
数据要素市场的分级授权机制研究
2022-11-17 08:56戎珂刘涛雄周迪郝飞
管理工程学报 2022年6期
戎珂刘涛雄周迪郝飞
(1.清华大学 社会科学学院经济学研究所,北京 100084;2.同济大学 经济与管理学院,上海 200092)
0 引言
近年来,数字经济日益成为各国经济增长的重要驱动力。中国的数字经济增加值从2007 年的1.39 万亿逐年增长至2017 年的5.30 万亿,年平均增长率达到了14.32%,累计增长近4 倍;2017 年中国数字经济增加值在GDP 中的占比约为6.46%,成为国民经济的重要组成部分[1]。数字经济的发展让数据的价值不断提升,《经济学人》杂志在2017 年指出“世界上最有价值的资源已不再是石油,而是数据”。中国充分意识到了数据要素在数字经济中的重要地位,且高度重视数据要素市场的发展。2017 年,习近平总书记主持中共中央政治局第二次集体学习并在讲话中指出“要构建以数据为关键要素的数字经济”。2020 年,《中共中央国务院关于构建更加完善的要素市场化配置体制机制的意见》将数据作为一种新型生产要素写入文件。2021 年,国家统计局发布的《数字经济及其核心产业统计分类(2021)》对数字经济作出具体定义,并指出“数据资源是数字经济发展中的关键生产要素”。目前,已有最新研究从宏观经济增长的视角阐述数据要素的重要作用[2-4],且数据要素的产业经济基础[5]、创新价值[6]乃至数字税费问题[7]也开始得到关注,但对整个数据要素市场和交易机制的研究仍有待进一步深化。
数据的确权是数据成为一类生产要素进入市场,进而进行后续流通和交易的基础[5-9]。从国民经济发展的历程来看,要素权属的重要性不言而喻。改革开放以来,生产要素的市场化改革为中国经济的发展作出重要贡献[10],要素市场的扭曲会阻碍经济的进一步发展[11]。生产资料的确权是生产要素市场得以健全运行的基础,我国很多的法律法规保障了各类生产要素能合理、合法地进入生产活动并获取报酬,比如,《中华人民共和国土地管理法》规定了土地的所有权及利用法则,《中华人民共和国劳动法》则保护劳动者的合法权益等。在现阶段,数据的权属问题正在成为阻碍数字经济进一步发展的制约因素,数据的确权已成为在数据要素市场发展中亟待解决的重要问题。
当前数据要素市场所面临的很多问题均源自数据权属不清。在数字经济时代,平台企业作为当前数据收集和使用的重要主体[12-13],其在数据要素市场中存在不合理行为。比如,互联网平台在收集、运用数据时存在不规范行为。早在2018 年,中国消费者协会就对100 款App 进行测评,结果显示超九成App 涉嫌过度收集用户个人信息,还有部分App存在账号注册容易注销难的现象。再比如,数据要素流通和交易中面临的各种障碍。数据的流通有助于数据本身发挥更大的价值[14],如果无法对用户在互联网平台上产生的数据进行确权,数据要素可能无法以较低的交易成本流向最能发挥其价值的地方。而根据科斯定理,在交易成本很高的情况下,数据确权不当会影响资源的配置效率并损害社会福利[15]。可见,数据权属不清造成的影响是贯穿整个数据要素流通的链条之中的,确权不合理很可能会降低整个数据要素市场的资源配置效率,进而损害用户的社会福利。
尽管数据确权非常重要,但是数据如何确权并没有在学术界达成一致。目前,解决数据确权问题的主要思路是,数字平台上所产生的数据,其权属需要在用户和数字平台之间进行界定。一些学者基于这一逻辑,试图对数据确权提出一个统一的标准[5,8]。但是,由于不同数字平台应用场景下,数据衍生的权利可能存在差异性,且用户和数字平台各自在多大程度上拥有数据所衍生的各项权利也存在很大的差异性,因此很难用一个统一的标准去对所有应用场景下的数据权属进行清晰的界定。
鉴于此,本文提出一种解决数据确权问题的新思路。本文认为,可以让用户和数字平台围绕着数字经济的生产活动进行市场化的数据分级授权。数字经济的实践中,数字平台对数据的基本诉求是能够让数据要素合法地进入到数字经济的生产活动之中,而数据所体现的与生产活动不相关的权利并不是数字平台关注的重点。因此在这一数据分级授权的新思路下,用户不再需要考虑数据衍生的具体权利有哪些,只需考虑数据能在何种程度上进入数字平台的生产活动之中即可。而事实上,针对数据进行分级的逻辑在一些最新的政策文件中已有探索。比如浙江省市场监管局批准发布的《数字化改革 公共数据分类分级指南》提到,需对公共数据的敏感程度进行从L1 到L4 的分级,从而促进公共数据的共享开放和增值利用。但是这类文件更多是基于数据的敏感程度外生地提出分级标准,而不是基于数据要素市场本身去内生地决定数据分级标准。
不论是在学术层面还是政策层面,有关数据要素市场的分级授权体系研究仍然有很大空间。因此,本文构建经济学模型,论证数据分级授权机制对数据要素市场带来的影响。研究发现,数据分级授权机制,可以提升愿意授权数据的总用户数和平台企业获得的数据要素总量;也可以提升用户福利和社会福利,并扩大用户在数据要素市场的社会福利占比。这一系列的结论证实了,数据分级授权机制的构建,有利于整个数据要素市场的健康、持续发展,也有助于用户更多地享受到数据要素市场发展所带来的红利,提升数据要素市场的普惠性,进而促进数据要素市场的“共同富裕”。
1 文献综述
1.1 数据的定义
资源的稀缺性贯穿着整个经济学研究,而对资源的确权及相关的权益保护同样伴随着市场经济的萌芽、发展和成熟。因此,首先有必要对数据这一资源的相关概念进行界定。从信息技术的视角来看,国际标准化组织(ISO)在信息技术词汇中将数据(data)定义为“以适合交流、解释或处理的正式方式对信息进行解释的表述方式”。从经济学的视角来看,数据被归为信息的一类[3]。具体而言,信息(information)可以被理解为能够完全用二进制位串(bit strings)表示的经济物品,可以分为两类。一类是创意(idea),在遵循了Romer 的研究后[16],创意被定义为能够产生经济物品的一组指令[3];另一类就是数据,所有除了创意之外的信息均被归为数据。从法学的视角来看,欧盟的《数字市场法提案(Proposal for a Digital Markets Act)》将数据定义为“行为、事实或信息的数字表现以及任何此类行为、事实或信息的汇编,包括以声音、视觉、试听记录的形式”。还有研究指出数据包括了符号层的数据和内容层的信息,前者指数据本身,后者指数据所包含的信息内容[17]。这些定义虽然基于不同的学科背景,但是可以认为信息相较于数据更为宽泛,数据相较于信息则更为客观化、标准化。
