
基于改进BTM 模型的医疗服务质量因素识别
2022-11-18 03:44:42高慧颖公孟秋于思佳
北京理工大学学报 2022年11期
高慧颖,公孟秋,于思佳
(北京理工大学 管理与经济学院,北京 100081)
随着在线医疗平台和网络健康社区的发展,众多在线的医疗评论语料成为知识的重要来源,许多学者对医疗评论语料展开了特征挖掘研究. 网络在线评论特征挖掘是指从大量的在线用户评论中自动地获取其关注的重要对象特征,挖掘方法主要分为有监督、半监督和无监督学习算法. 基于无监督学习算法的特征挖掘是利用算法自动识别评论文本特征,再进行筛选的过程,此方法不需要人工标注,省时省力且效率较高,其应用较为广泛的算法代表是主题模型. BLEI 等[1]提出利用LDA 主题模型进行主题特征提取;佘维军等[2]基于句法分析结合LDA 进行特征挖掘;PEROTTE[3]提出了自动决定层次主题数的LDA 模型;在医疗领域,HAO 等[4]使用LDA 主题模型对在线医疗评论进行挖掘以了解中国健康消费者的看法;高慧颖等[5]基于词共现分析改进LDA 模型进行医疗评论主题特征的挖掘;WU 等[6]考虑到从用户文本转换而来的向量空间模型的高维性,提出了一种基于LDA 的新方法挖掘在线健康社区的主题特征;YAN 等[7]为了解决短文本稀疏的问题,提出了BTM 主题模型.
虽然评论挖掘中基于无监督学习的特征提取自动化程度高且更为客观,但由于特征的挖掘有较强的领域针对性,且医疗评论文本存在其特殊性,如评论长度较短、规范性较差、语义较稀疏等,因此在主题挖掘方法上需要更多的探索. 针对在线医疗评论文本的特点,提出一种改进的BTM 模型进行医疗评论主题挖掘,提高主题挖掘的质量,并结合服务质量SERVQUAL 模型的五性,在前人研究的基础上,更全面地识别医疗服务质量影响因素.
1 BTM 模型
患者在网络平台中发表的医疗评论,往往以短文本的形式呈现. 针对短文本的挖掘,目前已有学者研究出专门处理短文本的主题模型,如BTM 主题模型. BTM 模型通过整个语料库建立BTM 语料库,不是利用简单的词频进行建模,而是挖掘短文本深层的语义关系. BTM 主题模型与传统主题模型的代表LDA 主题模型不同的地方在于,它是通过将文本中的词语排列组合成词对进行训练,扩展了训练的词语数量,如原评论包含{医生}、{态度}、{非常}、{和蔼}四个单词,BTM 会首先抽取Biterm 词对,构造{医生,态度}、{医生,非常}、{医生,和蔼}、{态度,非常}、{态度,和蔼}、{非常,和蔼}六个词对来参与训练.
然而由于未考虑语义相关性,BTM 主题模型仍存在一些不足之处,它往往假设出现在同一条评论的词对中的两个词语具有一定的相关性,但是并未考虑词对语义相关性大小对主题特征挖掘效果的影响,如有些词对虽然在一条评论中出现,但共现信息差,语义相关性较小,将这些相关性较小的词对导入训练,可能会导致挖掘出来的主题质量并不理想. 由于医疗评论短文本包含的词语数量较少,语义比较稀疏和分散,直接将传统的主题模型应用到短文本中,会面临主题特征单词共现信息少,无丰富的上下文等问题,使得文本特征高维稀疏,难以有效提取短文本的信息,导致无法挖掘出理想的医疗服务质量影响因素. 因此,本文基于这个问题,改进BTM 主题模型中词对的筛选方式,利用词共现分析方法计算词对的语义相关性,使其更适用于在线医疗评论短文本挖掘.
2 基于改进BTM 模型的在线医疗评论主题挖掘
2.1 研究方法
已有的国内医疗服务质量影响因素的识别大多依靠文献资料和临床指标,忽略了在线医疗评论中患者的真实感受. 一些学者针对在线医疗评论提出一种基于特征加权词向量的在线医疗评论情感分析方法[8],取得了一定的成果. 一些学者研究了中文文本及短文本特征提取的方法,例如基于主题和预防模型进行主题特征提取[9]、利用BTM 模型进行文本挖掘,然而由于医疗评论长度短,同一评论中的词量少且相关性不一定高,所以单纯采用以上方法无法得到理想效果.
