
联合面部线索与眼动特征的在线学习专注度识别 *
2022-11-21 09:12武法提高姝睿李鲁越任伟祎
中国电化教育 2022年11期
武法提,赖 松,高姝睿,李鲁越,任伟祎
(1.北京师范大学 教育学部 教育技术学院,北京 100875;2.北京师范大学 数字学习与教育公共服务教育部工程研究中心,北京 100875)
一、引言
随着信息技术的发展,在线学习受到越来越多的关注,逐渐成为不可或缺的一种学习方式。与传统的面对面学习不同,在线学习打破了时空界限,学习者可以随时随地开展学习,并能根据自身需求灵活选择学习内容、合理规划学习安排。尽管在线学习具有诸多优势,但时空分离的学习方式使得教师实时监控学习者成为较大挑战,学习者也因缺少监督及与教师和同伴的情感交流而出现难以专注于学习的情况,这会在很大程度上影响学习者对学习内容的记忆与加工,从而影响学习效果,因此在线学习的专注度问题亟需得到关注与探究。为了帮助学习者意识到在线学习时自身的专注状态,并帮助教师及时了解学习者情况,以据此调整教学策略,探索有效的在线学习专注度评估方法显得尤为重要。
传统的学习专注度评估方式主要有两类,一类是由教师通过观察学习者的外部行为表现(如肢体语言、面部表情等)判断其专注程度,另一类则是由学习者进行专注状态的自我报告,这两类方法均存在一定主观性,且难以实现对专注度实时、动态的评估,无法满足在线学习的评估要求。随着数据采集技术的成熟,教与学过程变得透明化,大量学者对如何基于学习者数据实现专注度的自动分析进行了探究。其中,较为常见的一种方法便是假设学习者在处于不同的专注状态时,会表现出不同的非语言行为,因此可使用摄像头以非侵入的方式采集学习者的计算机视觉数据,从中提取相关特征,并通过不同的机器学习方法识别学习专注度,该类方法已取得了不错的识别效果。目前,体现个体外在行为表现的计算机视觉数据得到广泛关注,而反映学习者信息关注范围的眼动数据却少有用于专注度识别。先前研究已发现,眼球运动与人类的认知和大脑活动之间存在着密切联系[1][2],可识别吸引学习者注意的内容和潜意识行为。由此眼动追踪技术也常用于多媒体学习研究领域,是一种记录学习者行为与状态的有效方法[3],故同样具有识别在线学习专注度的可能。因此,本研究试图探究结合面部线索与眼动特征来预测专注度的有效性,助力实现在线学习专注度的精准识别,为优化在线学习过程、提升在线学习效果提供有力支持。
二、相关研究
(一)面部线索是识别学习专注度的有效特征
