
基于知识图谱的豆瓣读书问答系统
2022-11-15 09:43卢方超韩梓政戴文华
湖北科技学院学报 2022年6期
钱 涛,卢方超,韩梓政,戴文华
(湖北科技学院 计算机科学与技术学院,湖北 咸宁 437100)
一、引言
知识图谱[1-3]是实现智能化信息检索与知识推理最常用的技术,该技术于2012年由谷歌提出并用于智能化语义搜索[4]。知识图谱技术在解决知识查询的精度及知识推理方面展现出了巨大的优势,成为学术与工业界的研究热点。并且已被广泛应用于智能搜索、智能问答、个性化推荐、内容分发等领域。当前有代表性的知识图谱产品包括当DBpedia[5],YAGO[6],CN-DBpedia[7],搜狗知立方[8]等。从本质上讲,知识图谱是一种实体之间关系的语义网络,可以对现实世界中的客观事物以及它们之间的关系进行形式化的语义描述。随着人工智能技术的逐渐成熟,尤其是自然语言处理技术的发展,知识图谱有了更广泛的应用场景。问答系统作为知识图谱的一个重要的应用方向,基于知识图谱的问答系统[9,10]可以快速地通过输入的自然语言问题,从知识图谱中找到正确的答案,并按照自然语言的形式呈现给用户,这种问答系统在响应及反馈上都是高效的。
豆瓣读书。是目前国内信息最齐全的、拥有用户最多的、并且最活跃的在线图书网站。该网站书籍类别丰富、种类齐全,为用户提供图书介绍、图书评论主要功能,是用户了解图书信息的主要窗口。虽然该网站收集了海量的图书信息,也提供了根据图书的作者、书名和国际标准书号ISBN来查找图书信息。但是其检索仅基于关键字匹配技术,难以满足用户多样化的图书检索需求。例如:用户需要检索“南海出版公司”出版的图书“解忧杂货店”,但忘记了书名,因此只能通过输出关键字“南海出版公司”,然后从返回的所有列表中依次查找该书目,这样的检索体验与效率显然不能满足用户的需求。另一方面图书包含大量的实体信息,如书名、作者、出版年代、体裁、出版社等,这些实体信息是相互关联的。利用知识图谱技术,能够生成一张语义关联网。例如,图1给出图书“解忧杂货店”语义网。如果用户知道该书的出版年份是2014年,用户能利用该知识图谱极大缩小查询范围,甚至能精准的返回查询结果。此外,采用问答形式与用户交互,能极大提高用户检索效率与体验。
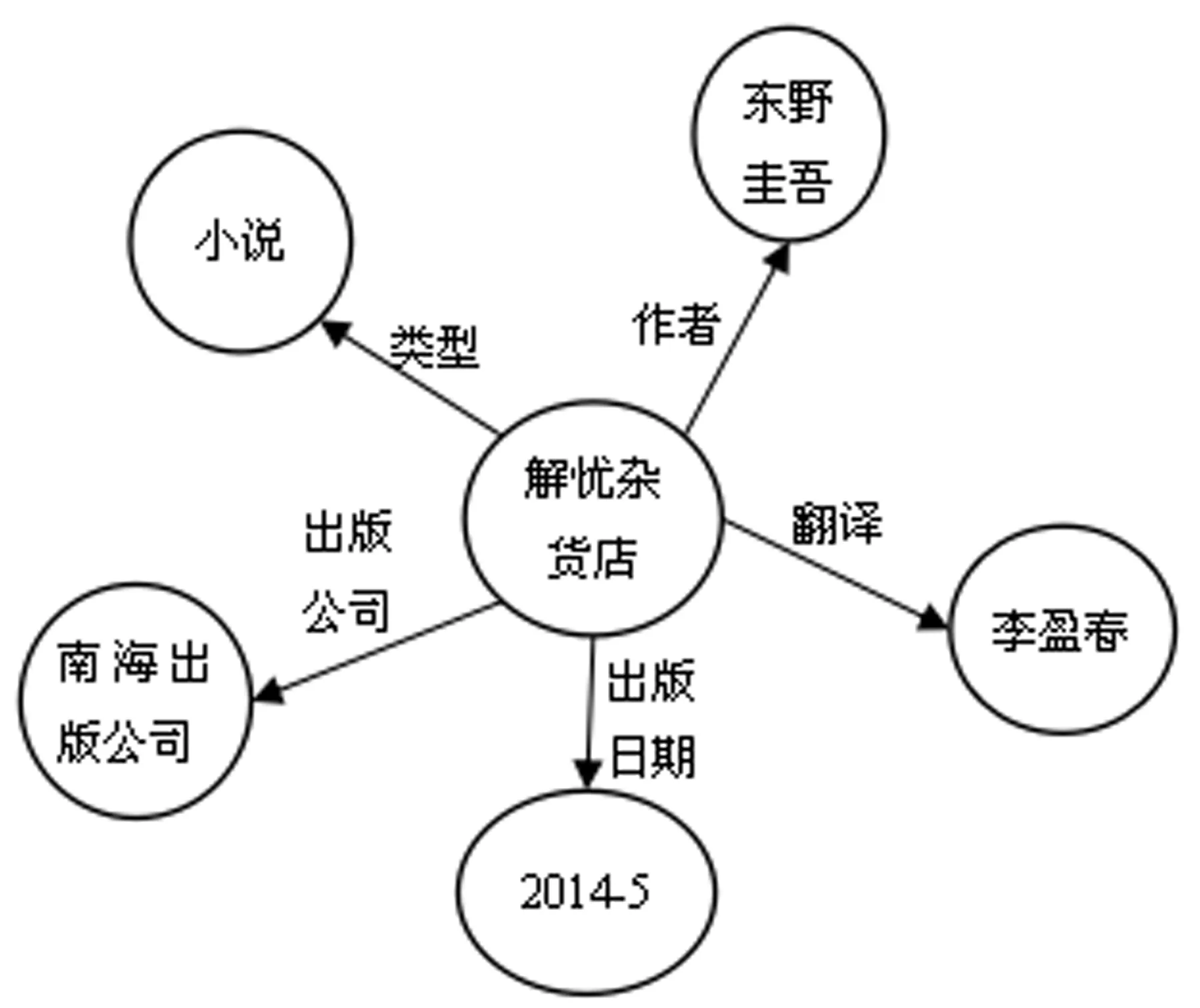
图1 图书知识语义网举例
该文针对豆瓣读书海量的图书信息难以满足用户多样化的图书检索需求,研究开发基于知识图谱的图书问答系统。首先给出相关工作进展;然后提出图书领域知识图谱构建方案;最后探讨基于知识图谱的图书问答系统关键技术。
二、相关工作进度
无论是在学界还是在业界,知识图谱研究已成为热点。典型的代表包括DBpedia[5]、Yago[6]、Freebase[11]与谷歌等。近几年,国内也开始强调知识图谱的研究和应用,如CN-DBpedia[7]、zhishi.me[12]、百度等。 知识图谱按照功能可以分为通用知识图谱与领域知识图谱。通用知识图谱主要用于构建综合性常识知识,可用于语义检索,知识问答等,如百科类的DBpedia、zhishi.me和语言学类的WordNet[13]等。通用知识图谱强调知识的广泛性,大多数采用自底向上构建。