
基于驾驶行为和交通运行状态的事故风险研究
2022-11-20 11:42郭淼赵晓华姚莹吴大勇苏岳龙毕超凡
华南理工大学学报(自然科学版) 2022年9期
郭淼 赵晓华 姚莹† 吴大勇 苏岳龙 毕超凡
(1.北京工业大学北京市交通工程重点实验室,北京10024;2.北京工业大学城市建设学部,北京 100124;3.招商新智科技有限公司北京 100070;4.高德软件有限公司高德未来交通研究中心,北京 100102)
我国道路交通事故年平均发生数和死亡人数约占全国安全生产事故的60%以上,万车死亡率约为德国的3倍、美国的2倍;据交通运输部统计,2017年中国交通事故死亡人数位居世界第二位,占中国意外死亡总人数的80%[1],可见我国道路交通安全形势十分严峻。交通事故风险识别与主动防控是提升交通安全的重要途径,可为交通安全的诊断、研判与评价提供依据。
随着微波、雷达检测器等道路交通监测设施设备的完善和车载导航等移动数据采集终端的广泛使用,为高精度、细粒度、多维度、海量的实时动态交通流数据和风险驾驶行为数据的采集奠定了基础。由于交通事故的小概率特征和数据采集的滞后性,为交通事故实时动态的识别、预防带来了困难,而交通流和风险驾驶行为与事故的发生存在强相关性[2],现有研究已经从交通运行状态、交通冲突以及风险驾驶行为等层面对交通事故风险的识别做了探索。
交通运行状态层面,早在上世纪90 年代Hughes等[3]基于环形检测器采集的交通运行状态数据,率先研究了实时速度变化等变量与交通事故风险之间的关系,论证了在交通事故风险识别中动态交通运行状态特征比静态交通运行状态特征更有优势;之后,学者们对动态交通参数与交通事故之间的关系进行了广泛的研究,主要通过流量、速度、占有率及其组合指标建立交通运行状态和交通事故风险之间的关系,其中Abdel-Aty 等[4]应用逻辑回归模型将交通事故发生的概率与实时交通运行特征联系起来,结果表明交通事故发生的概率与交通事故上游道路的车辆占有率和下游车辆的速度变化相关;Pande 等[5]基于分类树和神经网络模型论证了多车道路段的交通事故风险,指出平均速度、速度标准差、相邻车道占用率的差异等是引发交通事故的主要因素;徐铖铖等[6]采用Fisher 判别分析方法建立了交通流量、平均速度、速度标准差、占有率标准差等交通运行参数的线性组合,并作为交通安全实时评价指标,进而采用条件逻辑回归模型研究了这些指标与交通事故风险之间的定量关系,以判别危险交通运行状态;Shi 等[7]发现上游流量与高速公路上的事故风险呈正相关关系,同时下游拥堵指数越高,事故风险越高。可见,学者们在基于交通运行状态数据对道路交通事故风险进行识别的过程中在变量挖掘、方法验证等方面做了大量工作,为实时准确识别道路交通事故风险提供了帮助和借鉴。
交通冲突层面,针对道路上具有明显交通冲突的区域,如交叉口、合流区、交织区以及施工区等交通事故多发位置,学者们提出使用交通冲突技术来评价交通事故风险,并开展了广泛的研究[8]。最初由于交通冲突数据的可获得性受限,研究者通过Vissim 仿真实验模拟道路交通的运行过程,根据仿真数据建立交通冲突计算模型对道路的安全状态进行评价[9];近年来,随着数据采集技术的进步,学者们基于多源交通冲突数据对上述关键位置的交通事故风险进行了论证[10],在交叉口层面,Guo等[11]通过视频监控数据提取信号信息、交通运行参数和交通冲突指标,建立基于交通冲突的Bayesian Tobit模型识别信号交叉口的交通安全状态,研究结果有助于识别交叉口安全隐患,优化信号控制,降低冲突或事故的风险;在合流区层面,张鑫等[12]通过分析交通流量、断面速度和车道速度提取交通冲突数据,结合模糊评价法对城市快速路合流区在不同交通流状态下的交通安全状况进行量化评价;在交织区层面,孙璐等[13]通过分析车辆轨迹,识别和统计城市快速路交织区发生的交通冲突,以交织区交通冲突数与交织区交通量、交织区长度的比值作为评价指标,评价交织区的交通安全状况;在施工区层面,朱顺应等[14]通过雷达采集交通冲突数据,基于贝叶斯网络建立高速公路施工区合流路段交通冲突模型,论证了匝道合流路段发生交通冲突的概率和严重性较转幅路段更高,进而对驾驶策略进行评估并提出冲突规避措施以降低交通事故风险。可见,随着数据可用性的增强,作为一种较新的交通安全评价技术,交通冲突技术在评价道路交叉口、施工区、分流区以及合流区等道路关键位置的交通安全,降低道路交通事故风险方面发挥了重要作用。
