
一种融合关系抽取的推荐系统
2022-11-18 03:57:30高春晓卢士帅刘琼昕宋祥
北京理工大学学报 2022年11期
高春晓,卢士帅,刘琼昕,宋祥
(1. 北京理工大学 北京市海量语言信息处理与云计算应用工程技术研究中心,北京 100081;2. 北京理工大学 计算机学院,北京 100081)
随着信息技术的快速发展,人们越来越难以从庞大的信息流中寻找自身感兴趣的信息. 推荐系统通过用户的历史交互行为发掘用户的兴趣爱好,为用户个性化推荐物品.
基于内容的推荐算法应用广泛,但存在知识利用不充分问题. 为了解决这一问题,本文提出了一种融合关系抽取的推荐系统FRE-RE(A REcommendation system with Fusion Relation Extraction),用补充模板的关系抽取技术构建增强知识图谱,进而获得增强实体特征,与文本特征、基础实体特征融合后构建物品特征,应用到推荐系统中来. 实验证明,补充模板特征的关系抽取模型可以提高基础模型的效果,具有广泛的适用性;融合关系抽取的推荐系统效果优于其它模型,模型改进的各部分都是有效的.
1 国内外研究现状
推荐系统主要包含3 类:基于内容的推荐系统、基于时间线的推荐系统和基于知识图谱的推荐系统.
基于内容的推荐算法根据物品的特性和用户的特殊偏好等特征属性进行推荐. 矩阵分解是内容推荐算法中一种常见的方法,DIETZ 等[1]提出了NRTCBR 模型,将对话引用到推荐系统中,让用户在对话回合中反馈更新数据. OPPERMANN 等[2]提出了Viz-Commender 模型,在存储库中计算文本的相似性. 刘琼昕等[3]提出了一种基于知识表示学习的协同矩阵分解方法,该方法从物品的知识图谱中学习其向量表示,并在此基础上联合地分解反馈矩阵和物品关联度矩阵,两种矩阵共享物品向量,利用物品的语义信息弥补反馈数据的缺失.
基于时间线的推荐系统将用户与物品的交互时间信息融入模型中,YU 等[4]提出DREAM 模型,把用户在不同时间的动态偏好和用户的全局序列特性结合. LI 等[5]提出NARM 模型,使用新的注意力机制,对用户的行为进行序列化建模并捕获用户在当前会话中的主要目的.
知识图谱在多个领域取得了很多应用,许多学者尝试将其引入到推荐系统中. SUN 等[6]提出了NIAGCN 模型,使用逐层邻居聚合(PNA)并行图卷积网络(Parallel-GCNs)和跨深度集成(CDE). JIN 等[7]把创新后的图卷积神经网络应用在知识图谱推荐系统上来,提出了MBGCN 模型. SHI 等[8]使用深度神经网络搭配自注意力机制,提出了NeuACF 模型. KGAT[9]在CKG 嵌入层将用户-项目交互矩阵与知识图谱相结合,通过嵌入的方式得到图谱项目向量表示,然后进行推荐. 刘琼昕等[10]提出了基于知识增强的深度新闻推荐网络,利用长短期记忆网络提取知识图谱中的实体路径特征.
2 融合关系抽取的推荐系统模型介绍
系统的流程图如图1 所示,首先通过实体链接将历史行为中交互物品的文本描述转化为包含实体集合的文本描述,然后构建基础知识图谱和增强知识图谱;利用得到的两个知识图谱,进行物品特征构建;将用户历史行为中交互的物品特征向量用用户兴趣构建模型进行融合,得到用户兴趣特征向量,与目标物品的特征向量通过多层感知机相关度预测,进而进行推荐.
