
基于移位窗口多头自注意力U型网络的低照度图像增强方法
2022-10-29 03:29孙帮勇赵兴运吴思远
电子与信息学报 2022年10期
孙帮勇 赵兴运 吴思远 于 涛*
①(西安理工大学印刷包装与数字媒体学院 西安 710048)
②(中国科学院西安光学精密机械研究所光谱成像技术重点实验室 西安 710119)
1 引言
利用现有成像传感器在弱光条件下所获取的图像,多存在低对比度、噪声大、颜色细节失真等缺陷,导致该类图像的视觉感受质量较差,同时也会降低图像分割、目标识别及视频监控等后续图像处理任务精度。低照度图像增强算法,能够提升弱光条件下退化图像的视觉感受质量,形成近似于正常光照条件下的图像质量,因此在计算机视觉相关领域具有较强应用前景,已成为图像处理领域的研究热点之一。
低照度图像提升方法的关键,在保持原低照度图像结构和不同位置亮度相关性的基础上,提升图像的整体亮度值并重建颜色信息。研究发现,低照度图像增强方法主要分为3类,即基于底层图像处理的方法、基于视网膜(Retinex)理论的方法和深度学习类的图像增强方法。基于底层图像处理的低照度增强方法,直接利用线性函数提高图像亮度,虽然图像全局的亮度得到提升,但是由于不考虑图像亮度的空间分布,常导致增强图像高亮区域过饱和、细节丢失严重等缺陷。后来,研究者又采用非线性映射函数提升图像亮度,例如Kim等人[1]、Celik[2]所提出的直方图均衡化(Histogram Equalization, HE)方法。这类非线性函数通过调整参数改变图像亮度的提升幅度,以不同程度增加高亮区域和低亮区域的亮度信息,一定程度保证了增强后的图像质量。该类算法操作简单、效率高,但增强图像常存在伪影缺陷,真实感不强。
基于Retinex理论的低照度图像增强方法,通过模拟人眼视觉系统,将低照度图像分解为照明分量和反射分量,通过调整照明分量提升图像亮度和对比度。其中,Jobson等人[3]提出单尺度Retinex算法(Single-Scale Retinex, SSR),将高斯核作为卷积核对低照度图像进行卷积操作,得到的结果近似表示为反射分量。同年,Jobson等人[4]又提出多尺度Retinex算法(Multi-Scale Retinex, MSR),MSR是SSR的改进算法,其采用不同尺度的高斯滤波,对滤波结果进行加权平均以估计照明图像。Wang等人[5]提出保留图像自然度的Retinex算法,利用Retinex理论和log双边转换使光照分量映射更加接近自然色。Li等人[6]提出鲁棒的Retinex算法,通过加入一个噪声项来处理弱光图像增强。该类算法在照明调节方面和低噪声消除方面具有一定的效果,但算法模型较为复杂,需要人工设定合适的参数,无法自适应处理图像的多样性。
基于深度学习的低照度图像增强方法,关键利用大规模训练数据集对最佳网络模型进行学习,建立低照度图像和正常光照图像之间的复杂映射关系。Lore等人[7]最先提出使用深度自编码器网络来增强低照度图像,提升亮度的同时消除一定噪声。Wei等人[8]基于Retinex理论提出Retinex网络(Retinex decomposition for low-light enhancement Network, RetinexNet),采用两个子网络将低照度图像分解成照明分量与反射分量,并对照明分量进行调整。Zhang等人[9]在RetinexNet基础上提出点燃黑暗网络(Kindling the Darkness, KinD),对图像分解与重建结构进行优化,并添加图像恢复网络用于去除图像噪声。Chen等人[10]提出学习网络(learning to See In the Dark, SID),直接对传感器数据进行低照度图像增强。Wang等人[11]提出深度光照估计网络(Underexposed Photo Enhancement using Deep illumination estimation, DeepUPE),通过学习图像-光照映射关系来预测平滑的光照映射。Jiang等人[12]提出无监督对抗网络(Enlighten Generative Adversarial Network, EnlightenGAN),利用全局-局部鉴别器和自正则化注意力机制,实现了网络结构不需要成对图像数据集训练,能够适应真实的图像状态,应用领域更加广泛。尽管基于深度学习的方法在一定程度上弥补了前两类方法的不足,针对多数低照度图像都能够取得较好的视觉效果,但是,现阶段对于较暗条件下拍摄的低照度图像,该类方法仍不能有效抑制图像噪声,难以产生令人满意的视觉质量。
