
局部-整体双向推理的文物无监督表征学习
2022-10-27 04:53:44耿国华刘阳洋周明全
光学精密工程 2022年18期
刘 杰,耿国华*,田 煜,王 毅,刘阳洋,周明全
(1.西北大学 文化遗产数字化国家地方联合工程研究中心,陕西 西安 710127;2.西北大学 信息科学与技术学院,陕西 西安 710127)
1 引 言
随着传统博物馆向数字博物馆的转变,文物的展示方式突破了藏品展陈的时空限制,变得丰富多样,同时稀缺文物也可以得到很好地交流与共享。作为考古史上的重大发现之一,由于自然环境和人为因素的影响,兵马俑大多以碎片的形式出土。因此,兵马俑的修复工作亟待解决。传统的人工修复方法不仅费时耗力,同时会对文物造成二次伤害。随着激光扫描仪技术的飞速发展,文物虚拟修复技术成为研究热点。作为文物修复的关键步骤,强大的碎片特征表示可大大提高碎片分类、匹配和拼接等工作的效率,对文物保护起着不可或缺的作用。
文物表征学习方法通常分为传统机器学习方法和基于深度学习的算法。传统方法一般采用专家设计的特征描述算子。Rasheed等[1]提出了依赖于RGB颜色特征和纹理特征、文物碎片之间以及基于灰度共生矩阵(Gray Level Cooccurrence Matrix,GLCM)从碎片中提取纹理特征的算法。路正杰等[2]提出了一种点云局部信息与显著性多特征描述子,并结合旋转投影特征,解决文物破损严重时分类效果差的问题。上述算法依赖于专家的先验知识,需花费大量时间,且手工设计提取特征的方法表达能力较弱,使得分类模型的泛化能力不强。近年来,随着深度学习的快速发展,一些学者将深度学习理论应用于自动驾驶[3-4]、遥感[5]、文化遗产保护[6-10]等领域,其中文物修复包括文物模型简化[6],文物碎片分类、分割[7-9]和文物碎片拼接[10]等。随着激光雷达传感器和深度传感器等三维数据采集设备的普及,点云已成为一种常见的三维模型数据,其结构简单且描述的形状信息丰富。如何将点云数据应用于上述领域,已经成为深度学习计算机视觉领域新的热点。由于点云是无序的且分布稀疏,使得将二维卷积直接应用在点云上是困难的。Charles等[11]提 出的PointNet是利用 深度网络 直接处理点云的开创性工作,并取得了较好的效果,但该模型没有考虑局部特征。许多后续工作通过设计能够更好地获取点云的局部特征的卷积来扩展这个方向[12-17]。PointNet++[12]通过将点云划分为小的子集,构建了通过层级结构学习局部区域特征的网络。Yang等[7]提出一种基于双模态神经网络,能够较好地同时提取兵马俑碎片的空间特征和图像纹理特征。Liu等[17]提出一种基于多尺度和自注意力机制的深度神经网络,可以较好地提取兵马俑碎片点云的局部特征和全局特征。
上述有监督学习方法虽然取得一定的成绩,但往往需要大量的人工标记数据做训练,人工标注工作费时耗力[18],尤其是对于真实场景数据集。因此,无监督特征表示方法的研究具有一定的现实意义。从无标签的数据中学习有用的表征是点云分析中一个具有挑战性的问题。现有方法大多数主要是基于生成或重建任务提供的自我监督信号,包括自我重建[19-21]和局部到整体重建[22]。Achlioptas等[19]通过多层感知器(Multi-Layer Perceptrons,MLPs)从特征表示中生成与原模型相似的结构,即Auto-Encoder(AE)结构。