1.2 数据要素的特征
数据如果进入到了生产活动中,那么数据便成为了一种生产要素。在过去经济发展过程中,数据之所以没有被单独作为一类生产要素强调,主要是因为数据往往和信息通信技术(information and communications technology,ICT)紧密结合在一起。ICT 的投资可以促进相关产业和整个经济的发展[18-19],而数据一直在这个过程中发挥着作用[20],因此将数据单独归为一种生产要素体现出对数字经济生产活动一种更加深刻和精细的认识。Jones and Tonetti 在对信息分类的基础上指出创意是生产函数,而数据则是生产要素,作为生产要素的数据本身不产生经济物品,却能够在经济物品的生产过程中发挥作用[3]。互联网平台企业收集到用户的个人数据后,这些个人数据本身不是一类产品,但是这些数据可以通过人工智能、大数据等算法被用于预测[4],从而帮助平台企业更好地开展生产活动,比如广告服务产品、短视频推送产品、个人信用评级产品等的开发。数据的聚集可以帮助整个系统提升效率[21],因此如果互联网平台企业收集汇总大量用户的个人数据后将其用于经济的生产活动,那么这些个人数据就是数据生产要素。
数据要素或数据资产的特征在一些文献中已经得到了较为完整的阐述[3,22-24],而数据要素的这些特征不仅让其区别于其他传统生产要素,也为数据确权的复杂性埋下伏笔。总结而言,数据要素主要包括如下几个特征:(1)虚拟性,即数据必须依附于其他生产要素才能发挥,比如数据要素与信息技术的结合[25],与劳动力的结合[3]等。而这也导致了数据在不同主体的手中可能拥有不同的价值[26]。(2)规模报酬递增,即数据规模的增加或种类丰富度的提升可以让数据要素的规模报酬不断提升[3,22]。具体而言,平台企业能从数据中获得的价值取决于数据的质量、规模、范围和独特性等四大维度,因此数据聚集在一起才能产生更强的规模报酬[27]。但显然,数据的聚集也会在一定程度上导致平台企业市场势力过大[28],甚至形成垄断。(3)非竞争性,即数据在被分享和复制后,使用数据的效用并不会因为使用者的增加而大幅度下降[3,4,29]。非竞争性意味着数据的分享可能会削弱数据收集者的竞争力,因此很多花费大量成本收集到独特数据的企业并不愿意分享其所拥有的数据[30],进而加剧数据垄断。(4)负外部性,即数据在形成生产力的同时也可能存在隐私泄露的风险[29,31-32]。因此,数据要素在生产过程中需要去标识化、脱敏,需要隐私计算、区块链等数字技术的支撑。此外,负外部性也包括了数据的大量汇集对国家安全造成的潜在隐患。
1.3 数据的确权
数据要素在数字经济的生产活动中扮演关键角色,数据确权首先需要基于上述特征。相比公共数据而言,本文主要探究的个人数据甚至需要考虑更多的属性。当前互联网平台所收集的数据主要为个人数据,个人数据(personal data)不等同于个人信息(personal information),但是个人数据能够体现个人信息,两者存在被混淆使用的情况[33]。个人数据体现的个人信息可以被认为是一类人格权的客体,而客观存在的个人数据又可以被认为是一种财产权的客体,个人数据兼具人格权和财产权的属性让个人数据的确权变得更加复杂[8]。
个人数据这种兼具人格权和财产权的特征会极大地增大数据要素市场的交易成本,这主要可以体现在以下三个方面:第一,数据要素定价需要同时考虑人格权和财产权。《民法典》规定人格权不得转让,但是可以许可他人使用,因此获得个人用户的许可或授权是互联网企业收集个人数据的前提。于是,数据要素市场中数据要素的价格既需要反映个人数据财产权相关权益的转让价格,也需要考虑其中包含的个人信息人格权的许可价格。第二,数据具备人格权会致使数据要素呈现更强的禀赋效应[34]。禀赋效应是指用户对个人数据的估值会比互联网平台企业更高,且这种估值具有异质性。这就导致,就算数据权属明晰,互联网平台企业也可能需要和每一类用户进行谈判,以不同的价格获取数据要素。第三,数据要素的规模报酬递增、非竞争性等特征[16,22]容易导致数据垄断。用户手中单一、少量的数据可能并不具备很高的价值,但是互联网平台企业收集起来的大规模数据却能产生很高的价值。这种情况下,互联网平台企业一方面可以通过低价甚至是免费的方式收集到用户的数据,另一方面又不愿意将收集到的数据进行分享。久而久之便会造成数据垄断,阻碍数据要素进一步的流通[24]。通过科斯定理可知,在数据要素市场交易成本很高的情况下,数据确权不恰当会影响数据要素的资源配置并损害社会福利[15]。鉴于数据确权所面临的问题以及数据权属不清所会导致的后果,目前学者主要从两个方面探讨数据及其所衍生出的各类权利的确权问题:
第一,偏重财产权,设计二元权利结构。经济学研究认为当数据生成市场更重要时,用户应该拥有数据;当数据使用市场更重要时,企业应该拥有数据[5]。法学研究则不仅考虑了数据所有权,还指出了用益权问题,并尝试提出数据所有权与用益权的二元权利结构的确权方案,认为数据原发者拥有数据所有权,数据处理者拥有数据用益权[8]。这一做法在理论上是可行的,但是在实际操作过程中不可避免地需要数据处理者或者数据生产者与用户进行谈判,以解决获取用户多少数据、给予用户多少份额的数据收益等问题。
第二,不区分人格权和财产权,提出新的确权体系。数据所有权的提法更适用于竞争性物品,而数据接入权(data access)的提法则更适用于数据这一类非竞争性物品[35]。因为用户将个人数据出售给互联网平台企业的交易方式在实践中并不多见,更多的则是平台企业向用户请求数据使用的许可。但是,这样的做法往往无法规避互联网平台企业过度收集数据的问题,很多情况下平台企业会向用户请求远超其提供的数字服务所需的数据许可。此外,还有一类观点是将数据市场看成是一种共享经济市场[36],并把数据看成一类拟公共物品。鉴于共享经济是一类接入经济(access economy)[37-38],那么对数据的使用自然也可以被认为是一种接入权的获取。但是这种做法的前提是数据为市场所共有,这一假设本身就存在很大的可行性问题。