根据在线医疗评论长度短、语义稀疏的特点,提出一种基于词共现分析的双词主题模型(co-occurrence analysis biterm topic model,COA-BTM). 研究方法如图1 所示,具体分为3 个步骤:①爬取在线医疗评论,通过筛选、分词、去停用词等预处理建立规范的医疗评论语料库. ②将规范的评论语料库中的文本词语进行两两组合,生成词对,利用词共现分析计算共现词对之间的相关性,通过设置共现阈值,筛选参与训练的词对. ③设置参数并进行吉布斯采样,更新每个词对所对应的主题,重复操作直到吉布斯采样收敛.
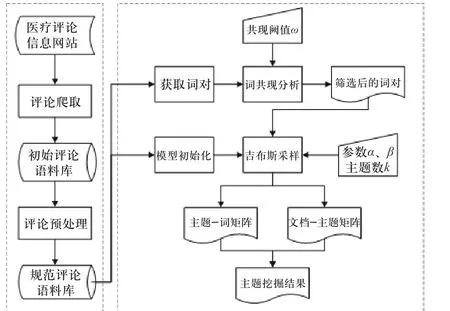
图1 基于COA-BTM 模型的在线医疗评论主题挖掘方法Fig. 1 Topic mining method of online medical reviews based on COA-BTM model
2.2 COA-BTM 算法设计
在BTM 主题模型词对的选择过程中,引入词共现分析计算语义相关性,通过设定阈值,筛选参与训练的词对,最终提高生成的主题质量,COA-BTM 算法模型图如图2 所示.
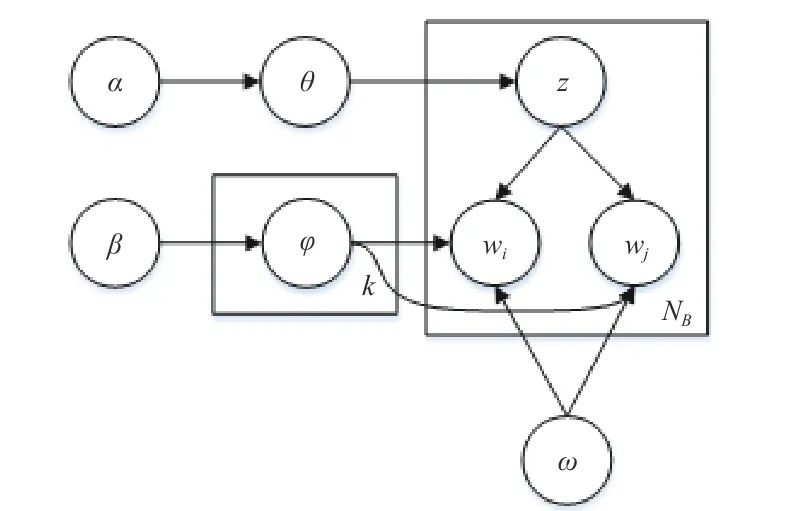
图2 COA-BTM 算法模型图Fig. 2 COA-BTM algorithm model diagram
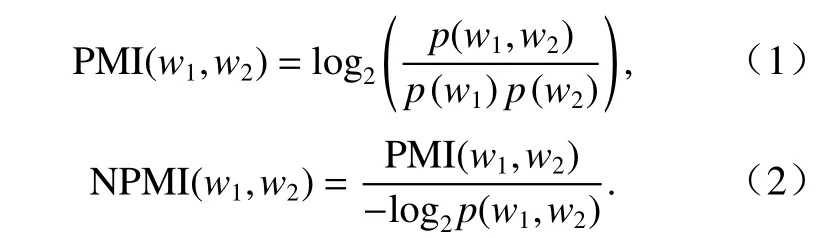
图2 中各个参数的含义分别是:NB是规范语料库中词对的集合,集合中包含文本中词语排列组合得到的所有词对(wi,wj),wi、wj是一组词对中的两个词 语,z表示 词对的主题,k表 示主题的维 度, θ 和 ϕ为文档主题和主题词语的分布, α 和 β为 参数, ω为词语共现阈值. 所提出的COA-BTM 算法具体的步骤如下.
步骤1 生成词对. 首先获取规范评论语料库中的文档,将每条文本中的词语进行两两组合,生成Biterm 词对(wi,wj),得到初始文档-词对列表.
步骤2 基于词共现分析筛选词对. 提取评论词汇表,计算共现词对之间的相关性,通过设置共现阈值ε,筛选掉语义相关性较低的词对,得到筛选后的文档-词对列表.
利用点互信息(pointwise mutual information,PMI)来判断词对中两个词语的语义相关性,统计两词在文本中同时出现的概率,越大表示词语的语义相关性越大. 计算公式如(1)所示,其中p(w1,w2)代表词语w1和w2共同出现的概率,p(w1)和p(w2)分别表示词语w1和w2单独出现的概率;为了判断词语共现的质量,选择归一化互信息(normalized pointwise mutual information, NPMI)来筛选词对,公式如(2)所示.
