
基于改进循环生成对抗神经网络的语音增强
2022-11-11 03:28徐珑婷田娩鑫魏郅林
东华大学学报(自然科学版) 2022年5期
徐珑婷, 田娩鑫, 魏郅林
(东华大学 信息科学与技术学院, 上海 201620)
语音是人们交流常用的一种信息载体。在实际环境中,语音信号总会受到外界噪声的干扰,常见的噪声包括自然界的白噪声、其他人说话的干扰声以及录音设备中的内部电噪声等。过多噪声的存在,会使原有语音无法分辨。语音增强是解决噪声污染的一种有效方法,通过抑制背景噪声,从嘈杂的语音中保留干净的语音信号,进而提高语音质量和清晰度。
语音增强算法早期大多基于滤波的概念,例如频谱减法算法[1]、Winner滤波[2]、信号子空间算法[3]和最小均方误差频谱估计器[4]。随后又发展出K奇异值分解[5]、非负矩阵分解(nonnegative matrix factorization, NMF)[6]等算法。随着深度学习的发展,深度神经网络(deep neural networks, DNN)已被广泛且有效地应用于语音增强。比如Xu等[7]提出了一个基于回归的语音增强框架,利用多层深度架构的DNN来实现语音增强,试验结果表明,与对数最小均方误差方法相比,基于DNN的语音增强算法在各类语音质量评测标准中都取得了明显的优势。Huang等[8]提出了一种基于DNN的多波段激励的语音增强方法,在增强阶段利用每帧的音高和DNN的输出来增强有噪声的语音,该方法在不同信噪比下均优于基线。因此DNN在语音增强领域有很大的潜力。生成对抗网络(generative adversarial network, GAN)是基于零和博弈思想构建的一种深度学习模型,它的生成器和鉴别器一般均由DNN构成。GAN在语音增强领域最大的优势是能够学习任何分布下的数据,并能生产相似分布的数据[9],通过对纯净语音样本的学习,使含噪语音转换为类似于纯净语音的增强语音,以达到语音增强的目的。但GAN需要大量成对的数据集进行训练,训练的难度增大,不利于实际的应用。