但该AE模型生成的点云模型较稀疏、粗糙。Yang等[20]提出一个通过深度网格变形的点云自编码器(FoldingNet),以此来得到可以表示高维嵌入点云的特征表示,并以基于折叠的解码器替换原有的全连接解码器。Li等[21]将已有的生成对抗网络框架(Generative Adversarial Networks,GAN)扩展到处理三维点云数据,提出一个用于点云分层采样和推理网络的深度生成对抗网络(Point Cloud-GAN,PC-GAN)。该网络通过使用层次贝叶斯建模和隐性生成模型的思想来学习生成点云。Liu等[22]通过局部到整体重建方法L2G Auto-Encoder同时学习点云的局部和全局结构。Hassani等[23]利用聚类、自动编码和自监督分类这三个无监督任务来学习点云上的点和形状特征并取得较好结果,但网络架构复杂。上述无监督学习方法在提取点云低层次结构信息时是有效的,但通常不能或难以从点云中学习高层次的语义信息。
针对上述问题,本文通过不同抽象层次的局部表征与文物碎片对象的全局表征之间的双向推理,提出一种能够同时学习点云的结构和语义信息的无监督点云表征学习。该局部-整体双向推理模型由两部分组成:(1)局部到整体推理:首先定义预测网络,将局部特征和全局特征映射到一个共享的特征空间内,然后衡量由局部特征得到的全局特征与直接提取的全局特征之间差异,进行反复学习,使其局部特征向全局特征靠拢;(2)整体到局部推理:为保证全局特征的质量,利用自重建任务学习文物碎片对象必要结构信息的全局特征。本文算法在兵马俑数据集和Modelnet40公开数据集上的准确率分别达到93.33%和92.02%。其中在兵马俑数据集上,该算法优于除有监督模型AMS-Net(较AMS-Net准确率低2.35%)之外的所有方法。实验结果表明,本文无监督方法的点云表征在下游分类任务中比部分有监督表征更有鉴别力,同时缩小了无监督和监督学习方法之间的差距。作为将无监督表示学习应用于3D兵马俑数据集的一次新的尝试,该方法减少了文物数据集在收集和注释过程中所花费的大量成本,对文物虚拟修复提供一种可行的方法,具有一定意义。

图1 兵马俑碎片数据集示例Fig.1 Examples of the Terracotta Warriors fragments datasets
2 兵马俑数据集制作
本实验所使用的兵马俑碎片数据集是由西北大学文化遗产数字化国家地方联合工程研究中心可视化研究所的学生使用Creaform VIU718手持式3D扫描仪采集得到的,共来自3 250块兵马俑碎片,并根据每个碎片所属部位的不同,将其分为手臂(800块)、身体(810块)、头部(810块)和腿(830块)四类。兵马俑碎片数据集示例如图1所示。对扫描得到的点云进行去噪声和下采样等一系列预处理操作。首先,使用Geomagic软件获得如图2(a)所示的原始稠密点云。其次,为减少网络的过拟合,同时提高网络预测的鲁棒性,需对稠密点云按一定比例进行下采样。使用随机采样方法,将一个碎片点云重新采样为四个不完全重叠的点云,且保证每个点云包含固定的点个数(1 024点),如图2(b)所示。图2(c)表明上述四个点云集合不完全重合。通过上述一些列操作,最终得到包含11 996块碎片的扩增数据集,将其划分为训练集和测试集两部分。其中,训 练 集 包 含10 144块 碎 片(Arm:2 656,Body:2 720,Head:2 272,Leg:2 496),测试集包含1 852块碎片(testArm:476,testBody:504,testHead:428,testLeg:444)。
