
一种面向产品模型管理的PLMM接口实现方法
2022-11-08 06:27:38岳继光邹鸿宇吴琛浩王萍刘军
中国工程机械学报 2022年5期
岳继光,邹鸿宇,吴琛浩,王萍,刘军
(1.同济大学电子与信息工程学院,上海 201804;2.山东山大华天软件有限公司,山东 济南 250102)
为适应企业产品的网络协同制造需求,一些公司研发了产品全生命周期管理(product lifecycle management,PLM)系统[1]。其友好的用户界面、涵盖的功能组件、丰富的基础模块,为企业内部和相关企业之间的产品协同研制提供了便利。
近年来,随着产品高效研制要求的不断提高,基于数据与文档的PLM系统越来越难以满足企业高质量敏捷制造的要求。现代制造业希望能够在PLM系统基础上,加大产品深层次协同力度,缩短研发周期,推演预测产品研制状况,实现跨单位、跨部门、跨层次的产品高效管理。因此,将具有解释内在属性、描述内涵知识、反应研制流程的产品模型融入PLM系统[2],进而形成产品全生命周期模型管理(product lifecycle model management,PLMM)系统,对实现高层次的产品协同制造具有创新性。
PLMM系统是一种新的产品管理解决方案。在保留了PLM“前台人机交互”方式的同时,还提供基于产品模型的“中台”支持。PLM基于产品“文档+数据交互”模式,提升到基于“模型”的产品属性交互、模型协同、仿真推演乃至数字孪生的高层次联动研制,是产品由“碎片化”数据管理转型到“体系化”模型知识管理的有效途径。
产品研制类的软件系统管理的特点是文件交互。为将PLM系统高效地转变为PLMM系统,其焦点是高效地处理涉及产品信息的文件。然而人工很难胜任非结构化的文件文本数据处理[3],自动化、智能技术手段的运用和应用文本数据的挖掘技术成为产品管理的关键部分之一[4]。本文提出一个基于“产品模型文件包”的“文本关键词特征联合预测算法”,实现面向协同研发的PLMM接口。
1 产品生命周期协同研发
