
基于指导轨迹加速的机械臂强化学习运动规划
2022-11-02 12:25:22刘哲潘爱强魏本刚江安烽张家维白成超
电气自动化 2022年5期
刘哲, 潘爱强, 魏本刚, 江安烽,2, 张家维, 白成超
(1.国网上海市电力公司电力科学研究院,上海 200437;2. 国网上海能源互联网研究院有限公司,上海 201210;3.哈尔滨工业大学 航天学院,黑龙江 哈尔滨 150001)
0 引 言
运动规划是机械臂执行操作任务的前提,其目的是为机械臂找到一条满足无碰撞和运动平滑度等约束的关节运动轨迹。机械臂的运动规划空间通常为高维的关节构型空间,这导致了很多传统的运动规划算法很难直接用于机械臂的运动规划。针对机械臂的高维规划空间,目前基于采样的运动规划算法可以取得不错的效果,如快速拓展随机树(rapidly-exploring random trees, RRT)[1]、概率路线图(probabilistic roadmap method, PRM)[2]。此外常用的机械臂运动规划算法还包括人工势场法[3]和轨迹优化算法[4]等。
上述的运动规划方法的效率不可避免地随机械臂自由度的增加而降低。近年来基于深度强化学习[5]的机械臂运动规划算法得到了很多学者的关注。与模仿学习[6]相比,深度强化学习运动规划算法能够更好地探索障碍物的边界,进而得到更高的成功率。与经典的运动规划算法相比,基于强化学习的运动规划算法执行速度更快,且不受关节空间维度影响。本文利用软动作-评论家(soft actor-critis, SAC)[7]算法进行强化学习训练,并利用经典运动规划算法计算得到的指导轨迹来辅助探索,提升训练的效果。
1 算法理论
1.1 基于深度强化学习的机械臂运动规划

当机械臂的末端位置与目标位置之间的距离小于阈值ε时,认为规划成功,当机械臂与障碍物发生碰撞或规划时间超出限制时,认为规划失败。对于奖励函数的设置,本文设计了一个密集奖励函数和一个稀疏奖励函数,密集奖励函数可以表示为如下形式。
(1)

(2)
稀疏奖励函数可以表示为如式(3)所示。
(3)
1.2 SAC算法
机械臂强化学习运动规划问题的动作空间为连续动作空间。本文采用适用于连续动作空间的SAC强化学习算法来进行训练。SAC算法中用神经网络对三个函数进行了分析,分别是状态价值函数Vψ(s),其对应的神经网络参数表示为ψ;状态-动作价值函数Qθ(s,a),其对应的神经网络参数表示为θ;策略函数πφ(a|s),其对应的神经网络参数表示为φ。
在SAC算法中首先对状态价值网络进行更新。在计算Vψ(s)的损失函数时Qθ(st,at)和πφ(at|st)的神经网络参数保持不变。状态价值网络损失函数JV(ψ)的计算公式为:
(4)
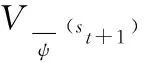
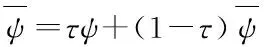
(5)
式中:τ为更新速率。JQ(θ)的计算公式为:
(6)

(7)
式中:tanh(·)为双曲正切函数;μφ(s)为策略网络输出的动作均值;σφ(s)为策略网络输出的策略方差;N(0,I)为维度与关节自由度数相同的正态分布函数。经过重参数化之后策略网络损失函数Jπ(φ)的计算公式为:
(8)
1.3 指导轨迹
在利用强化学习进行机械臂运动规划的早期训练阶段需要进行大量的随机探索,才能逐步学会规划策略。为了解决这一问题,可以将传统运动规划算法规划得到的成功运动轨迹加入经验池中来为机械臂提供指导。本文在训练开始之前生成了10 000组不与障碍物发生碰撞的起始点和目标点以及两者对应指导轨迹数据。起始点和目标点的生成规则如下:
(9)

