
基于DeepLabV3+的骨料图像自动分割算法
2022-11-10 02:36张社荣欧阳乐颖王枭华
水利水电科技进展 2022年6期
张社荣,欧阳乐颖,王 超,王枭华
(天津大学水利工程仿真与安全国家重点试验室,天津 300350)
骨料质量是影响混凝土质量的关键因素,骨料的级配越合理,越能够降低孔隙率,从而降低水泥用量,达到减少混凝土干缩、降低水化热的目的[1]。当前常用的在料堆上均匀取样、用筛分法检验级配的方法耗时较长,不能在骨料生产过程中及时反馈数据。利用传统图像分割方法进行骨料目标分割并计算粒径大小,其提取的特征较为低级,分割结果缺少高级语义信息,骨料堆积等复杂场景下算法的表现较差[2-4]。随着深度学习方法的飞速发展,在图像语义分割方面出现了许多优秀的网络,如全卷积神经网络(FCN)[5]、U-Net网络[6]、DeepLab系列网络[7-9]等。FCN丢弃了以往卷积神经网络的全连接层,以全卷积层代替,再通过上采样得到与原图大小相等的分割图,并通过跳层连接优化输出,但该网络的分割效果在细节方面不太理想,且对像素分类时未充分考虑像素之间的关系,模型训练速度也相对较慢;U-Net网络采用编码器-解码器形成U型架构,并采用叠操作进行跳层连接,该网络在医学图像分割领域以及小样本数据集上取得了较好的效果,虽然网络轻量训练速度较快,但并不适用于室内外场景语义分割;DeepLab系列网络最早由Chen等[7]在2015年提出,基于VGG16,经过不断的优化与改进,并在2018年提出了DeepLabV3+[9],采用了Encoder-Decoder体系,并强化了Decoder,使模型整体在语义分割的边缘能够取得良好效果。除了DeepLabV3+外,上述其他算法均未对解码器模块进行有效利用或仅仅使用了单一的对称结构,丢失特征信息问题严重,导致分割结果粗糙。
语义分割常常应用于工程施工过程中的表面缺陷检测、砂石图像分割、裂缝识别等方面。Xue等[10]对FCN进行改进,并将改进后的模型应用于隧道衬砌缺陷的自动分类与检测,检测率为94.4%,准确率为86.6%,速度达到0.266 s;朱大庆等[2]提出了一种两阶段深度学习网络模型,实现了砂石图像的分割,并使用欧几里得距离公式计算砂石目标的最长径,但阶段1的骨料分割效果较差,粘连骨料较多,过于依赖阶段2的分离模型;李思琦等[11]基于改进的生成对抗网络进行建筑垃圾数据集扩充,再利用DeepLab模型进行参数迁移学习,建立建筑垃圾语义分割模型,试验得出的平均交并比为75.32%,基本满足建筑垃圾识别要求;王超等[12]融合轻量化卷积神经网络以及FCN搭建裂缝识别模型,并对某输水渡槽结构表面的裂缝宽度进行计算。
