
基于RF-XGBoost的光伏发电功率预测
2022-11-02 12:13:48葛浩然夏宇邹文进郝少飞马刚
电气自动化 2022年5期
葛浩然,夏宇,邹文进,郝少飞,马刚
(南京师范大学 电气与自动化工程学院,江苏 南京 210046)
0 引 言
光伏发电功率预测可为电力系统的安全稳定和经济运行提供重要保障,对于未来电力系统的发展十分重要。
目前光伏功率预测的方法可以分为物理方法和统计方法等几类[1]。物理方法通过光伏设备特性方程等进行预测,此方法运算难度较大且对数据有着严格要求,不适用于所有光伏电站[2]。统计方法利用大量历史光伏发电和数值天气预报数据进行预测。如反向传播神经网络模型[3]、最小二乘向量机模型[4]和径向基神经网络模型[5]。其后又出现了如小波变换与最小二乘向量机组合模型[6],主成分分析和遗传算法优化反向传播网络组合模型[7],提高了模型预测精度。
尽管当前的模型已经进行了诸多应用,但还存在着预测精度不理想和训练集缺失数据时鲁棒性较差等问题。因此本文提出一种基于随机森林算法(random forest, RF)特征值选择和极限提升树(eXtreme gradient boosting, XGBoost)算法结合的光伏预测模型,通过使用随机森林算法对数据集中提供的各特征进行降维处理,并利用XGBoost算法多决策树加权求和,可有效提高预测精度与缺失数据情况下的鲁棒性。以夏威夷某光伏电站数据进行预测对比验证,表明RF-XGBoost模型在发电功率预测的准确性和适应性。
1 RF-XGBoost功率预测模型
1.1 RF特征值降维原理
RF的原理如图1所示。通过分析各特征对于输出功率影响的重要性决定最终训练与预测使用的特征。