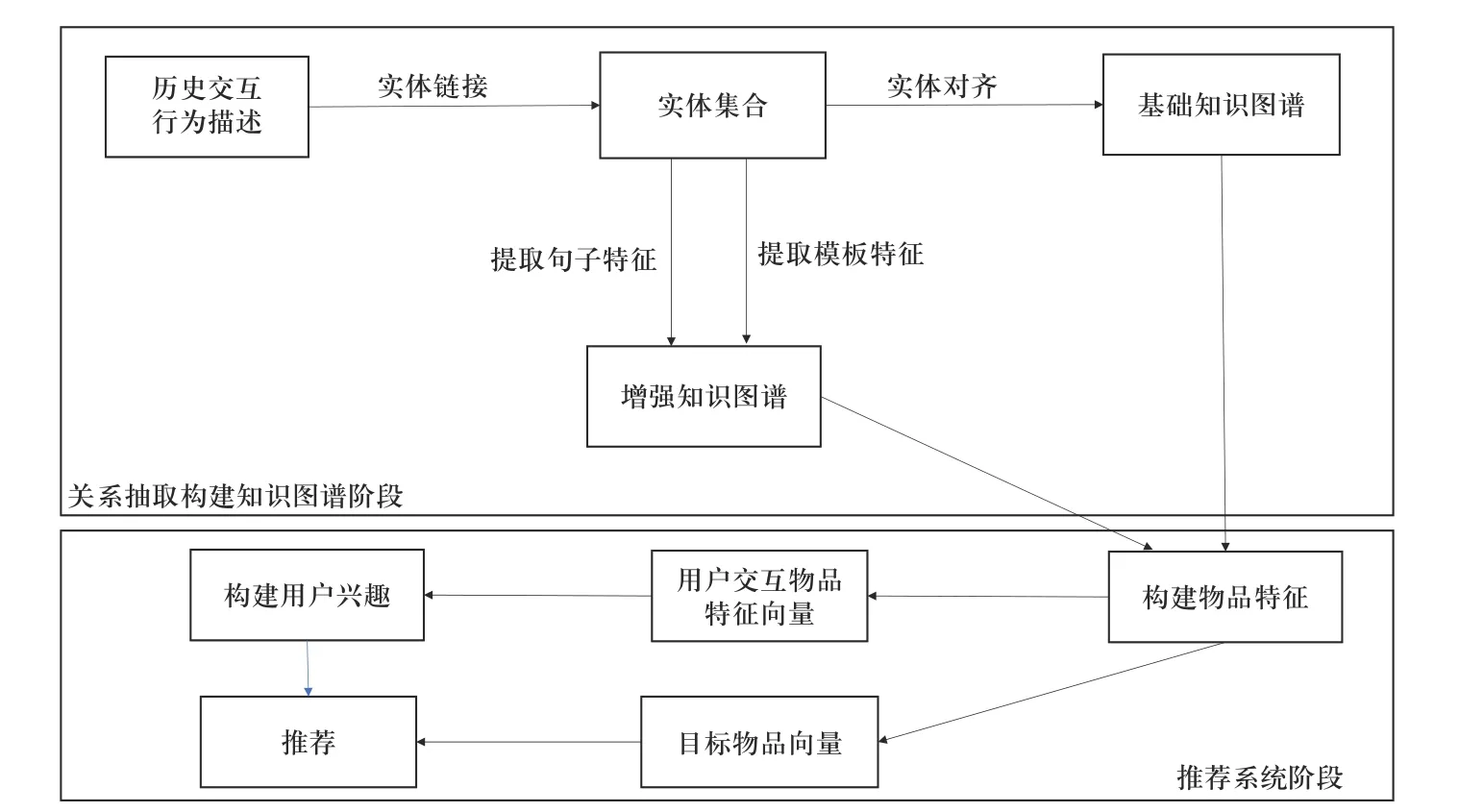
图1 融合关系抽取的推荐系统整体流程Fig. 1 The whole process of recommendation system based on fusion relationship extraction
2.1 模型架构介绍
本文提出的融合关系抽取的推荐系统由4 部分组成,分别是知识提取、物品特征构建、用户兴趣构建和多层感知机(如图2 所示).
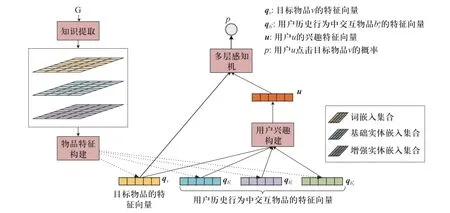
图2 融合关系抽取的推荐系统Fig. 2 Recommendation system with fusion of relation extraction
模型定义如式(1)所示.
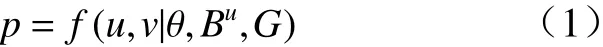
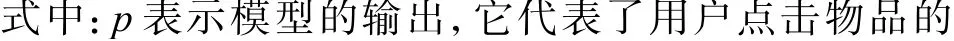

2.2 补充模板特征的关系抽取模型
传统的关系抽取模型没有充分挖掘实体在词典中的深层次联系,并且对WordNet 词典信息利用过于简单. 为此,提出了一种补充模板特征的关系抽取模型,使用WordNet 词典中实体上位词路径,同时使用与传统模型完全独立的网络结构提取模板特征.
2.2.1 模板特征
模板特征是指一个句子按照一定规则用上位词路径替换实体之后得到的句子的语义特征. 某个实体的完全上位词路径是实体在WordNet 词典中从顶层实体到该实体的一条路径.