综上所述,将深度学习算法应用在工程领域能够得到不错的检测效果,但是仍然存在模型体量过大、目标边缘的细节特征提取较差导致边缘分割效果不好等问题。针对上述问题,本文旨在利用优化后的DeepLabV3+网络建立骨料图像自动分割模型(以下简称“本文模型”),为实现水利工程施工中骨料粒径大小的快速准确查验提供参考。
1 骨料图像收集及预处理
本文收集了150张某水利工程不同条件下的骨料图片进行图像预处理,利用模型完成对骨料轮廓特征的提取,分割各个骨料,针对骨料图像特点对原始DeepLabV3+模型在激活函数、权重分配以及骨干网络3个方面进行优化,以实现在减小模型体量、提高训练速度的同时提高模型精度的目的,并与FCN、U-Net进行对比,以验证本文模型的可行性,模型构建流程如图1所示。
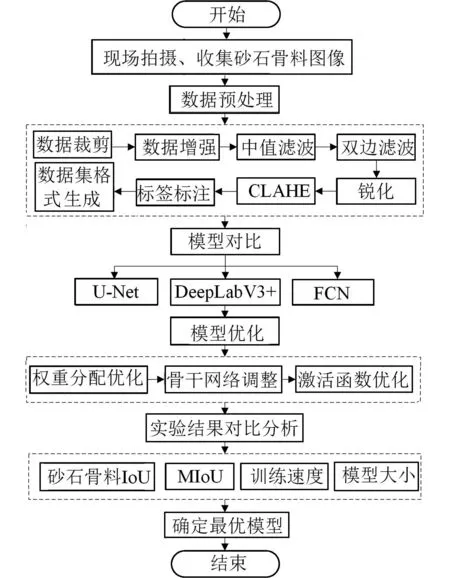
图1 模型构建流程
1.1 数据收集
在某水利工程现场进行拍照采集试验图像,为保证试验数据能够反应最真实的数据环境,分别选择在晴天、阴天等不同天气及光照条件下进行图像拍摄,并且拍摄的砂石色泽、尺寸均不相同。数据采集设备为Canon 3D mark Ⅲ,拍摄距离为50~120 cm,拍摄角度与拍摄平面间的夹角均为90°,图像分辨率为3 840×5 760像素。为使图像的尺寸适合DeepLabV3+网络的输入尺寸,将收集到的数据统一剪裁至分辨率为512×512像素。由于数据集本身较小,采用图像旋转、翻转、缩放等数据增强方法来扩充数据集,因为骨料在图片中目标众多且聚集紧凑,因此本试验收集图片数量相对较少,共150张骨料图像,按9∶1的比例随机拆分成训练集和验证集。
1.2 数据预处理
由于骨料图像具有较多噪声,部分图像稍有模糊,部分由于曝光导致骨料边缘不够清晰。因此,试验采用中值滤波以消除孤立噪声,利用双边滤波在保持图像边缘清晰的同时,进行降噪平滑[13-14],通过图像锐化增强图像边缘、突出骨料的轮廓,最后利用限制对比度的自适应直方图均衡法(CLAHE)在抑制图像噪声的前提下,增强图像对比度。图像处理前后对比如图2(a)~(e)所示。将预处理之后的图像使用Labelme进行图像分割标签标注,而后参照PASCAL VOC2012数据集格式进行数据集制作以满足训练要求,标注之后的图像如图2(f)所示。

图2 图像预处理
2 模型构建
2.1 DeepLabV3+网络