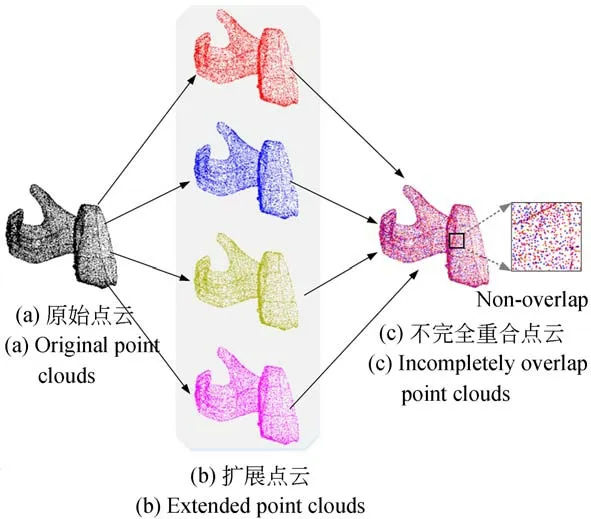
图2 扩展数据集制作流程Fig.2 Approach of the extend dataset
3 基于局部-整体双向推理无监督表征学习方法
利用三维模型的底层语义信息和结构信息融合在对象的整体结构中这一独特属性,使得三维模型可以由单个部分推理整个对象。如图3所示,通过给定兔子耳部的点云,可推断出相应整体对象;整个兔子的表示也包含所有必要的细节来推断该兔子的局部结构。受上述启发,本文通过局部-整体之间的双向推理问题来实现点云表征学习。
本文提出的局部-整体双向推理无监督表征学习整体网络框架图如图4所示。首先,将点云P输入至由两个多尺度壳模块组成的分层结构。编码器通过构建分层结构的点分组,逐步扩大感受野,最终得到第l层局部特征Fl和维度为512的全局特征G。为保证全局特征G能够获得更丰富的点云表示,本文建立由局部到整体推理模块,从而使得全局特征包含更多的结构信息和语义信息。为保证全局表征不偏离原始点云,再次提出从整体到局部的推理模块,利用折叠解码器(Folding-based Decoder)将学习到的全局特征G重新解码为3D坐标,使得全局特征G能够捕捉到更多的点云结构信息。接下来将详细介绍每个模块的组成部分。
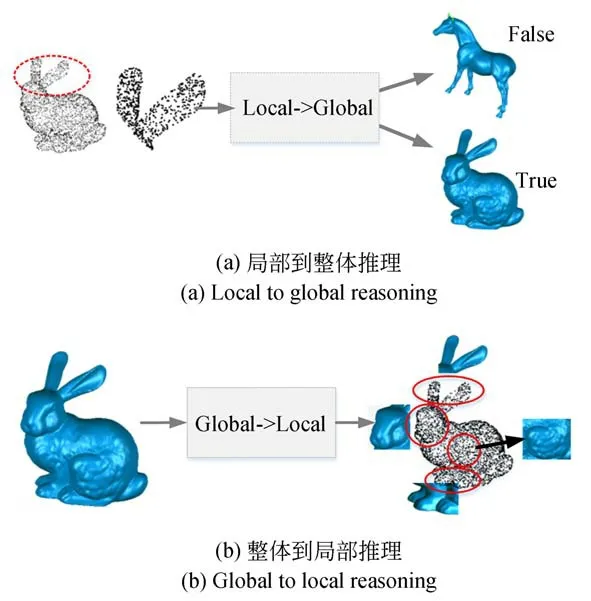
图3 局部-整体双向推理Fig.3 Local-global bidirectional reasoning
3.1 多尺度壳卷积层级结构特征提取
多尺度壳卷积模块如图5所示。本节将从多尺度局部区域的构造、单尺度特征提取和多尺度特征融合三部分分别予以介绍。
3.1.1 多尺度局部区域的构造
与PointNet++[12]和ShellNet[13]类 似,该 模型的多尺度局部区域构造分别由采样层、搜索层和分组层组成。首先,采样层利用最远点采样算法(Farthest Point Sampling,FPS)从输入点云P中选择M个点作为局部区域的质心,即PMc=在每个局部区域中,搜索层通过最近邻搜索算法(K-Nearest Neighbors algorithm,KNN)寻找质心点的ki(i=1,2,3)个最近邻点,并返回对应的点索引。其中,ki为各个局部区域每个尺度包含点云数目,本文使用三个不同大小的尺度,故i取值为3。最后分组层将点云集分成多组具有不同尺度大小的局部点集,其大小为M×ki×3。
3.1.2 单尺度特征提取
为便于理解,接下来先介绍单尺度模块结构及特征提取,如图5(b)所示。
本文提出一种邻域的划分方法。对于每个采样点,将其邻域划分为一组同心球体,两个同心球体之间的空隙定义为同心球壳。对于任意采样点,壳卷积算子计算局部特征的算法如下:
输 入:采 样 点pi∈P,i=1,2…N,邻 点pj,∀pj∈Bp,邻 域Bp,以 及 前 一 层 特 征F()l-1(pj)(上标l表示第l层)。
输出:采样点pi经过壳卷积的输出特征Fp。
Step1:通过KNN搜索采样点pi的邻点pj,并将邻点特征维度提高到F()l(pj)。
Step2:若已存在前层特征F()l-1(pj),则将F()l-1(pj)与F()l(pj)拼接在一起作为该点提取得到的特征F(l-1)(pj)。