Zhu等[10]提出的循环一致性生成对抗网络(cycle-consistent generative adversarial network, CycleGAN)模型,适用于两种不同风格语音域之间的转换。CycleGAN通过添加循环一致性损失函数,有效地解决了缺少成对的训练语音的问题。为进一步提高CycleGAN生成语音的质量,通过改进CycleGAN的生成器网络结构(2-1-2D CNN)提出一种基于改进CycleGAN的语音增强模型,即CycleGAN-2-1-2D模型。CycleGAN-2-1-2D结合了1D-CNN和2D-CNN的优势,能更好地捕捉特征的动态变化和局部特征的细节。
1 基本原理
1.1 生成对抗网络GAN
GAN的网络结构主要包括生成器和鉴别器,生成器的任务是模仿X域样本并生成翻译数据,鉴别器的任务是将这些生成的翻译数据与X域样本进行区分[11]。随着生成器与鉴别器不断地对抗训练,生成器生成的翻译数据便会获得与X域样本越来越相似的风格,鉴别器判别能力也会随着不断提高,最终使得生成器与鉴别器达到一种平稳态。该过程目标函数如式(1)所示。
Ez~p(z)[log2(1-D(G(z)))]
(1)
式中:x为X域的语音样本;z为随机噪声,其同时作为生成器的输入;pdata(x)为X域的概率分布;p(z)为随机噪声的概率分布;G为生成器参与的z→x映射过程中的映射函数;G(z)为生成器生成的翻译语音;D为鉴别器的判别函数;D(G(z))为鉴别器判定翻译语音为X域样本的概率;D(x)为鉴别器判定x是X域样本的概率;E为数学期望;~表示服从关系。
1.2 循环一致性生成对抗网络CycleGAN