驾驶行为层面,通过研究风险驾驶行为和交通事故之间的关系,可以评估风险驾驶行为对于交通事故的影响。当前,由于驾驶行为数据采集的局限性,通过风险驾驶行为对道路交通事故进行识别的研究还处于探索阶段[15]。Bagdadi[16]研究发现交通事故的发生与驾驶行为中的制动时间之间存在正相关性;Toledo 等[17]监测分析驾驶人在发生交通事故、近碰撞事件及正常条件下驾驶行为特征,表明驾驶风险指数能够作为涉及事故风险的评价指标;Wang 等[18]采样自然驾驶实验方法,收集道路上的驾驶行为数据,发现最大制动减速度、平均制动减速度以及车辆动能减少率能够用来确定驾驶风险等级,进而表征道路交通风险;王雪松等[19]基于自然驾驶数据提取纵向加速度的最小值和均值、与前车距离的最小值以及车速的标准差来识别接近碰撞和碰撞等危险事件,为基于驾驶行为数据识别道路交通事故风险提供了参考。
综上所述,交通事故发生往往伴随特定的交通运行状态变化、交通冲突的加剧及驾驶行为的异常。其中,基于交通运行状态的交通安全风险评价已经取得了丰硕的研究成果,交通冲突技术也在特定路段的交通事故风险识别中发挥着重要作用。而随着数据采集技术的进步,通过车载导航等采集风险驾驶行为大数据为基于风险驾驶行为数据的交通事故风险识别提供了很大的研究空间。因此,考虑通过建立风险驾驶行为、交通运行状态和交通事故之间的关系,基于高德导航采集的用户风险驾驶行为和交通运行状态等实时、动态的大数据对交通事故风险进行识别,从事故发生概率的角度评价道路交通安全,以便更好地研判交通事故风险,为交通事故风险的准确识别和主动预防提供参考,助力交通事故防控水平的提升。
1 数据准备
1.1 数据基础
本研究的数据采集对象为G15沈海高速温瑞段的部分路段,起点桩号为K1755,终点桩号为K1775,双向长度共40 km。所采集的数据类型包括交通运行状态、风险驾驶行为等实时动态数据以及事故数据。如表1所示,为原始数据中包含的主要字段和数据采集精度说明。其中,风险驾驶行为数据的主要字段和交通运行状态数据中的平均速度、拥堵指数变量来自于高德导航,据统计,导航软件月活跃用户数达到3.257 9 亿,拥有海量的驾驶人行驶数据[20]。需要指出的是,基于高德导航采集的数据仅代表部分驾驶员的风险驾驶行为。据统计,高德导航的日均活跃用户占比达到60%以上,能够在一定程度上表征驾驶员的驾驶行为特征。交通事故和交通流数据中的流量来自于高速公路运营管理公司。数据采集的时间范围为2019年5月1日至31日和2019年10月1日至31日。
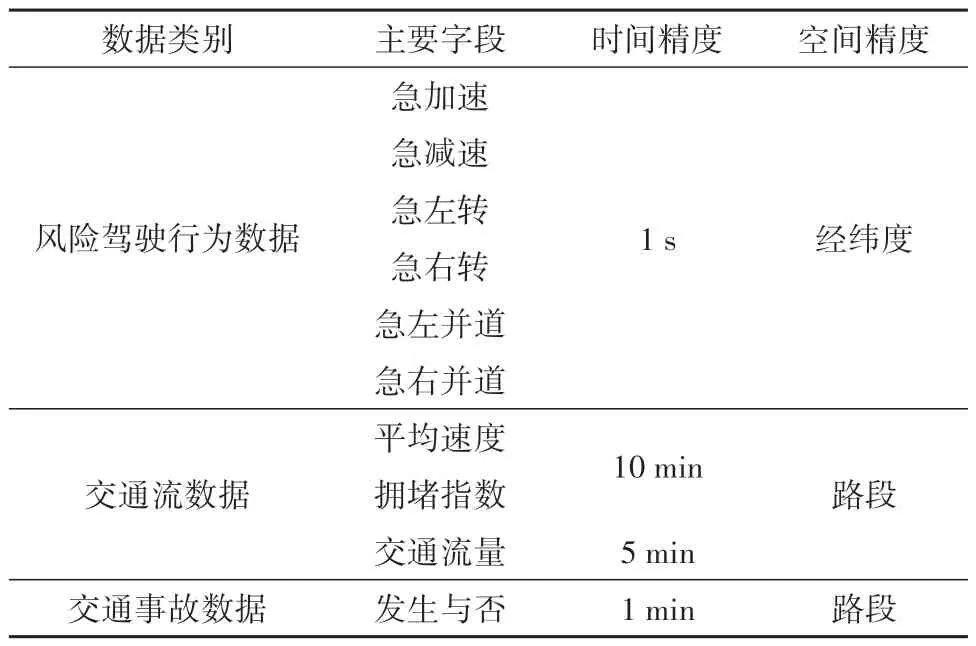
表1 主要字段和数据采集精度说明Table 1 Description of main indicators and data acquisition accuracy
上述字段中,各类风险驾驶行为是触发型数据,即当司机在驾驶车辆的过程中若产生上述风险驾驶行为则被记录,包括时间、位置和类型等信息。6种驾驶行为事件根据手机传感器与GPS 采集的车辆加速度和角速度判定,基本定义如下:
(1)急加速与急减速当手机姿态固定的情况下,若线性加速度大于某一阈值,则识别并记录一次急加速或急减速;
(2)急并道和急转弯当手机姿态固定的情况下,判断转弯的向心力。如果检测角度大于某一阈值,则判定为一次急并道或急转弯。
由于涉及到商业问题,无法公布高德导航软件公司在计算过程中采用的急加速、急减速、急并道、急转弯等驾驶行为具体的判断阈值。
此外,拥堵指数是指当前道路自由流速度v与平均速度的比值,拥堵指数越大,代表道路的拥堵程度越高,计算式[21]为

