
基于神经网络的英语口音识别
2022-11-23 11:35刘辉翔赵云梦陈雯柏董立成
北京信息科技大学学报(自然科学版) 2022年5期
刘辉翔,赵云梦,陈雯柏,董立成
(1.北京信息科技大学 自动化学院,北京 100192;2.博鼎实华(北京)技术有限公司,北京 100096)
0 引言
世界上母语环境是英语的国家有十余个,把英语作为官方语言使用的国家有七十多个。由于本土的语言背景影响,不同地域存在英语的口音偏差,发音偏重和语速快慢均有不同,口音的特点有时会反映一个人的母语背景。人们在交流的过程中听到不同于自己的口音时,一般会非常敏感地注意到这种差异,这种偏差在一定程度上影响了交流的效果。同时口音差异也会在一定程度上影响人机交互的准确度。
语音识别是一项融合了多学科的近代新兴技术,已在智慧家居、医疗、车辆交通、电子通讯等领域[1-2]得到了广泛应用。自20世纪30年代美国贝尔实验室的Homer Dudley提出语音分析与合成的系统模型以来,隐马尔可夫模型(hidden Markov Model,HMM)、高斯混合模型(Gaussian mixed model,GMM)、梅尔频率倒谱系数(Mel-frequency cepstral coefficients,MFCCs)等关键技术陆续被应用在语音识别中。
随着深度学习的兴起,出现了深度神经网络隐马尔可夫模型(deep neural networks hidden Markov model,DNN-HMM),该模型用深度神经网络(deep neural network,DNN)对语音状态进行建模,考虑了语音的时序结构信息,使得语音状态的分类概率有了明显提升[5]。DNN超群的学习能力提升了模型对噪音、有地域特色语音的鲁棒性和准确率。此外,应用于图像识别任务的主流框架卷积神经网络(convolutional neural network,CNN)也被引入到语音识别模型中;同时,循环神经网络(recurrent neural networks,RNN)的代表模型长短时记忆(long short-term memory,LSTM)网络和门限循环单元(gated recurrent unit,GRU)网络、注意力机制(Attention)等语音识别的核心技术的发展都提升了语音识别模型的性能。
语音识别技术的提高,可以实现麦克风语音输入转文字时的高准确率,从而提升其在各个领域的应用价值,而口音识别的技术研究,可以在一定范围内提高语音识别的准确率。
本文以英语为例,根据不同地域的发音习惯来确定说话对象来自的国家或地区,提高发音分类的准确率,促进人机交互领域对已知的地域口音进行更准确的英语识别及翻译。
1 相关工作
现代语音识别系统的核心主要是三大部分:声学模型、语言模型和解码器。口音识别在国内外的研究大部分都是基于各类神经网络,如DNN、RNN等,采用的特征主要包括MFCCs、Fbank、语谱图、词汇特性等,并以识别的准确率作为口音识别分类的评估机制。
