
一种基于子空间聚类的雷达字提取算法*
2022-10-28 03:27高天昊王鹏达董尧尧姜浩浩
电讯技术 2022年10期
高天昊,曲 卫,王鹏达,董尧尧,姜浩浩
(航天工程大学 a.研究生院;b.电子与光学工程系,北京 101416)
0 引 言
为了深入研究多功能相控阵雷达(Multifunction Phased Array Radar,MPAR)的行为规律,为战场中的上级决策提供直接有效的一手作战情报,加拿大McMaster大学的Visnevski[1]于2005年在其博士论文中建立了一种多功能雷达的句法模型。该模型运用离散事件系统(Discrete Event System, DES)的相关理论展开建模,以“雷达字(Radar Word)”为最基本的模型单元,构建了雷达字、雷达短语和雷达句子逐级递进的层级模型。在此基础上,该团队又进行了雷达威胁等级判断[2]、雷达状态估计[3-4]等课题研究,并且取得了一定的成果。后续进行多功能相控阵雷达的行为分析,也大多基于句法模型中的雷达字,所以雷达字是否提取准确,对之后MPAR行为认知具有至关重要的作用。Visnevski等[5]运用事件驱动的方法进行雷达字的提取,简单易实现,但当脉冲描述字(Pulse Description Word,PDW)中其他参数不同而脉冲到达时间(Time of Arrival,TOA)相同时将会导致雷达字难以区分。王勇军[6]针对上述缺陷进行了改进,提出了一种改进的事件驱动的 MFR雷达字提取方法,但在虚假脉冲增多时提取准确率下降太快。欧健[7-8]提出了一种基于匹配滤波的雷达字提取方法,将雷达字提取转化为从随机信号中找出确定信号的问题,但其在测量误差和漏脉冲率较低情况下的提取性能不如传统算法。刘海军等[9]运用三级匹配(数据库级、脉冲级和码序列级)的方法,在脉冲丢失和假脉冲的噪声环境下也具有良好的提取能力,但该方法没有充分利用侦收信号的全部信息,只使用了脉冲到达时间一个参数,在很多特殊情况下提取效果很差。Li等[10]利用改进的TTP(TOA to PRI)变换法进行雷达字提取,但也只用到了TOA信息。
