
高速公路网车辆碳排放测算方法研究
2022-11-20 11:42林旭坤张扬罗芷晴林培群林陆荣姚岢李梦月温惠英
华南理工大学学报(自然科学版) 2022年9期
林旭坤 张扬 罗芷晴 林培群† 林陆荣 姚岢 李梦月 温惠英
(1.华南理工大学土木与交通学院,广东广州 510640;2.广东省交通运输厅综合规划处,广东广州 510101;3.广东省交通运输规划研究中心资源环境室,广东广州 510101)
随着工业化、城镇化进程加快和消费结构持续升级,我国能源需求刚性增长,资源环境问题仍是制约我国经济社会发展的瓶颈之一,节能减排形势严峻。党中央、国务院在《中共中央国务院关于完整准确全面贯彻新发展理念做好碳达峰碳中和工作的意见》中明确了“双碳”战略目标,要求加快推进低碳交通运输体系建设。落实“碳达峰”、“碳中和”政策,首先应完善交通运输碳排放统计监测体系,形成量化监督手段。
车辆碳排放主要是指二氧化碳的排放。现有碳排放计算方法主要有“总量-结构法”[1]、全生命周期法[2-3]、IPCC(Intergovernmental Panel on Cli⁃mate Change)自上而下法、IPCC自下而上法[4]四种。景国胜等[5]以广州市为例,用“总量-结构法”测算个体交通工具向集约化交通工具转移带来的减碳量效益。郭耀等[6]以昆明市为例,对不同生命周期人群的出行特征和出行碳排放差异进行研究。自上而下法是通过燃料使用数据测算CO2排放量[7],粒度较粗。景侨楠等[8]构建了一套自上而下的城市能源消耗碳排放估算方法,有一定的启发性。Chang 等[9]充分利用ITS(Intelligent Transporta⁃tion System)收集到的数据,运用自上而下法对北京市CO2排放的时空分布特征进行研究,该方法无法体现不同交通方式的差异[10]。自下而上法[11]是通过车辆的详细参数和驾驶模式测算CO2排放量的方法,基于该方法,Le等[12]测算了2008年至2018年中国交通碳排放总量,张清等[13]对上海不同客运交通方式CO2排放量进行了测算,并从交通供给、需求管理以及城市空间角度给出了控制客运交通碳排放的对策。自下而上法能准确反映不同交通方式的碳排放,精度较高,但数据常分布在不同单位[14],获取难度大。
综上所述,不少学者对交通碳排放测算方法进行了探索,具有一定的成效,但仍存在不足:一是多数研究采用自上而下的总量估计法,精度较低;二是高精度研究对象往往是局部路段,不够全面;三是碳排放测算常以年作为时间粒度,无法反映季节规律。
本研究旨在利用多源交通运输数据,由微观信息出发,构建高速公路全路网碳排放计算模型,在国内首次实现对省域路网车辆碳排放量进行精确测算,为交通运输行业碳排放政策的制定、研判交通“碳达峰”时间点提供有力的技术支持。
1 基础数据
1.1 数据内容
本研究采用的基础数据种类较多,相互补充,具体包括:高速公路收费数据、机动车登记数据、汽车理论能耗数据、客货运企业调研数据等。其中,高速公路收费数据主要字段包括:车牌号、车辆类型、车辆种类和公里数等;机动车登记注册数据主要字段包括:号牌号码、型号、燃料种类、核定载客量和发证日期等;汽车理论能耗数据主要字段包括燃料类型和百公里能耗等;客货运企业调研数据主要字段包括:车牌号、燃料类型、总里程、百公里能耗、行驶里程和总质量等。
1.2 基于多元线性回归模型的能耗量插值
由于设备和网络等问题,数据在采集过程中出现数据丢失等现象是不可避免的;为准确测算车辆碳排放指标,本研究采用等比例扩样法对缺失的数据进行补充。
此外,部分车型能耗、排放指标并未公布,如何对其进行估测也是本研究要重点解决的问题。汽车理论能耗数据来自第一电动网、商用车网、商车网、专汽网、中国汽车燃料消耗网、电车资源网等所给出的百公里能耗数据。部分车型的数据无法从上述资源库中获取,本研究采用线性回归法对其进行补充。具体做法:选取整备质量、车辆类型、燃料种类3个特征作为输入,车辆百公里能耗值作为输出,建立映射模型。对于车辆类型、燃料种类两类非数值型无序离散随机变量,采用独热编码(One-Hot)进行处理:使用N位状态寄存器对N个状态进行编码,每个状态都有独立的寄存位,并且在任意时刻只有一位有效。
回归分析是确定变量与变量之间定量关系的分析方法。按照变量数量可分为一元线性回归分析和多元线性回归分析等;按照自变量和因变量之间关系复杂程度可分为线性回归分析和非线性回归分析等。线性回归是回归分析中的一种,用来描述因变量和一组自变量之间的关系,其一般形式为