国内的研究主要是基于汉语普通话对不同地区的方言进行识别。汉语口音识别相对于英语口音识别来说,难点主要在于多音字、同音字、近音字对语句造成的影响。徐凡等[6]在2021年提出了一种融合了多种语言特征,基于自注意力的端到端的方言识别模型,在基准赣方言和客家方言两类中表现较好,模型采用了双向长短时记忆(bidirectional LSTM,BiLSTM)网络结构,在帧间特征提取方面具有优势。在汉语同音字、近音字研究上,吕坤儒等[7]提出了融合语言模型的端到端中文语音识别算法,攻克了语音模型中的误差梯度无法传递给声学模型的难点,字错误率被降低了21%。张盼等[8]针对对话语音,根据说话人口音进行自适应识别,将词错误率由40.6%降低到了20.6%。冯萌等[9]基于CNN-BiRNN-Attention模型对美国、澳大利亚、英国、加拿大、欧洲和印度6种口音进行区分,取得了86.24%的准确率以及85%的宏平均F1得分。师小凯等[10]基于极限学习机对阿拉伯、英国、中国、韩国、法国和西班牙6种口音进行区分,最终取得了82.75%的分类准确率。
科大讯飞公司[11]针对长时类的语音做了相关研究,把整句语音作为输入,通过使用卷积层的堆叠直接进行建模,建立了深度全序列卷积神经网络(deep fully convolutional neural network,DFCNN)结构。同时,阿里云的语音识别模型[12]基于前馈顺序存储器网络(feed-forward sequential memory network,FFSMN),在前馈全连接神经网络的隐含层中,通过添加一些可学习的记忆部分,同样可以获得对长时类的语音匹配性较好的模型。
国外相关的研究工作可追溯至1969年,美国佛罗里达亚特兰大大学的Melvyn C.Resnick等[13]提出了针对同种语言不同口音的语音识别分类算法,而后在西班牙语的元音质量分析、长度分析、方言等方面做了大量研究[14]。1996年,麻省理工学院林肯实验室的Marc A.Zissman[15]建立了基于音素信息的语言模型,将语言模型与音位识别相结合,应用于西班牙的古巴方言、秘鲁方言的识别,准确率达到了84%,使得口音识别的研究向前迈了一大步。
2021年,印度班加罗尔大学的Shylaja S.S.等[16]在区分印度口音和美国口音的研究中,将MFCCs特征序列连接,并在数据上应用适当的监督学习技术很好地解决了重音检测和分类问题,平均准确率达76%。Das A.等[17]进一步探讨使用单一模型进行多方言语音识别,利用LSTM网络产生的注意力权重对集合的输出进行线性组合,对美国口音、加拿大口音、英国口音和澳大利亚口音进行区分,结果表明,与基线模型相比,提出的最佳模型平均降低了4.74%的错误率。
2 基于CNN-LSTM的口音识别模型
2.1 CNN-LSTM模型
