
基于改进U2-Net与迁移学习的无人机影像堤防裂缝检测
2022-11-10 02:36李怡静程浩东李火坤
水利水电科技进展 2022年6期
李怡静,程浩东,李火坤,王 姣,胡 强
(1.南昌大学工程建设学院,江西 南昌 330036; 2.江西省水利科学院,江西 南昌 330029)
堤防是水利工程中重要的挡水建筑物,是保障经济和社会发展的基础设施之一。堤防在施工和后期运行过程中容易出现开裂的情况,获取裂缝形态可为维护堤防的结构健康提供依据,是保障堤防安全运行的重要措施[1]。
传统的结构裂缝检测主要由人工完成,结果受检测人员的主观影响,且耗时费力,也存在一定的安全隐患,在有通行要求的堤防还会对交通产生影响。因此如何便捷高效且准确地对裂缝进行检测,以便维修人员对裂缝选择最佳的养护策略和维修措施,提高堤防监测和养护的自动化水平,是亟待解决的问题。利用无人机遥感摄影技术可以方便快捷地获取大区域影像数据,再结合图像处理方法从影像中识别和获取裂缝信息,可大幅度提高检测效率[2-3]。
传统的影像裂缝检测利用裂缝和背景的灰度值差异或采用机器学习与数字图像处理方法实现裂缝识别[4-7],这需要人工设定参数,降低了检测的自动化水平和检测方法的普适性,且堤防上存在较多干扰噪声,如光线、杂草、水渍、路面标记和碎片等,会对检测效果产生影响。近年来流行的深度学习方法具有更强的识别能力,利用深度学习方法进行裂缝检测受到了广泛关注。识别裂缝的深度学习方式可分为筛选、检测和提取3类,其中裂缝筛选是对图像中是否含有裂缝进行区分[8];裂缝检测是确定图像中是否含有裂缝,并将裂缝的大致位置或种类标注出来[9];裂缝提取是从复杂的背景中将每个像素分类为裂缝像素或非裂缝像素,从而获取整个裂缝的轮廓,目的是准确提取裂缝并进行特征量化[10-11]。裂缝筛选和检测只能实现裂纹的分类和粗略定位,而裂缝提取能为堤防裂缝评估提供直观和准确的依据。为提高裂缝提取的精度,张紫杉等[12]利用U-Net实现了对高陡边坡裂隙的智能识别;Dung等[13]使用深度卷积网络VGG(visual geometry group network)作为全卷积网络(fully connected network, FCN)的主干对整个编码器-解码器结构进行端到端训练,训练、验证和测试集的综合评价指标和平均精度均可达到约90%;Park等[9]基于YOLOv3-tiny算法,利用结构光原理建立了一套裂缝检测和量化系统;Kumar等[14]基于Mask