产品的协同研发是先进制造技术中并行工程运行的核心[5-6]。将数据转化为能够影响产品性能的决策信息成为国内外工业管理的共识,Siemens的HD-PLM框架为大规模、分布广泛、来源不同的数据赋予意义[7],Solid Works Enterprise基于全产品线搭建产品生命周期解决方案[8],如华天PLM、武汉开目、数码大方、艾克斯特、上海思普等国内厂商,以产品数据为基础,以知识库为核心,建立工艺设计与管理的软件数据信息集成平台[9]。
在PLMM平台上的协同研发,指通过PLMM完成产品的高质量、高效研发。要使产品利益攸关者高效的协同工作,需要建立准确、快速、高质量地信息交换和相互协同机制[10]。因此,构建面向协同研发的产品模型管理接口就显得十分重要[11-12]。
2 PLMM系统上的模型管理接口
2.1 模型管理接口功能描述
面向协同研发的产品模型管理接口,应满足产品利益攸关者分享相关的产品模型,通过模型来提高协同设计的效率[13]。模型管理包括产品的概念模型、三维设计模型、工程分析模型、过程模型和知识模型的管理。
当前国内产品模型管理体系,例如山东大学华天团队的PLMM系统,如图1所示。在“前台人机交互”层面依然为文件方式,将产品模型涉及的“功能、结构、行为”等要素,表述为“文档、图纸、表单、实物图”等文件类信息,进而“打包”为若干文件,形成“产品模型文件包”。PLMM系统后台,产品模型文件包通过相互关联组织,形成具有结构化、数字化意义的对象,在原型系统相关模型支持的软件层中以模型为基本组成单位被调度和协同。
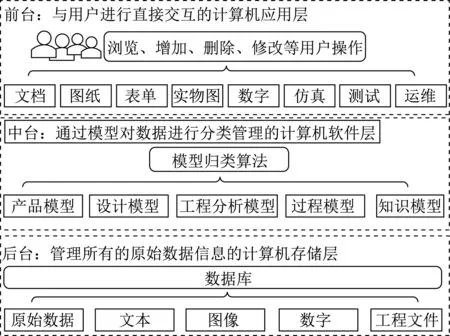
图1 PLMM系统架构Fig.1 Framework of PLMM system
“产品模型文件包”是指与产品概念、设计、采购、生产、销售和售后服务全生命周期6个阶段相关的所有文件,可以通过PLMM平台打开或互联、互通,由产品制造企业及产品利益攸关者在不同时间、不同地点、不同人员、按照不同权限查阅、设计、协同、制造、购置以及运行维护。“产品模型文件包”中的文件名称用规范的编码表示,具体参考产品全生命周期管理平台编码规范,见表1。
