
融合Lite-HRNet的Yolo v5双模态自动驾驶小目标检测方法*
2022-11-17 05:47刘子龙沈祥飞
汽车工程 2022年10期
刘子龙,沈祥飞
(上海理工大学光电信息与计算机工程学院,上海 200093)
前言
随着近10年计算机软硬件的迅速发展,人工智能成为目前炙手可热的领域,其中作为人工智能领域领头羊的计算机视觉,是目前应用最广的领域。作为计算机视觉的基本分支之一,目标检测发挥着至关重要的作用,其主要任务是实现目标的定位和分类。目前我国大力发展新能源汽车,并且都配备自动驾驶系统和驾驶辅助系统。自动驾驶系统可以辅助驾驶员进行安全驾驶,以此提升道路安全。而在自动驾驶系统和驾驶辅助系统中,目标检测技术也显得尤为重要。
随着深度学习的发展,与传统方法相比,神经网络有着更强大的学习特征能力和信息表征能力,而且传统方法的模型复杂,难以取得重大突破。基于深度学习的目标检测方法逐渐成为主流,其主要分为两大类。第1类是两阶段目标检测算法,其中最为经典的就是Girshick等推出的RCNN(region convolutional neural net-works)算法[1],随后又连续推出了Fast RCNN[2]与Faster RCNN[3]算法。第2类是单阶段目标检测算法,代表作有SSD(single shot multibox detector)[4]、Yolo(you only look once)[5],Yolo
系列算法是Redmon等在2015年提出的一个目标检测算法,随后Redmon等又推出了Yolo v2[6]以及Yolo v3[7]。虽然两阶段算法在目标检测中有着不错的准确率,但由于检测速度的限制,使得该系列算法难以在工业应用中进行推广。而基于回归方法的端到端Yolo系列算法降低了网络复杂度,导致其检测精度有所降低,但却显著提高了检测速度。
Yolo v5作为目前最新的Yolo系列算法,其在检测速度和检测精度上有着显著的提升,但是在小目标以及密集目标中表现仍有不足。为了解决小目标检测中存在的问题,Zhang等[8]提出了Yolso(you only look small object)目标检测算法,该算法指出分类网络的特征提取器不能合理表达小目标的特征,原因在于目标的外观信息不足,且周围存在大量的背景干扰。为了解决这些问题,该学者构建了背景感知模块加强对背景的感知,但该算法与Yolo v3相比也并未取得较大的领先,所以难以达到实际使用要求。
基于上述主流目标检测算法的优缺点,并且考虑到现有算法只利用可见光图像进行检测,由于这种单一的图像输入模式,明亮场景与暗光场景对目标检测的效果会产生巨大的差异。在暗光场景下,传统相机传感器接收到的光线不足,使得目标与背景之间无法准确区分,严重影响了检测器的性能。因此本文针对小目标和密集人群检测效果不佳及暗光场景下目标背景间难以区分的问题对Yolo v5进行改进,首先对主干网络进行修改,利用Lite-HRNet[9]高分辨率特征网络增加高分辨率的特征层来提高对小目标和密集人群的检测精度。其次为了提高检测速度取消融合层中复杂的融合结构,并且对边界框损失函数进行改进以提高回归速度和精度。然后为了充分发挥可见光图像与红外图像的互补优势,在输入端使用动态加权融合的方式将可见光图像与红外光图像进行输入。最后利用小目标数据增强算法对数据集进行样本扩充,并且考虑到算法应用场景的特殊性,使用二分K-means算法来选取更为合适的锚框。实验结果表明该算法在检测速度基本不变的情况下,对密集目标和小目标的检测精度明显提升,满足实际应用需求。
1 Yolo v5简介