R-CNN实现了检测和分割不同类型的裂缝,便于对不同种类的裂缝采取有效的预测措施;Zou等[15]在SegNet[16]的编码器-解码器架构基础上构建了DeepCrack模型,使用端到端可训练的卷积神经网络(convolutional neural networks,CNN)来学习裂纹特征,取得了较好的提取结果;Liu等[4]设计了一种路面裂缝检测与分割方法,使用改进的YOLOv3-tiny算法检测图像中的裂缝,使用改进的U-Net对检测图像中的裂缝进行分割,所提出的两阶段式的裂缝检测方法具有较高的精度;Li等[17]提出了一种基于FCN的混凝土损伤检测方法,可以用于检测裂缝、剥落、风化和孔洞4种混凝土损伤;Feng等[18]根据SegNet结构的特点提出了一种大坝表面裂缝检测模型(crack detection on dam surface ,CDDS)用于大坝裂缝的像素级检测,其效果优于SegNet、U-Net和FCN。
上述裂缝检测模型通过基于图像分类模型的主干,例如VGG、ResNet、DenseNet等,来解决裂缝区域的筛选和提取问题,但这些模型主干不是专门为了语义分割而提出的,因此模型对局部细节与全局对比度关注不够,在裂缝检测中无法获得满意的语义分割结果。U2-Net[19]是一种语义分割模型,其特有的残差块(residual U-blocks,RSU)具有捕捉多尺度信息的能力,在一定程度上可以弥补常用的语义分割模型对局部细节与全局对比度关注不够的问题,且不依赖于现存的任何分类网络主干。堤防具有距离长、面积大的特点,利用无人机采集影像检测裂缝可提高工作效率。针对无人机影像中的堤防裂缝特征不明显和背景存在大量噪声的问题,本文使用扩张卷积(atrous convolution,AC)和深度可分离卷积(depthwise separable convolutions,DSC)对U2-Net原有的RSU进行改进,提出了新的残差块ADS-RSU,基于ADS-RSU构建了语义分割模型U2-ADSNet,通过迁移学习对模型进行训练后采用切片预测实现了对大尺度无人机影像中的堤防裂缝的像素级检测。
1 语义分割模型U2-ADSNet
1.1 ADS-RSU
1.1.1DSC与AC
DSC的思想于2014年提出[20],经过改进之后被应用于Xception和 MobileNets等深度学习模型中。普通卷积同时提取特征图的区域信息和通道信息,DSC将区域信息和通道信息分开进行学习,这种方式有助于模型在区域和通道之间建立新的连接,更好地学习堤防裂缝特征,提高裂缝检测性能。
