
基于局部-全局双分支网络的密集人群计数方法
2022-11-18 03:57:18邸慧军宋凌霄余晓王蔚然
北京理工大学学报 2022年11期
邸慧军,宋凌霄,余晓,王蔚然
(北京理工大学 计算机学院,北京 100081)
人群计数是计算机视觉中一个重要的研究课题,广泛应用于视频监控中. 高效且准确的人群计数算法可以对公共场所的人群密度做出准确分析,方便管理人员及时控制人口流量,防止重大公共安全事故的发生. 因此,人群计数引起了研究者们广泛的研究兴趣.
一些早期的人群计数的研究[1-2]主要采用行人检测方法. 它们通过检测图像中的行人,然后统计行人检测框的数目实现人群计数. 然而由于密集人群场景中行人遮挡频繁,基于检测的计数方法的计数精度会受到影响. 之后,LIU 等[3]使用基于高斯过程的贝叶斯回归模型建模输入图像与人群数量之间的关系. 然而,这类方法无法反映人群的位置分布,影响计数算法在监控场景中的应用.
近年来,随着基于卷积神经网络的视觉算法[4-5]的成熟,以卷积神经网络为基础的人群计数方法成为主流. 这类方法利用卷积网络强大的特征表征能力,减少人为设计特征泛化能力不足的影响. ZHANG等[6]提出了MCNN,通过设置多列不同感受野的浅层卷积网络提取不同尺度的特征. 为了提升多列CNN 生成的密度图的质量,CP-CNN[7]在MCNN 的基础上,加入了局部和全局上下文预测分支,同时在多尺度提取的分支中加大了网络的深度. 由于多列网络分支较多,结构复杂并不能高效解决人头尺度不同的问题,Switch-CNN[8]在原有的MCNN 基础上设计了一个人群密度感知分类器,对输入人群图像选择最佳的分支,更有效地提取人群多尺度特征. 这种基于分类的多列卷积网络可以有效解决由尺度不同造成的人头大小不均给计数造成的困难,获得了不错的计数结果.
但是,使用多列网络提取特征需要分别训练每一个分支. 随着分支数量的增多,参数量变大,复杂度也随之变大,这对网络训练造成困难. 因此,一些工作采用在不增加网络复杂度的情况下扩大感受野实现复杂场景的人群计数. 例如,CSRNet[9]采用堆叠膨胀卷积从而有效地估计复杂场景中的人群的密度.然而由于膨胀卷积的不连续性,会出现栅格效应,对密集的人群没有办法很好地建模. 同时,密集场景中的人群通常由数个像素点表示,这对网络准确识别人群带来了挑战与困难.
为了解决多尺度特征网络结构过于复杂,且容易出现人和场景的混淆这两大问题,本文提出一个新的计数网络:全局-局部双分支网络(global-local dual branch network, GLDBNet). 该网络主要分为两个分支:由多个多尺度特征提取模块组成的局部分支用于提取人群图像的局部信息,由多个位置感知注意力模块组成的全局分支用于提取全局信息. 这种局部-全局双分支网络,既可以解决人头尺度不均的问题,同时提升人群与场景的判别能力. 本文在常用的人群计数数据集上进行了大量的实验. 定性和定量的实验结果表明了本文方法的有效性.
1 方法
1.1 方法概述
GLDBNet 采取编码器-解码器结构,结构如图1所示. 编码器采用在ImageNet 数据集上预训练的VGG-16 网络前10 层抽取深度特征. 解码器由3 个部分组成:局部特征提取分支(local branch,LB),全局特征提取分支(global branch,GB),特征融合分支(fusion branch,FB). 局部分支通过提取多尺度特征解决人头尺度不均的问题,全局分支采用位置感知注意力获取全局上下文信息,融合分支完成全局信息和局部信息的融合. 最后通过上采样操作获得输入图像尺寸大小密度图.
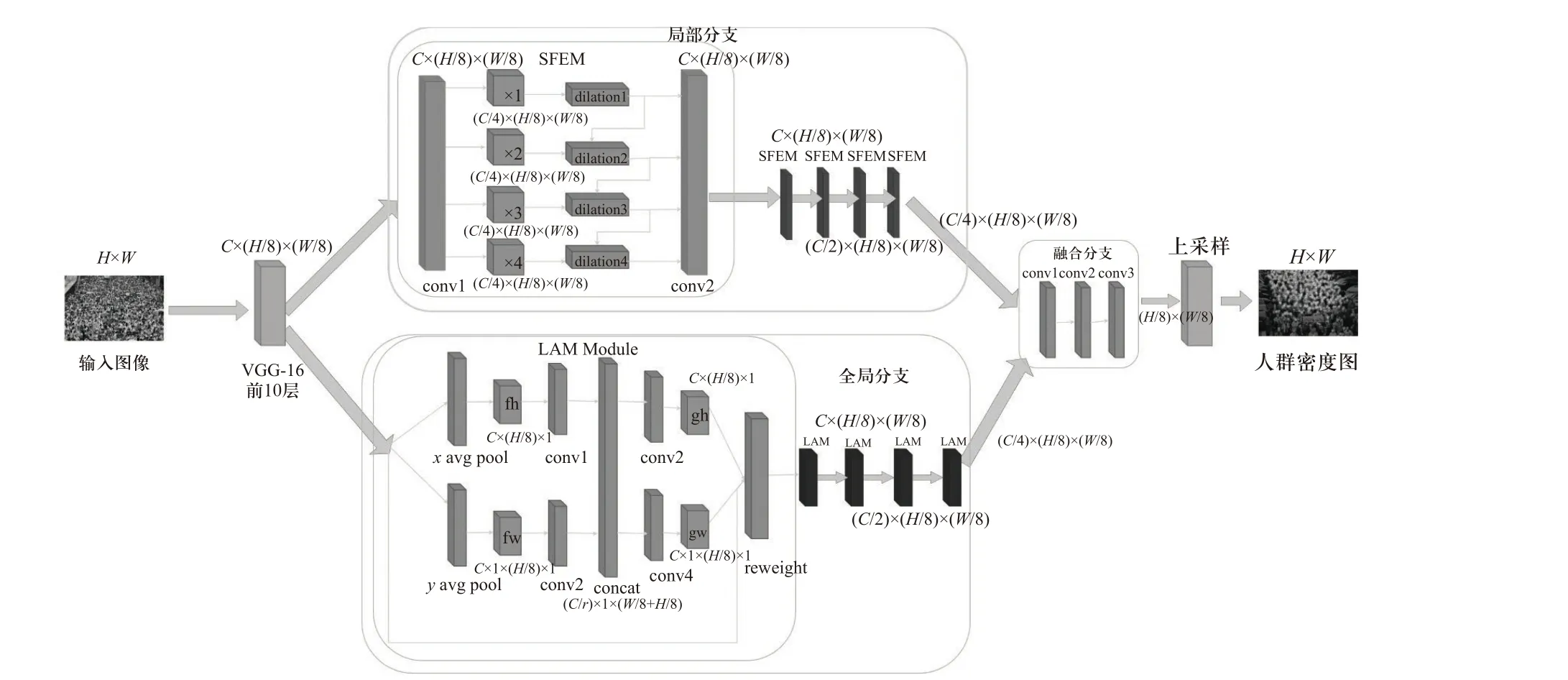
图1 本文提出的网络结构图Fig. 1 The network architecture of our proposed network for crowd counting
1.2 局部特征提取分支
“局部特征提取分支”的具体结构组成如表1 所示,其主要由多个尺度感知特征抽取模块(scaleaware feature extraction module,SFEM)级联组成,建模场景中人头尺度的变化. 每个SFEM 模块的结构如图2 所示.
