
多尺度密集连接注意力的红外与可见光图像融合
2022-10-27 04:53:52张娇娇
光学精密工程 2022年18期
陈 永,张娇娇,王 镇
(兰州交通大学 电子与信息工程学院,甘肃 兰州 730070)
1 引 言
红外辐射是一种与可见光频谱相邻的不可见光,其在云雾中具有很强的穿透力,受不良天气干扰较小,红外视觉在安防和军事等各个领域有突出优势。但红外图像相比于可见光图像存在细节缺失、边缘结构模糊、分辨率不高等缺点。可见光图像虽纹理细节信息丰富,但在弱光条件下成像后存在有效目标模糊、难以被识别的问题。因此,利用红外与可见光图像的互补信息,将两者融合,其纹理细节和目标信息都尽可能被保留,具有更优的可视效果,能够提高目标的检测及识别率,非常有利于目标指示和场景信息的获取[1]。通过红外与可见光图像的融合可以扩展系统的时空覆盖率,增强系统的可靠性和鲁棒性,其可广泛应用于交通安全监控[2]、军事侦察[3]、医学成像[4]、遥感[5]等多种应用场景。
目前,红外与可见光图像融合方法分为传统方法和基于深度学习的融合方法。传统融合方法根据理论依据不同,可分为变换融合[6]、稀疏表示[7]、拉普拉斯金字塔融合[8]等方法。其中变换融合方法因其算法简单,性能较好被广泛应用,该类方法包括双树复小波变换(Dual-Tree Complex Wavelet Transform,DTCWT)[9]、非下采样轮廓波变换(NonSubsampled Contourlet Transform,NSCT)[10]等。然而上述传统方法在融合阶段,需要根据具体问题手工设计融合规则,导致其泛化性能较差。
随着深度学习的快速发展,图像融合领域也提出了很多基于深度学习的方法[11-14]。文献[15]提出了一种基于卷积神经网络融合方法,但该方法网络层数较少,难以提取有效特征信息,以致融合结果存在信息缺失问题。文献[16]提出一种基于生成对抗网络的融合方法(Generative Adversarial Network for infrared and visible image Fusion,FusionGAN),该方法通过生成器与判别器的博弈来完成融合,但其判别器在对抗训练时仅以可见光图像为参照,忽略了红外图像对于融合的互补作用,导致融合后的图像局部信息不明显。文献[17]提出了一种深度无监督的图像融合方法(Deep unsupervised approach for Fusion,DeepFuse),该方法通过色彩空间转换后进行双分支特征提取进行融合,但该方法在融合时采用相同权重,这一操作导致无法获取到图像的差异化信息,最终的融合图像出现细节纹理模糊的问题。文献[18]提出了一种基于残差网络(Residual Network,ResNet)的图像融合方法,该方法可利用网络结构提取红外与可见光图像特征,但在融合重构时采用加权平均的策略,融合后图像容易丢失重要信息。文献[19]提出了基于密集连接网络的融合方法——Densefuse,该方法将源图像输入编码网络构造特征映射,再利用解码网络重构出最终融合图像,但该方法在编码网络中只使用单尺度的卷积核提取图像特征,导致融合后的图像目标边缘易出现模糊现象。