从计算机视觉数据中提取面部线索、身体姿态等特征是识别专注度的常用方法。由于在线学习场景的特殊性,身体姿态难以被完整记录,而通过高清摄像头伴随式地采集学习者的眼睛注视方向、头部姿态、面部特征等面部线索数据易在在线学习场景中实现,因此,从该类数据中提取相应特征并建立学习专注度识别模型,是诊断在线学习专注状态的有效方式,先前大量研究结论也证实了通过以上面部线索识别专注度的可行性。眼睛注视方向是通过个体眼球在三维空间中的注视点坐标识别出的视线关注点,是判断学习者是否将注意力集中于学习内容的重要依据:例如郑天阳通过计算学习者眼神在左右方向、上下方向的偏移值是否在合理范围内来判断专注状态[4];Daniel等人则证实学习者对相应任务的注视时间、注视率、注视次数等是识别专注度的有效指标[5]。类似地,反映学习者头部偏转情况的头部姿态也可较好地反映学习者的注意力范围,从而判断其是否专注于学习:如Useche等人认为可通过学习者头部的俯仰值与偏航值判断其是否专注[6],Xu等人同样通过头部的俯仰角、偏航角与旋转角实现了较高精度的专注度识别[7]。面部特征则能通过个体五官的动作单元反映其情绪、疲劳程度等状态,同样是识别专注度的可行依据:如刘冀伟等人[8]与Peng等人[9]均是通过人脸的眉毛、眼睛、嘴巴等部位的运动特征实现了较高准确率的专注度识别;郭晓旭[10]、Sharma等人[11]、Gerard等人[12]均通过学习者的面部特征识别其表情,并通过给每种表情赋予不同权重从而计算学习专注度分数;张双喜则基于学习者的眨眼及哈欠情况判断其是否疲劳,并通过计算疲劳帧数比例判断其是否专注[13]。
此外,也有研究在识别专注度时融合了以上几类面部线索,表现出更高的识别准确率:Li等人使用面部特征、眼睛注视方向等特征训练专注度识别模型,得出识别准确率为73.3%,相较于单独使用面部特征或眼睛注视方向,准确率分别提升了4.67%及15.66%[14];熊碧辉融合了学习者的眼睛注视方向、头部姿态、面部特征,通过计算3秒内无人脸帧数、头部偏离帧数、眼睛闭合帧数和视线偏离帧数等占内总帧数的比值判断学习者是否出现了不专注状况,最终获得了89.3%的准确率[15];阮益权则将有无人脸、眼睛开闭、视线落点等作为判断学习者是否专注的依据,发现单一特征类型的最高准确率为74.1%,而融合全部特征依据后准确率高达91.9%[16]。可见,大量研究已证实,通过计算机视觉数据提取的面部线索是识别专注度的有效特征。
(二)眼动特征具有识别专注度的较高潜力
近年来,随着眼动仪智能化程度的不断提高,眼动追踪技术常被用于多媒体学习领域。根据Just与Carpenter提出的“眼-脑”(Eye-Mind)假设,眼球运动为个体注意力的分配提供了动态追踪的可能[17],即眼动特征与信息加工机制有着密切的联系[18]。眼动特征中常关注的指标包括视线落点、注视时间及次数、眼跳路径等:视线落点反映了个体所关注的具体信息区域,可明确其注意的位置和范围;注视时间反映了加工难度与注意量,注视时间越长,一般说明在相应区域投入的注意量越多,信息处理可能会表现出复杂深入的特点[19];眼跳路径则是个体注意力的动态转移轨迹,能反映更为精细的视觉加工信息,如著名的帕福利迪斯实验发现,阅读困难者的回视路径更多,因此可认为阅读困难儿童负责行为顺序的中枢存在缺陷,进而导致注意力的持续时间较短[20]。