为减弱下采样带来的细节特征丢失,本文利用AC提高语义分割模型的准确性,可以扩大卷积时的感受野,又不会降低分辨率,从而提升语义分割的精度。
1.1.2改进的ADS-RSU
为减弱下采样带来的细节特征丢失,提升对裂缝分割的效果,同时降低训练成本,在RSU的基础上,ADS-RSU利用DSC替换各层的普通卷积,并在DSC的第一步深度卷积使用AC代替。图1为ADS-RSU内部改进细节。
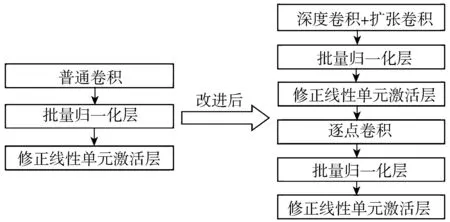
图1 ADS-RSU内部改进示意图
1.2 U2-ADSNet模型的构建
U2-Net是2020年国际计算机视觉与模式识别会议(CVPR)提出用于显著对象检测的深度模型结构,其特有的RSU可以获取图像不同尺度的信息,在增加网络深度的同时不显著增加计算复杂度。该模型对轮廓的提取效果表现优秀,其外层主要结构类似U-Net,通过底层的RSU来提取多尺度特征。
受此模型结构的启发,本文以ADS-RSU为基础架构构建了语义分割模型U2-ADSNet。图2为 U2-ADSNet模型构架,为两级镶嵌的U形结构,外层为大U形结构,每个立方体代表一层,左侧为编码层,右侧为解码层,由ADS-RSU填充,一共有11层。网络结构分为编码模块(En_1~En_6)、解码模块(De_1~De_5)和特征融合模块(Side_1~Side_6)3个主要部分。网络体系结构建立在ADS-RSU上,不需要任何预训练主干即可适应不同的应用环境。此外U2-ADSNet在具有较深的网络架构的同时可以保持较低的训练成本。
2 无人机影像的堤防裂缝检测
无人机可以便捷地获取大范围堤防影像,本文基于U2-ADSNet实现了无人机影像中的堤防裂缝快速检测。
无人机影像的堤防裂缝检测流程(图3)如下:基于U2-ADSNet,通过制作裂缝分割数据集和迁移学习,利用裂缝开源数据集和少量堤防裂缝样本,实现无人机影像中堤防裂缝的特征学习。最后,在预测阶段采用切片预测实现大范围的堤防裂缝检测,利用连通区域搜索去除可能的误检。
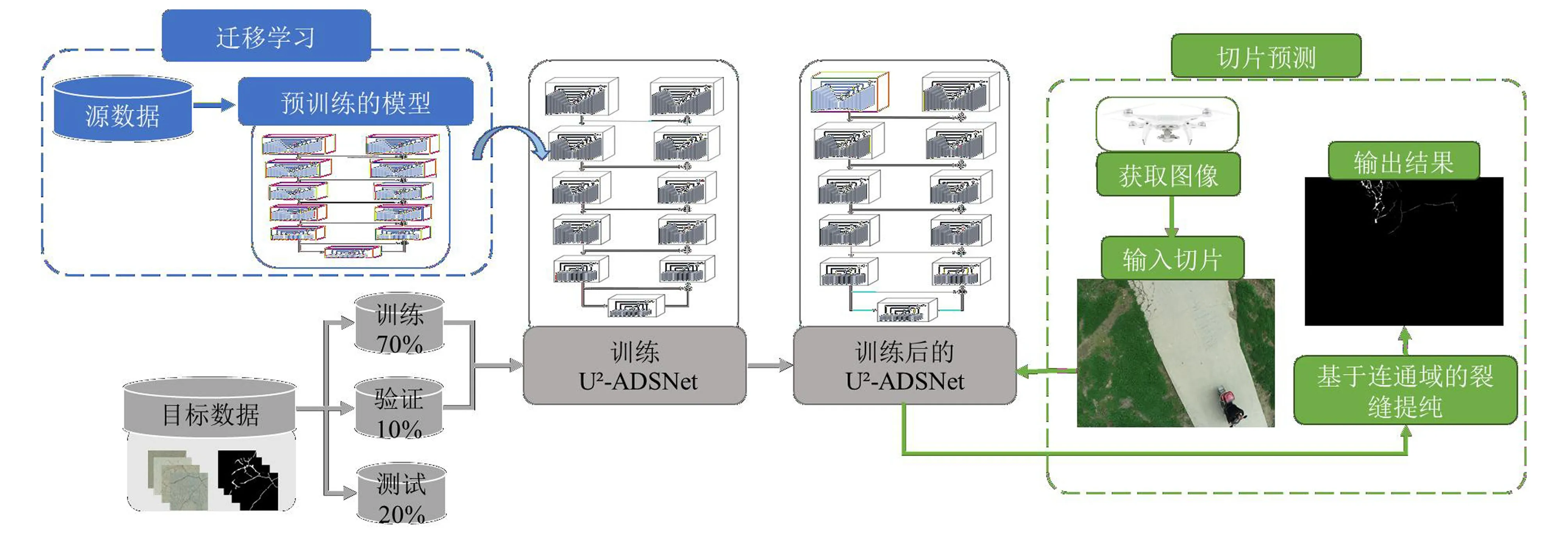
图3 无人机影像堤防裂缝检测流程
2.1 迁移学习
深度学习需要进行大量的样本训练,而人工制作样本数据集效率低下。针对缺乏无人机航拍图裂缝样本的问题,利用迁移学习机制,利用大众摄影图像的公共数据集和少量无人机影像数据进行特征学习,既可以提高检测精度又可大大降低训练成本。
