
基于TF-IDF算法的文本量化方法及作者识别应用
2022-11-19 09:15李楚
现代信息科技 2022年19期
李楚
(东北大学秦皇岛分校,河北 秦皇岛 066099)
0 引 言
作者识别问题于1887年首次由Mendenhall 提出,它的主要目标就是根据匿名文本的内容识别出匿名文本最可能的作者。作者识别任务可以被看作是多类别单标签的分类问题,每个可能的作者身份代表一个标签,最终目标是为每一个匿名文本匹配到最可能的作者标签[1]。因此,许多文本分类技术已经被运用到作者识别任务中。
文本以一种非结构化或半结构化的形式存在,它没有确定的形式,机器也无法直接理解其语义。为了将数据挖掘技术用于探索获取文本信息,通常需要对文本进行预处理,再以统计的方法将其转变为机器可以识别处理的数值型结构。
根据经典的词袋模型(Bag-of-words)理念,文本可以看作是由若干个词汇构成的集合。一个作者的写作风格可以由该作者经常使用的文体特征表达,如词频、单词长度、一个句子中动词出现的频率等等[2]。其中,词频用于表达文本内容十分常见。在一个文本中,有一部分词汇携带了大量信息,能很好地表达文本的内容,同样还有一部分词汇,如没有实际语义的停用词和携带信息量极少的词汇,不仅无法表达文本的内容,还会增加文本分类或作者识别过程的时间成本,并对最终的分类或识别结果造成不利影响,因此识别文中真正重要的词汇十分重要[3]。
在作者识别任务中,文本预处理方法分为基于文本和基于实例两种类型[4]。在基于文本的方法中需要将同一个作者的所有文本进行合并,而在基于实例的方法中每一个文本都是一个独立的对象并对应一个作者标签。在大部分研究中,采用相似度或距离度量识别匿名文本的作者时,一般以基于文本的方法预处理文本,而采用机器学习分类器识别作者时,则一般以基于实例的方法预处理文本。识别文本作者通常分为基于分类的方法和基于相似性的方法[5]。基于分类的作者识别方法主要利用文本训练集的样本实例训练机器学习分类器,然后将训练好的分类器用于预测匿名文本的作者标签,而基于相似性的作者识别方法则是通过计算匿名文本和所有已知作者文本的相似度来判定匿名文本最可能的作者[6]。
文章基于词频-逆文档频率(TF-IDF)算法提出了一个新的文本量化方法用于将文本转变为向量,还提出了一种混合距离度量用于识别匿名文本的作者身份。提出的方法的性能评估在英文、中文两种不同类型的文本数据集上进行,分别使用TF-IDF 算法和提出的文本量化方法量化文本,然后运用提出的混合距离度量和七种常见的分类算法包括五种经典的机器学习分类器、闵可夫斯基距离度量和余弦相似度识别匿名文本的作者。
文章结构为:第一部分是对相关研究的综述;第二部分介绍了一些文本处理的相关概念并提出了新的文本向量化方法和混合距离度量;第三部分引入了大量实验对提出的算法进行评估;最后是文章的总结及未来研究工作的展望。
1 相关研究