步骤3 参数设置. 在吉布斯采样之前,需要设置参数,根据经验值设置参数 α 和 β,利用困惑度Pp确定主题数k,如公式(3)所示,它表明预测的不确定度,该值越小表示性能越好,但主题过多可能会导致过拟合.

2.3 实验评价标准
评价主题挖掘效果的两个常用标准是主题一致性(topic coherence,TC)和JS 散度(Jensen-Shannon divergence). 主题一致性是通过测量主题中出现频率高的词语之间的语义相关度来衡量主题好坏,在之前的研究中,主题词分布的差异性通常采用KL 距离(Kullback-Leibler divergence) 来度量. 由于KL 距离是不对称的,而通常两个主题词具有语义相关性,因此采用具有对称性的JS 散度[10].
TC 值反映的是主题内的一致性即内聚程度,能够很好地应用于主题模型的主题内聚效果的对比,公式如(7)所示.
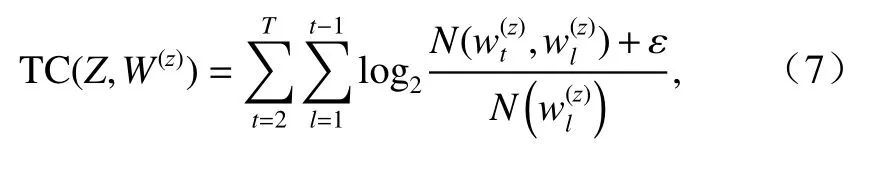

从公式(7)可以看出,主题中的一个词语和其他词语在文档集合中共现次数越多,且这个词在文档集合中出现的次数越少,主题一致性就越大. TC 值一般小于0,TC 值越高主题的内聚程度就越大.
JS 散度体现的是主题之间的差异性即离散程度.JS 散度越大则主题间的差距越大,主题的质量越高,公式如(8)所示.

3 实验分析
3.1 实验数据
目前国内具有丰富的医疗评论信息网站,其中,大众点评网(http://www.dianping.com)是中国知名的第三方综合服务评价网站,医疗服务作为服务的一种,人们也常在大众点评网发表医疗服务的相关评论. 相比于一些在线医疗评论网站只针对医生进行评价的特点,用户在大众点评网可以针对不同医疗机构做出评价,尤其是大众点评网可以定位到不同的城市,且针对不同城市的三甲医院,均有用户发表一定数量的评论. 因此利用Python 爬取大众点评网上北京地区和西部地区所有省份(或直辖市)的在线医疗评论,获取总计31 399 条在线评论信息,随机抽取22 000 条评论作为原始评论语料库. 利用Python 程序进行评论文本预处理后得到最终的规范语料库,共18 904 条在线医疗评论文本.
3.2 实验结果及分析
3.2.1 词对语义相关性计算
STUDHOLME[11]等提出基于归一化互信息的方法,弥补了互信息方法的不足. 归一化互信息可以有效平滑配准函数,提高配准精度,较传统的互信息具有更强的鲁棒性,因此本文采用归一化互信息作为相似性测度. 从规范评论语料库中随机抽取10 000 条评论数据进行实验,获取所有词对后,计算词对中两个词语的归一化互信息NPMI,来衡量词语间的语义相关性,表1 为通过计算NPMI 得到的部分词语间的语义相关性.

表1 部分词语间的语义相关性Tab. 1 Semantic correlation between some words
从表1 可以看出,词对中的两个词语经常在一起出现时,会得到较高的语义相关性,如“{核酸,检测}”这一词对. 从结果看,利用词共现计算出的语义相关性和人们的主观认知基本相同.
3.2.2 阈值选取
主题一致性不仅取决于COA-BTM 主题模型算法本身,还取决于阈值 ε的选择. 通过选取不同的阈值 ε来对模型进行对比验证,选取最好的TC 值对应的阈值 ε. 根据计算所得的语义相关性的范围,分别选取阈值 ε为0.1、0.2、0.3、0.4、0.5,选取语义相关性大于阈值 ε的词对. 参考经验值[12]将参数 α设置为50/k, β设置为0.01. 分别设置主题数k为5、10、15、20,取3 次实验的平均值,得到的主题一致性结果如图3 所示.