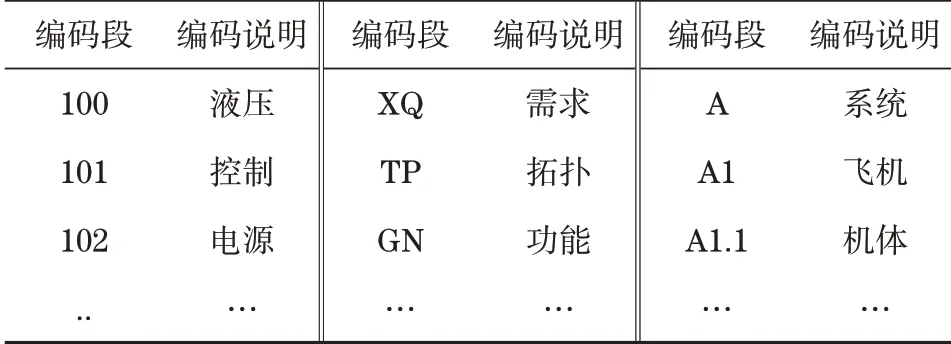
表1 基于模型的PLM平台编码规范Tab.1 Coding specification of PLM platform based on model
PLMM模型接口包括如下功能:①对来自不同领域、不同部门、不同来源、不同结构的“产品模型文件包”进行特征识别;②将产品的概念模型、三维设计模型、工程分析模型、过程模型以及知识模型等组成的“产品模型文件包”进行分类;③根据用户需求意见推送结果;④继续推送直到协同研发结束。
2.2 产品模型管理接口的实现
面向协同研发的PLMM模型管理接口的结构按照输入-活动-输出(input process output,IPO)三元组模式,如图2所示。其输入为“产品模型文件包”,其活动包括产品模型特征识别、提取、属性分类以及协同推送,其输出为产品利益攸关者。
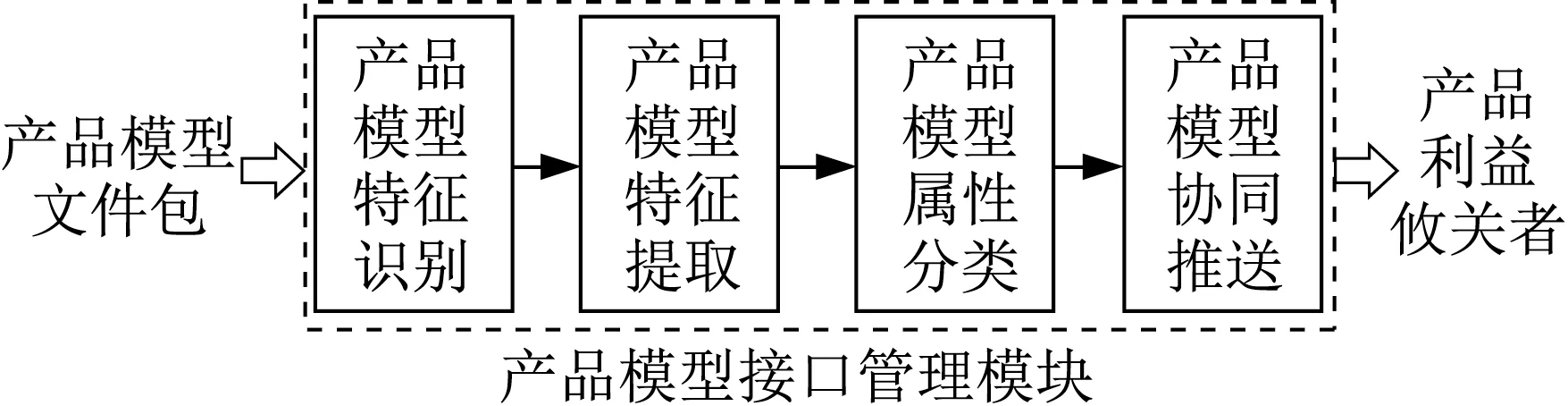
图2 PLMM系统上的产品模型接口结构示意Fig.2 Schematic diagram of product model interface structure on PLMM system
面向协同研发的PLMM模型管理接口的核心是基于中文文本自然语言处理的智能化算法,输入为产品文件包,及其包含文件的文本信息,输出该产品的模型文件包对应的模型类别。其具体步骤如图3所示。
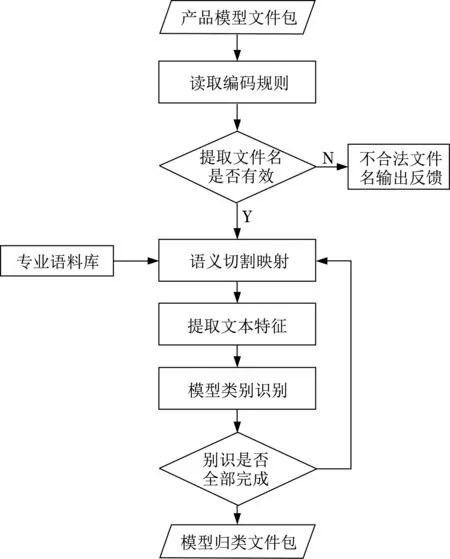
图3 产品模型管理接口算法步骤Fig.3 The procedures of product model management interface algorithm
3 面向某军机后机身平尾控制模拟系统的工程示例
后机身平尾控制系统是军机典型复杂产品,由油源、伺服阀、液压缸、控制电路、连接机构、平尾、传感变送装置以及供电电源等组成,核心是阀控液压缸系统,其方框图如图4所示。
