
注意力机制改进信息增益模型
2022-11-10 05:04:36黄思佳郑肇谦
长春工业大学学报 2022年2期
黄思佳, 郑 虹, 郑肇谦
(长春工业大学 计算机科学与工程学院, 吉林 长春 130102)
0 引 言
自机器学习发展以来,文本分类一直是重要的研究领域。随着互联网行业技术的成熟,文本分类研究也越来越成熟。特征选择是特征工程的重要组成部分,不仅在文本分类中得到广泛应用,而且在计算机视觉等领域也得到了广泛应用。特征选择的主要工作过程一般是按照规定的准则去除一些低相关性的特征后,选取合理有效的特征,以降低特征空间的维数过程。有效的特征选择有助于减少噪声数据,提高工作效率。文本分类中的特征选择是指选择与类别相关度高、冗余度小的特征。目前,常见的特征选择方法有:皮尔逊相关系数(PCCs)、信息增益(IG)、基尼系数(Gini index)等。大量的研究数据表明,信息增益算法在一般情况下的分类效率优于其他特征选择算法。
近几年,很多学者对信息增益算法进行研究并对其改进。张方钊[1]提出一种基于类信息的信息增益算法,并与LDA主题模型相结合,以解决信息增益在词频和语义信息上的缺陷。董露露等[2]在传统信息增益中引入了最大词频比因子和离散度因子解决信息增益算法在不平衡数据集上分类性能下降的问题。郭颂等[3]提出一种基于特征分布加权的信息增益改进算法,克服信息增益的缺陷问题。
由上述已取得的成果可以看出,以往学者改进信息增益算法主要是从算法忽略词频因素对特征的影响和算法在不平衡数据集上分类效果不好这两方面着手。而针对信息增益算法忽略词性因素和上下文相关语义的问题改进较少。为了解决这一问题,文中提出一种基于注意力机制的改进信息增益模型,实验表明,改进后的特征选择模型在分类性能上有所提升。
1 相关理论
1.1 信息增益
信息增益[4]在概率学上是指在一个条件下,信息复杂度也就是信息的不确定性减少的程度,就是信息熵与条件上的差值。熵是不确定性或随机变量的一种度量,假设一个随机变量
X={x1,x2,…,xn},
其概率分布为p(x),则该随机变量的熵为
H(x)=-Σx⊂Xp(x)logp(x)。
(1)
在文本分类[5]中,信息增益通过一个特征词能给整个分类提供信息量来评价其重要性,是没有特征的文本的熵与采用特征后的文本的熵之间的差值,IG的计算公式为
IG(x)=H(C)-H(C|x)=
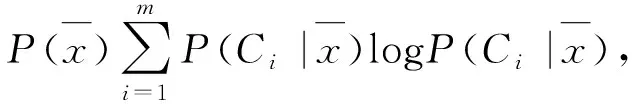
(2)
式中:P(Ci)----Ci类文档在语料库中出现的频率;
P(x)----含特征x的文档的频率;
P(Ci|x)----含特征x的文档属于Ci类的概率;
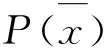
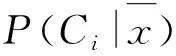
M----类别数。
1.2 注意力机制
