
融合注意力机制和用户信任机制的深度推荐算法
2022-11-03 06:23张养硕牛存良张琳钰
河北工业大学学报 2022年5期
张养硕,牛存良,姚 政,张琳钰
(河北工业大学 人工智能与数据科学学院,天津 300401)
0 引言
随着数据的爆炸增长与大数据技术的普及,如何快速的从海量数据中挖掘有效信息成为当今研究热点。推荐系统作为一种缓解信息过载的重要技术,能从大量的数据中挖掘数据信息,适应用户的喜好,并通过推荐列表向用户提供其喜爱的项目,该功能在电商(Amazon、淘宝)、社交(Face-book、微信)、新闻(Google News、今日头条)等方面应用日益广泛。
本文在融入用户数据、项目数据、用户信任关系数据、项目属性数据的基础上,提出一种新的融合注意力机制和用户信任机制的深度推荐算法(DRAAT,deep recommendation algorithm integrating attention and user trust mechanism)。实验结果表明,本文所提出的DRAAT算法,在一定程度上提高了推荐的效率和精度,同时给用户提供了更个性化的推荐。
1 相关工作
早期的基于内容的推荐(Content-Based Recommendation)[1]主要是给用户推荐项目种类相同的物品,推荐方法简单直接,推荐形式单调,无法为用户找到感兴趣的其他种类,后来提出的影响深远的协同过滤技术(Collaborative Filtering)[2]能给用户提供新的选择,并且在技术上易于实现。通过数据收集用户喜好,并根据相似度预测评分,协同过滤技术使推荐问题逐渐变成回归问题,矩阵分解应运而生。Salakhutdinov等[3]提出的概率矩阵分解(PMF,Probabilistic Matrix Factorization)模型运用高斯分布、贝叶斯原理进行数学建模,从概率的角度来预测用户的评分。随后,降噪自编码器也应用到矩阵分解中,Wang等[4]通过降噪自编码器实现了更好的推荐效果。
随着大数据技术的发展,国内外众研究者对基于深度学习的推荐算法展开广泛研究[5]。Hinton等[6]提出深度信念网络概念,它比传统的神经网络训练简单,多应用在音乐推荐中。He等[7]提出挖掘用户和项目之间复杂关系的神经协同过滤模型,利用多层神经网络建模用户和项目之间的线性与非线性特征。注意力机制最初被应用于机器翻译领域,后来逐渐应用于推荐系统,它通过学习特定关系来挖掘用户特定层面的隐含信息,以提升推荐性能。Gong[8]等在卷积神经网络(CNN,Convolutional Neural Network)的基础上加入注意力机制,提取微博的标签特征进行话题推荐。Wang[9]等利用CNN提出动态注意力模型,通过CNN学习文章的表达形式和语义信息,捕获作者选文章时的动态行为。王永贵等[10]通过双层注意力机制挖掘项目信息,但缺少对用户信息的挖掘导致推荐效率偏低。柴超群[11]通过社交网络信息构建用户信息,但缺少对社交网络信息的挖掘,同时只挖掘项目单一属性,导致数据利用不充分。虽然上述算法可以实现很好的推荐效果,但是缺少对历史项目的挖掘,缺少通过用户信任机制对用户信息的建模。针对以上问题,本文提出了一种融合注意力机制和用户信任机制的深度推荐算法,研究工作主要优势如下:
1)同时关注用户数据、项目数据、用户信任关系数据3方面数据,以实现更精准的深度推荐;
2)通过双层注意力机制实现历史项目信息的挖掘,更有效地捕捉有价值的高阶交互信息;
3)通过显性和隐性信任关系定义新的用户信任关系,并利用注意力机制总结社交网络中用户信任关系的影响力;
4)引入多层感知机同时处理用户项目的原始特征和高阶特征信息,以提供top-N推荐。
2 融合注意力机制对用户信息建模的深度推荐算法
为挖掘信息的潜在特性,对数据进行全面的分析,本文使用降噪自编码器对原始数据编码,在输入时使用预处理的One-Hot编码,表示用户和项目的向量。通过降噪自编码器的训练后得到嵌入数据。研究通过获取用户数据、项目数据、用户信任关系数据、项目属性数据的降噪自编码作为输入,经过4个独立的降噪自编码器的训练,得到嵌入表示p、q、t、l,其中(p,q,t,l)∈ℝk。
2.1 融入注意力机制的项目综合特征
注意力机制借鉴了认知心理学中的人脑注意力模型,核心目标是从众多信息中选择出对当前任务目标更关键的信息。本文的注意力机制应用在Encoder-Decoder的模型中,利用降噪自编码器对输入数据进行Encoder编码,即将每个输入的数据映射成相同长度的上下文向量,之后Decoder编码输出的是编码后的上下文向量。在Decoder编码时加入注意力机制,其输出后的数据不是对数据在上下文信息的简单的累加,而是引入对于各个输入信息的权值对其进行加权求和运算的结果。
传统的注意力机制针对不同的历史项目分配相同的权重,未能充分挖掘历史项目信息。为了挖掘项目更深层次的信息,本文利用两层注意力机制,专注于处理项目属性偏好和交互偏好,最终融合得到项目综合特征,项目综合特征模型如图1所示。
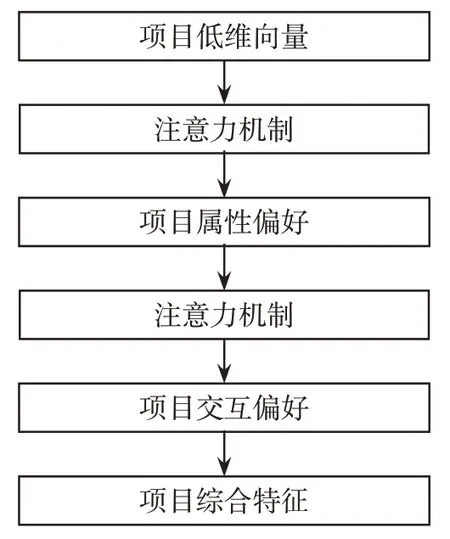
图1 项目综合特征模型Fig.1 Project comprehensive feature model
本文的项目级注意力机制的构建如下。通过降噪自编码器建模用户数据,获得项目的低维向量化表示,其中项目i的表示向量为qi,(qi1,qi2,…,qix)为项目i的第x个属性,qr为待推荐项目。为了推荐时更多的挖掘项目信息,使不同的历史项目在预测时做出不同的贡献,学习各个项目的潜在信息为用户提供带推荐项目qi时,充分考虑用户的历史数据,将用户u的历史数据融入待推荐项目qj的属性偏好,则项目的属性偏好向量qi表达式为

