
局部通用加权协同表示人脸识别*
2022-11-10 06:39游春芝
计算机时代 2022年11期
崔 建,游春芝
(山西医科大学汾阳学院基础医学部,山西 吕梁 032200)
0 引言
随着人工智能的飞速发展,人脸识别被广泛的应用于各个领域当中,如刷脸支付、身份认证、目标定位等。近些年来,稀疏表示[1-2]在人脸识别、深度学习等领域深受研究者的青睐,而基于稀疏表示的人脸识别往往在面临着表情、光照、遮挡等复杂的变化环境时识别效果不大理想。如何在这种复杂变化环境中取得更好的效果,成为现阶段人脸识别研究的热点。稀疏表示理论最早是由Wright[3]等人提出并用于人脸识别领域,在理想环境下取得了较好的效果。稀疏表示的核心在于:将测试人脸图像在L1范数约束下通过训练样本进行线性表出,理想状态下同一类人脸样本线性表示后对应的组合系数非零,而其他系数全为零。稀疏表示中系数求解需要构建一个过完备的训练字典,而且在L1 范数约束下计算量比较大。Zhang[4]等人提出基于L2范数约束的正则化协同表示算法,讨论并说明样本整体之间的协同作用在线性表示过程中起到至关重要的作用,而且对应系数的解是封闭的,相比稀疏表示计算要快的多。文献[5-6]中一些基于加权的稀疏表示算法相继被提出,作者将测试样本与训练样本之间的局部距离作为系数权重约束,增强稀疏表示或协同表示的线性可分性,进而增强算法的识别效果。但是如果待测人脸存在遮挡或者表情发生巨大变化时这些算法就很难取得理想的识别效果。为了增强鉴别性特征的稀疏表示性能,基于构建通用训练样本的算法相继被提出。如Deng等人[7]提出一种扩展的稀疏表示算法ESRC 方法,通过训练样本构建人脸类内变化字典,克服样本信息的缺失,增强稀疏表示性能;Yang 等人[8]提出一种基于局部通用表示的协同表示人脸识别算法,首先将每个人脸图像进行分块化处理,然后构建类内变化字典,从而提高算法的性能。
受构建通用训练集加权约束思想的启发,本文提出了一种基于局部通用的加权协同表示人脸识别算法。为了增强协同表示的性能,我们一方面根据训练样本构建通用的类内变化字典,增强因光照、表情遮挡等变化训练样本对测试样本的线性表示性能;另一方面为了提高协同表示中样本之间的竞争性,以及同一类样本的线性表示性能,我们引入加权判别项别,以便从正确的类别中获得优势的线性表出,从而更高效地对人脸进行协同表示,提高表情、遮挡等环境变化下人脸识别的准确率和鲁棒性。
1 相关工作
稀疏表示的核心在于将测试样本通过训练样本线性表示,并且对系数增加稀疏性条件约束。对于给定的训练样本A=[A1,A2…AR],测试样本y ∈Rm×1,其中训练样本A 是由R 个用户组成,Ar=[v1,v2…vm]表示第r个用户的m张人脸数据组成的矩阵。存在线性表示使得y=Aα,如果对系数α 添加稀疏性约束后,理想状态下稀疏系数就可以表示为x=只有同类样本对应的系数非零,而其他系数为零。对应的目标函数就可以表示为:

其中‖ ‖0表示L0 范数,即对应系数中非零元素的个数,式⑴是一个NP 问题,不能直接进行求解。为此Wright 等人提出将目标函数进行缩放,转化成可求解的基于L1范数约束的可求解优化问题。即:

最后根据误差对样本进行分类。

为了克服基于L1 范数约束导致的计算复杂度,Zhang 等人提了一种基于L2 范数约束的正则化协同表示算法(CRC),与L1 范数约束不同,L2 范数约束强调的是样本整体的协同作用,而非稀疏性。对应的目标函数为:

而且,式⑶的解是封闭的,根据最小二乘法,对应的系数α可表示为:

2 局部通用加权协同表示(LGWCR)
为了增强样本的表示性能在[3-5]中研究者们提出构建局部通用变化训练集的方法(Local Generic Weighted Collaborative Representation,LGWCR),即测试样本y可以表示为:

与式⑴不同,式⑸增加了一项Bβ,其中B表示新构建的通用训练样本,B=[-Gr,…,-Gr,…,-Gr],Gr一般表示标准化人脸,Gv表示包括光照、表情、遮挡变化的一组训练人脸。假设训练集Gv由M 种表情变化人脸组成Gv=[,…,,…,],那么基于通用表情变化字典就可以通过Gv、Gr构造,即B=[-Gr,…,-Gr,…,-Gr],与稀疏表示不同,协同表示着重强调样本整体之间的协作表示,而不是系数的稀疏性,基于L2范数约束的目标函数⑸就可以表示为:
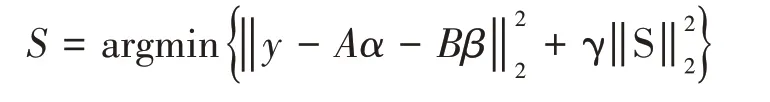
记X=[A,B],S=[α β]T,根据最小二乘法系数S 就可表示为:
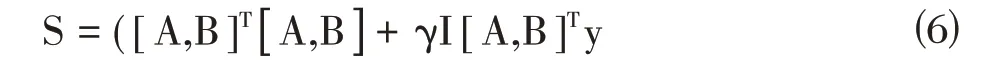
为了增强协同表示中样本之间的竞争性,提高同一类样本的线性表示性能。我们引入加权判别项别,以便从正确的类别中获得优势表示。其中Ui表示第i 类训练样本的均值,wi表示对应类别的权重,一般来说训练样本的均值能够很好地反应样本数据的结构特征,同类样本与其均值样本更相似。增加该约束项可以确保来自同一类别的线性表示能够更接近样本的均值。基于局部通用加权稀疏表示模型的定义为:

其中γ1,γ2表示正则化参数,Ui表示第i 类样本均值,定义为:

最后根据样本误差最小来判断所属类别:

3 实验结果与分析
为了验证改进算法在人脸识别当中的有效性,我们取公开的Extended Yale B、AR 人脸数据库进行仿真实验,实验对照组算法为:CRC、SRC、RPCA、LGCRC、ESRC。将所有图像调整为大小30×30 像素的灰度图像,并对其标准化。在SRC,CRC 中我们选择最优正则化参数l分别为0.0005、0.001。选用的机器是Accer笔记本电脑,Windows 10 系统,Matlab2014a,作为仿真平台。
3.1 Extended Yale B人脸库
实验一:Extended Yale B 人脸库是由38 个人的2414 张人脸数据组成,按照光照角度变化又分成5 个子集。选取子集1 和2 的每个人前4 张图像作为训练样本,取子集1每个对象第一张正面人脸作为标准脸,子集2、3、4、5上选取每个人脸的前两幅图像用于构建通用训练集的变化人脸,其余作为测试样本,部分实验样本如图1所示。

图1 Extended Yale B人脸数据部分样本
在Extended Yale B 人脸库的5 个子集上进行仿真实验,我们将改进算法与CRC、SRC、RPCA、LGCRC、ESRC 算法进行对比,对比结果如表1 所示。整体来看,从子集1 到子集5 识别率随着光照变化逐步识别率逐渐降低,尤其是在子集5 上识别率最高才72.7%,但是在这几种对照试验中我们的改进算法相比较取得很好的效果。在子集1 上改进的算法和ESRC 达到最高,改进的算法比LGCRC 略高,LGCRC 与本文算法的不同之处就在于改进的算法增加了加权条件约束项‖,用于增强协同表示中同类样本的竞争表示。在这几组数据集上基于通用表示算法如:ESRC、LGCRC、LGWCR 要比传统的CRC、SRC 算法平均要高出将近10 个百分点,而且即便在子集5 上识别率基本上都能达到68.3%。随着光照强度的变化这些传统的基于表示的算法要比ESR、LGCRC以及本文的算法识别率要下降的快,尤其是CRC 识别率下降了40个百分点,失去了协同表示的优势。改进的局部通用加权协同表示算法在Extended Yale B 数据集上都比LGCRC 识别率普遍要高,平均要高出2 个百分点,说明增加加权条件约束项在通用协同表示算法中起到了一定作用,这有助于提高光照变化下协同表示的识别率,增强算法的鲁棒性。