由于专注度是注意集中程度的体现,故而眼动特征也为学习专注度的识别提供了可能性。目前,有少量研究探索了采用眼动特征识别专注度的可行性:例如D' Mello等人聚焦于在线阅读场景,基于学习者对阅读材料整体的注视频率、注视持续时间、眼跳长度等全局特征以及不同长度单词的阅读时间、跳过的单词数量、首次注视长度等关注材料词汇的局部特征判定其是否专注于学习内容,结果显示全局特征的识别精度高于局部特征,且结合全局特征与局部特征的识别准确率最高[21];Bixler等同样关注到在线阅读时的全局特征与局部特征,证实了采用眼动数据识别阅读专注度的可行性[22];Veliyath等人则从学习者的眼动数据中提取出其眼球注视位置、被查看的任务位置及相应的时间戳等特征,使用四种机器学习方法进行专注状态评估,最佳方法的识别准确率为77%[23]。可见,眼动特征具有较高的专注度识别潜力。
通过现有研究可以发现,结合多模态特征可以显著提升学习专注度评估模型的性能,但目前,多数相关研究集中在从计算机视觉数据中提取的面部线索特征组合上,少有学者同时结合眼动数据预测学习专注度,这种组合可能会为专注度识别补充额外的有效信息,进而提高识别效果。因此,本研究通过伴随式采集学习者在线学习中的过程性视频数据和眼动数据,分别提取面部线索特征与眼动特征,通过传统机器学习方法构建学习专注度评估模型,以探索对学习专注度的识别效果。
三、研究过程与方法
(一)实验场景
在在线学习中,阅读是基于文本材料获取并理解知识的重要途径,也是常见的学习任务。本研究则聚焦在线阅读场景,实验环境设置如图1所示。该学习场景选定在实验室中,室内有可正常使用的办公桌椅、台式电脑等物理硬件,主要光照为日光灯。实验过程中,需要伴随式采集的数据包括面部线索数据以及眼动数据;同时采集能较为客观、准确地反映被试专注度的脑电数据[24],以标定专注度真值。因此,实验中需配备的数据采集硬件设备包括三类:(1)内置ThinkGear AM芯片的脑电头带设备,采集大脑的Alpha波、Beta波、Theta波等信号数据及由其系统计算的学习专注度数据(0—100);(2)Logitech网络摄像头,固定在显示器的上边缘中间位置,分辨率为1920×1080,采集被试的计算机视觉数据;(3)Tobii X2-60眼动仪,固定在显示器的下边缘中间位置,与被试双眼的距离约为70cm, 采集被试的眼动数据。
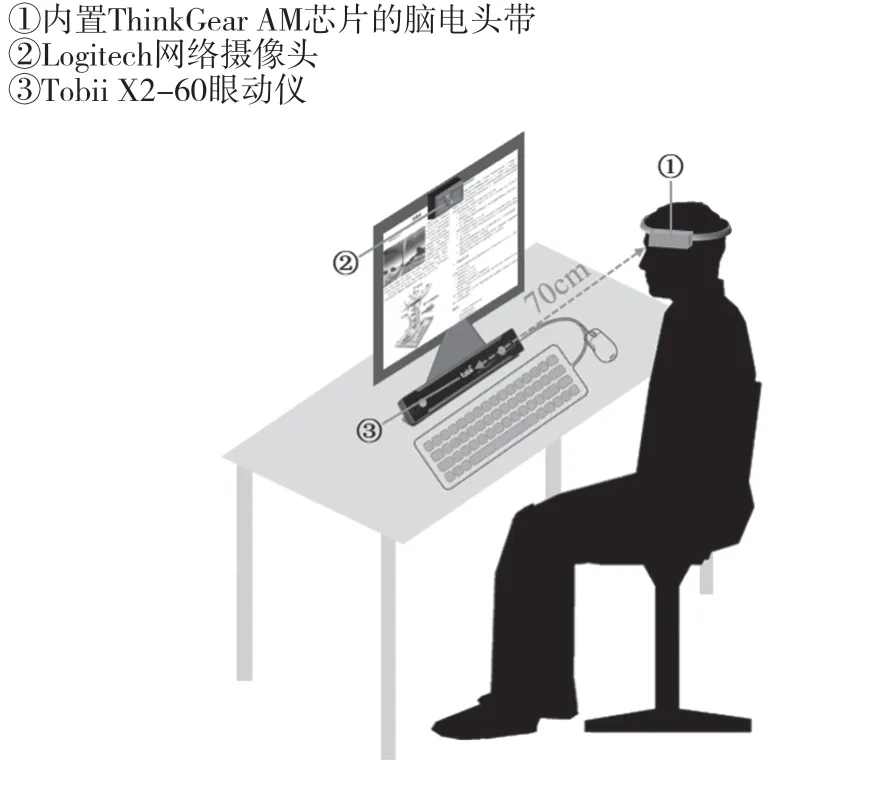
图1 环境设置
(二)实验材料