本文中实体上位词路径定义为该实体的前n层完全上位词路径. 使用实体上位词路径替换实体后,得到的句子作为补充模板关系抽取模块的一个训练样本,通过模型训练提取模板特征.
2.2.2 关系抽取模型框架
模型分为3 个部分,分别是句子特征提取器、模板特征提取器和门限融合(如图3 所示).
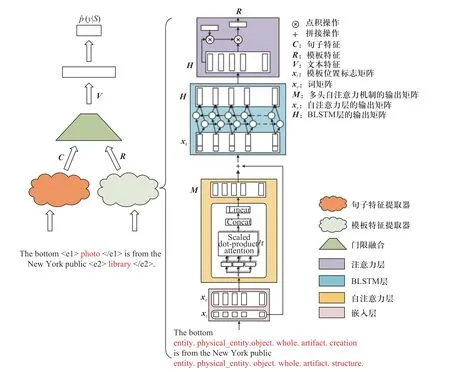
图3 补充模板特征的关系抽取模型Fig. 3 Relation extraction model supplemented with template features
1)句子特征提取.

2)模板特征提取器.
模板特征提取器是通过神经网络提取句子模板特征,并在提取过程中尽可能减少实体信息. 由于模板是一个全局特征,而双向LSTM 对提取全局特征有天然的优势,同时使用注意力机制可以进一步提高特征的准确性,所以采用双向LSTM 和注意力机制结合的方式进行特征抽取.
模板特征提取器的架构图如图3 右侧所示,由5部分组成,分别是实体替换、嵌入层、自注意力层、BLSTM 层和注意力层.
模型首先将句子中的实体替换为实体上位词路径. 具体地,采用迭代的方法,不断地寻找当前词语的上位词,直到WordNet 词典中的顶层实体;然后截取实体的前s层完全上位词路径,即得到实体上位词路径,s为超参数,实验中选取s=6(见算法1). 经过实体替换后,句子可以表示为x=[x1,x2,···,xn], 其中,xi表示句子中第i个 词,n为句子长度.


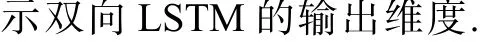


2.2.3 关系预测
