
一种基于预训练的固态硬盘RUL预测方法
2022-11-23 11:59王小毫陈雯柏张波刘辉翔王一群
北京信息科技大学学报(自然科学版) 2022年5期
王小毫,陈雯柏,张波,刘辉翔,王一群
(北京信息科技大学 自动化学院,北京 100192)
0 引言
数据是当代社会核心的资产,包括固态硬盘(solid state drive,SSD)和硬盘驱动器(hard disk drive,HDD)在内的存储磁盘一旦损坏,便会导致数据丢失甚至造成经济损失。根据 存储服务商Backblaze的报告[1],Backblaze公司2021年磁盘的年故障率为1.01%,一年有1 800多个存储磁盘故障。在磁盘寿命终结前完成数据的迁移和备份是十分重要的。
最常见的HDD故障预测方法是使用自我监控分析和报告技术(self-monitoring analysis and reporting technology,SMART)监控HDD,将得到的数据进行分析进而预测磁盘故障。Lu等[2]提出SMART监控数据在故障发生之前的几天时间里变化不够频繁,SMART不具有强大的提前预测能力。目前,借助深度学习提取特征的能力,使用深度学习对HDD进行剩余使用寿命(remaining useful life,RUL)预测成为主流。Pereira等[3]使用健康的磁盘建立模型,用健康磁盘来检测异常实例。Zeydan等[4]使用随机森林分类器在合理的时间内将HDD的剩余使用寿命按照临界、高和低状态进行三分类。Lima等[5]提出了一种新的类编码方法预测硬盘驱动器寿命。Wang等[6]提出自适应 Rao-Blackwellized粒子滤波器(Rao-Blackwellized particle filter,RBPF)误差跟踪报警方法,使用当前观测数据和相邻数据跟踪每个硬盘中的退化信息,进而确定HDD故障。在重建方法基础之上,Pereira等[7]还采用了潜在空间降维方法的思想,使用自动编码器的异常检测方法对HDD进行故障检测。Han等[8]提出了一个通用的流挖掘框架,用于预测具有概念漂移自适应的HDD故障。Wang等[9]针对HDD的SMART监控数据中健康和故障数据高度混合并且不平衡情况,提出了一种基于长短期记忆网络(long short-term memory,LSTM)和注意力机制的多实例长期数据分类方法来预测HDD故障。Zhang等[10]使用不同存储介质的迁移学习有效地预测磁盘故障,实现小数据下HDD模型故障预测。