
Contrastive Consensus Graph Learning for Multi-View Clustering
2022-10-29 03:30ShipingWangXincanLinZihanFangShideDuandGuobaoXiao
Shiping Wang, Xincan Lin, Zihan Fang, Shide Du, and Guobao Xiao
Dear Editor,
This letter proposes a contrastive consensus graph learning model for multi-view clustering. Graphs are usually built to outline the correlation between multi-model objects in clustering task, and multiview graph clustering aims to learn a consensus graph that integrates the spatial property of each view. Nevertheless, most graph-based models merely consider the overall structure from all views but neglect the local spatial consistency between diverse views, resulting in the lack of global spatial consistency in the learned graph. To overcome this issue, a deep convolutional network is built to explore latent local spatial information from raw affinity graphs. Specifically,we employ a consensus graph constraint to preserve the global consistency between the learned graph and raw graphs. Furthermore, a contrastive reconstruction loss is introduced to achieve the samplelevel approximation between reconstructed graphs and raw graphs,which facilitates the network to enhance the consensus graph learning. Experiments on six classical datasets demonstrate that the proposed model outperforms other nine state-of-the-art algorithms.
Related work: In real-world applications, multimedia data are usually generated from multiple ways and presented in diverse forms,referred as multi-view data. Compared with single-view data, multiview data contains more comprehensive information, which makes multi-view learning be a hot spot. Previous work [1], [2] has been devoted to this field and achieves satisfactory results. As an important branch of multi-view learning, multi-view clustering aims to effectively fuse information and discover the underlying clustering structure shared by diverse views. Since each view has a distinct focus on the same object, multi-view data tends to be complementary and consistent. Therefore, it is critical to integrate multi-view features and fully exploit the consistency and complementarity to obtain shared discriminative representations.
Plenty of research has attempted to extract shared information from multi-view data to improve clustering performance [3]–[5], among which the graph-based approach is a mainstream issue. Graphs are typically built to represent relationships between different objects,with nodes corresponding to data objects and weighted edges depicting the similarity between data points. Generally, multi-view graph clustering methods can be roughly boiled down to two stages: first learning a consensus graph from all views, then applying post-processing techniques on the learned graph to obtain clustering results [6].Since the quality of the learned graph can directly determine the clustering effect, how to learn a high-quality graph becomes a critical issue [7]. For that, [3] proposes a self-weighted method to explore a Laplacian constrained graph and directly obtain the clustering result without any follow-up processing. Reference [8] designs a regularization term to adaptively learn weights of the views for diversity enrichment and redundancy reduction. Furthermore, to avoid the effect of the predefined graph quality, [9] introduces a disagreement cost function and constrains the rank of the Laplacian matrix of the learned graph. However, these methods merely focus on optimal weight learning for each view and neglect the local spatial consistency between different views, resulting in the lack of spatial integrity.
Besides, various deep clustering methods are constructed to exploit latent semantic information among data. For instance, [10] proposes a deep canonical correlation analysis framework, which employs two deep neural networks to extract implicit features of each view. To better explore complementary information, [11] presents a semi-nonnegative matrix factorization method for learning hierarchical semantics of multi-view data. Reference [12] integrates the within-view invariance, the between-view consistency, and the nonlinear embedding network to learn a common space for spectral clustering.Recently, [13] proposes an instance-level and cluster-level contrastive learning method for clustering and [14] lifts the instancelevel consistency to the cluster-level consistency for graph learning.Furthermore, [15] learns an informative and consistent representation by maximizing the mutual information between diverse views by introducing contrastive learning. Despite these autoencoder-based models can effectively extract latent information, they solely achieve the element-level reconstructed approximation but lack of samplelevel approximation, which are not conducive to the consensus graph learning.
