
考虑多气象因子累积影响的光伏发电功率预测
2022-11-09 01:26邱桂华何引生邱楠海钱美伊
广东电力 2022年10期
邱桂华,何引生,邱楠海,钱美伊
(1.南方电网广东佛山供电局 广东 佛山 528000;2. 烟台海颐软件股份有限公司,山东 烟台 264000)
光伏发电具有高效、低污染、安全便利等特点[1],近年来,光伏发电功率预测成为了国内外的研究热点。由于光伏发电具有间歇性和随机性,大规模的光伏并网可能会影响到电力系统的稳定性与安全性[2]。高精度的光伏发电功率预测可以提供功率的瞬变信息,对保障电网平稳运行、优化电力系统调度具有重要的意义[3]。
国内外针对光伏发电功率预测做了大量研究。文献[4]使用K-means聚类算法和改进多输出支持向量机(support vector machine,SVM)模型预测光伏发电功率,并计算了3种数学相关系数;但该算法模型相对简单,预测精度有待提升。文献[5]提出了基于森林模型的光伏发电功率(forest for photovoltaic power generation, FPPG)预测方法,通过集成多个回归树,构建森林模型预测光伏发电功率;但该方法选择的模型种类相对单一,挖掘的特征信息不够完善,因而预测精度欠佳。文献[6]详细分析了辐照度、天气类型、气温等多种气象因子对光伏发电站输出功率的影响,但是并未对光伏发电功率进行预测。文献[7]使用了基于高斯核函数的SVM和长短期记忆(long short-term memory,LSTM)算法,并将二者的预测结果与深度置信网络(deep belief networks,DBN)级联,进一步训练DBN模型,提升了光伏发电功率预测精度,但整体的训练速度较为缓慢。文献[8]用门控循环单元(gate recurrent unit,GRU)模型代替LSTM模型,引入注意力机制优化GRU,并使用粒子群优化(particle swarm optimization,PSO)算法调整神经网络的超参数,在一定程度上提升了运行速度。文献[9]集成Mean-shift算法和层次聚类,并使用极限梯度提升(extreme gradient boosting,XGBoost)算法预测光伏发电功率,运行速度较快,但是计算效率仍有待提升。文献[10]使用了集合经验模态分解,将1条光伏发电功率曲线分解为多组本征模态分量,各分量分别采用PSO算法优化的LSTM实现训练与预测,最后将各分量的预测结果累加;但模态分解可能会产生预测误差的累积问题,从而导致该方法预测精度欠佳。文献[11]使用K-means++聚类算法划分训练集,计算相关系数选取气象因子,使用基本的卷积神经网络(convolutional neural networks,CNN)提取二维气象矩阵特征,并且用CNN的预测结果修正LSTM的预测值;但该方法中LSTM的训练、预测耗时长,除此之外,基本的CNN结构较为简单,提取特征的丰富度有待完善。
基于上述文献存在的不足,本研究提出考虑多气象因子累积影响的光伏发电功率预测方法:首先,采用皮尔逊相关系数法,筛选关联气象因子,并基于余弦距离改进的K-means++聚类算法,将训练数据集高效地划分为K个类簇;其次,在第1路预测中,考虑到光伏发电可能会受到近期气象因素的影响,构造二维气象矩阵,并输入柯西变异改进的特征金字塔网络(feature pyramid network,FPN)模型(采用柯西变异策略优化FPN目标函数,一定程度上可防止神经网络陷入局部最优解),提取二维气象矩阵的深层融合特征,从而挖掘气象因子对光伏发电功率的累积影响;接着,在第2路预测中,训练高效的轻量梯度提升机(light gradient boosting machine,LightGBM)算法模型,并借鉴集成学习的思路;最后,将第1、2路预测的结果按照(1-0.618)∶0.618的比例加权求和,作为最终的光伏发电功率预测值。
1 筛选关联气象因子与优化聚类
1.1 皮尔逊相关系数筛选关联气象因子