基于以上研究发现,当前低照度图像增强方法主要面临两个难题:(1)如何在不同曝光区域自适应提升图像亮度,解决图像的光照不均匀问题;(2)如何有效抑制图像噪声并保持颜色纹理细节的一致性,提高图像信噪比。本文针对以上两个低照度增强问题,建立了一种基于移位窗口多头自注意力U型低照度图像增强网络。针对自适应提升图像亮度问题,本文设计了移位窗口多头自注意力模块,利用多头自注意力机制的特征提取优势,对输入输出的全局依赖关系进行建模,在学习图像亮度提升模型的同时,针对图像照明不足区域的噪声进行抑制。对于保持图像颜色纹理细节一致性问题,本文将网络整体框架设置为U型结构,利用下采样模块,增加深层网络的感受野大小,使模型学习到图像的全局特征。此外,为了缓解深层网络在提取较高语义特征时丢失部分浅层信息的缺陷,本文加入跳跃连接,在编码器和解码器子网络的相同尺寸的特征映射上进行聚合,使网络解码部分依然拥有网络的浅层特征信息。利用U型网络架构学习到的图像全局特征,在恢复图像时更好地保持图像颜色纹理细节的一致性。本文其余结构如下:第2节介绍低照度图像成像模型;第3节详细讲述本文提出的算法;第4节阐述实验结果与分析;第5节为本文的结论。
2 低照度图像成像模型
根据物体呈现色彩感知的光学原理,人眼形成色彩感觉基于3种因素:光、物体对光的反射以及人的视觉感知。特定光谱能量分布的可见光照射到物体上,在各波长位置上一定比例的光子被吸收,另一部分则被反射进入人眼,刺激视神经传递到大脑,在参考光源的对比下形成物体的色彩信息。与物体呈现色彩原理类似,数字相机成像中的图像传感器模拟人的视觉感受器,将读取到的光信号转变为数字信号形成图像。如图1所示,低照度图像成像过程中,多存在遮蔽物等因素阻碍光源充分照射到目标物,当部分入射光分量到达物体表面,根据物体自身的物质特性吸收部分入射光并将其余光线反射,反射光线经过空气介质传播到相机,根据相机的成像响应模型将光信号转变为数字信号形成数字图像。
低照度环境下进行数字成像,多存在光源来源复杂、照度不均匀等问题,造成成像数字图像的总体亮度值极低,可见度和对比度损失严重,并伴大量随机噪声;有时由于光照分布不均匀,部分区域照明充足而周边区域却亮度极低,从而出现细节丢失等问题。由以上成像模型分析可知,导致低照度图像的主要成因是:入射光线不足;反射光从反射物体表面到相机传感器之间的光衰减;相机成像传感器对反射光的非线性响应函数。以下对该3个成因进行分析。
2.1 低照度图像的入射光线不足成因
数字成像是一个将目标物表面光辐射强度转换为图像灰度的过程,其本质是光信号、电信号和数字信号的转换,所形成的数字图像信号强度主要取决于目标物体本身的亮度和成像传感器的光电转换特性。对于非自发光目标,物体本身的亮度与环境光辐射强度和表面吸收特性相关。数字成像时,物体表面亮度转化为图像灰度的过程可描述为
其中,f(x,y)代表数字图像灰度值;i(x,y)代表照度分量,即入射到物体表面的光通量,主要由环境光源决定;r(x,y)代表反射分量,由物体的表面特性决定,·代表乘法运算。在夜晚、避光房间等光线不足环境下采集图像时,光源照射在物体表面的光通量强度很低,照度分量i(x,y)很小,导致图像灰度值f(x,y)范围较小、分辨力差,从而形成退化的低照度图像。
2.2 低照度图像的反射光衰减成因
入射光照射在物体表面,产生的反射光在到达相机镜头之前的传播路径中,存在光衰减现象。光衰减主要受大气透射系数、空气中雾霾或尘土等颗粒以及成像景深等影响,较显著的光衰减会导致图像物体反射光进入镜头不充分,而与目标物无关的大气散射光则可能进入相机,这将导致数字图像出现细节丢失、质量下降等退化问题。一般,在理想的大气环境下,不考虑雾、霾、尘土等粒子的光线散射影响,光衰减过程可以表示为