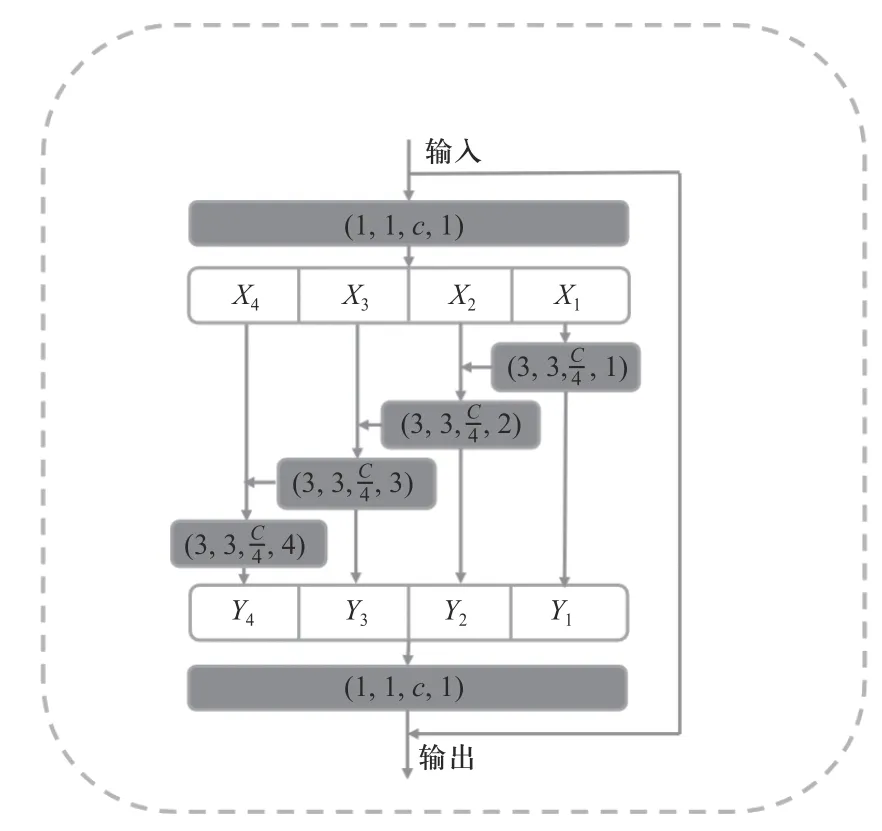
图2 尺度感知特征提取模块Fig. 2 The detail of scale-aware feature extraction module(SFEM)
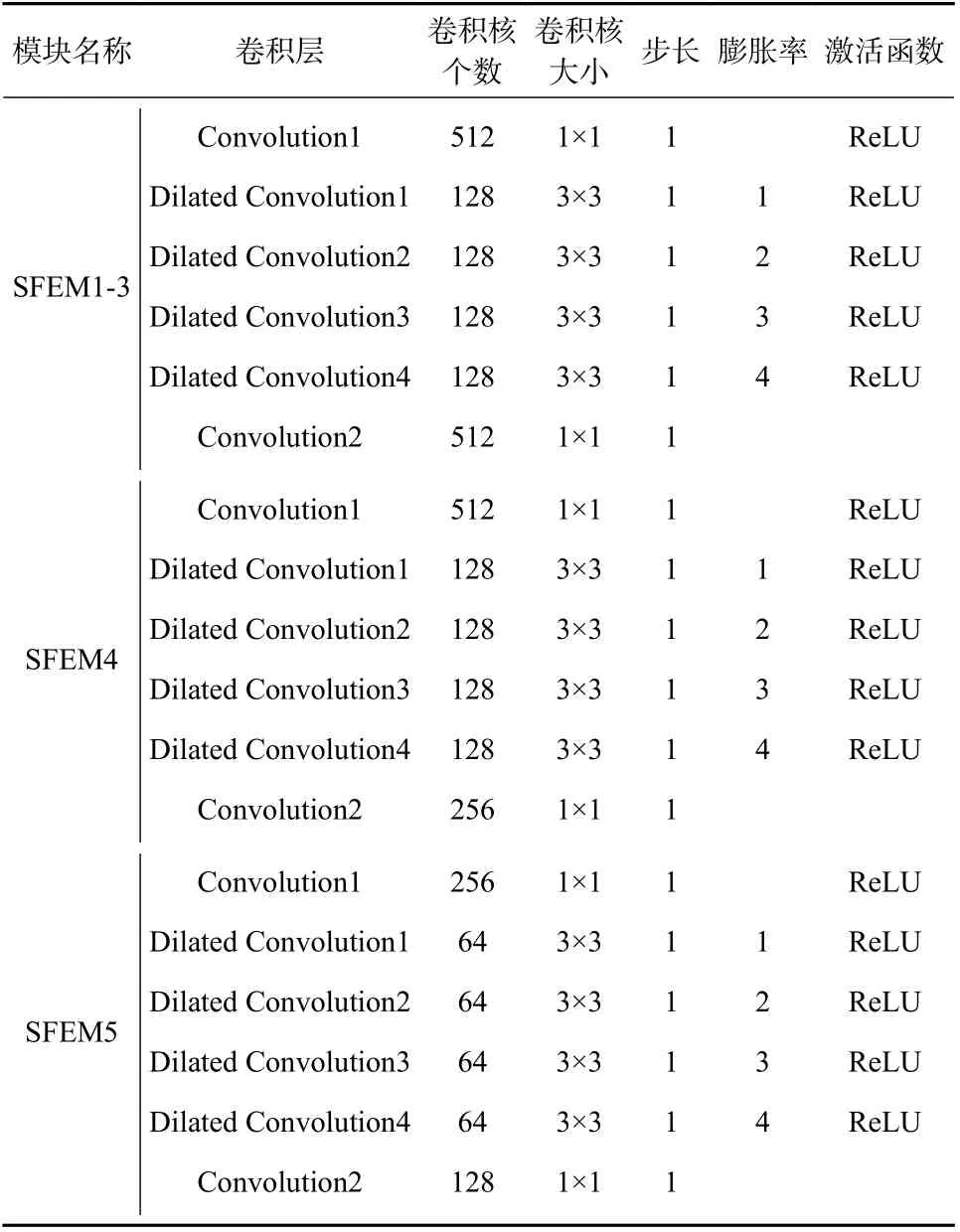
表1 局部特征分支各模块网络结构Tab. 1 The network structure of each module of the local branch
首先,输入特征经过1×1 的卷积之后按通道划分成d组特征xi(i∈{1,2, ···,d}),xi拥有和输入特征相同的空间,通道数是输入特征的 1/d. 之后,每个xi都会经过一个膨胀率为ri的3×3 空洞卷积Ki(·)处理,建模不同尺度的人头特征. 空洞卷积的示意图如图3所示. 空洞卷积在普通卷积的基础上引入了一个称为膨胀率的超参数,该参数定义了卷积核处理数据时各值的间距. 空洞卷积可以在不改变图像输出特征图的尺寸的条件下增大感受野.
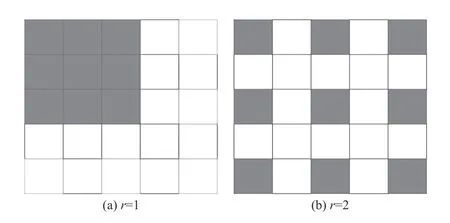
图3 空洞卷积示意图Fig. 3 Illustration of the dilated convolution