实验以一篇插图文本形式的阅读材料作为实验材料(如图2所示),材料主题为龙卷风的产生原理,由标题部分、文本部分、插图部分和思考题部分组成。文本部分包括三个部分:第一部分简要描述了龙卷风是什么;第二部分详细阐述了龙卷风是如何形成的;第三部分则介绍了龙卷风的分类。材料中包含两张插图:第一张插图呈现了龙卷风的形态;第二张插图则与文本中的第二部分相关,详细描述了气流运动的过程。思考题部分包含三道与文章主题相关的题目,被试可在完成材料阅读后进行思考。整份阅读材料可完整显示在屏幕上,阅读时间为10分钟。阅读实验完成后,被试需完成由三道思考题组成的后测问卷,三个问题的分值均为6分,根据答案的正确性和完整性程度进行评分。

图2 阅读材料
(三)实验对象
实验面向北京某高校招募了61名非地理专业的大四学生(24名男生,37名女生)作为被试,全部被试的视力正常或矫正视力正常。被试本着自愿的原则参与该实验,实验前全部被试均签署了知情同意书,并在实验结束后收到实验酬金。
(四)实验流程
被试到达实验地点后,主试先向其介绍实验过程与注意事项,被试在无疑问后,需填写背景信息问卷,而后主试调试摄像头以确保被试人脸可被完整捕捉,调整Tobii X2-60眼动仪以校准被试眼睛,并帮助被试佩戴脑电头带设备;全部设备连接无误后,被试需进行5分钟的基线测试,也作为被试熟悉实验环境的时间,之后正式开始实验。在实验过程中,被试仔细阅读显示器上的学习材料,并在10分钟之内完成阅读。阅读结束后,被试按下键盘上的空格键,由主试保存设备采集的数据并帮助被试摘除设备;而后被试需填写有关学习主题的知识后测问卷,以明确被试对知识的掌握程度。
四、数据预处理
实验完成后,对采集的多模态数据进行检查与筛选,剔除数据采集有误的样本,最终获得55个有效样本,每个样本均包含视频数据、眼动数据与脑电数据。其中,视频数据的相关指标提取流程如图3所示,即通过开源工具箱Open Face逐帧分解图像[25],对每一帧图像进行人脸检测、面部特征点估计、面部特征输出等步骤从而计算抽象特征,集成后获得包含眼部视线方向、头部姿态、面部动作单元等特征向量,并通过统计分析计算相应的均值、标准差、最小值与最大值等,共提取104个具体指标;眼动数据则通过Tobii Studio软件进行预处理[26],首先使用区域划分工具将阅读材料标记为文本部分、插图部分与思考题部分三个兴趣区,而后导出在时域与空域上皆有追踪痕迹的眼动数据,并提取出各兴趣区的眼动特征,通过统计分析共得到12个眼动数据的量化指标,如表1所示;脑电数据则由头戴式设备采集,根据eSense的相关参数[27],将具体的专注度数值划分为高(简称H,数值为60—100)、中(简称M,数值为40—60)、低(简称L,数值为0—40)三种类型,以确定专注度标签。此外,因不同特征的量纲不同,特征的实际数值间差异较大,不具备直接比较的意义,故使用Z-Score标准化方法将116个指标的取值转化为标准分数。

图3 面部线索特征提取流程
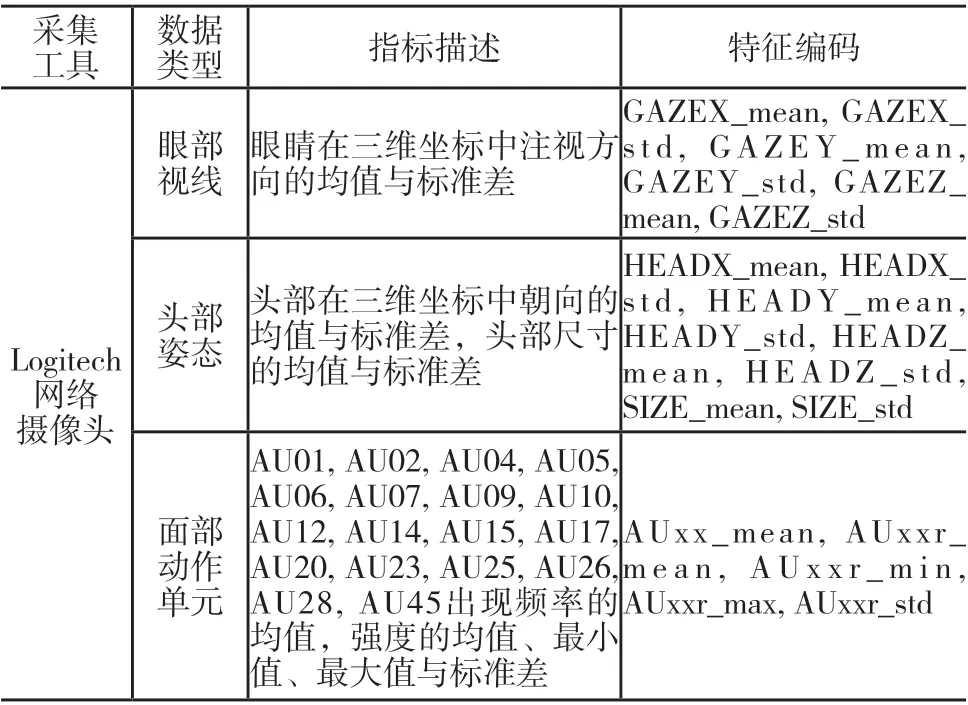
表1 视频数据与眼动数据的相关指标
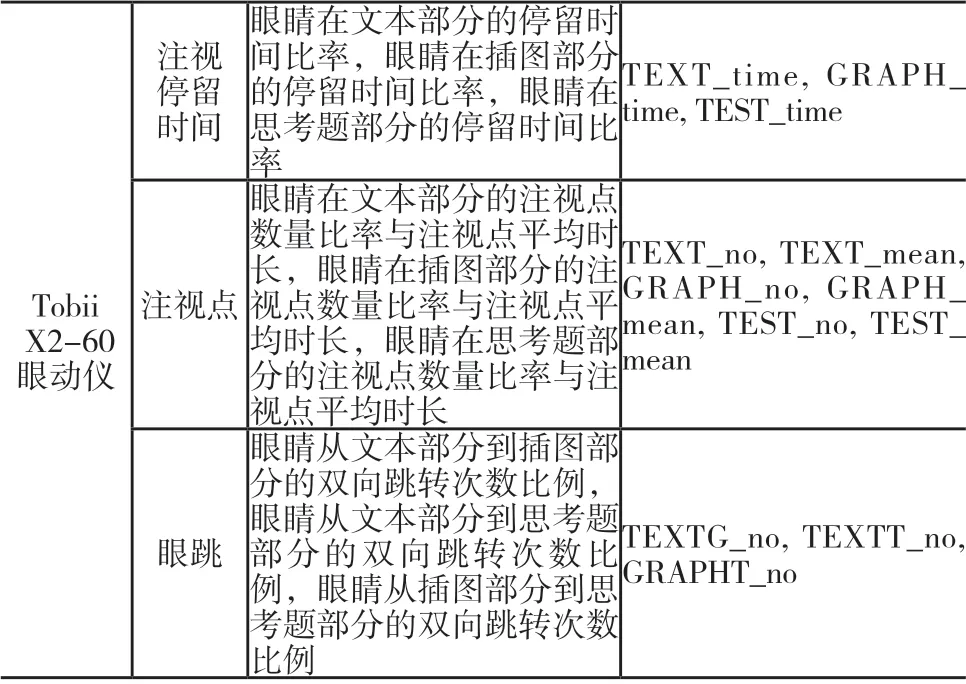