简单来说,注意力机制就是关注重点,而忽略其他不重要的因素是否重要这一点取决于应用程序场景的不同。在生活中也是如此,当我们在读一篇文章的时候,通常会潜意识里记住重要的关键词或者是关键的句子,最快速地理解一句话或一段话的意思。而每个人的注意力又不同,也就“每个人看到的世界都是不一样的”这个说法。在面对数据时,要表现出的关注程度是不一样的,需要为重要性不一致的数据信息分配不同的关注度,这也是注意力机制应用的意义所在。
根据不同的应用场景,Attention分为空间注意力(用于图像处理)和时间注意力(用于自然语言处理),Attention的原理是计算当前输入序列和输出向量之间的匹配程度,高度匹配是注意力集中点,相对分数也就越高。
2 基于注意力机制的改进特征选择模型
针对传统信息增益算法的不足,文中对其进行相关改进:针对忽略词性题,为算法引入词性标注过滤;针对忽略上下文相关语义,引入注意力机制。提出一种基于注意力机制的改进特征选择模型,如图1所示。
该模型主要包括词性过滤模块、注意力机制模块、全连接输出模块。模型的输入部分是原始文本,经过简单的预处理后,首先进行词性标注过滤,这一步主要根据词性对特征词筛选过滤,去除冗余词。
通过IG(信息增益)特征选择[6]算法选出特征词,生成词向量。同时使用Bert预处理模型生成语义向量,将词向量与语义向量融合,连接注意力模块。最后连接全连接层,通过softmax得到最后的分类结果。
引入注意力模块的主要目的就是更好地联系上下文语义特征,为与类别有较强关联的特征词可以分配更多的注意力。
2.1 词性标注
与大多数传统特征选择算法一样,信息增益算法在特征选择时没有考虑特征词词性对分类的影响。
通常文本经过去停用词后,剩下的文本大部分都为有价值的信息。传统的特征选择算法通常会直接将预处理后的词送入算法中进行筛选。但实际上,大部分有价值的特征词是以名词、形容词和副词等为主。虽然预处理步骤也会对英文文本进行词根还原,但是处理后的文本还是会存在大量的其他形式。
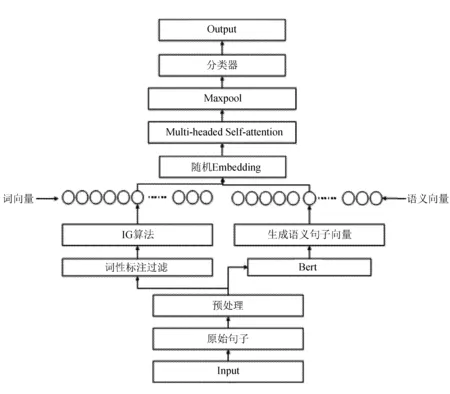
图1 基于注意力机制的改进特征选择模型结构
因此,文中在将文本送入信息增益算法之前,采用了双重保险模式,根据词性对特征词又进行了一次过滤。nltk[7]为我们提供了文本特征词的词性,文本对其进行筛选,筛选后留下′JJ′,′JJR′,′JJS′,′NN′,′NNS′,′RB′,′RBR′,′RBS′,′RP′,′VB′,′VBD′,′VBG′,′WRB′几种词性的词作为特征词进行选择。
2.2 Bert预训练模型
引入Bert模型主要是为了将IG算法选择出来的词向量与Bert模型训练得到的语义向量相结合。Bert模型[7]是一种基于双向Transformer[8]编译器的实现自然语言处理的模型。主要有Embedding模块、Transformer模块和输出的预微调模块[9]。词嵌入、段嵌入以及位置嵌入三个嵌入信息都是由Bert模型训练得到的,将这三部分的嵌入信息相加,即可得到最后的文本输入表征。BERT中只使用了经典Transformer架构中的Encoder部分,完全舍弃了Decoder部分。经过Transformer层的处理,Bert模型的最后一次会根据任务的不同需求进行调整。