因此,每个特征子集的输出yi如下所示.
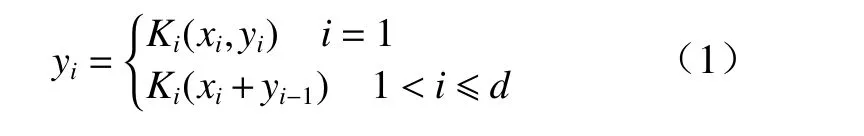
每个3×3 卷积操作Ki会接受任意j<i的子集xj.xj每经过一次空洞卷积操作,都会获得比处理前更大的感受野. 该模块输出的结果是一个不同数目、不同尺度的感受野的集合.
在获取不同尺度的特征后,本文使用1×1 卷积将划分的通道融合以获得最终的多尺度特征表达.
1.3 全局特征提取分支
“全局特征提取分支”的具体结构如表2 所示,其主要由多个位置感知注意力模块(localization-aware attention module, LAM)级联组成,获取人群场景的上下文信息. 每个LAM 模块具体工作流程如图4 所示.
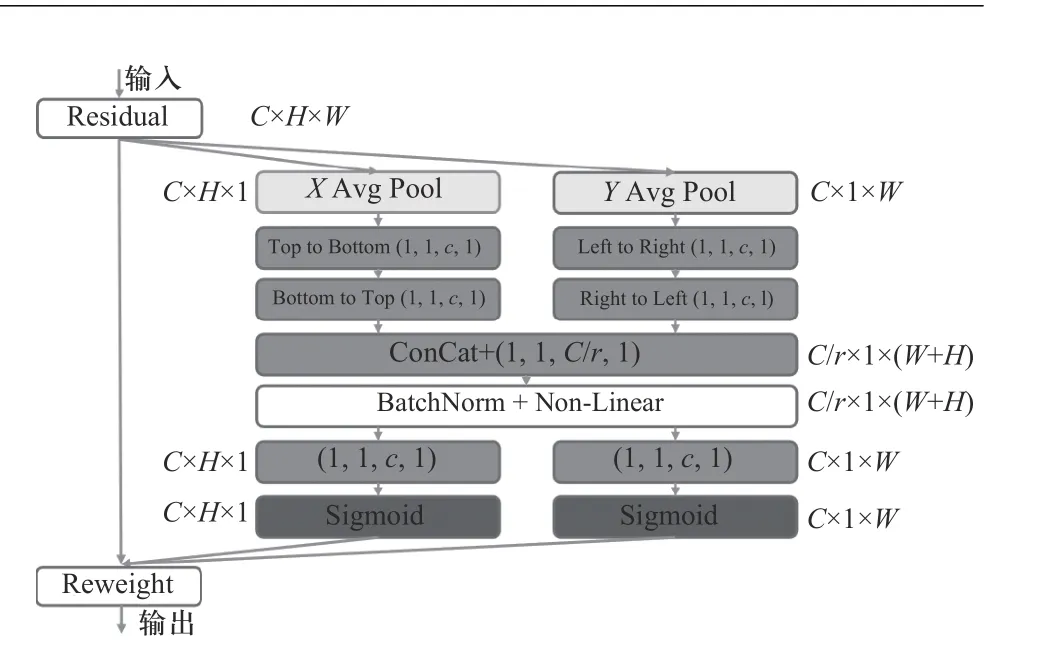
图4 位置感知注意力特征模块Fig. 4 The detail of localization-aware attention module(LAM)
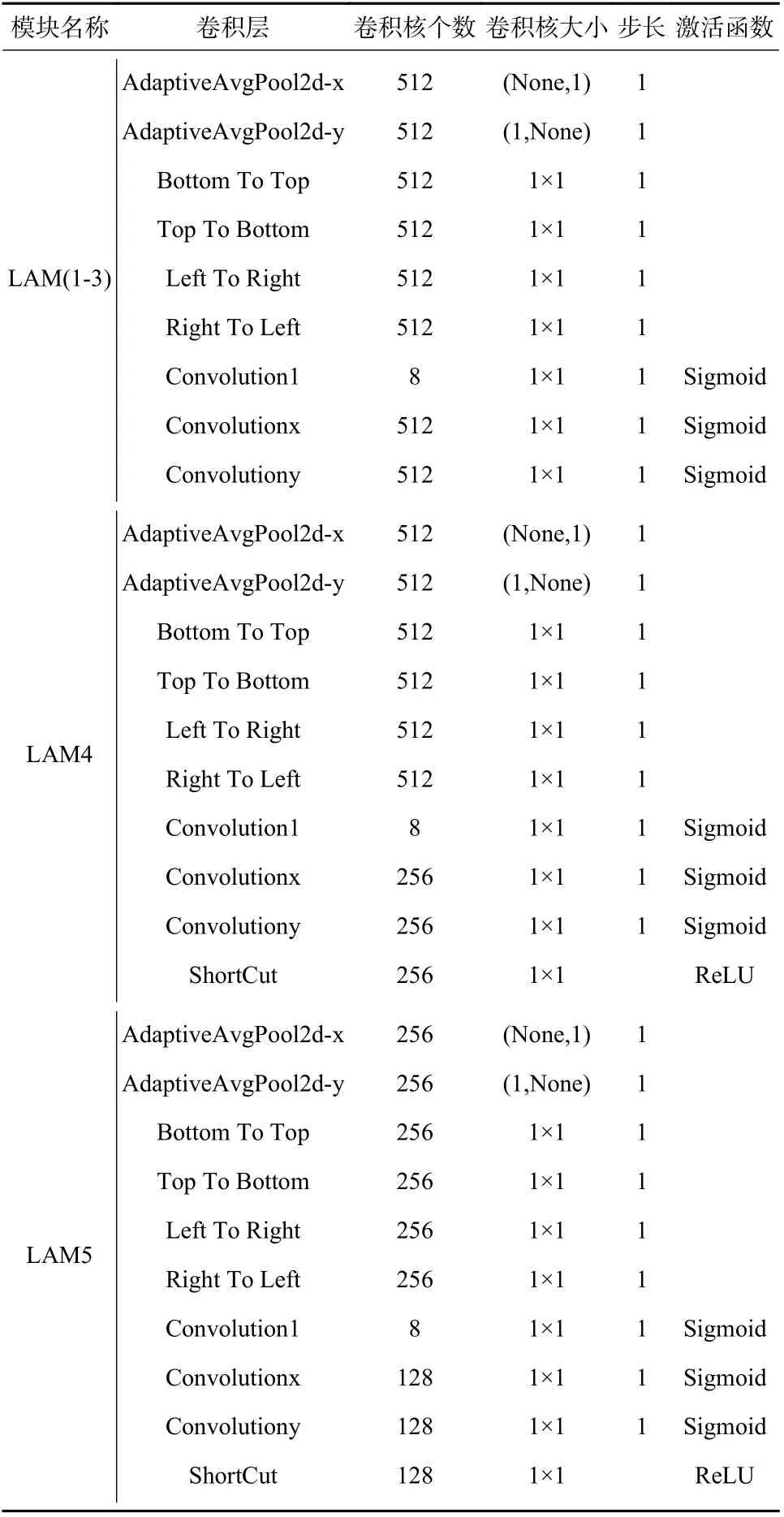
表2 全局特征提取分支各模块网络结构Tab. 2 The network structure of each module of the global branch