CycleGAN是在GAN的基础上发展来的,用于训练不成对的数据集,CycleGAN模型训练原理如图1所示。CycleGAN由生成器、逆生成器、鉴别器1和鉴别器2组成。CycleGAN的前向循环过程中,生成器将X域的样本x映射为Y域的y′,逆生成器将Y域的样本y′映射为X域的x′。CycleGAN的后向循环过程中,逆生成器将Y域的样本y映射为X域的x′,生成器将X域的样本x′映射为Y域的y′。鉴别器1用于判断y′是否为Y域的样本,鉴别器2用于判断x′是否为X域的样本。
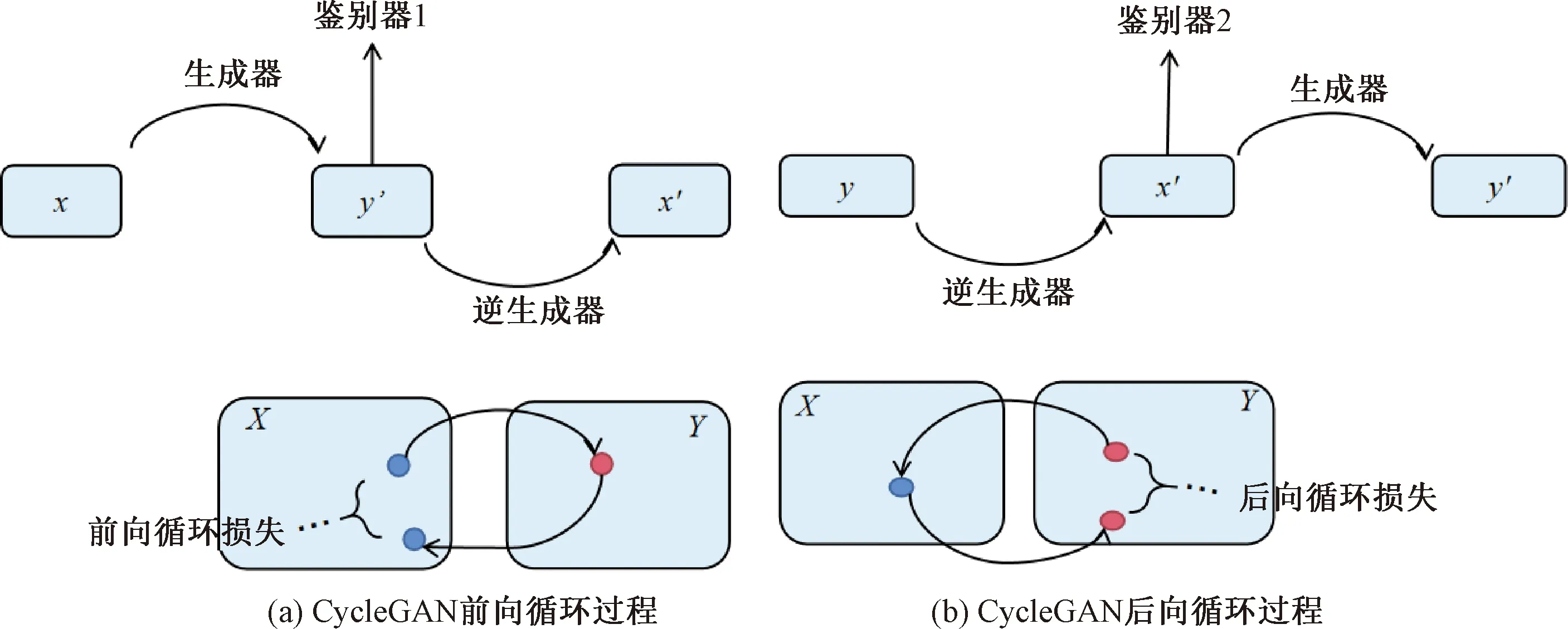
图1 CycleGAN原理图

Ex~pdata(x)[log2(1-Dy(G(x)))]
(2)
(3)
式中:pdata(y)为Y域的概率分布;F为逆生成器参与的y→x映射过程中的映射函数;G(x)为X域样本x输入到生成器所生成的与Y域语音相似的翻译语音;F(y)为Y域样本y输入到逆生成器生成的与X域语音相似的翻译语音;Dy为鉴别器1的判别函数;Dy(G(x))为鉴别器1判定生成器生成的语音G(x)属于Y域的概率;Dx为鉴别器2的判别函数;Dx(F(y))为鉴别器2判定逆生成器生成的语音F(y)属于X域的概率。
Ey~pdata(y)[‖G(F(y))-y‖]
(4)
Ex~pdata(x)[‖G(x)-x‖]
(5)
结合4个损失函数,总体损失函数如式(6)所示。
(6)
式中:λcyc为用于控制循环一致损失函数相对重要性的常数;λid为用于控制标识映射损失函数相对重要性的常数。
最后,两个生成器按式(7)进行求解。
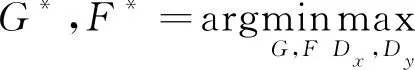
(7)
循环生成对抗网络的语音增强可以通过训练两个具有特殊内部结构的自动编码器来实现上述循环对抗生成网络,即加噪语音和纯净语音可以通过中间表示层映射到自身。这种设置也可以看作是生成对抗自动编码器的一种特殊情况,它使用对抗损失来训练瓶颈层以匹配任何目标分布。
2 改进CycleGAN的语音增强模型
2.1 损失函数
(8)
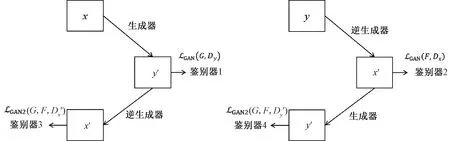
图2 CycleGAN模型的两次对抗性损失