考虑到之前的提取算法对侦收信号的信息利用不充分的因素,加上脉冲间载频(Radar Frequency,RF)、脉宽(Pulse Wide,PW)、脉冲重复间隔(Pulse Repetition Interval,PRI)的调制模式反映了脉冲信号的变化规律,是分析判断雷达工作模式的重要依据,因此,本文将利用PRI、PW和CF三个参数的时空信息,采取子空间聚类的方法进行雷达字的提取。
1 认知电子战和MPAR
传统的电子战可以广义地界定为任何以控制电磁频谱为目标的军事行动[11]。发展到现在的认知电子战,主要是使得最初的电子战系统更加智能化,形成一个包含认知效能评估环、认知对抗环、认知侦察环和一个动态更新的知识库的闭合回路,其结构如图1所示。认知电子战的一个重要方面是MPAR与侦察方的相互作用。
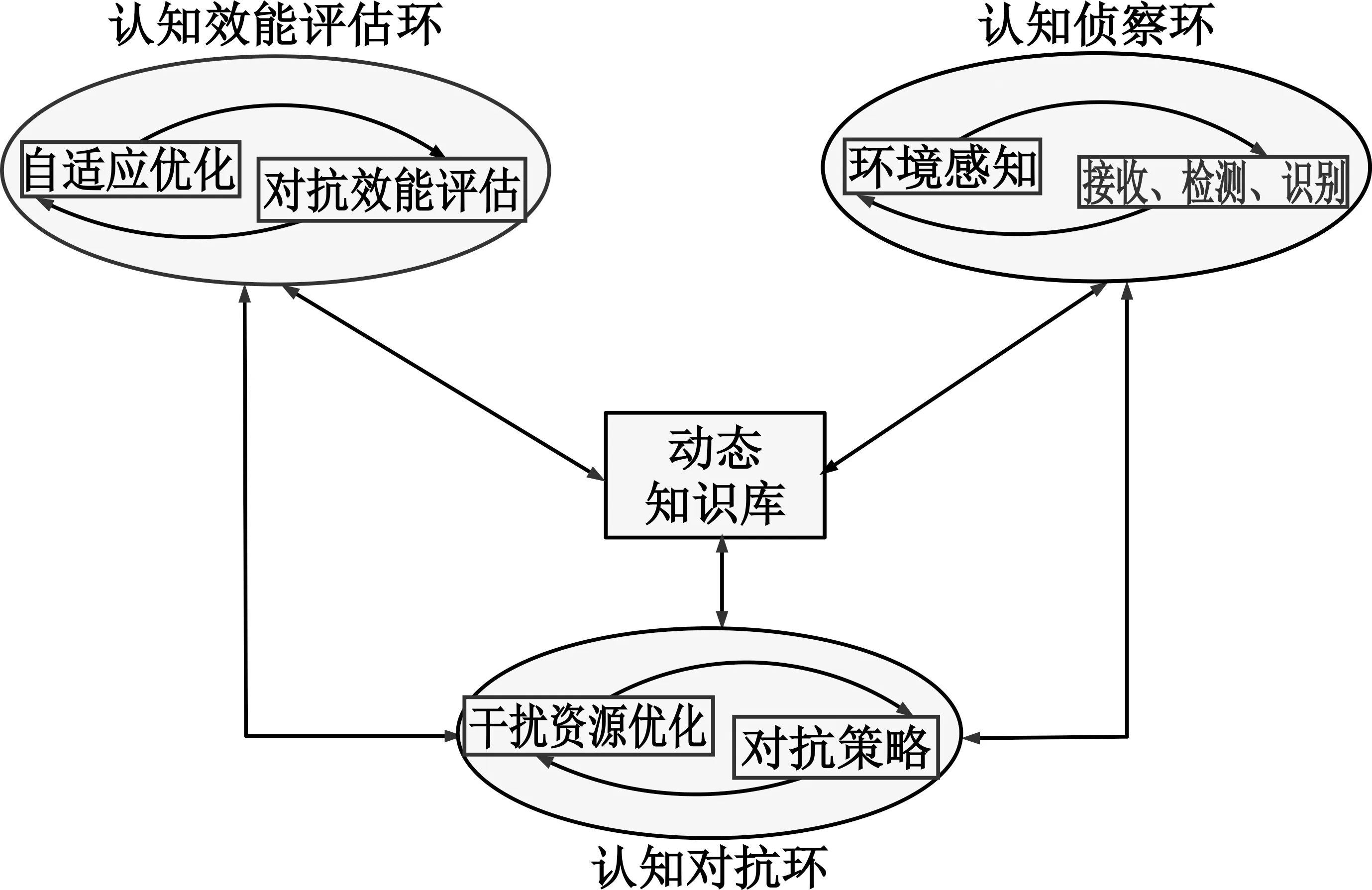
图1 认知电子战系统框图
一般来说,这种相互作用可以从两个完全不同的角度来研究,即MPAR和侦察方的角度。从MPAR的角度来看,侦察方是被检测和识别目标,需要对其保持稳定的跟踪。从侦察方的角度来看,是通过解释截获的MPAR辐射信号并评估其威胁(电子支援或专家系统)来保护自己免受雷达装备的威胁,并为上级的指挥决策提供直观的信息支援。在本文中,主要从侦察方去考虑问题,将MPAR作为威胁目标。
信号解释由两个主要组件组成,一个信号到符号转换器和一个符号推理机。以对海上航行的导弹驱逐舰进行认知侦察为背景,图2说明了专家系统体系结构环境中的两个组件,这里给出了对这两个组件的简要描述。
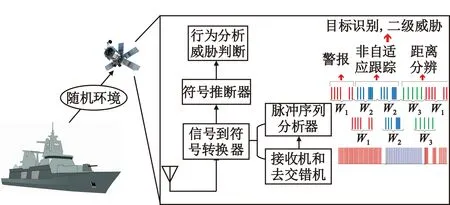
图2 侦察导弹驱逐舰场景模拟
信号到符号转换器由两部分组成,包括针对原始侦察数据的接收机和去交错器,以及脉冲序列分析器。接收机处理天线截获的雷达脉冲,并输出一系列PDW,其中PDW是一种数据结构,包含载波频率、脉冲幅度、单个脉冲的脉宽、脉冲到达时间等参数[12]。然后,解交织器(去交错机)对脉冲多普勒计程仪进行处理,并根据其原始雷达辐射源进行分离。