目前针对作者识别任务的解决方法主要是在选择文本特征并量化文本后,将其用于训练机器学习分类器和计算文本之间的相似度、距离度量或关联程度。因此,文本特征的选择和量化受到了广泛关注。许多学者旨在通过提取文本最重要的特征来提高分类算法的准确性并减少识别过程耗费的时间成本。比如BinSaeedan 和Alramlawi 基于二进制粒子群优化算法(BPSO)和卡方优化算法提出了CSBPSO 特征选择算法用于提高识别阿拉伯语言电子邮件的作者的准确性,在实验中分别考虑了动态和静态特征,结果表明利用CS-BPSO 算法提取动态特征较好的提高了各个分类器的识别准确性[7]。Ramezani 提出了一种语言独立的作者识别方法,该方法不需要任何的自然语言处理技术,基于改进的特征权值算法来计算匿名文本与已知作者文本的相似度并将与匿名文本相似度最高的已知文本的作者判定为匿名文本最可能的作者[6]。Bhatti 等人提出了一种专门针对乌尔都语的文本分类和文本相似度衡量的方法,该方法利用TFIDF 算法提取文本特征、利用chi-2 进一步选择特征,然后利用线性判别分析(LDA)将文本向量映射到二维空间以达到较好的特征降维效果[8]。考虑到Word2vec 模型无法确定特征在文本中的重要性程度,Wang 和Zhu 将TF-IDF 算法与Word2vec 模型结合形成了加权的Word2vec 分类模型。在预处理过程中,他们还引入了一个新的特征提取算法来对StringToWordVector 算法进行改进并将其用于降低文本特征维度[9]等等,这些研究都取得了大量成果。
虽然目前存在许多的特征选择与文本量化算法,且其中大部分都考虑了特征在目标文本中出现的频率以及在其他文本中的普遍性两个因素。然而文本集中特征分布的密集度这个因素却被忽略了,考虑到这个因素,文章基于TF-IDF 算法提出了一个新的文本量化方法。另外,为了评估 闵可夫斯基距离度量和余弦相似度在作者识别任务中识别匿名文本作者的共同作用,还提出了一个混合距离度量用于计算两个文本之间的距离并将与匿名文本距离最近的已知文本的作者判定为匿名文本最可能的作者。
2 提出的方法
2.1 向量空间模型
向量空间模型在文本处理、自动索引、信息检索等领域中被广泛使用。它旨在将文本由文字形式转变为向量空间中的数值向量形式,一般采用向量之间的余弦夹角衡量文本之间的相似度。在向量空间模型中,一个文本被看作是由若干个不同的术语构成的集合,每个术语都代表文本的一个维度且可以根据其在文本中的重要性大小进行权值化。假设文本Dj由n 个不同的术语构成,则文本Dj可以表示成一个n 维向量,即Dj=(wj1,wj2,…,wjn),其中wji代表第i 个术语在文本Dj中的权值[10,11]。
2.2 原始TF-IDF 算法
TF-IDF 算法是一种用于文本特征数值化的统计计算方法,用于评估特征对于文本的重要性程度。根据TF-IDF 算法,一个在目标文本中频繁出现但在所有文本中普遍性很小的特征对目标文本是十分重要的。如式(1)所示,特征i 在文本j 中的TF-IDF 权值表示为[12,13]:

其中T 表示总文本数量,tfij表示特征i 在文本j 中出现的频率,dfi表示含有特征i 的文本数量。TF-IDFij的值越大,则表明特征i 在文本j 中越重要。
2.3 余弦相似度
余弦相似度用于描述两个文本向量之间的相似程度大小,如式(2)所示,任意两个文本向量Dj=(wj1,wj2,…,wjn)和Dd=(wd1,wd2,…,wdn)的余弦相似度表示为[14,15]:

