
面向水声信道传输的视频编码研究进展
2022-11-23 11:35:14张洋任郭晶冯清娟杨鸿波
北京信息科技大学学报(自然科学版) 2022年5期
张洋,任郭晶,冯清娟,杨鸿波
(北京信息科技大学 自动化学院,北京 100192)
0 引言
水下视觉观测是自主式水下航行器(autonomous underwater vehicle,AUV)、载人潜水器(human occupied vehicle,HOV)等先进的海洋装备最直接、最有效的探测方式。由海洋装备采集到的水下视频图像,利用编解码技术通过水声信道传输到水面母船或工作站。水声信道作为水下装备与水面母船之间进行远距离无线通信交互的主要途径,摆脱了对传输线缆的依赖,与有线通信方式相比具有更高的灵活性。受限于声学信号的传播特性,水声信道是一个时、空、频变的多径传输通道[1],具有带宽窄、远距离传播延时高、传输易错三大缺陷。视频编码算法在满足水声信道容量要求的同时,其相应的副作用是高压缩比码流对传输差错非常敏感,码流中少数几个二进制位上的错误或丢包,即可对视频质量产生较大影响。如图1所示,由于水声信道传输差错造成接收端解码视频质量恶化,会因此干扰水上人员根据水下视频进行实时环境监测和任务下达,延误AUV/HOV作业进度。因此,水下视频编码方法在提升压缩性能的同时,必须具备抗误码能力,以确保水声传输后的视频质量。

图1 水声信道传输差错对视频质量的影响
相比于单目/单视点成像方式,多视点成像可提供更多的观测视角和更大的观测范围。如图2所示,无论是通过图2(a)所示单台AUV/HOV上装配多部相机的形式,还是通过图2(b)所示多台AUV组成分布式观测集群的形式,水下多视点成像技术均可显著提升海洋探测与作业装备的视觉感知能力,拓展其应用领域,例如AUV集群协同导航、水下目标三维重建、海底地貌绘制、海洋资源勘查、失事船舰残骸搜寻、海底油气管道检修、海洋军事防务等。另外,随着近些年水下智能物联网(internet of underwater things,IoUT)的发展,多视点成像技术也被逐渐应用于图2(c)所示的水下无线传感器网络中。针对无线水声通信速率低、延时高和传输易错这三大问题,开展水下多视点视频容错编码与传输关键技术研究十分必要,实现多视点视频数据的高效编码、快速传输和高质量解码,可达到利用水声信道实时、有效地传输深海多视点视觉观测信息的目标。

图2 水下多视点观测应用场景
本文回顾了面向水声信道传输的视频编码技术研究进展,分别介绍了水下单视点视频编码、水下单视点视频容错编码和多视点编码研究取得的成果,最后总结了现有技术存在的问题以及未来的发展方向。
1 水下单视点视频编码
在水下远距离无线通信中,水声信道的超窄带宽限制了视频数据的实时传输。我国著名的“蛟龙号”[2-4]、“深海勇士号”[5]和“奋斗者号”[6]等载人潜水器的水声通信系统,在千米级下潜范围内的传输速率约为 5~15 kbit/s,仅能传输数据量较小的单幅静态图像、文字和语音,尚未实现水下观测视频的实时输送。
目前面向水声通信的水下视频编码算法大多旨在提升压缩效率,并且是针对单视点成像系统而设计,这些算法可分为两大类:基于标准编码器的改进算法和自主设计的编码算法。
常用的视频标准编码器,例如H.264/AVC[7]、MPEG-4[8]、HEVC[9]、VP9[10]等,主要是针对数据传输率在100~1 000 kbit/s的陆上应用场合而设计的,很难在信道容量小于100 kbit/s的水声信道上发挥其编码优势。Campagnaro等[11]对比了不同的标准编码器在水声信道上的编码表现,仿真实验结果证明编码器VP9在小信道容量下的压缩效率优于H.264和HEVC,但在实际测试中VP9仅能传输分辨率为200×96、帧率为5帧/s的低质量视频。
为了匹配水声信道的数据吞吐量,有学者对标准编码器进行了改进。Avrashi等[12]在H.264的基础上,通过自适应降低帧频实现了36 kbit/s码率的高效压缩,并在解码端利用运动矢量插值完成缺失帧的重建,以恢复正常帧率。针对水下前扫声呐视频的传输问题,Mirizzi等[13]提出了一种基于区域分割的编码算法,对图像前景和背景分别采取不同码率的编码策略,并将算法嵌入到HEVC编码器中,该方法适用于帧内图像内容较为单一、易于分割的声呐视频,但不适用于含有丰富细节信息的光学视频图像。