传统注意力机制通过将特征图全局池化来提取全局信息,把空间信息压缩成一个通道描述子而丢失位置信息,而位置信息在获取图像全局空间信息中是至关重要的. 为了让注意力机制能提取位置信息,本文对特征图在水平和竖直方向分别进行平均池化,使得空间特征信息变成一对带有空间上下文信息的一维向量. 通过该方法,网络可以提取两种空间方向的特征以及带有方向信息的特征图,在捕获长距离依赖同时,根据两个方向特征的关系获取准确的位置信息,从而更精准地定位人群.
给定输入特征F∈RC×H×W,通过水平和竖直方向的平均池化,得到两个方向的空间特征fh∈RC×H×1和fw∈RC×1×W. 随后,每个方向的特征图经过双方向卷积,获得像素级联系. 以水平方向的上-下卷积为例,池化后的特征图是一个一维向量. 从该向量的第二个像素开始,该像素的输出是当前像素和上一个像素的输出结果合并之后输入到1×1 卷积的结果,如公式(2)所示:
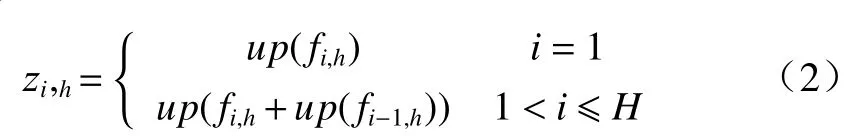
其中up(·)代表由下至上的1×1 卷积层与池化层,fi,h代表fh的第i个特征,卷积之后zh再经过一次方向相反的下-上卷积获得最终的输出结果zh'∈RC×H×1. 同理,fw按照从左至右再从右至左的卷积方式获得zw'∈RC×1×W.