卷积神经网络[18]由于其良好的特征提取能力在各类任务中得到了广泛应用。音频特征矩阵与图像表示具有相似性,因此,CNN可被用来进一步提取音频特征的局部特征,其特征提取过程可概括为式(1)所示。
am=σ(am-1*Wm+bm)
(1)
式中:m为所在层数;a为第m层的输入;W为第m层的权重矩阵;b为第m层的偏置;σ为激活函数;*表示卷积。
CNN类模型通常是由若干个卷积层和池化层组成,其典型结构如图1所示。
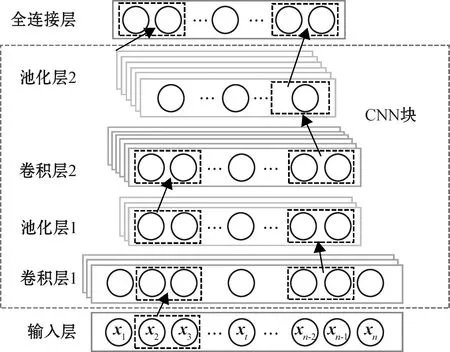
图1 CNN类模型结构
LSTM网络作为RNN的典型代表,引入了“门”的概念,借助于“记忆机制”解决RNN潜在的梯度爆炸和梯度消失问题。LSTM的内部结构如图2所示。
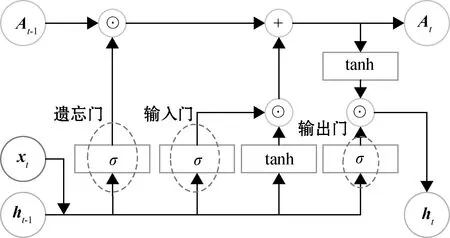
图2 LSTM的内部结构
图2中,At-1为上一阶段的信息状态,ht-1为上一阶段的隐藏状态,At为当前阶段的信息状态,ht为当前阶段的隐藏状态和输出,xt为当前阶段的输入向量。结构中,At是“细胞状态”部分,类比于神经元,“输入门”决定要在“细胞状态”中存储什么信息,“遗忘门”用来删除过去的部分特征信息,“输出门”负责更新并输出特征信息。这些门的功能类似于新的神经网络学习过滤重要信息,LSTM网络的数学表达[19]如式(2)~(6)所示。
it=σ(Wxixt+Whiht-1+bi)
(2)
ft=σ(Wxfxt+Whfht-1+bf)
(3)
At=At-1⊙ft+it⊙tanh(Wxaxt+Whaht-1+ba)
(4)
ot=σ(Wxoxt+Whoht-1+bo)
(5)
ht=tanhAt⊙ot
(6)
式中:it、ft、ot分别为当前阶段的输入门、遗忘门和输出门;Wxi、Wxf分别为输入门、遗忘门输入权重;Whi、Whf、Wha、Who为遗忘门循环权重;Wxa为“细胞状态”输入权重;Wxo为输入权重;bi、bf、ba、bo分别为输入门、遗忘门、细胞状态和输出门的偏置;ht计算LSTM的前向信息传递;⊙为哈达玛积,表示矩阵对应元素相乘。
1D-CNN-LSTM模型综合考虑了CNN和LSTM各自的优势以及语音信号的特点,其基本结构如图3所示。
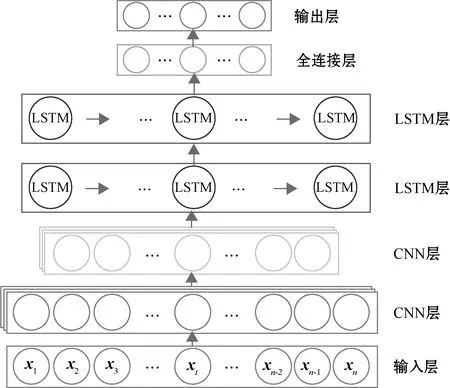
图3 1D-CNN-LSTM模型结构
1D-CNN包括卷积层和池化层,各层有卷积核和池化核,每层1D-CNN后连接最大池化层。LSTM包括两层层单元,后接全连接层至输出。
2.2 CNN-BiLSTM模型
在1D-CNN-LSTM网络的基础上,将LSTM层更新为BiLSTM,CNN层与全连接层不变,由此构建的1D-CNN-BiLSTM模型结构如图4所示。
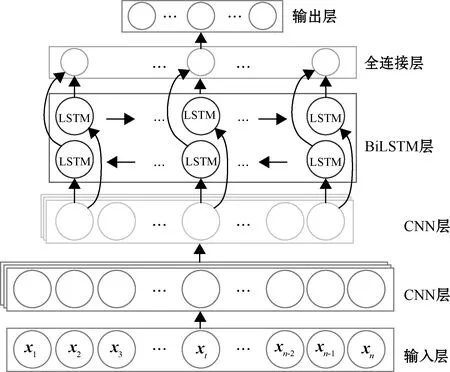
图4 1D-CNN-BiLSTM模型结构