本文采用迁移学习方法中使用最普遍的的模型参数迁移进行深度学习,其主要思想是使目标域共享源域的模型参数[21],实现方法是先利用源数据对模型进行预训练,然后通过对预训练模型共性特征复用的方法对目标数据进行训练,而无需从零开始训练模型,能够加快模型收敛速度,降低训练成本。
2.2 切片预测
由于卷积神经网络计算复杂且运算量大,为了降低训练时硬件负担,训练模型所用的图片尺寸往往较小,但实际应用场景的影像尺寸远大于训练数据集中的图片,而裂缝在图片中占的比例较小,直接用于模型预测,裂纹被网络识别的机会较小,甚至无法识别。为了解决这个问题,本文采用切片预测方式,通过对大尺寸图片进行切片分割,分块送入训练好的模型,自动对影像进行分块预测。图4为切片预测效果,很明显使用了切片预测之后的结果更加精确。

图4 切片预测示意图
在切片之前先按照无人机飞行方向根据影像的重叠部分对堤防影像进行拼接,得到完整的堤防影像。影像拼接采用OpenCV库的Stitcher类。经过大量的试验,得到切片合适的尺寸应接近神经网络训练时实际输入的大小,切片过大则无法检测出裂缝,过小会出现大量干扰。
2.3 基于连通域的裂缝提纯
实际应用场景下环境复杂多变,难免会出现一些模型无法准确识别的特征,预测得到的二值图片含有一定的噪声,采用连通域特征来进行裂缝提纯。
结合裂缝形态特征,4邻域连通会影响裂缝标记的准确性,因此整合了8邻域连通规则进行裂缝提纯。U2-ADSNet预测结果中偶尔会出现白点噪声,其像素基本在1 000以下,均远小于裂缝实际像素。经过试验,设置500~1 000之间的阈值均可过滤掉白点噪声。
3 试验与分析
3.1 试验数据
试验数据集1来源武汉市新洲区一处长江堤坝段实地采集的影像数据,采集设备为大疆精灵4pro,飞行高度20 m,相机型号FC6310R。数据集1包含了一些具有代表性的裂缝类型和复杂背景,样例如图5所示。从无人机影像中手动截取165张227×227像素的图片,标注了所有标签,经过随机旋转和裁剪操作扩展到2 000张,其中裂纹图片和非裂纹图片各1 000张,并随机挑选70%用于训练,10%用于验证,20%用于测试。

图5 数据集1样例
数据集2来自用于混凝土裂缝分类的开源数据集[22],图片为布达佩斯城市大学(METU)的各个校园建筑表面裂缝,包括裂纹图片和非裂纹图片两类,大小为227×227像素,每个类别有2万张图片,总共4万张图片。本文从该开源数据集中随机挑选了420张图片,人工进行了标注,然后随机旋转和裁剪扩展到了4 000张,其中裂纹图片和非裂纹图片各2 000张,部分样本如图6所示。

图6 数据集2样例
3.2 评价指标