续表1
五、研究结果
(一)学习专注度的分类结果
完成数据处理后,选择六个常用且有效的机器学习方法同时执行具有三类学习专注度标签的分类任务,包括单一规则法(OneRule)、线性逻辑回归(SimpleLogistic)、支持向量机(SVM)、贝叶斯网络(BayesNet)、决策树(DecisionTree)与随机森林(RandomForest)。为了评估和比较以上六种方法的预测性能,将基于混淆矩阵计算得出的准确率、精确率、召回率和F1分数作为性能参数[28]。此外,为了减少有监督机器学习方法中常见的过度拟合问题,利用交叉验证来提高最终预测模型的鲁棒性:采用五折交叉验证配置来训练和测试分类模型,即整个特征数据集被随机分为5份子样本,其中4份子样本作为训练数据,1份子样本作为验证数据,在选取可用的子样本作为验证数据后,得出的性能指标数值是5次迭代的平均值。一般而言,对于特定的分类任务,分类性能更好的方法具有更强大的预测能力,通常会被优先选择,而任何比基线分类器性能更好的模型实际上均是有效的,本研究则选择OneRule作为基线分类器。
为了明确结合视频数据和眼动数据提高学习专注度识别的准确性,分别评估了单模态和多模态的机器学习模型的分类性能,如下页表2所示。根据分析结果,基于从视频数据中提取的面部线索特征的识别学习专注度的效果普遍并不理想,其中SVM、DecisionTree与RandomForest的表现不如OneRule基线分类器,所有性能参数均低于0.500。而眼动模型整体的评估效果较好,全部识别性能参数均高于0.500,能较为有效地区分不同的学习专注程度。此外,多模态模型的学习专注度评估性能整体优于基于单个模态的模型,性能参数值至少提高5.5%,且不论是单模态模型还是多模态模型,BayesNet方法的预测表现都是最优的,尤其在多模态模型中的识别准确率达到了0.745,是较为理想的识别结果。
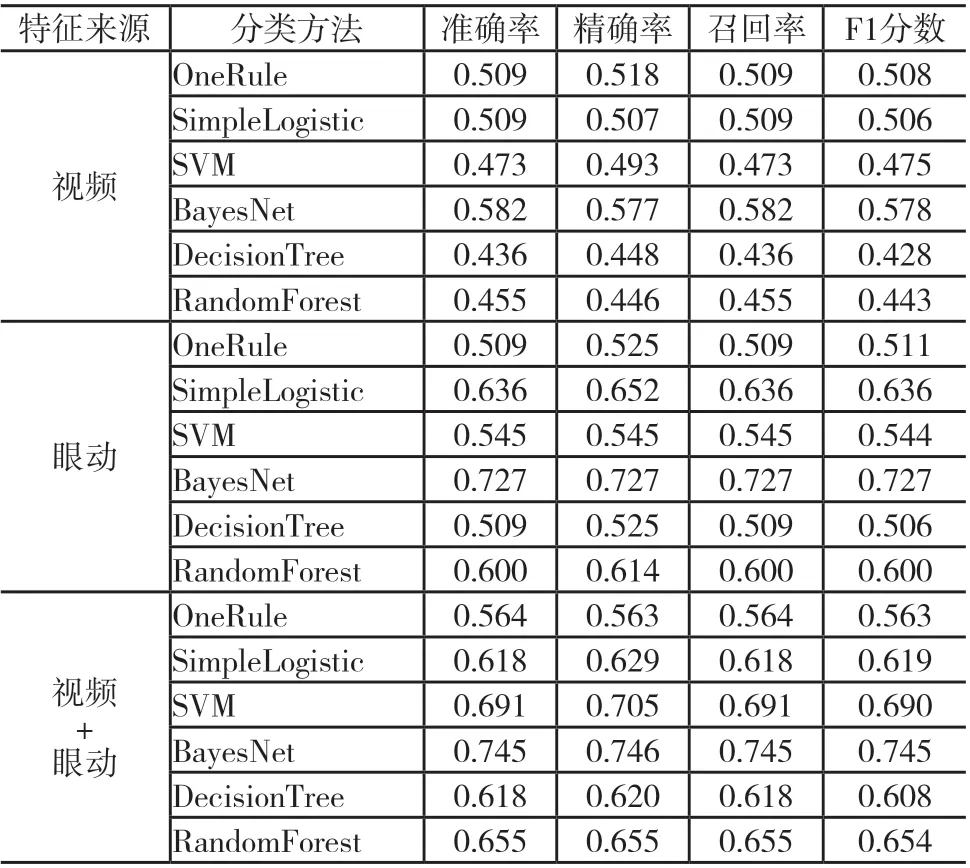
表2 学习专注度分类结果
(二)不同特征对专注度分类结果的混淆概率
为了对比眼动模型与视频模型的识别能力,本研究基于混淆矩阵计算了两类特征对专注度类别的混淆概率,如图4所示。通过分析可知,在视频模型中,H被混淆为M的概率是14.3%,反之则为18.2%, M被混淆为L的概率是36.4%,反之为42.1%;在眼动模型中,H被混淆为M的概率是14.3%,反之则为13.6%,而M被混淆为L的概率是18.2%,反之则为21%。可见,眼动特征比面部线索特征对M和L的识别精度更高。总之,相比较而言,眼动特征比面部线索特征具有更强的学习专注度识别能力。
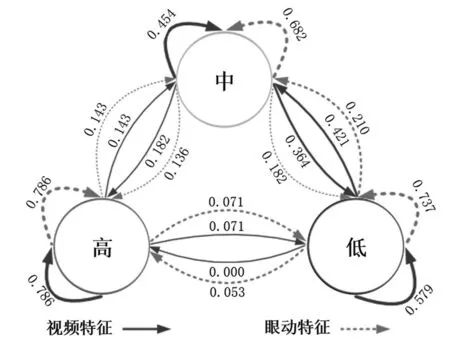
图4 不同特征的学习专注度类别混淆概率
(三)眼动特征的有效性验证