Based on the above observations, we propose a multi-view clustering network by utilizing a convolutional autoencoder for learning a consensus graph. The proposed network is illustrated in Fig. 1, which is composed of a graph construction layer and a symmetric convolutional autoencoder. Specifically, we integrate convolutional autoencoder, consensus graph learning, and contrastive reconstruction learning into a unified framework to obtain a common graph with spatial consistency. The main contributions are summarized as:1) Build a convolutional autoencoder to capture the local spatial information from different views and obtain a latent consensus graph;2) A consensus graph loss is proposed to approximate the consensus graph with all raw graphs so as to preserve the global spatial consistency of the learned graph; 3) Introduce a contrastive reconstruction loss to constrain the sample-level consistency, and to enhance the similarity between reconstructed graphs and raw graphs.deconvolution operation, respectively. The architecture of the proposed model is described as follows.
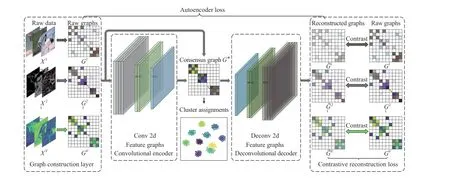
Fig. 1. A scheme of the proposed model, which consists of a graph construction layer and a convolutional autoencoder network. Given raw data, the proposed model first constructs affinity graphs by a specific graph construction method. Accordingly, the affinity graphs are fed to the convolutional autoencoder to learn a consensus graph by jointly minimizing the autoencoder loss, the consensus graph loss and the contrastive reconstruction loss.



1) Graph construction layer: The nearest neighbors method is first utilized to generate the adjacency matrices of raw data, then the affinity matrices are constructed by Gaussian kernel function as whereαandβare employed to balance the impact of consensus graph loss and the contrastive reconstruction loss. In the process of minimizing the total loss, the network is steered to learn a consensus graph as summarized in Algorithm 1. Finally, the clustering result is obtained by conducting spectral clustering on the learned graph.

Algorithm 1 Contrastive Consensus Graph Learning Input: Multi-view data , the number of nearest neighbors k,learning rate , training epochs t, weight parameters α and β.G*Output: Consensus graph .X G X lr 1: Generate adjacency graphs by KNN from , and then construct affinity graphs using (1).2: Initial the network weights by Xavier normalization.epoch=1 →t 3: for do G ˆG 4: Calculate feature graphs and by (2) and (3).5: Compute the autoencoder loss by (4).Lc Lae 6: Obtain the contrastive recounstruction loss by (9) and (10).ωi Lz 7: Calculate for each view through (8), then compute the consensus graph loss by (5).L 8: Calculate the total loss by (11).9: Update network parameters by gradient descent method.10: end for G*11: return Ouput of the encoder .

Experiments:
1) Datasets: The experiments are conducted on six classical datasets, and a brief description is illustrated as follows. Specifically,ALOI contains 1079 object images with four color features. Hand-Written (HW) are 2000 handwritten digits images with six views.Caltech101-20 is a object recognition dataset with 101 categories,and we select 2386 samples of 20 classes for testing. Youtube consists of 2000 samples including three visual features and three audio features. NUS-WIDE is comprised of 1600 web images of six available features. MNIST10k is a image dataset of 10000 handwritten digits with IsoProjection, linear discriminant analysis (LDA) and neighborhood preserving embedding (NPE) features as three views.
