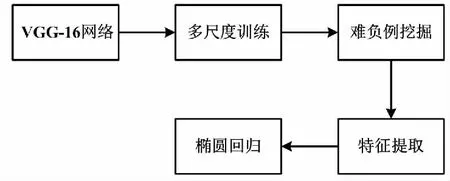
图1 基于改进Faster RCNN的多尺度人脸检测网络结构图
图1所示网络基于RCNN[12]框架,主要由以下2部分组成。
①区域候补网络(region proposal network,RPN)。RPN用于生成可能包含对象的区域建议列表,或称为感兴趣区域(regions of interest,ROI)。
②检测网络。检测网络用于将图像区域分类为对象和背景,并细化这些区域的边界。
此外,2部分网络在用于特征提取的卷积层中共享公共参数,从而使得整体网络快速收敛并完成目标检测任务。同时,所提人脸检测模型对Faster RCNN架构进行继承和扩展,进一步提升了模型训练效率和准确度。首先,使用数据增强产生大量数据集,并测试预先训练的模型,从而生成大量难负例挖掘(hard negative mining,HNM)样本。其次,将这些HNM样本输入网络进行再训练,从而提高模型鲁棒性。接着,基于特征串联策略,进一步提高模型的性能。最后,将生成的检测边界框转换为椭圆,从而更紧密地包围人脸区域。
2 模型关键步骤
2.1 HNM
HNM是提高深度学习性能的有效策略。该策略的主要思路为:考虑到难负例是网络无法作出正确预测的区域,因此将难负例再次输入网络,从而作为改进训练模型的补充。
基于HNM思想,本文从预先训练的模型中获得大量HNM样本。试验时,假设交并比(intersection over union,IOU)小于0.5。在HNM训练过程中,进一步将这些难负例添加到ROI中以微调模型,并将前景和背景的比率平衡为1∶3,通过重训练提高模型鲁棒性。由此产生的训练过程将能够改进模型,从而减少虚警和提高分类性能。
2.2 模型预训练
为了使改进的Faster RCNN适应人脸检测,本文选择在人脸检测数据集和基准(face detection data set and benchmark,FDDB)数据集上微调视觉几何组(visual geometry group,VGG-16)网络的预训练模型。然而,考虑到FDDB数据集规模较小,在微调之前,需要在大量多尺度人脸数据集上训练所提模型。
此外,为了处理个别可能会破坏训练过程收敛性的特殊案例,本文对数据集进行了清洗工作。进一步,对清洗后的数据集进行了数据增强操作,如图像缩放、平移、旋转、亮度和滤波等。不同数据增强方法的尺度如表1所示。考虑到数据增强级别过多将增加试验运行时间,本文为每种增强操作选择3种尺度,即表1表头中的尺度1~尺度3。

表1 不同数据增强方法的尺度
2.3 多尺度训练
传统Faster RCNN网络结构通常对所有训练图像采用固定的比例。通过将图像调整到随机尺度,模型能够在很大范围内学习特征,从而提高其尺度不变性性能。本文对每幅图像进行数据增强并随机分配3种尺度中的1种,然后将其送入网络进行多尺度训练。该策略可使所提模型对不同的大小图像更具鲁棒性,并提高了基准测试结果的检测性能。