通过上述方法得到的两个方向的特征,要把它们送到共享的1×1 卷积变换F1中,将之整合在一起,如下所示.
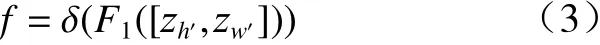
其中:[. ,.] 代表空间维度的整合操作;δ代表非线性激活函数;f∈R(C/r)×(H+W)是中间层特征图,它编码了水平、竖直方向的空间信息和像素级联系.r代表压缩率,控制模块的大小. 随后在空间维度上将f划分为两 个 独 立 的 张 量f h'∈R(C/r)×H和fw'∈R(C/r)×W,另 外 使 用两个1×1 卷积变换Fh和F w,将两个张量f h'和f w'的通道数和输入特征保持一致:
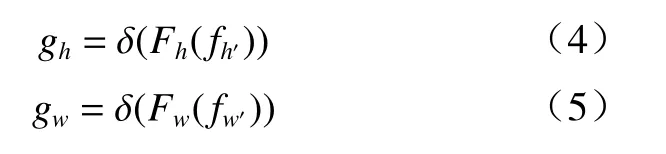
其中,δ为sigmoid 函数. 输出gh和gw作为最终的注意力权重. 该分支的各模块网络结构如表2 所示.
1.4 融合分支
融合分支是一个将双分支获取的局部特征和全局特征整合成密度图的网络分支,它由两个3×3 卷积和一个1×1 卷积构成,获取一个分辨率是原图像1/8 的密度图,最后通过上采样得到最终的密度图.其网络结构如表3 所示.
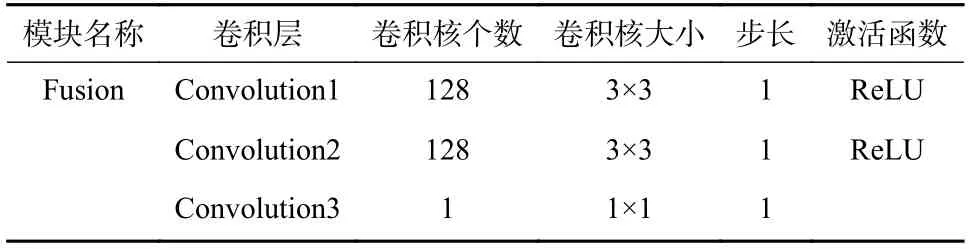
表3 融合分支网络结构设计Tab. 3 The network structure of fusion module
1.5 损失函数和评价标准
本文采用L2 损失函数优化网络,具体如下.
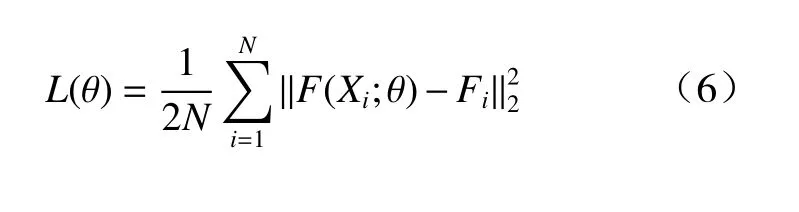
式中:N代表训练图像的数目;Xi代表第i个输入图像,F(Xi;θ)和Fi分别代表输出的密度图和对应的真实密度图;θ代表GLDBNet 网络学习的参数.
本文使用常用的平均均方误差(mean square error, MSE)和平均绝对值误差(mean absolute error,MAE)来评价网络的计数性能,具体如下.
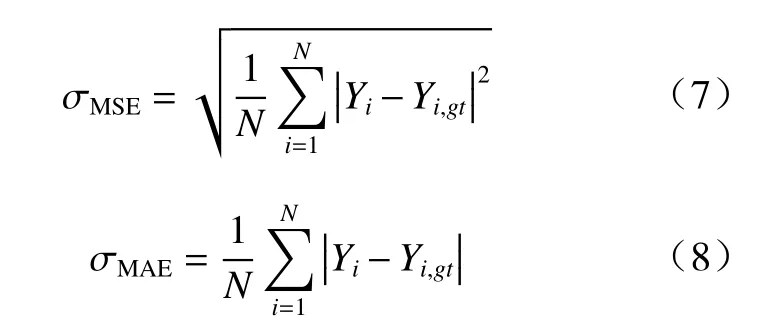
式中:N代表测试图像数量;Yi代表预测的计数;Yi,gt代表第i张图像的真实人数.
1.6 密度图生成
本文采用高斯卷积的形式生成密度图F(X),按照如下方式生成对应的密度.
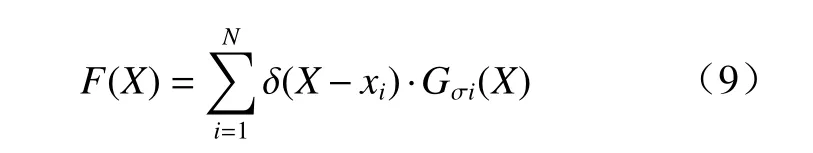
式中:G代表高斯卷积;xi(i∈1,2, ···,N)代表真实的人头位置;狄拉克函数δ(X-xi)与高斯卷积核做卷积运算. 标准差根据数据集的不同会做调整. 通过这种方式生成真实的密度图.
2 实验
2.1 实验设置与数据集介绍
2.1.1 实验设置
编码器采用在ImageNet 上预训练的VGG-16 网络,其他网络层初始化采用均值为0,方差为0.01 的高斯分布. 为了方便训练并防止过拟合,本文在每一个batch 上做随机裁剪,使得batch 上的图像分辨率保持一致. 本文将batchsize 设置为8,使用Adam 优化器训练我们的网络模型,网络的初始学习率为1×10-5,衰减率为0.99,每个epoch 的学习率通过上一个epoch 的学习率×衰减率获得. 所有实验均在1 张NVIDIA RTX 2080Ti GPU 上运行,并借助深度学习框架Pytorch 实现.
2.1.2 数据集
本文在3 个常用的人群计数数据集上进行实验,分别是ShanghaiTech,UCF_CC_50 和UCF-QNRF. 同时使用遥感数据集RSOC 做拓展实验.