随机森林算法有一个重要特点是袋外估计,不仅可以优化随机森林的泛化误差,还可以通过对特征值重要性的计算完成筛选[8]。对于一个特征而言,每一棵决策树都可以计算得到一个Out of Bag(OOB)误差Error1,此后随机为OOB中的对应特征加入噪声干扰,再次计算OOB误差得到Error2,通过计算前后误差,当加入噪声后准确度下降大时则说明该特征重要性高。特征值重要性计算公式如式(1)所示。
(1)
式中:Error1i、Error2i为加入噪声前后的袋外误差;K为决策树数量。
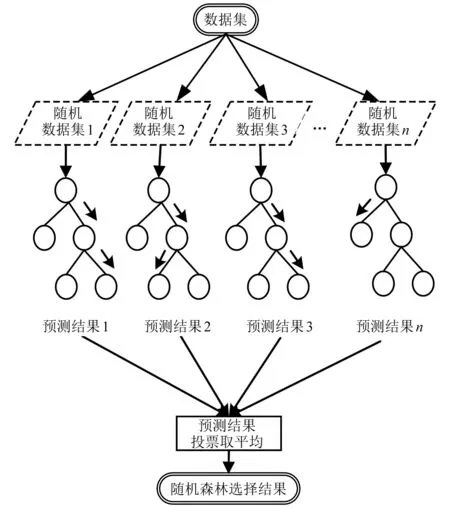
图1 随机森林算法原理
1.2 XGBoost算法原理
极限提升树XGBoost是一种基于梯度提升树的集成学习算法,通过根据特征不断生成树模型以得到目标样本预测值[9]。XGBoost相比与传统算法,扩展了算法的应用范围;限制了过拟合现象的产生,提高了算法的泛化能力;对于缺失的数据XGBoost也能进行自动学习进行补全,减少前期数据预处理工作量。
XGBoost算法的核心思想就是通过不断添加树并进行特征分裂生长树,以拟合上一棵树预测的残差。当训练完成后得到k棵树,将树中所有叶子节点所对应的分数w相加即可得到最终预测结果。XGBoost的算法原理过程如图2所示。
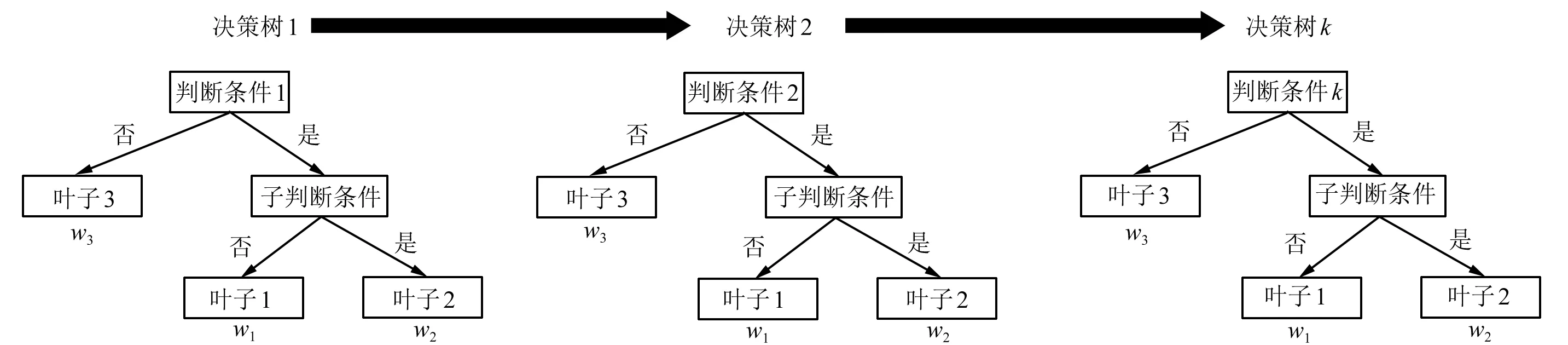
图2 XGBoost算法原理
对于第i个数据而言,输出公式如式(2)所示。
(2)
式中:k为决策树的数量;F为所有CART树组成的函数空间;f(x)为F空间中的一个函数。
目标函数可以写作如下形式:
(3)
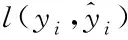
2 RF-XGBoost功率预测模型参数设置
2.1 模型参数选择
本文模型中XGBoost部分参数设置情况如表1所示。
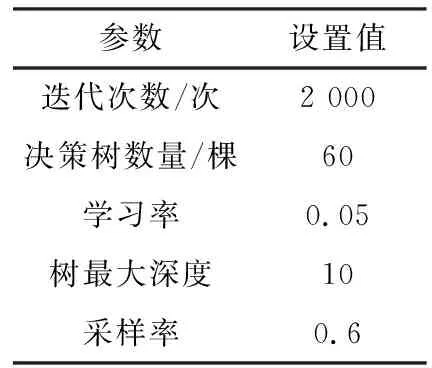
表1 XGBoost参数设置
其中,迭代次数、决策树数量与树最大深度决定着模型对复杂问题的求解能力,而学习率和采样率的设置是为了减少过拟合现象的发生。