τguide={q0,a0,q1,a1,…,qn,an}
(10)
而经验池中数据的存储形式为:
D={(st,at,rt,st+1)}
(11)
将指导轨迹加入到经验池中之前,需要根据机械臂每一时刻的关节角度qt和机械臂的运动学模型计算状态st,并根据奖励函数计算采取动作之后获得的奖励rt。
2 试验验证
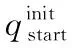
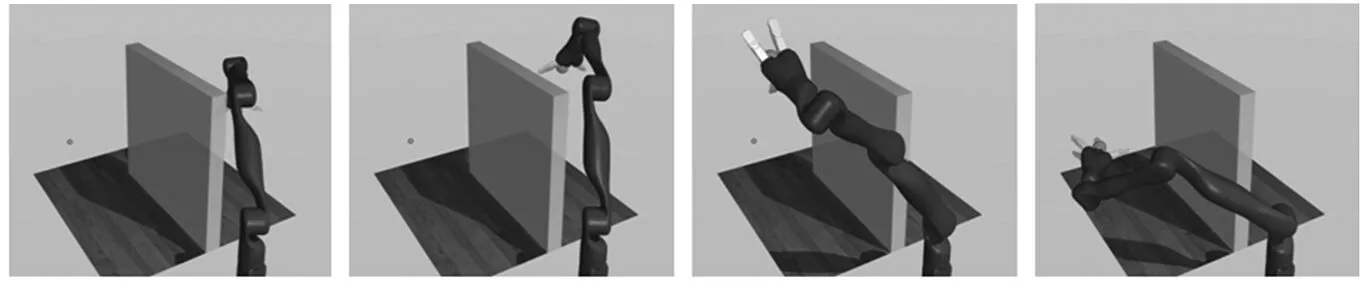
图1 机械臂运动到目标位置的过程
本文共进行了4组试验,每组试验在同样的训练参数下重复训练3次。在训练过程中每隔100个回合输出一次神经网络运动规划器的规划成功率,图2中的曲线表示3次训练的成功率均值。
本文选择评估训练10 000个回合后神经网络规划器的规划成功率和训练过程的收敛速度。在成功率评估方面,本文将神经网络运动规划器在新的起始构型和目标构型下运行100次规划,将100次规划的成功率作为神经网络运动规划器的真实成功率估计值,并计算了3次训练的成功率均值。本文将训练过程中成功率首次达到80%时的训练回合数作为评价策略收敛速度的指标,成功率和收敛速度测试结果如表2所示。
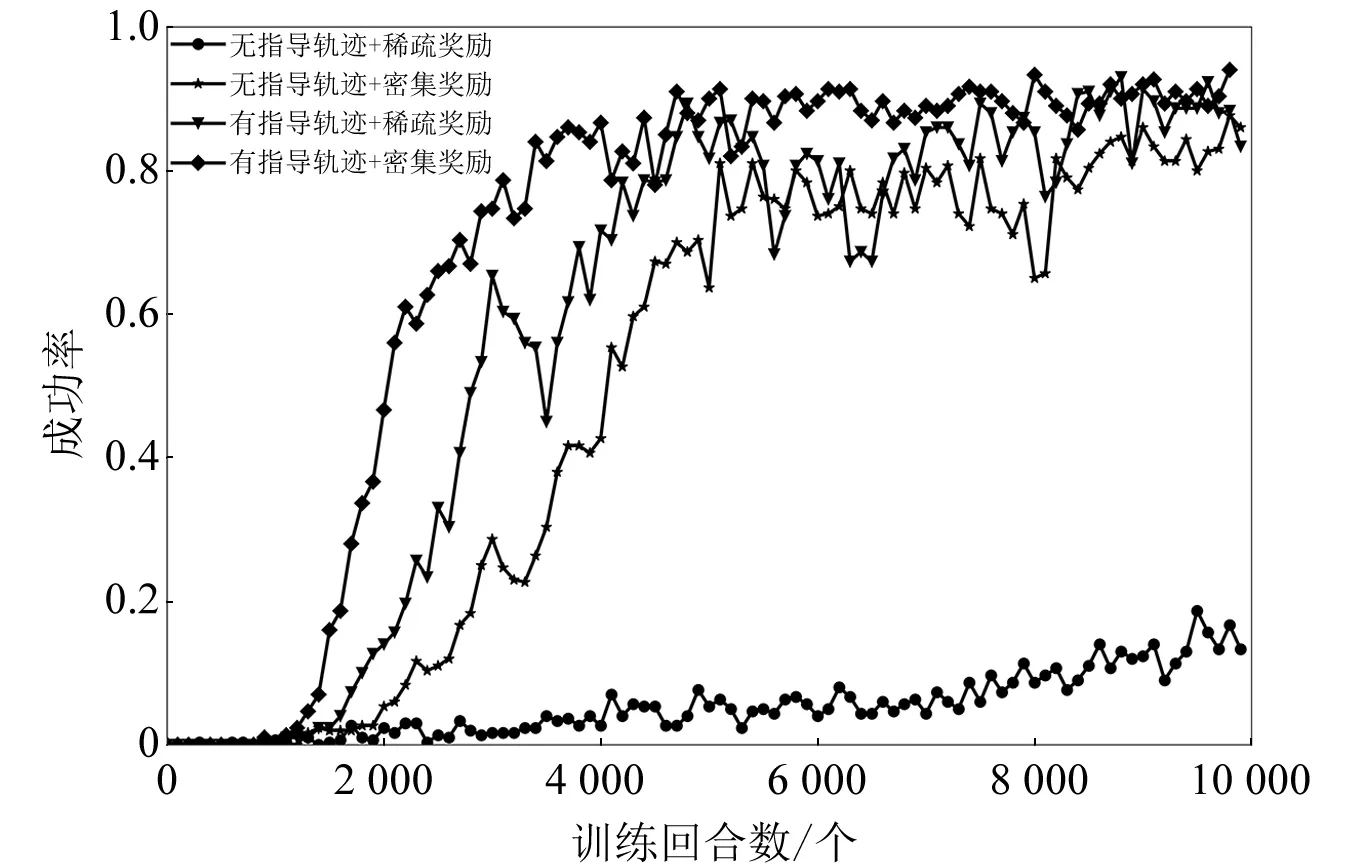
图2 训练过程的成功率变化曲线

表2 神经网络运动规划器的测试结果
3 结束语
本文基于SAC强化学习算法,研究了指导轨迹和奖励函数设计对运动规划成功率和收敛速度的影响。试验结果表明,密集奖励较稀疏奖励有更好的训练效果。指导轨迹的加入明显地减少了训练的收敛回合数,提高了运动规划的成功率。当奖励函数为稀疏奖励时,指导轨迹的作用更加明显。
猜你喜欢
当代水产(2022年6期)2022-06-29 01:12:02
中国生殖健康(2020年8期)2021-01-18 03:05:34
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
电子制作(2019年19期)2019-11-23 08:42:00
中国生殖健康(2018年3期)2018-11-06 07:20:12
现代装饰(2018年5期)2018-05-26 09:09:39
中国三峡(2017年2期)2017-06-09 08:15:29
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