式中,βi为模型的参数,ε为噪声,xi为解释变量,y为被解释变量。
线性回归在建模过程中通常采用均方误差MSE(Mean Square Error)及拟合优度R2来衡量模型的优劣。均方误差可反映预测值和真实值之间的差异,计算公式如下:

拟合优度是通过数据的变化比较不同量纲下模型的优劣,正常取值范围在0~1之间,其值越接近1表示模型越好,计算公式如下:
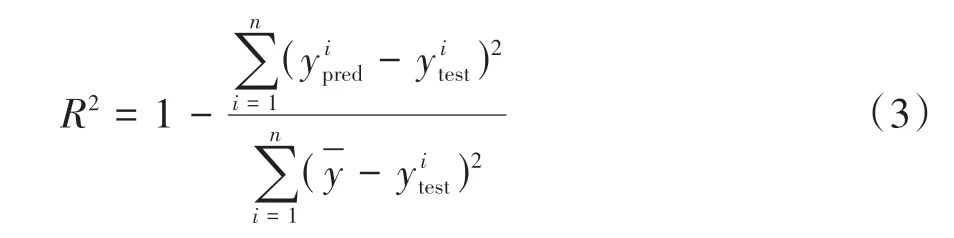
式中,n为测试集中的样本数,为测试集中的真实值,为模型的预测值,为均值。
利用汽车理论能耗数据进行实验,按行业常用做法以7∶3的比例划分训练集和测试集,并取不同随机状态进行测试。实验结果表明模型的拟合优度接近95%,均方误差为3.4,表明模型用来补充车型能耗值的缺失是可接受的。
2 车辆碳排放测算模型
2.1 计算原理
通过分析现有多源交通运输数据,确定模型的相关变量,进而得到模型框架:获取(或插值计算)不同燃料分类下各车型理论能耗和平均碳排放系数,并结合客货运企业调研数据予以修正,使能耗和平均碳排放系数更符合车辆本地化运行特性。最后,结合高速公路车辆运行趟次、平均行驶里程等指标,计算得到各类车型的总能耗与总碳排放量。
2.2 计算流程
高速公路网车辆碳排放测算模型具体计算流程如图1所示。
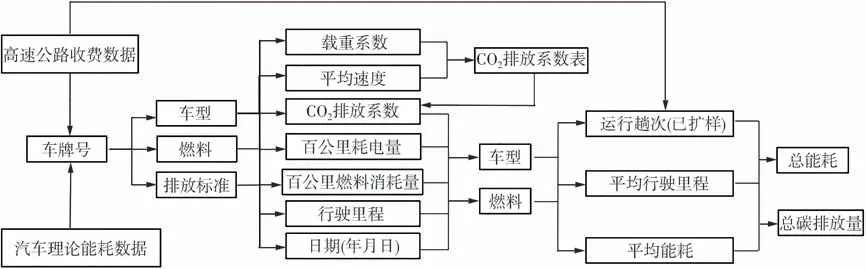
图1 高速公路网车辆碳排放测算模型计算流程Fig.1 Calculation process of vehicle carbon emission calculation model in expressway network
(1)运行趟次计算
对统计时期内高速公路的车辆出口流量进行计算,获取高速公路中各种车型的运行趟次,记所得的高速公路网中车辆运行趟次为c,则有:

式中:i为车辆类型,按交通运输部高速公路车型分类标准,分为9 大类(n=9,详见表1);j为燃料类型,按机动车登记注册数据划分为7大类(m=7),分别为汽油、柴油、纯电动、天然气、混合动力、氢燃料电池、其他类型;ci,j指使用燃料j的第i类车的运行趟次。

表1 高速公路网车辆碳排放测算模型车型分类标准Table 1 Vehicle carbon emission measurement model classifi⁃cation standard for expressway network
(2)平均行驶里程计算
对统计时期内车辆在高速公路网上的单次出行平均行驶里程进行计算。先获取单辆车单次出行的行驶里程li,kk,再根据车型和燃料类型将车辆进行二级分类,并计算其平均值,进而统计出每类车单次出行的平均行驶里程:

式中,li,j为使用燃料j的第i类车的平均运距,为使用燃料j的第i类车中第k辆车的行驶里程,s为总车次数。
(3)平均能耗计算
对统计时期内高速公路网各类车的平均能耗进行计算。先基于车辆品牌和型号获取单辆车的百公里能耗(理论值),计算得到每类车的平均百公里能耗(理论值),再将其与基于调研数据获取的各类车的能耗修正系数αi,j相乘,得到每类车的平均百公里能耗(修正值)。

式中,为使用燃料j的第i类车中第k辆车的百公里能耗的理论值,αi,j为燃料j的第i类车的百公里能耗修正系数,为燃料j的第i类车的平均百公里能耗修正值。
(4)车辆总能耗计算
对统计时期内高速公路网的车辆能耗总量(燃料消耗量和耗电量的总称)进行计算。先将计算所得的高速公路网各类车的运行趟次ci,j、平均行驶里程li,j与平均燃料消耗量相乘,计算得到高速 公路网各类车的总燃料消耗量fi,j:

再将各类车的燃料消耗量求和,即可获得高速公路网所有车辆的总燃料消耗量fj:

车辆能耗的单位为千克标准煤或吨标准煤,为便于计算分析,需将燃料消耗量和耗电量统一转换为千克标准煤。
通过上述分析,可得到高速公路网中各类车的总能耗e为

式中,ρj为燃料j转换为千克标准煤的转换系数。能源类型换算标准[15]具体如表2所示。

表2 能源类型换算表Table 2 Energy type conversion table
(5)碳排放量计算[16]
车辆碳排放主要指燃料燃烧活动产生的二氧化碳(CO2)的排放。
车辆燃料产生的CO2排放量及排放因子计算:

式中,ADj指第j种燃料的活动水平,EFj指第j种燃料的CO2排放因子,即

其中,NCVj指第j种燃料的平均低位发热量,FCj为第j种燃料消费量。化石燃料的二氧化碳排放因子按下式计算:

式中,CCj为第j种燃料的单位热值含碳量,OFj为第j种燃料的碳氧化率,44/12为二氧化碳与碳的相对分子质量之比。
3 广东省高速公路网能耗与碳排放测算
3.1 数据校准
截至2020 年底,广东省高速公路通车总里程超过1万公里,总长度和交通量连续七年排名全国第一[17],因此本研究具有较高的代表性。考虑到汽车能耗数据中车辆百公里能耗的理论值与真实值存在差异,本研究结合2019 年广东省道路货物运输量专项调查数据,以及客运企业问卷调查数据,提取了1 287辆客车,4 422辆货车的能耗信息进行参数本地化校准。将所采集的车辆百公里能耗实际值与各车型百公里能耗理论值进行对比分析,计算得到各类车型的理论能耗修订系数(实际能耗/理论能耗),如表3所示。

表3 不同车型实际能耗与理论能耗平均比值Table 3 Average ratio of actual energy consumption and theo⁃retical energy consumption of different models
各类客车的能耗实际值与理论值的平均比值均在1.24~1.34左右,相对稳定;重型货车的能耗实际值与理论值相差不大,但轻型货车的能耗实际值与理论值差异较大。
3.2 测算结果
基于已有数据资源,计算各类车的平均行驶里程、百公里燃料消耗水平等参数。据此获得在高速公路全路网的车辆能耗与碳排放指标,测算结果详见表4。

表4 高速路网车辆能耗与碳排放量计算Table 4 Calculation of vehicle energy consumption and carbon emission index in expressway network
研究时段内,广东省高速公路全路网能耗与碳排放量在2020年10月达到峰值,2021年2月及6月数值相对较小。
以2021年3月为例,微型小型客车能耗与碳排放量占比最大,分别为53.2%,52.9%。其次是重型客车,能耗与碳排放量占比分别为24.8%,25.0%。中型货车能耗与碳排放占比小,均为1.5%,如图2所示。以2021年3月为例,汽油车能耗与碳排放的量最大,占比分别为52.7% 和50.6%。其次是柴油车,能耗与碳排放占比均为44.2%,如图3所示。
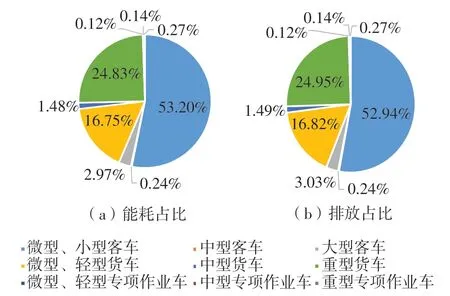
图2 按车辆类型分类(以2021年3月为例)Fig.2 Classified by vehicle type(taking March 2021 as an example)