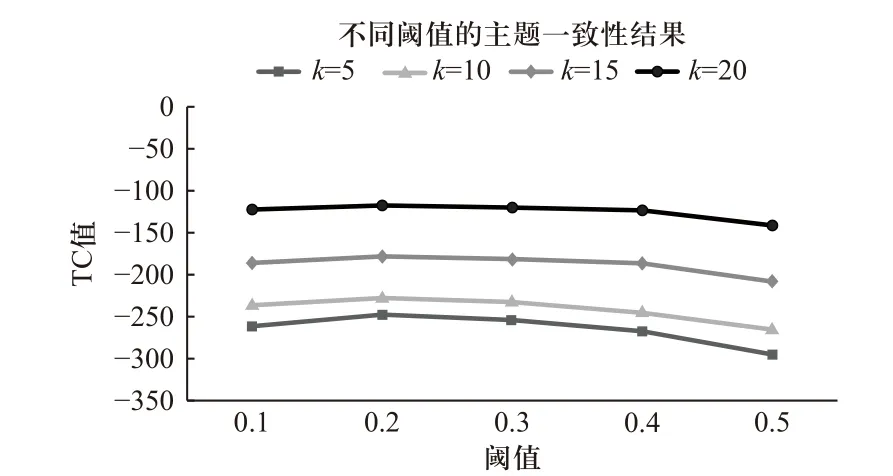
图3 不同阈值的主题一致性Fig. 3 Topic consistency for different thresholds
根据图3 中的数据和折线走势可以看出,当阈值 ε=0.2 时,主题一致性最高,而当阈值继续上升时,由于医疗评论短文本中的词语数量较少,内容比较稀疏,对其进行词共现分析时不会存在很多的双词,且对于大部分评论,并不会存在语义相关性特别高的词对,造成采样时词对更加稀疏,不能得到更高的主题一致性. 而当阈值设置得过小时,虽然词对数量相对较多,但词对间的语义相关性不大,也不能获得良好的挖掘效果. 通过分析发现,虽然主题数量的选取不同,但是阈值ε=0.2 时取得的主题一致性都是最高的,因此选取阈值ε=0.2 来进行词对的筛选.
3.2.3 基于COA-BTM 模型的医疗评论主题挖掘
为了验证本文提出的COA-BTM 主题模型算法对在线医疗评论文本挖掘的有效性,将本算法与LDA 和BTM 主题模型进行对比. 将参数统一设定,并利用主题一致性和JS 散度来验证主题挖掘效果.首先将参数统一设定为 α=50/k, β=0.01,迭代次数为1 000 次. 然后分别设置主题数为5、10、15、20、25,对于COA-BTM 模型,参考3.2.2 节的实验结果,设置阈值 ε=0.2 来筛选语义相关性大于阈值的词对,实验结果如表2 所示.
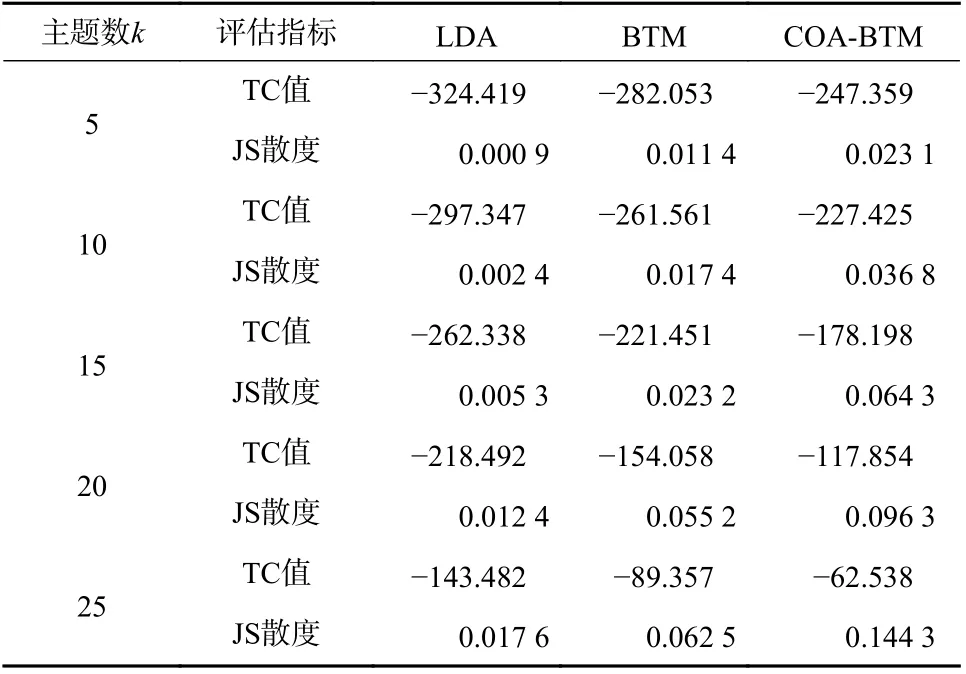
表2 不同主题模型实验结果Tab. 2 Experimental results of different subject models
从COA-BTM、LDA、BTM 三种主题模型的实验结果来看,所提出的COA-BTM 主题模型算法在医疗评论文本上具有更高的主题一致性和JS 散度. 且在不同的主题数下, COA-BTM 主题模型相较于LDA 和BTM 主题模型均具有更高的主题一致性和JS 散度,说明了COA-BTM 主题模型挖掘结果的主题内聚性更高,主题间离散性更大. 因此COA-BTM主题模型在医疗评论挖掘中具有更好的效果,因此对在线医疗评论文本有良好的适用性,证明了此算法的有效性.