总结而言,目前对数据确权的研究,思路仍然是基于数据的基本属性,探讨数据衍生出来的各类权利如何在用户和数字平台之间进行合理地划分。本文认为,沿着这一研究思路可能并不能提出一个合理、统一的数据确权标准,反而需要针对不同的应用场景进行不同的确权探讨,并不利于降低数据要素市场的交易成本。因此,本文提出了通过数据分级授权机制来解决数据确权问题的新思路。具体而言,针对用户在平台上所产生的各类数据,由用户和数字平台以市场化的方式达成不同层级的数据授权协议,以便让平台基于这一协议不同程度地使用数据要素开展数字经济的相关生产活动。这一数据分级授权协议的好处一方面在于,数字平台无需考虑平台上数据衍生出的各类复杂权利及相关权属问题,可以直接通过市场化的授权协议,合理、合法地使用数据要素;另一方面在于,可以在源头上解决数据确权问题,打通整个数据要素市场,为后续数据要素的进一步流通和交易打下基础,进而降低数据要素交易成本,提升数据要素市场的效率。
2 数据要素市场对分级授权的自然选择
通过对已有研究的综述总结,本文接下来将构建经济学模型,探讨数据分级授权对数据要素市场的福利影响。首先,需要对模型中的授权进行说明:用户在数字平台上所产生的一系列数据及其所衍生出来的各项权利,是由用户和数字平台所共同拥有。而传统确权方法的局限在于无法合理、清晰地区分用户和数字平台各自在多大程度上拥有这些权利。本文模型中的授权过程是,用户和数字平台对其共同拥有的数据达成一个授权协议,授权的对象为数字平台,授权的目的则是让数字平台可以使用授权后收集到的数据要素开展数字经济的生产活动。
事实上,在《中华人民共和国个人信息保护法》(以下简称个保法,于2021 年11 月1 日起正式施行)实施前,绝大部分互联网平台企业在收集用户个人数据过程中并没有分级授权的理念。很多App 在用户第一次下载注册后都会提供一份服务协议,这份协议一般包含App 会收集用户的哪些数据以及App 会如何去使用这些数据的相关条款。如果用户没有勾选该协议同意选项,那么可能无法使用该App。由于服务协议往往篇幅很长,很多用户都不会进行认真研读,而是在未充分知情的情况下就直接勾选同意选项。在很多情况下,用户甚至无法知道到底有多少数据被平台企业收集,也无法知道平台企业到底将这些数据进行了何种程度的加工和使用。而在个保法实施以后,一些平台企业开始对数据要素的分级授权进行探索。比如,微信更新iOS 8.0.17 和Android 8.0.18 版本后,在设置-隐私界面中增加了个人信息收集清单的条目,用户可以查看诸如用户基本信息、用户使用过程信息(包括位置、图片和视频)、社交与内容信息、联系人信息等的使用场景及其次数;用户也可以在设置-隐私-系统权限管理界面对允许微信收集的个人数据进行调整,比如点击设置-隐私-系统权限管理-位置-聊天后,可以选择是否允许微信在聊天时使用用户的位置信息。本文在第二部分,先探讨政府没有出台分级授权要求时,平台企业的最优选择;在第三部分,再探讨分级授权要求出台后,平台企业的最优选择。
基于上述对数据分级授权的实践探索,本文对数据要素市场的产业经济环境设定如下:沿用Dosis and Sand-Zantman的研究[5],假定数据要素市场中仅存在一家垄断的互联网平台企业。尽管用户和平台企业共同拥有用户在平台上所产生的所有数据,但是用户可以通过授权协议将数据授权给平台企业,以享受该平台企业所提供的数字服务。在授权协议的保护下,平台企业可以将数据要素投入到生产过程中,并取得相应的经济收益。
2.1 政府不要求分级授权,平台企业选择不分级授权
先考虑政府不要求分级授权,即没有出台对数据要素市场相关监管文件的情况。此时,平台企业可以选择分级授权,也可以不选择分级授权。本文先求解平台企业选择不分级授权的结果。
2.1.1 用户效用
假定每一个用户在平台上所产生的数据总量为D >0。由于用户在网络上的各类操作又会随着时间的推移产生大量的行为点击数据(click-stream data),即每一个用户每时每刻都在互联网平台上产生各类可供收集的数据,因此数据总量是连续的。用户需要进行是否将平台上产生的数据授权给平台企业的决策。数据要素存在很强的负外部性[29,32,39],这些负外部性对不同用户带来的负面影响并不一致。有些用户特别看重自身的隐私,因此隐私泄露风险会对其造成很强的负效用;另一些用户则相对不那么看重自身的隐私,相应地,隐私泄露风险对其造成的负效应也就相对较弱。假定用户i对数据负外部性的担忧程度θi服从一个从0 到1 的均匀分布,即θi~U(0,1),数据的负外部性对用户造成的负效用则为ei=这一函数形式意味着数据负外部性对大部分用户影响较小,对少数用户的影响非常大。这一假设与现实较为相符,因为大部分用户还是在没有仔细研读服务协议的情况下就勾选同意选项进入了App 使用界面。
同时,由于数据要素市场未分级授权,用户只有两种选择:要么选择将自己在平台上产生的数据D全部授权给平台企业,要么选择不授权。平台企业在获得用户的授权许可后,会给同意授权数据的用户提供一个质量为v的数字接入服务,对于拒绝授权数据的用户则不提供数字接入服务。显然,如果用户接受了平台企业的数字接入服务,那么大量接入的用户同时也会受到网络效应的影响[40,41]。因此,参考Schaefer and Sapi[42],本文认为数据授权后,用户从平台中所获得的效用一方面来自平台上的网络效应,另一方面也受到接入质量v的影响。如果平台的网络效应强度为α∈(0,1),平台上的用户数量为n,数字服务的接入质量为v,那么用户能在平台上获得的正效用则为αnv。这里,可以通过当前App 中比较流行的会员制度对于接入质量v进行理解:比如QQ 音乐中,非会员只能收听部分免费曲目;而绿钻会员则可以额外收听会员专属曲目。显然,绿钻会员在QQ 音乐平台上享受了更高的接入质量,他们可以在所有的曲目下同所有的用户进行评论互动、音乐分享以产生比非会员用户更强的网络效应。因此,在考虑了正效用和数据负外部性所导致的负效用后,我们认为用户i最终的效用函数如下:

如图1,参考霍特林模型[43]的设定,由于θi~U(0,1),可以认为所有的用户均匀分布在一条0~1 的线段之上。最后一位愿意授权数据的用户,其选择授权与不授权所带来的效用是一致的。同时,最后一位愿意授权数据的用户也决定了市场上愿意授权数据的用户数量,即最后一位愿意授权数据的用户对数据负外部性的担忧程度就是市场上愿意授权数据的用户数量。

图1 用户对数据授权的选择(未分级授权)Figure 1 User decision on data license (non-hierarchical)
因此,我们可以有:

基于(2)式,可以得到数据要素市场愿意授权数据的用户数量为n=。这里,我们假定最担忧数据负外部性的用户对其数据负外部性的担忧程度始终是大于平台企业的数字接入服务质量v的,即-emin=D >αv。这一假定的逻辑在于,总有用户会出于对自身数据安全性的考虑不去长期地使用某一个App。现实情况下,用户对App 账号注销的需求可以支撑这一假定。而从模型上来看,这一假设保证了n=(0,1)。综上,可以得到(1)式等同于:

2.1.2 平台利润
平台企业在收集到用户授权的数据后,使用数据生产要素进行生产,并为接入平台的用户提供数字服务。参考Jones and Tonetti[3],考虑了数据生产要素的生产函数可以记为如下形式:
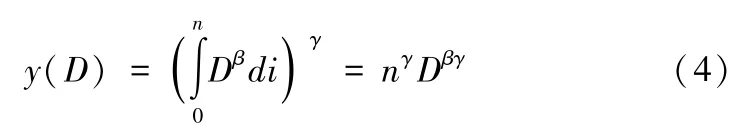
其中,γ∈(0,1),βγ >1,这保证了整个生产函数相对于数据要素D是规模报酬递增的。数据要素的虚拟性要求数据要素需要结合其他生产要素才能进行生产活动。因此需要指出的是,我们假定了其他生产要素的投入均为1 个单位,所以在(4)式中不再具体表述其他生产要素。之后,我们假定平台企业为每个用户提供接入服务的成本为φ,那么平台企业的利润则为nγDβγ -φn。在平台企业只有一个用户的数据时,其利润为Dβγ -φ。基于此,我们定义单位数据生产成本为c=表示了单独一份数据进行生产时的每单位产出成本。于是,可以得到平台企业的利润函数如下:

平台需要确定最优的接入服务质量v来最大化自身的利润,将n=代入(5) 式,平台企业的最优化问题即为:

基于(6)式,求解平台企业利润最大化问题的一阶条件(first-order condition)为:


由于前文已经假定D >αv,因此根据(8) 式可知,必有c>γ。当然,c还需保证平台企业具备持续经营的能力。因此根据(5) 式,有c <1。于是,c∈(γ,1)。因此,根据(9) 式知,n*∈(0,1)。
2.2 政府不要求分级授权,平台企业选择分级授权
接下来,求解政府不要求分级授权,平台选择分级授权的情况。
2.2.1 用户效用
若数据要素市场分级授权,我们假定提供完整接入服务所需的数据为D,提供的完整接入服务质量仍然为v;而平台企业提供基础接入服务所需的数据为kD,其中k∈(0,1) 说明基础接入服务只需要用户在平台上产生的部分数据,而基础接入服务的质量则为u <v。于是,用户i最终的效用函数可以在(1) 式的基础上调整为如下:

此时,所有的用户可以被划分成三大类。我们假定有n1的用户愿意授权全部数据,有n2-n1的用户愿意授权部分数据,剩下1-n2的用户拒绝授权任何数据。根据前文的逻辑,如图2 所示,最后一位愿意授权全部数据的用户,其选择授权全部数据与授权部分数据所带来的效用是一致的;最后一位愿意授权部分数据的用户,其选择授权部分数据和选择不授权数据所带来的效用也是一致的。

图2 用户对数据授权的选择(分级授权)Figure 2 User decision on data license (hierarchical)
因此,我们有:

2.2.2 平台利润
类似于上文,平台企业在收集到用户授权的数据后,使用数据要素进行生产活动。但是在数据要素市场分级授权后,平台企业收集到的数据共有两类。相应地,平台企业提供的数字服务也会分为两类。首先,来看平台企业的生产函数:

本文基于对腾讯公司的调研访谈,构建(14)式。腾讯的数据处理模型是根据数据包含的字段数所构建的,不同授权程度的数据会进入到不同的数据处理模型之中。(14)式中:第一项表示全部授权的数据,进入字段齐全的数据处理模型,积分范围为(0,n1);第二项表示部分授权和全部授权的数据,均包含部分字段,这些数据进入字段不齐全的数据处理模型,积分范围为(0,n2);第三项表示单独采用全部授权数据的部分字段所得到的价值已经囊括在第一项之中,需要剔除重复计算的部分,积分范围为(0,n1)。当然,通过软件计算,采用所得出来的结论也是一致的,只是无法获得一个显示解。为了模型求解的方便,本文最终采用(14) 式的形式。
然后,我们假定平台企业为授权全部数据的用户提供质量为v的完整接入服务所需承担的单位数据成本仍为c,为授权部分数据的用户提供质量为u的基础接入服务的单位数据成本则会降低。在分级授权后我们假定为了提供基础接入服务而对数据进行存储、计算成本会从c减少为kβc。采用这一形式同样是基于腾讯公司的调研访谈,数据进入生产的过程可以理解为2 个步骤。第一步,单一的数据经过平台公司的收集后,可以通过运算、加工获得更多的数据,比如可以获得一些加总后的数据。第二步,原始数据与运算后的数据一起进入算法,实现数据的生产。结合(14)式,第一步对应于平台企业从每个用户中获取到的,经运算、加工后最终可用于生产活动的数据,如果全部授权,为Dβ;部分授权,则为kβDβ。第二步则是以f(data)=dataγ的形式实现数据的生产。鉴于数据存储、计算成本是对应于经运算、加工后最终可用于生产活动的数据,而部分授权后,可用于生产活动的数据从Dβ减少为kβDβ,因此单位数据成本也从c减少为kβc。
我们假定平台企业需要拿出t比例的净利润用于新算法的开发和维护,可以得到平台企业的利润函数如下:


2.3 数据要素市场的自然选择
在政府没有出台相关政策的情况下,垄断的平台企业具备市场势力,其会根据自身的利润来决定是否选择数据的分级授权。
将(9)式代入(5)式,便可以得到平台企业不选择分级授权后所得到的利润:

而将(21)式、(23)式代入(15)式,则可以得到平台企业选择分级授权后所得到的利润:
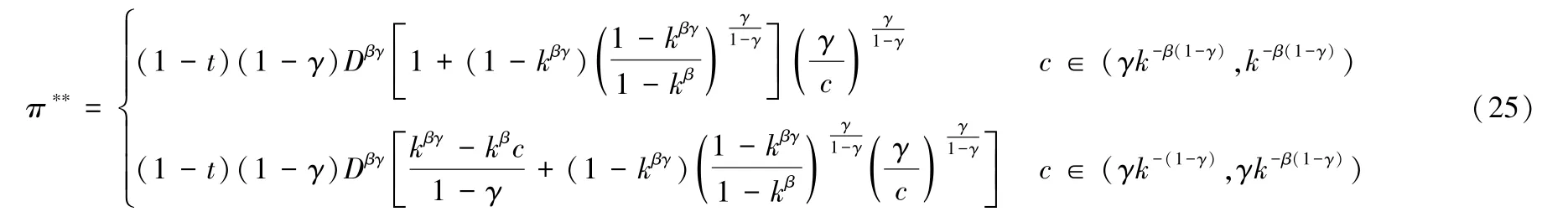

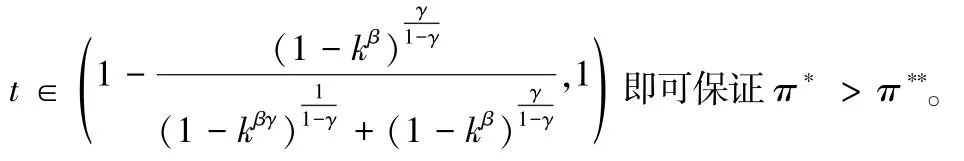
在现实情况下,平台企业进行算法的切换和App 的整改具备较大成本,因此往往选择不分级授权。根据定理1,本文得到如下推论:
推论1由于数据分级授权给平台公司带来的技术成本较大,平台企业在没有政府监管政策约束的情况下,会选择不分级授权。
后续的讨论将基于