综上所述,现有融合方法大都采用单一尺度卷积核提取图像特征,未考虑红外与可见光图像中具有多样复杂的特征信息,导致融合结果存在特征提取不充分、细节信息重构缺失等问题。针对上述问题,提出了一种多尺度密集连接注意力的红外与可见光图像融合方法。主要工作有:(1)设计多尺度卷积神经网络编码子网络提取红外与可见光图像中不同感受野大小的特征信息,克服了单一尺度特征提取不足的问题;(2)在编码子网络末端引入通道与改进的可变形卷积空间注意力机制用于捕捉全局信息的依赖关系,以促进网络有效地对红外与可见光图像中的重要特征信息进行聚焦;(3)将编码子网络提取到的红外与可见光特征信息输入融合层,使用基于L1范数的融合策略进行融合;(4)构建解码子网络对融合后的特征进行重构,得到最终融合后图像。对红外与可见光的融合实验结果表明,所提方法较对比方法在主、客观角度均取得较好的融合效果。
2 方 法
2.1 网络总体框架
可见光RGB图像一般包含丰富的细节信息,红外图像含有突出的目标信息,为了提高可见光与红外图像特征提取能力,提升融合性能,提出了一种多尺度密集连接注意力的红外与可见光图像融合深度学习模型,网络总体框架如图1所示,主要由红外与可见光特征编码子网络、融合子网络和解码子网络三部分构成。
模型工作时,首先,在网络模型中编码子网络通过多尺度特征提取层获得多通道图像特征信息;其次,将得到的特征输入密集连接模块从而尽可能地保留红外与可见光图像的特征信息;然后,利用在编码子网络末端引入改进的可变形卷积注意力机制(Deformable-Convolutional Block Attention Module,D-CBAM),从通道和空间两个方面对红外与可见光图像的显著信息聚焦,并抑制无用信息,以确保在融合层所有的显著特征都可以被利用;接着,融合层使用基于L1范数的融合策略[19]对编码子网络提取的特征进行融合;最后,解码子网络由全卷积构成,在解码子网络中将提取的特征信息进行重构,输出红外与可见光图像的融合结果。

图1 网络总体框架图Fig.1 Overall network framework
2.2 多尺度红外与可见光特征提取编码子网络
本文编码子网络由多尺度层、密集连接块和注意力机制模块三部分构成。所提方法设计了多种尺度的卷积核提取不同感受野的特征信息,红外光与可见光图像都具有复杂的纹理信息,密集连接网络可以提取到图像的目标深层特征,使得最终的融合图像具有更好精度。注意力机制则可以促进全局的依赖关系,使网络提取到更丰富全面的红外与可见光图像特征信息。
2.2.1 多尺度特征提取层
红外图像和可见光图像的融合实质是将红外图像中的信息根据一定的规则融合可见光图像。融合时除了考虑图像的亮度信息还需要考虑当前像素所在的连通区域特征,若能充分考虑包含当前像素的多尺度区域特征,将会提取到关于目标对象更准确的图像特征。在基于深度学习的方法中通常使用卷积层提取图像特征,但如果单纯使用一种尺度卷积核提取特征,导致图像在其他感受野的特征表现将无法被感知。为了充分获得输入红外与可见光图像在不同尺度下的特征,首先分别使用5×5、3×3和1×1三种不同尺度大小的卷积核对输入红外与可见光图像不同维度的特征信息进行提取,其结构如图2所示。多尺度卷积操作能够克服单尺度卷积操作感受野单一、特征范围受限的问题。
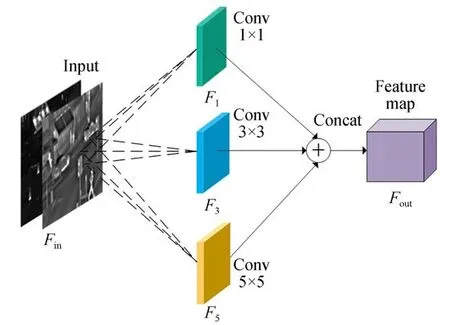
图2 多尺度特征提取图Fig.2 Multi-scale feature extraction diagram
