
智采工作面中部液压支架集群自动化后人工调控决策模型
2022-11-09 04:46张锦涛付翔王然风王宏伟
工矿自动化 2022年10期
张锦涛,付翔,3,王然风,王宏伟
(1.太原理工大学 矿业工程学院,山西 太原 030024;2.太原理工大学 山西省煤矿智能装备工程研究中心,山西 太原 030024;3.山西焦煤集团有限责任公司 博士后工作站,山西 太原 030024;4.太原理工大学 机械与运载工程学院,山西 太原 030024)
0 引言
近几年来国家大力推行煤矿智能化建设,我国煤矿智能化建设日新月异,发布了各类政策,拟定了行业标准,定义了煤矿智能化概念,建立了煤矿智能化基础理论体系,构建了煤矿智能化总体架构,很大程度上支撑了煤炭行业的健康发展[1-4]。但我国煤矿综采工作面地质条件差别很大,目前煤矿智能化建设面临着许多技术难题,尤其是智能化煤矿自适应能力较差[5],液压支架自动化后会出现丢架、直线度不平整、支架歪斜等异常工况,所以液压支架自动化后人工调控依然必不可少[6]。
针对液压支架自适应跟机问题,文献[7-9] 简化了综采设备群全局最优规划问题,给出了液压支架群组分布式协同控制方法;文献[10]阐述了在大数据背景下,实现智能综采装备协同控制知识自学习、开采行为自决策、分布协同自运行等目标的理论基础与方法体系;文献[11]通过分析液压支架自主跟机原理,提出了根据不同推移状态模式,分段感知液压支架推移行程并实现液压支架自主跟机决策的方法;文献[12]分析了综采“三机”的行为约束规律,通过建立基于多智能体系统理论的综采“三机”全局任务规划及任务协调控制机制,实现了综采“三机”协同调度运行;文献[13]从液压支架精准控制不同动作角度研究了液压支架的智能协同控制,为解决综采工作面液压支架在自主跟机过程中出现的控制精度低、协同性差、直线度无法满足需求等问题提供了新思路;文献[14-16]从综采作业工序、稳压供液等不同角度对自动跟机系统进行了研究。上述研究主要从液压支架自动跟机角度出发,实现自动跟机满足生产要求的目标,然而目前智采工作面的自动化系统是以过程化控制为核心,自动化后人工调控工况变化频繁,但目前缺乏对生产过程中液压支架自动化后人工调控工况的知识发现,不利于工人快速判断需人工调控的液压支架架号。因此本文从判别液压支架自动化后动作不达标液压支架架号出发,提出了智采工作面中部液压支架集群自动化后人工调控决策模型,对自动化后人工调控工况进行知识发现与逻辑推理,将自动化后液压支架架号进行分类,找出需人工调控液压支架架号,为减轻工人劳动强度、提高生产效率提供了新思路。
1 液压支架集群自动化后人工调控操作工况
1.1 人工调控操作工况出现频次
本文所用数据源自山西吕梁某煤矿3404 工作面的实际生产数据,该工作面为薄煤层工作面,工作面长度为200 m,采煤机机身长度约为12 m,有130 架液压支架,液压支架推移油缸最大行程为700 mm。
本文采集了3404 工作面2021-11-01-12-12 共42 d 的数据。通过初步筛选得到15 d 质量较好的数据,然后对中部液压支架(20-110 架)的立柱压力数据、推移油缸行程数据、动作数据和采煤机位置数据进行分析,结合井下观测记录,对数据进行人工可视化标注后,得到的样本数量统计结果见表1。可看出15 d 内共有899 个自动化后人工调控工况样本,占全部样本的15.27%,由此可知目前智采工作面在液压支架自动跟机完成后需人工干预程度较大。