2.3 低照度图像的相机响应曲线成因
相机拍摄图像的处理流程如图2所示,物体反射的光线进入相机镜头后,通过线性映射在图像传感器的表面形成辐照度E,利用快门控制一定时间后达到图像传感器足够的曝光量,在图像传感器上进行光电转换得到模拟信号,最后经过模数转换等步骤形成每个像素的颜色值。
数字成像过程中,辐照度E映射到像素值Z的过程是一个非线性过程,称为相机响应函数(Camera Response Function, CRF)。由于人眼对图像中间阶调的灰度敏感,为了模拟人眼感受,相机响应曲线一般呈S型曲线,提高对中间灰度的辨识度,而对较低和较高的数值不敏感。在低照度环境下,正常曝光时间内到达相机传感器的光子数量较少,所获取的图像灰度集中在CRF较低的不敏感区域;同时对于部分极度微弱的光线环境,其光信号甚至可能无法引起相机传感器响应,这将造成大量的图像细节丢失。尽管可以通过调整光圈、延长快门时间来增加进入相机镜头的曝光量,或者调整相机感光度增加对光的灵敏度,来提升成像图像整体的亮度,但利用这些手段拍摄的图像多伴随明显颗粒感、复杂噪声、颜色失真等问题。
3 本文算法
3.1 网络框架
针对低照度成像中的传感器响应不充分、颜色失真、复杂噪声等问题,利用传统模型对低照度图像直接校正存在较大难度。考虑到深度网络在建立复杂非线性映射关系的优势,本文采用深度学习方法提出一种基于移位窗口多头自注意力U型网络的低照度增强方法。针对低照度图像的一系列退化问题,设计了移位窗口多头自注意力模块,并配合编码器解码器网络结构,不仅能够自适应提升图像亮度、抑制噪声,并且还较好地保持图像颜色纹理细节的一致性,有效提高了图像的视觉感受质量和其他客观评价指标。
本文所提低照度图像增强网络以U型架构为框架,主要由嵌入(Embedding)层、编码器、解码器、跳跃连接和扩张(Expanding)层组成,与现有的大量低照度提升方法不同,该网络采用了移位窗口多头自注意力模块,可以更充分地提取图像特征并学习低照度图像和参考图像的复杂映射关系。如图3所示,所建立的增强网络是一种端到端结构,输入为待增强的低照度图像,输出为同尺度正常亮度的重建图像。
如图3,本文所提低照度图像增强网络包含图像预处理、特征学习、图像重建等过程。首先,利用Embedding模块进行像素预处理,低照度图像被划分为多个大小为4×4的非重叠图像块(patch),每个patch内的像素值排列为一个向量,从而将输入的像素级低照度图像转化为patch嵌入,以便于下一步提取图像语义信息。然后,预处理后的嵌入图像块被输入到3层结构的编码器,编码器应用了典型的U型神经网络(U-Network, U-Net)[13]结构。编码器每层由移位窗口多头自注意力模块和下采样模块组成,其中移位窗口多头自注意力模块负责特征表示学习,有效提取预处理图像的特征信息,捕获长期依赖关系,而下采样模块主要负责降低特征尺寸并增维。同时,本文在编码器与解码器之间单独增加一个移位窗口多头自注意力模块,对编码器获取的长期依赖关系进行融合,防止编码器可能出现的不收敛情况。类似地,解码器也采用3层结构,每层由上采样模块和移位窗口多头自注意力模块组成,其中上采样模块负责增加特征尺度并降维,移位窗口多头自注意力模块负责从语义特征中恢复图像信息。最后,利用Expanding模块将解码器输出特征图分辨率恢复到输入分辨率并映射为红绿蓝(Red Green and Blue, RGB)3通道,所重建的图像达到正常亮度范围。
3.2 移位窗口多头自注意力模块