图2中,多尺度特征提取时,利用式(1)和式(2)计算如下:
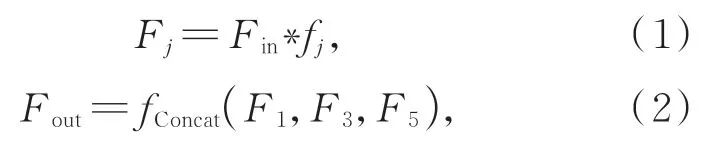
其中:Fin为输入特征图;*代表卷积操作;卷积核大小为fj,j=1,3,5;Fout为输出的特征图。
2.2.2 密集连接特征提取模块
为了进一步提高网络提取图像特征信息的准确性,在多尺度卷积层之后再采用密集连接网络提取图像的深层特征信息。密集连接网络将每层卷积提取的特征输出至后续所有的卷积层,这种方式可以让每个卷积层都能感知到前驱卷积层的计算结果。密集连接将网络的宽度控制在一个较窄的水平上,很好地解决了过拟合等问题[20]。为了能够充分利用图像各层卷积的特征输出,本文在多尺度卷积层后连接了一个密集连接网络模块,该模块是由3个密集连接的卷积层组成,密集连接模块中的卷积算子的尺度都是3×3,其结构如图3所示。
从图3可以看出,密集连接块的输出是之前每一层的拼接,输出图像的通道数不发生改变,每一层的输出如式(3)所示。

其中:xt表示第t层的输出,xt-1为前一层,Ht代表非线性转化函数(Non-liear Transformation),可表示一个组合函数操作,密集连接块中采用的是BN+ReLU+Conv(3×3)的结构。
2.2.3 可变形卷积注意力机制
在编码网络模型中,通过不同尺度的卷积核以及密集连接块提取可见光与红外图像更丰富、更深层次的图像特征,克服了单尺度图像融合特征提取不足的问题。但普通卷积操作仅为局部信息感知,无法获得全局关联信息,而注意力机制能够捕获全局的依赖关系[21]。
本文在红外与可见光图像融合网络结构中采用提出的可变形卷积注意力机制D-CBAM,以便更加有效地对红外与可见光图像中的重要特征信息进行聚焦。相比于SE注意力方法(Squeeze-and-Excitation,SE)仅关注通道之间的关系,忽略了红外与可见光融合对象轮廓特征信息的关注。而CBAM[22]注意力机制能够同时在通道和空间维度上进行注意力特征提取,其通过在内部运用全局最大池化和全局平均池化的并行方式来减小池化操作带来的损失,从中将可见光与红外轮廓及纹理细节特征信息得以增强。并且CBAM模块是一个轻量级模块,集成到网络中产生的额外开销可忽略不计,其结构如图4所示。CBAM主要由通道注意力单元(Channel Attention Module,CAM)和空间注意力单元(Spatial Attention Module,SAM)构成,两个模块分别独立作用于通道与空间,可节约参数并且避免了繁琐的计算。
本文在CBAM空间注意力模块中将最大池化和平均池化通道拼接后的7×7标准卷积改进为一个3×3的可变形卷积。这是因为普通卷积的感受野根据卷积核的大小是固定的矩形,但在实际应用过程中,各种图像物体的特征形状大小各不相同。而可变形卷积通过增加偏移变量可以对感受野大小进行自适应调节,结构如图5所示。
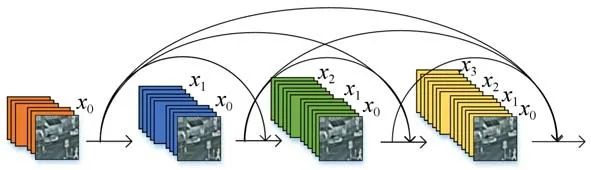
图3 密集连接模块Fig.3 Dense connected module
图5中,特征图通过3×3的可变形卷积层操作,能够输出带有偏移量参数的特征图。可变形卷积是在普通卷积的采样点位置都加了一个可学习的偏移量{Δan|n=1,…,N},如式(4)和式(5)所示。