表1 样本数量统计Table 1 Quantity statistics of samples
1.2 人工调控操作工况与正常工况数据
采用探索性可视化分析方法对上述数据样本进行筛选、补缺、标注、比对、可视化等处理,结合工作面现场观察采煤过程及与工人交流经验等,总结液压支架自动跟机完成后人工操作规律,并根据强相关性和计算可行性原则,得出自动跟机拉架距离、自动跟机前后推移油缸行程变化量、采煤机与被操作液压支架的位置差3 个关键特征。限于篇幅,本文以典型工况举例分析。
2021-11-20T09:35-09:55,第20 号液压支架在正常工况下特征值变化曲线如图1 所示。液压支架自动跟机过程:自动降柱-自动拉架-自动升柱-自动推溜,从图1(a)可看出,立柱压力先由43.3 MPa降为0;然后进行自动拉架,推移油缸行程由700 mm变为60 mm;接着自动升柱,立柱压力升高为30.3 MPa;最后自动推溜,推移油缸行程逐渐增加到700 mm。根据此工作面作业规程,从整个过程的立柱压力变化与推移油缸行程变化可判定此次液压支架自动跟机过程为正常跟机。正常跟机前后的推移油缸行程变化量接近于0,自动跟机拉架距离略小于700 mm。从图1(b)可看出在正常跟机时,自动跟机支架与采煤机之间有8 架液压支架,符合工作面作业规程。

图1 第20 号液压支架在正常工况下特征值变化曲线Fig.1 Change curves of characteristic value of No.20 hydraulic support under normal working conditions
2021-11-20T16:35-16:55,第20 号液压支架在自动跟机及自动化后人工干预调控工况下特征值变化曲线如图2 所示。从图2(a)可看出,立柱压力有2 次先降后升,推移行程也有2 次减小变化,根据此工作面作业规程,判断第1 次立柱压力变化与推移行程变化为自动跟机导致,第2 次立柱压力变化与推移行程变化为人工调控导致,两者时间差约为5 min。自动跟机时,立柱压力先由46.9 MPa 降为0;然后进行自动拉架,推移油缸行程由700 mm 变为110 mm,拉架距离小于600 mm,导致直线度不平整;接着自动升柱,立柱压力升高为38.4 MPa;最后自动推溜,推移油缸行程逐渐增加到700 mm。人工调控目的是补足拉架距离,调整直线度,但人工调控时立柱压力较高,为40.4 MPa,无法直接拉架,所以人工调控再次进行降柱-拉架-升柱操作,此次人工调控行程变化量为65 mm,且人工拉架后不进行推溜操作,推移油缸行程保持在635 mm。从图2(b)可看出,自动跟机液压支架与采煤机之间有11 架液压支架,人工调控液压支架与采煤机之间有18 架液压支架,人工调控液压支架与采煤机的距离更远,这是因为工人巡检具有随机性且要保证工人安全。