对光伏发电可能造成影响的因素主要包括太阳能电池板的装机容量,以及各种类型的气象因子,例如辐照度、天气类型、湿度、PM2.5、气温等。将上述各项指标数据按照时刻对齐后,计算各影响因子与光伏发电功率之间的皮尔逊相关系数[12],判断各类影响因子与光伏发电功率的相关关系,从而筛选机器学习模型所需要的各项关联气象因子[13]。皮尔逊相关系数
(1)

此处相关系数阈值设置为0.3,只保留|r|≥0.3的气象因子,将其作为关联气象因子。
1.2 基于余弦距离的K-means++聚类
K-means算法是基于划分的常规聚类算法,其目的是将对象集划分为若干个类簇,每个簇内数据的相似度较高,而簇间数据的相似度则较低。K-means算法具有原理简单、收敛快速的优点,但是其聚类效果可能会受到初始聚类中心的影响;因此,本研究采用K-means的改进算法——K-means++算法[11]为基线,对影响光伏发电功率的各项因子进行聚类。
由于本文所提算法使用的数据集样本数据量大,气象因子种类较多,为了提高计算效率,将原K-means++算法中的欧式距离度量指标替换为余弦距离[14],余弦距离
(2)
式中:x、y为数据集的任意2个样本,二者均为具有相同维度的N维向量;xn、yn分别为向量x、y当中每个维度的数值。计算的余弦距离d(x,y)取值范围为[0,2]:d(x,y)越接近0,说明向量x与y越近似;d(x,y)越接近2,说明向量x与y的差异越大。
采用余弦距离改进的K-means++聚类算法的计算步骤如下:
a)输入数据集合C、聚类个数K。
b)从集合C中随机选取一个点c1,作为第1个聚类中心向量。
c)使用式(2)计算集合C中的第j个向量xj到聚类中心的余弦距离d(xj)。对距离的平方求和,可以得到∑d2(xj)。
d)计算每个点被选为下一个聚类中心的概率P,
(3)
e)生成[0,1]内的随机数ρ,用ρ依次减去P(1),P(2),…,P(j),得到差值首次不大于0的P(j),将其对应的点作为下一个聚类中心。
f)重复步骤c)—步骤e),可以找到K个初始聚类中心{ck},k=1,2,…,K。
g)计算集合C中每个点到各初始聚类中心ck的余弦距离,找到距离最近的聚类中心,将该点划分到对应的子集合中。
h)计算各子集合的均值,并用该均值更新聚类中心。使用
(4)
计算误差平方和。
i)重复步骤g)—步骤h),直至误差平方和E收敛。
经过上述步骤,将筛选后的数据集高效地划分为K个子簇,每个子簇内的变量具有相近的特性,这利于后续机器学习算法模型更好地拟合训练数据,进而提升预测效果。
2 改进FPN挖掘多气象因子累积影响
光伏发电功率可能受到短期内多气象因子的累积影响,因此需要设计算法挖掘关联气象因子对光伏发电功率的累积影响。首先,构建二维气象矩阵,并将其送入FPN模型,生成多层级融合的气象特征图。采用柯西变异策略优化FPN的目标函数,在一定程度上可以防止神经网络陷入局部最优解。
2.1 关联气象因子构建二维气象矩阵
在使用聚类算法得到的每个子簇内,将间隔15 min采样得到的关联气象因子(如辐照度、PM2.5、气温等)历史数据,按照时间先后排序对齐,构造二维气象矩阵,如图1所示。

图1 二维气象矩阵
在图1的二维气象矩阵中:每一列代表不同的气象因子种类(比如辐照度、天气类型、湿度、PM2.5、气温等),以及光伏装机容量;每一行代表同一时间的数据。通过构建二维气象矩阵,模拟CNN的输入样本图像,即是将二维气象矩阵中的气象数据当作样本图像各个位置的像素值,并使用卷积核计算特征图。由于装机容量对预测结果有较大的影响,需要在气象矩阵最后一列增加对应时刻的装机容量。
2.2 FPN挖掘多气象因子累积影响
以CNN为代表的深度学习算法,凭借卓越的性能成为计算机视觉领域的主流算法之一。CNN内部采用了局部连接和参数共享,具有强大的特征自提取能力,可以充分提取二维数据所蕴含的特征信息。