DeepLabV3+网络可看作Encoder-Decoder编解码器结构[15],首先通过具有良好图像级分类能力的主干特征提取网络,再经过空洞空间卷积金字塔池化(atrous spatial pyramid pooling,ASPP),ASPP包含1个大小为1×1、采样率为0的卷积核,3个大小为3×3、采样率分别为6、12、18的膨胀卷积核,并联全局平均池化(global average pooling,GAP)以提取多尺度语义信息。解码器部分融合了从主干网络中提取的特征图、经过ASPP模块以及4倍上采样之后的特征图以确保同时具备细节特征和语义特征,最后再进行4倍上采样输出最终分割图片。
2.2 主干特征提取网络
MobileNetV2作为典型的轻量型网络[16],在含有的深度可分离卷积的基础上通过反残差单元结构[17],使网络在较少运算量的情况下具备较高精度,并引入线性瓶颈结构,即将单元结构的最后一个ReLU激活函数替换为线性激活函数,从而保存低维空间中的特征,防止神经元坏死。MobileNetV2单元结构与Resnet压缩、卷积、扩张的顺序相反,MobileNetV2扩张、卷积、压缩的顺序计算量较小,分别为1×1卷积、3×3空间卷积、1×1卷积,首先通过提升通道数来增加特征的提取,再改用深度卷积,最后进行降维操作,由于最后一层激活函数ReLU6[16]会破坏原有特征,故使用线性函数进行替换。采用MobileNetV2作为骨料图像自动分割算法中的主干特征提取网络,能够使模型满足嵌入系统进行快速检测的需求。
2.3 权重优化
骨料图像自动分割模型训练过程中,由于骨料与背景信息之间像素占比差距过大,导致训练网络的原有权重无法有效地训练模型识别像素占比过小的背景像素。因此,本文通过计算试验数据集中各类标签的像素占比,获得训练网络中各类标签的训练损失权重:

(1)
式中:wj为第j类标签的训练损失权重;i为试验数据集中的图像编号;Nij为第i张图像中第j类标签的像素数。本文通过式(1)计算结果得到背景像素与骨料像素权重比为4∶1,将计算权重代替原有单一权重,从而消除标签像素占比差异带来的训练效果差的问题。
2.4 Swish激活函数
Swish函数可视为介于线性函数与ReLU之间的平滑函数,相比于ReLU,该函数在神经网络中能够实现更高的测试准确率,且收敛速度较快、非单调、函数以及其一阶导数均具有平滑特性的特点。DeepLabV3+使用的激活函数ReLU具有当输入值小于0时权重产生无法更新的缺陷。因此,基于骨料图像数据特点,测试对比多种激活函数在MobileNetV2作为骨干网络的DeepLabV3+网络中训练1 000步时总损失(total_loss)的收敛效果(图3),Swish激活函数配合批标准化(batch normalization,BN)层(Swish+BN)在激活函数中表现效果最好,比ReLU+BN的损失小0.0174,因此最终选择Swish+BN。