在长周期的预测故障中,Wu等[11]使用熵来选择最相关的预测属性来提炼SMART监控数据,提出了基于多通道卷积神经网络的LSTM(multiple channel convolutional neural network based LSTM,MCCNN-LSTM)模型来预测HDD在未来几天是否会发生磁盘故障。Basak等[12]建立了具有广泛数据预处理的在线预测方法,能够以较高精度预测一个HDD在未来10 d内是否会出故障。Coursey等[13]在硬盘发生故障前60 d,通过给出一系列HDD数据,能够以较高的准确度预测HDD剩余的使用寿命。Lima等[14]采用自定义间隔的RUL分类,对HDD预测进行更细粒度的控制,在长期分类任务中表现较好。Santo等[15]提出了一个基于LSTM的模型,结合SMART监控数据和时间,能够判断HDD在45 d内是否出现故障。
以上的寿命预测是对HDD进行分类,进而判断是否会出现故障。回归方法是在预测故障基础上预测HDD多久失效,方便管理员更深入地了解磁盘状况,并支持更好的磁盘替换计划和管理。Anantharaman等[16]直接预测硬盘驱动器的剩余使用寿命,使用随机森林和LSTM两种方法对HDD寿命进行回归预测。Lima等[17]评估了在HDD故障预测任务中两种最常见的深度学习架构:卷积神经网络(convolutional neural network,CNN)和LSTM。
在这些剩余使用寿命预测方法中,用的神经网络模型基于LSTM和CNN的居多,很少使用注意力机制,并且模型几乎全是对HDD建模预测,几乎没有对SSD的预测,这是因为已有公开的磁盘SMART监控数据中HDD的故障数据占绝大部分,而SSD的故障数据极少。因此,本文提出一种基于Transformer预训练的固态硬盘剩余使用寿命预测方法,首先在源任务上使用HDD训练一个剩余寿命预测初始模型,然后在目标任务SSD剩余使用寿命上使用样本数量少的SMART监控数据对该模型进行精调,实现对固态硬盘剩余寿命的准确预测。
1 磁盘的剩余使用寿命预测方法
本文方法中的磁盘数据包括HDD数据和SSD数据,都是二维张量,用行和列表示:列为SMART监控数据,行为每个特征的数据序列。每个磁盘的SMART二维数据经过时间窗口处理后,得到的样本尺寸表示为(w,m),其中w为窗口大小,也即样本长度,m为特征数量,这样每个训练样本X∈w×m,包含多个多元时间序列特征向量xt∈m,即X=[x1,x2,…,xt,…,xw]。