3.2.4 医疗评论主题挖掘
基于3.2.3 节得知,模型中不同主题数得到的结果的主题一致性和JS 散度不同,因此主题数k直接影响主题挖掘结果的质量. 使用困惑度来确定最优主 题 数k值,分 别 选 取 主 题 数 为 5、10、······、150,困惑度计算结果如图4 所示.
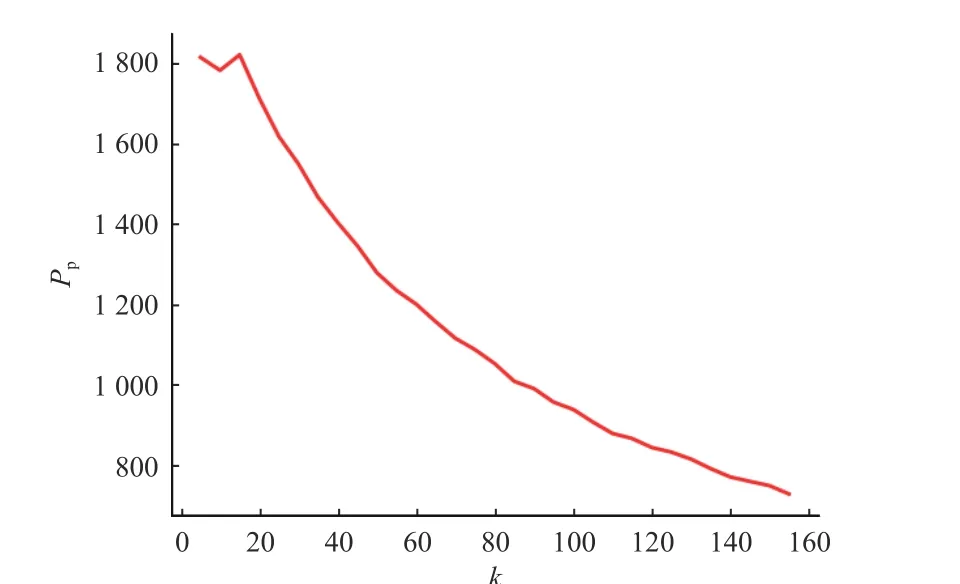
图4 不同主题数下的COA-BTM 模型困惑度Fig. 4 Confusion degree of coa-btm model under different subject numbers
由图4 可以得知,困惑度与主题数量呈反向趋势,且随着主题数增大,困惑度下降的速率逐渐变慢,主题数再增加时不会有明显的改善效果,而且会提高模型的复杂程度,可能会导致过拟合. 综合考虑,困惑度在主题数为150 时逐渐趋于平稳,且此时的时间空间成本不会太大,为了防止出现过拟合现象,本文选择主题数k=150. 并且选取每个主题中主题-词分布排名前10 的词语作为特征描述词,此时主题具有较强的可读性. 同时根据上一节的经验,设置参数 α=50/k, β=0.01,使 用COA-BTM 主 题 模型 对 规范评论语料库进行主题特征挖掘,部分主题特征示例如表3 所示.
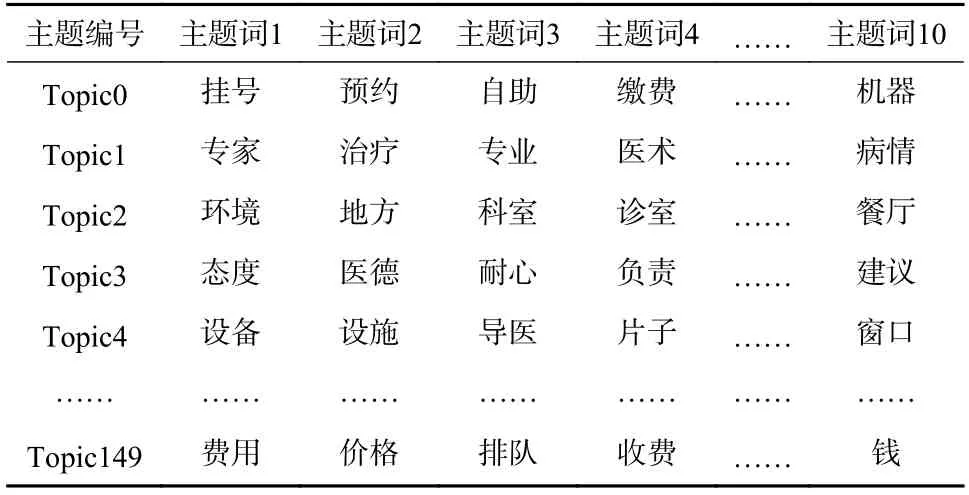
表3 部分主题特征示例Tab. 3 Examples of some topic features
基于改进的BTM 模型进行医疗评论主题挖掘,可以提高主题挖掘的质量. 在此基础上将结合SERVQUAL 模型的五性,识别医疗服务质量影响因素.