Yolo作为单阶段算法的代表作之一,Yolo v3是Redmon等所提出的最后一个算法,在其退出计算机视觉领域之后,有学者提出了Yolo v5算法,其主要由输入层、主干网络层、特征融合层和检测层组成,网络结构如图1所示。作为目前最新的Yolo系列算法,Yolo v5算法采用了CSPDarknet53作为主干网络,其中包含了两种CSP(cross stage partial)[10]结构,解决了主干网络中的梯度信息重复问题,将梯度的变化集成到特征图中,在保证检测精度和检测速度的同时减少了运算量。Yolo v5算法在较深的主干网络中使用了带有残差模块的CSP1_X结构,可以避免梯度消失导致网络退化的问题,而为了减少计算量将带有普通卷积的CSP2_X结构在特征融合层中使用。
Yolo v5网络在头部增加了图像切片(Focus)结构,将1张图片按照像素点分成4张,长宽缩小两倍,通道数增加至原来的4倍,提高了检测速度。Yolo v5在尾部还增加了空间金字塔池化(spatial pyramid pooling,SPP)结构,其主要作用是扩大感受野来解决特征图与锚框的对齐问题。Yolo v5的融合网络由特征金字塔网络(feature pyramid networks,FPN)和路径聚合网络(path aggregation networks,PAN)组成,FPN可以增强算法对不同尺度目标的检测性能。但是其单一自上而下的融合方式忽略了重用底层特征图中的信息,加入的PAN采用自下而上的融合结构,改善了底层信息的传播,丰富了整个特征信息层次。
在Yolo v3网络中,正样本匹配方式是最大交并比(intersection over union,IoU)[11]策略,并且一个真实框只能对应一个锚框,极易造成正负样本失衡,使得正样本锚框梯度下降,最终导致算法收敛速度过慢。而Yolo v5网络利用增加正样本锚框的方法来代替最大交并比的匹配策略,将靠近中心点的两个邻近网格同时作为该真实框的正样本锚框,利用该方法将正样本数量提升至3倍,大大提升了模型的收敛速度。
2 Yolo v5算法优化方法
2.1 边界框损失函数改进
Yolo v5中使用GIoU[12]来解决预测框A与真实框B不相交时,IoU损失为0的问题。公式如下:
式中:Ac表示预测框A与真实框B的最小外接矩形的面积;u表示框A与B相交的面积。
但在实际使用过程中还存在一些不足,Zheng等[13]经过研究发现网络会优先选择扩大预选框的面积而不是移动预选框来覆盖真实框。为解决这些问题,提出DIoU(distance-IoU)的思想,公式如下:
式中:ρ2(b,bgt)为A与B中心点之间的距离,gt表示真实框;c2为A与B最小外接矩形的对角线。
相比GIoU,DIoU直接限制了最小外接矩形的面积,这使得网络更倾向于移动预选框而不是扩大预选框。但是当两个框的中心点重合时,c2与ρ2(b,bgt)的值都不变,所以又在DIoU中加入了长宽比提出了CIoU(complete-IoU)[13]的思想,公式如下:式中:a为权重系数;v指的是预测框和实际框长宽比的差异,如果一致则v=0。
CIoU考虑到了边界框回归时的重叠面积、中心点距离和纵横比,但由于纵横比描述的是一个相对值,在计算时存在不确定性。因此本文采用Zhang等提出的EIoU(efficient-IoU)[14],公式如下:
式中cw和ch分别表示宽和高。
EIoU的损失分为3个部分,分别是重叠损失、中心距离损失和宽高损失。将纵横比的损失拆分成预测的宽高分别与最小外接框宽高的差值,不仅解决了宽高比的不确定性还加快了收敛速度。文献[15]中提出在损失函数IoU中引入超参数α,提出了一种新的alpha-IoU损失函数,公式如下:
在选择合适的α时可以改进检测器的性能,这种加权的方式不仅为实现不同边界框的回归精度提供了很大的灵活性,并且不会引入额外的参数。因此本文也在EIoU中引入超参数α,改进之后的损失函数公式为
2.2 可见光图像与红外图像特征融合