自主设计的水下视频编码算法更多地从水下成像和水声信道的特点出发,有效去除视频序列中的空间冗余和时间冗余,克服了标准编码器在甚低比特率水声传输中存在的不足。Hoag等[14]率先提出了一种基于离散小波变换(discrete wavelet transform,DWT)的水下视频低比特率编码方法。由此,多数独立定制的水下视频编码技术使用DWT作为算法基础,以充分消除像素数据的空间相关性。Negahdaripour等[15]将小波变换与帧间运动补偿相结合,算法的平均压缩比达到150∶1。为了进一步消除视频帧间的时间冗余,Nagrale等[16]利用全局和局部运动混合补偿策略,实现水下视频高效压缩。以Li等[17]提出的小波编码树为基础,Zhang等[18]提出一种信号表征能力更强的小波变换改进算法——自适应混合小波与方向滤波器(adaptive hybrid wavelets and directional filter banks,AHWD),用于水下视频编码。如图3所示,该方法在帧内编码中采用AHWD变换,可消除图像重建中的振铃效应,获得更佳的解码质量;在帧间编码中,提出时空最小可觉察失真模型(just noticeable distortion,JND),从人类视觉感知的角度深入挖掘水下视频中的各种冗余信息,在保证解码质量的前提下兼顾了算法的编码效率。
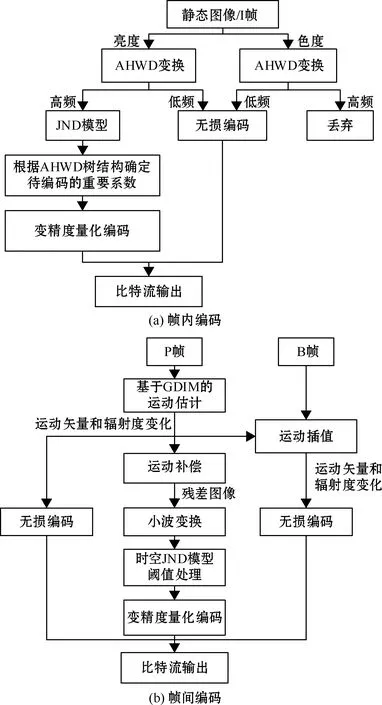
图3 水下视频帧内与帧间编码流程[18]
上述水下视频编码技术,无论是基于标准编码器的算法还是特别定制的算法,均是为单视点观测系统设计的,并且不具备传输纠错能力,传输接收端的解码视频质量容易受到水声信道传输差错的影响。
2 水下单视点视频容错编码
当视频数据以定长数据包的形式在水声信道中传输时,主要会遇到3种形式的传输差错:丢包差错、随机比特差错和突发差错[19]。水声通信调制解调器中的信道编码技术可以起到一定的抗误码作用,但会占用相当多的编码比特开支,使得视频数据本身的码字预算被削减,从而影响解码质量。如果能将抗误码技术融入视频压缩编码算法之中,既可以节省数据传输带宽,又可以得到满意的解码效果。然而,目前关于水下视频编码与传输的研究,大多数方法旨在提高压缩效率、实现甚低比特率传输,很少将研究重点放在解决传输差错的容错编码或差错掩盖方面。
针对水声信道的视频传输误码问题,Ribas等[20]设计了一种基于MPEG-4编码器和正交频分复用(orthogonal frequency division multiplexing,OFDM)调制解调器的水下视频传输系统。该系统主要依靠调制解调器中的信道编码和交织来抵抗水声信道的传输错误,误码率可控制在10-3以内。Vall等[21]进一步提升了该水下视频传输系统的抗误码性能,利用多普勒补偿算法有效抑制了由多普勒效应造成的比特差错,同时采用 MPEG-4 编码器中自带的差错控制工具,可抵抗最高误码率为1.3×10-2的传输差错。Rahmati等[22]采用 H.264/AVC编码器的扩展技术——可分级视频编码算法(scalable video coding,SVC),在SVC算法的基础之上通过多进多出(multiple input multiple output,MIMO)声学广播系统,对视频数据各编码层实现自适应多路复用传播,一定程度上可减少水声传输差错对视频质量的影响。
上述几种方法解决的是水下单视点视频传输问题,不能直接用于传输海量的多视点视频数据,也未考虑到多视点间的切换播放延时问题。
尽管像H.264/AVC、MPEG-4等商用标准编码器本身都自带差错控制技术,但它们并不是专门针对水声传输的3种误码类型而设计的,仍然存在一定的不足和局限性。
在陆上视频传输研究中,多描述编码[23-29]和冗余图像[30-31]技术也可以有效抵抗信道传输错误,但是两者都是以增加比特开支为代价的。视频压缩算法中的抗误码技术需要占用一部分码字,导致发送端不得不生成更多的数据传输包,以保证在接收端能获得相同的重建效果。然而,由于水声信道的带宽极其有限,压缩比特率上的任何改变都会直接关乎水下视频能否顺利传输。如果视频在编码端压缩后的数据比特率大于传输信道的容量,那么传输过程中的丢包率会急剧增加,从而导致在解码端视频重建质量严重下降。因此,一个理想的水下视频编码与传输系统,应当能够在压缩效率与纠错能力之间进行合理地权衡,既能实现甚低比特率传输又能有效抵抗传输错误。
3 多视点视频编码