领域知识图谱针对特定领域,可以进行知识推理、辅助分析和决策支持等功能。典型的领域知识图谱包括金融、电商、医疗等。电商领域的主要代表是阿里巴巴,它的知识图谱已经达到百亿级别,可以广泛支持商品搜索、商品导购、智能问答等。在金融领域,知识图谱可以让投资者和融资者更快速地了解投资行为,把握行情。张德亮针对金融图谱缺乏问题,利用爬取到的金融股票及企业信息等结构化数据构建了一个小型金融知识图谱[14]。王电化等人提出了一套档案领域知识图谱构建方案[15]。此外,吴荣等人构建了面向图书馆的图书知识图谱并用于图书推荐[16]。不同吴荣等人直接采用结构化数据构建知识图谱,该文尝试探讨如何有效利用互联网海量的无结构图书信息,构建图书领域知识图谱。
知识图谱的一个主要应用是与问答系统相合,构建基于知识图谱的问答系统。它能充分利用海量的语义网络知识,采用自然语言技术,为用户提供人性化的、高效的问答服务[9,10]。在专业领域,问答系统所需的庞大专业知识储备导致过度占用存储空间和降低查询效率的问题可以被知识图谱解决。据研究在规模相同的数据中,运用知识图谱可以节省 10% 的存储空间,查询效率提高近 30 倍[17]。陈刚等人[18]使用BiLSTM-CRF命名实体识别模型增强企业风险知识图谱,构建了一个智能问答机器人,实现了对知识图谱的检索和利用。陈金菊等人[19]提出了基于道路法规知识图谱的多轮问答系统,可以更好地识别用户意图;陈璟浩等人[20]利用“一带一路”投资相关信息构建知识图谱,并实现了问答系统中预处理、问题分类、问题模板匹配以及答案生成功能。李贺等人[21]优化已有的基于疾病知识图谱的自动问答系统,为公众提供一种准确率更高的疾病知识查询工具。上述所建立的问答系统都在各自领域得到了较好的应用,并且在问答系统流程中都融合了领域特色。该文研究将图书知识图谱应用于图书问答系统,尝试为具体网站如何有效利用海量互联网信息提供解决方案。
三、图书知识图谱构建
图书知识图谱构建包含三个关键技术:数据采集、图书三元组构建及知识图谱存储可视化。
1.豆瓣图书数据采集
豆瓣读书网站海量的图书信息是该文构建图书知识图谱的信息源。首先分析标签网页的结构,然后通过爬虫抓取该网页下的所有标签,获取各个标签下的数据URL。在豆瓣读书中,每个URL都有其特殊的结构,因此在对于URL进行解析时,首先要分析其URL的基本结构,URL结构通常为:https://book.douban.com/tag/{}?start={}&type=T, 第一个{}代表着该标签,第二个{}代表开始的第一本书,每一页为二十本书。获取网页源代码后,通过xpath对节点定位并获取所有标签。然后分析标签下的书籍网页代码,通过正则表达式抓取每本书籍里面的书名、评分、评价人数、作者、译者、出版社、出版时间、价格和简介等。此外由于有些书籍基本信息、评分和介绍缺少,因此需要对其作缺省处理。
最终共抓取豆瓣图书标签145个(文学类27个、流行类36个、文化类33个、生活类21个、经管类13个、科技类15个),共28 627本书籍信息,每本书都包含书名、评分、评价人数、作者、译者、出版社、出版时间、价格和简介这些基本信息,抓取的初始数据存放到文件,并用于后续流程处理。