1) ShanghaiTech:该数据集分为Part A 和Part B.Part A 是一个人群较为密集的人群计数数据集,包含了482 张图像. 每张图像都有人头标定,Part A的人数在33~3 139 之间变化,Part B 在9~578 之间.其中,有300 张图像用作训练,182 张图像用作测试. Part B 是一个人群较为稀疏的人群数据集,包含了716 张图像. 其中400 张用于训练,316 张用于测试.
2)UCF_CC_50:该数据集图像数目极少,只有50 张,且人数在94 到4 543 之间变化,平均人头计数为1280.
3)UCF-QNRF:该数据集的密度变化较大,包含1 535 张高分辨率图像,每张人头数目在49 个到12 865不等. 其中1 201 张图像用于训练,334 张用于测试.
4)RSOC:作为最大的遥感计数数据集,它包含了4 种遥感物体,如建筑,轿车,大型车辆和船舶. 建筑图像采集于谷歌地球,另外3 种物体采集于航空影像目标检测数据集Dataset for Object deTection in Aerial( DOTA )[10]. 本数据集有3 057 张图像,286 539个标定.
各数据集的详细信息如表4 所示.
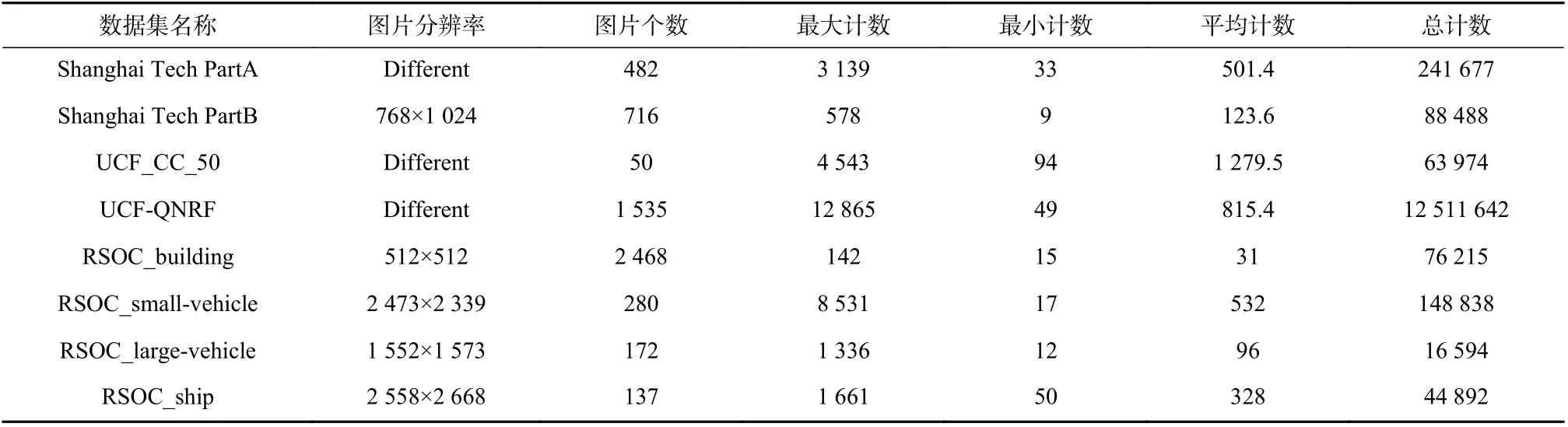
表4 数据集介绍Tab. 4 Summarization of the datasets
2.2 主要实验:人群计数
表5 展示了本文方法与其他技术方法在人群计数数据集上的性能比较. 可以看出,GLDBNet 几乎在所有数据集上均取得了令人满意的计数结果. 与RANet[11]相比,GLDBNet 在各个数据集上均取得了优异的性能表现,原因在于GLDBNet 在建模图像中像素之间关系的同时,也建模了场景中的人群尺度变化,因此,优于只考虑像素之间关系的RANet[11]性能. 与CAN[12]相比,GLDBNet 在密集人群数据集(例如ShanghaiTech PartA, UCF_CC_50 与UCF-QNRF)均取得了优异的结果, 并在UCF-CC-50 数据集上MAE指标取得了51.45 的性能增益. 这得益于本文局部特征提取分支有效地建模了密集场景中人群尺度变化. 本文方法在所有数据集上MAE 与MSE 指标均远超PRM-V1[13]与URC[14],进一步表明了本文方法的有效性.