口音的音频信息通常是对上下信息相互关联的,当前时间步的状态不仅取决于前一个时间步,还受到下一时间步的影响,双向的LSTM结构较好地解决了单向LSTM网络仅捕捉信息单向性关联这一不足,使网络能够充分利用上下文信息,做出更加准确的预测。如图4所示,在模型结构中,模型输入为前期处理过的特征矩阵,局部特征主要由两层一维CNN网络提取;全局特征主要由双向的LSTM网络(BiLSTM层)进行提取,进而连接至全连接层(Dense层),模型中用于特征提取的中间层均使用ReLU函数作为激活函数;最后,利用Softmax函数进行英语口音分类。值得注意的是,网络中添加了Dropout层来防止训练过程的过拟合。
在CNN-BiLSTM网络的基础上,将双向LSTM层中的LSTM单元更改为GRU单元,构建成为CNN-BiGRU模型,作为实验对比模型。
2.3 带注意力机制的CNN-BiLSTM模型
注意力机制在近几年来与深度学习相结合,被广泛应用于自然语言处理等领域,在语音情感识别[20]、文本分析[21]、图像分类[22]等任务中取得了较好的效果。注意力机制使神经网络对特征相关的部分投入更多的关注,对于不相关的部分则关注较少。
在CNN-BiLSTM模型的基础上引入注意力机制,对网络中传输的信息进行加权计算,增加某些特征的权重。以1D-CNN-BiLSTM为骨干网络,带注意力机制的1D-CNN-BiLSTM-Attention模型结构如图5所示。
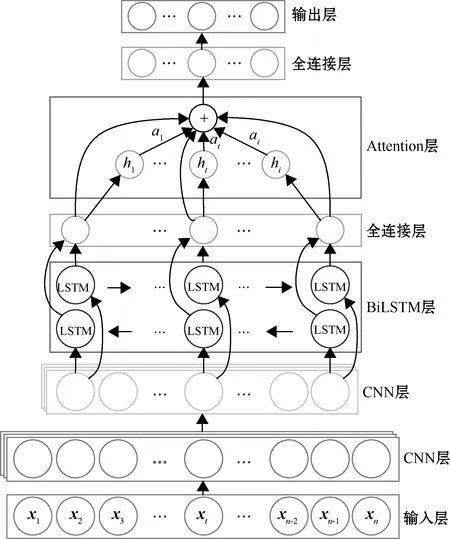
图5 1D-CNN-BiLSTM-Attention模型结构
同样地,模型输入为前期处理过的特征矩阵,局部特征主要由两层一维CNN网络提取,全局特征主要由BiLSTM网络进行提取;添加注意力模块,通过注意机制对特征赋予不同权重,其计算过程如式(7)~(9)所示;最后,利用Softmax函数计算所有加权向量的概率分布,如式(10)所示,选择概率最高的序列作为分类正确的结果序列。
at=tanh(st)
(7)
(8)
(9)
P=η(Wav+ba)
(10)
式中:st为BiLSTM层的输出序列;at为目标注意力的权重;pt是通过Softmax函数生成的类别概率的向量;v是at的加权向量;Wa为权重矩阵;ba为偏置;η为Softmax函数;P为各类序列的概率分布。
3 实验与讨论
3.1 数据集介绍
实验基于开源数据集VoxForge[23]中选取的5种地区的英语音频数据,共1 143条,从每类口音数据样本中随机抽取30例作为测试集,剩下的作为训练集,各类样本训练集和测试集的切分数量如表1所示。
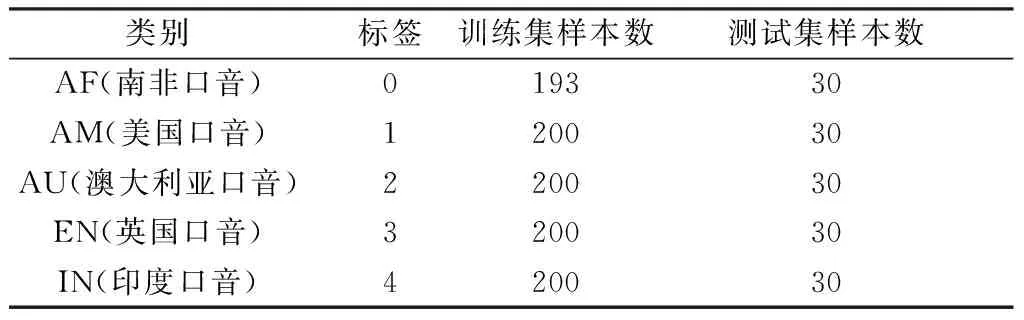
表1 实验数据集
由于MFCCs特征提取方法类似于人类听觉感知的机制,利用梅尔滤波器组模拟人耳对声音的非线性感知,可提取区分度更好的语音信号特征,使得模型鲁棒性更强。所以本文选取MFCCs作为特征,通过数据预处理、数据分帧、加窗、快速傅里叶变换、带通滤波将输入信号转化为梅尔频率,最后进行倒谱分析提取MFCCs。