在得到文本特征向量V后,本文使用全连接网络和softmax 函数作为分类器进行预测. 文本特征向量V作为输入,得到关系类别的概率分布pˆ(y|S),则预测结果yˆ 是概率分布pˆ(y|S)的最大值所对应的关系类别,如式(20)~(21)所示. 其中,S表示句子,WS∈Rm×mg为 文本特征与关系的映射矩阵,bS∈Rm为偏置向量.
2.3 融入关系抽取的推荐系统
2.3.1 知识提取
为了获取物品的描述文本中所包含的知识,本文通过一些流程进行知识提取,如图4 所示. 流程分为3 个部分,分别获得词嵌入集合Sw、基础实体嵌入集合Sb和增强实体嵌入集合Se.
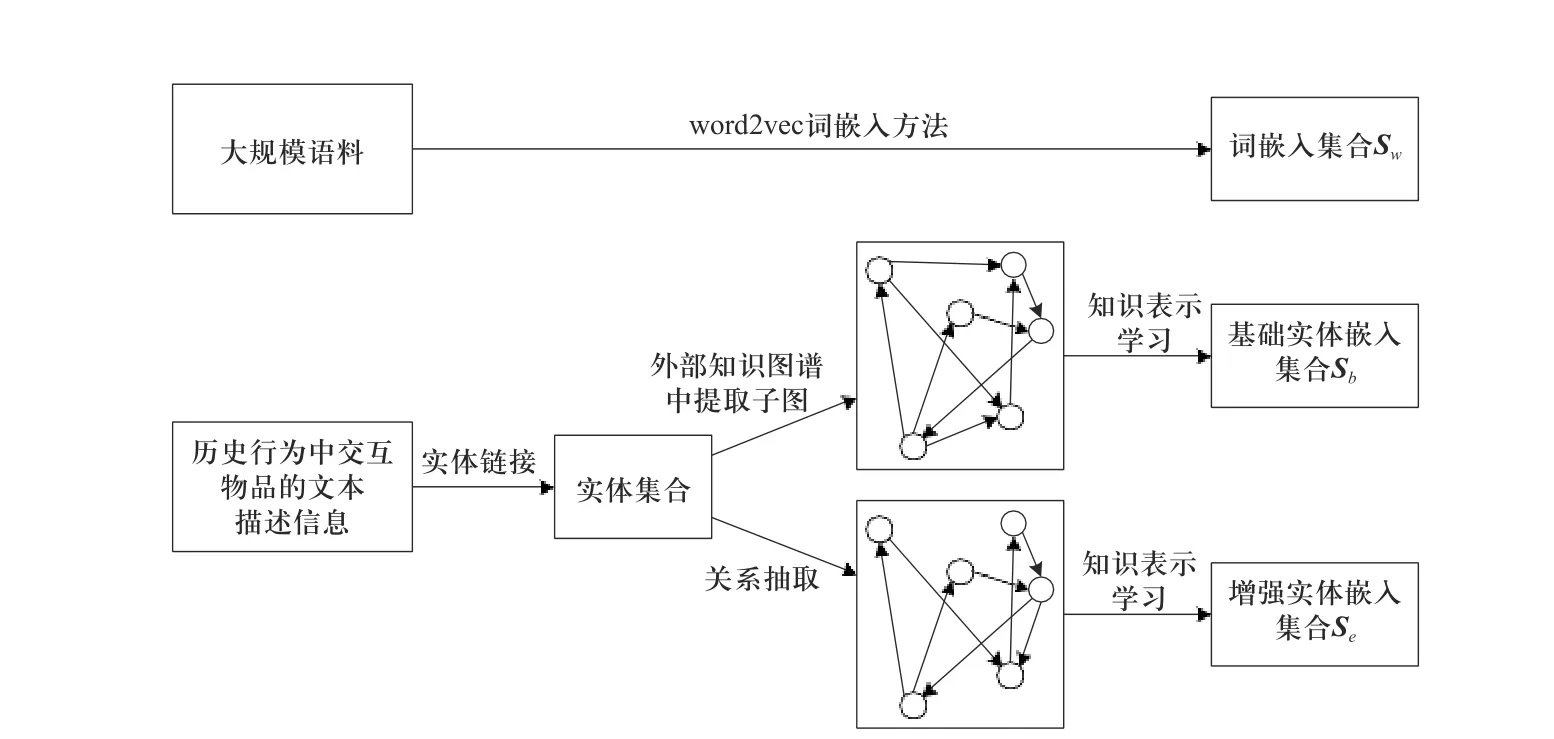
图4 知识提取流程Fig. 4 Knowledge extraction process
在获得词嵌入集合的流程中,本文使用word2vec词嵌入[12]方法,从大规模语料中训练得到词嵌入集合Sw,其中每个词嵌入的维度为dw.
在获得实体嵌入集合的流程中,本文采用实体链接技术[13-14],通过与知识库进行匹配消歧,获得文本中包含的实体集合. 由于原始知识图谱规模较大,本文从中抽取一个子图,去除不在实体集合中的结点,得到基础知识图谱. 此外,本文依据实体集合,在描述文本中标注出对应的实体,采用第2.2 节的补充模板特征的关系抽取模型进行关系识别. 经过实体链接后,一个句子中可能包含多个实体,本文对所有的实体进行组合、预测,构建出增强知识图谱. 最后本文采用知识表示学习方法(如TransE、TransR、TransD等),将基础知识图谱和增强知识图谱中的实体和关系映射到低维向量空间中,获得基础实体嵌入集合Sb和增强实体嵌入集合Se,其中每个基础实体嵌入和增强实体嵌入的维度均为de.
2.3.2 物品特征构建
本文构建物品特征采用知识感知的卷积神经网络KCNN,考虑3 种特征,分别是文本特征、基础实体特征和增强实体特征. 物品特征构建如图5 所示.