2.2 2-1-2D CNN生成器
1D-CNN生成器结构由降采样层、残差层和升采样层组成,在保留时间结构的同时捕获帧与帧之间的特征关系以及特征方向,因此1D-CNN更适合捕捉动态变化。但1D-CNN中的降采样和升采样会损失部分采样特征结构,导致语音增强效果较差。相比之下,2D-CNN将转换后的区域限制为局部,更适合在转换特征的同时更清晰地保留原始语音特征,从而实现良好的语音增强效果。
为了兼顾1D-CNN和2D-CNN的优势,本文使用了2-1-2D CNN的网络架构。在该网络中,将2D-CNN用于降采样和升采样,并将1D-CNN用于主要转换过程。为了调整通道尺寸,在重塑特征图之前或之后应用1×1卷积。生成器结构如图3所示。由图3可知,1D-CNN、2D-CNN和2-1-2D CNN输入特征的尺寸由Q×T×1表示,其中:r为降采样率和升采样率;c为残差层的固有尺寸;Q为特征维数;T为序列长度。
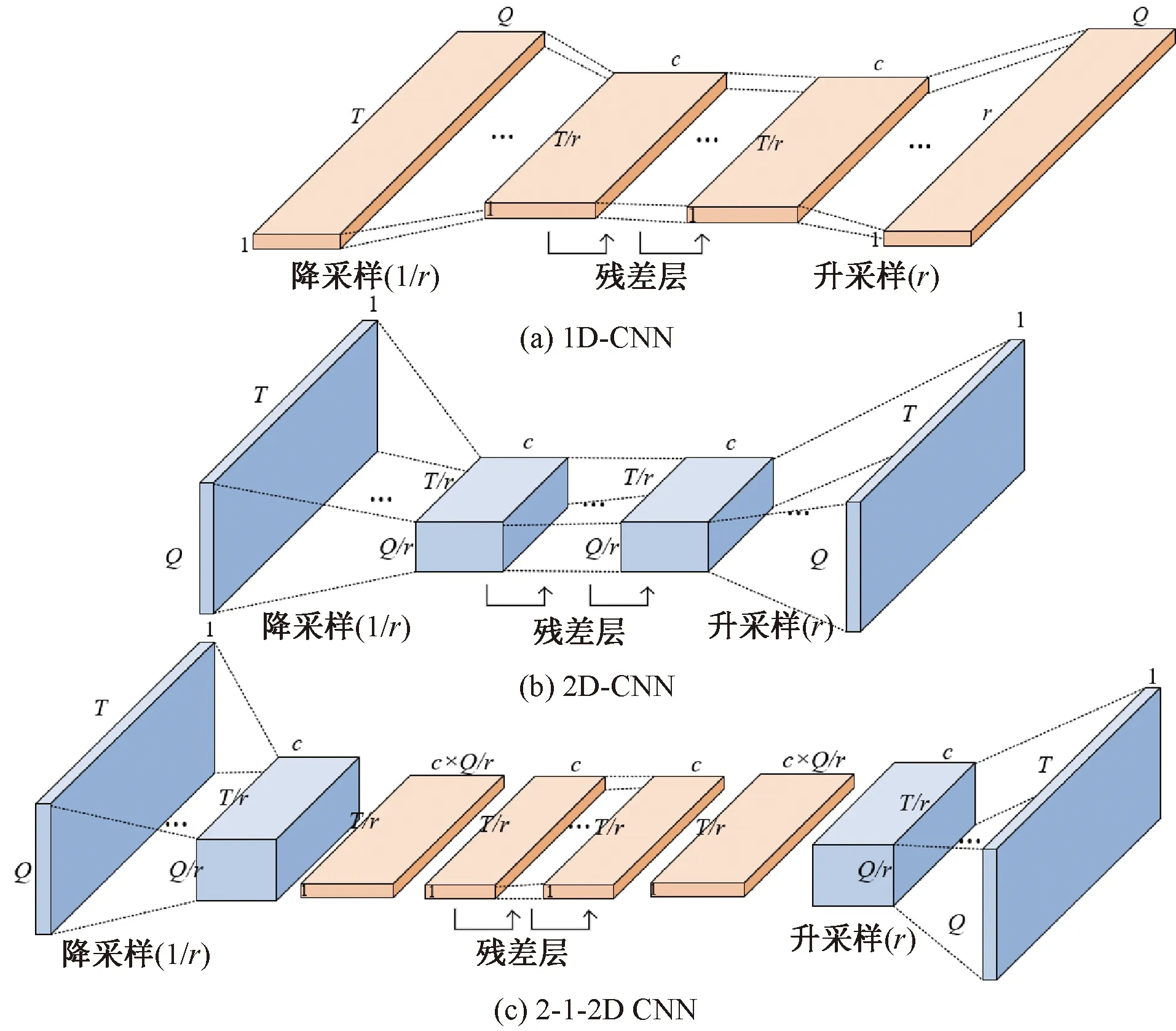
图3 生成器结构
2.3 PatchGAN鉴别器
FullGAN使用2D-CNN[12]作为鉴别器,以专注于二维结构,更准确地说,在最后一层使用了一个完全连接的层来确定考虑输入的整体结构的真实性。但最近在计算机视觉中的研究[12]表明,鉴别器的宽范围接受区域需要更多的参数,这使得训练时间大大加长。受此启发,使用PatchGAN[13]取代了FullGAN。两种鉴别器结构如图4所示。
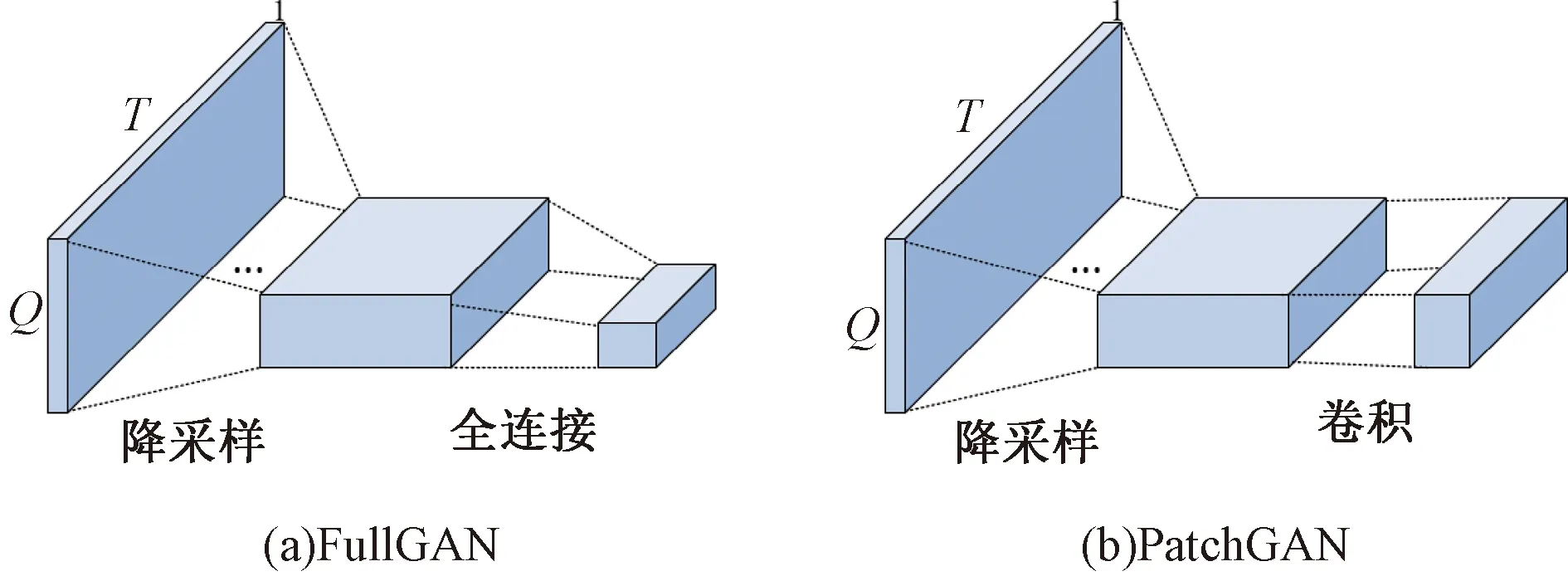
图4 鉴别器结构
PatchGAN在最后一层使用了卷积网络,该网络用于捕获特征统计信息,输出为m×m的矩阵,将矩阵中的每一个元素求和取均值,最终影响语音的判别结果。使用PatchGAN结构的鉴别器需要较少的参数,在大大缩短训练时间的同时也能有效捕捉语音的关键特征,使生成的语音保持高清晰度。
3 CycleGAN-2-1-2D模型的语音增强方案