本文所建立低照度提升网络的主要特色,采用移位窗口多头自注意力模块进行特征提取和学习,利用自注意力机制的特征提取优势,获取有用的图像特征,建立图像特征的长期依赖关系,有效保证了网络模型建立正确的非线性映射关系。移位窗口多头自注意力模块由传统多头自注意力模块改进而来,其通过划分窗口将输入图像划分为不同的窗口,并在每个窗口内部利用多头自注意力模块捕获依赖关系,同时又利用移位窗口策略,完成了不同窗口之间的内容交互,极大地减少了网络的计算复杂度。在窗口内单独进行自注意力计算,无法获取整体图像全局特征信息,移位窗口策略是将输入图像采用像素循环位移方式,循环位移半个窗口大小,对输入图像进行像素位置改变,再通过划分窗口将移位后输入图像划分为不同的窗口,确保划分窗口内与未移位窗口划分,分别包含输入图像不同位置区域的特征信息,保证不同窗口内信息交互。移位窗口多头自注意力模块如图4所示,由正则化层(Layer Normalization, LN)、窗口多头自注意力(Windows based Multi-head Self-Attention,W-MSA)、移位窗口多头自注意力(Shifted Window based Multi-head Self-Attention, SWMSA)、前馈网络层和残差连接组成。其中,LN正则化层主要作用是进行批量正则化处理,对输入数据进行归一化处理,从而保证输入层数据分布的规则性。W-MSA和SW-MSA代表在不同区域窗口内进行自注意力计算,自注意力[14]计算可表示为
其中,Q代表查询矩阵,K代表键矩阵,V代表值矩阵,d代表查询矩阵或键矩阵的维度。B代表位置矩阵,取自偏置矩阵B ∈R(2M-1)(2M+1),M代表输入嵌入块内patch的数量。
本文所提移位窗口多头自注意力模块基于当前流行的自注意力机制改进而来,具有如下优势:(1)采用窗口划分,将自注意力计算由整张图像限制在划分窗口内,并通过移位窗口策略,确保不同窗口之间的信息交互,极大地降低了自注意力计算复杂度,使之网络变得轻量化。(2)尝试将自注意力机制用于图像处理领域,并针对低照度图像增强任务取得了较好的结果。
3.3 损失函数
考虑到低照度图像增强任务的特殊性,以准确重建图像亮度范围、提高颜色真实性及消除噪声等为目标,本文构建了一种综合性损失函数。该损失函数主要由L1[15]损失函数、结构相似性(Structural SIMilarity index, SSIM)[16]损失函数、感知损失[17]函数和感知颜色损失[18]函数组成,被表示为
结构相似性损失:本文采用结构相似性SSIM损失函数从亮度、对比度和图像结构3个方面来衡量真实图像和预测图像的结构损失,有助于恢复图像的结构和局部细节。SSIM值范围为0~1,其中值越高表示相似性越好
感知损失:本文采用结构感知损失约束真实图像和预测图像之间的差异,保持图像感知和细节的真实性,同时保持感知和语义保真度
感知颜色损失:本文采用感知颜色损失约束增强结果与真实图像在欧几里得空间中的颜色差异,促使增强结果产生与参考图像相似的颜色,保证增强结果的颜色一致性
4 实验与结果分析
4.1 数据集及实验设置
本文实验数据使用Wei等人[8]提供的低照度图像数据集(LOw-Light dataset, LOL),LOL数据集图像分为室内和室外两种场景,是在微光环境条件下获取的真实微光图像。为了适应网络模型,对LOL整体数据集进行裁切处理,每张图像被裁切为224像素×448像素。实验采用裁切后LOL数据集中前689对图像作为训练集,后100对图像作为测试集。另外,为了提高模型的泛化能力,训练集中又加入900对人工合成图像。
本文实验环境配置如下,在Windows 10系统下采用Nvidia GTX 2080显卡,运用Python编程语言和Pytorch框架实现网络搭建。网络参数设置中,批处理大小为6,epoch为1000次,使用ADAM优化器进行优化,前300轮生成模型的学习率为0.0001,后700轮次模型的学习率每隔300轮次缩小为原来的0.5。
4.2 评价指标
本文采用3个不同的有参考客观评价指标:峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)、结构相似性(SSIM)和图像感知相似度(Learned Perceptual Image Patch Similarity, LPIPS)[19]指标。PSNR是计算对应像素点间的误差,即基于误差敏感的图像质量评价,测量图像之间的保真度。SSIM更多地考虑图像结构,分别从亮度、对比度、结构3方面度量图像相似性。目标图像和生成图像的相似性,两者越相似,SSIM和PSNR的评分越高。LPIPS利用深度神经网络来评价生成图像质量,评价图像特征之间的感知距离,其数值越高意味着两幅图差异越大,越低意味着越相似。