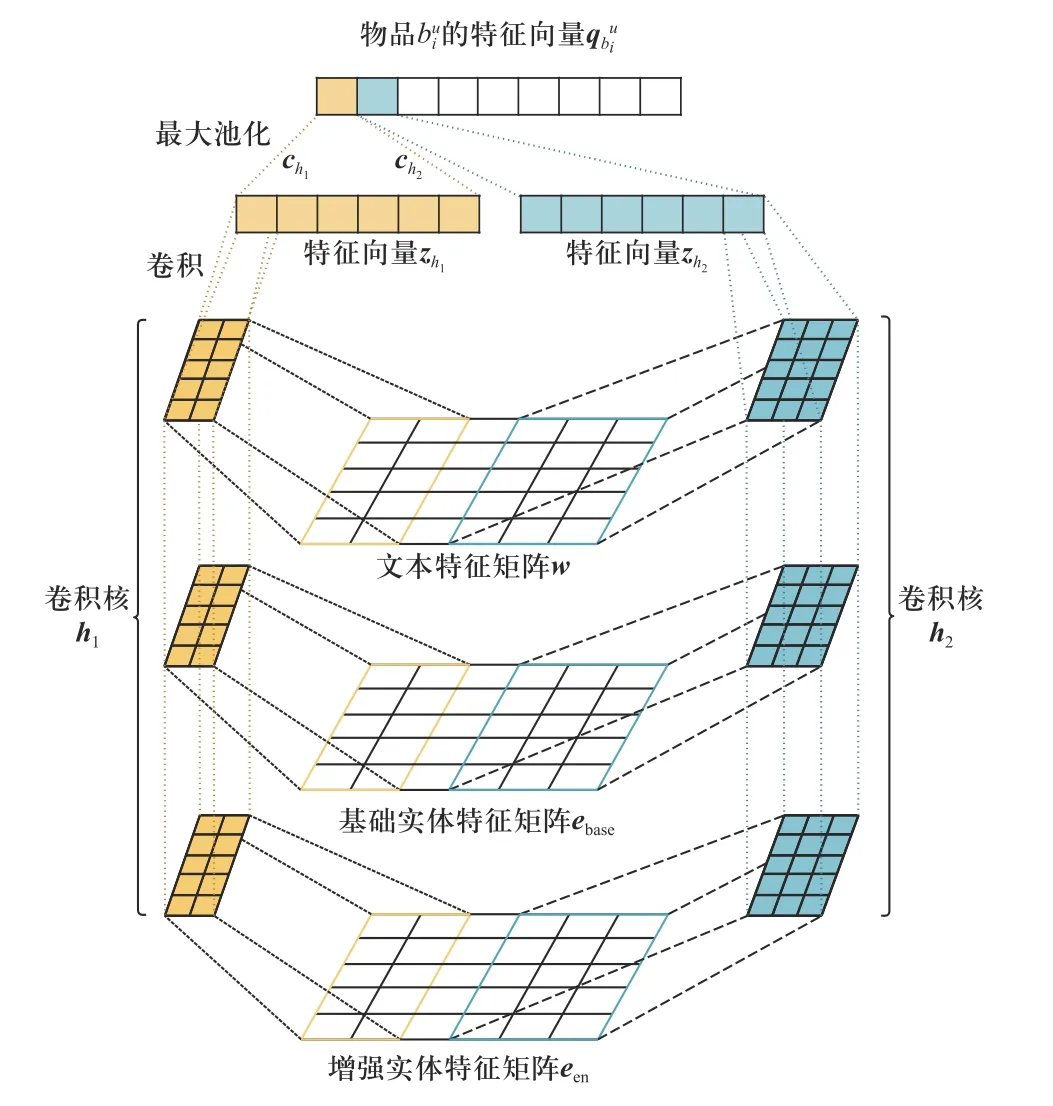
图5 物品特征构建Fig. 5 Item feature construction
2.3.3 用户兴趣构建
本文使用注意力机制构建用户兴趣,如图6 所示. 假定用户u的历史交互行为中包含n个物品,其描
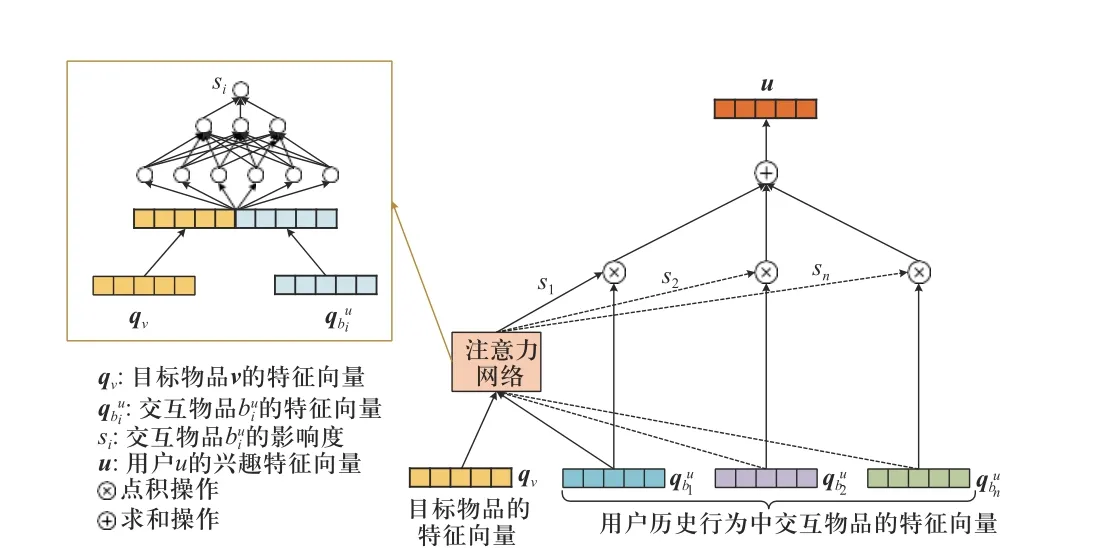
图6 用户兴趣构建Fig. 6 User interest building

3 融入关系抽取的推荐系统实验
实验包含两部分,首先验证补充模板特征的关系抽取模型的有效性,然后证明融合关系抽取的推荐系统的有效性.