脉冲序列分析器进一步处理去交错的脉冲波形,并将它们分类成称为雷达字的抽象符号(具体定义在下一节介绍)。符号推理器使用雷达信号的结构描述和人类语言的语法之间的类比,一个符号推理机被称为包含“说话”的“语言”MPAR的先前特定领域知识。该知识由雷达分析员获取的操作规则和约束组成,这些规则和约束被认为应用于为每个特定任务目标生成雷达信号,并且这种知识允许雷达分析员区分“语法”雷达信号和“非语法”雷达信号,同时推理MPAR正在执行的特定任务目标。在今天的现代雷达系统中,操作规则通常用模糊逻辑或专家系统来实现,传统的数学形式如微分和差分方程在分析它们时是无效的。相反,为了紧凑地存储制造商语言的语法知识,应用了形式语言理论,并且制造商语言将通过建立语法来完全指定。本文的重点在于信号到符号转换器,也就是雷达字的提取工作。下面简单介绍一下MPAR信号的分层体系结构以及雷达字的概念。
2 MPAR信号的分层体系结构
MPAR采用复杂的信号结构和计算机控制的脉冲重复间隔调度。Visnevski建立了一种针对于MPAR的句法模型,以“雷达字”为最基本的模型单元,构建了雷达字、雷达短语和雷达句子逐级递进的层级模型,如图3所示。图中最上层的雷达字是脉冲序列根据特定模式排列成若干组,是整个分层体系的基元结构;雷达短语由若干个雷达字组合在一起(图中是4个雷达字),表示MPAR的某种工作模式,如非自适应跟踪、距离测量、边搜索边跟踪等等;雷达句子是由雷达短语组成的,一个句子中短语的数量决定了MPAR可以同时执行的任务的数量。

图3 MPAR信号的分层体系结构
通过对多功能相控阵雷达信号的分层体系结构的描述不难看出,雷达字实际上就是经过特殊模式组合的一系列脉冲串。由于MPAR涉及到重大军事秘密,现有文献很少有具体公开介绍某种MPAR的具体雷达字设计细节。目前全球公开的MPAR雷达字仅有两种,如图4所示,分别是加拿大的“水星”多功能雷达和“冥王星”多功能雷达。“冥王星”雷达有4个不同的雷达字(w1w2w3w4)和一个终止字符(w5)。