红外相机的工作原理是接收红外辐射,而红外辐射具有较强的穿透性,甚至可以克服部分障碍而探测到目标,具有较大的作用距离和较强的抗干扰性,所以对于因距离远而导致尺度小的目标具有较好的捕捉能力。在不同的场景下,可见光图像与红外图像也体现出了较大的差异,例如白天光照充足或者出现热量交叉的情况下可见光图像保留了更多的细节信息,但是在暗光场景下红外图像可以不受目标颜色和尺度变化的影响,甚至在完全漆黑、烟雾、恶劣天气和眩光等具有挑战性的场景中,也可检测并区分行人、骑行者和机动车辆,弥补了传统相机在暗光场景下的弱感知力的问题。为了发挥两者的互补优势得到更好的检测效果,本文设计了动态权重分配策略,根据图像灰度值的离散程度来分配权重,始终将较高的权重分配到目标与背景对比度较大的图片中。如图2所示,可见光图像中目标与背景之间的对比度较低,目标与背景之间没有形成显著的区分,且灰度分布相对集中。红外图像中目标与背景之间对比鲜明,且细节处纹理清晰,通过灰度离散图可以看出灰度值分布均匀。
对此本文使用标准差函数来量化图像灰度值的离散程度,首先计算大小为A×B的图片灰度平均值,然后根据式中的灰度平均值进一步计算灰度的标准差,公式如下:
式中:x(i,j)表示图片中像素点为(i,j)的灰度值;arg表示图片灰度平均值;σ表示图片灰度标准差。
为了标准化权重分配,将可见光图像和红外图像的标准差进行归一化,记可见光图像的权重为Wrgb,红外图像的权重为Wip,公式如下:
式中:σrgb表示可见光图像的灰度标准差;σip表示红外图像的灰度标准差。
输入端结构如图3所示。分别计算两张图片的标准差并归一化权重,然后根据权重进行线性融合,将融合后的图像输入到算法中,这样可以充分发挥红外图像和可见光图像的互补优势。
2.3 Yolo v5网络模型改进
在自动驾驶领域,小目标包含道路中的小动物、行人等小目标,也泛指由于距离较远而导致的小尺度目标。由于这类目标在图片中占用的像素点较少,现有的算法难以准确地将其与背景区分导致检测效果不尽人意。又由于Yolo v5算法的主干网络经过了多次下采样,导致低分辨率特征图中的细节信息大量丢失。而高分辨率的特征图中含有较多的细节信息,并且拥有的较小感受野可以更好地识别小目标,所以增加一层高分辨率的检测层对提升小目标的检测效果有着至关重要的作用。为得到高分辨率特征图本文采用高分辨率HRNet[16]网络对主干网络进行改进,该方法由4个阶段组成,从高分辨率的卷积开始作为第1阶段,然后逐步增加高分辨率到低分辨率的子网,将多分辨率子网进行并行连接,并且在每个阶段都进行各个分辨率之间的信息融合,使每一个高低分辨率的表征都从其他并行连接中反复提取信息来实现信息增强。因此HRNet网络可以保持一条高分辨率特征层用于小目标的检测,而不是使用低分辨率网络通过上采样恢复成高分辨率网络,但由于自动驾驶场景中的实时性也同样重要,本文对HRNet网络进行轻量化处理。受轻量化网络ShuffleNet[17]的启发,将高效置换模块嵌入到HRNet网络中。又由于置换模块重度使用1×1卷积造成的计算量过大,引入一种轻量化条件通道加权来替换1×1卷积,结构如图4所示。
图中H是交叉分辨率加权函数。由于第s个阶段有s个并行分辨率,以及权重映射W1、W2、W3、W4,分别为对应的分辨率。使用轻量级函数H计算多个并行分支的通道权重,使用该权重进行通道、分辨率之间的信息交换,映射公式如下:
式中{X1,...,Xs}是s分辨率的输入映射,X1对应最高分辨率,Xs对应第s个最高分辨率。
图中F是指空间加权函数,函数实现为:Xs-GAP-ReLU-Sigmoid-Ws,全局平均池化算子(GAP)的作用是从所有位置收集空间信息。为了探究使用条件通道加权替换前后模型的大小变化,使用10亿次浮点运算(GFLOPs)和浮点运算数量(Params)来量化模型的大小,分别将替换前后的网络在flir测试集中进行测试,实验结果如表1所示。从表中可以看出替换后的网络复杂度减少了50%,由此可得使用条件通道加权可以显著加快网络的运行速度。