作为CNN的一种改进算法,FPN[15]算法能够提取多层级的融合特征图,该特征图兼具低层级的细节特征以及高层级的深层语义特征,从而显著提升CNN的性能。FPN算法流程如下:首先,设置3个卷积阶段,在每个卷积阶段内,都含有卷积层、激活层和批量归一化层等;在相邻的卷积阶段之间,采用池化操作实现特征图尺度的下采样;得到各个卷积阶段的输出特征图之后,按照由深层至浅层的顺序,依次放大特征图的尺度,至与相临较低层级的特征图具有相同尺度,并对二者执行加法操作;经过上述迭代计算,可以得到FPN多层级融合特征图。
在本文提出聚类算法划分的各个子簇中,分别训练不同的FPN算法模型:将各个时刻的光伏发电功率作为训练目标,将各个时刻与之前3个连续时刻内的二维气象矩阵(含有各个时刻的装机容量)作为输入,通过监督学习的方法训练FPN模型,从而确定其各项参数。在预测过程中,根据即时气象因子找到对应的类簇,并将待预测时刻以及之前连续3个时刻内的二维气象矩阵输入该类簇的FPN模型,从而得到考虑多气象因子累积影响的光伏发电功率预测值。
2.3 柯西变异优化的FPN目标函数
原始的FPN算法是为计算机视觉领域的目标检测任务而设计的,其目标函数包含分类损失函数和边界框回归损失函数,而本研究只需要预测光伏发电功率数值;因此,本文提出算法只需使用其中的smooth L1损失函数来训练算法模型。损失函数
(5)
式中e为训练误差。
神经网络的训练采用的是梯度下降法,这可能会陷入局部最优解,而忽略全局最优解。为此,本研究引入柯西变异策略[16]来优化FPN的目标函数,这样可以使得神经网络的动态回调过程中,具有相对更宽泛的搜寻范围,从而提升全局寻优能力。以原点为中心的标准柯西分布的概率密度函数
(6)
式中Θ为标准柯西概率分布函数中的自变量。
柯西分布是一种连续的概率分布,其概率密度函数在原点处的取值相对较小,函数图像的两端较为扁长,接近0的速率也相对较慢,有利于产生更大的扰动。引入柯西变异策略后,FPN的目标函数改进为
(7)
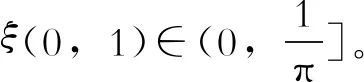
3 考虑多气象因子累积影响的光伏发电功率短期预测
3.1 LightGBM光伏发电功率即时预测
实时气象因子对光伏发电功率的影响非常明显,因此,需要挖掘光伏发电功率与即时气象因子之间的关系。LightGBM[17]算法属于集成学习中的梯度提升决策树算法,其前身XGBoost算法的每次迭代需要遍历整体训练数据多次,无法满足海量数据的扰动分析需求。与之相比,LightGBM算法采用多线程并行、直方图加速算法,并采用单边梯度采样、互斥稀疏特征绑定来预处理数据。其使用了带深度限制的Leaf-wise生长策略,在减少计算时间的同时,可以有效防止过拟合现象,提升预测准确率。XGBoost、LightGBM算法训练过程的可视化对比如图2所示。
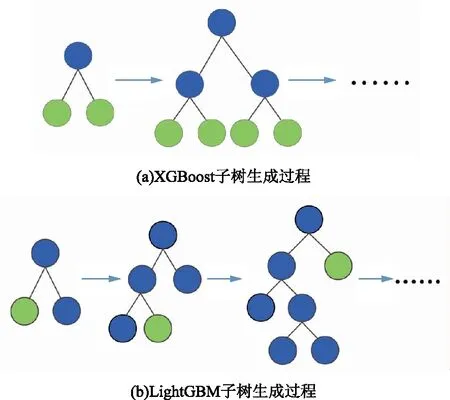
图2 XGBoost与LightGBM的可视化对比
由图2对比可知,LightGBM算法在每次迭代时只增加1个叶子结点,而XGBoost需要增加1层叶子结点,因而LightGBM相对更快速。LightGBM算法的详细实现过程如下:
a)LightGBM算法在第t次迭代时的优化目标是获得弱学习器ht,它能够使本次迭代损失函数
L(φi,Ft(θi))=L(φi,Ft-1(θi)+ht(θi))
(8)
最小,式中:θi为第i个样本数据的因变量部分;φi为第i个样本数据的训练目标;ht(θi)为第t次迭代得到的弱学习器ht对第i个样本的预测值;Ft(θi)、Ft-1(θi)分别为第t、t-1次迭代得到的强学习器Ft、Ft-1对第i个样本的光伏发电功率预测值。
b)利用上一次强学习器损失函数的负梯度,拟合本次迭代弱学习器训练目标的近似值。第i个训练样本经第t次迭代后的负梯度
(9)
c)使用平方差函数近似拟合ht(θi),
(10)
式中:hct为第t次迭代生成的各个候选新弱学习器;Ht为hct构成的集合;hct(θi)为新弱学习器hct对第i个样本的预测值。
d)得到第t次迭代生成的弱学习器ht,并最终得到第t次迭代生成的强学习器Ft,其与上一次迭代的强学习器Ft-1之间满足
Ft(θi)=ht(θi)+Ft-1(θi).