Step3:根据邻点pj到采样点pi的距离确定pj属于哪个壳,同一个壳内的点用X表示。
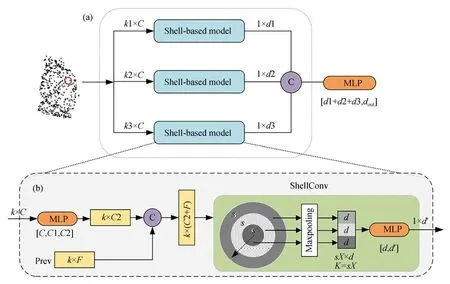
图5 多尺度壳卷积模块Fig.5 Multi-scale shell convolution block
Step4:通过最大池化操作获取每个壳的局部特征。
Step5:按照从内到外的顺序对所有壳的局部特征执行一维卷积,得到输出特征Fp。
对于任意采样点pi来说,pi点上传统的卷积为:
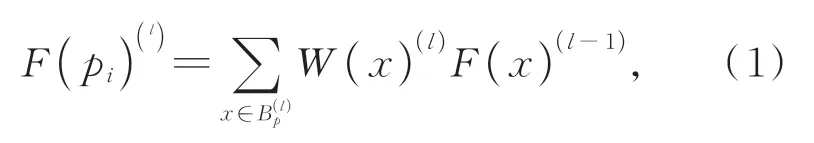
其中:F(·)表示输入点的特征,W表示卷积的权重。每个点均需一个与之对应的权重,但点云是无序的,为每个邻点pj都分配卷积权重W(pj)是不切实际的。为解决该问题,本文将划分为同一壳内的点的特征分配相同的卷积权重。如图5所示。规定每个壳中的点个数是固定的,确保每个壳中包含的点数达到阈值s后,向外扩展,直到下一个壳内点个数也达到s,依此类推。假设该采样点的邻域由X个壳组成,则邻域数k为sX,那么采样点的邻域可表示为M×k×3。改进后的卷积可定义为:
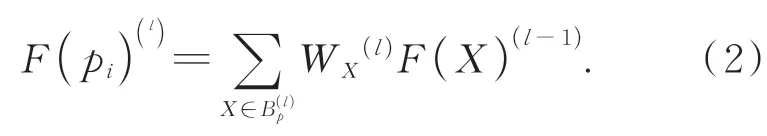
按照由内到外的顺序对壳进行排序,每个壳的权重为WX。但每个壳中的点仍然是无序的,为了产生对输入顺序不敏感的输出,通过最大池化来聚合同一个壳内的点,并使用一维卷积整合所有壳的特征以获得采样点的融合特征Fp:
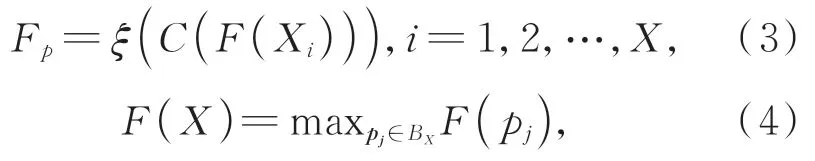
其中:C(·)为拼接操作,ξ(·)为一维卷积操作。
3.1.3 多尺度特征融合
受文献[13]启发,本文提出一种基于多尺度壳卷积点云特征提取方法,其结构如图5所示。
每个单尺度模块输出的特征在进入下一个多尺度壳模块之前还将进行特征聚合,以形成包含不同尺度局部信息的全局特征。其中,三个不同尺度的特征分别记为Fpk1,Fpk2,Fpk3,融合后的多尺度特征记为Fmulti:
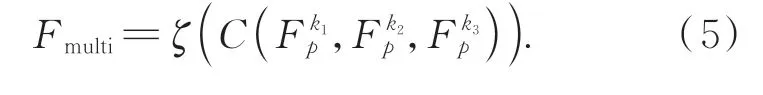
3.2 局部到整体推理模块
本文利用局部和整体形状之间的关系作为监督信号,用于训练丰富的表征进一步理解点云。由于全局表征通常比局部表征能更好地捕捉对象的语义信息,所以局部到目标的推理是通过预测局部的全局表征来进行的。为了评估预测结果,本文将预测视为自监督度量学习问题,并使用改进多类N对损失(N-pair loss)来监督预测任务。
首先,简单回顾三元组损失函数[24](Triplet loss)。三元组{pa,pp,pn}由锚点pa,正样本pp和负样本pn组成。映射函数fω(·)可以将点pi映射到嵌入特征fω(pi)∈Rd。为方便表示,令χa=fω(pa),χp=fω(pp),χn=fω(pn)。Triplet loss的目标是使同类样本的特征在空间位置上尽量靠近,不同类样本位置尽量远离,并要求pa到负样本pn的距离与pa到正样本pp的距离之差至少大于阈值η,图6为Triplet loss与N-pair loss示意图,其中,“+”代表正样本,“-”代表负样本。Triplet loss表示形式如式6所示:

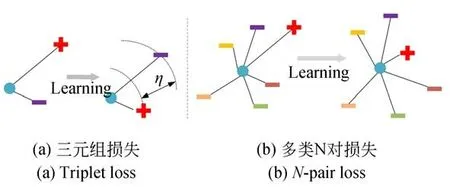