本文的裂缝检测属于语义分割中的二分类问题,选用正确率、精确率、召回率和交并比对预测结果进行评估。正确率、精确率、召回率和交并比计算公式分别为
Iacc=(Xtp+Xtn)/(Xtp+Xtn+Xfp+Xfn) (1)
Ipr=Xtp/(Xtp+Xfp)
(2)
Ire=Xtp/(Xtp+Xfn)
(3)
Iou=Xtp/(Xtp+Xfp+Xfn)
(4)
F1=2IprIre/(Ipr+Ire)
(5)
式中:Iacc、Ipr、Ire、Iou分别为正确率、精确率、召回率和交并比;F1为综合评价指标,越接近1说明模型性能越好;Xtp为模型正确分割为“裂缝”的像素数;Xtn为模型正确分割为“非裂缝”的像素数;Xfn为模型错误分割为““非裂缝”的“裂缝”像素数;Xfp为模型错误分割为“裂缝”的“非裂缝”像素数。
3.3 模型对比试验
试验基于PyTorch 1.7.1,计算机CPU为英特尔 i7 10700(32GB RAM),GPU为英伟达RTX4000(8GB)。
FCN、SegNet和U-Net为语义分割领域常用的模型,其中本文试验采用的FCN为FCN16,主干基于VGG16网络,编码部分分别使用了VGG16特征提取部分的第0到第15层、第17到第22层和第24到第29层;SegNet的主干编码部分使用了VGG16特征提取部分的第0到第4层、第5到第9层、第10到第16层、第17到第23层和第24到第30层。DeepCrack为最近提出的一种主要用于路面裂缝检测的模型,该模型在SegNet的基础上构建,融合了SegNet的5层特征。
在数据集1上进行对比试验,所有模型在训练时首先将输入的图片尺寸放大到320×320像素,然后随机裁剪到288×288像素送入网络进行训练,均使用Adam优化器,超参数设置如下:训练次数为100,批量为4,学习率为10-3。图7为训练过程中6种模型的训练损失和验证损失。
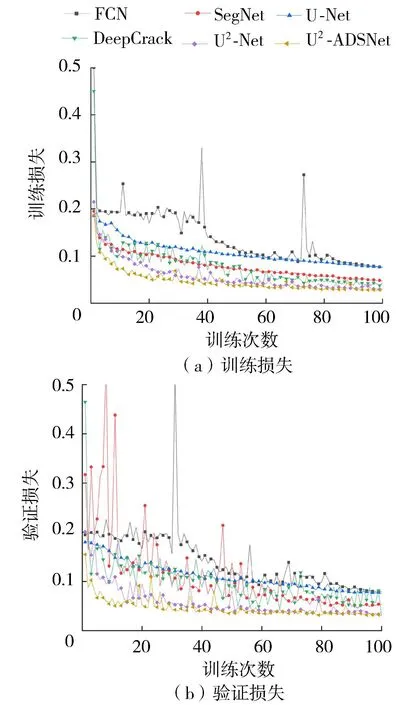
图7 6种网络在数据集1上的训练和验证损失
由图7可以看出U2-ADSNet在训练初期具有更快的收敛速度,和其他模型相比,在训练次数相同的情况下损失最小。各个模型训练次数到100时的损失曲线已经十分平稳且缓慢,将此时的训练结果在数据集1的测试集上进行了对比,获得6种模型的试验结果如图8和图9所示,可以明显看出U2-Net和U2-ADSNet具有显著的优势。在一些细节方面,U2-Net则没有U2-ADSNet表现得好,U2-ADSNet可以更好地提取裂缝细节特征,同时也能更好地过滤噪声,但是也存在一定程度的误识别,如图10(c)所示。