表1 使用条件通道加权替换前后模型大小对比
Yolo v5的检测层使用了FPN结构。文献[18]中指出FPN的成功在于它分而治之地解决了多尺度目标检测问题,而不是它的多尺度特征融合。最深一层的特征包含了足够多的上下文信息来检测中大尺寸的目标。如图5所示,图(a)在平均检测精度几乎一样的情况下计算量却远大于图(b)。最深的C5层携带了足够的上下文信息来检测中大尺寸的目标,这使得多尺度特征融合远远不如分治重要。
因此本文引入一种新的方法来优化Yolo v5算法,由于主干网络中已经进行了充分的特征融合,所以后续不再使用复杂的多尺度融合方法,而是直接使用主干网络中的多尺度输出,这样可以保证中大尺寸目标的检测性能基本不变的情况下降低网络复杂度,进而减少运算量。但是低分辨率的特征难以准确将小目标与背景进行区分造成漏检。为避免这个问题,本文在原有3层检测层的基础上利用主干网络中的高分辨率特征层增加一层针对小目标的特征检测层。高分辨率的特征图有着较多的细节信息和较小的感受野,有利于准确地将小目标与背景进行区分,改进后网络结构如图6所示。
2.4 数据集准备
由于本文网络适用场景的特殊性,使用大型通用数据集难以衡量本文网络的性能。因此本文使用flir红外数据集,该数据集提供了可见光图像和对应的红外图像,数据是通过安装在车上的普通相机和热成像相机真实录制的,共包含14 000张图片,其中60%为日间场景,40%为夜间场景。存在部分密集目标和远小目标的情况,可以验证本文算法的有效性,这些图片中包含person、car、dog、bicycle、bus、truck这6个类别。对这些图片按照8∶2进行划分,分别作为训练集和测试集,并且使用边缘特征匹配方法将可见光图像与红外图像对齐。
由于数据集中没有足够的小目标来验证本文算法增加小目标检测层的有效性,所以需要对数据集进行样本增强,本文采用文献[19]中提出的方法对数据集进行增强,解决了小目标样本数量太少的问题。该方法在自建的小目标库中随机选取8个小目标,采用泊松融合的方法融合到原始图片中,但是泊松融合存在一个严重的缺陷,即融合后的目标中含有背景的像素,导致目标的颜色与背景相近,但在本文算法中增加与背景颜色相近的训练目标可以增强算法对前后景的辨别能力并提高算法的鲁棒性,增强前后对比如图7所示。
2.5 锚框优化
每个数据集都有各自的应用领域和侧重点,COCO[20]数据集含有80个类别,并且多为大尺度目标,而本文中使用的flir红外数据集只有6个类别。为得到更好的预测结果,需要选出适合flir数据集的锚框。Yolo v5网络中使用的K-means[21]算法对真实框聚类生成9个锚框,但是由于K-means算法初始聚类点的随机性,极易造成局部最优。为得到更准确的锚框,本文采用二分K-means算法,该算法通过划分类来克服初始点的问题。由于本文算法增加了一个新的特征检测层,所以需要选取12个锚框,使用二分K-means得到最终的12个锚框分别为:(5,6),(7,14),(15,13),(13,26),(25,16),(34,28),(20,50),(54,21),(57,42),(46,97),(88,55),(130,78)。本文引入BPR(best possible recall)来对通过聚类得出的12个锚框进行验证,公式如下:
式中:best recall表示最多能够被召回的真实框数量;all表示所有的真实框数量。
BPR越接近1效果越好,计算聚类得出的12个锚框,最终得到BPR的值是0.997,表示锚框具有较强的代表性,可以满足实验的要求。
3 实验结果与分析
在本节中,将改进之后的算法与Yolov5进行比较,实验环境、训练细节、评价指标和实验结果分析如下。