2.图书三元组构建
数据在知识图谱中都是以三元组方式呈现。在图书知识图谱中,三元组主要包括两类:<实体,属性,属性值>和<实体,关系,实体>。<实体,属性,属性值>通常是一对一三元组,<实体,关系,实体>通常是一对多三元组。表1和2分别给出两类三元组实例。根据采集数据分析,该文创建了Book(图书)、Author(作者)、Translator(译者)、Press(出版社)、Publish(出版时间)、Type(类型)六个实体节点标签,name(名字)、score(评分)、price(价格)、bi(简介)、comment(评价人数)四个实体属性和is(是)、author(作者)、translator(翻译)、press(出版)、publish(出版日期)、jou(版次)、has(有)、pn(属于)、tn(被出版)、an(主角)、pun(被发表)、have(拥有)、haveg(体裁)十三种关系。

表1 <实体,属性,属性值>举例

表2 <实体,关系,实体>举例
3.知识图谱存储与可视化
通过对实体和属性的抽取,本文最终构建的豆瓣图书知识图谱包含41 395个节点,308 190条三元组。三元组存储在图数据库Neo4j中。图数据库是可以高效处理复杂关系网的数据库,是基于数学里面的图理论的思想和算法来实现的。在图中节点表示实体,实体间的关系表示为有向边,每一个节点与关系都具有属性。图可以由图、列表或其它多元实体组成,同时节点可以表现为任意结构,通过关系来连接。知识图谱能将数据以可视化形式表现出来。进一步,利用它们之间的关系,能实现知识推理,挖掘出其背后隐含的知识。
四、智能图书问答系统
1.问答系统框架
基于知识图谱的问答系统主框架如图2所示,主要包括三个模块:问题分析模块,知识图谱构建模块和答案查询模块。在问题分析模块中,该文选用模板匹配的问句解析方式。针对图书常用检索问题,分成19类图书问题,建立一个问题分类与问题模板匹配的映射表。具体的,通过机器学习对用户问题进行问题分类,根据分类结果对问题进行问句匹配,匹配好问句模板;再根据所匹配的问句模板,生成基于知识图谱的查询语句,最后在图数据库上查询答案并返回最后答案。
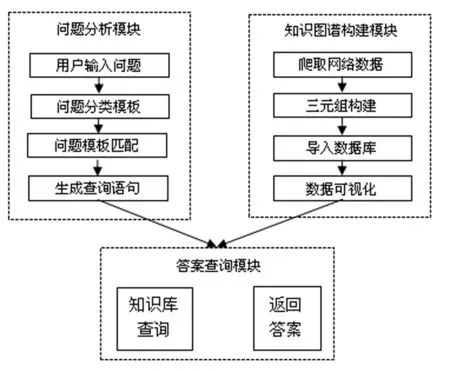
图2 图书问答系统框架
2.问题分类模板
图书问答系统作为特殊的领域问答系统,用户检索图书具有规律性及模板化。经对图书知识图谱数据及用户常用图书查询问题的分类统计,该文提出了19类用户问题模板。表3列出了所有图书问题模板。其中前11条是单条件简单问题模板。例如用户提问:解忧杂货店的出版时间是什么?则可把它归为模板“某本书的出版时间”。标签12-19是复杂问题模板,能对应对用户复杂的检索需求。例如用户提问:南海出版公司在2014年5月出版了什么书?显然通过关键字查询是无法回答该问题的。利用知识图谱,可把该提问归为模板“某出版社在某时间出版了什么书”。

表3 用户问题模板
3.基于贝叶斯的问题匹配算法
用户输入的问句需要匹配相应的问题模板,因此需要对用户问句进行分类处理。由于朴素贝叶斯相较于其它分类器,在分类速度上有着较大的优势,并且其具有数学可解释性,因此该文选用朴素贝叶斯作为问句分类器。下面简要描述该方法。