为了进一步验证融合常用的面部线索特征与眼动特征识别专注度的有效性,使用配对样本t检验测试了有无眼动特征的学习专注度分类F1分数的差异,分析结果如表3所示。实验结果显示,除了SimpleLogistic方法外,其它方法呈现的结果均表现出了不同水平的显著差异。可见,使用从眼动数据中提取的特征明显提高了分类器的预测能力。
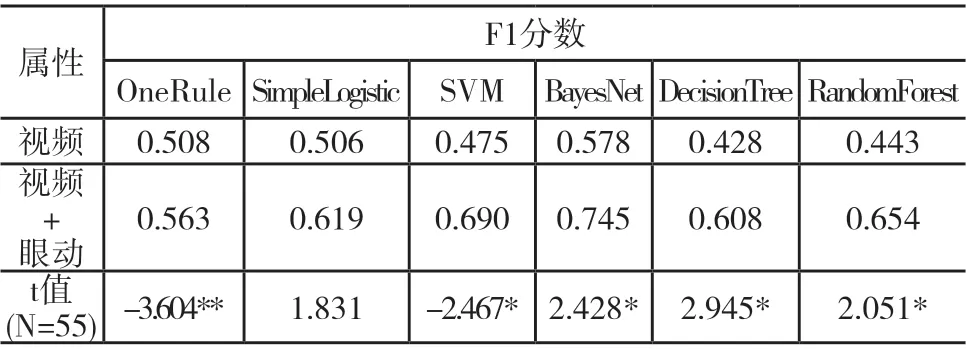
表3 眼动特征的有效性检验
(四)专注度与后测成绩的相关性分析
为明确专注度与学习结果的关系,判断专注度是否会显著影响学习者的学习成效,本研究对被试在实验过程中的平均专注度与后测成绩进行了相关性检验。分析结果显示,平均专注度与后测成绩在0.001水平上呈中等程度的显著正相关,相关系数为0.536。可见,学习越专注的学习者,其学习成效越好。
六、分析与讨论
(一)眼动特征比面部线索具有更好的识别潜力
通过分类结果可知,基于眼动特征的识别准确率整体高于面部线索,眼动特征的最佳识别准确率可高于面部线索14.5%;根据分类结果的混淆概率,眼动特征对中专注状态与低专注状态的识别精度明显高于面部线索。可见,相较于面部线索,眼动特征具有更好的专注度识别能力,尤其表现在对中专注状态与低专注状态的诊断上,而在在线学习中,低专注状态往往更需师生关注,且也是后续开展学习干预的重要依据:具体来说,若将过多中专注状态混淆为低专注状态,难免造成学习者接受不必要干预的现象,干扰其正常学习;若将低专注状态识别为中专注状态,则会导致相应学习者未能接受必要的教学指导,难以实现在线学习专注度诊断的核心价值。因此,眼动是更具备专注度识别潜力的有效特征。
面部线索中的眼部视线、头部姿态、面部动作单元等特征是从学习者个体出发,明确其主要关注的内容范围以及从面部动作中反映出的内部状态;而眼动特征则是关注学习者对学习材料认知加工的实际落点,揭示其视觉信息的选择模式及信息加工机制[29]。眼动特征表现出更好的在线学习专注度识别效果,其原因可能是:从特征产生上来看,在线学习时学习者仅能与固定范围的机器进行人机交互,产生的动作幅度较小,且实验时间较短,学习者尚未进入身体疲劳状态或放松状态,能出现的头部姿态变化与面部动作单元十分有限,导致学习者处于不同专注状态时的面部表现差异不大,故而面部线索对专注度识别的贡献较小;从特征本身的特性来看,眼动特征与面部线索分别关注学习者的内部与外部特征,而对于无教师引导、仅能由学习者自行安排学习进度与策略的在线学习,学习者的认知加工方式会表现出较大差异,相较于个体状态,其信息加工机制更能反映对学习材料的心理资源投入程度,故而眼动特征更具在线学习专注度的识别能力。
(二)多模态专注度识别效果显著优于单模态