图4(a)中展示的w1的长度为51 000个晶体时钟计数,为了适应字长的差异,采用了可变持续时间的死区(B区域);终止字符是一系列预定的脉冲重复间隔,由5个不同的区域组成。“水星”多功能雷达有9个雷达字(w1~w9),图4(b)中所展示的雷达字包含三段空载时间(A、C、E)和两段具有固定脉冲重复周期的脉冲列(B、D)。
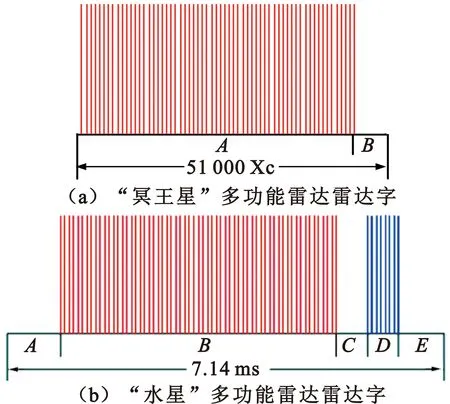
图4 两种典型雷达字
3 雷达字提取算法
3.1 雷达字提取面临的问题
雷达字作为多功能雷达信号分层体系结构的基元,对后续进行雷达行为分析起着至关重要的作用,所以亟需提出更加稳健的提取算法。经过前文分析,进行雷达字提取主要需要解决以下几方面的问题:第一是侦收到的雷达信号存在一定的测量误差,对后续雷达字提取带来一定的负面影响;第二是电磁环境中存在一定的环境噪声,使得侦收的脉冲列包含一定的虚假脉冲或者造成漏脉冲的现象;第三是提取算法需要具有很强的鲁棒性,不能对输入数据的顺序太过敏感。针对以上问题,本文提出了一种基于子空间聚类的雷达字提取算法,能有效解决以上问题。
3.2 相关概念和原理
本文所提的算法是根据1998年由Agrawal等人[13]提出的CLIQUE(Clustering In QUEst)聚类算法改进而来的。改进的算法基于以下定义和原理。
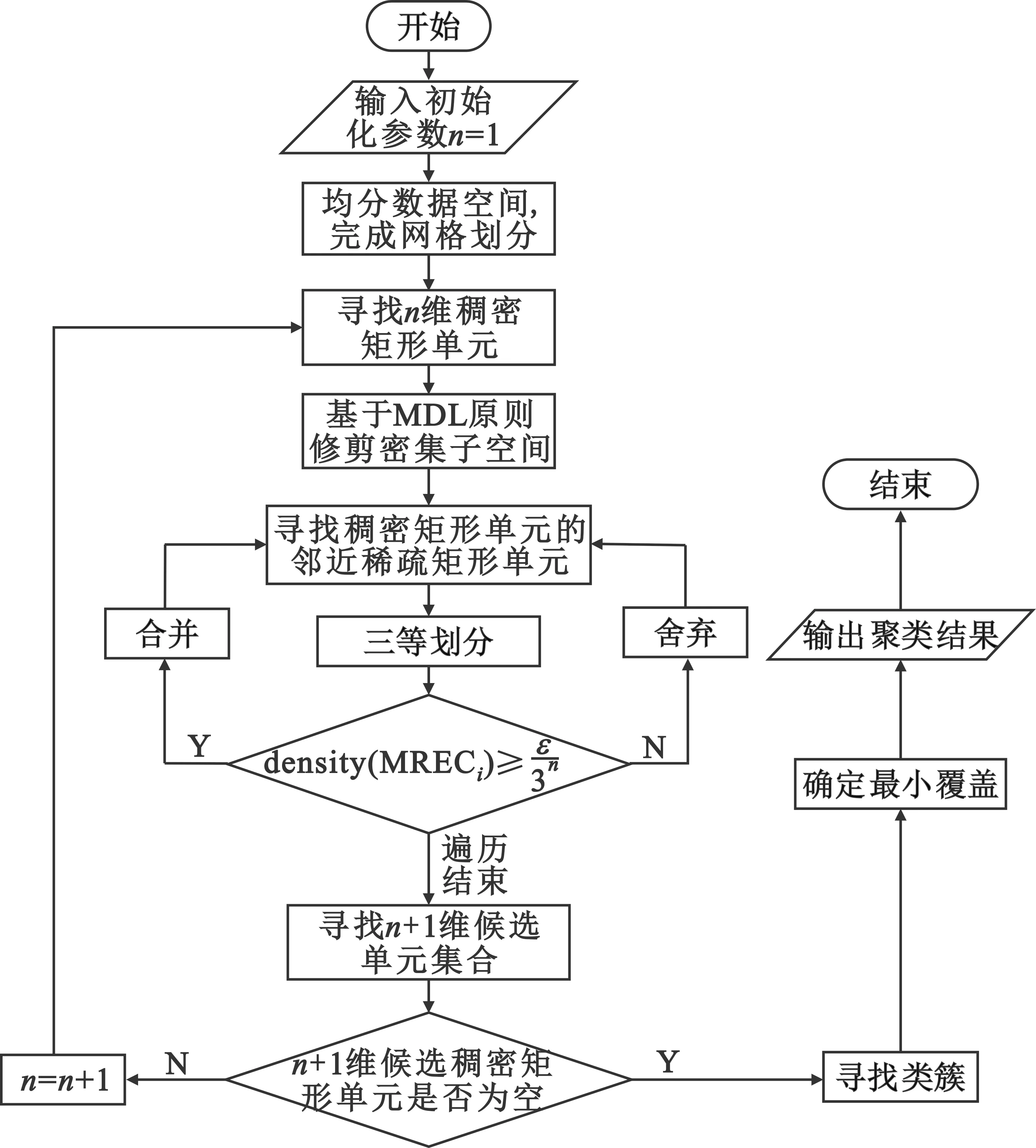
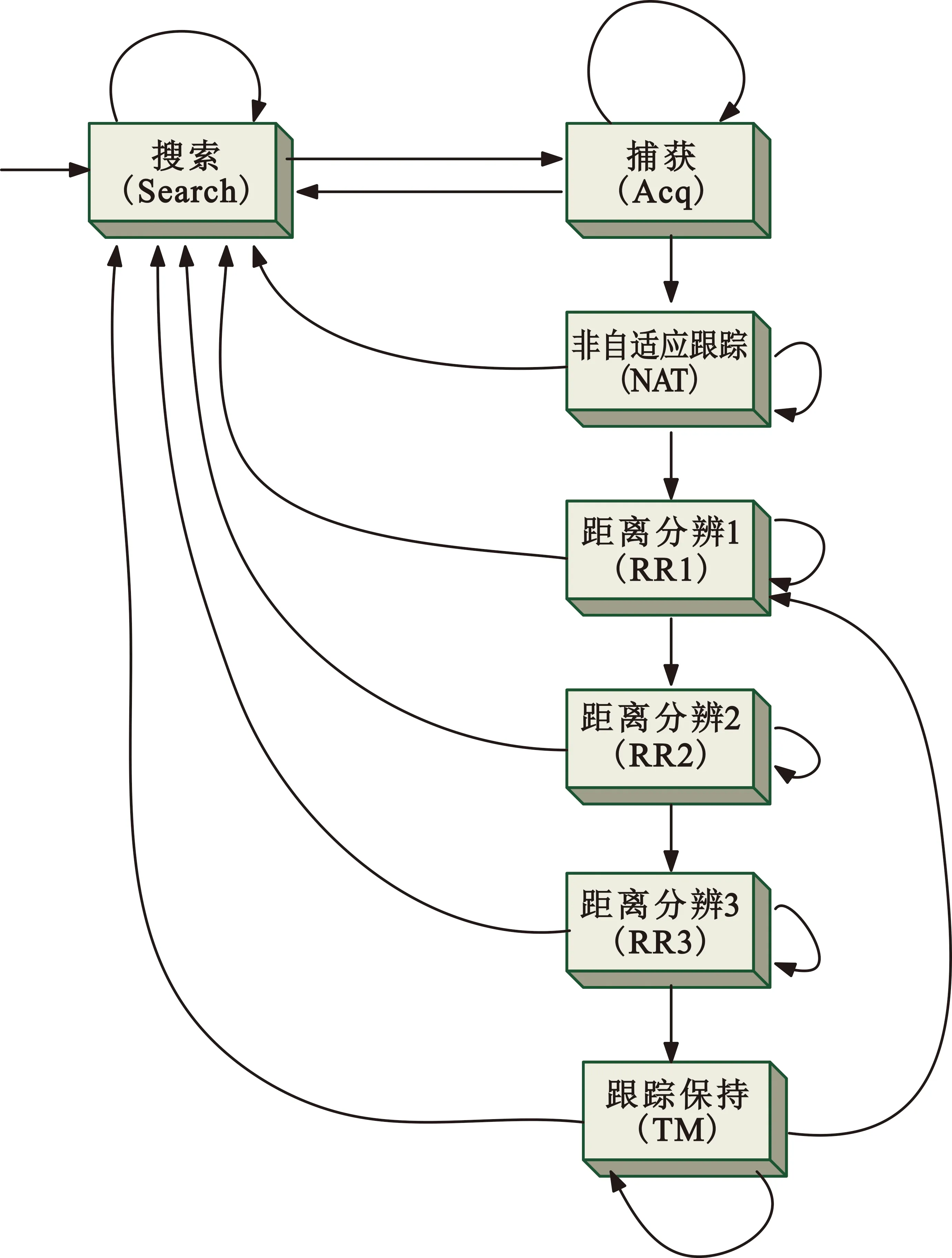
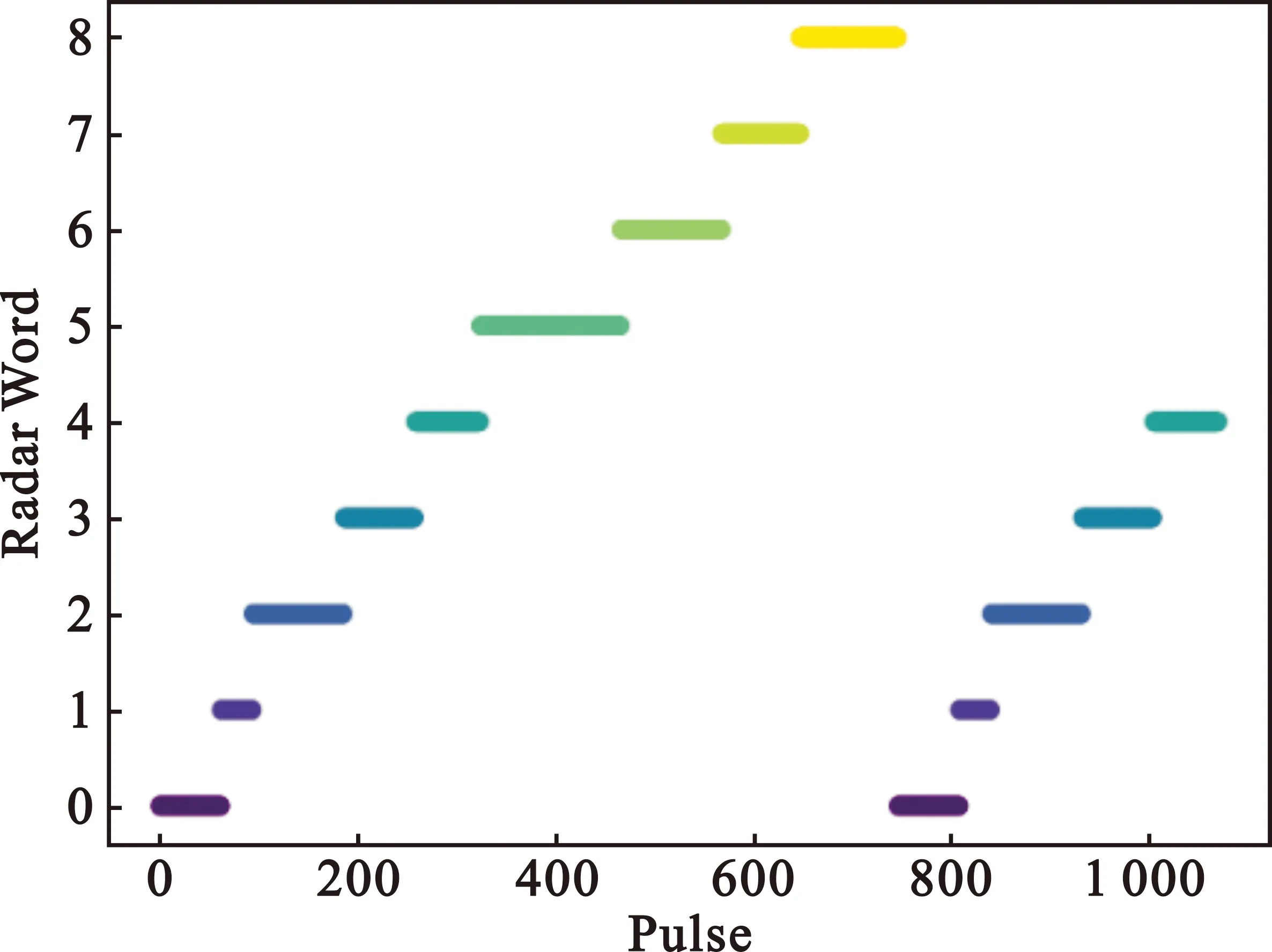
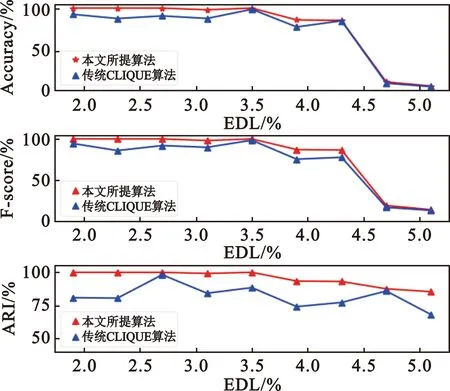
设存在n个有界子空间P,则原始数据集可以表示为原始数据集T={P1,P2,P3,…,Pn},由这n个子空间形成的n维空间记为S,则S=P1×P2×…×Pn,那么P1,P2,P3,…,Pn相当于S的每个维度或者属性。首先把整个数据空间的每一维均分为P等份,因此可以得到Pn个互不重叠的矩形单元,即RECk={u1,u2,u3,…,un},其中1≤k≤Pn,ui=(li,hi]表示一个左开右闭的空间。