3.1 实验环境
本次实验基于Windows 10平台通过Python语言实现,使用Pytorch深度学习框架来搭建网络模型,硬件环境为AMD R7 3700x CPU、32GB内存和RTX2070显卡。
3.2 训练细节
为了找出性能提升最大的α值,在Yolo v5算法中使用α-EIoU边界框函数进行测试,结果如图8所示。由图可见,当α=3时,对算法的检测性能提升最大,达到了1.68%。
分别将Yolo v5算法和本文算法在flir红外数据集上进行训练。批大小设置为8,模型训练迭代次数设置为300,初始学习率为0.001,训练过程中采用余弦退火算法对学习率进行动态调整。训练过程中的损失函数情况如图9(a)所示,由于本文算法进行了轻量化操作和对损失函数的改进,可以看出修改后的算法收敛速度明显变快,并且最终收敛之后的损失也比原算法更小。
3.3 评价指标
为了验证改进的目标检测算法的有效性,选取准确度P(precision),召回率R(recall)、AP(average precision)、mAP@0.5(mean average precision)和检测速度FPS(frames per second)5项指标对算法进行评价,各指标公式如下:
式中:tp表示识别为正样本的数量;fn表示错误识别为负样本的正样本数量;fp表示错误识别为正样本的负样本数量;P表示准确率;R表示召回率;k表示类别总数。
3.4 定量分析
训练过程中的R、P和mAP@0.5变化情况如图9所示,由于使用了高分辨率网络并且增加了小目标检测层,对小目标及密集目标的检测效果得到了提升,使得整体检测准确率明显增加。
由图9可知,本文算法的召回率、准确度和mAP@0.5相比Yolo v5均有明显的提升。再结合表2可知,本文算法在召回率R、准确度P和mAP@0.5分别有8.74%、8.31%和7.64%的性能提升,但是由于添加的高分辨率主干网络和新增的小目标检测层使得检测速度降低了0.62帧/s。

表2 Yolo v5算法改进前后的性能对比
为了深入探究本文算法对各个类别的影响。将Yolo v5算法与本文算法进行测试,如表3所示,可以看出本文算法在各个类别均有不同程度的提升,尤其是person、bicycle、dog,在AP(IoU=0.5)上分别有了6.74%、12.19%、10.39%的提升。这3个类别相对另外3个类别来说目标尺度较小,进一步验证了本文改进对小目标及密集目标检测的有效性。

表3 Yolo v5(A)和本文算法(B)的6个类别性能测试对比
3.5 定性分析
选取交通场景下具有小尺度目标或密集目标的图片,分别使用Yolo v5算法和本文算法进行检测,并将小目标和密集目标处进行细节放大。由图10(a)可知,图片中第1个放大处有一位推车的男子,该目标较小且左侧有其他行人遮挡。图中第2个放大处有大量密集程度较高且距离较远的购物人员,这两处在Yolo v5算法中都没有检测出来,可以观察到右侧对比图中的本文算法可以准确地检测出来,并且检测准确率均比原算法有一定程度的提高。
为了进一步验证本文算法在双模态输入下的有效性,又选取了一对可见光-红外图像进行测试。如图10(b),图中第1个放大处有两辆汽车,在可见光图片中由于光线较暗,进行特征提取时细节信息丢失,导致原Yolo v5算法只检测出第一辆汽车,图中第2个放大处有两位行人,右边的黑色衣服行人几乎与背景融为一体,原Yolo v5算法只检测出其中一位。由于是夜间场景,红外图像分配到了较高的权重,提取到了大量的红外信息,因此本文算法可以将两辆汽车和两位行人准确地检测出来。得益于本文设计出的动态权重分配策略,充分发挥了可见光-红外图像之间的互补优势。
这两张图片中一共有4处细节,检测难度非常大以至于原Yolo v5算法都没有检测出来,作为对比的本文算法都可以准确地检测出来,可以看出本文提出的改进方法效果是非常明显的。