2.2 评价模型的评价标准
本文使用均方根误差(root mean squared error,RMSE)、决定系数R2作为本模型的评价参数。均方误差用于评价数据的变化程度,RMSE值越小则说明预测模型有更高的精度。
RMSE的定义如下:
(4)
式中:N为测试集长度;Ot为实际值;Pt为预测值。
决定系数其可以充分反映两函数之间的相关关系,R2的定义如下:
(5)
2.3 RF-XGBoost预测流程
本文模型的预测流程如图3所示。

图3 RF-XGBoost预测模型
通过随机森林算法生成分类决策树以与发电功率的强相关性为目标进行特征值选择。选择完成后通过使用含有对应特征值的训练集对XGBoost预测模型进行训练,当模型满足预设损失函数与阈值训练完成后,将测试集数据导入XGBoost模型进行预测工作,完成预测结果输出后与实际值进行对比,输出预测精确度结果,完成整个预测过程。
3 算例分析
3.1 算例环境
本文采用了2016年9月至11月美国夏威夷某电站的数据作为本次训练数据集,12月的数据作为测试集。同时本文在原始训练集的基础上构建了随机删除部分气象数据和功率数据的修改训练集,用于体现XGBoost模型对数据缺失的适应性特点。本文选取12月16日和12月25日代表晴天和降雨气象条件下的情况,进行验证。
3.2 测试环境
本文使用了(back propagation, BP)预测模型以及(random forest-decision tree regressor, RF-DTR)预测模型,与本文所提出的RF-XGBoost预测模型的预测结果进行对照分析,以体现本文模型的精确度优势。本文使用均方根误差RMSE决定系数R2作为预测精度的判定条件。
同时对于本文提出模型,使用原始完整数据集和去除了部分数据的修改数据集进行了测试,以体现模型对缺失数据的适应能力。
3.3 不同模型预测结果对比分析