样本点表示为xj={xj1,xj2,xj3,…,xjn},当且仅当∀i∈n,均有li 原理1:若存在一个k维的稠密矩形单元,则该单元在下降一个维度的子空间上的映射也必然是稠密的。 原理2:针对k维的候选稠密矩形单元,如果其在下降一个维度的子空间上的映射都是稀疏的,则该单元也是稀疏的。 由于传统CLIQUE算法使用的是固定网格参数和固定密度参数,所以很可能会出现参数设置不当导致边界聚类丢失或者成锯齿形状聚类的现象,使得聚类精度不高。针对该问题本文采用一种改进的基于密度调整的边界扩展方法,具体做法如下: Step1 随机选取矩形单元RECx,寻找其近邻的稀疏矩形单元,若不存在则重返Step 1;若存在则标记为RECxi(1≤i≤4),并跳转至Step 2。 Step2 对所有的近邻稀疏矩形单元进行三等划分,可以得到3n个小的微矩形单元,记为MREC。 Step3 对落入微矩形单元的样本点数量进行求和,计算微矩形单元的样本密度,记为density(MRECi),其中1≤i≤3n。 (1) 式中:count(MRECi)表示MRECi落入微矩形单元的样本点总数,N表示整个样本空间的总点数。 Step4 比较density(MRECi)和ε/3n的大小,若density(MRECi)≥ε/3n,则把MRECi合并到RECx矩形单元,重复Step 1~4,直到遍历完所有稠密单元的近邻稀疏单元。图5给出了针对二维矩形单元中的粗边界稀疏矩形单元三等划分后的边界合并过程,可以明显地看出,改进算法可以有效地对簇边界进行扩展,避免由剪枝和算法本身的局限性造成的边缘损失。 图5 边界扩展过程 考虑到之前的提取算法对侦收信号的信息利用不充分的因素,加上脉冲间RF、PRI、PW的调制模式反映了脉冲信号的变化规律,是分析判断雷达行为的重要依据,因此本文将利用PRI、PW和CF三个参数的时空信息,采取子空间聚类的方法进行雷达字的提取。 