从专注度分类结果中可以看出,融合了面部线索与眼动特征的多模态专注度分类结果整体优于单模态;根据配对样本T检验结果可知,除SimpleLogistic方法外,使用其余算法进行多模态专注度识别的效果显著优于仅使用面部线索的单模态识别效果。虽然在视频模型与多模态模型中使用SimpleLogistic方法的F1分数未表现出统计显著性,但融合眼动特征后,其识别性能得到了改善,这可能是因为在相同的测试集下,有无眼动特征时错误识别的学习专注度类型几乎是不同的。整体而言,融合多模态特征的专注度识别效果明显优于单模态特征。
学习过程具有复杂性,学习的发生会体现在学习者心理特征、生理特征与行为特征的一系列变化[30],因此基于人的多重感知模式、采用多种方式追踪学习过程、通过不同层面数据洞悉学习过程的多模态学习分析逐渐得到学者关注[31]。正如在专注度的识别中,单一模态的数据往往仅能片面地反映学习过程:面部线索主要可反映个体在学习过程中的一般专注程度,但难以明晰对学习内容的具体加工情况,较难确认其是否将注意力集中于学习内容;而外显化的眼动特征往往较易“伪装”,虽能明确学习者关注的具体信息,但对于其处理信息时内在状态的判断较为有限。而来自不同模态的面部线索特征与眼动特征代表了学习专注度的不同方面,能综合判断学习者对学习内容的专注程度,因而与仅使用单模态数据相比,不同模态的互补信息可以构建更为稳健的学习专注度评估模型。
(三)学习专注度是优化在线学习的重要抓手
根据学习专注度与后测成绩的相关性分析可知,学习专注度会对学习成效产生显著的影响,这也与先前的大量研究结论不谋而合。当学习者将较多的心理资源投入到学习过程中,其能较好地记忆学习内容并对相关信息进行处理与编码[32][33],处于摄取知识的最佳状态[34];若学习者投入的心理资源较少,有效学习将难以发生。可见,专注度是学习状态的重要呈现,故而学习专注度可作为优化在线学习的重要抓手。
具体来说,对在线学习材料设计者而言,专注度识别利于明确学习者在面对不同内容时的学习状态,可以此为依据进行材料中学习内容与教学设计的优化;同时,面部线索中的眼部视线、头部姿态以及眼动特征等可明晰学习者对材料呈现的关注区域与关注重点,也可基于此完善学习材料的展现形式、页面布局、色彩搭配等呈现方式。对教师而言,自动化的专注度识别可解决时空分离带来的学习状态诊断难题,及时、准确地了解全部学习者的学习专注状态;依据学习者整体的专注度识别结果,教师可进行教学计划的调整与教学内容的修正,完善学习者的学习内容;基于学习者个体的专注度识别结果及其表现出的认知加工策略,教师也可为其提供个人学习方案、学习脚手架等个性化的干预策略,助力精准教学的实现。而对学习者而言,反馈学习专注度有助于了解自身的学习状态,进而调整个人学习方法与学习策略,促进自我调节的发生;也可在在线学习平台中嵌入“专注提醒”功能,当学习者的专注度低于某一阈值时进行弹窗提示,召回其注意力,提升在线学习效果;同时,可依据学习特定内容时的专注度了解可能存在的学习漏洞,便于后续进行有针对性的查缺补漏;此外,专注度也是个人素养重要的组成部分,长期的专注度监控也利于学习者培养专注习惯,助力个人良好综合素养的养成。