3 数据要素市场的分级授权机制设计
接下来,考虑政府要求分级授权,出台数据要素市场相关监管文件后的情况。为了防止平台企业过度收集用户的数据,政府会进行数据要素市场的分级授权机制设计,若平台企业遵循政府的数据分级授权要求,则可以合法经营;若平台企业违背政府的数据分级授权要求,就会受到政府的监管惩罚。尽管此时政府要求进行分级授权,但是政府并不能强制要求平台企业遵循分级授权的要求,需要通过一个合理的数据要素市场分级授权机制的设计,引导平台企业基于市场原则遵循分级授权的要求。一个合理的机制便是通过对罚款的设计,让平台企业遵循分级授权所得到的收益会高于违背分级授权的。
3.1 政府要求分级授权,平台企业违背分级授权
本文首先来看政府监管文件出台后,如果平台企业违背分级授权的情况。
3.1.1 用户效用
政府要求分级授权,但是平台企业违背分级授权,此时用户面对的情况与2.1 中一致,最终的效用函数仍为(3)式。
3.1.2 平台利润
对于平台企业而言,此时若违背分级授权,其将面临政府监管的惩罚。本文引入政府监管力度g >0。可以理解为,平台企业在违背政府对数据要素市场的分级授权要求后,就会受到比例为g的惩罚。于是,平台企业的利润函数被调整为如下:

沿用2.1 中的求解模式,可以求得此时数据要素市场中,愿意对数据进行授权的用户数仍然为(9)式的n*。
3.2 政府要求分级授权,平台企业遵循分级授权
接下来,探讨平台企业遵循分级授权的情况。
3.2.1 用户效用
政府要求分级授权,但是平台企业遵循分级授权,此时用户面对的情况与2.2 中一致,最终的效用函数仍为(13)式。
3.2.2 平台利润
同样,平台企业若遵循分级授权,就不需要受到政府的惩罚,此时最终的利润函数也同2.3 中一致。
3.3 有效的分级授权机制设计
一个有效的分级授权机制设计可以保证平台企业在市场规律的驱动下,自发地去选择数据要素分级授权。而鉴于平台企业利润最大化的本质追求,只有当数据要素市场分级授权的利润高于数据要素市场未分级授权的利润时,平台企业才会遵循政府的要求。
因此,需要进一步计算在政府要求数据要素市场分级授权时的企业利润。将(9)式代入(30)式,便可以得到平台企业违背分级授权后所得到的利润:

而平台企业遵循分级授权后所得利润仍为(25)式。



基于定理2,我们可以得到如下推论2:
推论2政府有必要进行数据要素市场的分级授权机制设计,以保证平台企业基于市场原则自发地遵循数据要素市场的分级授权要求。
本文第四、第五部分的分析将基于一个有效的数据要素市场分级授权机制展开。
4 数据要素市场分级授权的福利分析
促进数据要素市场发展,既要注重提升数据要素的使用效率,也要兼顾整个数据要素市场的福利。因此接下来,本文将对未分级授权与分级授权的数据要素市场进行进一步的比较,探究数据要素市场的分级授权对数据要素市场的影响。
4.1 数据授权量分析
首先,对整个数据要素市场中进入生产活动的数据要素授权量进行分析。可以从两个维度对数据要素授权量进行度量:愿意授权数据的人数和平台企业得到的数据要素总量。
根据上文求解,在政府出台监管之前,平台企业会选择不分级授权,从(9)式可以得到未分级授权下,平台企业获得的数据总量:

在政府制定有效的数据要素市场分级授权机制后,平台企业遵循数据分级授权,(21)式和(23)式分别表示数据要素市场分级授权时愿意授权全部数据的用户量和数据要素市场分级授权时愿意授权数据(部分与全部之和) 的用户量,进而可以求得此时平台企业获得的数据总量:
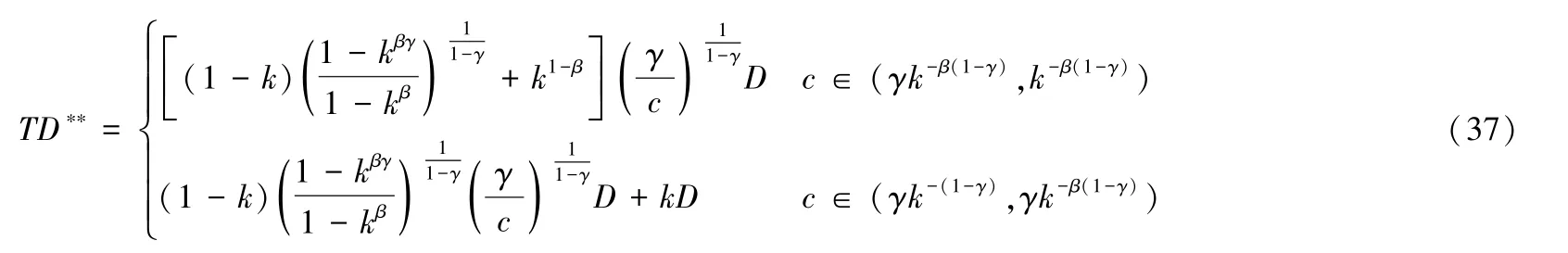
则基于上述模型的求解结果,我们可以得到:
定理3在k,γ∈(0,1),β,βγ >1,c∈(γk-(1-γ),


基于定理3,在考虑了现实的数据要素市场后,我们最终得出如下的推论3:
推论3在有效的数据要素市场分级授权机制下,企业自发地落实数据分级授权,愿意授权全部数据的用户数下降,但是愿意授权数据(部分+全部)的用户数上升,平台企业获得的数据要素总量也上升。平台企业在搜集数据的过程中既履行了最小必要原则,也提升了数字服务的普惠性。
4.2 用户福利分析
前文已经说明,在有效的分级授权制度下,平台企业选择遵循分级授权时,其利润会低于分级授权要求出台前的利润,即π**<π*。接下来,本文进一步针对数据要素市场中的用户福利展开分析。
在不分级授权的情况下,基于(3)式、(8)式和(9)式,可以得到用户福利如下:

然后,在分级授权的情况下,根据(13)式,我们可以得到此时的用户福利如下:

将(21)式、(23)式代入后,可以直接求得用户福利:
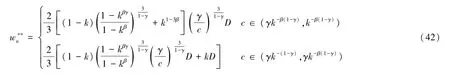
通过计算分析,可以得出如下关系:
定理4在k,γ∈(0,1),β,βγ >1,c∈(γk-(1-γ),

证明:
首先,分析平台企业利润。
其次,分析用户福利。先分析c∈(γk-β(1-γ),k-β(1-γ))的情况。
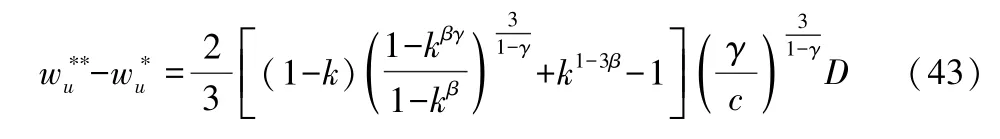