式中,μj,x为待推荐项目qr对历史项目第x个属性qj,x的偏好,学习到可靠的项目的属性偏好向量qi,便可用于注意力μj,x权重的学习,所以项目属性偏好注意力权重μj,x的表达式为

注意力的推荐中,有些用户的历史活跃度很长,softmax函数会对有较长历史活跃度的用户进行惩罚,引用文献[10]的做法引入λ作为平滑指数,score(qr,t,qj,t)为对齐分数,用来衡量两个向量的匹配程度,使用多层感知机模型进行学习。用tanh作为非线性激活函数,用来表示输入序列和输出序列的隐含层状态,score(qr,t,qj,t)表达式为

式中,Va1和Wa1为训练参数。为了获取更深层次的历史交互项目的数据,在得到用户属性偏好的基础上,针对用户的属性偏好向量qj和项目交互向量lr运用注意力机制,得到交互偏好的项目隐式向量,使用注意力机制,获取待推荐项目交互向量lr对于项目的属性偏好向量qj的影响力权重ηr,j。其第2层待推荐项目的交互的注意力权重ηr,j的表达式为

式中,score(,qj)为对齐分数,仍采用多层感知机模型进行学习,选择tanh作为非线性激活函数,score(lr,qj)表达式为

式中,Va2和Wa2为训练参数。通过两层注意力机制,感知器模型学习用户注意力偏好,结合项目的属性偏好向量qj和待推荐项目的交互向量lr的关系,确定各自的权重系数后获得项目综合特征q~r定义如下:

2.2 融入信任机制的用户综合特征
用户的社交关系能提供丰富的数据信息,在传统的社交网络推荐中,用户会受其信任朋友的影响,与其朋友具有相似的兴趣,通过挖掘用户的信任关系为待推荐用户推荐其信任朋友选择的项目。本文利用评分数据、用户信任关系分别定义显示和隐式信任关系得到用户综合信任关系数据,再利用注意力机制总结社交网络中用户信任关系的影响力,得到用户综合特征,模型如图2所示。
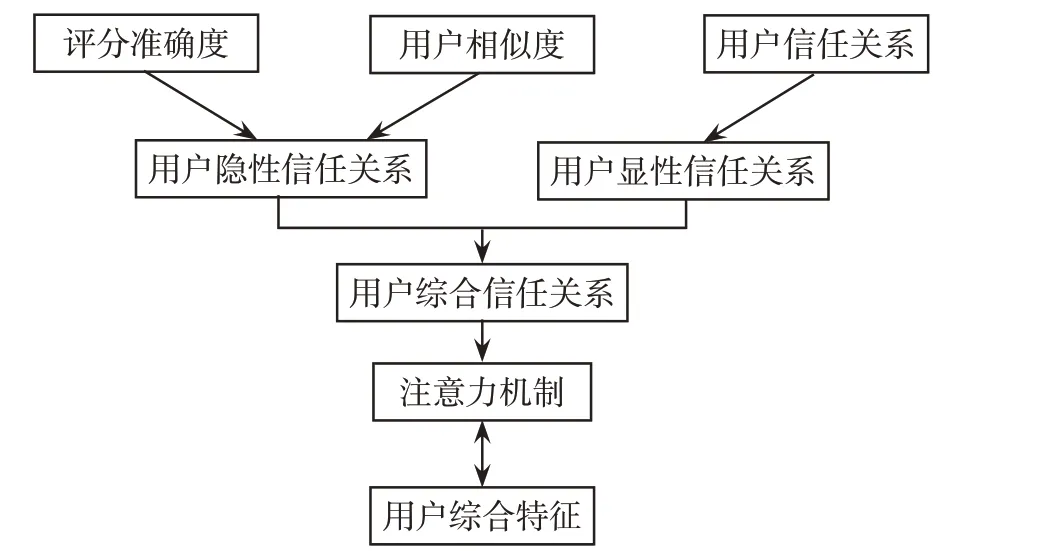
图2 用户综合特征模型Fig.2 User comprehensive feature model
传统的推荐大多只关注显性信任,而忽略了用户隐形信任关系。本文研究的用户信任机制基本思想是给用户推荐其信任用户的项目选择,所以挖掘用户间有效的信任关系,能得到融入信息更丰富的用户综合特征。首先通过用户评分整理用户隐性信任关系TI,接着通过用户被信任数量的大小定义用户的显性信任关系TE,最后得到用户的综合信任关系T~,将得到用户的综合信任关系形成社会化信任矩阵,为接下来注意力机制的引入提供保障。
用户评分的准确性直接影响推荐效率,用户评分越高表示对该项目越喜爱,但是日常生活中用户针对一些项目评分只打中间值,导致评分数据准确性低影响推荐效率,故引入用户评分准确度系数β。

式中:Rui表示用户u对项目j的评分;表示用户对所有项目i的平均评分。当用户u对项目i有评分,Fui取值为1,用户u项目i没有评分取值为0。
通常采用目前主流的Pearson相关系数计算用户评分相似度,开始需要找到用户i和用户j共同评分的项目集合,但是这样的用户相似度并没有考虑到目标项目信息,目标用户及其邻居用户的相似度都是恒定不变的,导致推荐效率降低,在计算用户相似度时引入项目相似度信息,定义项目的相似度SI(i,j)计算公式表示为

式中:Uij为对项目i和j同时评分的用户集合;和则表示项目评分均值。针对不同的项目,考虑不同项目对用户相似度的影响,将项目相似度SI(i,j)引入Pearson相关系数计算用户评分相似度,用户相似度计算公式为

式中:Ck为项目i的类别;为用户种类对Ck的共同评分集合。该公式考虑到了不同项目对用户相似度的影响,最终计算出的相似度会更加的准确。
这里定义用户隐式信任关系TI,用户u和v的隐式信任关系定义如下:

本文用TE表示用户i和j的显式信任关系。tij表示用户i和j的信任关系,用户i信任用户j时取1,否则取0。但是信任关系并不是对称的,显然信任和被信任的数量有关,当用户i被众多其他用户信任时则用户i的可信度高影响力大;反之用户i信任众多其他用户时,用户i的受每个用户的影响就小,可信度低影响力就小,因此结合影响力得到用户i和j的显式信任关系TE,定义如下:

式中:表示用户ui被信任的用户数量;表示用户ui信任的用户数量。用户的综合信任定义如下:

挖掘用户信任关系数据,考虑用户隐式信任关系和显示信任关系,得到用户的综合信任关系能更真实的体现推荐的过程。为获得更加丰富的用户信任关系,挖掘用户信任关系,定义用户信任阈值t,判断用户u和v之间的信任关系有无,定义如下:

在用户信任关系数据的基础上挖掘用户间信任关系,本文选择多层感知机学习用户的信任注意力关系,非线性激活函数选择RELU,用户u对于其信任用户v的对齐分数score(pu,tv)表达式为

式中:W是注意力的权重矩阵;b是系统的偏置。用户和其信任朋友间的影响力权重λu,v定义如下:

利用注意力机制挖掘用户和其信任朋友间的影响力权重λu,v,并融合用户原始数据,确定各自的权重系数之后计算获得用户综合特征定义如下:

2.3 完整模型
通过上述描述,本文充分考虑用户数据、项目数据、用户信任关系数据、项目属性数据,利用项目综合特征和用户综合特征得到用户项目综合评分定义如下

为了避免因过度挖掘造成推荐效率降低,通过横向并联少量数据得到更加丰富的信息。因此,横向增加用户和项目的原始隐性特征提升推荐效率。通过多层感知机获取用户特征和项目特征,经过池化层将用户向量和项目向量堆叠起来,得到更完整的数据嵌入,其公式为

将堆叠数据利用多层感知机获取用户和项目信息的隐式特征,使用RELU作为激活函数,定义如下:
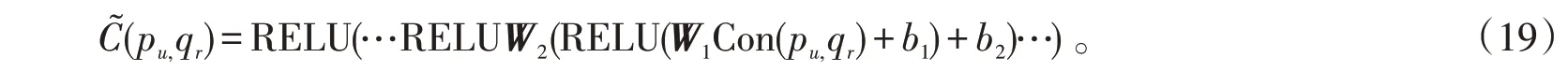
利用用户项目综合评分和用户和项目信息的隐式特征融合,综合变量h定义如下:

应用多层感知机,得到算法最终预测评分,引入Dropout机制防止过拟合得到最终预测评分h~。利用BPTT算法开展模型优化,其中交叉熵损失函数定义如下:

DRAAT算法模型如图3所示。本算法通过对项目信息引入双层注意力机制,挖掘项目属性偏好和交互偏好并联合得到项目综合特征,对用户信息建模分别定义显示和隐式信任关系得到用户综合信任关系,利用注意力机制挖掘用户信任关系权重,利用多层感知机获取用户和项目的原始特征,并融合用户项目综合评分,得到最终预测评分应用于top-N推荐。

图3 DRAAT算法模型图Fig.3 DRAAT algorithm model diagram
3 实验
3.1 数据集描述
使用推荐系统常用的公共数据集Film Trust和Ciao,Film Trust数据集包含了用户数、电影数、电影评分、社交信息等。Ciao为物评论网站数据,其中包含了用户、物品和物品的评分、有向社交关系等数据。为了清洗数据本文过滤项目评分数小于5的用户,数据集的统计情况如表1所示。
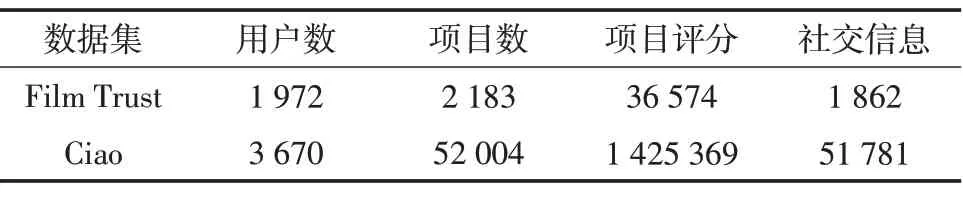
表1 Film Trust数据集的统计信息Tab.1 Statistics of Film Trust data set
3.2 评估方法
为了评价推荐系统的推荐质量,本文采用常用的评价指标:命中率(Hit Ratio,HR)和归一化折扣累计增益(Normalized Discounted Cumulative Gain,NDCG)。命中率HR衡量召回率,直观的测量推荐的准确率,式中GT为用户在测试集中所有项目的数量之和;归一化折扣累计增益NDCG衡量排序质量,评价指标定义如下:

3.3 基准模型
将本文提出的DRAAT算法与以下算法比较:1)LFM[12]是一种隐语义模型通过矩阵分解预测项目评分,是最经典的矩阵分解算法之一;2)PMF[3]是一种概率矩阵分解推荐模型,在传统的矩阵分解模型基础上从概率的角度对矩阵分解模型进行解释;3)SocialMF[13]将用户的社交信任信息融入到传统的矩阵分解模型中;4)DeepMF[14]利用深度神经网络获取多阶特征信息,学习特征间的高阶关系;5)NAIS[15]利用使用注意力机制和多层神经网络建模用户和项目的线性与非线性特征;6)CFM[16]使用卷积处理特征的交互模块,提取向量的二阶特征。
3.4 实验调参
依据以往实验经验,在数据集中随机抽取80%的数据作为实验训练集,20%的数据为实验测试集。本文使用数据集Film Trust调整模型参数,设置学习率为0.01,MLP各隐藏单元数为{128,64,32,5},各级隐藏层神经元个数为128。注意力权重尺寸与嵌入尺寸相同,嵌入特征向量维度设为{8,16,32,64},TOP-N推荐中的推荐个数N取值为{5,10,15,20}。
如图4所示当嵌入向量为8时,所有算法排序质量都较差,嵌入向量为度16时有大的提升,但随着嵌入向量维度的增加,其他算法提升效果不明显,但本文算法仍有一定程度的提升;在top-N推荐中,如图5所示N的值越大推荐效果越好,符合普遍认知,推荐的数量越多就会有更多用户喜爱的项目,N的各个取值中本文的算法与其它算法相比表现良好。图6表示基础信息引入的权重α和φ对于模型NDCG值的影响,由图中信息可知,α和φ的效果都是先提升后降落,分别在用户基础信息权重在α=0.7和项目信息权重在φ=0.6时排序质量最优。权衡模型性能后选择d=32,α=0.7,φ=0.6,N=10作DRAAT算法最佳参数组合。