图6 Triplet loss与N-pair loss示意图Fig.6 Illustration of Triplet loss and N-pair loss
Triplet loss在学习参数的更新过程中,只比较了一个负样本,而忽略了其他类的负样本,故Triplet loss收敛速度慢。针对上述情况,N-pair loss[25]被提出,它是由多个负样本对组成,即一对正样本对,选取其他所有不同类别的样本作为负样本与其组合得到负样本对。如果数据集中有C类别,则每个正样本都对应了N-1个负样本对。通过图6中两者比较,Triplet loss可看作是N-pair loss的一 个 特 例(N=2)。N-pair loss的 形式如式(7)所示:
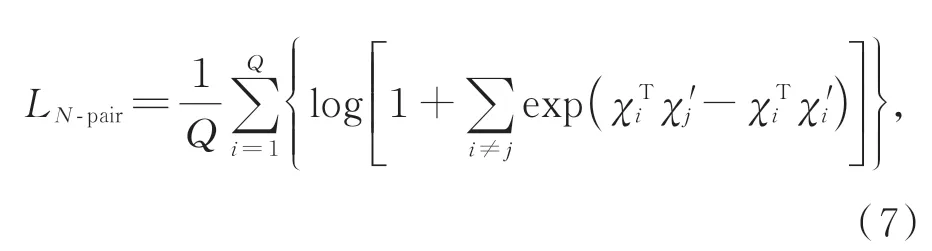
其中,χi=fω(pi)和{pi,p1′,p2′,…,pQ′}为来自Q个不同类别的样本对。为学习每个对象的不同语义信息,将当前对象的全局表示作为正样本,将其他类对象的全局表示作为负样本。由于局部特征Fpi(l)和全局特征G的维度不同,无法直接衡量它们之间的相似度。故先使用Γ(l)(·)和B(·)将它们分别嵌入到一个共享的特征空间中。
优化预测的一种直接方法是最小化Γ(l)(Fpi(l)),B(G)之间的整体差异,即最小化然而,该目标可能会导致将所有输入映射到一个常数。本文使用自监督度量学习任务来监督预测的好坏。对于每个嵌入的局部表示Fpi()l,强制其特征比任何其他类别对象更接近同一对象的全局表示,故本文使用的改进N-pair loss表示为:
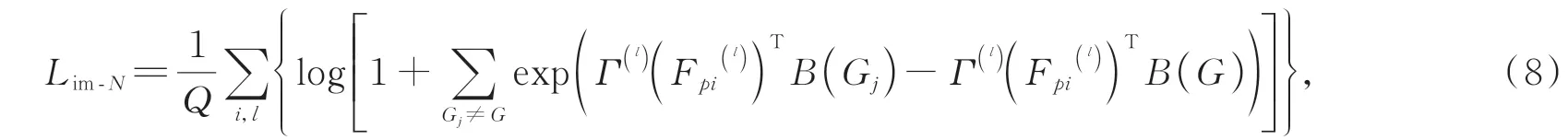
其中:{Gj}qj=1是批量大小为q的批量中不同点集的全局表示,M是局部特征的数量。
3.3 整体到局部推理模块
局部到整体的推理只能监督局部表征接近全局表征,全局表征的好坏至关重要。若全局表征效果好,则会对局部表征提供较好的监督,从而为局部和全局特征的学习创造一个良性循环。反之,会导致网络学习到不可预知的结果。为避免该问题的产生,本节提出自重建辅助任务来监督网络共同学习有用的表征。自重建模块采用3.1节提出的基于多尺度壳卷积层级编码器,解码器结构图如图4中Decoder所示。首先,将编码器所得到的全局特征G∈R1×512复制m次,可得FG∈Rm×512。其次,将大小为m×512的特征矩阵FG与包含m×2网格矩阵拼接得到Fnew∈Rm×514,其中m×2矩阵包含以原点为中心的正方形上的m个网格点。然后,将Fnew送入MLPs得到粗输出Fcoarse,其特征矩阵大小为m×3。为得到更好的重建点云,最后将m×512矩阵FG与粗输出Fcoarse拼接,再经过MLPs,得到最终重建点云。其中,网格大小m2是根据输入点云大小设置的,且需满足m2≥N。本实验m=32,N=1 024。
在给定输入点云P时,重建点云是由基于折叠解码器D将规范的2D网格变形到以全局表示G为条件的点云的3D坐标上,记为J(G),其中J(G)∈RN×3。重建误差Lrec定义为P和J(G)之间的倒角距离,故其损失函数定义为:
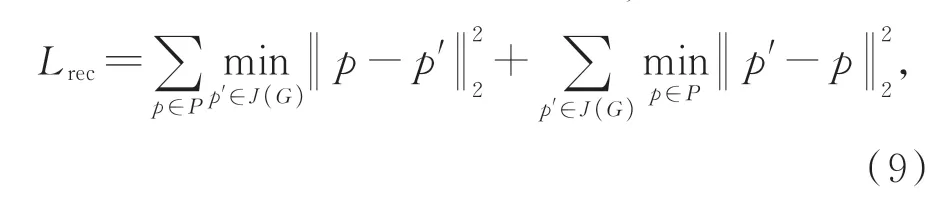
其中:P为输入点云,p为输入点云中的点,J(G)代表重建点云,p′是重建点云中的点。
4 实验结果及分析
4.1 实验数据集