Transformer[18]是一个序列到序列模型,可以在各种序列学习任务上表现出卓越的性能。在此基础上,Zerveas[19]等提出了多元时间序列数据通用模型架构。本文方法中,首先将每个样本数据的原始特征向量xt归一化为0~1之间的数值,然后线性映射到d维向量空间,映射操作表示为
ut=Wpxt+bp
(1)
式中:Wp∈d×m和bp∈d均是可以学习的参数;ut∈d(t=0,1,2,…,w)是模型的输入向量,对应于自然语言处理任务的词向量。Transformer是一种对输入顺序不敏感的前馈架构,为了使时间序列的序列性质起作用,需要添加可学习的位置编码Wpos∈w×d,最终得到含有位置信息的输入张量:
Uin=U+Wpos,U=[u1,u2,…,ut,…,uw]∈w×d
(2)
最后将含有位置信息的张量输入到Transformer的编码器,得到样本特征的最终表示张量Z=[z1,z2,…,zt,…,zw]∈w×m。本文方法构建的是回归模型,每条训练样本对应的输出为一个数字,对应剩余使用天数,将最终特征张量Z∈w×m扁平化得到w×m,通过全连接层便得到回归结果单个样本得到的回归结果表示为:
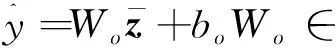
(3)
2 预训练下的剩余寿命预测方法
车万翔等[20]研究表明,预训练模型能够充分利用大模型、大数据和大计算的特点,使几乎所有自然语言处理任务性能都得到显著提升。Bodapati[21]也指出序列学习方法需要仔细调整参数才能成功。与随机初始化的序列模型相比,显然预训练的序列模型具有更好的性能。本文使用的预训练方式是参数迁移[22-23],这是因为SSD和HDD的数据都是基于SMART监控得到,数据中蕴含意义是一致的,因此使用HDD数据集做预训练可以得到不错的效果。
本文在进行SSD剩余使用寿命模型训练前,先使用HDD数据训练HDD剩余使用寿命模型。使用经过时间窗口处理和掩码处理得到的多维HDD的SMART监控数据作为输入,先经过全连接层对输入数据进行处理,得到输出对应于自然语言处理任务的词向量,紧接着添加可学习的位置编码,这样便能使时间序列的序列性质起作用,接下来将含有位置编码的向量输入到Transformer的编码器,得到的特征输出经过扁平化处理,并且按照掩码遮住部分数据,使得多维数据一维化并去掉无效数据,最后设置全连接层为一个单元,经过全连接层后得到最终HDD的RUL值。基于此得到了HDD预训练模型,最后用数据量少的SSD数据做微调。整个过程如图1所示。