七、总结与展望
本研究着眼于在线学习专注度的识别问题,由于专注度是与许多非言语线索相关的复杂内隐现象,仅使用单一模态数据难以建立准确率较高的专注度评估模型,因此本研究收集了学习者的视频数据与眼动数据,从中提取出相关的面部线索特征与眼动特征,进而使用机器学习方法进行在线学习专注度识别。实验结果表明:相比较而言,眼动特征对学习专注度的识别效果更为出色,而面部线索特征的评估表现稍显逊色,这表明眼动特征能为专注度识别提供更有价值的信息,可更为准确地揭示学习者的专注状态;而与使用单模态相比,多模态融合可以明显提高学习专注度识别的准确性,来自不同模态的特征代表了学习者专注度的不同方面,通过整合互补信息可以建立一个更为稳健的学习专注度评估模型,显示了多模态学习分析的优势,这也说明了融合不同模态的特征来识别学习专注度是具有良好发展前景的有效方式。融合多模态特征实现在线学习专注度的识别,有助于学习材料设计者优化材料内容与呈现方式,帮助教师及时掌握学习者状态,并恰当调整教学计划,实施个性化的干预策略,且利于学习者了解并调整自身学习表现,促进有效学习的发生或维持,并有助于专注习惯的养成。
研究虽取得了一定成果,但也存在些许局限,可能会在一定程度上影响研究结论的推广价值,未来可进一步予以完善。首先,由于眼动仪的跟踪范围有限,被试的注意力被限制在一个固定的区域内,因此他们的外部表现难以完全地、自然地展现,这可能会影响学习专注度的识别效果。同时,由于学习材料内容较少,阅读时间较短,被试可能在实验过程中一直保持着生理紧张状态,未能表现出放松状态下的较多姿态特征,这也是本研究中面部线索特征的专注度识别准确率低于先前研究结论的可能原因,因此未来研究中可适当增添实验材料内容,增加实验时长;而因阅读材料仅有一页,不需被试进行点击操作,故未能获得学习者的点击流数据,但有研究表明鼠标动力学特征对学习专注度具有一定的预测力,故而今后可进一步探究融合点击流数据是否能提高在线学习专注度的识别准确性。此外,由于有效样本量较少,本研究未能利用卷积神经网络、循环神经网络等深度学习方法来探索更好的预测性能,因此未来可扩大样本量,建立更大范围的数据集,提取更有意义的指标以构建更可靠的学习专注度预测模型,并验证深度学习方法是否能够有效提高学习专注度的预测能力。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
汽车实用技术(2022年7期)2022-04-20
昆明医科大学学报(2022年3期)2022-04-19
载人航天(2021年5期)2021-11-20
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
大自然探索(2019年7期)2019-12-13