图2 第20 号液压支架自动跟机及自动化后人工干预调控工况下特征值变化曲线Fig.2 Change curves of characteristic value of No.20 hydraulic support automatic following and manual lifting operation after automation
对比图1 与图2 可知,自动跟机拉架距离、自动跟机前后的推移油缸行程变化量、采煤机与被判断液压支架的位置差可作为判别液压支架自动跟机后是否进行人工调控的重要特征。
2 液压支架集群自动化后人工调控决策模型
液压支架集群自动化后人工调控决策模型是一个包含数据采集、数据预处理、特征工程、分类模型和输出的复杂模型,建模流程如图3 所示。数据采集模块为液压支架集群自动化后人工调控决策模型提供原始数据;数据预处理模块对原始数据进行异常值和缺失值处理、筛选、排序和相关性分析等数据准备工作;特征工程模块进行特征值计算及标准化处理,为分类模型提供样本集;分类模型对样本集进行划分后,利用ID3 决策树模型进行分类,最后输出正常工况下的液压支架架号与需人工调控工况的液压支架架号。
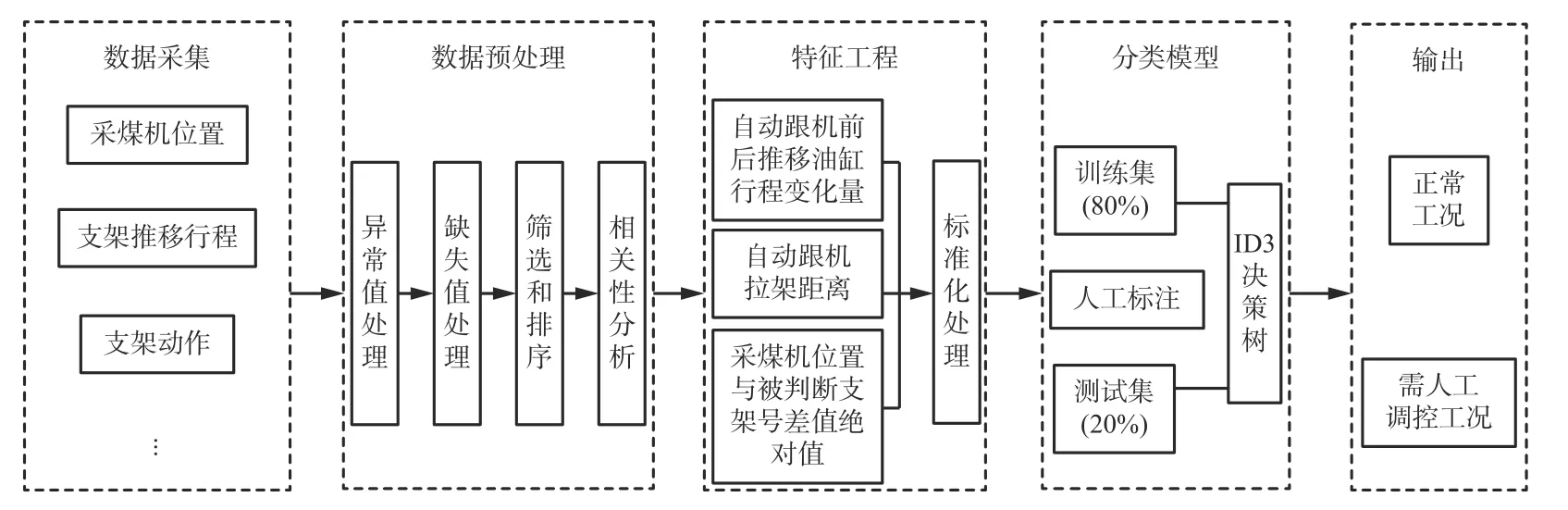
图3 液压支架集群自动化后人工调控决策建模流程Fig.3 Manual regulation and control decision modeling process after automation of hydraulic support cluster
2.1 数据采集
智采工作面数据源是建立液压支架集群自动化后人工调控决策模型的基础,包括设备状态数据和动作数据2 类,其中,状态数据主要通过设备上安装的传感器获取,动作数据主要通过设备控制系统获取。采集的数据通过工业万兆环网上传到地面调度室的关系数据库进行存储,作为构建模型的原始数据。
2.2 数据预处理
由于智采工作面环境复杂,经常发生传感器损坏或因设备故障造成工作面停电,易导致数据采集出现异常(主要是由于传感器内部元件损坏)和丢失(一般是指数据传输线路断开,常见于传感器本身损坏、传感器信号线损坏或工作面停电)。为了保证数据的完整性,采用时域相邻值或经验值填充的方法处理数据丢失的问题;针对数据异常问题,分情况进行处理,单个异常值采用相邻值替换,若异常数据较多则去除当天数据。按照液压支架的立柱压力值、推移油缸行程值、动作数据和采煤机位置数据对经过异常值、缺失值处理后的数据进行筛选,并对每种数据进行时间排序,得到可用的数据,然后对此数据进行相关性分析,得到自动跟机前后推移油缸行程变化量、自动跟机拉架距离、采煤机位置支架号与被判断支架号的绝对差值3 个特征值。
2.3 特征工程
利用预处理后的数据进行特征值计算,制作样本集。首先确定液压支架相邻2 次拉架动作发生时间,取相邻2 次拉架动作时间为截取数据的起始点与终止点;然后对每一时间段内的液压支架推移油缸行程数据、采煤机位置数据进行计算。

式中:ΔX为自动跟机前后的推移油缸行程变化量;x1为自动跟机前推移油缸行程;x2为自动跟机后推移油缸行程。
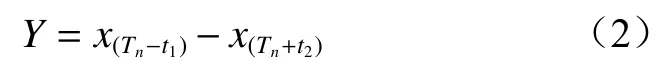
式中:Y为自动跟机拉架距离;为第n个时间段的起始点Tn前t1时刻行程;为第n个时间段的起始点Tn后t2时刻行程。