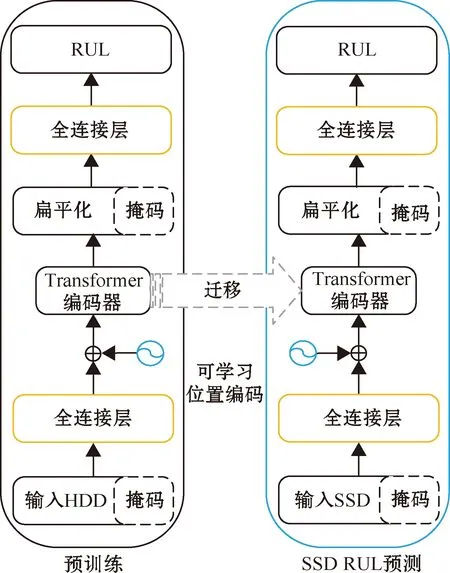
图1 预训练下SSD剩余使用寿命预测
3 实验及分析
3.1 存储磁盘数据集简介
本文使用的数据集是公开的Backblaze存储磁盘数据集[24],它包含了日常使用中HDD和SDD的SMART监控信息。从2013年到2021年,该数据中心记录了203 168个HDD以及3 760个SSD的日常 SMART监控数据。在Backblaze数据中心,维护人员每天都会对运行中的磁盘进行快照,此快照包括基本设备信息以及磁盘报告的 SMART 统计信息。SMART监控基本信息是:date、serial_number、model、capacity_bytes、failure,并且SMART数据属性不会超过255对。Backblaze记录数据中基本属性详细内容如表1所示。

表1 Backblaze记录数据中的基本属性
部分SMART监控数据的属性含义如表2所示。

表2 部分SMART属性含义
3.2 数据处理
数据集SMART监控数据至少80列,不同的SMART属性监测到的原始值具有不同量纲,为了统一计算,本文首先使用最小—最大归一化方法将所有原始值和标准化值都统一到[0,1]的范围内。每个磁盘的SMART监控数据为X=[x1,…,xi,…,xr]∈r×m,其中m为SMART属性的数量,r为磁盘从新购入使用到失效时记录到的数据的行数。磁盘特征向量每个数据需要经过最小—最大归一化处理:
(4)
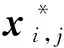
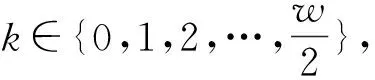
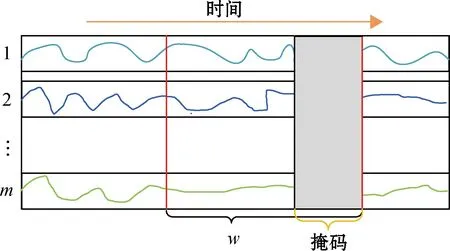
图2 滑动时间窗口和掩码
以上针对的是对于磁盘SMART数据记录条数大于等于w的情况。当数据记录不充足时,用0补齐到w,然后用掩码机制掩盖补齐的0,这样便能充分利用数据。并且当模型用于预测时,无须凑齐w条记录作为输入,大大增加了模型实用性。最后得到的训练数据为X∈w×m,对应的掩码为M∈k×m。
3.3 实验环境和数据集设置