表1 Extended Yale B上的正确识别率(%)
3.2 AR人脸数据库
实验二:AR 人脸数据库是由126 个人4000 多张彩色图像组成,该人脸主要包括光照变化、表情变化、伪装(眼镜和围脖遮挡),AR 人脸数据部分样本如图2所示。实验中我们选取男女各50 个样本作为实验对象其余作为构建通用集。选取每个人前8张图像作为训练样本,其余作为测试样本。构建通用训练样本时选取每个对象第一张正面无表情变化人脸作为标准脸,其余作为变化人脸。在AR 人脸数据中基于围脖、和眼镜遮挡比例大约为整幅图像的20%-40%,部分图像带有光照、表情的变化。

图2 AR人脸数据部分样本图像
在AR 人脸数据上我们分别对基于表情、墨镜、围脖遮挡的复杂环境下进行实验,实验结果如表2所示。不难发现LGWCR性能明显比其他算法在各种环境变化下效果要更理想。在这些复杂环境变化下LGWCR比传统的CRC 平均高出11 个百分比,比基于通用表示的LGCRC 平均高出3 个百分比,比RPCA 平均高出4 个百分点,比ESRC 高出2 个百分点。基于通用集的算法ESRC比传统的SRC平均高出7个百分点。
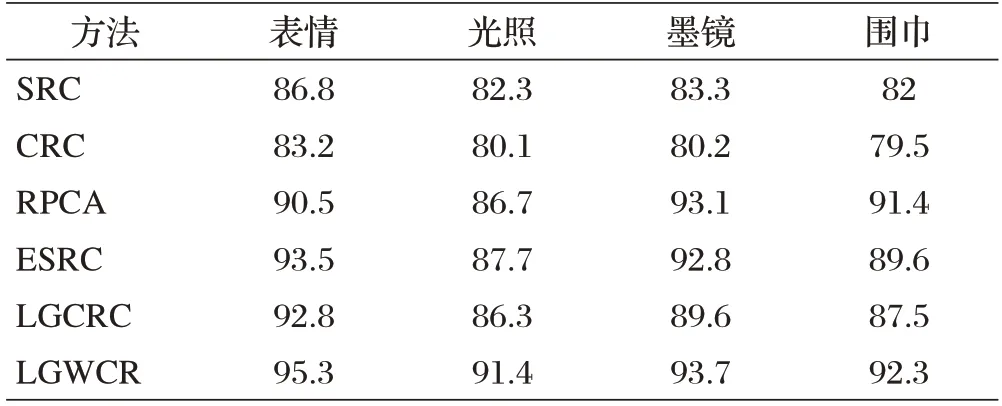
表2 AR人脸数据库识别率
3.3 结果分析
为了验证构建的通用训练集和加权约束项在复杂环境变化下协同表示效果,取传统的实验方法CRC、SRC、RPCA、ESRC 等作为对照,在Extended Yale B 和AR 人脸数据库上构建局部通用训练样本,结果表明,不管是ESRC、LGCRC 以及本文的新算法都比传统的稀疏表示和协同表示识别效果有很大的提高,这说明构建通用的训练样本有助于加强人脸的线性表示性能,提高识别效果。
通过LGCRC 和本文算法对比,增加加权约束后,改进算法识别率也都有不同程度的提高,表明加权约束增强同类样本的协同表示性能。而且改进的算法也是基于协同表示,其解是封闭的,要比基于稀疏表示、RPCA算法运算要快的多。
4 总结
针对人脸脸识别存在的表情、遮挡等问题,提出了一种局部通用的加权协同表示算法。算法汲取了通用训练集在遮挡等复杂环境下优势,而且为了增强协同表示中样本之间的竞争性,提高同一类样本的线性表示性能,我们在协同表示中构建加权约束项,从而更高效地对人脸进行协同表示,提高表情、遮挡等环境变化下人脸识别的准确率和鲁棒性。在公开的Extended Yale B、AR 人脸数据库进行仿真实验,实验结果表明算法的有效性。但是对于构建通用训练集的算法其对训练样本要求比较高,容易导致协同表示信息的沉于,因此如何高效的筛选通用训练集还有待进一步的研究。
猜你喜欢
计算机工程(2020年3期)2020-03-19
科技创新与应用(2020年6期)2020-02-29
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
中国校外教育(下旬)(2017年8期)2017-10-30
数学物理学报(2017年3期)2017-07-01
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
中国交通信息化(2016年2期)2016-06-06