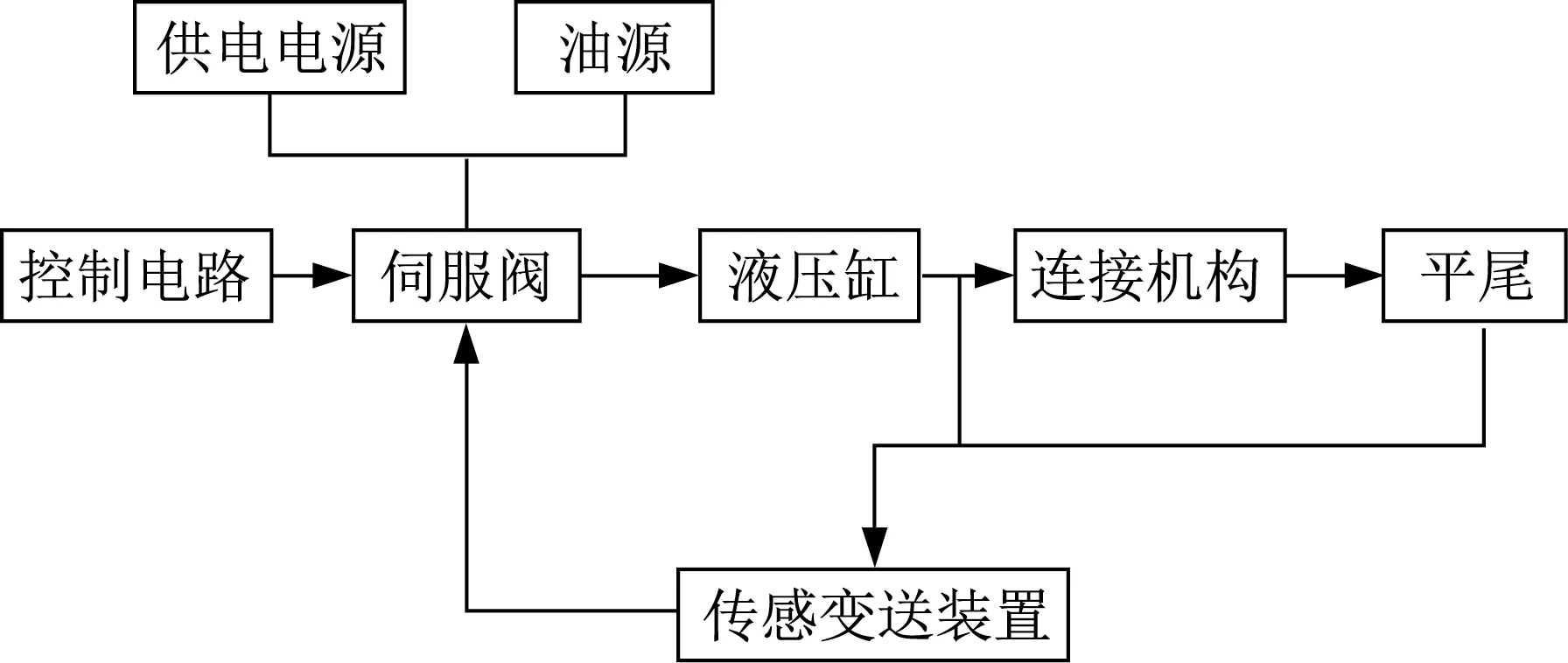
图4 阀控液压缸系统方框图Fig.4 Block diagram of valve-controlled hydraulic cylinder system
其“产品模型文件包”涵盖了如下文件:①基于SysML表达的阀控液压缸系统设计需求、用例、功能、架构、参数约束以及其他文件;②阀控液压缸系统配置、结构、公差和拓扑关系、装配关系和各类BOM等模型文件;③阀控液压缸系统所涉及的机械、电子电气、流体传动等不同学科的仿真模型间的耦合关联关系等模型文件;④表示阀控液压缸系统不同生命周期阶段的模型动态关联的过程模型文件;⑤表示阀控液压缸系统知识获取、知识表示、知识变换、知识重用等知识模型文件。
4 军机后机身平尾控制模拟系统产品模型管理接口的应用
4.1 基于关键字的产品模型文件包管理
产品模型管理接口复杂产品模型,根据模型在管理系统中的组织架构与自身包含的信息,来提取出模型特征,并基于特征预测其产品模型类别。
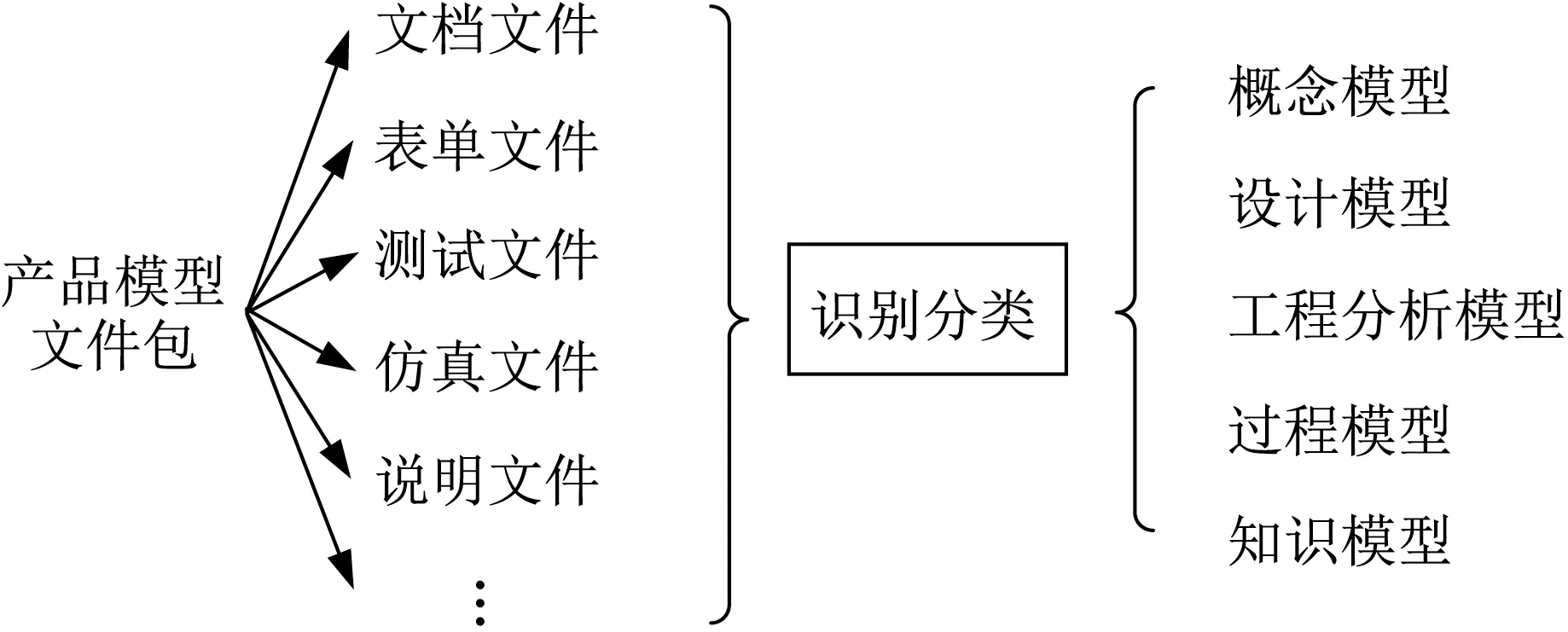
图5 协同接口识别分类功能Fig.5 Identification and classification function of collaborative interface
产品的任意一个模型,在PLMM系统中以“产品模型文件包”的形式呈现给用户,一个“模型文件包”的定义为
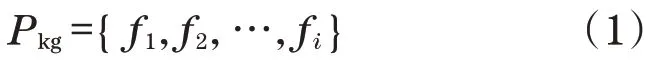
任意一个产品文件包Pkg,其内部包含的诸多文件fi,i的取值范围为[0,∞)。对于任意一个产品模型,最低限度的文件特征是没有文件,而文件数量不设上限,随着产品的研发进行而不断增加。
产品模型文件包的模型类别识别遵循以下步骤:
步骤1文本清洗与正则化匹配。
每个产品模型中的文件信息,使用文本清洗与正则化匹配,与标准编码进行正则匹配,从而剔除不符合工业要求的目标。正则表达式Re为
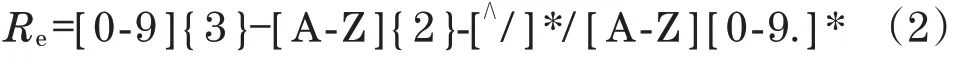