实验在Ubuntu操作系统上运行,处理器为Intel(R) Xeon(R) CPU E5-2620 v4@2.10 GHz,训练卡为NVIDIA GeForce TITAN XP。本文使用Backblaze数据中心2015年到2017年的HDD数据做预训练。抽取3年时间的HDD失效标志数据共有4 409条,即对应共有4 409个HDD故障,其中含有重复数据22条,去掉重复数据后最终可用于预训练的HDD共4 387个,每个HDD包含从上电使用到失效的按天记录的多条SMART监控数据。预训练后使用SSD的SMART数据进行微调。SSD训练数据使用Backblaze数据中心从2018年到2022年3月底的SSD数据集,同样先筛选失效标志的数据,抽取到4年时间的SSD失效标志数据共有145条,即对应共有145个SSD故障,每条SSD数据包含SMART监控数据54个不同的原始值和对应的54个标准化值。因为不同厂商记录的SMART监控数据属性不一致,经过筛选尽可能保留不同厂商公共的SMART监控数据属性。最终每个SSD包含19个不同SMART数据的原始值和对应的19个标准化值。
针对磁盘剩余使用寿命的回归问题,本文使用均方误差(mean square error,MSE)作为评价指标,记为EMS:
(5)
式中:di为RUL预测值与真实值的差,i=1,2,…,N。MSE的值越小,模型的预测能力越好。
3.4 预测结果
预训练和SSD剩余使用寿命预测模型选取使用的SMART监控数据属性为HDD和SSD公共的属性,最终使用7组包含原始值和标准化值的SMART监控数据,对应标号是1、9、12、192、194、241、242,这里标号1对应SMART 1属性,依次类推编号242对应SMART 242属性。选取故障前60 d以内的数据作为输入,最少抽取20 d数据,加上掩码机制补齐到40 d,以有效数据的最后一天作为真实RUL输出,这样RUL最大为40 d,最小为1 d。本文方法构建的模型的参数设置如表3所示。
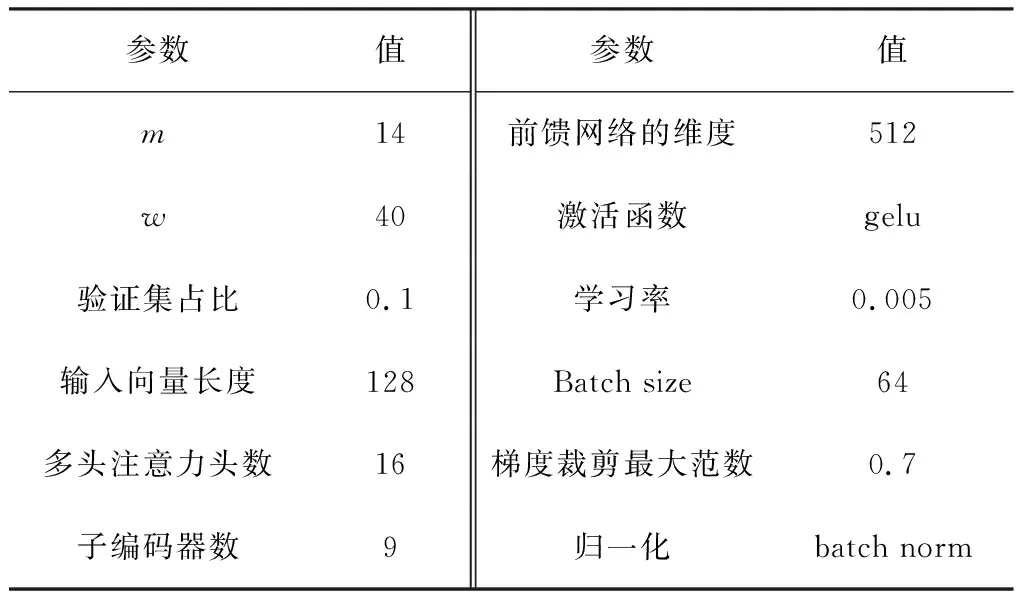
表3 模型参数
选取了预训练数据中10%的数据用作验证,训练10 000次后,预训练过程训练误差和验证误差如图3所示。
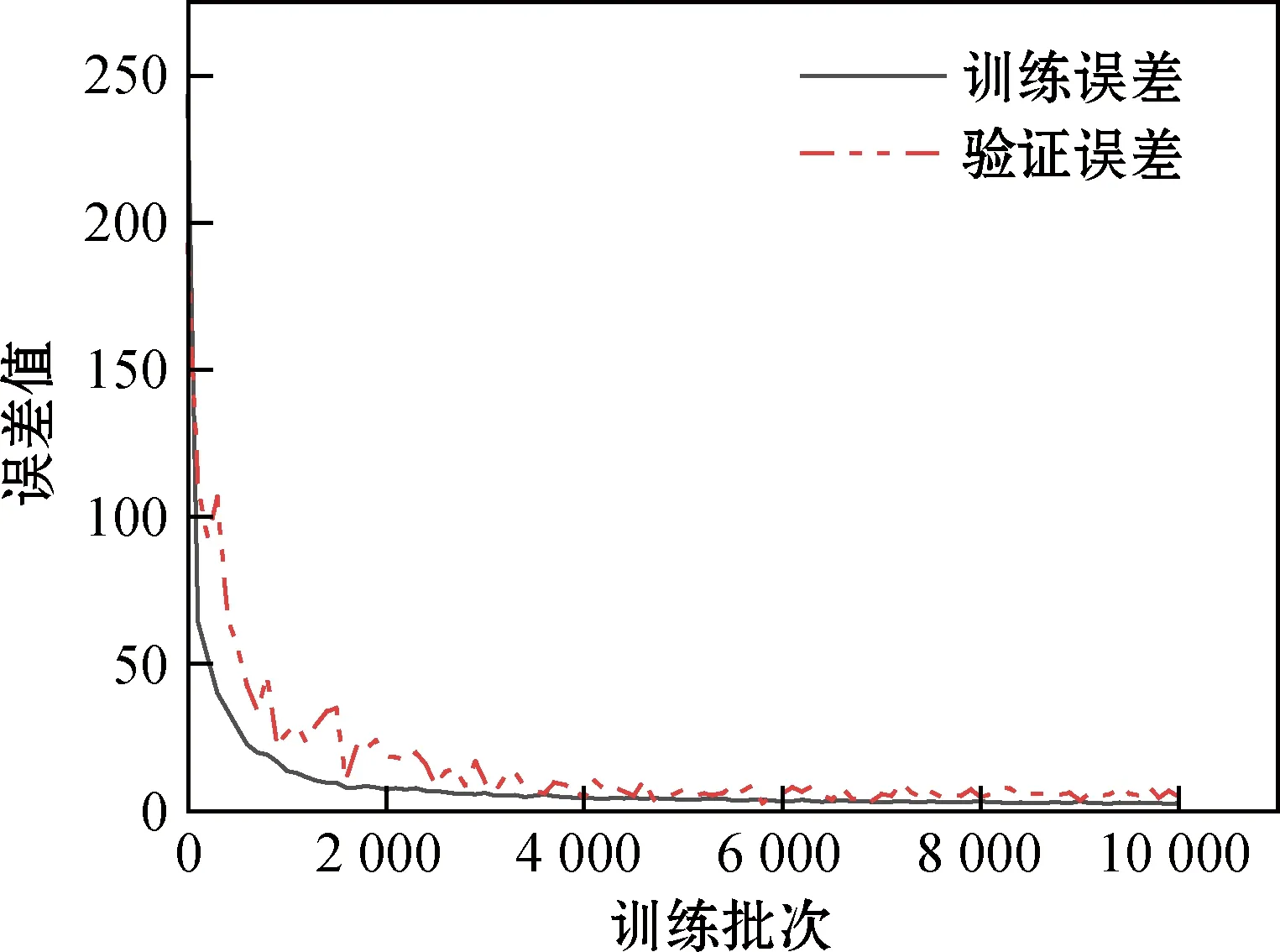
图3 预训练过程训练误差和验证误差
训练误差和验证误差下降到趋于平缓表明此模型训练到位。接下来使用SSD数据进行微调,去除RUL不到20 d的SSD数据,最后可用129个固态硬盘数据,使用60%的数据训练,剩下的51个SSD做测试,训练1 000次后,最后微调效果如图4所示。
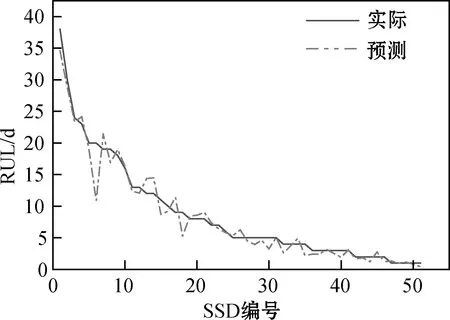
图4 目标任务微调最终预测结果
3.5 模型对比分析