三种预测模型输出功率与实际输出对比曲线如图4所示。其中,图4(a)、图4(b)为RF-DTR模型的预测结果,图4(c)、图4(d)为BP模型预测结果,图4(e)、图4(f)为本文提出的RF-XGBoost模型的预测结果。图中虚线为实际数值,实线为预测输出值。

图4 不同预测模型输出曲线对比图
由图4可知,在12月16日晴天状态与12月25日降雨状态下,三种预测模型都能较好完成预测工作,模型输出结果如表2所示。
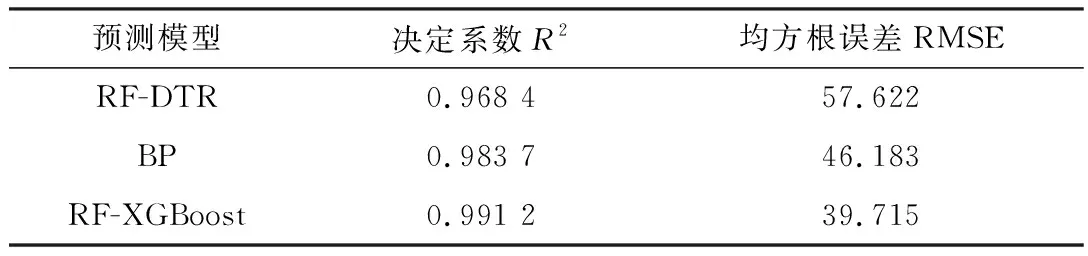
表2 12月16日不同预测模型预测结果对比
由图4(a)、图4(c)、图4(e)与表2可以看出,DTR算法由于其本身的特性无法适应较快波动,出现了较大误差,现今预测工作常用的BP模型效果相比决策树模型在RMSE上有了19%的提升,但由输出曲线可以看出还有较多的波动情况。RF-XGBoost模型在三种模型中取得了最好的预测效果,相比较为通用的BP模型也获得了14%的提升,由输出曲线中发现较为快速的波动也可以准确跟踪。
由图4(b)、图4(d)、图4(f)与表3可以看出,在存在降雨情况的12月25日,RF-XGBoost模型更加体现出了其跟踪波动情况和突变适应性的优势。模型的预测结果如表3所示。由R2与RMSE值可以看出,RF-XGBoost模型在预测精度上有了较大的提升,在RMSE参数上本文提出的模型相比BP模型的准确度提升了13%,体现了新型预测模型的精度优势。
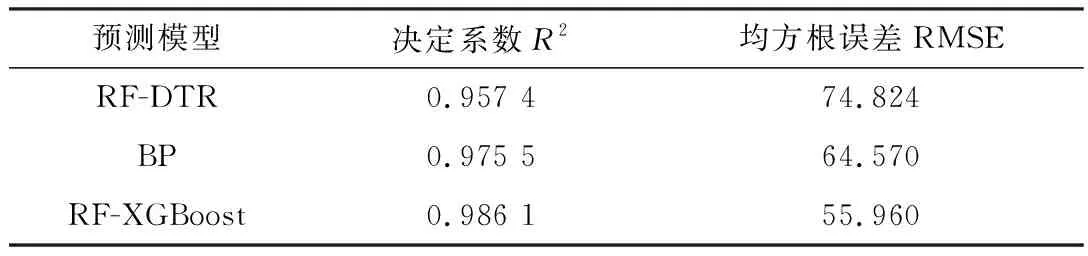
表3 12月25日不同预测模型预测结果对比
3.4 缺失数据情况对比
XGBoost模型有着对数据的自适应能力,在数据集存在缺失时依然能以较高的精度完成预测工作。本文以12月16日为例,将原始数据进行了随机参数的缺失处理以模拟数据缺失情况,并与原始状态进行了对比,输出曲线如图5、图6所示。