3.1 补充模板特征的关系抽取模型
3.1.1 数据集和对比实验
实验使用SemEval-2010 Task 8[15]数据集进行关系抽取.
为了验证模板特征提取器的有效性和适用性,本文选择不同的关系抽取模型作为句子特征提取器,对比添加模板特征提取器前后的模型效果,实验结果如表1 所示.
本文在句子特征提取器中采用的模型包含3 类,分别是使用词法的模型、基于句法的模型和端对端模型.
由表1 可知,模型在补充模板特征后效果均有提升,这表明模板特征提取器对提升模型预测效果是有效的,并且具有普遍的适用性.
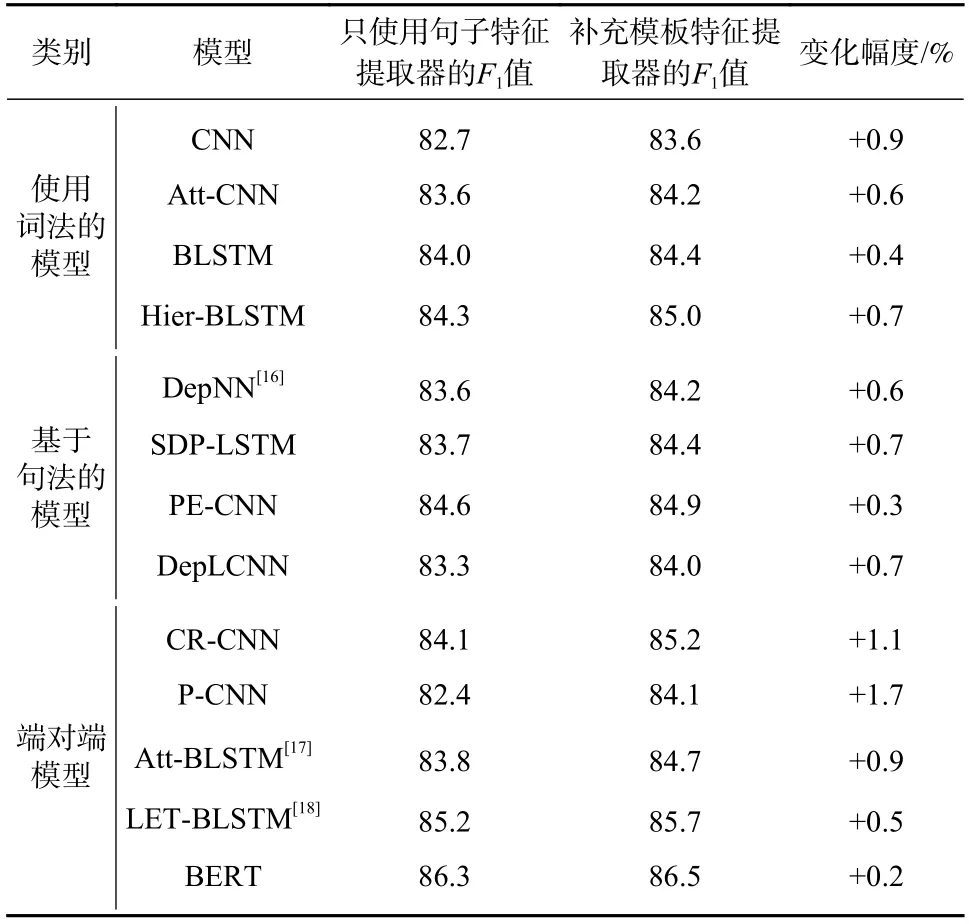
表1 模型补充模板特征前后的效果对比Tab. 1 Comparison of effects before and after model supplement template features
3.1.2 有效性实验
为了验证实体上位词路径和模板位置标志的有效性,本文采用P-CNN 模型作为句子特征提取器,设计了如表2 所示的有效性实验.