再分析c∈(γk-(1-γ),γk-β(1-γ)) 的情况。

基于定理4,我们同样可以得到数据要素市场分级授权后有关用户福利的推论:
推论4在有效的数据要素市场分级授权机制下,企业自发地遵循数据分级授权,用户福利得到提升,数据分级授权更有利于整个数据要素市场的健康发展。
最后,表1 总结了政府构建数据要素市场分级授权机制前后的福利对比。
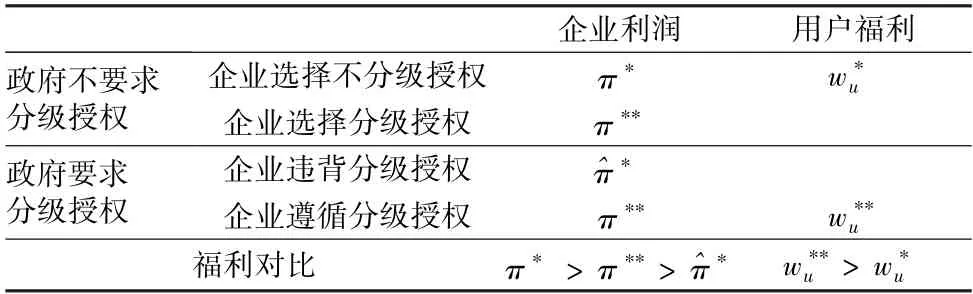
表1 分级授权和不分级授权的福利对比Table 1 A comparison of welfare between hierarchical and non-hierarchical scenarios
5 影响数据要素市场分级授权效果的因素分析
5.1 数据要素的规模报酬水平
由于数据要素有着规模报酬递增的属性,而规模报酬的大小在一定程度上可以反映出平台企业处理数据的数字技术水平,因此有必要针对规模报酬的大小展开进一步的分析。从上文的求解中可知,生产函数中有关数据要素的规模报酬与β和γ有关,规模报酬递增的条件为βγ >1。我们认为数据要素规模报酬递增的原因在于原本分散的数据要素被平台企业收集后所形成的规模化的数据库可以通过各类计算技术让价值得以提升。由于我们假定γ∈(0,1),数据要素规模报酬递增的关键在于β。因此,β的取值可以衡量平台企业的数字技术水平。基于此,我们分析β的变化对数据要素授权量和社会福利的影响,具体变量的取值为:D=1.5,φ=1.9,k=0.5,γ=0.7,β∈(1.5,2.5)。
我们首先来看β对愿意授权的用户数和数据授权总量的影响,数值模拟的结果如图3 和4 所示。图3 说明随着数据要素的规模报酬递增水平逐渐增强,愿意授权数据的用户数会上升。而相比于数据要素市场未分级授权的情况,数据要素市场分级授权下愿意授权数据的用户数上升的速度更快。图4 说明随着数据要素的规模报酬递增水平逐渐增强,平台企业获得的数据总量会增加。而相比于数据要素市场未分级授权的情况,数据要素市场分级授权下平台企业获得的数据总量上升速度同样更快。本文认为,由于数据要素规模报酬递增水平的增强,平台企业可以提升数字服务的质量,从而可以吸引更多用户授权自己的数据来接入到数字服务中,进而提升获得的数据总量。当然,随着数据要素的规模报酬递增水平的进一步加强,最终有可能出现全部用户均愿意授权全部或者部分数据的情况。基于这一数值模拟结果,本文提出如下推论:

图3 β 对愿意授权用户数的影响Figure 3 The effect of β on the number of users willing to license data

图4 β 对授权的数据总量的影响Figure 4 The effect of β on the total amount of data licensed
推论5在有效的数据要素市场分级授权机制落实后,平台企业遵循分级授权,此时数据要素规模报酬水平的增强对愿意授权数据的用户数、平台企业获得的数据总量的提升作用均更强。因此,有效的分级授权机制可以让数字技术的提升更好地惠及用户。
我们再来看β对用户福利的影响,数值模拟的结果如图5-8 所示。图5 和图6 分别展示了在数据要素规模报酬递增水平逐渐增强的情况下,数据要素市场未分级授权和分级授权时企业长期利润和用户福利的变化趋势。可以发现,无论数据要素市场是否分级,长期来看,规模报酬递增水平的增强均会提升企业利润和用户福利,而相对而言,用户福利在数据要素市场分级授权后提升得更快。图7 和图8 更清晰地展示了长期情况下,企业利润与用户福利的分配。可以发现,数据要素市场分级后,同等数据要素规模报酬水平下,用户福利所占的份额更大。此外,一旦平台企业占据了整个市场后,再增强规模报酬递增水平,用户福利所占的份额反而会下降。这是因为此时所有用户已经根据自己的偏好将数据部分或全部地授权给了平台企业,规模报酬递增水平的提升将主要作用于平台企业的生产力之上,用户福利份额的下降是因为企业利润的快速提升。总结后,可以得出如下推论:

图5 β 对用户福利的影响Figure 5 The effect of β on the user welfare

图6 β 对社会福利的影响Figure 6 The effect of β on the social welfare

图7 β 对社会福利分配的影响-未分级Figure 7 The effect of β on the welfare allocation (Non-hierarchical)
推论6在有效的数据要素市场分级授权机制落实后,平台企业遵循分级授权,此时社会福利、用户福利及用户福利份额更大,且数据要素规模报酬水平的增强对用户福利及用户福利份额的提升作用也更大。因此,有效的分级授权机制可以让数字技术的提升更好地促进数据要素市场的“共同富裕”。
5.2 数据的分级授权标准
最后,我们来分析数据分级授权标准的问题。模型中的分级标准是k,即平台企业提供基础接入服务时向用户收集的数据比例。我们希望平台企业能够遵守最小必要原则,在提供基础接入服务时只收集这些接入服务所涉及的数据,而不去过度收集额外的数据。分级标准k在我们的模型中起到关键作用,不仅仅体现在基础接入服务的数据收集比例,也会通过对效用函数、生产函数的影响,最终反应在数据要素授权量和用户福利之中。同时,分级标准k也可以为平台企业确定基础接入服务的质量提供参考依据。平台企业可以制定较大的分级标准k,从而提供质量相对较高的基础接入服务;也可以制定较小的分级标准k,仅提供质量相对较低的基础接入服务。具体变量的取值为:β=2.0,D=1.5,c=1.8,γ=0.7,k∈(0.1,0.9)。
我们首先来看k对愿意授权的用户数和数据授权总量的影响,数值模拟的结果如图9、10 所示。图9 和10 说明在数据要素市场分级授权的情况下,在平台企业全部占据数据要素市场之前,降低分级标准k既能扩大愿意授权数据(部分与全部之和)的用户数,同时也能增加收集到的数据总量;但是在全部占据数据要素市场之后,如果继续降低分级标准k,愿意授权数据(部分与全部之和)的用户数并不会改变,反而会降低收到的数据总量。这是因为在占据数据要素市场之后,再降低分级标准k,会让原先愿意授权全部数据的用户转化为授权部分数据,从而导致授权数据总量的下降。基于上述分析,可以得到如下推论7:
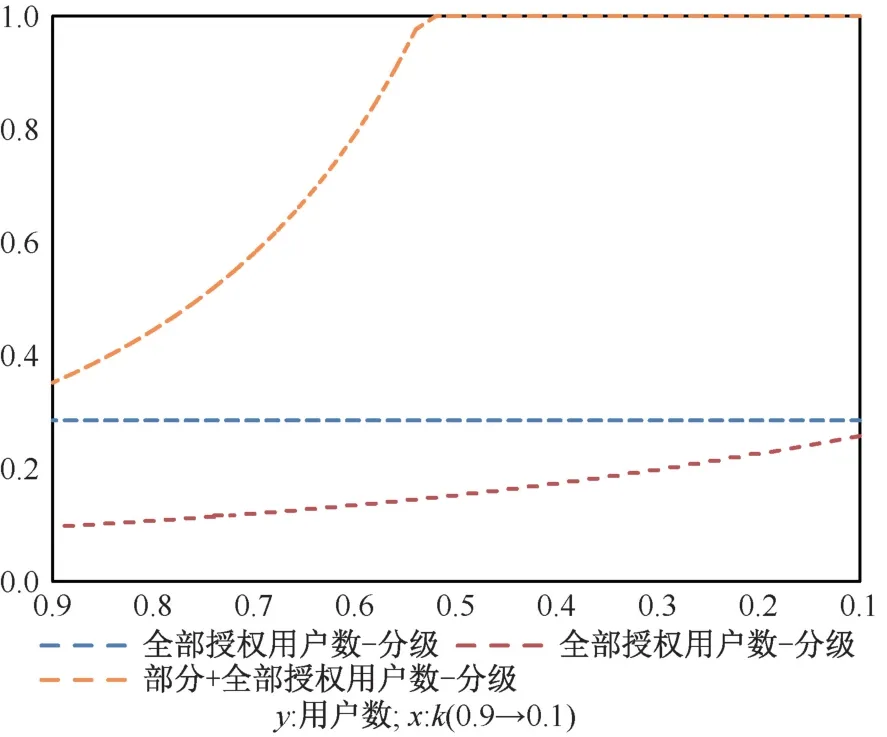
图9 k 对愿意授权用户数的影响Figure 9 The effect of k on the number of users willing to license data
推论7有效的数据要素市场分级授权机制落实后,平台企业遵循分级授权,当平台企业提供基础接入服务的数据要素授权标准正好可以帮助平台企业占据全部市场份额时,平台企业获得的数据要素总量也最多。因此,一个合理的数据要素授权标准有助于平台企业更加合规、合理地采集更多的数据要素。
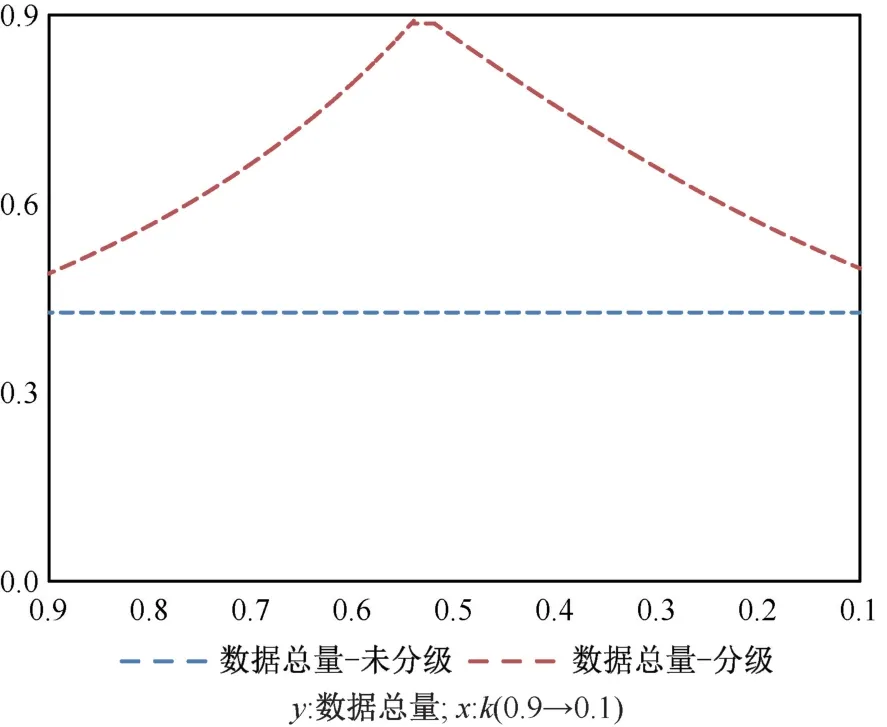
图10 k 对授权的数据总量的影响Figure 10 The effect of k on the total amount of data licensed
我们再来看k对社会福利的影响,数值模拟的结果如图11-14 所示。图11 和图12 分别展示了长期来看,在分级标准k逐渐下降的情况下,企业利润和用户福利的变化趋势。可以发现,在数据要素市场分级授权的情况下,企业利润和用户福利均大于未分级授权的情况。同时,可以发现企业利润和用户福利会随着分级标准k过度下降先上升后下降,让企业利润最大化的分级标准k要比让用户福利最大化的k要更大。本文的模型中,分级标准k是外生给定的,而现实情况下,平台企业对分级标准k有更大的选择权,因此若要让平台企业选择用户福利最大的分级标准仍然需要政府对数据分级授权相关机制进行进一步的设计。由于篇幅问题,本文针对这一问题不再展开进一步的讨论。从图13 和图14 可以发现在数据要素市场分级授权的情况下,用户获得的社会福利份额是要大于未分级授权情况下的。类似地,随着分级标准k逐渐下降,用户获得的社会福利份额同样是先上升后下降。基于上述分析,可以得到如下推论6:
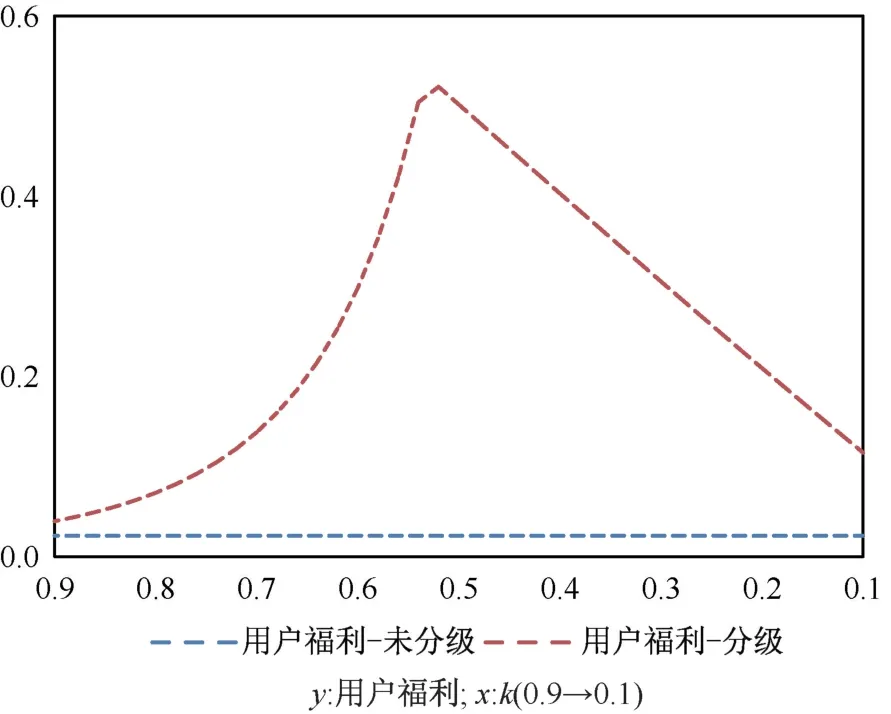
图11 k 对用户福利的影响Figure 11 The effect of k on the user welfare

