
基于状态转移算法的极限学习机
2022-10-26 07:03邹伟东李钰祥夏元清
北京理工大学学报 2022年10期
邹伟东,李钰祥,夏元清
(北京理工大学 自动化学院, 北京 100081)
为解决多层神经网络[1]在模型训练时需要设置大量参数且训练耗时较长的问题[2],HUANG 等[3]提出了极限学习机(extreme learning machine,ELM),这是一种求解单隐藏层前馈神经网络的算法,具有结构简单和随机生成参数的特点. 目前极限学习机算法已经广泛用于图像识别[4]、目标追踪[5]和在线预测[6]等领域.
在之后的ELM 研究中,正则化极限学习机(RELM)的提出解决了模型过拟合的问题并被广泛使用[7],LAI 等[8]基于凸优化理论提出的ADMM-ELM 提高了算法的收敛速率,这些方法都是目前较为主流的极限学习机算法. 另一方面,对ELM 的许多研究都是从网络结构层面出发的,比如基于群智能优化角度,研究人员分别提出了利用比较流行的自适应差分进化算法优化网络结构[9]和利用不同拓扑结构对PSO-ELM 进行结构搜索的方法[10]等. 从增量构造法和剪枝构造法的角度出发,YE 等[11]和ZHOU 等[12]分别提出了基于QR 分解的增量QRI-ELM 算法和基于随机傅里叶映射的 ℓ2,1RF-ELM 算法.
以上研究使极限学习机得到了进一步发展,但是没有解决极限学习机建模精度不足的问题. 虽然极限学习机相比于多层神经网络有建模效率高的优点,但由于其参数生成具有随机性的原因导致建立的模型泛化性能弱. 同时利用的Moore-Penrose 广义逆的方式求解输出权重矩阵建模导致模型的精度不理想. 在一些复杂的场景下,经常会出现隐藏层输出矩阵的阶数很大的情况[13],此时利用广义逆解矩阵方程效率低且精度较差. 在面对矩阵方程的问题上,有时也会用迭代法来解决问题,比如Jacobi 迭代、Gauss-Seidel 迭代[14]、逐次超松弛(SOR)迭代[15]等都是常见的迭代法. 这些算法相较于利用广义逆的方法来说具有更高的效率,但同样也有较大的局限性,比如Jacobi 算法只适用于相关矩阵为方阵的情况[16],有些算法占用的硬件资源过多等,由此可知设计一种满足收敛性且性能较好的迭代算法是十分困难的.
以上对极限学习机的研究主要有两点不足:①对极限学习机的优化大多都是针对梯度和网络结构层面的,忽略了极限学习机本身精度不够好的问题,具有一定局限性. ②在解决极限学习机求解输出权重矩阵的问题上利用设计迭代方程的方式可行但较为困难.
为了解决上述问题,提出了基于状态转移算法(state transition algorithm,STA)[17]的极限学习机(STAELM),该算法不再利用广义逆和迭代方程求极限学习机中的输出权重矩阵,而是通过一种新型随机性状态转移的方法对输出权重矩阵进行全局搜索. 算法既保留了极限学习机优化后的网络结构,也提高了建立模型的精度. 本文通过将STA-ELM 算法与传统ELM 和一些主流算法在分类和回归数据集上进行性能对比,验证了算法的有效性和准确性.
1 基本算法概述
1.1 极限学习机
极限学习机是由单隐藏层组成的一种前馈神经网络,通过随机产生输入权重和偏置计算输出权重.
对于给定的M个训练样本(xi,ti),其中xi和ti分别表示第i个样本的输入特征向量和标签对应的输出特征向量. 若m为特征维数,l为标签维数. 设g(x)为激活函数,则极限学习机的网络结构由一个m维输入层、一个含有N个节点的隐藏层和l个节点的输出层组成. 其数学模型为
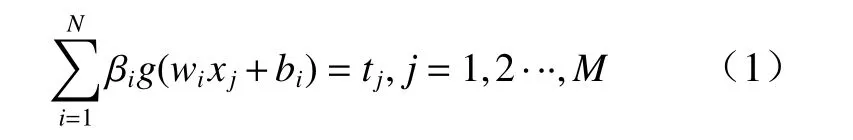
式中:wi为连接第i个隐藏层节点与输入层节点的输入权重; βi为连接第i个隐藏层节点与输出层节点的输出权重;bi为第i个隐藏层节点的偏置.
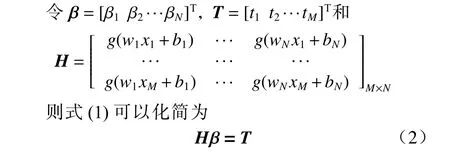
式中H为隐藏层输出矩阵,通过线性方程组(2)易得到输出权重的最小二乘解

式中H+为H的Moore-Penrose 广义逆矩阵.
1.2 状态转移算法
状态转移算法是基于状态与状态转移提出的一种优化方法,具有结构简单、寻优效率高的优点,一直较为广泛地应用于传统优化和工业控制领域. 其基本思想是通过不同算子的变换计算进行解的更新.算法中候选解产生的框架如下
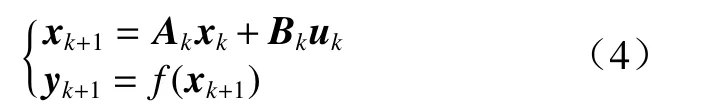
式中:xk为当前状态,代表搜索中产生的一个候选解;Ak和Bk为状态转移矩阵,是优化算法中的一个算子;uk在控制中可以看成是控制变量;f(·)为目标函数或者评价函数.