CycleGAN-2-1-2D模型的语音增强方案是将带噪语音转变成类似于纯净语音风格的去噪语音,训练出一个智能的语音增强模型。该增强方案的具体实施分为数据集准备阶段、训练模型阶段、测试模型阶段。
3.1 数据集准备阶段
用LibriTTS语料库[14]作为数据集,该语料库包含以24 kHz采样率阅读英语语音约585 h的语音样本。3种噪声的类型设为机舱噪声、工厂车间噪声1和工厂车间噪声2。由于CycleGAN-2-1-2D网络的训练时间较长,设置机舱噪声、工厂车间噪声1和工厂车间噪声2分别对应的信噪比(SN/R)为5、10和15 dB。
从LibriTTS语料库中分别选取男/女性语音各N个样本,其中,N/4个样本加噪后作为训练集A,N/4个样本作为训练集B,对N/2个样本加噪后作为测试集。其中N应尽量大,以满足CycleGAN-2-1-2D模型的训练需求。
3.2 CycleGAN-2-1-2D模型训练阶段
训练集A={a1,a2,…,aN/4}作为CycleGAN-2-1-2D模型的加噪语音域,训练集B={b1,b2,…,bN/4}作为CycleGAN-2-1-2D模型的纯净语音域。将训练集A={a1,a2,…,aN/4}和B={b1,b2,…,bN/4}置入CycleGAN-2-1-2D模型中进行训练学习,训练过程如图5所示。设置每迭代1 000次保存1次模型。
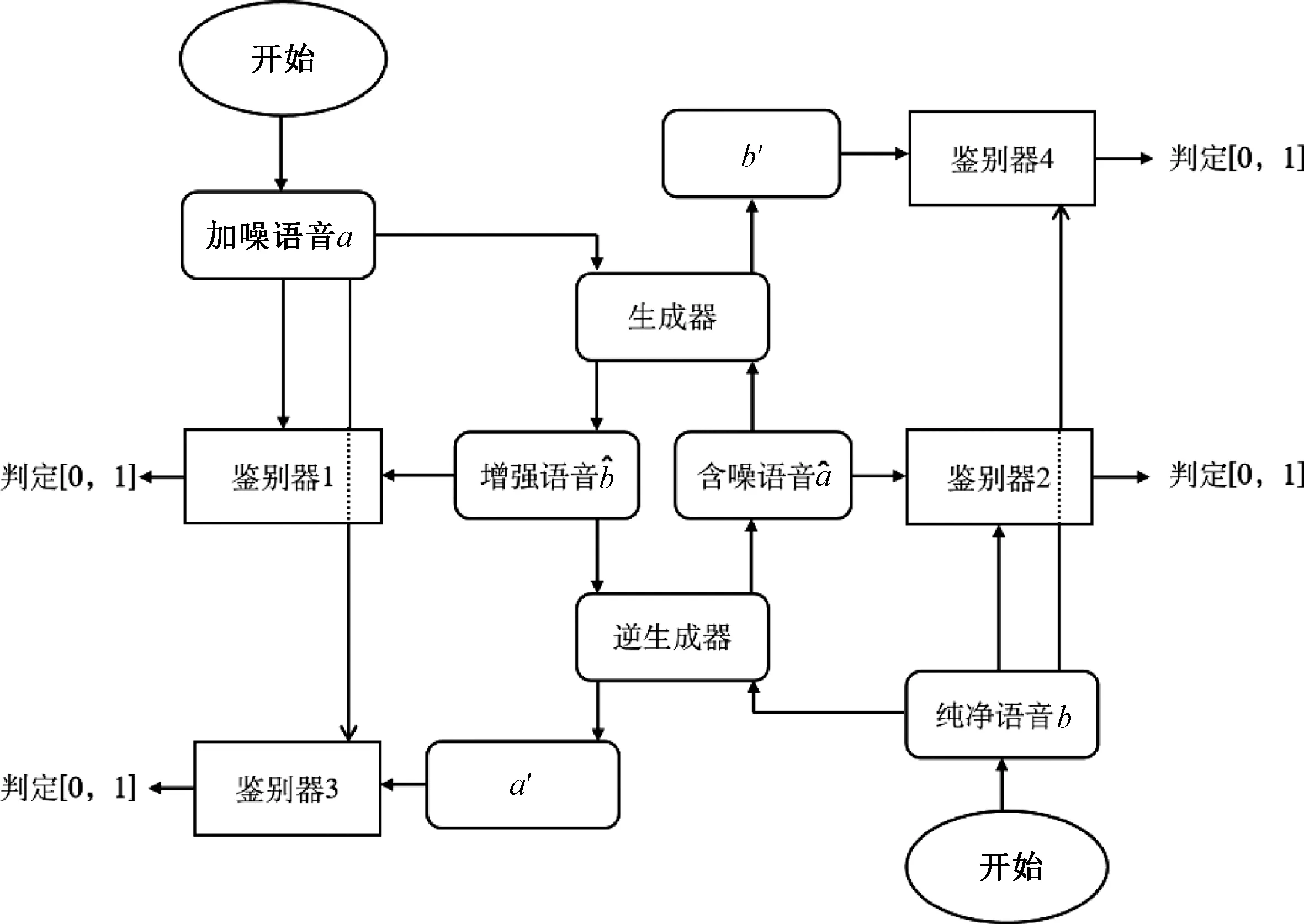
图5 基于CycleGAN-2-1-2D的语音增强模型的训练过程
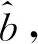
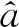
鉴别器与生成器间随着迭代次数的增加不断博弈,使学习结果和学习目标之间的差异不断减少。生成训练模型后,把测试样本(含噪语音)输入到最终的生成器中,以检验增强效果。
3.3 测试模型阶段