3.2 评价指标
实验过程中,采用多种评价指标来综合评估模型的性能,包括准确率、精确率、召回率和F1值。其中:准确率为正确预测的样本占总样本的比例;精确率为正确预测的正样本占所有预测为正的样本的比例;召回率为正确预测的正样本占真实类别为正的样本的比例;F1值为精确率与召回率的二倍乘积与和的比值,F1值越高,表示模型的性能越好。
3.3 实验结果
1)CNN-LSTM模型
CNN-LSTM模型的超参数设置如表2所示。

表2 超参数设置
为了防止过拟合,分别在第一个CNN层、第二个CNN层和LSTM层中添加L2正则化参数为0.01、0.001、0.001,同时添加“dropout”结构和“Early stopping”策略。
实验过程中,我们首先探索了基于当前数据规模不同LSTM层数下模型的性能,实验结果表明,在1D-CNN连接两层LSTM时模型性能最好,准确率为70.0%。因此,在对比的所有模型中,均以两层1D-CNN加两层LSTM层(或一个双向LSTM层)为骨干网络。
1D-CNN-LSTM模型的综合实验结果如表3所示,实验结果表明,在5类样本中,CNN-LSTM模型在南非口音的判别方面性能表现最好,对美国口音的判别相对较好,对澳大利亚的口音判别效果一般,在英国口音和印度口音判别方面相对较差。
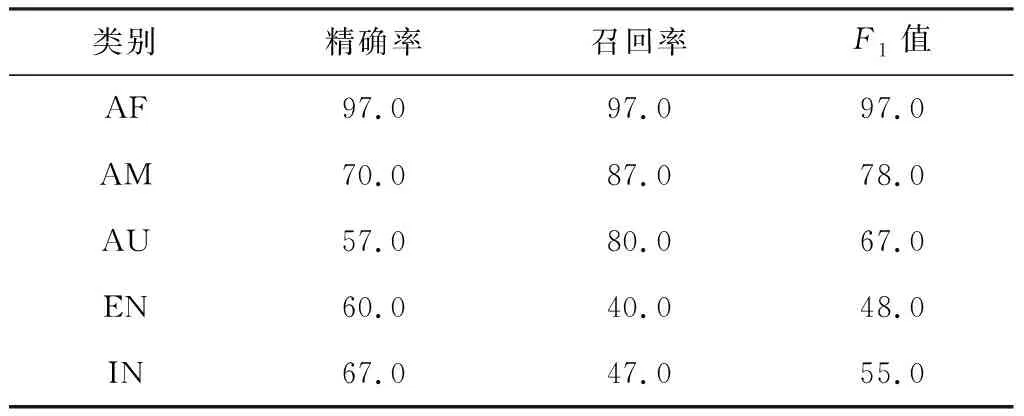
表3 1D-CNN-LSTM模型性能表现 %
2)CNN-BiRNN模型
为了尽可能固定变量,参照1D-CNN-LSTM网络模型,在1D-CNN-BiRNN网络模型中添加相同数量的Dropout层,同时在两层1DCNN和BiLSTM/BiGRU网络中分别添加L2正则化参数为0.01、0.001、0.001。
CNN-BiLSTM与CNN-BiGRU综合实验结果如表4所示,可以看到两种CNN-BiRNN模型在南非口音和美国口音的预测方面表现较好。相较而言,CNN-BiGRU模型对于南非口音、美国口音以及澳大利亚口音的识别性能优于CNN-BiLSTM模型,对南非口音的识别召回率甚至可以达到100%;但CNN-BiGRU模型对印度口音的识别准确率略低于CNN-BiLSTM模型;在英国口音识别上,CNN-BiLSTM模型表现更好,比CNN-BiGRU模型的F1值高了19%。

表4 CNN-BiLSTM与CNN-BiGRU模型性能对比 %
3)CNN-BiLSTM-Attention模型
为固定变量,CNN-BiLSTM网络部分的参数设置不变,带注意力机制的1D-CNN-BiLSTM-Attention模型实验结果如表5所示。
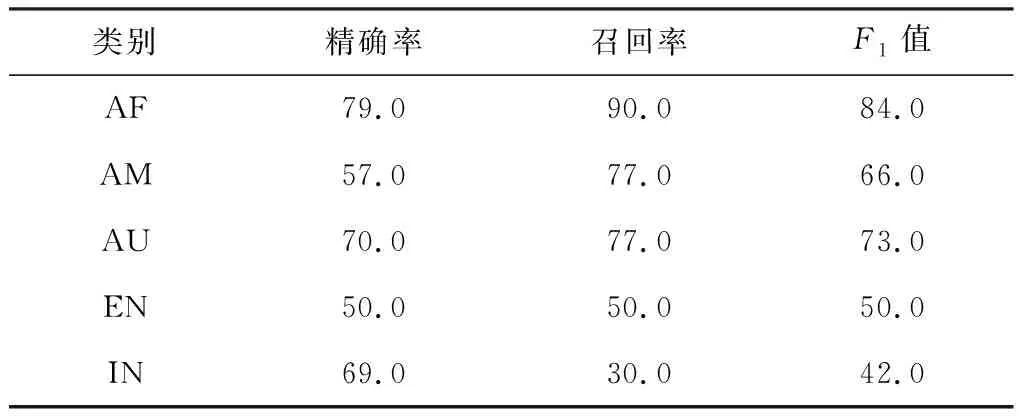
表5 1D-CNN-BiLSTM-Attention模型性能 %
