
基于多信息融合的噪声人脸图像超分辨率重建
2022-11-11 12:45魏子凯辛经纬王楠楠
西安工程大学学报 2022年5期
魏子凯,辛经纬,杨 恒,王楠楠
(1.西安电子科技大学 通信工程学院,陕西 西安 710071; 2.深圳爱默科技有限公司,广东 深圳518109)
0 引 言
随着科技的发展,手机、无人机、监控摄像头等非限制场景图像采集设备越来越普及,而由于物理成像系统和成像条件的限制,非限制场景下采集中的噪声和模糊等降质因素导致采集的人脸图像的区分度和信息量都大大降低。当面对一些实际应用如人脸识别等高级视觉任务时,这些低分辨率人脸图像很难满足要求。因此为满足实际应用,需要对这些低质人脸图像进行人脸超分辨率重建(face super-resolution,FSR)。
人脸超分辨率重建是指从低分辨率(low-resolution,LR)人脸图像重建出高分辨率(high-resolution,HR)人脸图像的技术。目前主流的FSR算法以深度学习算法为主。
早期人脸超分辨率重建主要使用现有的一般图像超分辨率重建方法,如SRCNN[1],但是其在恢复人脸高频信息上效果并不好。于是,HUANG等提出了一种优化算法SRCNN-IBP,可以提高算法的重建效果[2]。后来,随着注意力机制的广泛应用,许多整合注意力机制的FSR方法也相继被提出[3-5]。
由于人脸具有一些特定的先验信息可以用来帮助FSR网络恢复出面部结构细节更清晰的人脸图像,因此基于先验指导的FSR方法是目前人脸超分辨率重建领域的一个主要研究热点。
先验引导的 FSR 方法是指通过提取人脸先验信息并利用它来促进高分辨率人脸重建的方法。ZHU等设计了一种级联双网络CBN,通过估计人脸密集对应场先验信息并联合FSR重建网络进行训练[6]。CHEN等提出FSRNet方法,利用人脸热力图和人脸解析图两种先验信息进行人脸超分辨率重建[7]。YIN 等提出JASRNet,利用共享的编码器同时提取超分辨率重建和先验估计所需要的特征[8]。HU等提出由3D面部先验引导的FSR方法FSRG3DFP,通过估计3D先验信息来学习3D面部细节信息,帮助进行人脸超分辨率重建[9]。随后,由于生成式对抗网络(generative adversarial networks,GAN)[10]具有生成图像清晰度高,细节丰富的优势,研究人员开始研究基于GAN的FSR算法。YU等提出UR-DGN实现了大尺度的人脸超分辨率重建[11]。随后,HSU等提出了基于身份信息保留的SiGAN,利用人脸识别网络来定义身份损失,从而生成更加真实的高分辨率人脸图像[12]。结合GAN和人脸先验信息,CHEN等提出PSFR-GAN方法,将面部解析图先验信息与GAN网络进行融合,进一步提高模型性能[13]。MENON等提出基于生成先验的FSR方法PULSE,将FSR作为一个生成问题来生成高质量的SR人脸图像[14]。
人脸先验指导的方法虽然取得了较好的重建效果,但是大多数现有方法仅对单一类型的面部先验信息进行探索,人脸先验信息没有得到充分利用。此外,许多以前的FSR方法复杂且难以在现实场景中进行应用。在图像退化严重的非限制场景中,这些方法会出现先验估计不精确的问题,制约了FSR性能的提升。而基于GAN的FSR方法重建的图像质量虽然比较高,但是这种类型的网络模型很难训练。因此,设计出可以充分利用人脸的先验信息并且适用于退化图像的噪声人脸图像超分辨率重建方法是本文的研究重点。