其中:x为输入的特征图;y为输出的特征图;w是 权 重 值;R表 示 采 样 区 域,R={(-1,-1),(-1,0),…,(0,1),(1,1)};a0表示特征图y中的点;an表示R内的所有采样点;因为Δan可能是小数,所以一般使用双线性插值计算x(a0+an+Δan)的值。
在红外与可见光图像融合时,利用可变形卷积能更高效地关注特征区域,相较与普通卷积其采样点更加贴近物体的真实形状及位置,如图6所示。
在可变形卷积注意力机制中,通道注意力可以增强可见光与红外图像中的重要通道特征,并削弱无关特征,其示意图如图7所示。在此模块中输入特征图F(H×W×C),H为特征图的高,W为特征图的宽,C为特征图的通道数,然后,经过全局最大池化和平均池化及多层感知器(Multi-Layer Perception,MLP)单元后,得到两个特征向量,最后经过元素加操作和Sigmoid激活后得到通道注意力权重值。

图4 注意力机制模块图Fig.4 Convolutional block attention module

图5 可变形卷积Fig.5 Deformable Convolution

图6 标准卷积和可变形卷积对比Fig.6 Comparison of standard convolution and deformable convolution
红外与可见光融合时,通道注意力通过式(6)计算得到:
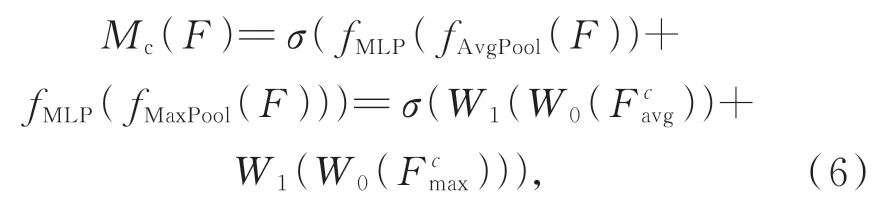
在得到通道注意力权重Mc(F)后,在输入空间注意力模块之前,再将其与输入图像特征做基于元素的乘法操作,计算过程如式(7):
其中:σ是Sigmoid函数,F是输入的特征图,F′是通道注意力模块得到的特征。
接着将通道注意力特征信息输入空间注意力模块中,通过最大池化和平均池化进行通道拼接,其结构如图8所示。
在图8特征图通道拼接后,再经过3×3的可变形卷积操作,接着通过Sigmoid激活函数,如式(8)所示:
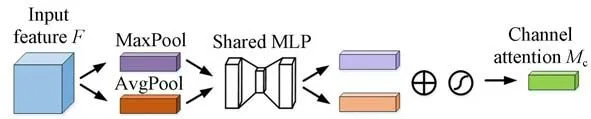
图7 通道注意力模块图Fig.7 Channel attention module
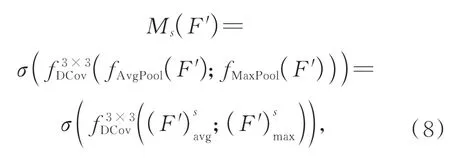
其中,f3×3DCov表示可变形卷积操作。将得到的空间特征图与输入的特征信息做元素乘积操作,输出D-CBAM注意力机制增强后的特征图,如式(9)所示:
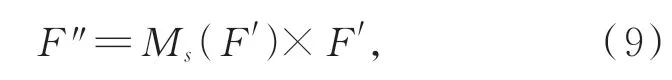
其中:F″是运行空间注意力模块得到的特征。
2.3 融合策略
红外与可见光图像的目标信息具有突出的互补性,在融合时为了提高特征图融合的有效性,采用L1范数[19]的融合策略,如图9所示。该策略是通过计算活动图完成融合工作。由编码子网络输出的特征图用φmi表示,通过L1范数得到特征图φmi的初始活动水平图Ci,最终活动水平i由基于窗口的平均算子获得;再将i经过Soft-max函数运算,得到融合后的特征图fm。
基于L1范数的融合策略详细步骤如下:
(1)采用L1范数得到初始活动水平图Ci:
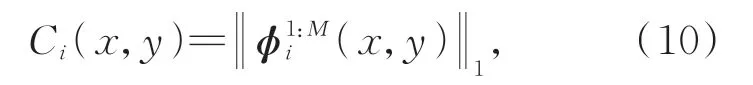
其中,φ1:Mi(x,y)是一个M维的向量,(x,y)代表位置坐标。
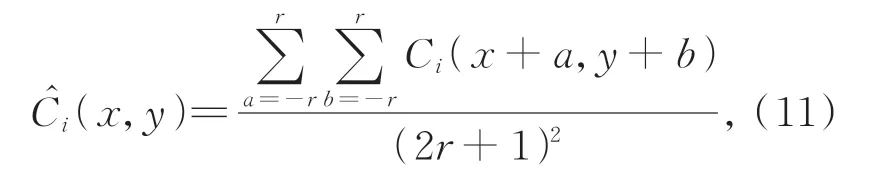