如表1所示,由于风险驾驶行为、交通流以及事故数据的来自于不同的数据采集部门,在处理和记录的过程中存在时间精度不一致的问题。为了使各类数据在时间精度上保持一致,本文采用各类数据时间精度的最小公倍数(10 min)为时间粒度进行数据统计。在空间上,以1 km 为单位将该路段划分为40 个研究单元。去除在数据收集过程中由于设备等原因产生的缺失值,共得到28.545 4万个观测值。数据的基本统计特征如表2所示。

表2 数据统计特征Table 2 Statistical characteristics of dataset
由于不同类型的数据取值差异较大,为了消除由于数据本身取值大小和量纲的差异对交通事故发生与否贡献度的影响,本研究对数据进行了标准化处理,在保持数据分布特征不变的情况下,使所有数据都聚集在坐标原点附近,标准化过程如下:
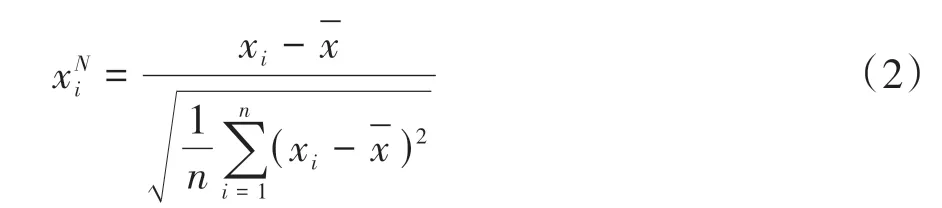
式中:为变量标准化后的值;为变量的均值;为变量的标准差。
1.2 显著性检验
为了深入探究风险驾驶行为、交通运行状态与交通事故之间的关系,为将风险驾驶行为和交通运行状态纳入交通事故识别模型中奠定基础,本文进行了风险驾驶行为和交通事故、交通运行状态和交通事故之间显著性检验。检验方法采用Spearman检验,取95%的置信区间,显著性检测概率p>0.5则认为该变量对事故数有显著性影响。各因素自变量与事故数的显著性检验结果见表3。
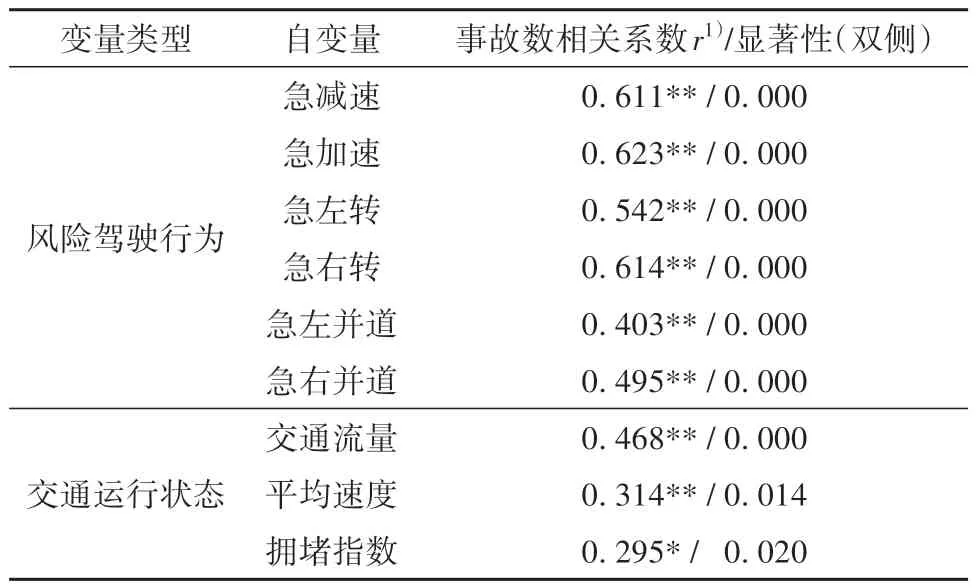
表3 风险驾驶行为、交通运行状态与事故数的显著性检验Table 3 Significance test of risky driving behavior,traffic run⁃ning state and cashes
由表3可看出,风险驾驶行为变量、交通运行状态变量与事故数在95%的显著性水平上均具有显著相关性。其中,在风险驾驶行为中,急减速、急加速、急右转与事故数的相关系数大于0.6,属于强相关,急左转、急左并道、急右并道与事故数的相关系数大于0.4,属中等程度相关;在交通运行状态中,交通流量与事故数之间的相关性最大,其次是平均速度和拥堵指数。
1.3 相关性检验
为了检验风险驾驶行为和交通运行状态之间的相关性,计算了Pearson 相关系数检验变量之间相关性的大小,以剔除相关性较高的变量。结果如图1所示。