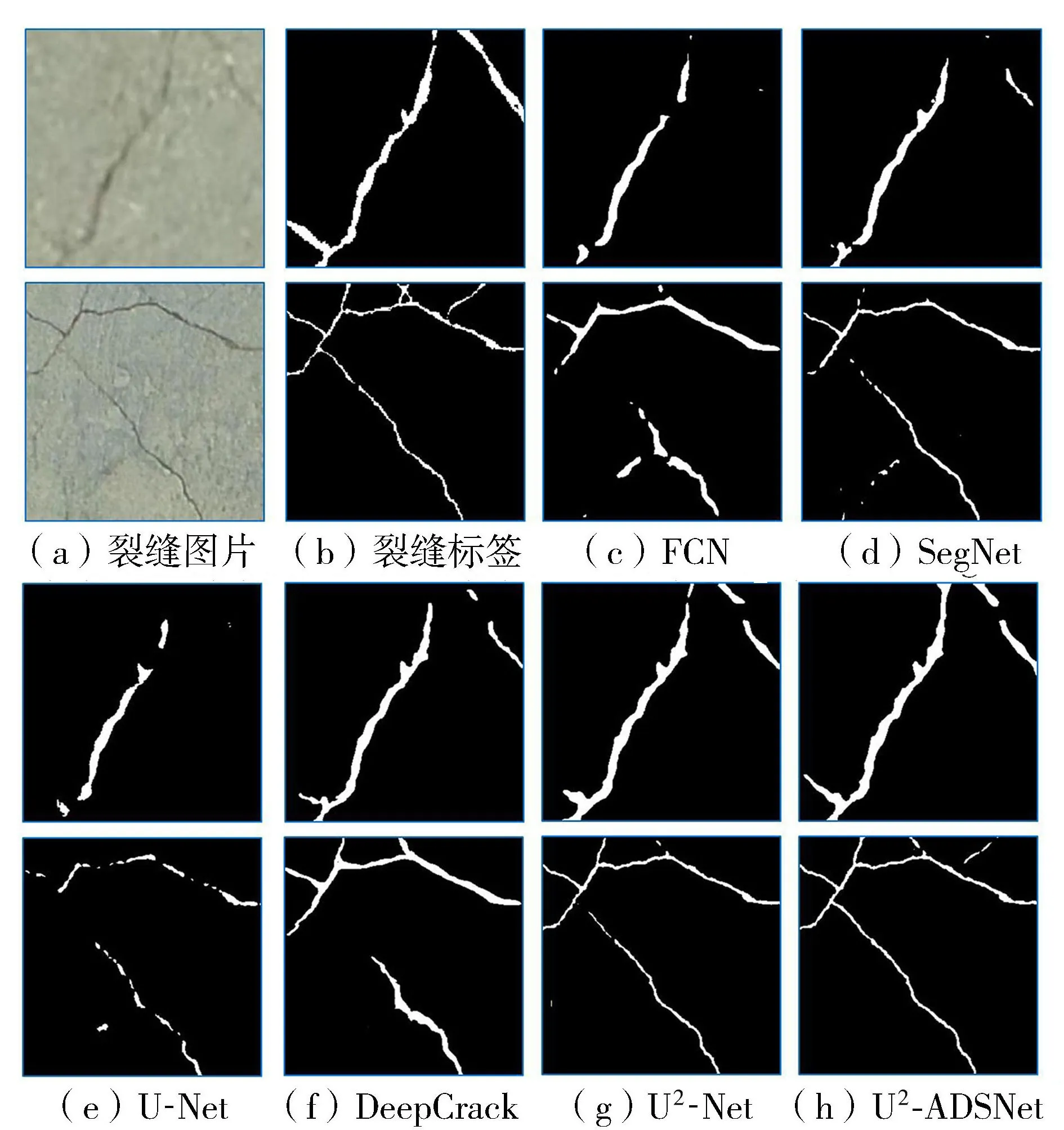
图8 不同模型在数据集1裂缝图片上的表现

图9 不同模型在数据集1非裂缝图片上的表现

图10 U2-ADSNet识别失败案例
FCN16分割失败的主要原因在于模型结构简单,其最终的分割结果由最底层特征图上采样2倍后与第4层最大池化后的特征图相加,然后再上采样16倍得到,较大的上采样会损失细节信息。SegNet记录最大池化时最大数值的位置,在上采样时能更好地还原,但是其性能的提升主要在速度上。U-Net在背景较为简单的医学图像表现良好,难以适应部分堤防裂缝特征不明显、背景复杂的情况。DeepCrack相比SegNet有一定提升,但是在堤防裂缝检测上仍然存在不足。
U2-ADSNet采用改进的ADS-RSU残差结构,相比U2-Net较为精确,误识别主要存在于特征不明显或者与裂缝特征极为相似的区域。如图10所示,在裂缝识别方面,一些清晰度不够或者特征不明显的裂缝仍然存在识别误差,提升无人机航测摄像头的清晰度有望提高识别精度;在背景噪声过滤方面,一些表面破损但没有裂缝的情况下会存在一定的噪点,其形态与裂缝存在差异,可在后处理中去除。
表 1为各个模型在数据集1 测试集上的表现,其中浮点运算量、乘加运算量和模型参数量的数值越大代表模型越复杂,训练时间和测试时间越长代表模型训练成本越高。由表1可见,U2-Net和U2-ADSNet的正确率(Iacc)、精确率Ipr、召回率Ire、交并比(Iou)和综合评价指标(F1)均优于前4种模型。相比U2-Net,U2-ADSNet的精确率略微下降,但召回率、交并比和综合评价指标均有所提高。

表1 不同模型评价指标、模型参数量和训练成本对比
受标注工具的限制,一些裂缝内部的细微噪声(实际为裂缝)无法手动准确标注。U2-ADSNet因为使用AC增大了卷积层感受野,将裂缝内部细微噪声归类为裂缝,而评价指标是基于手动注释的标签统计的,这就导致U2-ADSNet的正确率和精确率相比U2-Net有略微降低。由于裂缝外部轮廓更加精细,带来交并比提高。虽然精确率下降了3.07个百分点,但召回率提升了近5个百分点,综合评价指标的提升则体现了U2-ADSNet对裂缝的识别具有更好的性能。
由表1可以得出,U2-ADSNet在浮点运算量、乘加运算量和模型参数量上,相比其他模型具有明显优势,测试时间远少于前3种模型,与U2-Net几乎无差别,训练时间相比U2-Net下降了11.44%,表明本文提出的U2-ADSNet在实际应用阶段易于训练。