(11)
在本文提出聚类算法划分的每个子簇内,将各个时刻的光伏发电功率作为训练目标,将与之关联的气象因子、装机容量作为模型输入,分别训练不同的LightGBM算法模型。在预测时,根据即时气象因子找到对应的类簇,并向该类簇的LightGBM模型输入即时关联气象因子和装机容量,从而预测即时光伏发电功率。
3.2 考虑多气象因子累积影响的光伏发电功率预测
本文提出的考虑多气象因子累积影响的光伏发电功率预测的总体流程如图3所示。
如图3所示,首先获取各个光伏发电站的历史真实光伏发电功率、装机容量、各项候选气象因子。采用皮尔逊相关系数法,筛选光伏发电的各项关联气象因子。基于余弦距离的K-means++聚类算法,将训练数据集高效划分为K个子簇,在每个子簇当中,分2路预测短期光伏发电功率:在第1路预测中,使用关联气象因子构建二维气象矩阵,并送入改进的FPN模型,提取气象矩阵的深层融合特征,修改原始FPN损失函数,并引入柯西变异策略优化FPN损失函数,辅助神经网络跳出局部最优解;在第2路中,训练LightGBM算法模型,实现光伏发电功率的即时预测。最后,借鉴集成学习的思路,将上述2路预测值按照黄金分割比(1-0.618)∶0.618的比例加权求和,得到最终的光伏发电功率预测值,实现本文提出的考虑多气象因子累积影响的光伏发电功率预测方法。
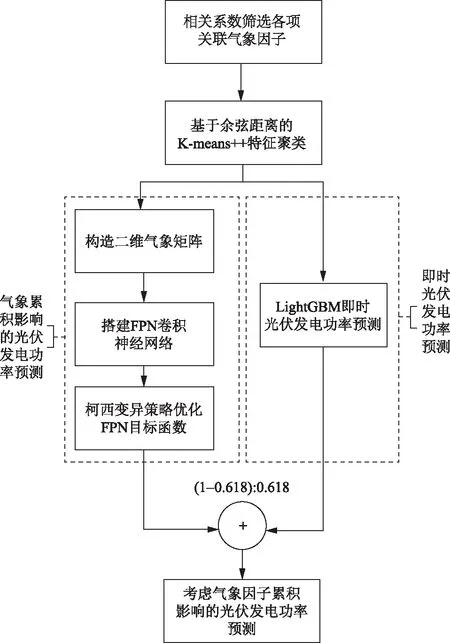
图3 本文提出的算法流程
4 实验分析
4.1 实验环境与数据获取
为完成本研究的实验内容,使用的服务器信息如下:硬件配置方面,CPU为Intel Xeon E5-2678 2.50 GHz,GPU为NVIDIA GeForce GTX 1080 Ti,内存容量32 GB,硬盘容量10 TB;软件环境方面,操作系统为Linux Ubuntu 21.04,编程语言为Python语言,Python库为Anaconda3,Python版本号为3.6.5,数据库为Oracle 11g Server。
本实验使用的数据为某地级市内的数十个供电所光伏发电相关数据,主要包括光伏发电功率、太阳能电池板的装机容量、各项候选气象因子等。其中,光伏发电功率、装机容量来自于数据采集与监视控制系统(supervisory control and data acquisition,SCADA)和配电管理系统(distribution management system,DMS),各项气象数据主要来自于互联网的气象数据接口。实验数据的时间范围为2021年3月至10月共8个月,数据的采样时刻点间隔为15 min。由于分布式光伏的数据量相对较大,为保证脚本程序运行的流畅性和稳定性,使用大型Oracle 11g数据库实现相关数据的读写与存储。通过多组对比实验,比较各项算法在不同气象条件下的预测效果和精度,以验证本文提出方法的有效性和可行性。