输入数据集T={PRI、RF、PW},算法采取自下而上的方法,首先逐个属性对侦收到的脉冲列信号进行处理,完成网格划分;之后根据初始化的参数遍历所有网格,寻找大于密度阈值的稠密矩形单元,并记录好每个稠密单元的样本点总数;接着根据最小描述长度原则(Minimum Description Length MDL)进行修剪,除去大概率不会成为稠密矩形单元的子空间单元格;下一步是改进算法的核心,首先找到稠密矩形单元的邻近稀疏矩形单元,然后进行三等划分,根据新的密度阈值判断是否要合并到稠密矩形单元还是选择丢弃;接着由n维稠密单元寻找n+1维候选单元集合,若候选稠密单元不为空,则让n=n+1,重新寻找n维矩形单元,反之则通过贪心算法确定最小覆盖,输出聚类结果。具体的算法流程如图6所示。 图6 雷达字提取算法流程图 改进算法主要针对原始算法簇边缘丢失的问题进行改进,需要额外扫描所有包含数据点的矩形单元,所以相对原算法会增加这一过程的计算复杂度,增加的计算开销为O(p×q×k),其中p代表稀疏单元中样本点的总数,q表示含有样本点的矩形单元个数,k是维度。由于远小于传统算法的复杂度O(ck),所以对算法整体复杂度影响并不大。 本算法有三个雷达字提取性能指标,分别是F-值(F-score),准确率以及调整兰德系数(Adjusted Rand index,ARI)。F-值和准确率(Accuracy)比较常用,这里不做过多介绍。调整兰德系数假设模型的超分布为随机模型,即X和Y的划分为随机的,那么各类别和各簇的数据点数目是固定的。要计算该值,先计算出列联表(Contingency Table,CT ),如图7所示,表中每个值nij表示某个document同时位于cluster(Y)和class(X)的个数,再通过该表计算ARI值即可。 图7 列联表 (2) ARI∈[-1,1]。ARI的数值越靠近1表明聚类效果越好,与实际的簇越吻合;反之,ARI的数值越靠近-1代表结果越差。 由于MPAR雷达字集涉及到各国的核心机密,所以暂时没有相关的数据集。本文根据文献介绍,合理地构建了“水星”多功能雷达的雷达字集,包括9个雷达字,分别为w1w2w3…w9。