试验表明,U2-ADSNet在召回率、交并比和综合评价指标等方面均优于U2-Net,训练时间和网络的计算量上也具有明显优势,这表明ADS-RSU有助于网络更好地学习并更准确地分割对象,在堤防的裂缝分割任务中更具有优势。
3.4 无人机影像的堤防裂缝检测试验
为了检验U2-ADSNet在实际场景下的表现,在数据集2上先对模型进行预训练,确定最优的迁移学习策略,以便后续用少量无人机样本数据实现堤防裂缝的检测。在预测阶段采用切片预测(切片为288×288像素),并进行裂缝提纯。
神经网络靠近输入端的卷积层一般提取图像的通用特征,因此通过5次试验确定预训练的U2-ADSNet编码层效果最优加载层,5次试验训练过程中的损失曲线对比如图11所示(图中“迁移En_1”代表加载预训练 的U2-ADSNet特征提取层的第1层,“迁移En_1-2”代表加载预训练 的U2-ADSNet特征提取层的第1到第2层(即前两层),其他以此类推)。

图11 不同迁移学习策略下的训练损失
由图11可见,采用迁移学习策略后模型在训练次数相同的情况下,损失更小,表2为U2-ADSNet采用5种不同迁移学习策略在数据集1测试集上的性能对比。
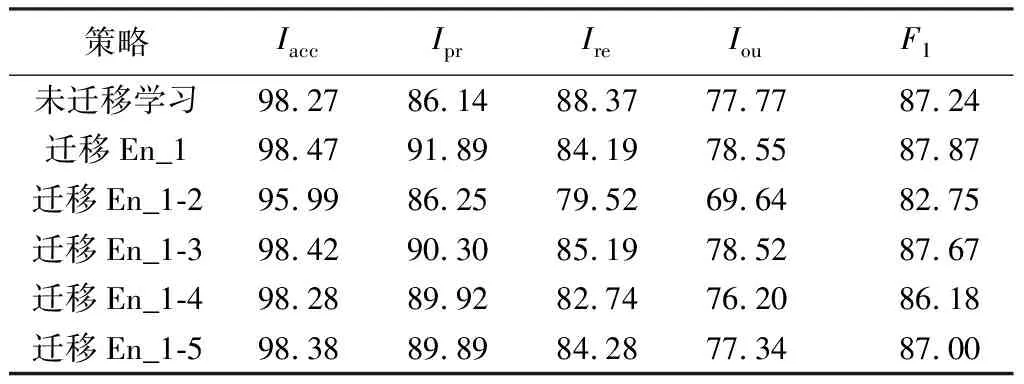
表2 U2-ADSNet采用不同迁移学习策略的性能对比 单位:%
由表2可知,只加载第1层预训练参数(迁移En_1)得到的迁移学习模型效果最优,可以在降低训练成本的同时进一步提高模型的效率和精度,因此实际场景的应用使用此种迁移学习策略。图12为迁移学习U2-ADSNet和深度学习中常用的裂缝检测方法无人机影像预测结果对比(无人机影像的高度为4 864像素,宽度为3 648像素,每张图选择两个细节展示,分别用红色和绿色标记)。
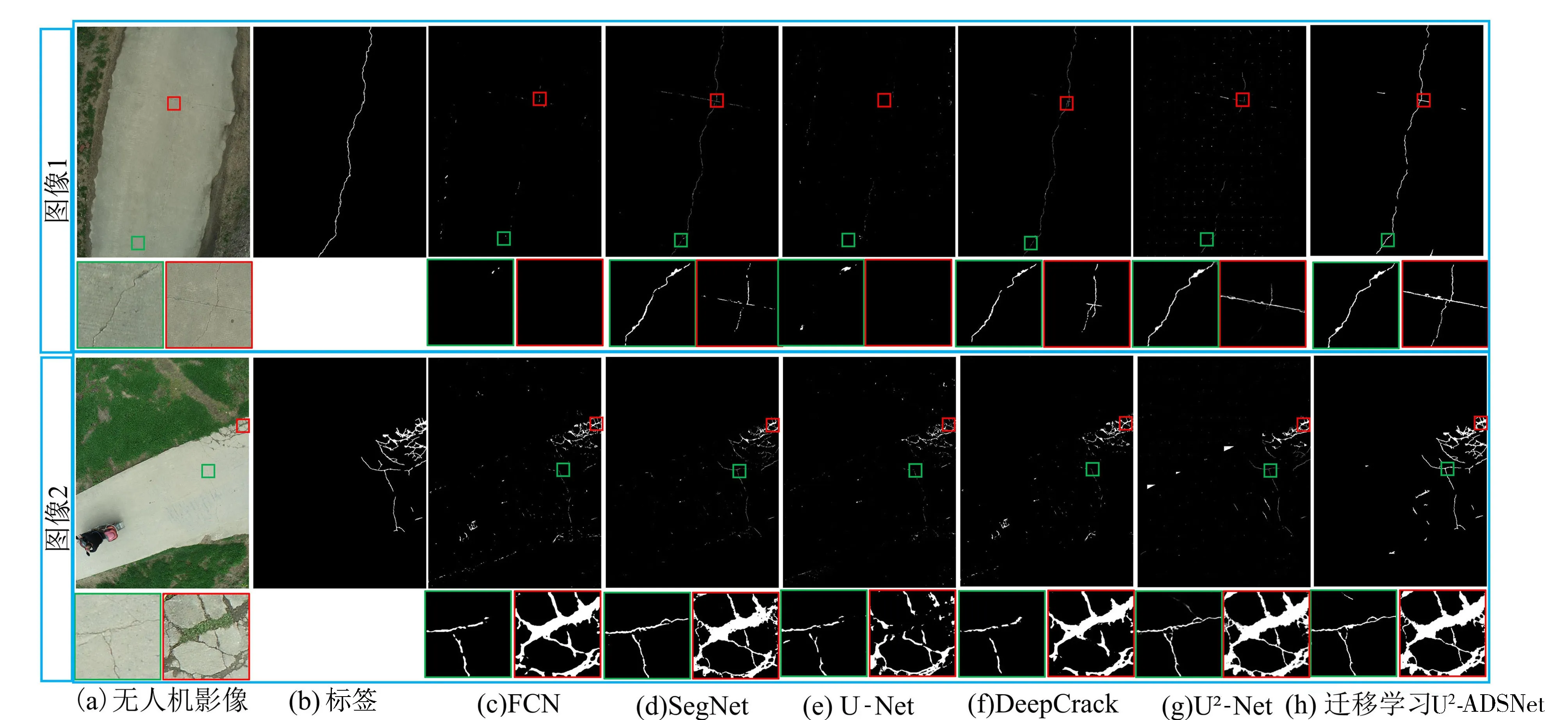
图12 不同模型无人机影像预测结果对比
FCN、SegNet和U-Net的预测结果仅能预测裂缝的位置分布,对裂缝细节信息预测较差而且没有完全过滤背景区域。DeepCrack预测的结果虽然有一定提升但是仍然不够理想。U2-Net的预测效果有所提升,但是不能完全预测出图像1中微小裂缝。迁移学习U2-ADSNet对背景区域的噪声具有较好的过滤效果,可以准确预测大多数裂缝,但是也存在部分伸缩缝被误识别为裂缝的情况,如对图像1的预测结果。
3.5 试验结果分析