其中:a为窗口横坐标取值,b为窗口纵坐标取值,r代表窗口大小。
(3)通过Softmax函数得到初始权重图wi,并得出最终的特征图fm。
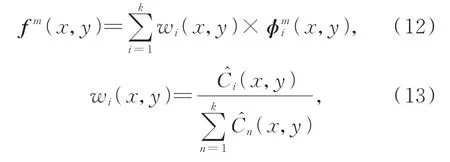
其中,fm为融合后的待解码特征图。
2.4 解码子网络
解码子网络的输入为融合层的输出特征图,实现对融合后图像的重构。通过解码子网络,使得网络得到的融合图像保留更多的目标细节信息。为了获得更加精细的解码效果,解码子网络采用全卷积结构构成,如图10所示,使用4个3×3卷积核和ReLU激活函数进行解码重构操作,最终输出重构后的红外与可见光融合图像。
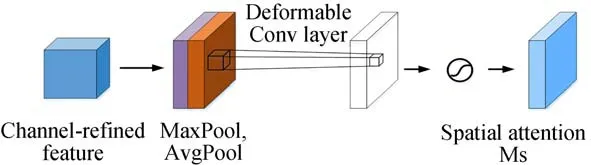
图8 空间注意力模块图Fig.8 Spatial Attention Module
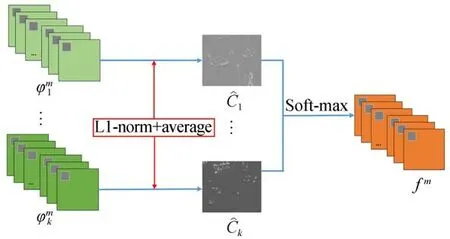
图9 基于L1范数的融合策略Fig.9 Fusion strategy based on L1 norm
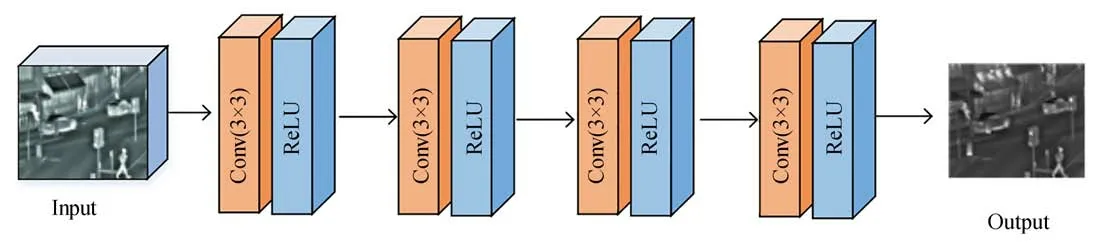
图10 解码子网络结构Fig.10 Encoder subnet structure
2.5 损失函数
设计损失函数时,为了使网络可以更精确地提取并重构图像特征,在训练过程中加入最小化损失函数来训练网络模型。损失函数(Lloss)由加权λ结构相似性度量误差(Lssim)和像素误差(Lpixel)组成,由式(14)可得:
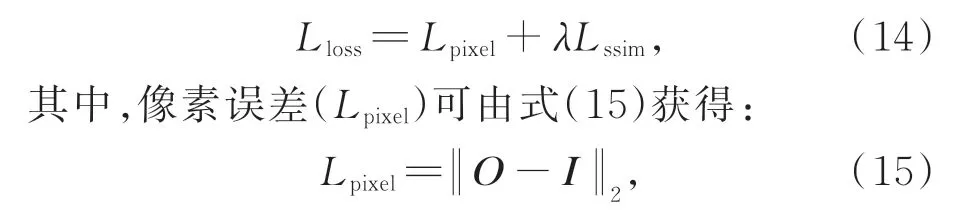
其中:I表示图像融合训练网络的输入图像,O表示网络输出图像。相似度损失(Lssim)可由式(16)得到:
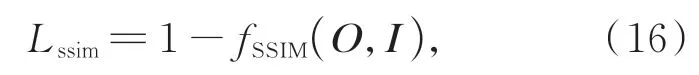
其中,fSSIM(·)函数代表结构相似度操作,即fSSIM(O,I)代表输入与输出图像的结构相似度。
3 实验结果与分析
3.1 实验设置和环境
为了验证所提方法的有效性,与8种代表性的融合方法进行比较,包括双树复小波变换(DTCWT)[9]、非下采样轮廓波变换(NSCT)[10]、基于双分支多聚焦特征融合的深度卷积神经网络(CNN)[15]、生成对抗网络(FusionGAN)[16]、密集连接网络(DenseFuse)[19]、卷积稀疏表示(Convolutional Sparse Representation,CSR)[23]、多 尺度分解(Novel Decomposition Method for Infrared and Visible Image Fusion,MDLatLRR)[24]、潜在低秩表示(Infrared and Visible Image Fusion using Latent Low-Rank Representation,LatLRR)[25],并通过主客观评价指标进行评价分析。软件环境为Windows10、python3.6及pytorch。硬件配置环境为Intel(R)Core i7-9700K CPU@3.6 GHz,64.0 GB RAM,NVIDIA Ge-Force GTX 1660,对比实验的软硬件环境相同。实验测试阶段选取了TNO数据集中的红外与可见光图像。训练阶段使用MS-COCO数据集,其目的是训练网络模型的重构能力。