假设一个用户问题q∈X,X是向量空间,和问题类别集合C={c1,c2,…,c19},又称为标签。朴素贝叶斯方法利用贝叶斯准则计算q属于类ci的概率如下:
(1)
其中p(ci)为先验概率,p(w|ci)为类条件概率,最后计算选取概率最大的类作为预测的问题类别。
朴素贝叶斯是一个机器学习算法,需要事先构建语料来训练模型。问题的文本特征提取采用TF-IDF特征提取算法。通过对模型训练与测试,该文所构建的分类模型达到95%的分类精确,且每100条语句的分类时间仅为0.1ms。
4.查询语句生成
对用户提出的问题进行分类,匹配与之相对应的问题查询模板。为了在所构建的知识图数据库Neo4j查询,需要生成Cypher查询语句。由于用户提问已经模板化,因此该文也采用基于模板的方法生成Cypher查询语句义。表4给出用户问题与对应查询模板例子。例如:用户问题为‘解忧杂货店的评分多少’,得到的分类标签是0,从而得到模板查询语句‘match (b:Book)-[]->() where b.name='{book_name}' return b.score’,将命名实体‘解忧杂货店’替换上去形成了完整的查询语句‘match (b:Book)-[]->() where b.name='解忧杂货店' return b.score’,通过完整的查询语句查出最后的结果。
此外,该文也采用了容错处理策略。如果用户查询问题没在数据库中出现,提出模糊查询策略。例如,如果数据库中没有“解忧杂货店”实体。可先把中文名字转为拼音,然后再利用Levenshtein方法计算两个字符串的相似度,找出与相似高的前k个实体,把结果列表返回到给用户。

表4 用户问题与对应查询模板举例

续表4 用户问题与对应查询模板举例
5.平台设计
该文采用flask框架来搭建本问答系统平台。其工作的流程如图3所示:用户向问答系统提出相应的请求后,网页端向服务器发送请求,服务器接受请求后向控制层发送消息,控制层接受消息后传递给服务层来处理业务逻辑,并与数据库交互后将消息返回给服务器端,最后呈现给用户。

图3 问答系统平台流程
五、结论
针对豆瓣读书海量的图书信息难以满足用户多样化的图书检索需求,提出基于知识图谱的图书问答系统。该文探讨了领域知识图谱搭建智能问题系统关键技术,包括数据爬取、三元组构建、数据可视化,问题模板分类及匹配。为行业网站充分利用海量互联网信息提供了一套可操作的解决方案。在未来,将研究自动实体关系的抽取,以扩充图书知识图谱的信息量;研究深度学习自动生成查询语句,使问答系统更加智能化。
猜你喜欢
山西大学学报(自然科学版)(2021年1期)2021-04-21
少先队活动(2020年12期)2021-01-14
五邑大学学报(自然科学版)(2019年3期)2019-09-06
计算机技术与发展(2018年12期)2018-12-20
中成药(2017年3期)2017-05-17
领导科学论坛(2016年9期)2016-06-05
专利代理(2016年1期)2016-05-17
现代防御技术(2014年6期)2014-02-28
杂草学报(2012年1期)2012-11-06
质量与标准化(2010年5期)2010-05-03