Sim(Dj,Dd)的值越大,则表明文本向量Dj和Dd越相似。
2.4 闵可夫斯基距离度量
闵可夫斯基距离度量是计算两个文本向量之间距离大小的一种度量,如式(3)所示,任意两个文本向量Dj=(wj1,wj2,…,wjn)和Dd=(wd1,wd2,…,wdn)的闵可夫斯基距离表示为[16]:
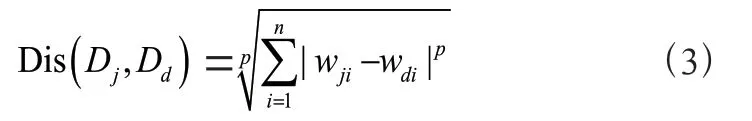
p 为可变的正整数:
p=1 时,Dis(Dj,Dd)称为曼哈顿距离;
p=2 时,Dis(Dj,Dd)称为欧氏距离;
p →∞时,Dis(Dj,Dd)称为切比雪夫距离。
Dis(Dj,Dd)越小,则表明文本向量Dj和Dd越相似。
2.5 提出的方法
2.5.1 新TF-IDF 算法
为了更好地量化文本特征,在TF-IDF 算法的基础上进行调整得到了一个新的TF-IDF 量化方法,如式(4)所示:

其中tfij表示特征i 在文本j 中出现的频率,dfi表示含有特征i 的文本数量,表示特征i 在除文本j 以外的其他文本中出现的频率之和。
新TF-IDF 量化算法在原始TF-IDF 量化算法的基础上增加了几点考虑,可根据如下案例表达:
(1)对于文本j 的两个特征a 和b,若a 和b 在文本j 中出现的频率相等,即tfaj=tfbj,且在所有文本中含有a 和b 的文本数量也相等,即dfa=dfb。那么根据原始TF-IDF 算法可得到a 和b 在文本j 中的权重值相等,即tf-idfaj=tf-idfbj。若继续考虑a 和b 在其他文本中出现的频率大小,当a 在其他文本中出现的总频率大于b 在其他文本中出现的总频率时,即客观看来相比于a,b 对文本j 更加重要,因此在文本j 中赋予b 更大的权重值较为合理,根据新的TFIDF 算法可得到这个结果,即tf-idfaj≤tf-idfbj。
(2)对于文本j 的两个特征a 和b,若a 和b 在文本j中出现的频率相等,即tfaj=tfbj,a 和b 在其他文本中出现的总频率也相等,即,而所有文本中包含a 的文本数量大于包含b 的文本数量,即dfa>dfb。根据原始TFIDF 算法可得到a 和b 在文本j 中的权重大小关系有tf-idfaj<tf-idfbj。而新的TF-IDF 算法则考虑特征在文本集中分布的密集度因素,一个在目标文本以及许多其他文本中分布密集的特征对任意一个文本的表达能力都很弱。由于包含a 的文本子集(不含文本j)中a 分布的平均密度小于包含b 的文本子集(不含文本j)中b 的平均密度,因此可以认为在文本j 中a 更重要,根据新的TF-IDF 算法可以得到这个结果,即tf-idfaj>tf-idfbj。
相比于原始TF-IDF 量化算法,新算法考虑的因素更加全面,如特征在其他文本中的频率和在文本集中分布的密集度,其旨在通过更好的量化特征以达到提高分类准确率的目标。
2.5.2 混合距离度量
若Dj=(wj1,wj2,…,wjn)和Dd=(wd1,wd2,…,wdn)为两个文本向量,如式(5)所示,文本j 和文本d 的混合距离定义为Dis(Dj, Dd):

其中n 为特征个数,p 为可变的正整数,Sim(Dj,Dd)为文本向量Dj和Dd之间的余弦相似度。