3.3 医疗服务质量影响因素识别过程
国内外医疗服务质量影响因素相关研究表明在线评论体现了患者的真实就医体验,包含大量有关医疗服务质量的信息,直接体现了患者的需求. 张琪运用Probit 对医疗服务质量影响因素研究得出就医体验类指标,如医生给予尊重等对医疗服务质量影响显著[13]. 毛瑛通过患者感知的中介效应分析得出,就医流程、医生技术水平等因素对医疗服务质量具有显著影响[14]. 基于上述的在线医疗评论主题挖掘结果,结合服务质量SERVQUAL 模型五性的定义及组成进行医疗服务质量影响因素识别,识别流程如图5 所示.
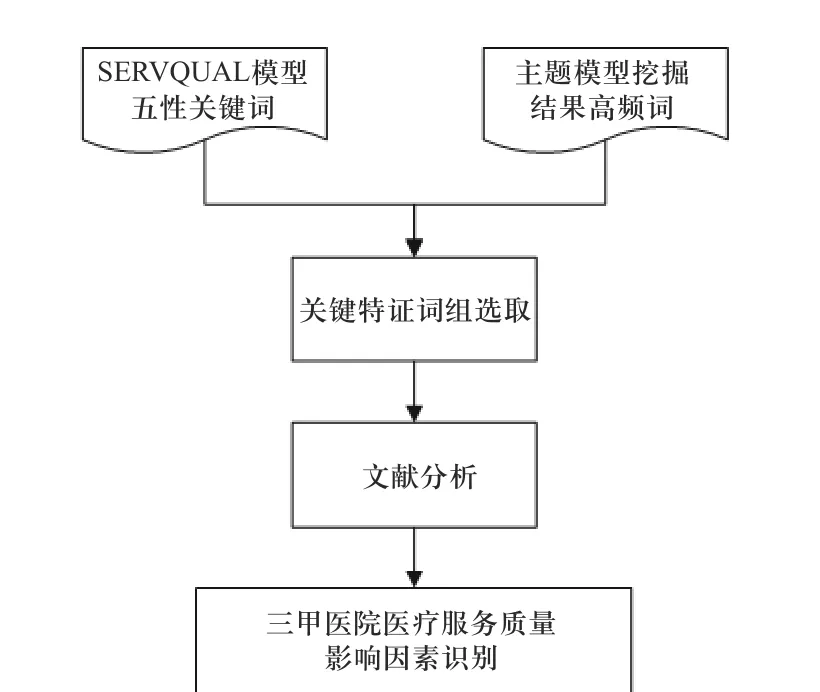
图5 医疗服务质量影响因素识别流程图Fig. 5 Construction flow chart of influencing factor model of medical service quality
3.3.1 关键特征词组选取
SERVQUAL 模型是常用服务质量模型之一.SERVQUAL 为英文“Service Quality”(服务质量)的缩写[15],包括有形性、可靠性、响应性、保证性和移情性五个维度,每一维度又包含多个问题. 根据SERVQUAL 模型的各维度定义及组成问题筛选维度关键特征词,同时对上一节得到的主题特征集进行特征词频统计,根据各维度的定义人工选取符合各维度的高频词,从而根据五性关键特征对主题词进行分组,由这两部分组成各维度的关键特征词组.
以“有形性”维度为例,展示关键特征词选取的过程. SERVQUAL 模型的有形性指服务过程中的有形部分,包括现代化的设备等. 首先从SERVQUAL模型的有形性维度定义和组成问题中抽取关键特征词,如“设备”、“设施”、“穿着”、“服装”、“外观”,然后从主题特征集高频词中抽取符合有形性定义的关键特征词,如“科室”、“机器”、“窗口”、“病房”、“床位”等,由这两部分的关键特征词取并集组成有形性维度的关键特征词组,其他维度以同样的步骤选取关键特征词组. 最终得到的五性关键特征词组如表4 所示.