本文分别选用兵马俑数据集和公开数据集ModelNet40作为基准数据集并完成对该模型的测试,将其实验结果与其他方法进行比较。其中,兵马俑数据集已在第2节介绍。ModelNet40包含来自40个类别的12 311个CAD模型,其中包含9 843个训练样本和2 468个测试样本。本实验中所有数据只使用点云的坐标特征(x,y,z)。
4.2 实验设置
编码器网络结构包含两层多尺度壳卷积模块,每个模块均包含三个不同尺度的壳卷积算子。其中,参数Mj、sj和Xi(i=0,1;j=0,1,2)分别表示每层的采样点的个数、每层壳的大小和不同尺度中壳的数量。因此,每个采样点的邻域个数为sj×Xi。具体参数取值如表1所示。对于第一层模块来说,三个尺度邻点个数分别等于32,64,128.同理可得,第二层模块中不同尺度的邻点个数为16,32,64。
本文使用Lim-N和Lrec联合损失为损失函数,并使用Adam优化网络,初始学习率为0.001,动量为0.9,批量大小为22。同时使用Lambda学习率调度器,每20轮将学习率衰减0.5。
实验硬件环境为Intel Core i7处理器、16 G内存、2 T硬盘、显卡NVIDIA GTX 1080Ti;软件环境为Ubuntu16.04 x64+CUDA9.0+cuDNN 7.0+PyTorch1.2+Python3.7.
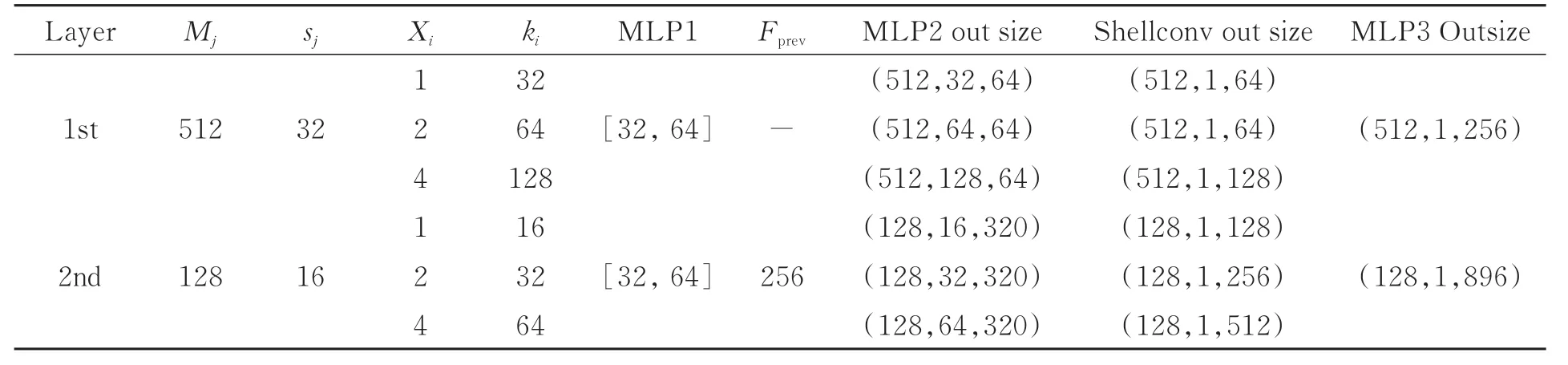
表1 编码器网络参数Tab.1 Encoder network parameters
4.3 不同方法实验对比分析
为验证本文方法的有效性,选取一种传统点云分类方法和五种深度学习点云分类方法与之比较。目前基于兵马俑点云集的无监督表征学习方法研究甚少,上述对比方法只有Foldingnet[20]为 无 监 督 方 法,其 余 方 法 均 为 有 监 督方法。
从表2可以看出,除AMS-Net方法之外(准确率比本文方法高2.35%),本文方法在兵马俑数据集上取得了93.33%的最高分类准确率。表中输入数据类型字段中“P”代表点云,“G”代表图像。基于模板的兵马俑碎片传统分类算法[26]将分类问题转化为形状匹配问题,分类准确率为表2所 列 出 方 法 中 最 低。PointNet[11]缺 乏 局 部 特征的提取,易造成细节特征的丢失,故分类精度仅为88.93%。文献[7]在PointNet基础上结合图像轮廓特征,提出一种融合点云和图像轮廓的双模态网络,相比于单独使用PointNet网络,正确率提升了2.48%。然而本文提出的无监督方法比文献[7]提高了1.92%,并远超于无监督方法Foldingnet(提高了11.42%)。另外,本文所提出模型的编码部分是在ShellNet的基础上结合了多尺度策略,最终分类准确率高于ShellNet方法0.89%。但在ModelNet40数据集上,ShellNet高于该无监督方法1.08%(见表10),由此可以表明,该方法能够针对兵马俑碎块数据集进行较好的特征表示,为兵马俑碎块分类任务提供了更加可靠的信息。
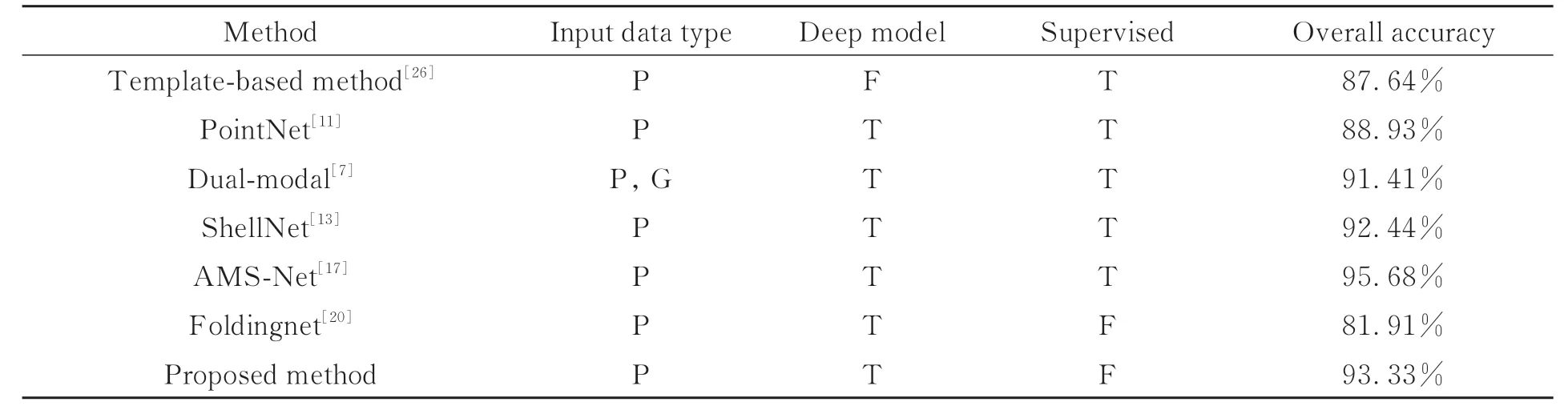
表2 兵马俑数据集上不同方法的分类准确率Tab.2 Classification accuracies of different methods on Terracotta Warrior fragments dataset.