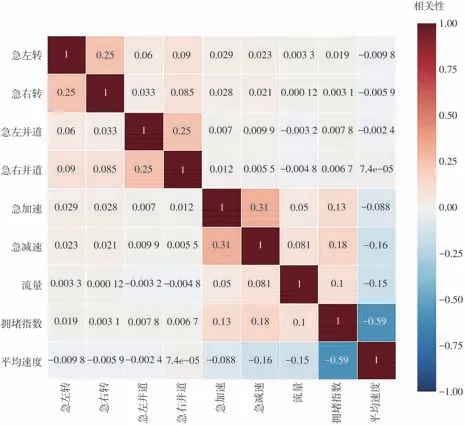
图1 相关性矩阵Fig.1 Correlation matrix
在以往的研究中,对于两个变量之间相关性系数的取值从0.6 到0.95 不等[22],当相关系数大于0.6、0.7 或者0.95 时,即认为两个变量之间的相关性较高,需删除其中一个变量。经过计算,在本研究中每两个变量之间的Pearson 相关性系数|ρX,Y| <0.6,其相关性大小处于可接受的范围内,因此,研究中将风险驾驶行为和交通运行状态变量均纳入模型中。
2 模型与方法
相关性分析表明,风险驾驶行为对于交通事故具有显著影响。为了进一步论证风险驾驶行为在交通事故风险识别中的贡献,本文分别构建了仅包含交通运行状态变量的交通事故风险识别模型和同时包含交通运行状态变量、风险驾驶行为变量的交通事故识别风险模型。并使用逻辑回归算法进行交通事故风险识别,进而比较两类模型的敏感度、误报率以及Area Under Curve(AUC)值。此外,由于交通事故的小概率特征,导致数据库中事故样本和非事故样本的比例失衡。因此,为了避免模型出现过拟合问题,需要对数据集中的训练集进行数据平衡。模型与方法介绍如下。
2.1 数据平衡方法
由于交通事故的小概率特征导致事故样本远小于非事故样本,当以事故作为因变量构建模型时,较少的事故样本会导致在训练交通事故风险识别模型时,模型学习到的大部分是未发生事故时的风险驾驶行为和交通流特征,不利于模型识别交通事故风险。为了解决这一问题,本研究将原始数据集划分为训练集(70%)和测试集(30%)。其中,在训练集中使用合成少数类过采样技术(SMOTE)生成事故样本,解决事故样本和非事故样本占比不均衡的问题。训练集主要用于训练交通事故风险识别模型,通过学习发生事故和未发生事故时风险驾驶行为和交通运行状态的特征校正模型的参数;测试集是未使用SMOTE 技术的非平衡数据集,代表着现实中的数据分布状态,主要用于测试模型在实际应用中的准确性。因此使用SMOTE 技术平衡后的训练集训练的模型不会影响模型在实际数据中的使用。
SMOTE 是通过改进随机过采样算法,对数据中少数类样本进行分析并根据少数类样本合成新样本添加到数据集中,算法的基本思想如图2所示。