从LibriTTS语料库中随机抽取N/2条语音加噪作为测试集,将测试集输入到训练过的CycleGAN-2-1-2D模型后得到增强语音。经CycleGAN-2-1-2D模型增强后的语音长度会发生变化,与纯净语音长度不相同。所以采用无参照的语音评估方式,即MOSNet神经网络模型[15]来预估语音的平均意见得分。MOSNet是基于深度学习的语音质量评估模型,测量语音自然度和相似度的能力很强,利用MOSNet神经网络模型评估增强语音的平均意见得分,测试过程如图6所示。

图6 基于CycleGAN-2-1-2D的语音增强模型的测试过程
4 试验结果及分析
4.1 参数设置
残差层的特点是易优化,其内部的残差块通过跳跃连接的方式将信息传递到网络的更深层,在不增加计算复杂度的条件下解决梯度消失的问题,同时也加快了神经网络的收敛速度。卷积核是带着一组固定权重的神经元,可以用来提取特定的特征,每个卷积核的参数通过反向传播算法优化得到。2-1-2D CNN生成器由2层降采样层、6层相同结构的残差层、1-2D转换层、2-1D转换层、2层升采样层构成,具体的结构参数如表1所示。PatchGAN鉴别器由4层降采样层和2D卷积层构成,其结构参数如表2所示。

表1 2-1-2D CNN生成器结构参数
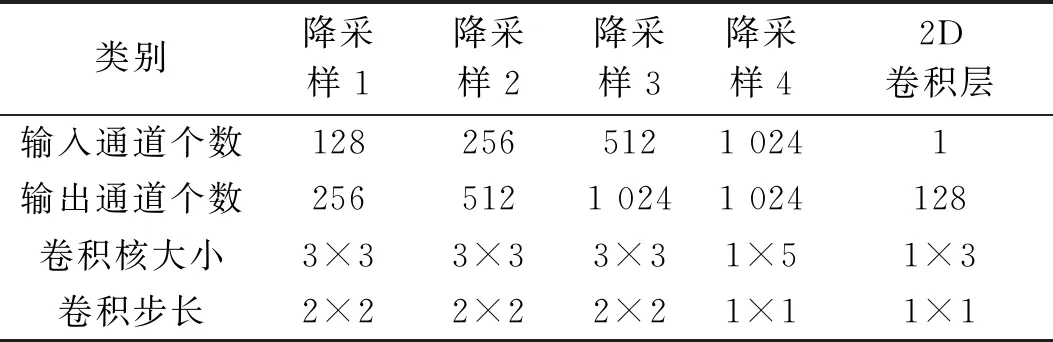
表2 PatchGAN的结构参数
4.2 试验结果
设置CycleGAN-2D和NMF的语音增强模型作为CycleGAN-2-1-2D模型的对照试验,分别对3种模型进行试验,试验结果如表3所示。
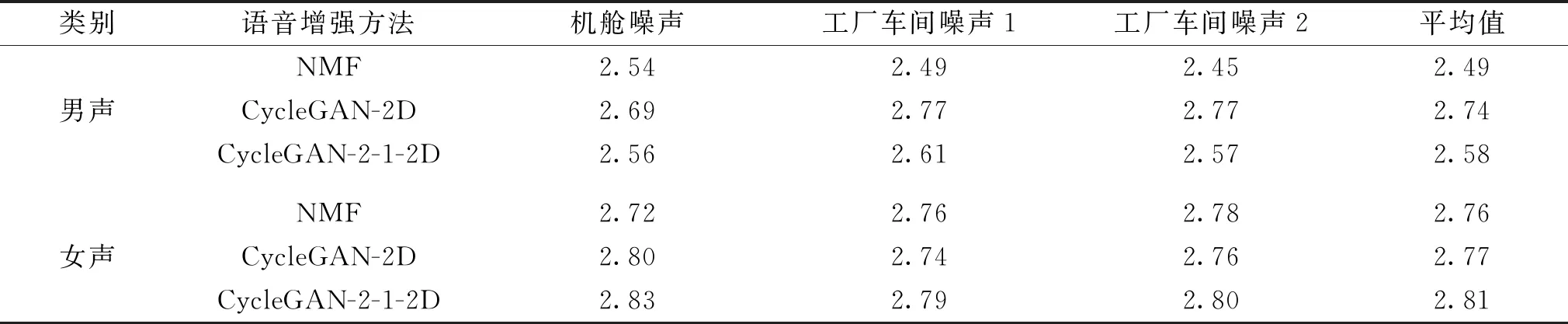
表3 3种不同语音增强模型的MOSNet评估结果