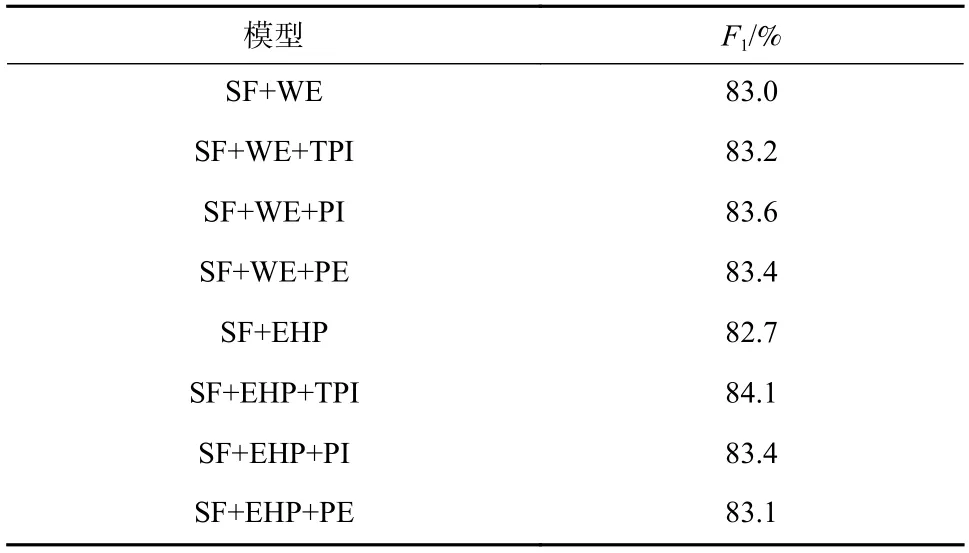
表2 模型中EHP 和TPI 的有效性验证Tab. 2 Validation of EHP and TPI in the model
其中,SF 表示句子特征提取器;WE 和EHP 分别表示使用实体和实体上位词路径进行关系抽取;TPI、PI 和PE 分别表示使用模板位置标志、位置标志和位置嵌入. TPI 指本文提出的模板位置标志;PI 指不去除4 个位置标志<e1>、</e1>、<e2>和</e2>,将其当作句子中的词,进行关系抽取;PE 指获得句子中词语与实体对相对距离,通过嵌入矩阵获得位置向量,与词向量拼接作为输入.
当使用词嵌入时,模板特征提取器模块与句子特征提取器模块功能类似,提取模板特征能力非常弱,提取句子特征能力非常强,因此使用位置嵌入方式影响最大,模板位置标志方式影响最小;当使用实体上位词路径时,模板特征提取器模块可以实现提取模板功能,且能力非常强,因此使用模板位置标志方式影响最大,位置嵌入方式影响最小. 由表2 可知,同时使用句子特征提取器和模板特征提取器,并且使用模板位置标志信息,模型可以获得最好的效果.
3.2 融合关系抽取的推荐系统
3.2.1 数据集和对比实验
融合关系抽取的推荐系统采用的数据集来自亚马逊(Amazon.com),在Electronics 子集上进行实验.将FRE-RE 与其他模型进行对比,结果如表3 所示.
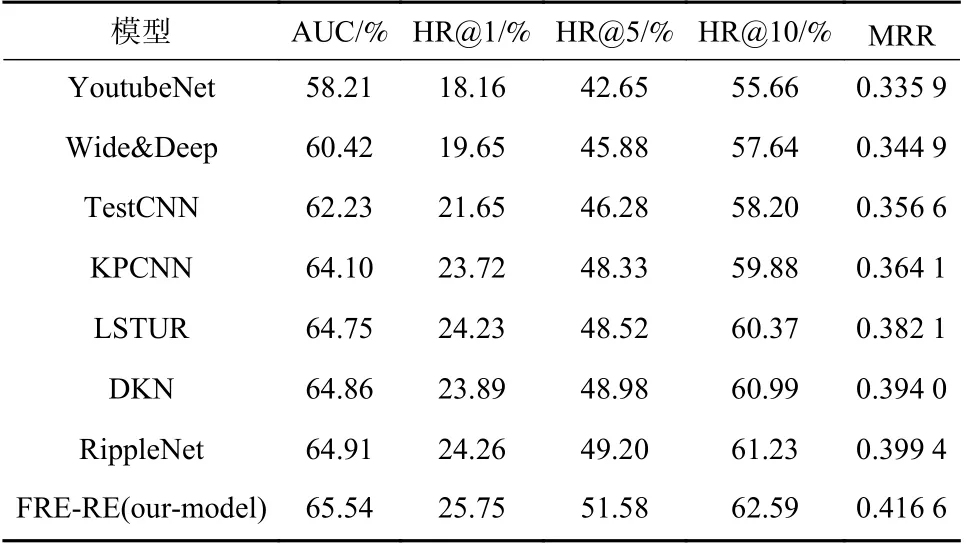
表3 Electronics 子集上与其他模型的对比结果Tab. 3 Comparison results with other models on Electronics data set
FRE-RE 在Electronics 子集上的推荐效果要优于其他推荐模型. FRE-RE 与DKN 模型相比增加了增强知识图谱信息,采用补充模板特征的关系抽取模型等获得增强实体特征,使得模型包含更多的知识信息;与RippleNet 模型相比区分了普适知识和专业知识,即基础实体特征和增强实体特征,保留了更多的有效信息,预测效果进一步提升.