首先,使用FDDB数据集对预训练的VGG-16网络进行微调,从而实现人脸检测预训练。多尺度训练网络结构如图2所示。
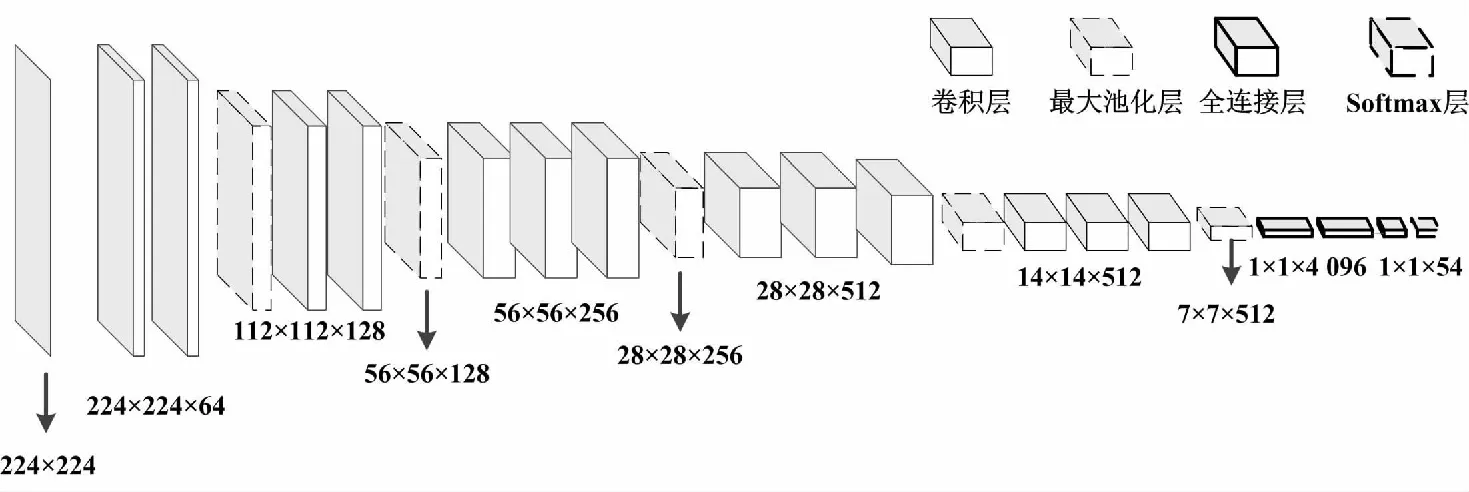
图2 多尺度训练网络结构
网络的输入为224×224的固定红、绿、蓝(red,green,blue,RGB)图像。网络结构主要由13个卷积层、5个池层和3个全连接层组成。最后1个全连接层有54个通道(数据集中包含54个身份类别)。VGG-16体系结构通过添加多卷积层来增加网络的深度,且卷积层的内核大小设置为3×3。卷积后空间分辨率保持不变,空间填充为1,卷积步长为1。下采样由5个最大池化层执行,且最大池化紧跟在一些卷积层之后(需注意,并非所有卷积层都紧跟在池化层之后)。同时,最大池化层在2×2像素窗口上以步长2执行。此外,本文选取修正线性单元(rectified linear unit,ReLU)激活函数用于卷积层和全连接层,softmax函数用于最后1层。
训练数据集用于训练模型,前向传播用于计算神经网络中不同层的输出。令卷积层的输出特征映射表示为C,则有如下运算式。
C=φ[H(x,y)]
(1)
式中:φ(·)为ReLU激活函数;H(x,y)为网络的输入特征,x和y分别为卷积层的输入和输出。
φ[H(x,y)]=max[0,H(x,y)]
(2)
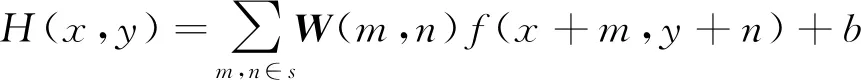
(3)
式中:W为卷积核的权重矩阵,且大小为m×n;f(·)为映射函数;b为偏置。
与tanh和Sigmoid等其他激活函数相比,ReLU函数的输出可以减少计算量,加快网络的收敛速度,且能有效改善梯度消失问题。
卷积层之后紧接着为最大池化层,所提网络设置核为2×2。池化层用于减少网络中的空间大小和参数数量,以及防止过拟合问题。令池化层的输出映射表示为P,则该层可通过式(4)计算。
P=g(C)
(4)
式中:g(·)为用于计算最大值的函数。
当池化层窗口穿过C,g(·)选择窗口中的最大值,并放弃其余值。同时,本文使用Dropout操作改善过拟合问题,且在训练阶段的每次Dropout更新概率为0.5。需要注意的是,Dropout操作不参与正向传播和反向传播,从而有助于防止过度拟合。
进一步,令神经元q处的全连接层输出表示为Fq。Fq的计算如式(5)所示。
(5)
然后,令网络的损失函数为Softmax损失函数,表示为L,并使用小批量梯度下降(mini-batch gradient descent,MBGD)方法对所提模型进行训练。具体如式(6)所示。
(6)
式中:M为一次迭代中的图像批处理数量(本文令批量大小为64);J为神经元数量;pq为神经元q处的网络输出。
最后,使用反向传播算法更新权重w,更新规则如式(7)、式(8)所示。
(7)