4.2 数据分析与处理
可能影响光伏发电功率的候选气象因子有辐照度、气温、湿度、PM2.5、天气类型、大气压强、风速、风向、降水量。将光伏发电功率与各项候选气象因子根据时间对齐,然后计算皮尔逊相关系数,结果见表1。
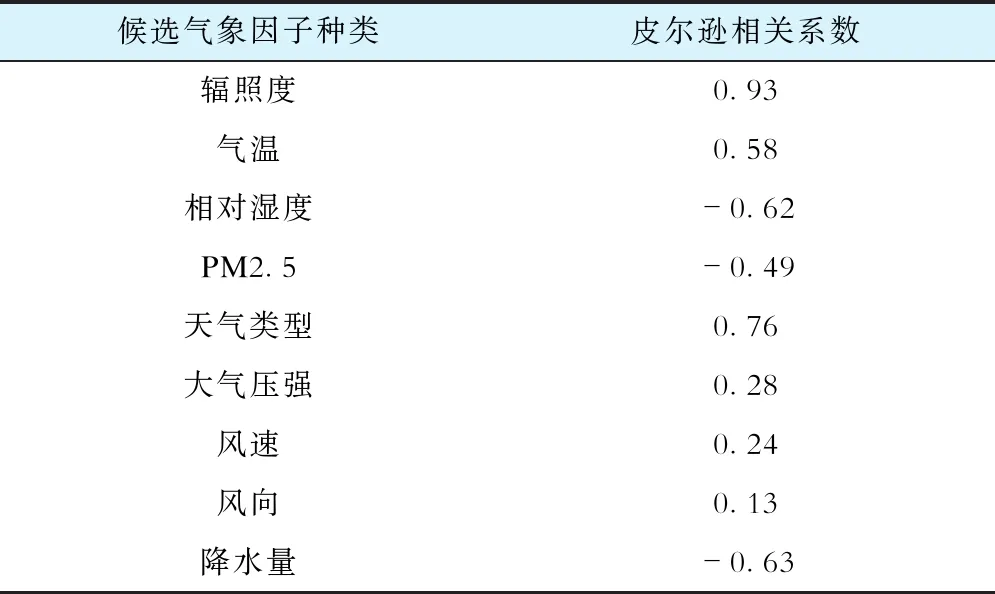
表1 候选气象因子的皮尔逊相关系数
由表1可知:在众多候选气象因子中,辐照度与光伏发电功率之间的皮尔逊相关系数为0.93,二者具有最强的相关关系;风向与光伏发电功率的皮尔逊相关系数为0.13,二者之间的相关性最弱。只保留皮尔逊相关系数绝对值不小于0.3的对应气象因子,得到筛选后的关联气象因子有辐照度、气温、湿度、PM2.5、天气类型、降水量。使用筛选后的关联气象因子、光伏装机容量,作为聚类算法和机器学习模型的输入数据。
为了实现光伏发电功率与各项关联气象因子的变化关系可视化,以辐照度为例进行分析。按照时间维度,选取连续多天的辐照度、光伏发电功率数据,对比结果如图4所示。
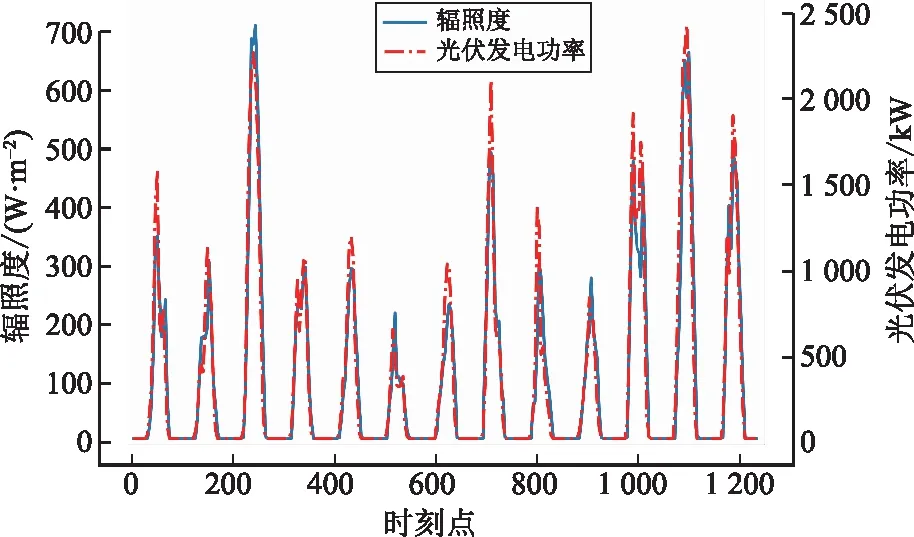
图4 光伏发电功率与辐照度总体对比
由图4可知,辐照度与光伏发电功率的变化趋势非常接近,具有较强的相关性。选取其中的2日数据深入分析,对比结果如图5所示。

图5 光伏发电功率与辐照度详细对比
结合图4、图5可以看出,虽然光伏发电功率与辐照度的大致走势相近,但是在局部位置还是存在不少跳点,例如点54、点61、点65、点140、点150和点153等。为得到光伏发电功率与各项关联因子的复杂变化关系,构建相关的机器学习算法模型,自主学习该复杂关系。
将筛选后的各项关联气象因子、装机容量,输入改进的K-means++算法,得到K个类簇。由于需要预先给定K-means++算法的类簇数量K,因此采用戴维森堡丁指数(Davies-Bouldin index,DBI)指标来评估聚类效果,从而确定最优聚类数量K。DBI指标
(12)
其中
(13)


表2 不同聚类数的DBI指标
由表2可知,当聚类数量K值取4,对应的DBI指标最小为1.40,说明这时的聚类效果最好;因此,在本研究实验中,将使用余弦距离改进的K-means++算法聚类个数设置为4。