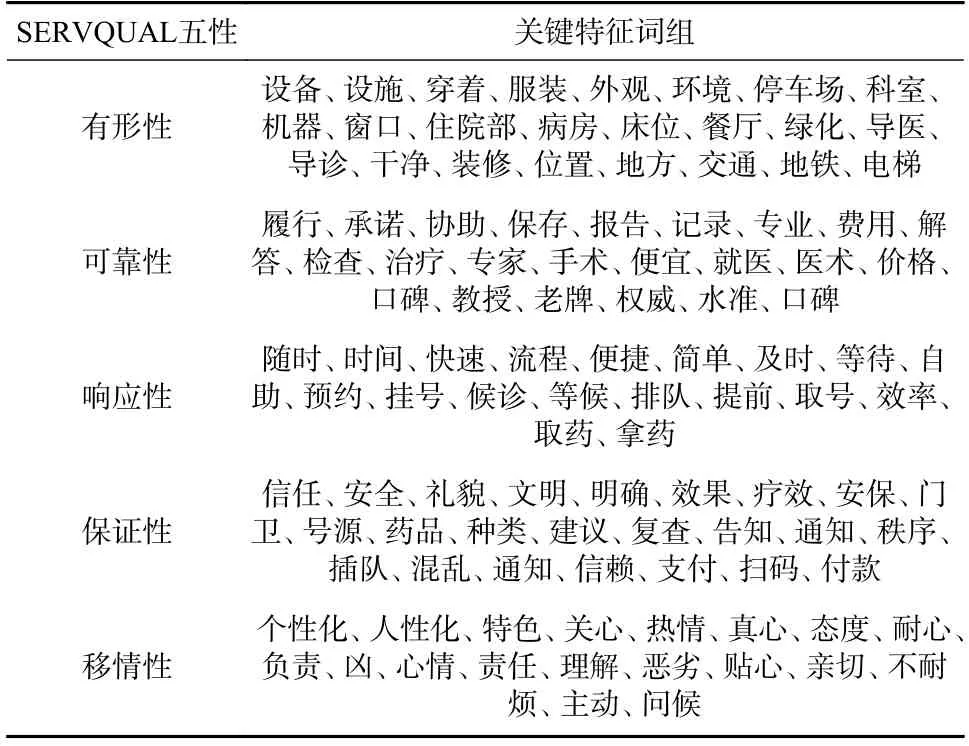
表4 五性关键特征词组Tab. 4 Five key characteristic phrases
3.3.2 医疗服务质量因素识别结果分析
本文基于文本挖掘的结果和SERVQUAL 模型,以及上一小节得到的五性关键特征词组,依据医疗领域相关特征,识别并总结得到五性维度下的42 个医疗服务质量影响因素. 为了验证所识别的医疗服务质量影响因素的有效性和全面性,查阅相关的文献资料,分析以往的文献中学者提出的医疗服务质量影响因素. 例如,林金雄等[16]提出病房情况属于有形性中的影响因素,罗海波等[17]提出就诊等候时间属于响应性中的影响因素,张慧等[18]、范关荣等[19]、马勇[20]提出治疗效果属于保证性中的影响因素,具体如表5 所示.以三甲医院为代表,本文基于文本挖掘和SERVQUAL 模型识别的医疗服务质量影响因素如图6所示.
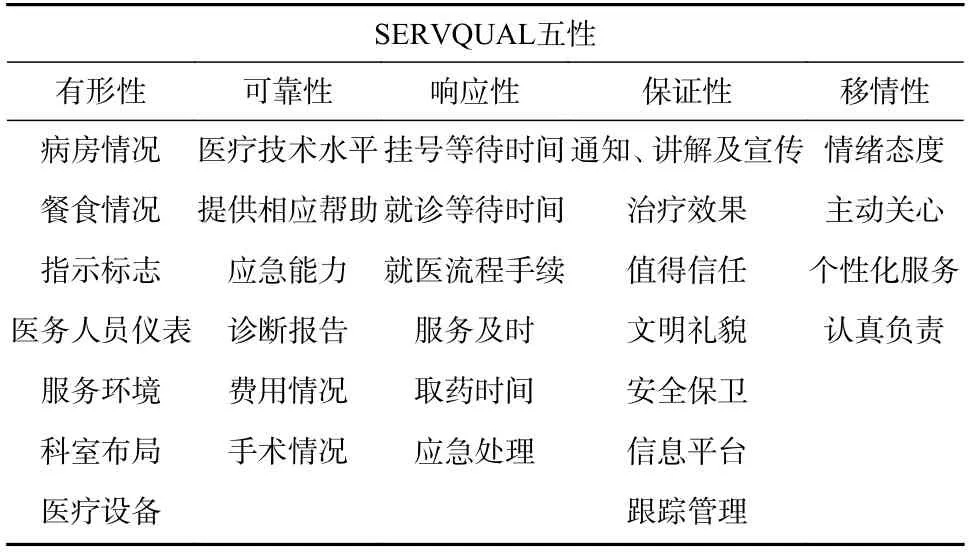
表5 医疗服务质量影响因素文献分析Tab. 5 Literature analysis on influencing factors of medical service quality
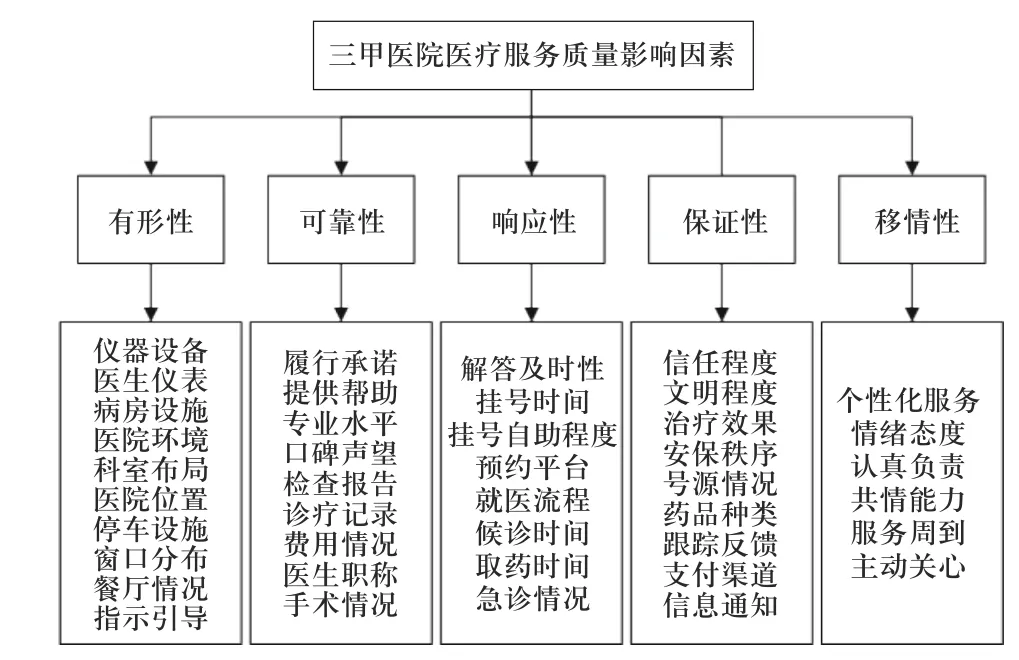
图6 三甲医院医疗服务质量影响因素Fig. 6 Influencing factors model of medical service quality in third class hospitals