式中:μ为可以加速收敛的动量系数(本文令μ=0.9);Δvt-1为之前更新的权重值;α为学习率(本文取α=0.01)。
wt=wt-1+Δvt
(8)
式中:wt为迭代t时的当前权重。
α更新规则如式(9)所示。
(9)
式中:γ为Gamma函数(本文令γ=0.1);u为最大迭代步长(本文令u=250)。
2.4 椭圆回归
椭圆回归的关键思想是直接从可见部分推断相对偏移参数,从而确保更紧密地包围脸部特征。在几何学中,任意定向的一般椭圆可以由5个参数定义:中心坐标(x0,y0)、半长轴长度a、半短轴长度b(a≥b),以及旋转角度(从正水平轴到椭圆长轴)。椭圆的标准形式如式(10)所示。
(10)

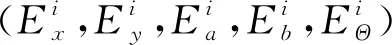
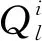
(11)
式(11)中的分子和分母分别对应于椭圆的水平切线和垂直切线。为了确定椭圆的轴对齐边界框,令式(11)中分子和分母分别等于零,故每个轴的边界框长度如式(12)所示。
(12)
式中:Δx为边界框横轴长度;Δy为边界框纵轴长度。
进一步,将正方形的包围盒扩展为椭圆边界框。其对角线长度可定义为正方形长度l。则l的计算式如式(13)所示。
(13)
3 仿真与分析
3.1 数据集与仿真环境
试验所用数据集为FDDB数据集。FDDB数据集包括2 845张图像,总共5 171张人脸。这些人脸图像质量不均,存在大量遮挡、低分辨率和失真情况,为准确识别带来了挑战。
仿真环境设置如下:数据增强算法基于Python3.8和OpenCV编译;所有深度学习网络基于Python3.8和tensorflow框架编译;所有程序均运行在CPU主频3.8 GHz,内存128 GB的intel酷睿i7 12700k,NVIDIA GTX 1080 GPU的Ubuntu 16.04工作站。仿真相关参数设置如下:在多尺度训练网络,学习率为0.001、最大迭代次数为250、参数γ为0.1、批处理大小为64、Dropout概率为0.5、动量系数为0.9、非最大抑制(non maximum suppression,NMS)阈值为0.3;在特征提取网络,学习率为0.0001、最大迭代次数为250、批处理大小为32、Dropout概率为0.2、动量系数为0.9。
3.2 模型执行
对于每个图像,在将其送入网络之前需执行数据增强操作。接着,对预先训练的VGG-16模型在FDDB数据集进行训练迭代。在整个训练过程中,RPN使用的锚框总尺寸为64×64、128×128、256×256、512×512,3个纵横比为1∶1、1∶2和2∶1。在执行NMS后,保留了2 000个候补区域。对于Fast RCNN分类部分,如果任何地面真值的IOU大于0.5,则将其视为前景;否则,将其视为背景。为了平衡前景和背景的数量,对这些ROI进行采样,并保持比例为1∶3。