4.3 预测效果对比
选取具有代表性气象特征的2日测试数据进行对比分析。改进的K-means++聚类算法将筛选后的数据集高效划分为4个类簇后,分别使用基线算法、各项改进算法实现预测,并将预测结果可视化。
以某供电所2021年9月4日为例,当天的天气类型为晴转阴,辐照度数据如图6所示,可知:当天辐照度最大值为800 W/m2;上午的辐照度相对较高,为晴天;下午的辐照度相对较低,为阴天。

图6 待预测日的辐照度(晴转阴)
该供电所当天的光伏发电功率预测结果如图7所示,图中Actual表示光伏发电功率真实值,FPN表示只使用FPN算法预测多气象因子累积影响的光伏发电功率,FPN-C表示单独使用柯西变异优化的FPN预测结果,LightGBM表示只使用LightGBM算法预测即时光伏发电功率,Proposed表示本文所提预测算法的结果。
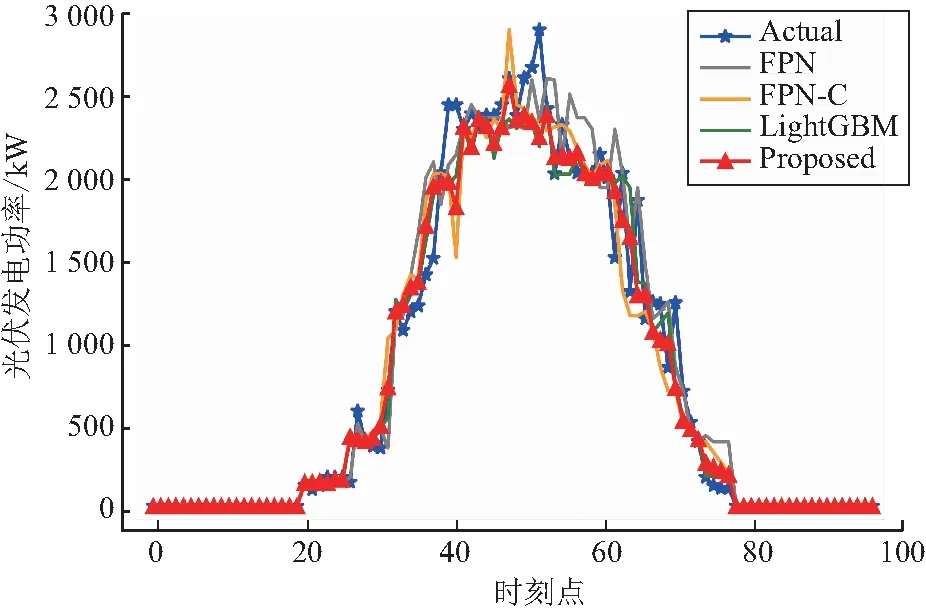
图7 光伏发电功率预测对比(晴转阴)
由图7可知:上午的光伏发电功率相对较高,最大值约2 500 kW;下午的光伏发电功率相对较低,最大值约为2 000 kW。从整体上来看:单独使用FPN算法在光伏发电功率实际值突变情况下的预测欠佳,其预测结果最不符合真实功率;单独使用柯西变异优化的FPN预测效果有所提升;单独使用LightGBM算法的预测效果也相对较好;与其他各项算法相比,本文提出的算法预测值最符合实际值,具有最好的预测效果。
以某供电所2021年8月9日为例,当天的天气类型为中雨,辐照度数据如图8所示,可知当天的辐照度最大值为175 W/m2,上午的辐照度相对较高,下午的辐照度相对较低。

图8 待预测日的辐照度(中雨)
该供电所当天的光伏发电功率预测结果如图9所示,可知:上午的光伏发电功率相对较高,最大值约550 kW;下午的光伏发电功率相对较低,最大值约300 kW;单独使用FPN预测时,在上午、下午的几个时刻的预测结果出现明显偏离,预测效果相对较差;单独使用柯西变异优化的FPN预测效果有所改善;而单独使用LightGBM的预测效果相对较好;与各项对照算法相比,本文提出的算法具有最好的预测效果。

图9 光伏发电功率预测对比(中雨)
4.4 预测精度对比
使用2021年3月至8月的数据作为训练集,使用2021年9月、10月的数据作为测试集。分别使用平均相对误差(mean relative error,MRE)、均方根误差(root mean square error,RMSE)来计算光伏发电功率的预测精度。平均相对误差