针对上述问题,本文在人脸图像降质的过程中引入噪声和运动模糊来模拟现实场景,并提出一种多信息融合的方法来进行噪声人脸图像超分辨率重建工作。该方法融合了人脸解析图和人脸属性2种先验信息,采用基于GAN的训练方式进行训练。本文方法将像素级先验信息和语义级先验信息进行充分融合利用,可以从含噪声的低分辨率人脸图像中重建出细节丰富的高分辨率人脸图像。
1 多信息融合网络
1.1 算法概述
本文所提出的基于多信息融合的FSR网络由3部分组成:粗超分辨率重建网络、解析图估计网络与属性分析和重建网络。网络结构如图1所示。

图 1 基于多信息融合的FSR网络结构
图1中,首先将LR图像输入到由残差模块构成的粗超分辨率重建网络中,重建出粗略的HR人脸图像。随后将粗略的HR人脸图像输入到解析图估计网络进行人脸解析图估计,然后合并粗略的HR人脸图像和估计的人脸解析图并输入到属性分析和重建网络中进行人脸属性估计和最终的HR人脸图像的重建。
1.2 粗超分辨率重建网络
输入的低质人脸图像由于存在噪声并且分辨率非常小,直接实现到高质量人脸图像的映射过程十分困难。因此,本文首先构造一个粗超分辨率重建网络来对输入的含噪声的低质人脸图像进行一次粗略的超分辨率重建操作,重建的粗略超分辨率图像可以缓解估计先验信息的困难。
设x表示LR输入图像,y表示网络重建的粗略的HR人脸图像,粗超分辨率重建网络SRcoarse(·)的重建过程可以表示为y=SRcoarse(x)。粗超分辨率重建网络的结构如图1左上角所示。其从一个3×3卷积开始,然后通过12个残差块进行残差学习,最后经过上采样模块重建出粗略的超分辨率图像。残差块的有效性已经在近年来的各种图像超分辨率重建方法中得到了验证,网络所重建出的粗略超分辨率图像将用于下一步的人脸先验信息估计和高分辨率人脸图像的重建工作。
1.3 解析图估计网络
不同的人脸图像在其形状和纹理上都有着不同的分布,当图片的分辨率下降时,图像的形状信息相比纹理信息可以更好地得到保留,同时图像噪声对于图像形状信息的影响也比纹理信息更小,因此本文提出一种解析图估计网络来对表征人脸形状信息的人脸解析图进行估计,其结构如图2所示。

图 2 解析图估计网络结构
从图2可以看出,解析图估计网络由编码器和解码器组成。具体地,编码器不断对图像进行下采样以去除纹理信息,而解码器将形状特征恢复到与输入图像相同的大小,该结构可以在多个不同的图像尺度上捕获重要信息。同时为了将不同尺度的图像进行空间信息的保留,解析图估计网络还使用了跨层的跳跃连接的机制,并在跳跃连接中使用了1×1卷积进行处理来使得特征具有相同的通道数。
解析图估计网络估计人脸解析图先验信息(p)的过程表示为p=Decp(Encp(y)),其中,Encp和Decp分别是编、解码模型,y为粗超分辨率重建网络的输出。最终,网络生成和真实人脸解析图监督信息通道数量一致的人脸解析图估计。
1.4 属性分析和重建网络
与自然图像相比,人脸图像具有更多的先验信息可以利用,例如人脸属性信息。本文考虑各种先验信息间的相关性,提出一种属性分析和重建网络,该网络通过对人脸的属性信息进行估计,在人脸解析图的像素先验信息的基础上引入了语义表征的属性信息来对人脸超分辨率重建进行进一步的约束。属性分性和重建网络的结构如图3所示。
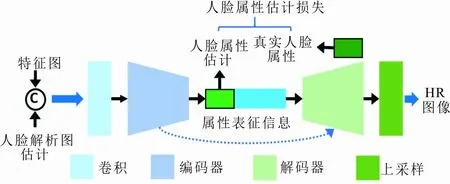
图 3 属性分析和重建网络结构