式中:0-9为任意有效阿拉伯数字;{3}为3位有效数字;A-Z为任意有效英文字母;{2}为2位有效字母;[∧/]*为任意多个非反斜杠符号字符的文本,故该正则表达式可匹配任意字段,单字母加数字结尾的编码格式,不同的文件名匹配结果,如图6所示。100-JG-CR32液压缸设计图纸/A1.1中,100匹配[0-9]{3},JG匹配[A-Z]{2},CR32液压缸设计图纸匹配[∧/]*,A匹配[A-Z],1.1匹配[0-9.]*。
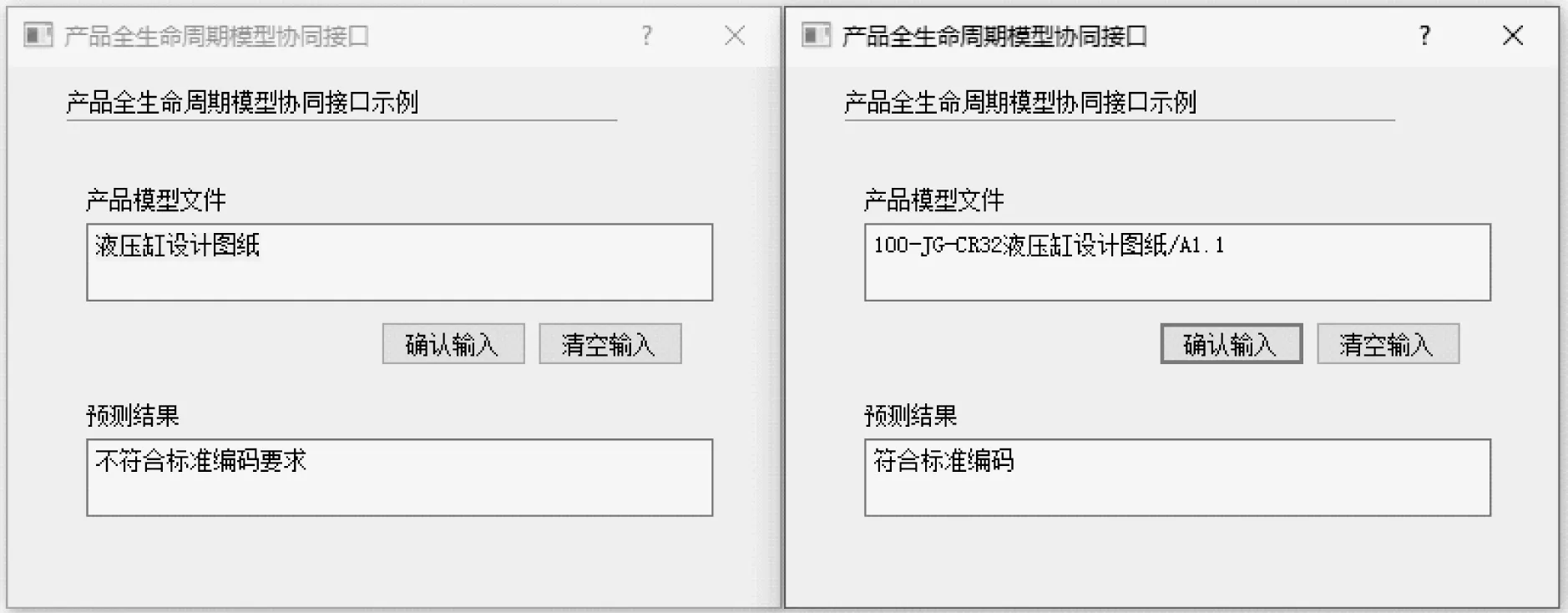
图6 不同的文件名匹配结果Fig.6 The match results of different file names
步骤2特征提取与特征转义。
通过冗余信息的清理和规则匹配来快速从文本中提取有效特征,对符合标准编码格式的文件fi进行特征提取与解析。具体方法为:①载入语料库C,获取语料信息corpus;②读取文件fi的名称Ni;③将Ni与正则表达式Re进行匹配,得到标准编码的结果,即编码段Code、数字段Num、文字段Str;④分别访问corpus中的code、corpus映射区段、num_corpus映射区段,并与Code、Num进行匹配,返回corpus中的映射结果,得到编码特征;⑤遍历Str中的字符,搜索corpus中相同的字符组合,存在复数搜索结果时按照字典序保留,得到文字特征。
对提取的特征属性,使用精确率、召回率、F1-score等5项指标对其效果进行评估,实验效果如图7所示。
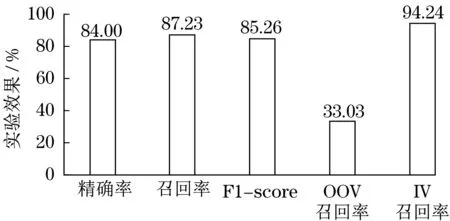
图7 特征提取效果验证Fig.7 Effect verification of feature extraction
通过对军机后机身模拟控制系统中的文本内容的验证,在精确率、召回率、F1-score分数以及已在语料库中的数据(in vocabulary,IV)的召回率上均取得了较好的效果,但是对于未在语料库中的数据(out of vocabulary,OOV),由于OOV的数据量过少,与IV数据的比例存在不平衡现象,所以分数相比于其他指标较低。