图12 k 对社会福利的影响Figure 12 The effect of k on the social welfare

图13 k 对社会福利分配的影响-未分级Figure 13 The effect of k on the welfare allocation (non-hierarchical)
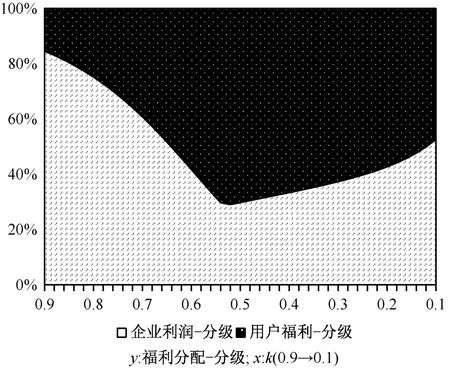
图14 k 对社会福利分配的影响-分级Figure 14 The effect of k on the welfare allocation (hierarchical)
推论8在有效的数据要素市场分级授权机制落实后,平台企业遵循分级授权,当平台企业提供基础接入服务的数据要素授权标准正好可以帮助平台企业占据全部市场份额时,用户福利及用户福利份额也最大。因此,一个合理的数据要素授权标准有助于促进数据要素市场的“共同富裕”。
最后,本文构建的探究数据要素市场分级授权机制的经济学模型虽然只考虑了分两级授权的情况,但是所得到的结论在一定程度上可以推广到更多级的分级授权情形。而在实际操作中,数据要素市场分级授权体系的构建也需要结合平台企业的实践操作,在权衡数据要素生产效率和用户权利保障的基础上进行更多级、更精细的分级授权设计,从而最终在长期形成一个低交易成本的数据要素市场。
6 结论
本文首次论证了数据要素市场分级授权的机制设计及福利分析。以往对数据要素的研究更多集中在数据作为一种生产要素对经济增长所起到的作用,而对于数据的确权问题则一直没有定论。数据的确权是数据要素市场进一步发展的基础。鉴于数据在不同应用场景下所衍生出来的权利存在差异性,因此很难用一个统一的标准对数据衍生出来的所有权利进行清晰的权属界定。本文提出通过数据分级授权机制来解决数据确权问题,让用户和平台企业以市场原则为基础,达成不同级别的数据授权协议。数据分级授权能够让平台企业无需考虑平台上数据衍生出的各类复杂权利及相关权属问题,从而直接通过市场化的授权协议,合理、合法地使用数据要素,进而降低数据要素市场的交易成本。
基于这一逻辑,本文首次构建有关数据要素市场分级授权的经济学模型,探讨数据要素市场分级授权机制对整个数据要素市场带来的影响。本文发现,政府需要构建有效的数据要素市场分级授权机制,以使平台企业能自发地基于市场原则选择遵循数据分级授权的要求。在数据要素市场分级授权后,愿意授权全部数据的用户会下降,但是愿意授权数据(部分+全部)的用户数会上升,平台企业获得的数据要素总量也会上升。平台企业在采集数据的过程中既履行了最小必要原则,也提升了数字服务的普惠性。同时,在数据要素市场分级授权后,用户福利和社会福利均会得到提升,说明分级更有利于整个数据要素市场的健康发展。基于这一基本结论,本文进一步从数据要素规模报酬和分级授权标准两大维度展开分析。首先,本文发现,在数据要素市场分级授权下,数据要素规模报酬水平的增强对愿意授权数据的用户数、平台企业获得的数据总量的提升作用均更强;同时,对用户福利的提升和对用户福利份额的提升作用也均更强。其次,在数据要素市场分级授权下,当平台企业提供基础接入服务的数据要素授权标准正好可以帮助平台企业占据全部市场份额时,平台企业获得的数据要素总量也最多,用户福利及用户福利份额也最大。由此可见,一个可行且合理的数据要素分级授权机制设计,可以更好地促进数据要素市场的发展。
本文研究具有重要的启示:(1)本文的研究脱离先前的基于数据所衍生的各类权利进行确权的逻辑[8,35],提出数据要素市场的分级授权机制,从而更合理地解决数据的确权问题,在学术方面具有创新性,在实践方面具有可行性。(2)本文的结论说明了构建数据要素市场分级授权机制的重要性,为当前中央及地方政府出台相关数据条例提供了支撑。比如,深圳市通过的《深圳经济特区数据条例》中就提出App要允许用户在不提供数据的情况下使用基础服务,这和本文模型所论证的最小必要原则和基础接入服务有一定的相通之处。(3)本文的研究说明在长期,数据要素市场的分级授权机制同样是有利于平台企业的,可以通过“数据采集歧视”在尊重用户的情况下根据不同用户的偏好尽可能多地采集不同用户的数据;也可以帮助平台企业以更加合理、合法的方式采集到更多的数据,并在后续使用这些数据的过程中不必担心法律上的权属问题,从而让平台企业更加放心地去利用这些数据进行生产和创新活动。(4)本文的结论表明数据要素市场的分级授权机制可以提升用户的福利和福利份额。一个有效的数据要素市场分级授权机制,既可以让用户自主控制其在平台上产生的数据,也可以让数字服务惠及更多的用户,提升原本处于弱势一方的用户在数据要素市场中的福利份额,实现数据要素市场福利分配上的“共同富裕”。
猜你喜欢
旅游世界(2021年5期)2021-11-07
当代水产(2020年4期)2020-06-16
现代园艺(2017年22期)2018-01-19
河北书画研究(2017年1期)2017-08-22
中国医疗保险(2017年6期)2017-07-18
中国卫生(2016年5期)2016-11-12
中国现当代社会文化访谈录(2016年0期)2016-09-26
山东青年(2016年2期)2016-02-28
中国卫生(2015年10期)2015-11-10
中国卫生(2015年6期)2015-11-08