从图3可以看出,网络首先将粗超分辨率重建网络输出的特征图和解析图估计网络输出的人脸解析图估计进行合并操作来作为属性分析和重建网络的输入,编码器通过堆叠多个卷积层来提输入图像的高级特征表征(a):a=Enc(concat(y,p)),其中,concat(·)表示合并操作,其作用是将2张图片在通道维度进行合并,Enc(·)表示网络的编码器。对于编码器输出的特征表征信息a,本文选取其中一部分来作为人脸属性信息的估计,并在网络训练期间通过真实人脸属性信息对其进行监督。随后,网络将属性表征信息a送入解码器进行重建操作,网络最终重建出的高分辨率人脸图像(z):z=Up(Dec(Enc(a))),其中,Dec(·)表示网络的解码器,Up(·)表示上采样网络。编解码器由一系列3×3卷积构成,编码器将大小为64×64的特征下采样至2×2大小,并通过1个全连接层得到人脸属性表征a;解码器则将a恢复至原始特征大小64×64,同时编解码器之间通过跳跃连接来减少图像轮廓信息的丢失,最后通过一个上采样网络重建出128×128大小的高分辨率人脸图像。
1.5 损失函数

1.5.1 像素损失
在图像超分辨率重建中使用均方误差(mean square error,MSE)损失可获得较高的客观指标,如PSNR和结构相似性(structural similarity,SSIM),但是其通常会丢失高频纹理信息,导致图像的过度平滑。为避免以上问题,本文使用Lpixel损失作为像素损失函数:
(1)

1.5.2 人脸先验损失
为了约束人脸先验信息的估计过程,充分利用人脸先验信息,本文采用人脸先验损失分别对解析图估计网络与属性分析和重建网络进行优化:
(2)
(3)
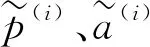
1.5.3 对抗损失
基于GAN的方法为图像超分辨率重建提供了良好的视觉效果,因此本文同时将GAN合并到FSR网络框架中,通过加入判别网络来区分SR图像和真实高分辨率图像,同时训练FSR网络以欺骗判别器。训练GAN的对抗损失表示为
(4)
式中:D(·)为判别网络。该损失有助于使重建图像的纹理更清晰逼真,提高图像的感知质量。
1.5.4 总损失
本文对各个损失函数进行加权组合,最终得到用于模型训练的总损失函数:
L=Lpixel+λ1Lp+λ2Lattr+λ3Ladv
(5)
式中:权重参数λ1、λ2、λ3设置为1、10、0.005。
2 结果和分析
本节首先介绍实验采用的数据集和数据退化模型,然后介绍具体的实验细节;之后将本文模型与7个主流FSR方法进行比较,以评价本文方法性能;最后通过消融实验来验证本文模型的有效性。
2.1 数据集、退化模型和参数设置
本文使用公开的人脸数据集CelebA[15]进行实验。本文取前36 000 张图像进行训练,并取接下来的 1 000 张图像进行测试。本文根据人脸区域粗略地裁剪图像,并在没有任何人脸对齐操作的情况下将图像大小调整为128×128。每张图像有40个属性标注。此外,由于CelebA没有原始的人脸解析图,因此本文借鉴FSRNet[7]中的解决方法,使用GFC[16]模型来生成图像的人脸解析图来作为网络训练时的人脸解析图监督信息。
为了检测网络对含噪声的退化图像的有效性,本文仿照FACN方法[17]使用3个退化模型(噪声强度n分为0、10、30)对HR图像图4(a)进行处理来模拟LR图像,8倍下采样的3个退化模型的LR图像效果如图4(b)、(c)、(d)所示。