由表3可知:对3种噪音条件下的男性语音进行增强时,CycleGAN-2-1-2D模型的语音增强效果皆优于NMF模型,证实了CycleGAN-2-1-2D模型中的2D-CNN结构能较为完整地保留语音特征的细节,实现良好的训练效果;对3种噪音条件下的女性语音进行增强时,CycleGAN-2-1-2D模型的语音增强效果皆优于NMF和CycleGAN-2D模型。这由于相对男声而言,女声的频率要高且动态变化更大,CycleGAN-2-1-2D模型中的1D-CNN结构更适合捕捉特征的动态变化,因此CycleGAN-2-1-2D模型对女声处理能达到更理想的效果。综上所述,CycleGAN-2-1-2D模型既具有2D-CNN擅长捕获局部特征细节的特点,又结合了1D-CNN对动态变化敏感的特点,在解决成对数据集缺失的问题的同时,进一步增强了模型的语音增强效果。
5 结 语
从深度学习角度对语音增强机制进行研究,通过将1D-CNN和2D-CNN结构引入到CycleGAN-2-1-2D生成器,使得CycleGAN-2-1-2D生成器更加关注语音转换的特征细节和动态变化,其中CycleGAN-2-1-2D模型中的PatchGAN鉴别器也可以大大缩短训练时长。试验结果表明:在原始数据十分有限的情况下,CycleGAN-2-1-2D模型能有效地学习样本的多维度特征,实现语音的高效增强,更适用于实际的应用场景。在下一步的研究工作中,将对CycleGAN-2-1-2D模型的结构参数进行合理化调整,对神经网络学习语音增强过程的靶点精细化,有望进一步提高语音增强效果。
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
中学生数理化(高中版.高一使用)(2021年2期)2021-03-19
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
劳动保护(2019年3期)2019-05-16
小说界(2018年5期)2018-11-26
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
客车技术与研究(2014年6期)2014-02-28