4.3 实验结果
为了验证本文所提方法的有效性,分别将本文方法与当前较为流行的算法进行对比实验,对比算法有多分支微光增强网络(Multi-Branch Low-Light image/video Enhancement Network, MBLLEN)[20],RetinexNet[8],KinD[9]、全局照明和细节保护网络(Global Lighting And Detail protection Network,GLADNet)[21]、自监督增强网络(Self-supervised Image Enhancement network, SIE)[22]、零参考增强网络(Zero-reference Deep Curve Estimation for low-light image enhancement, Zero-DCE)[23]。MBLLEN算法核心思想是提取不同层次的丰富特征,通过多个子网络进行增强,最后通过多分支融合产生输出图像。RetinexNet算法基于经典Retinex理论,采用两个子网络将低照度图像分解成照明分量与反射分量,并对照明分量进行调整。KinD算法在RetinexNet算法基础上,对图像分解与重建结构进行优化,并添加图像恢复网络用于去除图像噪声。GLADNet算法的核心思想是先计算出低照度输入图像的全局光照估计,然后在光照估计图的指导下调整光照,并通过与原始输入的级联来补充细节。SIE算法是一种基于深度学习的自监督低照度图像增强方法,只用低照度图像进行训练。Zero-DCE算法通过设计无参考损失函数,使得网络在没有任何参考图像的情况下能够进行端到端训练。以上选取的算法,分别采用当前计算机视觉领域流行的不同方法,在低照度图像增强领域非常具有代表性。对比实验主要分为两部分,分别从主观评价、客观评价两方面进行比较。考虑到公平性,实验时使用对比算法所提供的公开可用代码和所推荐参数设置。
4.3.1 主观评价
首先在LOL测试集上,将本文输出结果视觉效果图与对比算法输出结果进行主观比较。如图5所示,选取部分具有代表性图像的可视化结果,重点对比低照度图像噪声干扰、颜色失真以及正确提升图像对比度等常见问题。明显可以看出,RetinexNet算法的输出效果最差,输出图像不仅存在严重的噪声,并伴随图像部分区域过度曝光现象,具有非常差的视觉感受。MBLLEN, SIE, Zero-DCE算法的输出效果比RetinexNet算法的输出效果视觉感受要好,基本能够正确提升图像亮度,但提升亮度力度不够,与参考图像相比均整体亮度偏暗,且图像细节方面存在部分轻微噪声和颜色失真现象。GLADNet算法的输出效果与前几种算法相比,增加了图像亮度提升的力度,造成输出图像整体亮度高于参考图像,同时引起更加严重的颜色失真现象,输出图像整体色调偏黄。针对低照度图像光照不均匀问题,以上算法均不能准确提升图像亮度,并伴随噪声干扰以及颜色失真问题。KinD算法与本文算法在图像亮度提升方面,均能够准确提升不同区域图像亮度,与参考图像相比几乎无差异,在噪声抑制方面,都能够获得良好的视觉效果。在保持颜色一致性方面,KinD算法与本文算法的输出结果在大部分场景下与参考图像在颜色细节方面保持一致,但还存在部分场景颜色失真现象。例如针对绿色植被场景,KinD算法与本文算法的输出结果均与参考图像存在颜色差异,如图5的图像2所示,KinD算法和本文算法针对树叶的输出结果与参考图像相比,输出结果整体颜色稍微偏暗,树叶之间的层次感不强,存在轻微颜色失真,但整体来看,本文算法比KinD算法具有更舒服的视觉效果。