3.6 消融实验
为了探究本文改进点对Yolo v5算法的提升效果,对改进点逐一进行消融实验分析,实验结果如表4所示。其中A表示使用改进α-EIoU作为边界框损失函数。B表示使用改进Lite-HRNet网络作为主干网络。C表示在特征检测层中取消使用特征融合。D表示使用小目标样本增强算法。E表示使用改进二分K-meams算法对锚框进行聚类。F表示将可见光-红外图像使用动态权重进行融合。
由表4可见,将α-EIoU作为损失函数的算法1在mAP和FPS上均有小幅度的提升。改进主干网络后的算法2在检测精度上提升了4.46个百分点,但由于增加了主干网络的复杂度,使得检测速度降低了5.69帧/s。算法3中取消特征融合层中的复杂特征融合结构,大大减少了计算量。在检测精度基本不变的情况下显著提高了检测速度。算法4中加入了小目标样本增强算法,提升了小目标的检测性能,由于小目标样本量的增加,使得检测速度降低了1.42帧/s。算法5中对锚框聚类算法进行了改进,使得聚类出的锚框具有更强的代表性,实验结果表明检测精度和速度均有提升。算法6中采用了可见光-红外图像双模态输入,得益于本文设计的动态权重分配策略使两种图像之间发挥互补优势,显著提升了算法的检测性能。本文算法检测精度提升了7.64个百分点。
3.7 与其他目标检测算法进行性能对比
为了进一步验证本文算法的检测性能,将本文算法与Faster RCNN、SSD、Yolo v4、YoloX[22]、TPHYolo v5[23]、DetectoRS[24]目标检测算法进行对比,均采用flir数据集双模态输入进行性能测试,同时使用mAP@0.5和FPS作为评价指标,检测结果如表5所示。
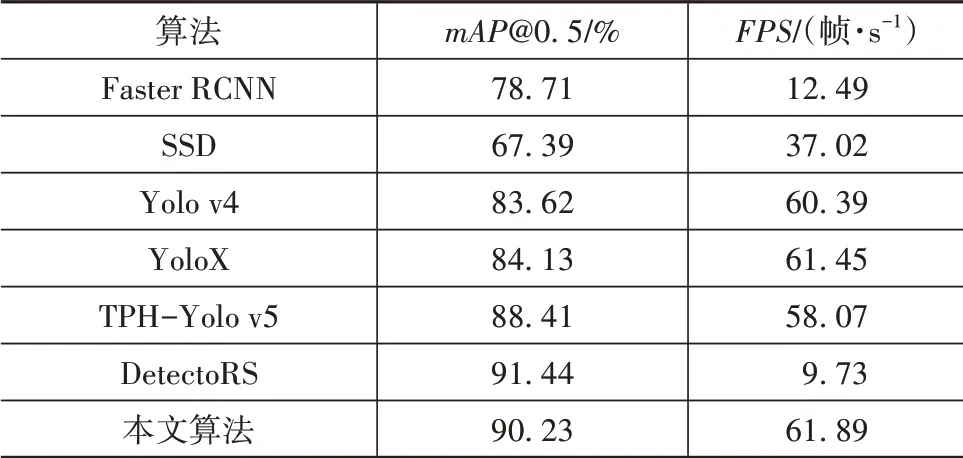
表5 主流目标检测算法测试结果对比
从表中可以看出DetectoRS作为两阶段算法,在检测速度上远远落后于单阶段算法。相反,其在检测精度上具有明显的优势,但是与主流单阶段算法相比依然难以拉开较大差距,而本文算法在检测速度遥遥领先的情况下检测精度基本与其持平。本文算法在速度与精度之间取得了平衡,在满足实时性要求的同时媲美两阶段算法的检测精度,满足工业应用需求。
4 结论
本文中以Yolo v5目标检测算法为基础,针对小目标以及密集人群检测效果不佳和暗光场景下目标背景间难以区分的问题,使用轻量化网络来作为Yolo v5算法的主干网络,并通过增加高分辨率的检测层来提高小目标和密集目标的检测效果。采用可见光-红外图像双模态输入,并通过动态权重融合策略,使得暗光场景下算法可以提取到更多的细节信息,改进特征融合来减少计算量以提高检测速度。在flir数据集上的实验结果显示,本文算法在检测速度基本不变的情况下,提高了7.64个百分点的检测精度,且对小目标和密集目标的检测效果改善明显。下一步将在保证检测精度的同时对算法进行更多的轻量化,进一步加快检测速度,并且将该算法应用于车载嵌入式设备,使该算法得以应用于智能汽车的目标检测中。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
环球时报(2022-05-23)2022-05-23
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
金桥(2021年4期)2021-05-21
集装箱化(2021年1期)2021-04-12
天津医科大学学报(2021年1期)2021-01-26
中国信息技术教育(2020年2期)2020-02-02
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
电子制作(2019年7期)2019-04-25