2.3 注意力机制的引入
引入多头注意力机制[9]来更有效地提取特征,主要目的是为与类别相关性强的特征分配更多的权重,从而更有效地提升特征选择的能力。
将原始文本分别进行文本分词和输入到Bert模型中,进行文本分词后,经过特征词性过滤后进行文本表示,得到特征词向量
Cm=(c1,c2,…,cm),
输入到Bert模型后得到句子向量
Sm=(s1,s2,…,sm)。
将得到的特征向量与句子向量进行矩阵拼接。通过随机Embedding[10-11]生成融合向量
Em=Con(Cm,Sm)。
多头注意力机制可以有效地捕捉上下文依赖关系,准确捕捉词法和句法语义特征。将融合向量Em送入Q,K,V一般框架下的标准Attention。其计算过程为
Attention(Q,K,V)=softmax(fatt(Q,K))V,
(3)
式中:fatt----概率对齐函数。
采用Scaled Dot Product,
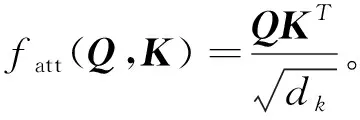
(4)
式中:dk----矩阵的维度。
在多头注意力机制中,使用不同的权重矩阵将输入特征线性化为不同的信息子空间,并在每个子空间中执行相同的注意力计算,以充分提取文本上下文相关语义。 i-head注意力的计算过程为
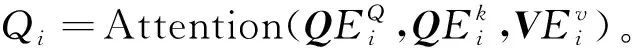
(5)
最后,将各head合并,得到多头自注意力机制的输出,设多头注意力的头数为n。
则Ek经过多头注意力计算得到A:
MHS(Q,K,V)=concat(Q1,Q2,…,Qn),
(6)
A=MHS(Ek,Ek,Ek),
(7)
完成特征选择过程。将经过注意力机制得到的特征向量送入全连接层,再经过最后softmax分类器得到文本所属类别的概率,以验证特征选择过程的有效性。
ρ=Linear(A),
(8)
ρ*=argmax(ρ),
(9)
式中:ρ----用来预测文本所属类别;
ρ*----经过函数argmax计算,导致概率值最大的文本类别标签。
3 实验及结果分析
3.1 实验环境
操作系统:win11;
GPUNVIDIA TITAN XP*4;
编程语言python;
深度学习框架为pytorch。
3.2 数据集介绍
文中使用的实验数据集是国外来源的影评文本数据集,数据集包含20 000多条真实的电影影评,共分为两个类别:好评和差评。
数据集包含两个标签内容,分别是content和category。
整体数据集按7∶3分为训练集和测试集。
3.3 参数声明
模型中的参数设置见表1。
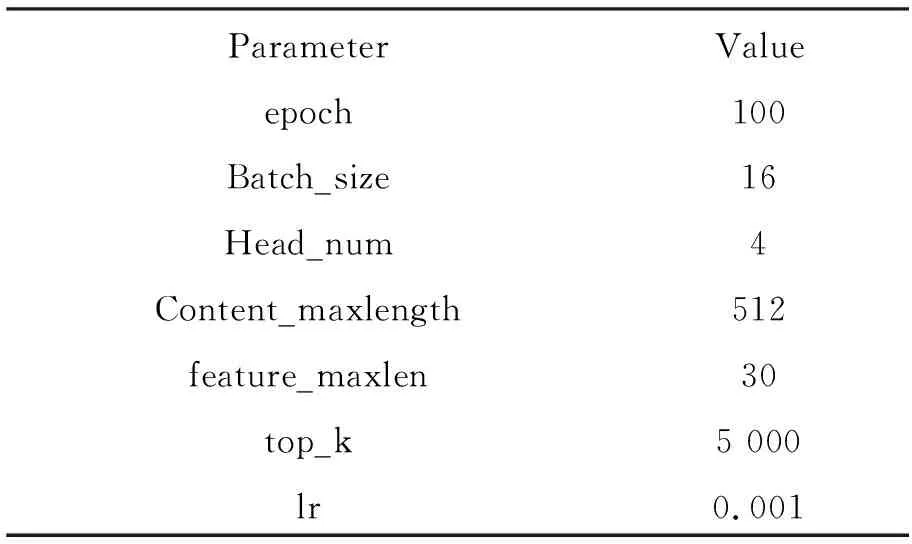
表1 实验中的参数设置
3.4 评价指标
目前,在自然语言处理领域的评价指标[12]多种多样,但在文本分类领域一般使用准确率P、召回率R和F1值作为评价指标,具体计算公式为:

(10)

(11)
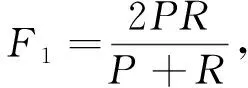
(12)
表2 评价指标中变量含义