步骤3基于关键字的搜索匹配。
从“产品模型文件包”到模型体系需要进行模型类别预测,本文采用语义推理的方法,通过在产品全生命周期词料库wd中,使用不同的关键字组KG对提取的特征进行相似匹配,从而得到产品模型文件包中的模型类别。
预测方程如下:

式中:S()为归一化方程,用于对产品模型文件的相似度向量vsim进行归一化,并得出对应类别的预测分值。其中:

式中:vi为其中一条文件特征与关键字组KGi的查询分值,由于不同的关键字库的体积不一定保持一致,故需要∑KGi保证不同关键字库的大小不会对结果造成影响;Q为其他一条文本的提取特征。
为加强产品模型的预测效果,实现对“产品模型文件包”中信息最大化的利用,在文件信息的基础上,结合文件格式进行协同预测,通过对产品模型文件包的数字化格式信息与文本化语义信息进行访问,对产品模型文件包所属模型类别进行预测:
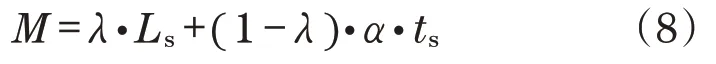
式中:M为产品模型文件包的预测结果与分值;ts为具体文件的文件类型预测分值;α为标准系数,用于保证Ls与ts在同一量级;λ为取值[0,1]的权重系数,用于均衡两者在最终预测中的作用程度。通过对两者的加权评估,使得最终的文件推送能够更准确,如图8所示,不同的λ对预测准确度的效果,如图9所示。
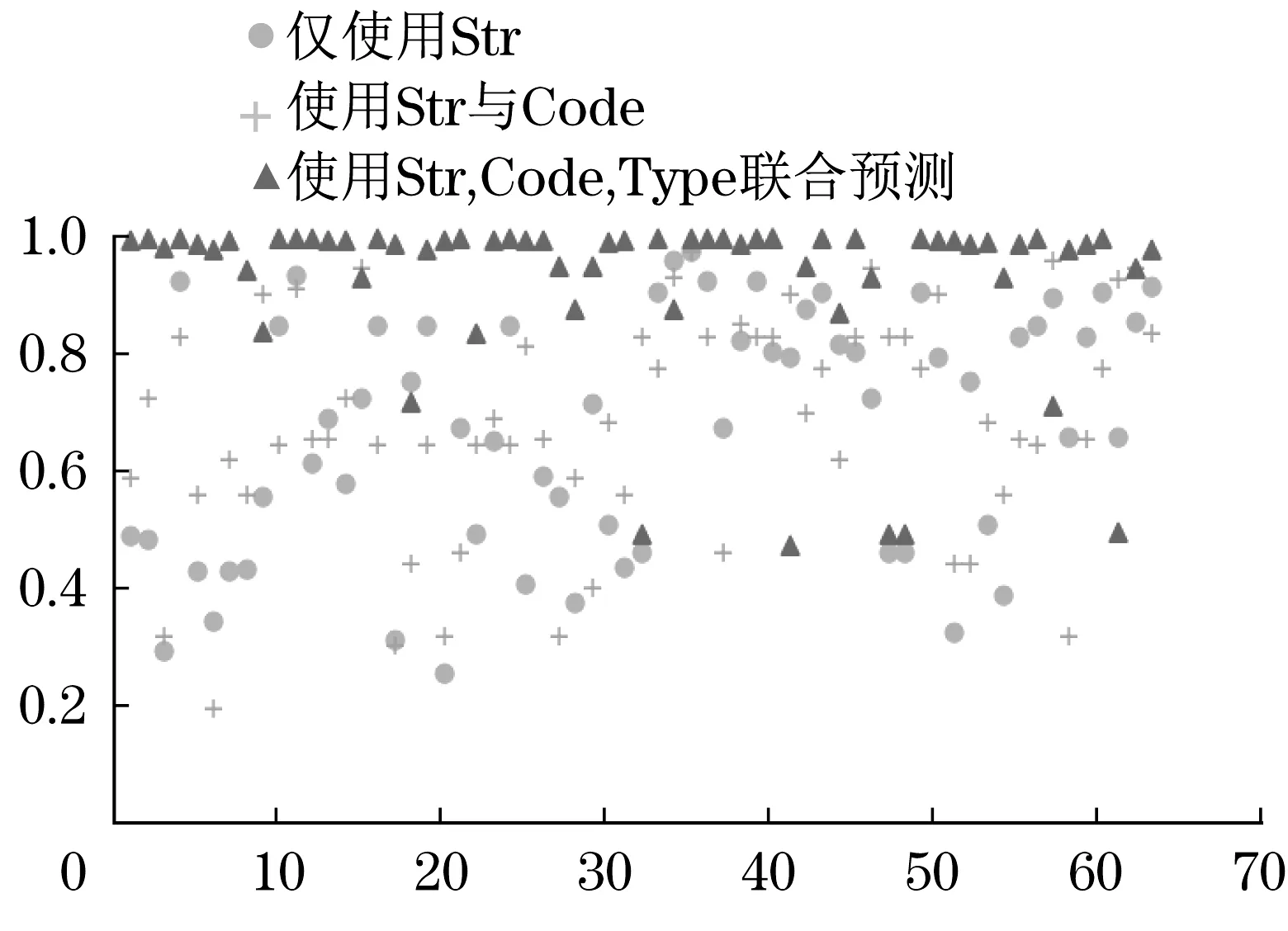
图8 对模型类别的预测分值Fig.8 The forecast score for model category
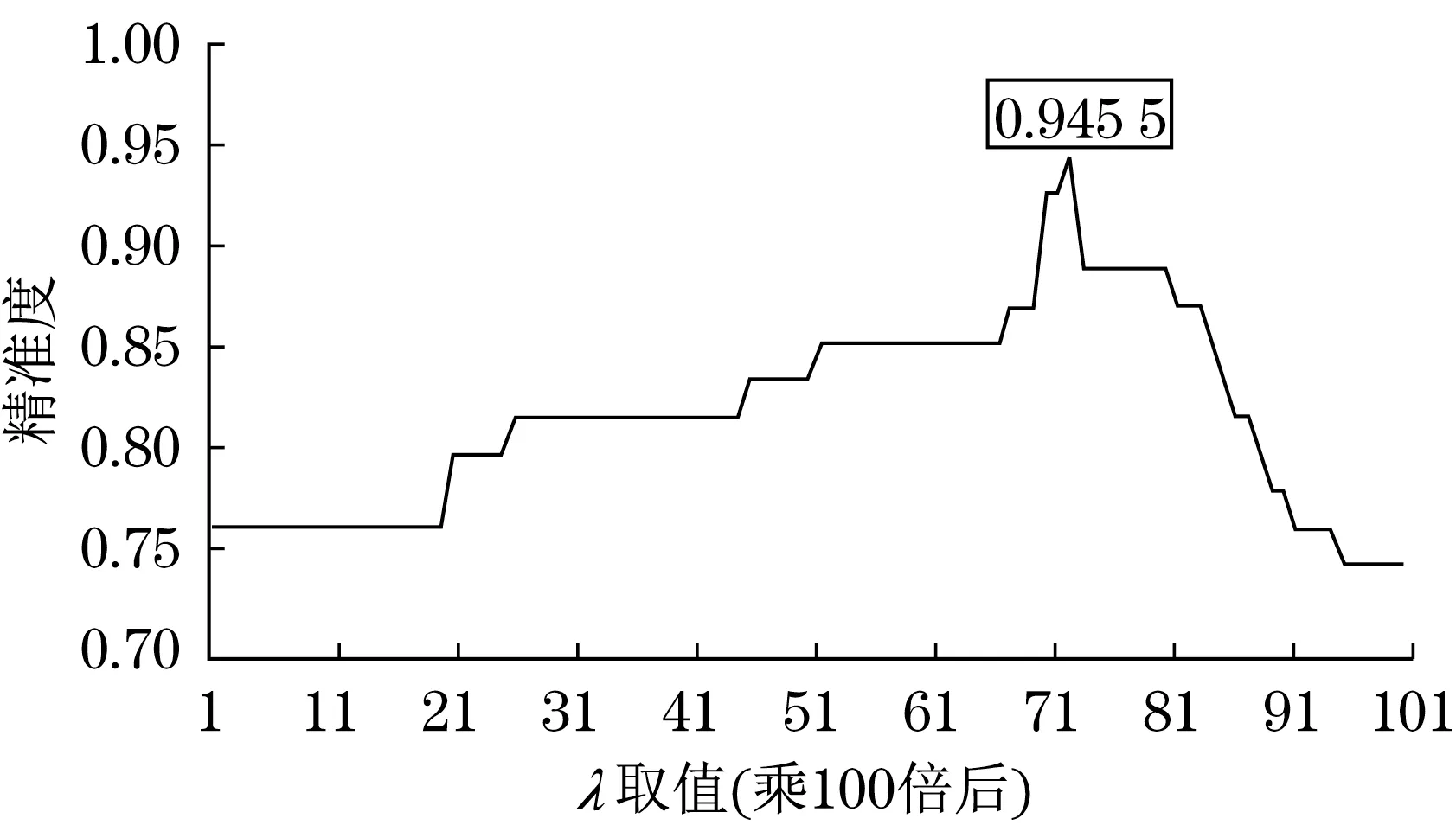
图9 不同λ对预测准确度的影响Fig.9 The impact of different λ on prediction accuracy