图2 SMOTE样本生成方法Fig.2 SMOTE sample generation method
图中●表示多数类样本,如非事故;★表示少数类样本,如事故。SMOTE 算法通过分析少数类样本的数据特征,生成更多少数类样本。计算过程如下。
①计算少数类样本的K 近邻对于数据库中的每一个少数类样本★,计算其到其它少数类样本的欧式距离,得到每一个少数类样本★的K近邻;
②确定样本生成比例根据样本不平衡比例和研究需要设置样本生成比例,对于每一个少数类样本,如★(a),从其K 近邻中按比例随机选择若干个样本,如★(b)。
③生成新的样本对于每一个随机选择出的K近邻样本★(b),分别按照下式计算生成新的样本。

式中:★(c)为生成的新样本;rand(0,1)表示生成0 到1 之间的随机数;|★(a) -★(b)|表示少数类样本★(a)和★(b)之间的欧式距离。
2.2 事故风险识别算法
逻辑回归模型最初起源于统计学,由于其结构简单、可并行计算以及较强的可解释性而被广泛应用于机器学习中,并且在解决二分类非线性问题时优势明显。其基本原理是:为了解决二分类任务,即因变量为{0,1},在线性回归的基础上引入Sig⁃mid函数,即

式中:y为因变量发生的概率值;z为线性回归模型,z=ωΤxi+b,其中xi为自变量,ωΤ为自变量的系数,b为截距项。
将线性回归的连续型结果的值转换为0/1 型的分类结果。如图3所示为Sigmid函数图。

图3 Sigmid函数图Fig.3 Sigmid function
经过Sigmid 函数变换,当预测值z大于零时就得到1(如交通事故)发生的概率;当z值小于零时则得到0(如非交通事故)发生的概率。
将线性回归带入Sigmid函数中即得到逻辑回归模型,即

2.3 模型效果评估
利用SMOTE 方法对训练集进行数据平衡,将平衡后的训练集用于训练逻辑回归模型,使用测试集评估模型的准确性,评估指标包括敏感度、误报率、漏报率,使用Receiver Operating Characteristic(ROC)曲线评价模型的拟合性能。本研究的因变量是一个二分类变量(是否发生交通事故),如图4所示,模型可能的识别结果可用混淆矩阵表示。