3.2 融合图像主观评价
选取TNO数据集中“street”组进行实验分析,实验结果如图11所示。可以看出,CNN算法和CSR算法实验结果中背景被过度虚化且含有噪声伪影的现象。FusionGAN算法、MDLatLRR算法实验融合结果虽然有所改善,但右上角行人部分依然是虚化的。NSCT算法、DenseFuse算 法、LatLRR算 法 和DTCWT算 法实验结果中目标和整体场景的层次对比度较弱且缺少红外与可见光图像更多的边缘和细节信息。本文提出的算法实验结果中右上方行人汽车的纹理结构特征丰富明显,较好地保留了边缘及细节信息。
为了进一步验证图像融合实验的优越性,从TNO数据集中继续选取五组不同的图像作为对比实验。实验结果如图12所示,可以看出,CSR算法和NSCT算法的融合图像结果不理想并且噪声现象非常严重。CNN算法相对于CSR算法和NSCT算法的融合结果噪声现象得以改善,但是依然存在严重的伪影。DTCWT、LatLRR和
MDLatLRR算法很大程度上解决了上述算法存在的问题,图像的轮廓信息比较清晰,但是一些重要信息仍得不到体现,如图中红框所示,DTCWT算法融合结果第四组图像中,房子上方的树枝纹理模糊。LatLRR算法融合结果第五组图像中,窗户边缘不清晰。MDLatLRR算法融合结果第三组图像中,融合效果不佳导致人像周围的信息缺失。FusionGAN和DenseFuse算法是基于深度学习的融合方法,其融合结果既保留了可见光的有用信息又存在红外图像的目标特征信息。但结果中目标特征信息边缘较为模糊,如在DenseFuse算法融合结果的第三组图像中,右下角的草丛与地面的轮廓不清晰,对比度不明显。本文所提方法融合结果目标信息更加清晰且保留了更丰富的纹理细节信息,并且在亮度上也得到一定的提升。


图12 不同算法对TNO数据集红外与可见图像融合结果比较Fig.12 Results of infrared and visible image fusion based on TNO dataset with different algorithms
主观评价是凭个人的感觉进行主观判断,具有一定的随机性与片面性。因此需要结合客观评价对融合图像的质量进行综合分析对比。
3.3 融合图像客观评价
为了更好地分析融合图像的质量,选取结构相似度(SSIM)、空间频率(SF)、信息熵(EN)、视觉信息保真度(VIFF)、差异相关系数(SCD)和边缘信息保持度(QAB/F)六种有代表性的公认的客观评价指标对融合图像质量进行对比实验分析。
首先对“street”这一组实验进行定量分析,结果如表1所示,其中黑体为最优值。根据表1的客观评价数据可以发现,本文方法在“street”这一组实验对比中,大部分评价指标较其他对比算法是最优的。尤其较DenseFuse算法,SF指标提高了约77.22%,说明图像中边缘与纹理信息更加丰富清晰;其次SSIM指标提高了约42.61%,说明图像中的显著信息表现更佳。同时在EN、SCD和VIFF指标都有不同程度的提高。在本对比实验客观评价的数据结果显示与主观评价是相符的。
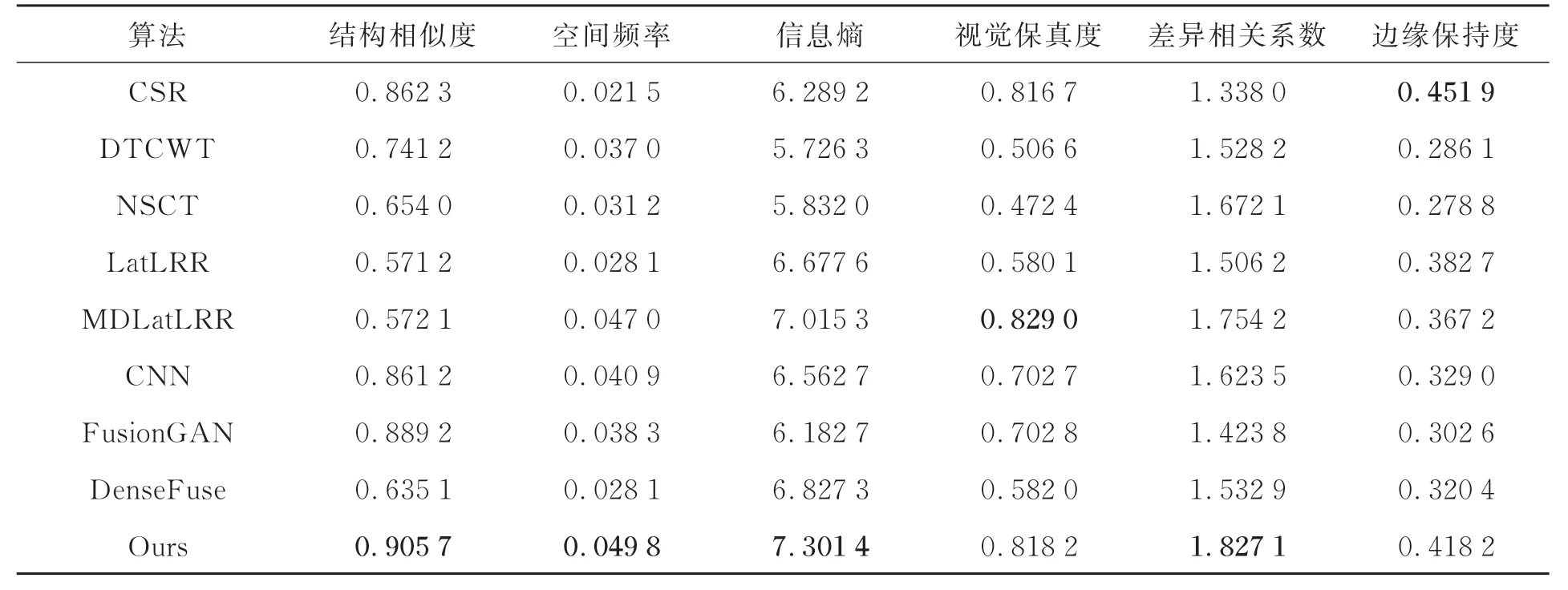
表1 “street”组客观评价Tab.1 Objective evaluation of“street”