(14)
均方根误差
(15)
式(14)、(15)中:Ppi为第i个时刻的光伏发电功率预测值;Pti为第i个时刻的光伏发电功率真实值;I为时刻数。
在测试集中对比各项改进算法和本文所提算法的精度,结果见表3,表中Proposed-no-K表示本文所提但不使用聚类算法的预测结果。

表3 各项算法的预测精度对比
由表3可知:①从平均相对误差来看,本文所提但不使用聚类算法的方法精度最低,为84.23%;单独使用FPN预测光伏发电功率的精度稍好,为85.37%;单独使用柯西变异优化的FPN预测精度有所提升,为86.24%;单独使用LightGBM算法的预测精度较好,为87.56%;而使用本文提出的光伏发电功率预测算法具有最高的精度88.12%。②从均方根误差来看,本文所提但不使用聚类算法的方法精度最低,为77.12%;单独使用FPN的精度稍好,为78.11%;单独使用柯西变异改进的FPN精度提升至79.13%;单独使用LightGBM算法的预测精度相对较好,为81.54%;与上述算法相比,本文提出的算法具有最高的预测精度,为82.03%。
综上,分别从平均相对误差、均方根误差来看,与各项对照算法相比,本文提出的考虑多气象因子累积影响的光伏发电功率预测算法都具有最好的预测精度。
5 结束语
本文提出了考虑多气象因子累积影响的光伏发电功率预测方法,主要内容有:
a)使用余弦距离改进的K-means++聚类算法,将含有关联气象因子的数据集进行高效分簇。
b)在每个子簇中,构建二维气象矩阵,并送入FPN模型提取深层融合特征。损失函数引入了柯西变异策略,辅助神经网络跳出局部最优解。
c)借鉴了集成学习思想,将改进FPN、LightGBM的预测结果按黄金分割比(1-0.618)∶0.618加权求和。
由实验结果可知,本文提出的方法与各项对照算法相比,在各种天气情况下具有较好的预测效果。
猜你喜欢
作文周刊·小学一年级版(2022年24期)2022-06-18
软件导刊(2018年11期)2018-11-19
现代计算机(2018年27期)2018-10-25
领导决策信息(2018年46期)2018-04-20
舰船电子对抗(2017年6期)2018-01-11
山东工业技术(2017年17期)2017-09-13
中国建筑科学(2017年6期)2017-07-20
风能(2016年8期)2016-12-12
互联网天地(2016年1期)2016-05-04