“水星”多功能雷达存在7种可以互相转换的功能状态,分别是搜索、捕获、非自适应跟踪、三个距离分辨率阶段和跟踪维护,这些功能状态之间的转换可以由图8所示的状态机捕获。 图8 各模式转换关系 如果雷达在搜索中,它可以保持在这个功能状态(如图8中搜索状态的自循环所示);倘若检测到目标,那么它可以移动到捕获状态;目标捕获周期包括从捕获状态到非自适应跟踪状态,再到距离分辨率状态,最后到跟踪保持。雷达可以在这些状态中的任何一种状态下保持一段不确定的时间。最后,目标捕获或跟踪可以在任何点放弃,雷达可以移回搜索。 在每个功能状态下,雷达都会发出一个由4个雷达字组成的短语,这些短语在雷达语言中形成了字符串。本文算法的关键就是通过原始脉冲列准确提取雷达字,为后续进行工作模式识别和后续的行为分析、威胁判断等工作提供依据。 实验1:设置漏脉冲率为30%,利用Python模拟生成“水星”多功能相控阵雷达的原始脉冲序列,将雷达字的发射序列设置为以下形式:w1w2w3w4w5w6w7w8w9w1w2w3w4w5。通过本文所提出的子空间聚类算法进行雷达字提取的仿真实验,得到图9所示的提取结果。 图9 雷达字提取效果图 由图9的实验结果可以发现,在漏脉冲率设置为30%的前提下,本文所提算法能完全正确地提取出雷达字,与实际发射的雷达字序列保持一致,验证了算法的可行性。由于MPAR发射雷达信号都是依据其功能状态来的,所以在实际作战背景下,并不会按照上述实验简单地按照1~9的顺序发射雷达信号,针对这个问题进行实验2的仿真模拟。 实验2:为了模拟实战背景,设置想定为“水星”多功能雷达正经历如下的工作模式转换:四字搜索→四字搜索→三字搜索→捕获→非自适应跟踪→距离分辨(RR1)→距离分辨(RR2)→三字跟踪保持→三字跟踪保持,生成对应的雷达字脉冲序列数据集。另一方面,在脉冲丢失率恒为30%的情况下,针对性地增加测量误差,使得同一类别原本在同一密集矩形单元的样本点可能会散布在邻近的稀疏单元格,进一步检验改进算法的合理性。实验中分别计算不同测量误差偏移水平(Error Deviation Level,EDL)对雷达字提取的准确率、F-值以及调整兰德系数三个指标的变化来度量本文所提算法的性能。