进一步从TNO数据集中选取6组不同场景的红外与可见光图像进行融合量化分析对比,将得出的指标得分以折线图的形式进行可视化,图13为不同算法的客观评价指标折线图。从各项指标之间的对比可知,本文方法在提高融合图像质量的同时具有较好的视觉信息保真度,与主观评价一致。
扩大客观评价实验,从TNO数据集中共选取10组融合结果进行对比实验,结果如表2所示。


图13 不同算法的6种客观指标对比Fig.13 Comparison of six objective metrics for different algorithms
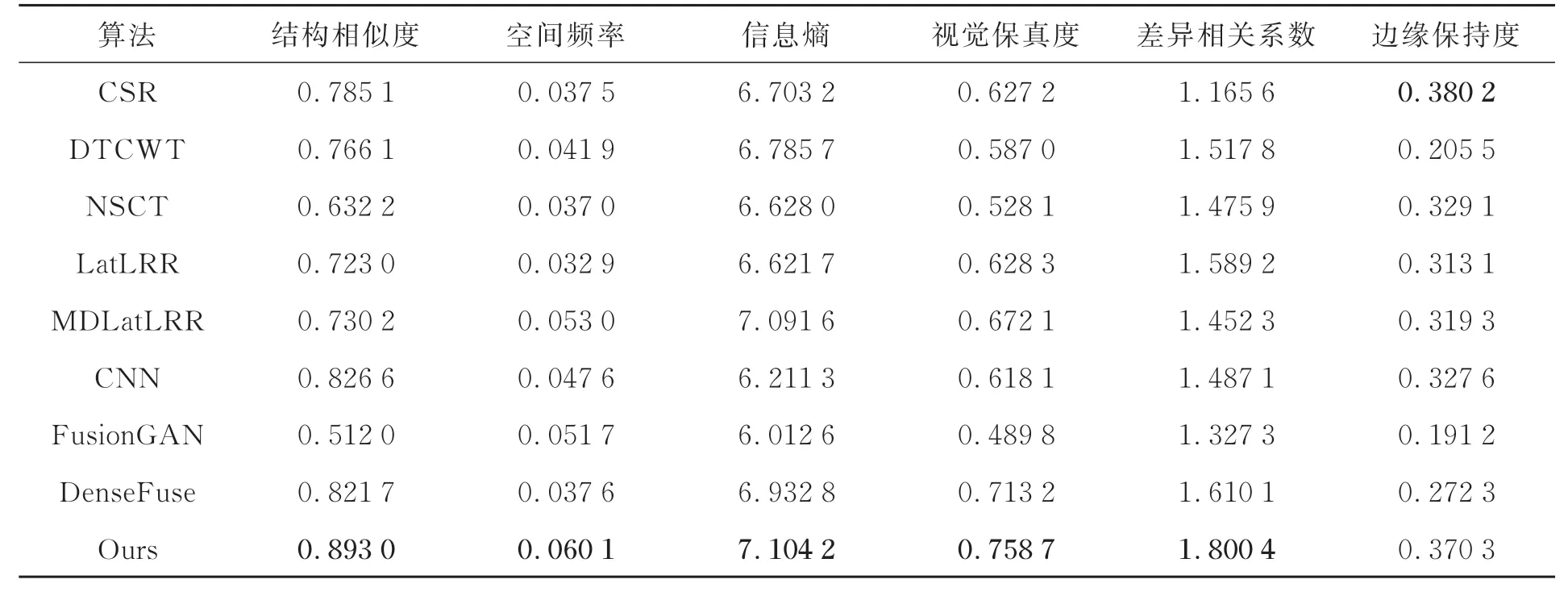
表2 10组融合结果平均定量值Tab.2 Average quantitative value of the fusion results of 10 groups
可以看出本文提出的方法在10组不同场景下得到的6种评价指标平均定量值,有5种评价指标结果都是最优的,其中SSIM、SF指标分别平均提高了0.26倍、0.45倍。此外,从表2可以看出,所提方法仅在边缘保持度(QAB/F)评价指标略低于CSR算法,这是因为CSR算法将源图像作为整体进行稀疏编码,有效保留了图像的全局边缘特征信息,但该算法在字典构造时,存在字典单一且不具备自适应性的问题,当噪声逐渐加大时,使用该算法融合后会产生模糊、清晰度差的问题。综合上述客观比较,所提方法融合结果自然清晰,层次感更好。
3.4 消融实验
为了验证本文方法中提出的各模块的功能及有效性,进行消融实验:(1)仅以密集连接(Densely Connection,DC)进行图像融合实验;(2)以多尺度的密集连接(Multiscale-Densely Connection,M-DC)进行图像融合实验;(3)以多尺度密集连接及注意力机制(Multiscale-Densely Connection+Convolutional Block Attention Module,M-DC+CBAM)进行图像融合实验;(4)以多尺度密集连接及改进的可变形卷积注意力机制(M-DC+D-CBAM)进行图像融合实验。在TNO数据集中随机选择一组图像“Kaptein”的融合结果作为主观对比,继续选取10组图像的融合结果进行消融实验的客观评价指标对比。图14为消融实验结果,通过观察发现,多尺度密集连接在亮度上有一定的提升,可以体现出更多的图像特征信息,但是图像对比度略显不足。多尺度密集连接及注意力机制的融合结果改善了上述缺点,行人后面的帐篷轮廓更加清晰,但红框内的草丛纹理细节依旧模糊。本文提出的多尺度密集连接及改进的可变形卷积注意力机制融合结果可以很好地保留红外与可见光图像中的特征信息,纹理信息丰富。融合效果良好。消融实验的客观指标选取了表示融合算法效果的结构相似性指标(SSIM)和反映图像细节和纹理信息的平均梯度(AG)指标。表3为消融实验的客观评价指标数据。

图14 消融实验结果Fig.14 Results of ablation experiments

表3 消融实验客观指标Tab.3 Objective indicators of ablation experiment