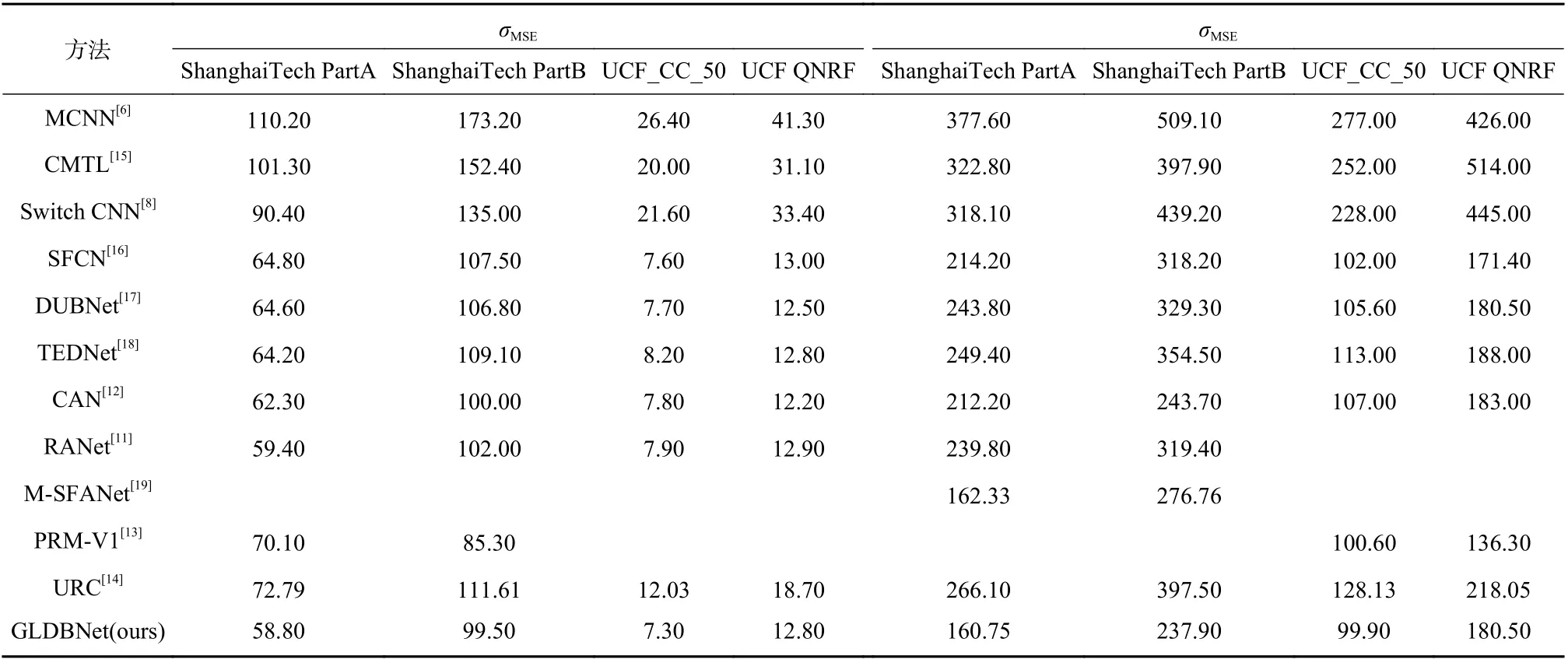
表5 在不同数据集上与11 个前沿方法的比较Tab. 5 Comparison with recent 11 state-of-the-art crowd counting methods on different datasets
图5 展示了本文方法在UCF-QNRF 数据集上不同人群密度等级下可视化的结果.该图从左至右边分别为UCF-QNRF 训练集中的第245、44、246、320、331 张图片.显然,本文方法获得的密度图更接近于真实值,计数结果更加准确. 实验结果表明,本文网络可以更好地解决拥挤的、尺度变化较大的场景.

图5 在UCF-QNRF 上运行的结果Fig. 5 The results on UCF-QNRF
2.3 拓展实验:遥感目标计数
鉴于遥感物体计数与人群计数有很多相似之处,本文通过遥感计数实验来验证网络的泛化性. 该实验的比较结果如表6 所示,估计的密度图如图6 所示,该图从上至下分别为RSOC 训练集中Ship 的第6、8张图片、Building 中的0251005 和000460、Large Vehicle中第1、3 张图片,以及Small Vehicle 中的第7、29 张图片. 本文模型在建筑、大型车辆、以及船舶数据集上有很大提升. 与每个数据子集的其他最好方法相比,本文方法提升了16.4%,2.5%,37.7%. 这证明了本文方法的鲁棒性非常优秀,即便将模型迁移到其他物体的计数上效果也很好. 虽然对于小汽车子集中,本文方法没有达到最好,但还是获得了不错的效果.有可能是预处理的时候本文做了降采样,丢失了一些信息. 同时,建筑类的可视化结果相对其他类别差了一些,这可能是因为在训练网络的时候,本文没有加语义类别的监督信息. 并且RSOC 数据集中,建筑类别的每张图片的目标数量相比于其他类别的每张图片的目标数量更少,其他类别目标分布情况相比于建筑类更稠密. 网络在训练过程中有更多的机会学习稠密小目标,而稀疏大目标学习到的机会更少.因此,网络对建筑类的识别结果不是很理想,而对小目标识别更敏感.
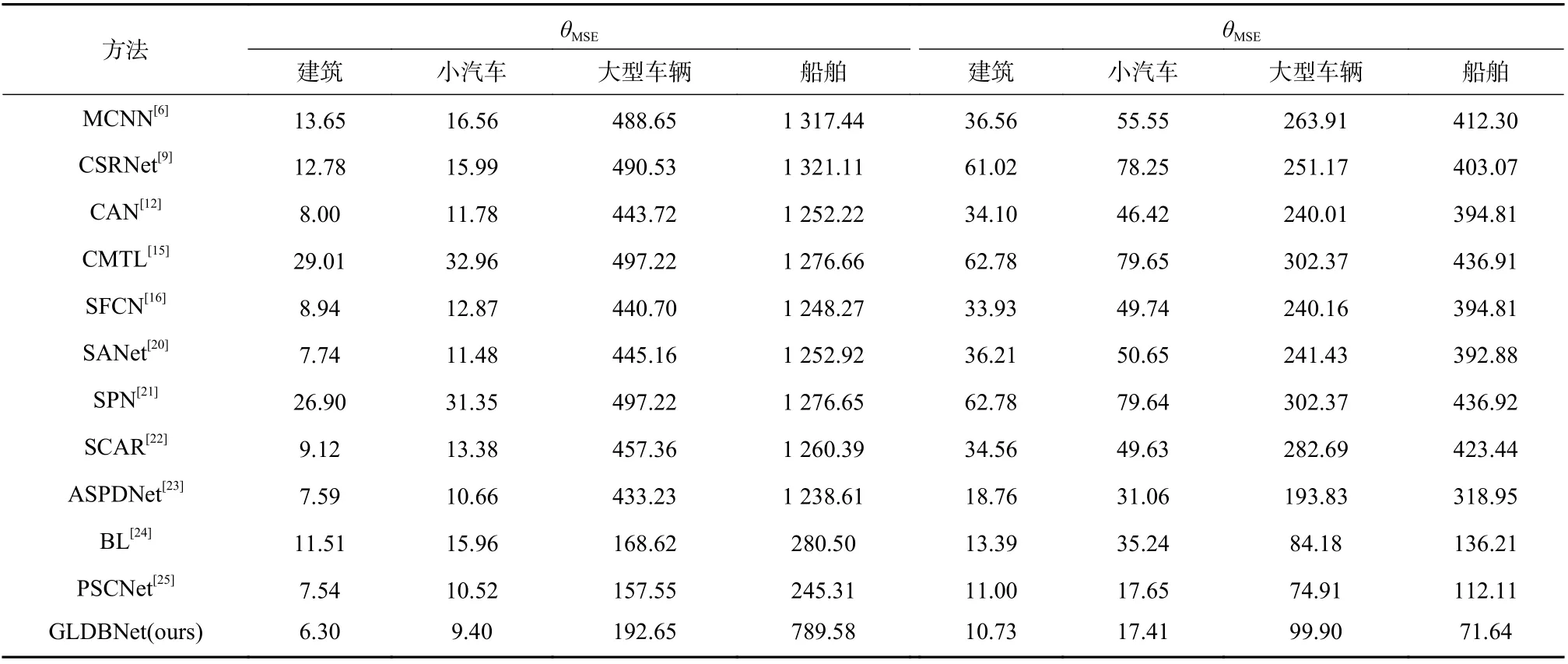
表6 RSOC 数据集上的结果比较Tab. 6 Performance comparison on RSOC dataset

图6 在RSOC 上运行的结果Fig. 6 The results on RSOC dataset
2.4 消融实验
本文先探究每个分支对计数结果的影响,然后探究每个分支模块数量对计数结果的影响.