每组进行10次蒙特卡洛仿真得到的结果如图10所示。 图10 聚类评价指标 一方面,针对实验2,通过增加测量误差使得更易出现“边缘丢失现象”,而图10所示的仿真结果中改进算法提取准确率明显高于传统算法。这主要是得益于改进算法在簇边缘的合并操作,证明了改进理论的正确性。另一方面,随着测量误差进一步增大,算法提取效果逐渐下降。这是由于测量误差上下的波动太大和漏脉冲率过高导致密集单元邻近的稀疏单元点散步更广,无法进行合并,但改进算法的整体性能仍优于传统算法,尤其是调整兰德系数提升效果显著说明聚类的结果和原始结果匹配程度更接近。 本文利用子空间聚类的方法能有效地从侦收的脉冲序列中提取雷达字符号,且相较传统算法有明显的优化。雷达字提取是雷达行为分析的第一步,后续的工作主要是根据MPAR特有的“文法”,利用提取成功的雷达字符号进行雷达行为识别[14]和行为预测。 需要强调的是,本文设置的场景中所发射的雷达信号比较均匀,在样本不均匀的情况下进行雷达字提取实验效果并不理想,下一步还需要在该方面进行改进。与此同时,网格划分参数和密度阈值的调整具有一定的盲目性,后续的改进应该从参数寻优和自适应参数调整等方面考虑。3.3 基于密度调整的边界扩展
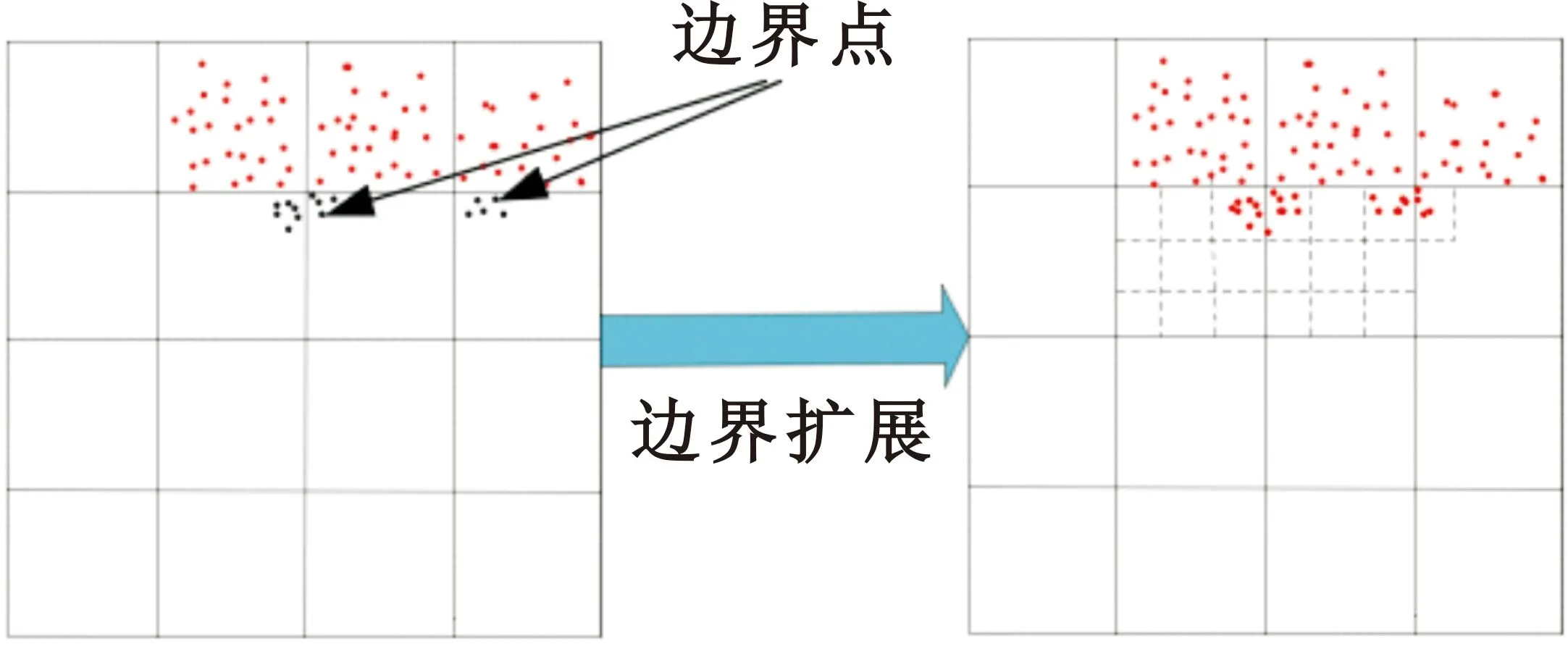
3.4 算法流程
3.5 雷达字提取的评价指标

4 仿真分析
5 结束语
猜你喜欢
有色设备(2021年4期)2021-03-16
中学生数理化·八年级数学人教版(2020年4期)2020-10-29
软件导刊(2018年11期)2018-11-19
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
制导与引信(2017年3期)2017-11-02
中学生数理化·八年级数学人教版(2017年4期)2017-07-08
北京航空航天大学学报(2017年10期)2017-04-20
福建中学数学(2016年4期)2016-10-19
互联网天地(2016年1期)2016-05-04