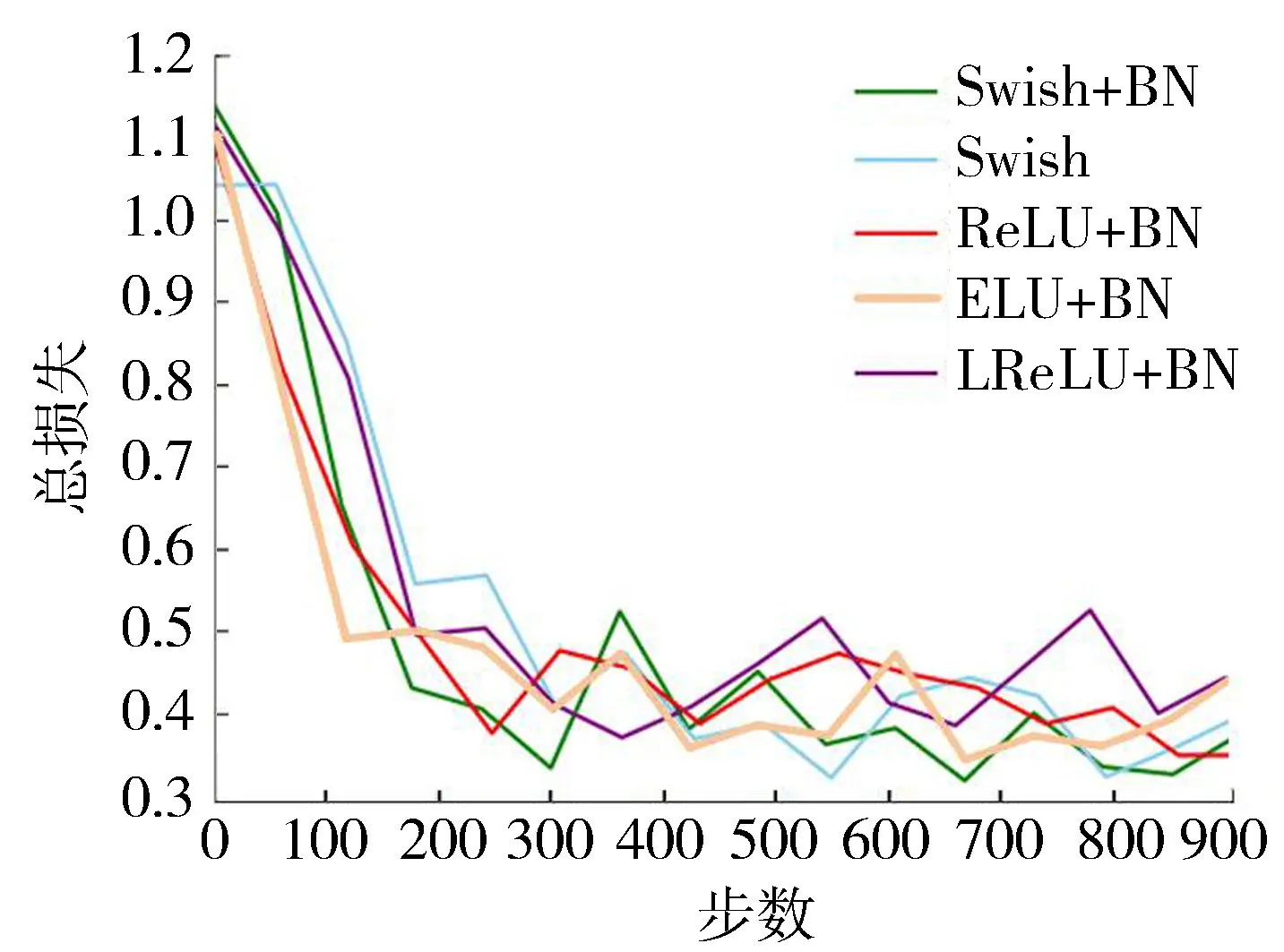
图3 多种激活函数训练收敛效果
试验使用5种激活函数进行训练,得到的训练结果如表1所示,当使用Swish+BN作为激活函数时,权重优化后的DeepLabV3+网络训练出来的模型在分割骨料时有最好的表现效果。
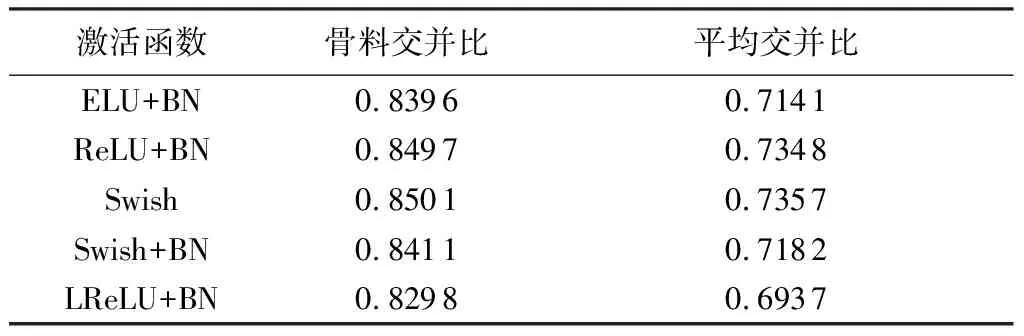
表1 不同激活函数的训练结果对比
3 试验过程与结果分析
3.1 试验环境
骨料图像自动分割试验所使用的操作系统为Windows 10,处理器为Intel(R)Core(TM)i7-6700 CPU,内存16GB,显卡为NVIDIA GeForce GT 730,版本为461.92,CUDA采用9.0版本,cuDNN版本为6.0。试验中涉及网络均使用TensorFlow深度学习框架,程序在PyCharm中使用Python3.6进行编写。
3.2 参数设置
将预处理后的骨料数据集进行试验,选择MobileNetV2作为主干特征提取网络,Swish作为激活函数,并将骨料与背景的权重比按照式(1)计算,最终设置为1∶4,优化器使用随机梯度下降(SGD),权重衰减为0.000 04,批量大小为12,迭代次数为30 000,学习策略使用Poly,初始学习率为0.000 1,动量为0.9。
3.3 评价指标
为了衡量网络性能,采用交并比(intersection over union,IoU)和平均交并比(mean intersection over union,MIoU)作为评价指标对试验结果进行对比分析。交并比表示该模型对某一标签真实值与预测值两个集合的交集与并集之比[18]。平均交并比常常被用作准确度评价的标准度量,即真实值集合与预测值集合的交集与并集之比。
3.4 对比分析
3.4.1不同主干特征网络对比分析
为确定最适合DeepLabV3+的主干特征网络,试验分别使用MobileNetV2、Xception、Resnet101作为主干特征网络进行训练,其损失变化曲线如图4所示。由图可以看出,与MobileNetV2相比,使用Resnet101和Xception的模型总损失的收敛速度较慢;使用MobileNetV2的模型在训练1万步时总损失即可达到0.4,并开始逐渐趋于稳定,而使用Resnet101和Xception的模型则需要在1万步训练后损失才到0.5,且即使开始趋于稳定,仍偶尔有较大震荡出现,训练最终总损失也较使用MobileNetV2的模型稍高。综上所述,使用MobileNetV2作为主干特征网络,收敛速度快,精度较高。