2) Comparisons and parameter settings: The proposed method is compared with the following nine methods. Best single view (BSV)is adopted to record the best spectral single-view clustering performance of all raw affinity graphs. The rest compared clustering methods are tensorized multi-view subspace representation learning(TMSRL) [16], multi-view clustering via deep matrix factorization(DMF-MVC) [11], deep generalized canonical correlation analysis(DGCCA) [10], multi-veiw spectral clustering network (MvSCN)[12], multiview consensus graph clustering (MCGC) [9], graphbased multi-view clustering (GMC) [7], binary multi-view clustering(BMVC) [17] and consensus graph learning (CGL) [6]. All the parameters involved in compared algorithms are set to the recommended values in their papers. For the proposed model, there are both 3 convolutional and deconvolutional layers and the size of all convolution kernels is 3 ×3, where each layer is followed by a ReLU activation. Strides of horizontal and vertical directions are both1 with one zero-padding layer to obtain feature graphs with the size ofn×n. In the encoder, the number of convolution kernels are [4, 2, 1]in order, while there are [2, 4,V] deconvolution kernels in the decoder. For all datasets, the number of nearest neighborskis chosen as 10 with the bandwidth ε=1, the exponentpof consensus weight is set to -1, and the temperatureτin the contrastive loss is fixed to 1, and we set α=1 and β=1 as default. Moreover, Adam optimizer is utilized to accelerate the minimization of the total loss withlr=0.01. Uniformly, we train 300 epochs on all datasets to obtain consensus graphs. All experiments are conducted for 10 times,then the mean and the standard deviation of the clustering performance are computed as the final results.
3) Clustering results: The classical metric accuracy (ACC) is adopted to evaluate the clustering performance. The clustering results of all compared algorithms are presented in Table 1, where we can obtain the following observations. Compared with BSV, the proposed model exhibits better performance. Compared with the tensorbased method TMSRL, the proposed model exhibits significant clustering superiority on all datasets. As for deep methods such as DGCCA, our method also gains superior performance on most datasets, which demonstrates the effectiveness of the convolutional autoencoder. Furthermore, compared with graph-based methods, the proposed model still obtains higher accuracy especially on HW and MNIST where the mean accuracy is close to 100%. In summary, the proposed model is capable of learning a well clustered graph and achieving satisfactory clustering results.
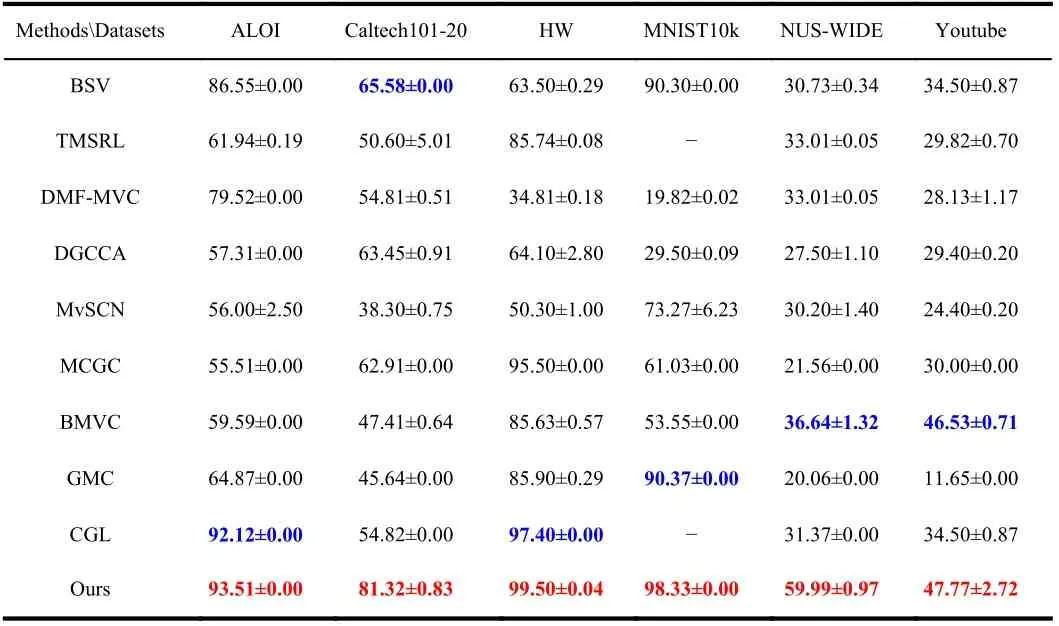
Table 1.The ACC (MEAN±STD%) of Multi-View Clustering Algorithms,Where the Best and Second Best Results are Marked in Red and Blue Respectively, And “-” Denotes the Failed Results.