图4 模型预测结果的混淆矩阵Fig.4 Confusion matrix of model prediction results
根据模型识别结果的混淆矩阵,可得到模型识别准确性的评估指标,计算方法如下,其中TP表示真正类,TN表示真负类,FP表示假正类,FN表示假负类。
①敏感度STP=TP/(TP+FN),表示模型将实际值中的正样本(如发生事故)识别为正样本的百分比,敏感度越高表示模型对事故识别的准确性越高;
②漏报率RFN=FN/(TP+FN),表示模型将实际值中的正样本识别为负样本的百分比,漏报率越高表示模型对事故识别的准确性越差;
③误报率RFP=FP/(TP+TN+FP+FN),表示模型将实际值中的负样本(如未发生事故)识别为正样本的百分比,误报率越高表示模型的性能越差;
④ROC曲线横轴为漏报率,纵轴为敏感度,根据样本类别判定阈值的变化绘制曲线,通过其与坐标轴围成的面积AUC 值判断模型的识别性能,AUC值在[0,1]之间,值越大,表示模型的识别效果越好。
3 结果与讨论
3.1 数据平衡结果
原始数据集中共包含事故样本200个,非事故样本285 254 个,事故样本与非事故样本的比例约为1∶1 426,如表4 所示。可见,事故样本与非事故样本存在不平衡问题,直接使用原始数据训练逻辑回归模型将导致模型过拟合。因此,需要对数据进行平衡。首先,将原始数据集划分为测试集(30%)和训练集(70%),测试集中包含事故样本60 个,非事故样本85 577 个,训练集中包含事故样本140 个,非事故样本199 677 个;然后,在训练集中采用SMOTE 算法进行数据平衡,为了避免数据集不平衡可能导致的误差,应尽可能保证训练集中事故样本与非事故样本的比例为1∶1[19]。平衡后的训练集中事故样本与非事故样本的数量均为199 677个。
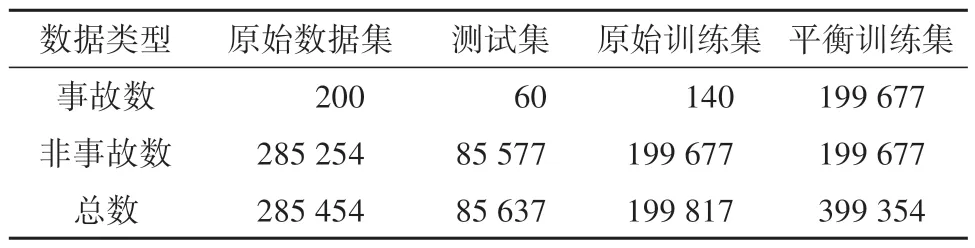
表4 事故数据概况Table 4 Crash data overview
通过比较原始训练集和平衡后训练集中各变量的平均值、标准差、最大值和最小值,发现经过SMOTE 算法平衡后的训练集与原始训练集具有比较强的一致性。并且,通过观测两组数据集的平均值和标准差,发现与直接将原始数据集中的少数类样本复制相比,使用SMOTE 算法生成的少数类样本具有更强的泛化能力。两组数据集的统计特征见表5。

表5 训练集数据统计特征Table 5 Statistical characteristics of training dataset
3.2 模型识别结果
图5为两类模型在测试集数据上的交通事故识别结果的混淆矩阵。两类模型对于交通事故的识别评价指标见表6。

表6 两种模型的预测结果比较Table 6 Comparison of the prediction results of two models

图5 两类模型识别结果的混淆矩阵Fig.5 Confusion matrix of detection results for two types of models
可见,与仅考虑交通运行状态变量相比,同时考虑交通运行状态和风险驾驶行为的交通事故识别模型的敏感度提高了5.00%,误报率降低了1.78%,漏报率降低了5.00%。同时模型的AUC值提高了0.03。
模型的计算结果表明,风险驾驶行为有助于提高交通事故风险识别的准确性,降低模型的误报率和漏报率。如图6所示,为两类模型拟合过程中的ROC 曲线,图中假正例率表示在所有正例(即事故案例)当中,被正确判断为正例所占的比例,实际就是精度,真正例率表示在所有负例(即非事故案例)当中,被错误判断为正例所占的比例。从图中可以看出,加入风险驾驶行为变量后模型的拟合效果更好。

图6 两种模型的ROC曲线Fig.6 ROC curves of two models
3.3 交通事故风险评价
通过上述分析,论证了引入风险驾驶行为变量后的交通事故风险识别模型性能有明显提高。在此基础上,为了进一步明确模型对于交通事故风险识别的能力,本研究选取了典型案例通过提取事故风险概率进行交通事故风险评价。而逻辑回归算法就是基于事故发生的概率计算敏感度、误报率、漏报率等指标,因此,模型计算得到的事故发生概率越大表明交通事故发生的风险越高。
通过提取模型计算的交通事故发生概率作为交通事故风险大小的评价指标,进一步分析交通事故发生前后风险的变化情况。以2019年5月2日和3日两天桩号K1769 处下行方向为例,经过统计分析,该位置发生的交通事故数量较多,共8起,事故发生的时间及其相应的交通事故风险概率值如表7所示。