3.5 实验结果与分析
为了验证文中提出的基于注意力机制的改进信息增益模型的有效性,文本做了对比实验,前人提出的其他模型[13]与文中改进的特征选择模型在相同条件下进行,分别与Bert、CNN、Seq2Seq_Att和transformer进行了对比,文中改进模型在准确率上略有提升,损失值上也略有进步。不同模型与文中提出的模型在影评文本的验证集上效果见表3。
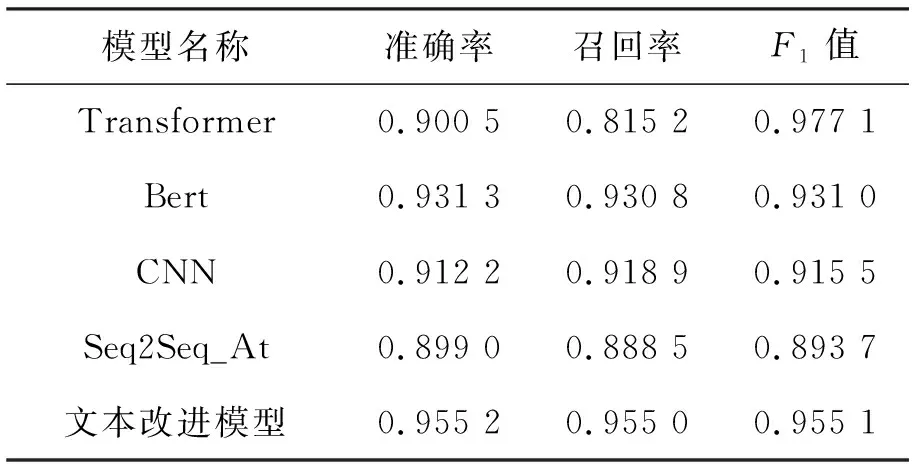
表3 不同模型的不同评价指标
通过表3中模型准确率对比可以看出,引入Bert模型的句子向量,并加入Attention机制后的改进特征选择模型在准确率上有了提升。从上述实验数据结果可以得出,文中改进模型在同等条件下与前人提出的模型在分类任务上有不错的提升,传统的IG算法在加入词性过滤和Attention机制后,整个特征选择结果更加准确,改进模型在特征选择上有效果。
在准确率、召回率和F1值的表现上看,文中准确率与只使用Bert模型时仅提升约2%,召回率有所增长,表明在传统特征选择算法与Bert模型结果是存在效果的,但Bert模型的预训练对语义信息的捕捉能力更强。总体来说,文中提出的改进模型在特征选择上效果良好,且在分类效果上表现也具有优势。
4 总结与展望
提出的基于注意力机制的改进特征选择模型,其主要创新点在于为IG算法引入了Bert模型和注意力机制,又改进了传统特征选择算法不考虑词性对分类效果的这一问题。这种词性过滤的创新,大大降低了特征选择算法的计算开销,减少了冗余;Bert模型与传统IG算法结合,提升特征选择的能力,注意力机制的引入,为与类别相关性强的特征分配更大的特征权重。对比实验结果表明,文中提出的改进模型效果优于其他模型。
虽然本模型在准确率上稍有提升,在文中重点数据集上也展现出较好的分类效果,但是,文本的工作仍有很多不足,例如,在结合IG算法与Bert模型时,仍存在一些特征词向量丢失的情况,对于影评数据集中短文本特征空间稀疏的问题没有得到良好的解决,对影评中一些口语、俚语词判断不准确等。因此,要继续对深度学习模型进行研究,并对IG算法的公式进行改进,争取进一步提升文中模型的效果。
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20 07:23:56
电子制作(2019年19期)2019-11-23 08:41:36
电子制作(2018年19期)2018-11-14 02:37:02
计算机技术与发展(2018年8期)2018-08-21 02:08:14
中国机械工程(2017年22期)2017-12-02 01:52:34
电子制作(2017年23期)2017-02-02 07:17:06
西北工业大学学报(2015年4期)2016-01-19 03:31:47
中文信息学报(2015年4期)2015-04-21 08:29:12
振动工程学报(2014年4期)2014-03-01 01:15:41
计算机工程(2014年6期)2014-02-28 01:26:36