4) Ablation study: As shown in Table 2, the ablation study is performed to investigate the influence of the consensus graph loss and the contrastive loss. The results indicate that the proposed model performs poorly with only autoencoder loss. After adding the consensus graph loss, the clustering performance of the proposed model is significantly improved. Further introducing the contrastive reconstruction loss, the proposed model performs best. It can be inferred that the consensus graph constraint can guide the network to effectively explore the discriminative spatial information from diverse views.Simultaneously, with the contrastive reconstruction loss, the samplelevel similarity between the reconstructed graphs and raw graphs can be strengthened, and in turn enhancing the graph learning.
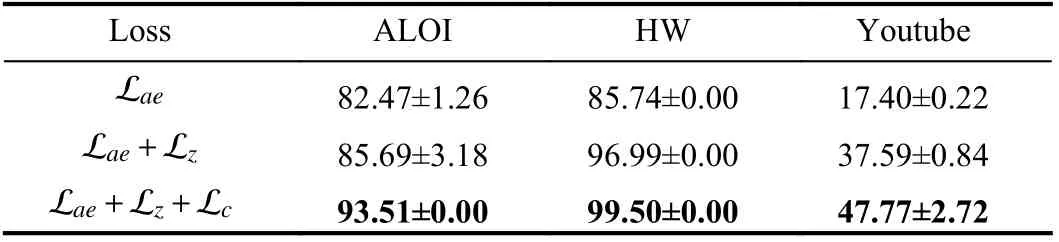
Table 2.The Ablation Study on ALOI, HW and Youtube w.r.t ACC(Mean±STD%), where the Best Results are in Bold.
5) Convergence and parameter sensitivity: The objective function values with the number of epochs are illustrated in Fig. 2(a), where MNIST10k is scaled by 10 times to keep all curves in the same inter-

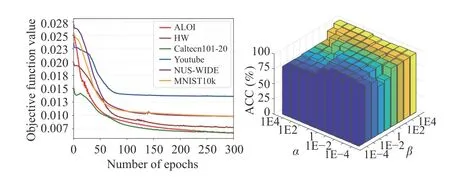
Fig. 2. Convergence and parameter sensitivity of the proposed method. (a)Curves of objective function values with the number of epochs; (b) Clustering metric ACC on HW with varied α and β.
Conclusions: This letter proposed a contrastive consensus graph learning model to learn a consensus graph, which adopted a convolutional autoencoder network to efficiently explore the latent spatial association among data. With the constraints of the consensus graph loss, the learned graph was able to maintain global spatial consistency across diverse views. Furthermore, a contrastive reconstruction loss was introduced to achieve sample-level approximations between the reconstructed graphs and the raw graphs, further to enhance the consistency of the learned graph. Experimental results demonstrated the superiority of the proposed model.
Acknowledgments: This work was supported by the National Natural Science Foundation of China (U21A20472, 62072223), the National Key Research and Development Plan of China (2021YFB 3600503), and the Natural Science Foundation of Fujian Province(2020J01130193, 2020J01131199).
 IEEE/CAA Journal of Automatica Sinica2022年11期
IEEE/CAA Journal of Automatica Sinica2022年11期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Adaptive Generalized Eigenvector Estimating Algorithm for Hermitian Matrix Pencil
- Receding-Horizon Trajectory Planning for Under-Actuated Autonomous Vehicles Based on Collaborative Neurodynamic Optimization
- A Zonotopic-Based Watermarking Design to Detect Replay Attacks
- A Bi-population Cooperative Optimization Algorithm Assisted by an Autoencoder for Medium-scale Expensive Problems
- Recursive Filtering for Nonlinear Systems With Self-Interferences Over Full-Duplex Relay Networks
- Frequency Regulation of Power Systems With a Wind Farm by Sliding-Mode-Based Design