由于声学信号的传播速度相对较慢,水声信道发送端与接收端之间存在控制指令和视频数据包的收发延时,进而造成水上用户进行视点切换时出现画面播放延时,无法达到实时传输的目的。这是现有的陆上多视点视频传输研究[32-37]无法解决的问题,因为这些研究的前提条件是收发端之间不存在信号传播延时。
为此,Fujihashi等[38]首次开展了水下多视点视频传输研究,建立播放概率模型,克服视点切换延时的问题。面向由多台AUV 组成的分布式联合成像网络,Rahmati等[39]设计了一种基于SVC的多视点视频传输方法,用于探测和调查海底垃圾污染情况。以上两种水下多视点视频传输方法,并没有考虑水声信道的实际传输差错,在实际应用场景下如何保证用户端的多视点视频解码质量不受传输错误的影响,仍是一项艰巨的挑战。
深度神经网络具备强大的学习泛化能力,为视频编码与传输领域提供了新的研究思路。近年已有学者[40-43]针对标准编码器HEVC提出了基于深度学习的改进方案,可降低编码复杂度,减少视频失真程度。在水下应用方面,Krishnaraj等[44]将卷积神经网络(convolution neural network,CNN)与DWT相融合,提出一种面向水下物联网的实时图像压缩算法。该模型在编码端利用CNN生成水下图像的紧凑表达形式,输送给基于DWT的图像编解码器进行压缩处理,经信道传输后,在解码端再次利用CNN以提高图像重构质量,经实验验证其解码效果在峰值信噪比方面,优于超分辨率CNN和标准编码器。Yu等[37]首次将深度学习方法引入到多视点视频传输研究中,利用CNN提升视频传输质量。然而,上述基于深度学习的视频图像编码与传输方法,旨在提升编码效率和解码质量,既没有围绕水下传输纠错展开研究,也不能解决水声信道特有的传输延时问题。为此,Zhang等[45]首次将CNN用于水下视频容错编码技术中,利用CNN有针对性地增加关键目标区域的编码冗余性,并与多描述编码共同组成双重码流保护机制,在水声信道有限的数据传输率下,能够最大程度地保证视频质量不受丢包差错的影响。由此可见,深度神经网络为水下多视点视频编码与传输提供了新的解决方案。
MIMO-OFDM已成为目前水声通信的主流传输模式。在MIMO-OFDM模式中,利用正交匹配追踪、压缩感知匹配追踪等信道感知算法[1],可提高频谱效率,满足水下高速传输需求。如能将视频容错编码与信道感知技术有效结合,构建一体化的数据通信系统,可实现水下多媒体数据的高速、稳定传输。
4 结束语
针对水声信道传输水下观测视频的需求,视频编码技术研究一直备受关注并不断深入。总结水下视频编码与传输研究现状,该领域依然存在许多有待解决和完善的关键性问题,可得以下结论:
1)现有的陆上视频编码方法无法克服水声信道特有的传输缺陷,不能直接用于水下视频传输。
2)现有的水下视频编码研究大多为单视点成像系统设计,未考虑到水声信号传播速率慢造成的多视点间切换与播放延时,不适用于水下多视点视频的远距离实时传输。
3)有关水下多视点视频编码与传输的研究相对较少,将深度学习方法用于抵抗水声信道传输差错是一种有效可行的方案,为面向水声传输的多视点视频容错编码研究提供了新思路。
4)在MIMO-OFDM系统中利用压缩感知算法进行信道估计,可有效提升水声信道的频谱效率和传输性能,未来可考虑将视频容错编码与信道感知技术相结合,进一步提高水下多媒体数据传输的可靠性。
因此,未来研究工作的开展方向将转变为依靠深度神经网络和信道感知技术,研发水下多视点视频容错编码与传输关键技术,同时实现甚低比特率压缩、高质量重建和无延时播放三大目标,以此来弥补水声通信自身的性能缺陷,为水下探测装备实时、有效地传输多视点成像信息提供有力的技术支持。
猜你喜欢
军民两用技术与产品(2021年1期)2021-07-28 06:05:54
电子制作(2017年22期)2017-02-02 07:10:34
电子制作(2017年19期)2017-02-02 07:08:28
福建中学数学(2016年7期)2016-12-03 07:10:28
系统工程与电子技术(2016年7期)2016-08-21 13:59:18
新闻传播(2016年17期)2016-07-19 10:12:05
河南电力(2016年5期)2016-02-06 02:11:24
新闻前哨(2015年2期)2015-03-11 19:29:22
中国水利(2015年5期)2015-02-28 15:12:40
声学技术(2014年1期)2014-06-21 06:56:22