3.2.2 消融实验
为了验证模型各个部分的有效性,本文设计了消融实验,结果如表4 所示.

表4 消融实验结果Tab. 4 Ablation experiment results
其中,“-EnhancedEntity”表示模型仅使用文本特征和基础实体特征;“-TemplateFeature”表示在知识提取中采用去除模板特征的关系抽取模型获得增强实体特征;“-TransE”、“-TransR”和“-TransD”分别表示使用不同的知识表示学习方法获得增强实体特征,使用不同知识表示学习方法的实验结果如表5所示.
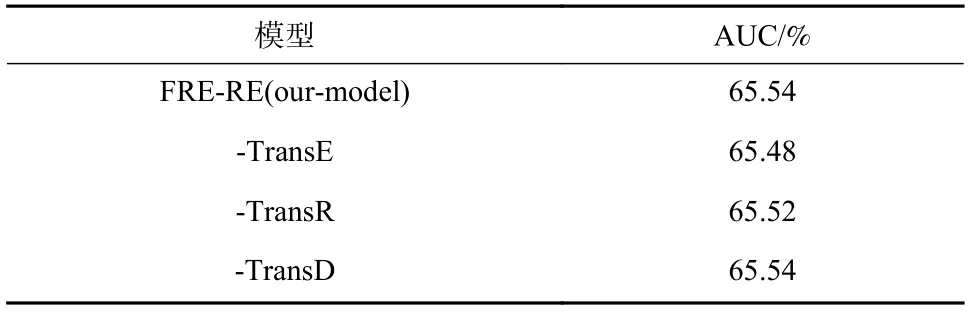
表5 不同知识表示学习方法实验结果Tab. 5 The results of different knowledge represent methods
由表4 可以得出,在物品特征构建中补充增强实体特征与未补充相比,前者模型效果比后者约高0.9%,这说明增强实体特征的有效性. FRE-RE 和去除模板特征后的实验结果相比约高0.4%,这说明模板特征在模型中的有效性. 由表5 可以得出,在知识表示学习方法的选择中,TransE、TransR 和TransD 效果依次提高,相差较小.
4 结 论
为了解决传统的推荐模型存在物品知识利用不充分的问题,本文提出了融合关系抽取的推荐系统FRE-RE,首先通过知识提取获得词嵌入集合、基础实体嵌入集合和增强实体嵌入集合;然后将所有的知识信息融入到神经网络中,构建物品特征;接着把用户的历史交互行为作为输入信息,采用注意力网络构建用户特征;最后使用多层感知机实现个性化推荐. 在获取增强实体嵌入集合时,需要使用关系抽取技术,本文对其进行深入研究,提出了补充模板特征的关系抽取模型,利用WordNet 词典信息挖掘实体间深层次联系. 该模型首先获得句子特征,然后通过WordNet 词典获得实体上位词路径作为模型输入,采用双向LSTM 和注意力机制等获得模板特征,最后通过门限融合的方式融合两种特征,预测关系类别.
实验表明补充模板特征的关系抽取模型可以提高基础模型的效果,具有适用性;融合关系抽取的推荐系统的预测效果比其他模型好,且模型的各个部分都是有效的.
在今后的研究工作中,可以考虑:在补充模板特征的关系抽取模型中使用蒸馏网络对多条路径进行选择;在融合关系抽取的推荐系统中把关系抽取和命名实体识别或事件抽取等任务联合学习. 通过这些手段,更加充分地挖掘现有数据,获取更加准确的知识.
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31 08:33:14
疯狂英语·初中天地(2021年11期)2021-02-16 00:38:58
少先队活动(2020年12期)2021-01-14 01:47:40
少年漫画(艺术创想)(2019年2期)2019-06-06 07:47:02
电子制作(2018年19期)2018-11-14 02:37:08
中成药(2017年3期)2017-05-17 06:09:01
自动化学报(2017年11期)2017-04-04 02:52:58
领导科学论坛(2016年9期)2016-06-05 14:59:58
小天使·一年级语数英综合(2015年8期)2015-07-06 06:23:32
噪声与振动控制(2015年4期)2015-01-01 07:08:21