a.从数据集1的测试结果来看,U2-ADSNet的模型参数量、评价指标和预测效果均优于FCN、SegNet、U-Net和DeepCrack,相比U2-Net也有一定的提升;U2-ADSNet比U2-Net对细微裂缝的检测效果更好,说明本文提出的语义分割模型U2-ADSNet具有一定优势。
b.以ADS-RSU为基础构建的U2-ADSNet具有U2-Net优点,同时降低了模型参数量,提升了模型感受野和学习能力,相比U2-Net在数据集1上的训练时间缩短了约24 min,有效地降低了训练成本。
c.使用U2-ADSNet在开源数据集2上的预训练参数后,可大大降低模型在应用时的训练和标注成本。由于没有开源的堤防裂缝数据集,为了达到精确的检测效果,仍需手动标注少量堤防裂缝样本进行训练。
d.从无人机影像端到端的检测效果来看,U2-ADSNet对堤防背景过滤和裂缝细节信息的预测方面具有更好的效果,可以快速实现大范围的裂缝检测,无需进行烦琐的预处理。
5 结 语
为有效实现堤防表面裂缝信息的快速获取,本文提出了一种U2-ADSNet语义分割模型与迁移学习结合的裂缝检测方法。U2-ADSNet通过将AC和DSC融入ADS-RSU,降低了模型的计算量,增大了感受野,提升了模型对微小裂缝的预测效果;迁移学习降低了训练成本,提升了识别精确率;切片预测实现了大范围无人机影像的裂缝检测;使用裂缝的连通域特征来进行后处理,降低了结果中的噪声。与FCN、SegNet、U-Net、DeepCrack和U2-Net的试验对比结果表明,U2-ADSNet在交并比、综合评价指标和召回率上均为最优,分别为77.77%、87.24%和88.37%。本文方法对于其他地方的裂缝也具有检测能力,但尚存在与裂缝特征相近的噪声被误识别的问题,后续研究将针对部分混凝土伸缩缝被误识别为裂缝这一问题进行改进,并扩充堤防裂缝数据集,提升识别精度。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
石油与天然气地质(2021年3期)2021-06-29
黑龙江水利科技(2020年8期)2021-01-21
红领巾·萌芽(2019年8期)2019-08-27
建材发展导向(2019年11期)2019-08-24
意林·全彩Color(2018年7期)2018-08-13
江西建材(2018年4期)2018-04-10
中国与非洲(法文版)(2017年10期)2017-11-23
CHIP新电脑(2016年3期)2016-03-10
海峡姐妹(2016年6期)2016-02-27