图4 不同主干特征网络训练损失变化
试验使用3种不同的主干特征网络进行训练,得到的训练结果如表2所示,当使用MobileNetV2作为主干特征网络时,DeepLabV3+训练出来的模型在分割骨料时表现最好,其骨料交并比能够达到0.861 5,平均交并比达到0.757 6。
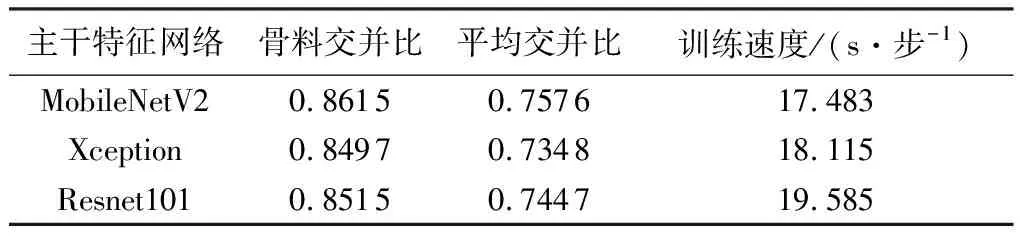
表2 不同主干特征网络的训练结果对比
3.4.2不同深度学习方法对比分析
为验证本文模型的有效性,在相同试验条件下对目前常用的深度学习语义分割方法U-Net、DeepLabV3+、FCN进行对比试验,训练得到的部分图像对比结果如图5所示,计算得到的评价指标的交并比及平均交并比如表3所示。由图5可以看出,使用同样的数据集进行训练,U-Net训练出的模型识别准确率低于其他网络,FCN训练出的模型对于骨料的边缘细节识别效果比DeepLabV3+、本文模型要差,DeepLabV3+以及本文模型识别效果均较为突出,且都能够识别出GroundTruth中存在的部分未作标记的骨料,但DeepLabV3+训练出的模型对于细节的分割稍逊于本文模型。

图5 不同语义分割方法训练图像对比
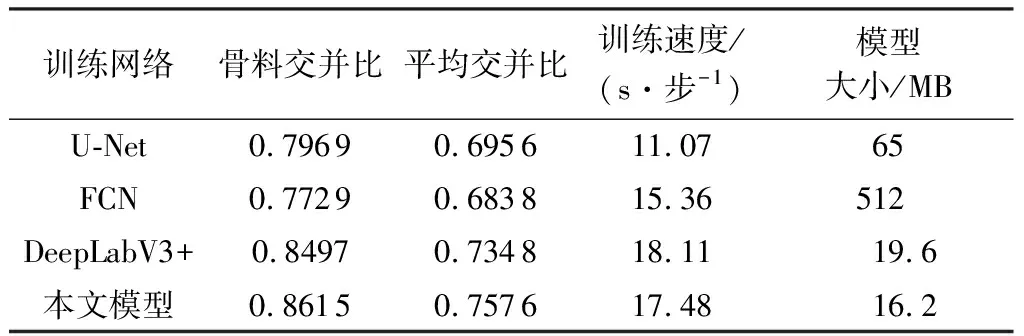
表3 不同语义分割方法的训练结果对比
由表3可以看出,U-Net模型虽然训练速度较快,且模型本身具有结构简单、易于定制的优点,但其骨料交并比较低,为0.796 9,且模型大小比DeepLabV3+大了45.4MB,不适用于嵌入系统进行骨料图像快速分割;FCN模型虽然训练速度比DeepLabV3+和本文模型快,但是其骨料交并比较低,为0.772 9,且模型大小过大,也不适用于骨料图像分割;DeepLabV3+相比于U-Net、FCN的骨料交并比、平均交并比都较高,但都较本文模型稍低,且模型大小比本文模型大3.4 MB,训练速度比本文模型慢0.63 s/步;经对比,本文模型骨料交并比达到0.861 5,平均交并比达到0.757 6,明显优于其他模型,且模型大小也最小,仅为16.2 MB,内存占用空间很小,因此处理骨料图像分割任务的性能最佳。
3.4.3粒径计算结果对比分析