通过对“文件包”中大量的异构信息的提取其有效特征的预测,在华天公司PLMM系统中,对图10所示的文件系统进行模型类别预测,通过文本关键词特征联合预测算法的结果形成了图11中按模型类别的分类视图,从结果上来看,类似的内容会被归类到其关联的模型类别中,实现文档到模型的接口功能之一。
图10 PLMM系统中的文件管理Fig.10 Documents management in PLMM
图11 PLMM中按照模型类别管理Fig.11 Management method through model type in PLMM
4.2 基于用户需求的协同资源管理
对于PLMM系统的用户而言,协同管理接口需要解决模型与产品利益攸关者的索引难题。协同管理接口的用户视角可以被视为如下的IPO结构,如图12所示。其中,输入为用户/利益攸关者在产品研发过程中的工程需求信息,不遵循固定规范,多为自然语言或关键词的组合。处理环节中协同管理接口识别需求,从产品模型文件包资源数据库中快速搜索与需求相匹配的资源数据。输出为工程师需要的资源。

图12 协同接口需求分析功能IPO结构Fig.12 The IPO structure of collaborative interface
在对用户输入需求信息前,检查产品模型数据库是否建立了协同接口的索引,若未建立索引,则执行数据库的搜索引擎初始化过程。
对每一个Pkg中的产品文件fi,使用中文分词算法,将f划分为多个独立的中文词语,建立索引对象dxi={title,context}。其中,title为协同推荐引擎推荐的标题,context为协同推荐引擎推荐的实际内容。对于每个产品模型,有

式中:text(x)为对象x的文本内容。通过遍历所有产品模型文件包,可以得到当前搜索引擎的索引
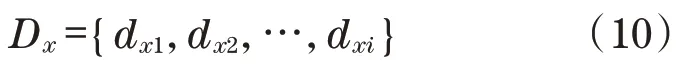
在已有数据库索引的基础上,对用户的非结构化输入In,使用特征提取算法,得到其关键需求词汇wdi组成的需求组N。
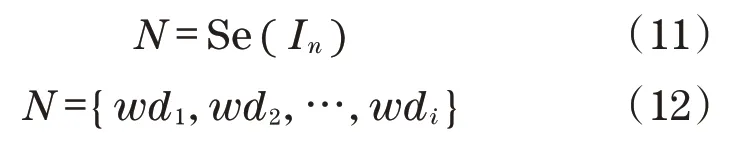