为了更科学地评估本文算法的分类效果,引入精确率(IPrecision)、召回率(IRecall)和F1值(IF1)作为评价指标。由于数据集包含多个类别,故文本采用平均精确率(P)、平均召回率(R)、平均F1值(F)作为整体的评价指标,三者分别为所有类对应值的算术平均值,其计算公式如式(10)~(12)。其中,NTP为正确判断的正样本数,NFN为误判的正样本数,NFP为误判的负样本数,类别个数为T。本组实验仅对表2代码公开的方法进行对比。从表3可以看出,本文算法在上述三个评价指标的结果与准确率保持一致,进一步说明该无监督方法在文物分类任务上具有一定的稳定性。
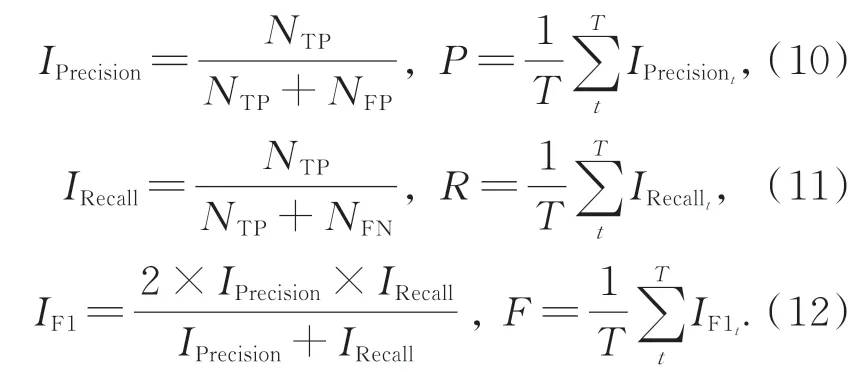
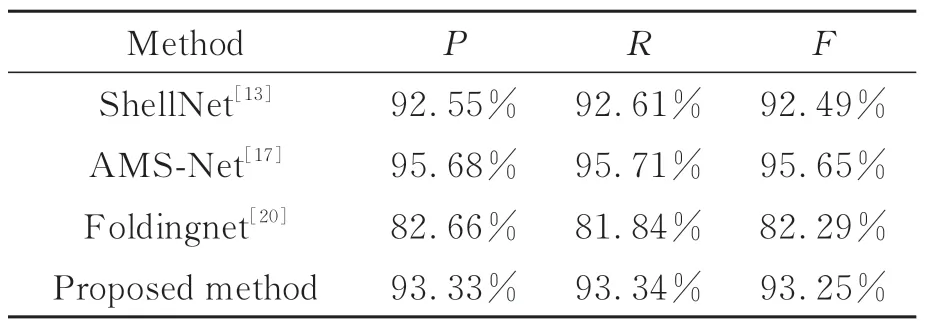
表3 不同模型的分类性能Tab.3 Classification performance of different models
从表4可以看出,表中的所有方法身体和头部两个类别的准确率要高于胳膊类和腿类。身体类的准确率最高,胳膊类的准确率最低。主要原因是身体大部分部位是衣服或盔甲,褶皱较多,特征较为明显(见图1)。部分胳膊类的特性与腿较为相似,容易被误分类。整体上本文方法相较于文献[7]都有很大的提升。
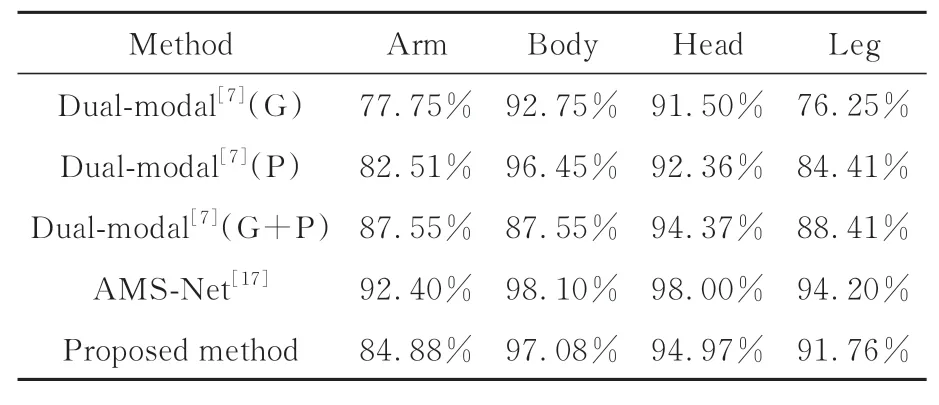
表4 4个类别中的分类精确度Tab.4 Classification accuracies of the four classes
4.4 消融实验分析
为进一步评估该网络模型中每个组成模块对网络性能的影响,在兵马俑数据集分别进行三组对比实验。
(1)编码器结构:单尺度与多尺度对比。从表5可以看出,多尺度模型比单尺度模型准确率高2.40%,这表明该模型编码器可以有效地提取多个尺度的细节特征。

表5 编码器对分类精度的影响Tab.5 Effect of the encoder on classification accuracies
(2)解码器结构:MLPs与Folding-based进行对比,其中,MLPs输出通道数为[512,256,3]。从表6可以看出,本文采用的折叠解码器比直接经过简单的MLPs准确率提升1.88%。为进一步证明该模型的有效性,将两个网络的收敛性进行了比较,结果如图7所示。该网络在训练25轮后逐渐变得平稳,且损失值低于MLPs解码器。损失函数值越小,表明解码生成的点云与输入点云越相近。

表6 解码器对分类精度的影响Tab.6 Effect of the decoder on classification accuracies
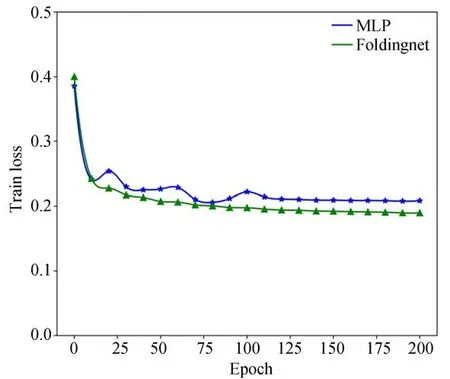
图7 不同解码器训练损失曲线Fig.7 Training loss curves for different decoders
(3)损失函数:Lrec与Lim-N+Lrec进行对比。从表7可以看出,仅通过自重建损失进行训练,得到89.47%的低分类准确率。当使用本文提出的联合损失时,准确率可提升3.86%。结果表明通过度量每层局部特征与编码获取的全局特征,可以使网络进一步捕获兵马俑碎片的潜在语义特征,从而提高分类准确率。

表7 损失函数对分类精度的影响Tab.7 Effectofthelossfunctiononclassificationaccuracies
4.5 鲁棒性
为进一步验证该模型的鲁棒性,将大小在[-1.0,1.0]的随机噪声添加到输入点云中,当一个点替换为噪声点(nn=1)时,该模型的准确率为92.13%,其中nn为噪声点数量。从表8可以看出,当噪声数量高达100时,该模型仍然有很好的分类结果。表明该方法更适合真实场景数据集。