(a) 高分辨率人脸 (b) n=0 (c) n=10 (d) n=30
图4(b)使用双三次插值下采样来模拟缩放因子为8的LR图像(简称为Bic)。图4(c)是在Bic模型的基础上添加噪声级别为10的高斯噪声(简称为BicN),其中噪声级别n表示[0, 255]像素强度范围内的标准偏差。图4(d)首先通过标准差为1.6、大小为7×7的高斯核对图4(a)进行模糊,然后进行双三次插值下采样并添加噪声级别为30的高斯噪声(简称为BBicN)。
本文的相关实验均在配置Nvidia 2080ti GPU的服务器上通过Pytorch深度学习框架实现。其中,网络学习率设置为1×10-4,批训练大小设置为16,梯度优化器采用Adam[18]优化器,优化器参数β1=0.5和β2=0.99;本文在图像的Y通道(YCbCr颜色空间)上使用PSNR和SSIM 2个客观评价指标来对噪声人脸超分辨率重建的效果进行客观评价。
2.2 对比实验
在本节中,将本文方法与Bicubic、GLN[19]、EDSR[20]、FSRNet[7]、AEUN[21]、SPARNet[5]和EIPNet[22]等7种方法进行对比实验。为了进行公平比较,所有方法的训练数据处理保持一致并对模型进行重新训练,并在经过3种不同降质模型的CelebA测试数据集上进行测试。对比方法中除SPARNet方法为基于GAN的方法外,其他6种方法均为未使用GAN方法训练的常规FSR方法。常规FSR方法的PSNR、SSIM指标值较好,但图像容易过度平滑;而基于GAN的方法是在常规FSR方法的基础上使用了对抗训练的方式,生成图像更符合人眼视觉,但是PSNR、SSIM指标会有所下降。表1展示了各方法在8倍超分辨率重建下的平均PSNR和SSIM值,PSNR和SSIM的值越大,表示效果越好。

表 1 不同降质下的CelebA数据集上的超分辨率重建结果指标对比
表1中,由于本文方法为基于GAN的方法,为验证本文方法的有效性,避免GAN对抗训练对客观指标的影响,方便和其他常规FSR方法进行比较,本文进行了2种实验设置:不使用GAN对抗训练的常规FSR训练方式和使用GAN方法进行对抗训练的方式,分别用“本文1”和“本文2”表示。
本文首先比较不加噪声时图像的超分辨率重建的定量结果。根据表1第2、3列的结果可知,在常规FSR方法中,本文方法在各项指标上都显著优于其他现有方法,PSNR相比指标最好的EIPNet方法提升了0.21 dB。在基于GAN的方法中,本文方法也优于SPARNet方法。然后,本文再比较添加噪声后的超分辨率重建结果。如表1第4、5列和第6、7列所示,可以看到在噪声的影响下,所有方法的性能都有所降低,但是相比其他方法,本文方法依旧有着最好的客观评价指标,PSNR相比最好的方法平均提升了0.2 dB。这说明了本文方法对含噪声的低分辨率图像依旧有着很强的适应性。
此外,本文还对不同方法的高分辨率人脸重建图像进行了主观评价,以验证本文方法的有效性。图5展示了不同方法在3种降质图像下8倍超分辨率重建的主观视觉效果。

目标图像 输入图像 Bicubic EDSR[20] GLN[19] FSRNet[7] AEUN[21]SPARNet[5]EIPNet[22] 本文1 本文2