提出的混合距离度量是闵可夫斯基距离度量和余弦相似度的结合体,它用于评估闵可夫斯基距离度量和余弦相似度在作者识别任务中的共同作用。Dis(Dj,Dd)的值越小,则表明文本向量Dj和Dd越相似。
3 实验结果
3.1 数据描述和实验方法
实验部分使用了英文和中文两种类型的文本数据集。两个数据集均包含10部由不同著名文学作家撰写的长篇小说,每部小说中均抽取了25个部分,其中80%的部分(20个部分)作为训练集样本,20%的部分(5 个部分)作为测试集样本。
实验运用提出的文本量化算法和原始TF-IDF 算法量化文本,运用提出的混合距离度量、余弦相似度、闵可夫斯基距离度量和五种机器学习分类器包括支持向量机(SVM)、随机森林(RF)、朴素贝叶斯(NB)、K 近邻(KNN)、神经网络(NN)共八种分类算法识别文本的作者,最后根据测试集样本的作者识别准确率评估所提出的算法的性能。如图1 所示,在运用五种机器学习分类器的过程中需要根据文本量化算法将数据集样本转变为向量形式,每一个文本向量有对应的作者标签,然后训练集的实例会用于机器学习模型的训练,最终在测试集上计算每个模型的作者识别准确率。如图2 所示,在运用提出的混合距离度量、余弦相似度以及闵可夫斯基距离度量时,需要将训练集中来自同一本书的所有部分融合成一个文本,每个文本对应一个作者标签,而测试集中每个部分对应一个作者标签,数据集的所有文本需根据量化算法转变为向量形式,然后通过计算各测试集文本向量与所有训练集文本向量的距离或相似度大小来预测测试集文本的作者,最终可得到测试集文本作者的识别准确率。

图1 机器学习分类器识别文本作者的过程

图2 相似度及距离度量识别文本作者的过程
3.2 数据预处理
文本在量化之前还需要进行预处理。英文中单词与单词之间存在空格,且大部分英语单词都有实际含义。中文以字为基本单位,由若干个字构成有意义的汉字字串,且字与字或者词与词之间没有分隔,只有句子与句子之间存在标点符号。中英文文本的预处理过程包括以下四个步骤:
(1)文本标记的处理。最初的文本通常含有表情符、链接等噪音字符,它们通常无法对后续的作者识别提供直接有用的帮助还可能对识别结果造成不利影响,因此需要剔除这些标记。
(2)文本分词的处理。英文文本根据单词与单词之间的空格进行划分。中文文本则基于字符串匹配的方法进行划分,该方法依赖于字典工具,根据字典中已经记录的术语来判断文本内相邻的字是否构成一个词语。
(3)去除停用词。经过分词后,文本中还存在一些没有具体含义的停用词,比如:而且、在、的,等等。停用词普遍出现在各类文本中,它们无法提供有用的信息,还会增加文本量化的工作量,因此需要剔除文本中的停用词。
(4)特征提取。剔除停用词后,文本特征维度仍然很大,为了减少文本量化和文本作者识别的时间成本,需要进一步降低文本维度。实验根据词频来提取文本特征,独立的每个部分选择词频最大的50 个特征,而经过合并形成的文本选择词频最大的200 个特征。
3.3 分类算法和性能评估方法
3.3.1 分类算法
(1)支持向量机(SVM)。支持向量机是一种建立在特征空间上的使得类和类之间间隔最大的超平面,实验运用引入核函数的支持向量机对非线性的文本进行识别[17],使用线性核函数进行非线性判别。