综上所述,本文算法在大部分场景下都能做到图像细节及纹理信息的精准还原,但针对图像大面积区域图像颜色单一,层次信息强,例如草地、树木以及绿色植被等这类图像。本文算法的输出结果同样存在颜色失真现象,其主要原因是这类图像大面积区域颜色较为单一,但又存在细微的明暗差别,且层次信息丰富,本文算法在抑制噪声的同时,削弱了图像的层次信息,导致输出结果在该区域层次感不强,颜色恢复细节不到位。总体来看,本文算法依然能够取得较好的视觉效果,在图像亮度提升、噪声抑制、颜色恢复以及保持图像结构纹理方面占有一定的优势。
4.3.2 客观评价
本文采用PSNR, SSIM和LPIPS 3种有参考图像质量评价指标对本文算法与对比算法进行客观评价,采用LOL测试集,客观评价结果如表1所示。可以看出本文所提出的方法在PSNR, SSIM和LPIPS 3个指标方面都取得了更好的结果,较对比算法中最优值分别提高了0.35 dB, 0.041, 0.031。证明了本文所提出的方法在低照度图像亮度提升、噪声去除以及纹理细节恢复等方面具有一定的优势。

表1 不同算法处理后客观评价指标结果图
4.4 消融实验
为了使网络学习到最优模型,本文分别对编码器3层结构中每一层移位窗口自注意力模块数量以及损失函数系数进行消融实验。在表2、表3中,分别量化了不同编码器结构以及不同损失函数系数的有效性。通过主观评价和客观指标对比可以看出,当编码器每层架构中的移位窗口多头自注意力模块的个数为[2, 2, 6],以及损失函数系数λs=0.25,λp=0.2,λc=0.05时,本文网络模型获得了最优效果,消融实验中部分代表性测试图像的视觉效果如图6所示。

表2 不同编码器结构在测试集上客观评价指标
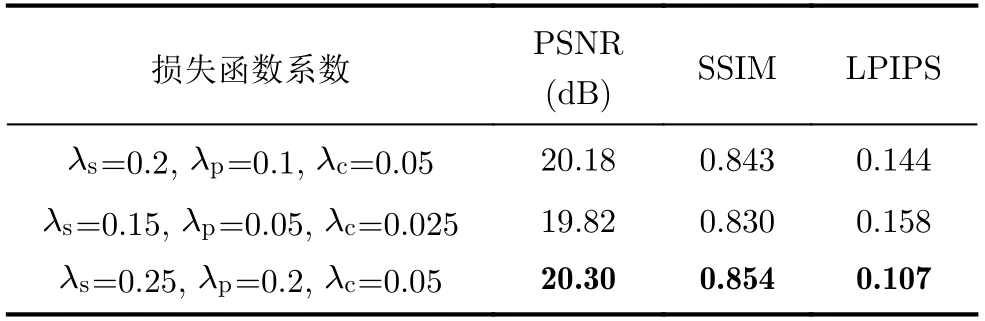
表3 不同损失函数系数在测试集上客观评价指标
从图6可以看出,当编码器结构为[2, 2, 2]时,增强后的图像明显出现颜色不一致、图像整体过亮等情况,并存在轻微噪声。当编码器结构为[2, 4,6]时,增强后的图像较[2, 2, 2]结构时有了明显的改进,但依然存在图像整体偏亮,轻微的颜色偏差。当损失函数系数λs=0.2,λp=0.1,λc=0.05时,增强后的图像能够正确提升图像亮度,但存在颜色不一致现象。当损失函数系数λs=0.15,λp=0.05,λc=0.02时,增强后的图像能够保持图像颜色的一致性,但图像整体偏亮。当编码器结构为[2, 2,6],损失函数系数为λs=0.25,λp=0.2,λc=0.05时,增强后的图像在亮度提升,噪声去除以及保持颜色纹理细节方面较上述方案均有更好的视觉效果,并与参考图像基本保持一致,只存在轻微的细节差别。
5 结束语
本文旨在解决低照度图像亮度提升、噪声抑制以及颜色细节恢复等问题,提出了一种基于移位窗口多头自注意力机制的U型网络框架,来实现低照度图像的亮度信息重建。所建立的低照度增强网络利用多头自注意力机制的特征提取优势,构建特征间的长依赖关系,更全、更广地提取图像语义特征;同时利用编/解码器结构,采用分层提取不同层次语义特征,来获取更大的感受野,获得更广泛的全局信息;通过跳跃连接,将对应相同尺度编/解码器的不同语义特征进行融合,充分保留图像纹理及颜色特征,拥有更好的图像恢复效果。最后通过大量的实验,主观和客观地比较本文方法与当前流行算法对低照度图像的处理效果,结果表明,本文方法均取得较好的增强效果,基本解决了低照度图像亮度提升、噪声抑制以及颜色细节恢复等问题,但依然存在一定进步的空间。在后续工作中,将进一步对本文模型进行改进,使之拥有更好的泛化性能。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
昆明医科大学学报(2022年4期)2022-05-23
锻压装备与制造技术(2021年5期)2021-11-13
科学技术创新(2021年5期)2021-03-17
辽东学院学报(自然科学版)(2021年1期)2021-03-12
——编码器
演艺科技(2020年7期)2020-08-13
数学学习与研究(2020年22期)2020-01-11
应用心理学(2019年4期)2019-12-05
船舶标准化工程师(2019年4期)2019-07-24
做人与处世(2009年7期)2009-08-11