图4 嵌入向量维度d的影响Fig.4 Influence of the embedding vector dimension d

图5 N的取值对排序质量的影响Fig.5 Effect of the value of N on the quality of sorting
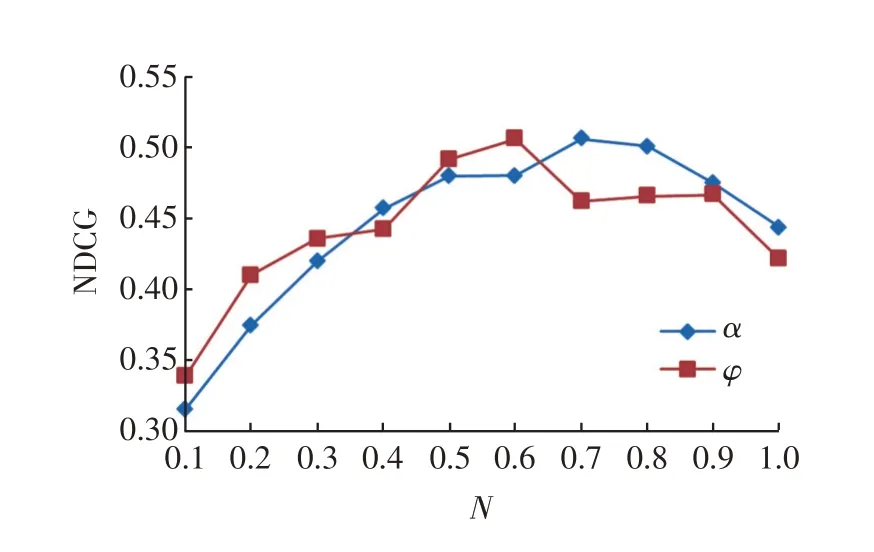
图6 α和φ的取值对排序质量的影响Fig.6 Effect of the value ofαandφon the quality of the sorting
3.5 实验结果
使用GPU训练所有模型,LFM、PMF、SocialMF基于概率矩阵的算法,应用格子搜索法确定获得隐因子数量和最优正则化系数;对于深度学习模型Deep-MF、NAIS、CFM,其超参数繁多,选择文献中表现最优的参数值进行实验。DRAAT算法参数选择d=32,α=0.7,φ=0.6,N=10,各类算法实验效果对比如表2所示。
通过表2可知,本文DRAAT算法在样本数量大的Ciao数据集比数据量小的Film Trust数据集有较好的实验效果,所以实验样本的大小影响推荐效果,说明本文提出的融合注意力机制和用户信任机制的深度推荐算法使用大量有监督的数据来训练模型,学习到更多的有效信息,提高了推荐的准确率。
通过实验数据得出本文提出的算法在两个数据集上的HR和NDCG的指标优于其他算法。由表2可知,本文DRRAT算法比传统的矩阵分解模型LFM、概率矩阵分解模型PMF、融入社交信任信息的矩阵分解模型SocialMF这些基于矩阵分解的算法在召回率上分别提升10.11%、10.33%、6.54%,在衡量排序质量的归一化折扣累计增益NDCG上分别提升9.5%、7.5%、6.6%;深度神经网络模型DeepMF、注意力模型NAIS、卷积特征交互模型CFM这些基于深度学习的推荐模型,利用非线性方式表示用户和项目特征获得不错的推荐效果,但是本文DRAAT算法比DeepMF、NAIS、CFM这些基于深度学习的推荐算法依然在HR的指标上提升6.34%、4.57%、4.21%,在NDCG的指标上提升4.8%、3.3%、2.4%。本文算法通过注意力机制和信任机制获得过更好的项目综合特征和用户综合特征,能更深入地挖掘数据来得到更好的推荐效果。实验表明,DRAAT算法拥有优秀的推荐性能。
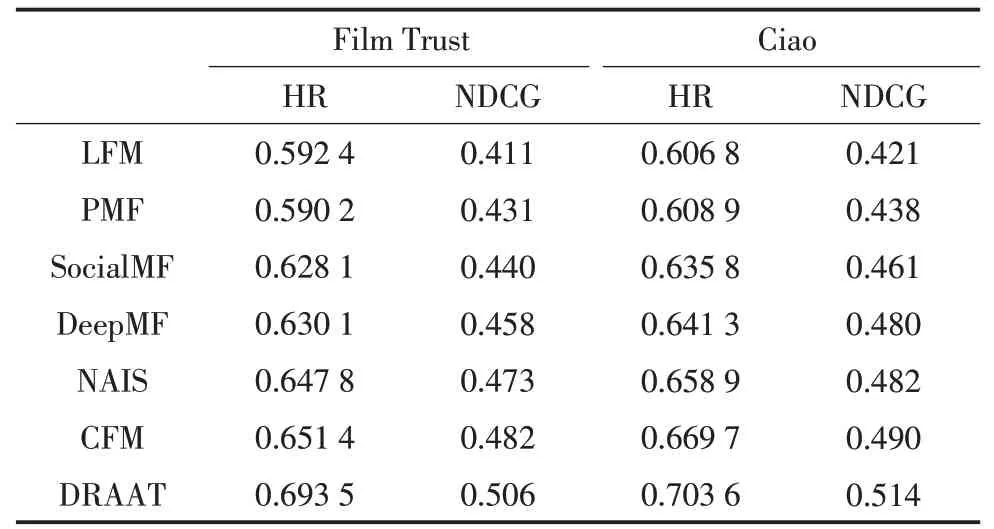
表2 各类算法实验效果对比Tab.2 Comparison of experimental effects of variousalgorithms
4 结语
为了给用户提供更个性化的推荐,如何精准的把握用户的喜好和需求,提高推荐的质量成为当下研究的主要方向。本文利用深度学习技术更精准的捕获数据间的交互关系,并且引入注意力机制和用户信任机制,在融入用户数据、项目数据、用户信任关系数据、项目属性数据的基础上,提出一种新的融合注意力机制和用户信任机制的深度推荐算法DRAAT。在数据集Film Trust和数据集Ciao上的试验结果表明,本文提出的算法对提高推荐精度有一定的效果,同时给用户提供了更个性化的推荐。在今后的工作中,需要继续钻研先进的推荐算法,提高推荐系统的质量和算法的可解释性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
文苑(2018年21期)2018-11-09
传媒评论(2017年3期)2017-06-13
桃之夭夭B(2017年2期)2017-02-24
第二课堂(课外活动版)(2016年2期)2016-10-21
中国卫生(2015年9期)2015-11-10
高中生·青春励志(2014年11期)2014-11-25
中国卫生(2014年3期)2014-11-12
中国火炬(2014年4期)2014-07-24