式中:Δq为采煤机位置支架号与被判断支架号的绝对差值;N为被判断液压支架架号;Q为采煤机位置所在支架号。
对自动跟机前后推移油缸行程变化量、自动跟机拉架距离、采煤机位置支架号与被判断支架号的绝对差值进行标准化处理,将不同量纲的数据按比例缩放到相同的数据范围,转化为无量纲的纯数值,从而减少不同特征对模型的影响,保证结果的可靠性。处理结果作为模型实例化的样本集。
2.4 自动化后液压支架工况分类模型
常见的分类算法有随机森林、支持向量机(Support Vector Machine,SVM)、决策树(分类树)等,其中,随机森林算法对于实时性要求很高的情况无法满足;SVM 算法对大规模训练样本无法实施;决策树算法能够直观地给出详细的分类过程,可在相对短的时间内得到良好的分类效果。由于煤矿生产过程中数据量庞大,对模型实时性要求较高,故选择决策树算法对自动化后液压支架工况进行分类。
ID3 决策树是通过信息增益(熵)确定对每个内部节点选择哪个属性进行判断,每个分支表示一种判断结果的输出,可以经过一层或多层逻辑判断实现操作类型分类。其学习的基本思想是以信息熵为度量构造一棵熵值下降最快的树,熵的表达式为

式中Pi为第i(i=1,2,···,m,m为节点属性编号)个支架动作概率值,当Pi接近于1 时,熵值H接近于0,即熵值越小,则判定选择的节点属性效果越好,反之则判定选择的节点属性效果越差。
在分类算法的基础上,对样本集进行人工标注,得到1 036 个样本,每个样本包含液压支架架号、自动跟机前后推移油缸行程变化量、自动跟机拉架距离、采煤机位置支架号与被判断支架号绝对差值和所属类别5 个数据,其中正常工况样本为675 个,自动化后人工调控样本为361 个。
3 模型构建及评估
3.1 模型构建
将人工标注后的样本集按照比例8∶2 划分训练集和测试集。利用决策树算法和训练集构建分类模型,利用测试集进行分类效果评价。
构建决策树模型的过程可分为生长和剪枝2 个过程。生长过程主要是选取最佳变量及寻找最佳分割点。剪枝过程是找到最佳变量和分割点后将其他影响模型精度的树枝剪掉,剪枝操作可降低过拟合风险,减少建模时间,提高模型的泛化能力,使模型达到最佳效果。经过剪枝操作后选取决策树模型的最大深度为5 层。
3.2 模型评估
将决策树与传统K 最近邻(K-Nearest Neighbor,KNN)、SVM、逻辑回归(Logistic Regression,LR)等分类算法进行分类效果对比,结果见表2。可看出KNN 算法与LR 算法的训练集准确率较低,说明KNN 算法与LR 算法泛化能力不足;SVM 算法的训练集准确率较高,但测试集准确率较低,说明SVM 算法存在过拟合问题;决策树算法的训练集与测试集准确率最高,说明决策树算法的泛化能力与过拟合能力较其他算法好。

表2 模型准确率统计Table 2 Model accuracy statistics %
4 结语
智采工作面中部液压支架集群自动化后人工调控决策模型以工作面集控中心所采集的生产数据为基础,利用大数据挖掘技术与机器学习算法实现液压支架自动化后工况的分类。首先,通过量化自动化后人工调控工况出现频次,证明了目前智采工作面人工干预程度较高。然后,利用大数据挖掘技术,对比分析自动化后人工操作工况数据与正常工况数据,深入挖掘智采工作面生产过程数据中蕴含的自动化后人工控制行为逻辑,找到自动化后人工干预工况数据规律。最后,运用机器学习算法,根据自动化后人工干预工况数据规律,通过相关性分析得到自动跟机前后推移油缸行程变化量、自动跟机拉架距离、采煤机位置支架号与被判断支架号绝对差值3 个特征值,结合实际生产过程数据量与实时性需求,提出基于决策树算法的智采工作面液压支架集群自动化后工况分类模型,智能识别需人工调控液压支架架号。模型实例化结果表明,决策树算法的测试集准确率为93.75%,与KNN、SVM 与LR 等分类算法相比,决策树算法的准确率高,泛化能力强,拟合能力强,说明基于决策树算法的分类模型可以很好地区分液压支架自动化后的正常工况与人工调控工况,为帮助工人快速定位自动化后人工调控液压支架架号提供了新的理论基础。
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
煤(2022年4期)2022-04-07
防爆电机(2022年1期)2022-02-16
河北画报(2021年2期)2021-05-25
煤矿现代化(2021年3期)2021-05-21
煤炭工程(2021年3期)2021-03-26
煤矿机电(2019年6期)2020-01-13
电子技术与软件工程(2019年15期)2019-12-03
汽车零部件(2019年7期)2019-08-16
民用飞机设计与研究(2019年2期)2019-08-05