从图5可以看出,常规FSR方法均存在图像过度平滑的问题,在图像不添加噪声时,方法“本文1”相比于其他在常规FSR方法所重建出的人脸图像更接近于目标图像。而图像加入噪声后,所有方法的重建效果有所降低,但本文方法仍然可以重建出清晰的面部,尤其是眼睛和鼻子部位。对上述结果进行分析,一般图像超分辨率重建方法EDSR由于没有考虑人脸图像的特殊性,重建人脸会出现纹理细节的缺失,在图像添加噪声之后尤为明显。其他几种对比方法均为FSR方法,故性能相对EDSR都有所提高。其中,方法AEUN在TEAD[23]方法的基础上引入人脸属性信息来帮助生成人脸图像的各个组成部分;方法EIPNet利用人脸边缘特征对图像进行约束,以减轻模糊效应,但是其在图像添加噪声后也会出现五官纹理细节丢失的问题。
如图5所示,基于GAN的方法相比于常规FSR方法有着更高的感知质量,重建出的图像更清晰,细节纹理更丰富。本文2的方法和同样是基于GAN的SPARNet方法相比,重建出的纹理更细腻,伪影更少,所重建出的图像也更接近真实图像。
对比其他同样利用人脸先验信息的方法,本文方法无论图像是在不加噪声还是添加噪声时都具有更高的客观指标和更好的主观质量,这充分证明了本文方法对人脸的先验信息进行了有效且充分的利用,并对图像中的噪声有着较强的鲁棒性。
2.3 消融实验
为了验证本文方法是否有效利用人脸的先验信息,本文进行了消融实验,实验结果如图6所示。
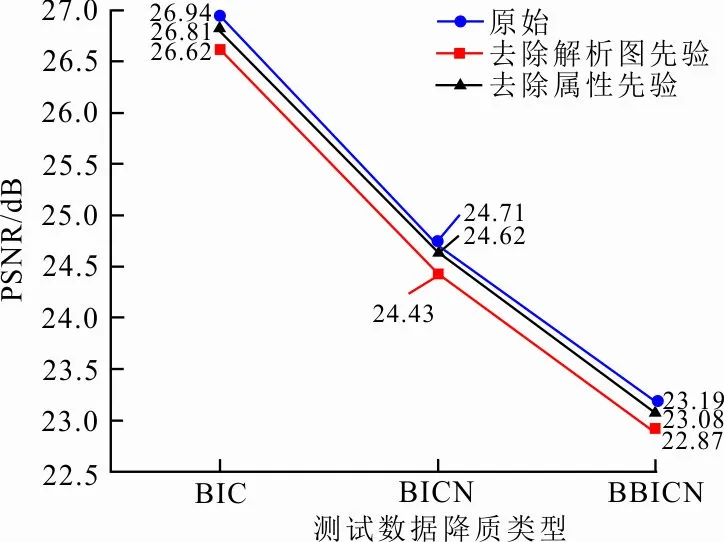
图 6 消融实验结果
图6中,本文分别将不同的先验信息监督去除并对网络进行重新训练,然后测试网络的超分辨率重建性能。具体的,本文分别去除了人脸解析图先验信息的监督和人脸属性先验信息的监督并对网络重新进行训练来观察不同先验信息对模型重建结果的影响以及网络对不同先验信息的利用情况。可以看出,分别去除人脸解析图和人脸属性的先验信息监督后,重建结果的PSNR值平均下降了0.3 dB和0.1 dB。这表明本文方法充分利用了人脸先验信息,其中人脸解析图先验相比人脸属性先验可以为噪声人脸超分辨率重建带来更大的性能提升。而使用2种先验信息的原始网络有着最好的性能,这表明更丰富的先验信息可以带来更多的提升,也证实了本文所提出的多信息融合方法的有效性。
3 结 语
本文提出了基于多信息融合的噪声人脸图像超分辨率重建方法。该方法首先将含噪声的低分辨率人脸图像输入到粗超分辨率重建网络中获得粗略的高分辨率重建图像,然后将其输入到解析图估计网络中进行人脸解析图估计,之后在属性分析和重建网络中估计人脸属性,通过融合人脸解析图和人脸属性这2种先验信息,最终重建出高分辨率人脸图像。实验结果表明,本文方法无论在定性的视觉质量还是在定量的评价指标上,均克服了噪声对图像的影响,获得了良好的重建性能。在今后的研究中,可以在此基础上探究多类别噪声对人脸图像超分辨率重建的影响,使其能在真实场景下更好地应用。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
成都信息工程大学学报(2019年3期)2019-09-25
数学物理学报(2019年3期)2019-07-23
家庭影院技术(2018年9期)2018-11-02
动漫星空(2018年9期)2018-10-26
制造技术与机床(2017年7期)2018-01-19
自动化学报(2017年5期)2017-05-14
自动化学报(2017年5期)2017-05-14
光学精密工程(2016年4期)2016-11-07