目前的存储磁盘剩余使用寿命预测几乎都是对HDD进行建模预测。为了证明本文方法的可行性,用本文方法同近几年的HDD剩余使用寿命方法进行比较,所用指标有MSE、均方根误差(root mean square error,RMSE)和平均绝对误差(mean absolute error,MAE),与常用的剩余使用寿命方法LSTM[17]和CNN[18]对比结果如表4所示。
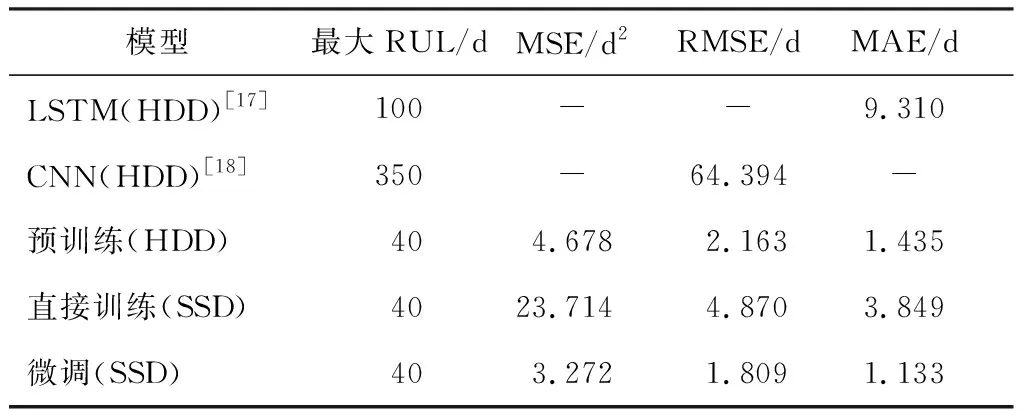
表4 存储磁盘剩余使用寿命预测模型的对比结果
由表4可以看出,在固态硬盘RUL预测(处理带有时间信息多维序列数据的回归问题)上,对于数据充足的HDD,直接使用多维Transformer模型能取得很好的效果。在数据少的时候,直接对SSD训练效果甚微,使用预训练方法能有更好的表现,能达到使用充足数据训练的HDD剩余使用寿命预测模型的效果。并且本模型在短期的剩余使用寿命预测中效果显著,所提出的方法在预测任务中非常有前景,尤其在数据不充足的情境中具有重要意义。
4 结束语
本文提出一种基于Transformer的预训练固态硬盘剩余使用寿命预测方法,通过提取HDD和固态硬盘SMART监控数据相同属性,用数据量多的HDD数据进行预训练,得到预训练模型后用数据量少的固态硬盘数据进行微调,最终实现了固态硬盘的剩余使用寿命预测。本文使用Transformer的掩码机制,使得输入数据不再局限于固定的时间窗宽度,不固定的采样增加了训练数据的量并且在实际使用中能更灵活地进行预测。
因固态硬盘数据不足的局限,本文方法目前仅能预测40 d以内的剩余使用寿命。在未来,随着固态硬盘SMART监控数据增多,我们将使用时间跨度更长的固态硬盘数据提高模型精度,以便达到更长时间的剩余使用寿命预测,并构建一个统一的磁盘使用寿命预测模型,能同时覆盖硬盘驱动器和固态硬盘。
猜你喜欢
舰船科学技术(2022年10期)2022-06-17
上海理工大学学报(2021年3期)2021-07-20
陶瓷学报(2021年1期)2021-04-13
陶瓷学报(2021年1期)2021-04-13
电脑爱好者(2019年2期)2019-10-30
网络安全和信息化(2018年2期)2018-11-09
电子制作(2017年8期)2017-06-05
网络安全和信息化(2017年3期)2017-03-10
中国公路(2017年12期)2017-02-06
网络安全和信息化(2016年8期)2016-11-26