从表3可以发现,加入各模块会使本文所提方法融合性能有不同程度的提高,第四组消融实验结构相似性指标可高达96.37%,平均梯度也明显上升,证明本文提出的多尺度密集连接及改进的可变形卷积注意力方法的有效性。
3.5 计算复杂度及运行效率分析
最后,对模型计算复杂度和运行效率进行比较分析。在深度学习神经网络模型中,一般通过计算量,即模型的运算次数来衡量算法计算复杂度,并根据融合十组红外与可见光图像所需的平均时间衡量算法的运行效率。将本文算法与3种经典的红外与可见光图像融合深度学习方法进行比较,包括基于双分支多聚焦融合的深度卷积神经网络融合算法(CNN)[15]、生成对抗网络融合算法(FusionGAN)[16]、密集连接网络融合算法(DenseFuse)[19],计算复杂度和运行效率的对比实验结果如表4所示。
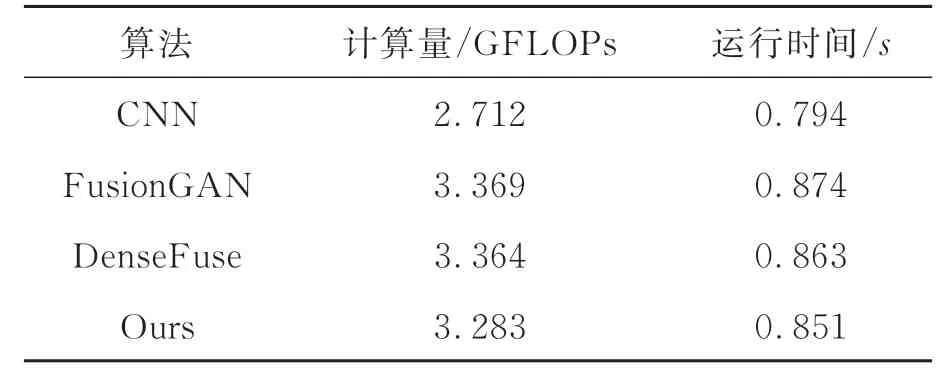
表4 计算量和运行时间Tab.4 Computational amount and runtime
表4中,1 GFLOPs=109FLOPs,从表4中可以发现,基于双分支多聚焦融合的深度卷积神经网络算法(CNN)因为网络层数较少,仅使用简单卷积操作进行特征提取,因此其计算量和运行时间在4种方法中最小,但该方法无法提取有效特征信息,融合结果较差。本文方法相较于生成对抗网络融合算法(FusionGAN)和密集连接网络(DenseFuse)计算量明显减少,且运行时间也低于上述两种方法。综上分析,结合表2客观指标评价和表4计算量和运行时间比较,可知本文算法在总体指标及算法性能上均取得了更好的评价。
4 结 论
本文结合多尺度和密集连接网络的思想,提出一种多尺度密集连接注意力的红外与可见光图像融合方法。在编码子网络模型中,通过多尺度卷积、密集连接可变形卷积注意力机制进行多维度特征提取,保留了红外与可见光图像中更多的细节和目标信息。然后,将提取到的红外与可见光特征在融合层使用基于L1范数的融合策略进行融合,最后通过全卷积解码子网络进行重构解码,生成最终的红外与可见光融合图像。通过数据集对比实验表明:相较于其他对比实验,本文方法客观评价指标都有所提高,其中结构相似性、空间频率指标分别平均提高了0.26倍、0.45倍。所提方法克服了现有深度学习模型在红外与可见光图像融合时特征提取不充分,细节重构丢失等问题,在主观视觉融合方面,能够有效减少伪影,使得目标边缘信息更加清晰,具有更好的对比度和清晰度,在主客观评价方面均优于对比方法。
猜你喜欢
环球时报(2022-05-23)2022-05-23 11:28:37
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
金桥(2021年4期)2021-05-21 08:19:20
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
电子制作(2019年7期)2019-04-25 13:17:14
传媒评论(2017年3期)2017-06-13 09:18:10
光学精密工程(2016年3期)2016-11-07 09:03:43
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
太空探索(2016年5期)2016-07-12 15:17:55
时代英语·高三(2014年5期)2014-08-26 17:01:17