(2)随机森林(RF)。随机森林模型由多个决策树模型构建而成,基于所有决策树的分类结果,根据多数表决准则得到随机森林模型最终的分类结果[18]。实验使用100 棵树的随机森林模型,采用Gini 系数作为树的分裂标准。
(3)朴素贝叶斯(NB)。朴素贝叶斯是一种基于贝叶斯定理和特征条件独立性假设的分类算法[19]。实验使用高斯贝叶斯分类器识别文本作者。
(4)K 近邻(KNN)。K 近邻是一种经典的分类算法,根据与目标对象最相近的K 个样本的类别标签来标记目标对象[20]。实验指定K=5 以及闵可夫斯基距离作为度量。
(5)神经网络(NN)。神经网络是模拟生物神经网络进行信息处理的一种数学模型,它由一个输入、一个输出和若干个隐藏层组成[21]。实验训练一个隐藏层数为100 的神经网络模型,使用relu 激活函数,并设置最大迭代次数为1 000。
除了运用以上机器学习分类器识别文本的作者,实验还使用提出的混合距离度量、余弦相似度以及闵可夫斯基距离度量识别文本的作者,与测试文本相似度最大或距离最小的训练文本的作者被判定为该测试文本的作者。
3.3.2 性能评估方法
实验根据分类结果的准确率(Accuracy)来评估提出的方法的性能,准确率指所有文本中被正确预测标签的文本的占比,如式(6)和表1 所示,准确率表示为:
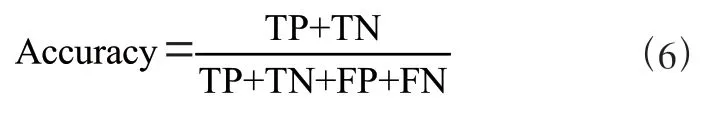

表1 式(6)中各指标含义
3.4 英文数据集实验结果
如表2 所列,在5 个和10 个作者标签的数据集上,与原始TF-IDF 算法相比,采用提出的量化方法量化文本使测试集中文本作者识别的平均准确率分别提高了10.7%和8.2%。其中支持向量机、K 近邻、闵可夫斯基距离度量(p=1和p=2)和混合距离度量(p=1 和p=2)的准确率明显提高,支持向量机模型的准确率分别提高了4%和22%,K 近邻模型的准确率分别提高了36%和18%,闵可夫斯基距离(p=1)的准确率分别提高了24%和32%,闵可夫斯基距离度量(p=2)的准确率分别提高了32%和30%,混合距离度量(p=1)的准确率分别提高了20%和12%,混合距离度量(p=2)的准确率分别提高了16%和8%。根据准确率的方差可以发现,使用提出的量化算法使得分类算法的准确性能更加稳定,各分类算法的准确率波动范围相对更小。

表2 英文数据集上作者识别的准确率
此外,与闵可夫斯基距离度量相比,混合距离度量的准确性能也更好。根据原始TF-IDF 算法量化文本时,在p=1 的情况下准确率分别高出12%和22%,在p=2 的情况下分别高出16%和22%,在p →∞的情况下分别高出12%和24%。根据提出的量化算法量化文本时,在p=1 的情况下准确率分别高出8%和2%,在p →∞的情况下分别高出8%和32%。
通过实验还可以发现,在采用朴素贝叶斯和余弦相似度算法识别文本作者时,采用原始TF-IDF 算法量化文本会有更好的识别效果。
3.5 中文数据集实验结果