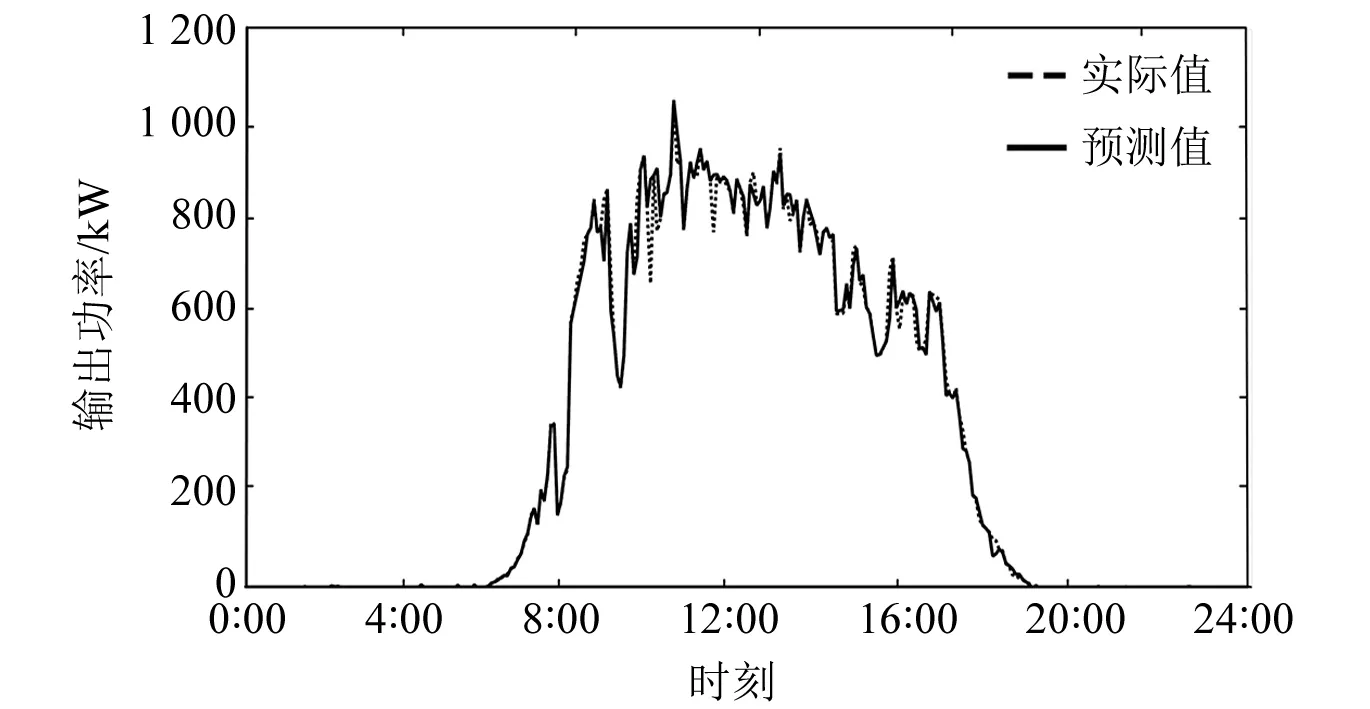
图5 RF-XGBoost原始数据预测曲线
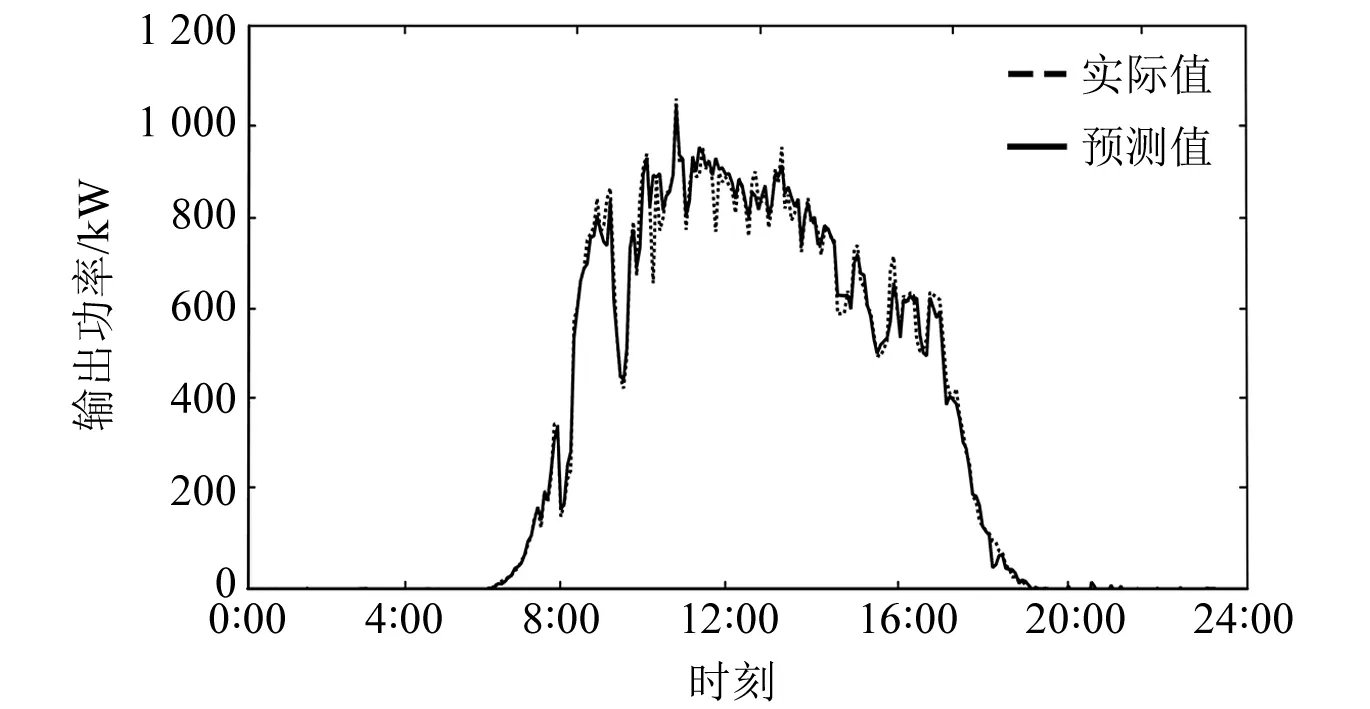
图6 RF-XGBoost缺失数据预测曲线
表4为RF-XGBoost模型对特征值数据随机缺失处理前后预测结果的对比,由R2与RMSE值可知,相比数据集完备的情况下,模型的预测精度并没有受到较大影响,依然能较为准确地完成预测工作。

表4 缺失参数训练预测结果对比
4 结束语
本文提出了基于RF-XGBoost的短期光伏预测模型,首先通过随机森林算法进行特征值筛选降维。随后通过XGBoost算法提高了预测精度并提供了缺失数据适应能力,从而能更好地适应不同规模不同情况的预测条件。最后在算例分析中通过对历史数据的测试分析也验证了本文所提出的RF-XGBoost模型的精度优势,在功率预测工作中有着较强的实用性,可降低光伏并网调度难度,有助于提升光伏发电的利用效率。
猜你喜欢
数学物理学报(2021年5期)2021-11-19 07:01:12
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19 08:38:40
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
电子制作(2018年11期)2018-08-04 03:25:38
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
测绘科学与工程(2016年5期)2016-04-17 06:51:15
东北电力大学学报(2015年1期)2015-11-13 05:20:25
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
电子设计工程(2015年3期)2015-02-27 12:03:45