式中:Se为前文中的特征提取方法,通过对中文文本进行切分得到关键词汇信息wdi。每一个关键词汇会在搜索引擎中进行索引匹配,优先在title中获取返回结果,其次对context进行二次访问,得到推荐的资源和结果,在一定条目限制下,推荐的资源会被组合在一起,向提出需求的用户展示。当用户对推荐的资源进行一定了解后,如果产生新的需求,则可以再次通过搜索引擎输入新的需求信息,来得到更准确、更符合用户需求的推荐结果。根据用户需求的资源推荐系统,如图13所示。

图13 根据用户需求的资源推荐系统Fig.13 Resource recommendation system according to user needs
5 结语
本文提出了基于PLMM模型管理接口方案,为产品制造企业和产品利益攸关者网络化协同智能化和高效化的提供了一种可行性;使用了基于关键字的模型类别预测方法,通过对输入的文件文本进行清洗、切分、搜索匹配,计算其在各模型类别领域的权重,并通过归一化给出其预测结果与对应分值,实现文件管理到模型管理的转化技术,预测效果最高可达94.55%;实现了一种基于关键字的搜索引擎,能够对用户提出的需求进行分析,提取其中的关键文本,并在PLM海量的数据库中为用户提供最匹配的资源信息,为工业软件管理系统提供一种快速查询的方案。
猜你喜欢
科学大众(2020年23期)2021-01-18 03:09:08
冶金设备(2020年2期)2020-12-28 00:15:26
重型机械(2020年2期)2020-07-24 08:16:20
汽车观察(2019年2期)2019-03-15 06:00:50
中国卫生(2016年5期)2016-11-12 13:25:26
新校长(2016年8期)2016-01-10 06:43:59
石油化工建设(2015年6期)2015-12-01 04:17:35
商事法论集(2014年1期)2014-06-27 01:20:42
生物进化(2014年2期)2014-04-16 04:36:26
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