然后,将上述数据集输入网络,并将输出区域的置信度得分高于0.8而IOU值低于0.5的样本标记为HNM样本。接着,对HNM样本执行再学习,确保这些HNM与其他ROI同时被采样。
最后,在FDDB数据集上进一步微调生成的模型,从而生成最终的检测模型。
3.3 交叉验证
本小节使用交叉验证思想确定数据增强方法中最佳尺度和因素的组合情况。首先,通过增强相同的原始样本,基于预先训练的VGG-16模型比较人脸检测的准确性,确定不同因素影响顺序,即图像旋转>图像缩放>图像亮度>图像平移>双边滤波>中值滤波>高斯滤波>均值滤波。进一步,对不同增强尺度进行交叉验证。表2和表3分别为图像数据和滤波数据增强识别准确率交叉验证结果。
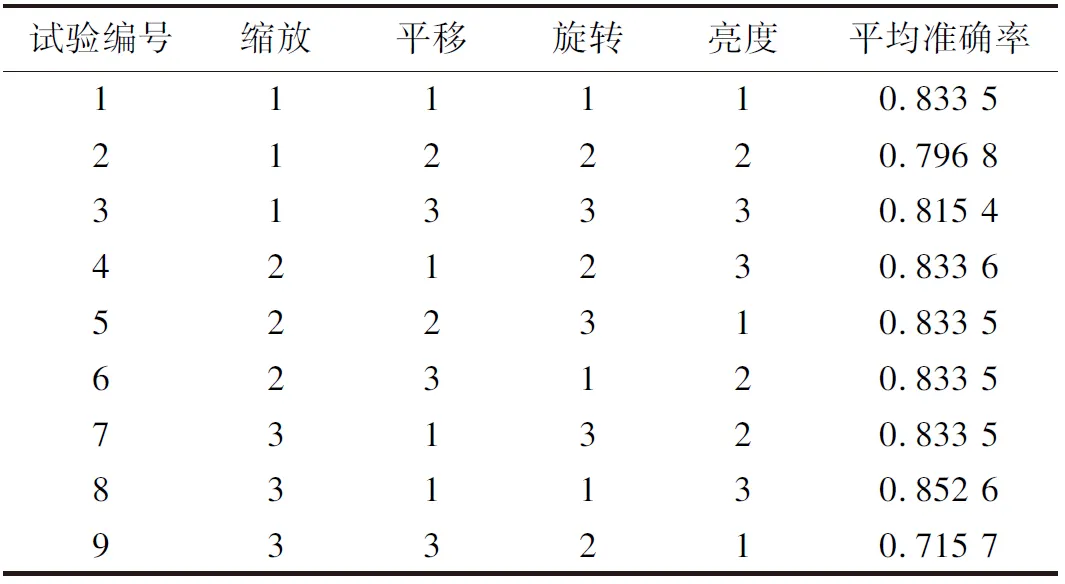
表2 图像数据增强识别准确率交叉验证结果
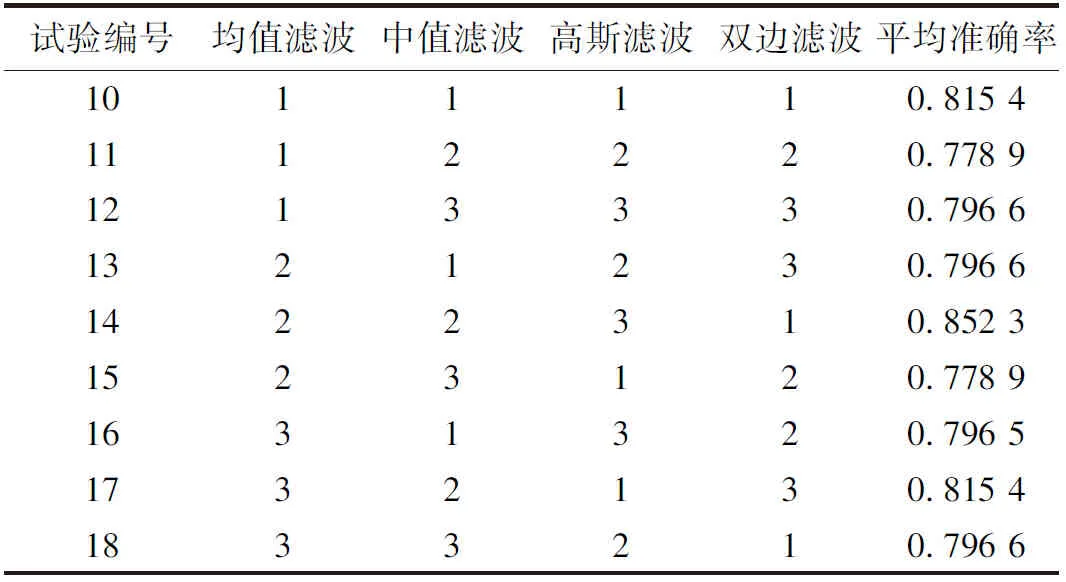
表3 滤波数据增强识别准确率交叉验证结果
由表2、表3可知,几何变换和图像亮度的最佳组合为图像缩放尺度3、图像平移尺度1、图像旋转尺度1和图像亮度尺度3;滤波最佳组合为均值滤波尺度2、中值滤波尺度2、高斯滤波尺度3、双边滤波尺度1。
采用最佳的数据增强方法对原始训练样本进行扩充。为了验证最佳组合性能,基于预先训练的VGG-16模型在HNM样本上进行训练与测试,得到的平均准确率为0.863 8。该结果表明,在少量训练样本的基础上,使用最佳组合数据增强可以有效提高人脸检测的准确率。
3.4 对比分析
图3所示为人脸检测网络部分识别结果。

图3 人脸检测网络部分识别结果
通过最佳数据增强组合形成数据集,并代入所提人脸检测网络。由图3可知,所提模型能够有效识别人脸区域。
表4所示为不同方法区域识别性能对比结果。由表4可知,所提模型识别准确率为93.38%,召回率为89.52%,F分数为91.65%。仿真结果进一步验证了所提模型性能提升明显。

表4 不同方法区域识别性能对比结果
4 结论
本文对深度学习模型进行了研究与分析,提出了1种基于改进Faster RCNN的多尺度人脸检测网络。首先,使用数据增强产生大量数据集,并测试预先训练的模型,生成大量HNM样本;其次,将这些样本输入网络进行再训练;接着,基于特征串联策略进一步提高模型的性能;最后,将生成的检测边界框转换为椭圆。所提多尺度人脸检测网络可以有效应用于大量遮挡、低分辨率和失真图像,为小样本人脸检测发展提供了参考。
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年9期)2019-05-30
动漫星空(2018年9期)2018-10-26
电子制作(2018年16期)2018-09-26
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