如表3 所列,在5 个和10 个作者标签的数据集上,与原始TF-IDF 算法相比,采用提出的量化方法量化文本使测试集中文本作者识别的平均准确率分别提高了7.7%和2.5%。其中支持向量机、K 近邻和闵可夫斯基距离度量(p=1 和p=2)的准确率明显提高,支持向量机模型的准确率分别提高了24%和52%,K 近邻模型的准确率分别提高了24%和16%,闵可夫斯基距离(p=1)的准确率分别提高了44%和22%,闵可夫斯基距离度量(p=2)的准确率分别提高了16%和8%。与英文数据集相似,根据准确率的方差可以发现,使用提出的量化算法使得分类算法的准确性能更加稳定,各分类算法的准确率波动范围相对更小,说明提出的量化方法普遍适用性更好。
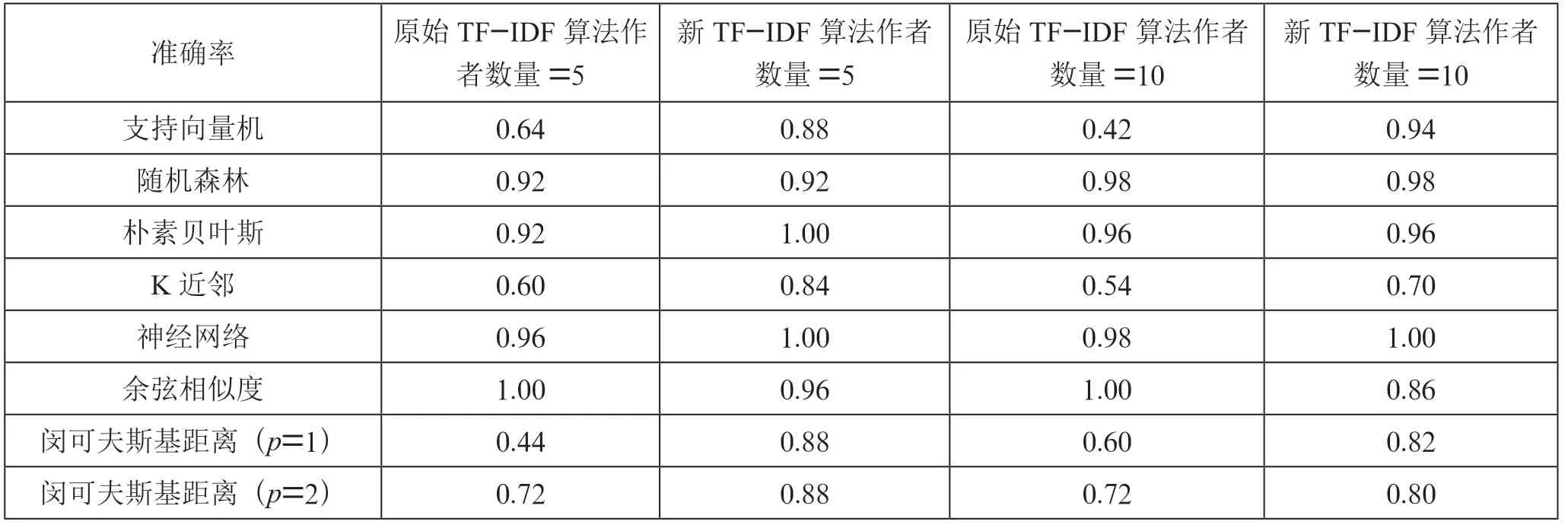
表3 中文数据集上作者识别的准确率
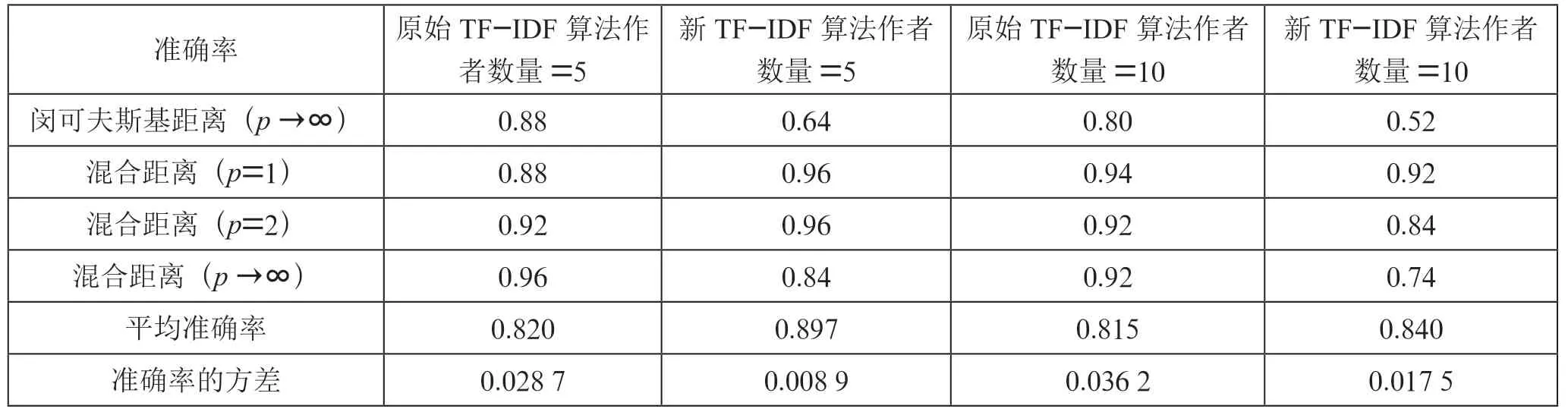
续表
此外,与闵可夫斯基距离度量相比,混合距离度量的准确性能也更好。根据原始TF-IDF 算法量化文本时,在p=1的情况下准确率分别高出44%和34%,在p=2 的情况下分别高出20%和20%,在p →∞的情况下分别高出8%和12%。根据提出的量化算法量化文本时,在p=1 的情况下准确率分别高出8%和10%,在p=2 的情况下分别高出8%和4%,在p →∞的情况下分别高出20%和22%。
通过实验还可以发现,在采用余弦相似度、闵可夫斯基距离度量(p→∞)和混合距离度量(p→∞)识别文本作者时,采用原始TF-IDF 算法量化文本会有更好的识别效果。
4 结 论
在作者识别任务中,文本内容的量化十分关键,它会直接影响作者识别的准确率。为了更好的量化文本特征,提出了基于改进TF-IDF 算法的文本量化方法,还提出了混合距离度量用于评估闵可夫斯基距离度量和余弦相似度识别文本作者的共同作用。
相比于原始TF-IDF 算法,提出的量化方法还考虑了特征在其他文本中的频率和在文本集中分布的密集度两个因素。运用提出的量化算法量化文本明显提高了支持向量机、K 近邻、闵可夫斯基距离度量(p=1 和p=2)和混合距离度量(p=1 和p=2)在英文数据集上的作者识别准确率。对于中文数据集,运用提出的量化算法量化文本明显提高了支持向量机、K 近邻和闵可夫斯基距离度量(p=1和p=2)的作者识别准确率。此外,在中英文两种数据集上,相比于闵可夫斯基距离度量,混合距离度量的准确性能也更好。
在实验过程中,根据提出的量化算法量化文本所耗的时间成本更高,主要是因为提出的量化算法考虑的因素更多,形式更加复杂。另外,预处理之后的文本特征维度仍然很大,直接影响了作者识别过程的效率。因此未来工作将着重研究特征降维的相关技术,如何提高大规模作者标签的作者识别准确率也值得进一步关注。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
作文与考试·初中版(2019年15期)2019-04-28
江西教育B(2019年2期)2019-04-12
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
小学生作文选刊·低年级版(2017年6期)2017-06-15
幸福·悦读(2009年5期)2009-06-10