图3 按燃料类型分类(以2021年3月为例)Fig.3 Classified by fuel type(taking March 2021 as an example)
因国庆假期出游频次增加,高速公路全路网各类型车辆能耗与碳排放量显著增加;春节期间,微型轻型货车与重型货车车次数减少,导致公路货运量减少,柴油车能耗与碳排放量显著减少;2021年6 月微型小型客车(大部分为小轿车)由于广州爆发新冠疫情的原因,出行受到限制,导致汽油车能耗与碳排放量略有减少,如图4所示。

图4 能耗与碳排放变化情况Fig.4 Changes in energy consumption and carbon emissions
新能源汽车在高速公路全路网中的占比在逐步提高,由2020年9月的5.83%提高到2021年6月的7.21%,如图5所示。研究时段内,新能源汽车车次占比为6.4%,碳排放占比仅为4.5%。因此,大力推广新能源车能够有效减缓碳排放量的增长速度。另一方面,由于常规燃油车的保有量过大,需要较长时间才能取得显著的节能减排效果。

图5 高速公路全路网上新能源车占比Fig.5 Proportion of new energy vehicles on the whole ex⁃pressway network
3.3 结果对比
本研究自下而上,通过完备的基础数据构建测算模型,计算流程科学、客观。由于所研究对象缺乏直接参照值(从未有机构精确测算过相关指标),因此采用中国碳排放数据库CEADs 进行间接比对。在CEADs 分部门核算碳排放清单中,广东省交通运输、仓储、邮政业月均碳排放量为5.8 Mt,与本研究测算结果2.51 Mt 相差仅8.19%(经换算),表明本研究所提出方法具有较高的准确性,计算差异的原因主要有2个。
(1)在计算方法层面,中国碳排放数据库采用自上而下法从总体上通过能源消耗对交通碳排放量进行计算,本研究则采用自下而上法利用多源交通运输数据,由微观信息出发,实现对省域路网车辆碳排放量进行精确测算。两者计算方法不同,导致计算结果有所差异。
(2)在统计范围上,中国碳排放数据库中的数据由交通运输、仓储、邮政业3部分构成。只能通过规律大致推算高速公路网车辆碳排放,导致计算结果有所差异。
4 结语
本研究所用数据全面,且均为客观、可测数据,据此构建的高速公路网碳排放测算模型具有较高的科学性。案例在国内首次实现对省域大范围高速公路网进行车辆碳排放精确测算,为研判交通“碳达峰”时间点和相关政策的制定提供有力的技术支持。研究同时表明:
(1)微型小型客车的车均碳排放量较小,但车次占比达到77.6%,因此碳排放量占比高达53%。重型货车车次占比仅为7.2%,碳排放总量占比达到25%。
(2)研究时段内,汽油车碳排放量占比达到49.8%,柴油车碳排放量占比约为45.4%;新能源汽车车次占比为6.4%,碳排放占比仅为4.5%,表明大力推广新能源汽车能有效减少碳排放量。
(3)2021 年6 月广东省受“新冠疫情”影响,私人小汽车出行减少,但货车等营运性车辆的车次并未显著变化,表明“新冠疫情”对不同车型的影响差异较大,但对交通运输经济的整体影响有限。
后续研究将结合连续式交通量观测站数据,对高速公路和普通公路进行全面的碳排放测算。
猜你喜欢
英语文摘(2021年8期)2021-11-02
煤气与热力(2021年6期)2021-07-28
小学科学(学生版)(2021年5期)2021-07-22
军事文摘(2020年14期)2020-12-17
高师理科学刊(2020年2期)2020-11-26
中国工程咨询(2017年3期)2017-01-31
中国国情国力(2016年1期)2016-11-26
通信电源技术(2016年5期)2016-03-22
西安建筑科技大学学报(自然科学版)(2014年1期)2014-11-12
应用数学与计算数学学报(2014年4期)2014-09-26