为进一步验证模型的准确性,以某水利工程现场拍摄骨料为例,采用本文模型分割后计算得到的粒径级配分布与传统筛分法得到的粒径级配分布进行对比,如表4所示。使用Python-OpenCV,通过Python脚本,以最小外接矩形的短边长度等效为骨料筛分粒径大小,对相机进行标定以确定其标定系数。将骨料颗粒近似为椭球体,以各粒径级别累计体积比计算级配,最终统计结果如表4所示,可以看出,使用本文模型得到的粒径计算结果的平均误差不超过20%,基本满足工程要求。

表4 本文模型与传统筛分法粒径计算结果对比
对于模型的实际测试速度方面,为了提高模型运行效率,在导入3 840×5 760像素分辨率的图片时,首先利用Python脚本将较大的图片自动分割为1 024×1 024像素分辨率的图像集,再分别导入模型中进行分割,平均每张图片分割时间为4.54 s,能够快速分割骨料图像,较传统筛分法筛分骨料效率高。
4 结 论
a.基于优化DeepLabV3+网络建立了骨料图像自动分割模型。在针对某水利工程的实验中,骨料交并比达到0.861 5,平均交并比达到0.757 6,相比其他常用语义分割算法模型,在保证较好的模型大小及训练速度的情况下,本文模型具有更好的分割效果。
b.对比多种激活函数在DeepLabV3+网络中的训练效果,发现使用Swish+BN作为激活函数时网络的训练收敛速度最快,同样在1 000步时,Swish+BN函数下网络的总损失具有最小值,收敛效果最好,能够更好地进行骨料特征提取。
c.基于DeepLabV3+网络,使用MobileNetV2作为主干特征网络,选择Swish+BN作为激活函数,并将原始统一权重按照计算出的各标签占比进行重新分配,优化后的网络与原始DeepLabV3+以及使用其他主干特征网络的DeepLabV3+进行对比试验,发现优化后的网络具有更高的平均交并比以及骨料交并比,更适合骨料图像的自动分割。
d.本文模型通过骨料轮廓等特征,对图像进行像素级的分类,准确性较高,基本满足后续骨料粒径级配计算的需要,为实现料场骨料生产质量实时检测、反馈与控制打下应用基础。骨料边缘的特征提取尚存在进一步优化的空间。
猜你喜欢
上海建材(2022年2期)2022-07-28
小哥白尼(军事科学)(2022年2期)2022-05-25
福建交通科技(2022年1期)2022-04-07
水利学报(2022年2期)2022-03-17
广东教育·高中(2022年1期)2022-03-16
河南建材(2021年1期)2021-01-28
红领巾·萌芽(2019年8期)2019-08-27
中国与非洲(法文版)(2017年10期)2017-11-23
中华心脏与心律电子杂志(2017年2期)2017-10-20
中国心血管杂志(2016年4期)2016-09-15