将表5 文献资料中已有的医疗服务质量影响因素与图6 中因素进行对比发现,基于改进BTM 模型进行在线医疗评论挖掘得到的结果包含文献中不存在的医疗服务质量影响因素,包括“医院位置”、“停车设施”、“窗口分布”、“履行承诺”、“口碑声望”、“诊疗记录”、“医生职称”、“挂号自助程度”、“预约平台”、“号源情况”、“药品种类”、“支付渠道”、“共情能力”和“服务周到”,说明利用本文提出的主题模型算法挖掘得到的医疗服务质量影响因素,具有一定的可靠性和创新性.
4 结束语
根据在线医疗评论长度短、语义稀疏的特点,本文利用词共现分析方法计算词对的语义相关性,设置阈值改进BTM 模型中词对的筛选方式,提出基于词共现分析的COA-BTM 主题模型,该算法在医疗评论文本上的挖掘结果相比LDA 主题模型和BTM主题模型具有更高的主题一致性和JS 散度,验证了此方法在医疗评论文本挖掘上的有效性和适用性,提高了在线医疗评论主题挖掘的质量. 基于主题挖掘的结果,并参考SERVQUAL 模型的五性,通过关键特征词组选取等过程,识别了三甲医院医疗服务质量的影响因素. 本研究依然存在一些有待改进之处,后期实验可以针对多个平台的医疗评论文本展开研究,并可进一步分析患者对医疗服务质量的满意度.
猜你喜欢
开放教育研究(2020年2期)2020-03-31 01:54:14
收藏界(2019年2期)2019-10-12 08:26:42
制造技术与机床(2019年9期)2019-09-10 07:36:54
西南交通大学学报(2018年6期)2018-12-18 02:22:28
河北遥感(2017年2期)2017-08-07 14:49:00
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
现代语文(2016年21期)2016-05-25 13:13:44
学习月刊(2015年6期)2015-07-09 03:54:20
学习月刊(2015年14期)2015-07-09 03:38:04
大连民族大学学报(2015年2期)2015-02-27 08:28:11