表8 不同噪声点的结果Tab.8 Results for different noise points
4.6 在Modelnet40公共数据集的结果分析
为评估该方法在点云表征学习方面的性能,接下来在Modelnet40公共数据集上对其进行实验测试。首先从上述预训练模型中提取Model-Net40数据集的全局特征;然后将其放入线性分类器进行训练,无需任何微调,得出分类结果。将本文方法与已有无监督表征学习方法进行比较,实验结果如表9所示,其中,l-GAN的实验结果为文献[22]的复现结果。本文方法只使用ModelNet40作 为 训练数据,而l-GAN[19]和FoldingNet[20]的 训 练 数 据 是 包 含 超 过57 000个3D对象的ShapeNet数据集。尽管如此,本文方法仍比它们分别提高4.75%和3.62%。从定量结果可以看出,本文方法取得较好的分类性能,准确率为92.02%,分别比L2G和Multi-Task方法高1.38%和2.92%。
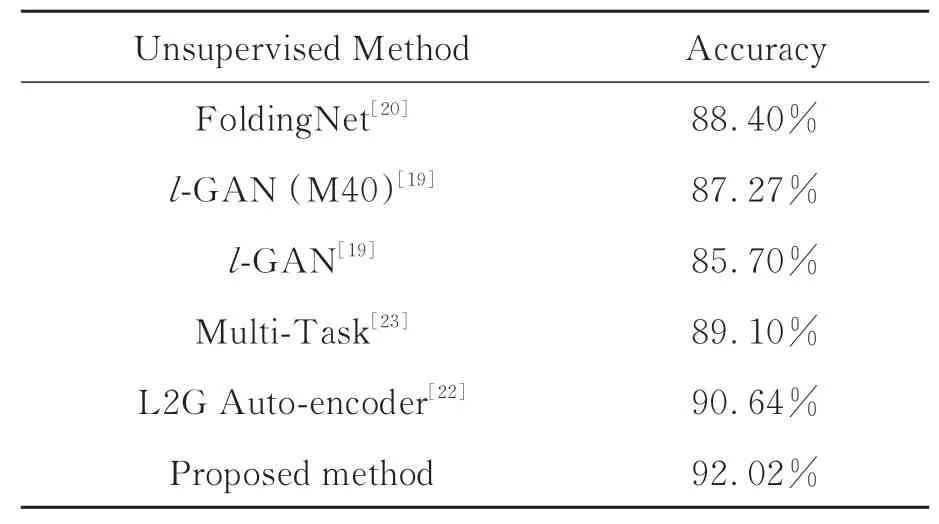
表9 与已有无监督方法在ModelNet40上的对比结果Tab.9 Comparisons of the classification accuracy of our method against the unsupervised learning methods on ModelNet40
从表10中可以看出,本文方法分类准确率分别 比PointNet和PointNet++提 高2.82%和1.32%。即使SO-Net输入点云个数为2 048,本文方法仍相比提高1.12%。结果表明本文方法获取的特征表示比一些监督表示更具辨别力。

表10 与已有监督方法在ModelNet40上的对比结果Tab.10 Comparisons of the classification accuracy of our method against the supervised learning methods on ModelNet40
5 结 论
本文提出一种无监督表征学习网络,应用于3D文物碎片分类的下游任务。首先通过层级结构的多尺度壳卷积编码器来学习点云模型不同区域之间的相关性。其次通过各层局部特征和全局特征之间的相似性度量以捕获模型的结构和语义信息。最后将学习到的点云表征应用于点云分类下游任务。实验结果表明,本文算法在兵马俑数据集和ModelNet40数据集的分类准确率分别为93.33%和92.02%。在ModelNet40数据集上,ShellNet比该无监督方法高1.08%;而在兵马俑碎块数据集上,该方法比ShellNet高0.89%。结果表明该方法更适合于兵马俑碎块分类,同时缩小了下游分类任务中无监督和有监督学习方法之间的差距。本文尝试将点云无监督表征学习网络应用于兵马俑碎片数据集,结果也验证了该方法的有效性。接下来将继续该方法扩展到更多的文物点云分析场景中。
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:07:12
数学物理学报(2022年2期)2022-04-26 14:08:04
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
中学生数理化·八年级物理人教版(2019年4期)2019-05-20 10:02:36
心声歌刊(2018年5期)2018-12-10 01:44:08
金桥(2018年4期)2018-09-26 02:24:54
小学教学研究(2017年24期)2017-08-29 14:49:54
太空探索(2016年5期)2016-07-12 15:17:55
大众考古(2015年6期)2015-06-26 08:27:12
中国卫生(2014年5期)2014-11-10 02:11:26