1)各分支的作用:首先探究某个单独的功能分
支对结果的影响,之后研究各个模块之间的组合后会对结果有多大的改善. 将事先训练好的VGG-16 网络的前10 层作为对照组BaseNet. 实验组的设置如表7 所示.
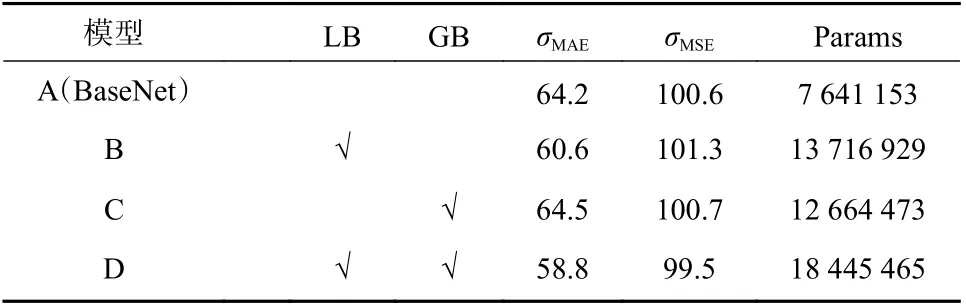
表7 不同分支组合的比较Tab. 7 The comparison results of different network configurations
通过模型A 与B 的比较可以发现,加入了局部分支对计数精度的提升有一定的作用,这是因为多尺度模块能有效提取局部特征进而提升模型精度.而模型C 比A 的效果要差一点,可能是预处理的时候丢失了一些全局信息导致的. 相比而言,模型D 获得了最好的结果,表明这种局部-全局的双分支信息,可以更好地提取特征,提高计数精度.
2)功能块数目的影响:提出的多尺度和多方向坐标注意力分支中,都有多个功能块来提取特征,所以功能块的数目是影响结果的重要因素. 由于本文网络采用的是双分支并行的模式,要保持两个分支的功能块的个数一致. 结果如表8 所示. 由表可见,1~5 的范围内,计数效果随着功能块个数的增加而提升,但是到了6 个块就下降了.
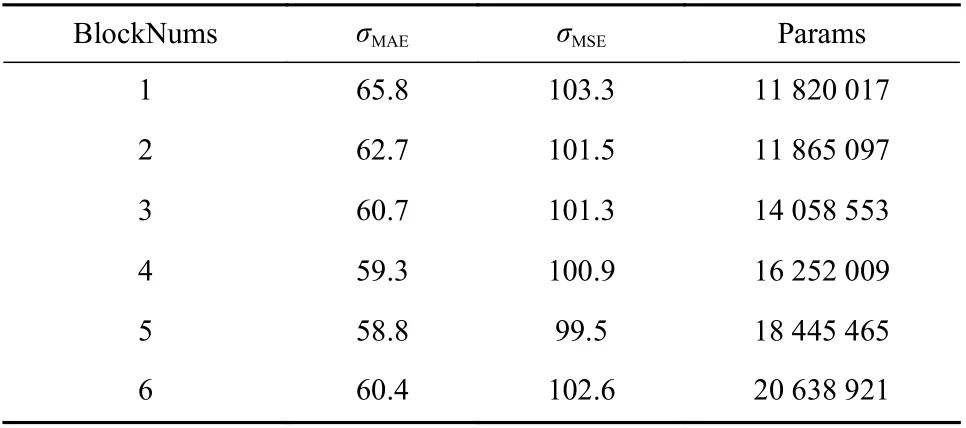
表8 不同功能块数目的比较Tab. 8 The comparison results of configurations with different block numbers
3 结 论
本文提出了一个多分支网络用于人群计数. 该网络含有两个分支:1)一个含有多个尺度感知特征提取模块的局部分支,用于高效地提取局部特征.2)一个含有多个位置感知注意力模块的全局分支获取位置信息和远距离依赖,获取全局特征. 网络充分利用人群图像中的全局特征与局部特征回归密度图,更好地应对密集场景人头尺度变化与前背景干扰问题. 本文还设计了相关实验,实验结果表明了本文方法的有效性. 同时,本文在RSOC 遥感数据集上做了实验,证明了本文方法具有极强的泛化性,较其他主流方法有较大程度的提升.
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:07:12
数学物理学报(2022年2期)2022-04-26 14:08:04
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
学生天地(2019年28期)2019-08-25 08:50:54
金桥(2018年4期)2018-09-26 02:24:54
数学物理学报(2018年1期)2018-03-26 08:16:36
太空探索(2016年5期)2016-07-12 15:17:55
中国卫生(2014年5期)2014-11-10 02:11:26
时代英语·高三(2014年5期)2014-08-26 17:01:17
山西大同大学学报(自然科学版)(2014年3期)2014-01-23 01:56:30