表7 交通事故发生时间与风险指数Table 7 Traffic crash time and crash risk index
以时间为横坐标,交通事故风险概率为纵坐标绘制24 小时内的交通事故风险概率变化趋势图,如图7所示,图中箭头为事故发生处。

图7 交通事故风险概率趋势图Fig.7 Traffic crash risk probability trend
总体来看,事故发生当天有多个时间段的交通安全风险较高,并且主要集中在[8:00,19:00]的时间范围内,与事故发生的时间段一致。具体来看,在交通事故发生前的一段时间内,交通事故风险概率有明显增加的趋势,如2019年5月3日10:30前交通事故风险概率持续走高,表明这段时间内极有可能发生交通事故,而随着交通事故高风险概率的累积导致了交通事故的发生;此外,在交通事故发生之后的一段时间内,受事故影响交通事故风险概率一直处于较高水平,且有上升的趋势,如2019年5月2日8:40、15:20以及18:20发生3起事故后的时段内具有发生二次交通事故的可能性。
因此,当监测到交通事故风险概率增加时应在相应的路段及时采取防控措施降低交通事故风险的概率,避免交通事故的发生;交通事故发生后的一段时间内也是交通事故防控的重点时段,应重点关注这一时段对交通运行状态和风险驾驶行为的影响,避免发生二次交通事故;此外,除交通事故发生前后的时间段,其他时间也存在交通安全风险增加的现象,如2019 年5 月3 日20:40 前后,这些时间段也需要重点关注,以防患于未然。
4 结语
基于高德导航采集的用户风险驾驶行为和交通运行状态大数据提取风险驾驶行为和交通运行状态指标,并引入到交通事故识别模型中,弥补以往交通事故风险识别模型对于风险驾驶行为考虑不足的问题,进而论证风险驾驶行为对于交通事故风险识别模型的贡献,提高模型对于交通事故风险识别的能力。论文通过比较两类模型对于交通事故风险的识别结果,发现与仅考虑交通运行状态的模型相比,同时考虑风险驾驶行为后,模型的敏感度、误报率、漏报率以及AUC 值均优于前者。风险驾驶行为对于交通事故风险的识别有重要的贡献。通过提取模型计算的交通事故发生概率作为交通事故风险大小的评价指标,发现在交通事故发生前的一段时间内,交通事故风险概率有明显增加的趋势;在交通事故发生之后的一段时间内,受事故影响交通事故风险概率一直处于较高水平,且有上升的趋势。为降低交通事故发生的概率,不仅要关注交通事故风险概率上升的现象,也要关注交通事故发生后相关路段的交通事故风险概率的变化情况,及时采取防控措施,避免发生交通事故。
本研究提出了将风险驾驶行为和交通运行状态相结合的交通事故风险识别方法,提高了模型的预测能力,为风险驾驶行为在交通事故风险识别中的应用提供了理论支持,为基于风险驾驶行为和交通运行状态构建交通事故的替代指标奠定了基础。与此同时,该研究为应用基于导航的风险驾驶行为、交通运行状态等大数据构建高速公路交通事故预防预警系统提供了核心模型支持,可为解决高速公路交通事故主动防控,降低高速公路交通事故率等工程问题提供保障。
本文研究工作尚存在一定局限性,如数据采集的周期有限,后续需要扩大数据采集的时间范围以增强模型的稳定性;此外,为了更加精确的识别道路交通事故风险的类型和严重程度,根据事故造成的损失量化交通事故风险的大小,未来需要采集详细的事故信息,采用更先进的算法提升交通事故风险识别的准确性。
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
中学生数理化·中考版(2021年6期)2021-11-22
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
童话世界(2020年32期)2020-12-25
公民与法治(2020年17期)2020-10-27
小雪花·成长指南(2020年2期)2020-10-12
小学生导刊(2018年16期)2018-07-02
灾害医学与救援(电子版)(2016年4期)2016-03-11
幼儿智力世界(2009年2期)2009-03-10