通过表5,同时对比前续实验结果可以看出,各类评价指标总体上有所下降,特别地,引入注意力机制后的模型对印度口音识别的准确率降低较明显;但在澳大利亚口音识别中各指标值有小幅度的提升。
4)综合对比
基于前面的实验数据,对CNN-LSTM、CNN-BiLSTM、CNN-BiGRU、CNN-BiLSTM-Attention模型的识别性能进行了横向对比,各模型对5类样本的平均区分结果如表6所示。整体而言,CNN-BiLSTM模型取得了最佳性能表现,总体准确率达74%。
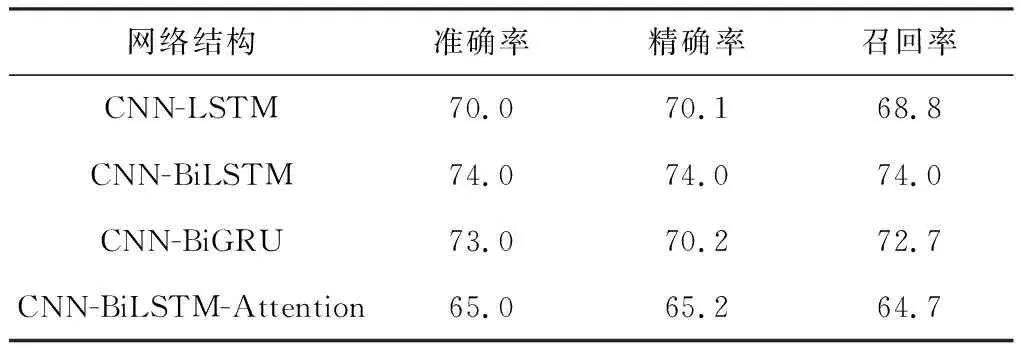
表6 不同模型的性能对比 %
此外,模型针对各地区口音的细分情况如表7所示。其中,在南非口音的识别方面,CNN-LSTM模型F1值高达97%;CNN-BiGRU模型和引入注意力机制的CNN-BiLSTM模型分别在美国口音和澳大利亚口音识别中性能表现最好;CNN-BiLSTM模型在英国口音和印度口音识别中的性能表现最好。
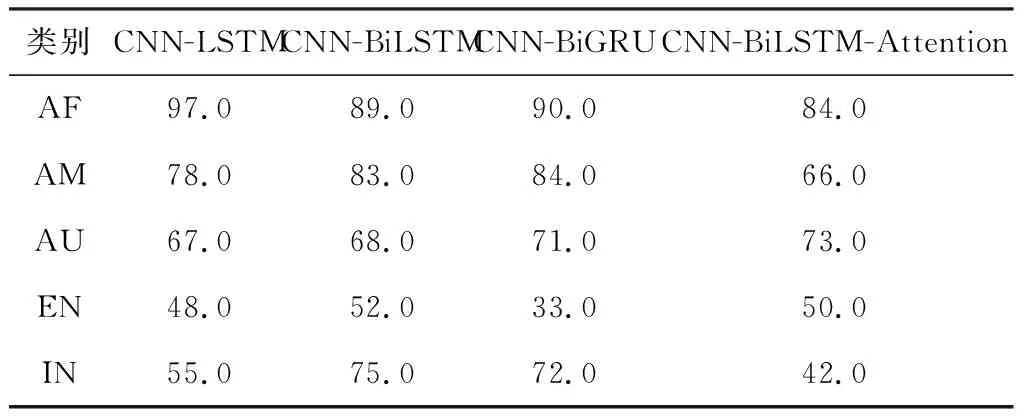
表7 不同模型在各地区口音识别中的F1值 %
4 结束语
在人工智能领域中,语音识别已然成为人们关注的焦点之一,也是有效利用人机交互的关键。本文基于神经网络对不同地域的英语口音识别展开研究。首先,提出了应用于英语口音识别的骨干网络模型CNN-LSTM;其次,在CNN-LSTM的基础上,将LSTM由单向转变为双向,各评价指标均得到了显著提升,尤其是印度口音识别的F1值提升了20%;同时,对比了两种CNN-BiRNN模型的性能,结果表明:CNN-BiGRU在南非口音和美国口音的识别中F1得分最高,分别达到了90%和84%,但CNN-BiLSTM综合性能更好,在所有任务中获得了74%的准确率;最后,在CNN-BiLSTM网络的基础上引入注意力机制,可能受限于样本规模小、模型深度较浅,实验过程中,注意力机制并未对模型性能有显著的提升。
本文开展了基于神经网络的英语口音识别研究,综合所有实验结果,模型的性能指标还有提升空间,扩充数据集后,基于注意力机制模型可能会产生更好的实验结果。除此之外,本文使用了微噪音的开源数据集,但在真实情景中,噪音对语音信号的影响可能更大,如何提升真实环境中模型的鲁棒性和泛化性也是值得探索的方向之一。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
环球时报(2020-11-30)2020-11-30
读者·校园版(2020年18期)2020-09-16
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
国际公关(2018年4期)2018-09-04
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