式中xbest为从候选解中选择的“最优解”.
状态转移算法定义了式(6)~(9) 4 种变换算子,按照一定规则循环进行4 种变换.
①旋转变换(rotation transformation, RT).
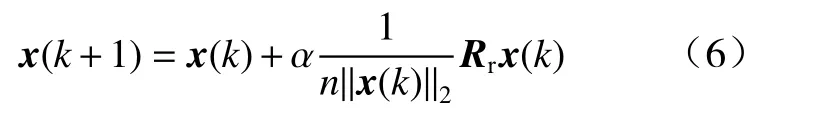
式中:k为状态转移的次数;α >0为旋转因子;Rr∈Rn×n为一个其元素取值在[-1,1]之间均匀分布的随机矩阵; ‖·‖2为向量2-范数或欧氏范数.
②平移变换(translation transformation, TT).
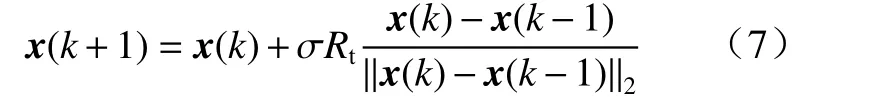
式中:β >0为平移因子;Rt∈R为一个其元素取值在[0,1]之间均匀分布的随机数.
③伸缩变换(expansion transformation, ET).
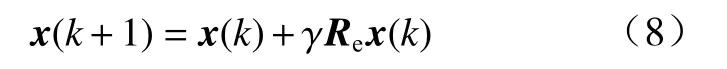
式中:γ >0为伸缩因子;Re∈Rn×n为一个其非零元素取值服从高斯分布的随机对角矩阵.
④轴向变换(axesion transformation, AT).
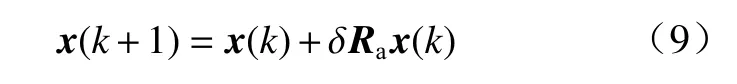
式中:δ >0为轴向因子;Ra∈Rn×n为一个其非零元素取值服从高斯分布的稀疏随机对角矩阵.
2 基于状态转移的极限学习机算法
2.1 基于状态转移的极限学习机
利用状态转移算法搜索矩阵方程的解既满足了收敛性条件又不用考虑矩阵的奇异性,同时避免了设计复杂的迭代规则.
本文根据实验效果对基本状态转移算法做出改进,根据几种变换算子的特性,改进的状态转移算法减小了伸缩变换的计算次数,增加旋转算子的计算次数,并将平移因子由固定值改为根据循环次数进行迭代赋值. 这是因为伸缩算法的特性可以避免搜索陷入局部最优解,而在每一次搜索中,只需要几次并行的伸缩变换便可以满足该次搜索的全局最优性,而旋转算子是算法可以在局部搜索到最优解的保证,因此该步骤需要并行搜索次数较多, 根据实验可以发现每次搜索大约需要30 次左右并行的旋转变换便可以搜索到当前邻域内的较好的局部最优解. 平移变换具有在实现上搜索的功能,根据STA 算法的可控性原则可知,平移因子可以逐次搜索设置更小的值,使每次搜索的候选解更加集中,有助于算法更快收敛到全局最优解.
设计基于状态转移算法的极限学习机步骤如下:
①得到训练样本数据集,数据集中的元素记为(x,t),其中,x为特征向量,t为标签向量.
②结合利用极限学习机的结构模型,随机生成隐藏层的输入权重矩阵和偏置矩阵,利用激活函数(Sigmoid 函数)得到输出权重矩阵H,结合样本标签T得到矩阵方程Hβ=T.
③利用状态转移算法求解输出权重矩阵 β,设置参数的初始值,随机生成初始解βbest=β0,按如下伪代码进行迭代:

算法1:搜索输出权重矩阵最优解1 For i=0 to G do α <αmin 2 if then α ←αmax 3 4 βnewbest ET(funfcn, βbest,SE1, )5 if f(βnewbest)< f(βbest) then←σ←γ 6 βnewbest TT(funfcn, βnewbest,SE0, )←7 βbest βnewbest←8 βnewbest RT(funfcn, βbest,SE2, )9 if f(βnewbest)< f(βbest) then←α 10 βnewbest TT(funfcn, βnewbest,SE0, )←σ 11 βbest βnewbest←12 βnewbest AT(funfcn, βbest,SE3, )13 if f(βnewbest)< f(βbest) then←σ δ 14 βnewbest TT(funfcn, βnewbest,SE0, )←15 βbest βnewbest α ←α/fcσ ←σ/fc 16 ,17 until 某个终止条件满足
其中,ET、RT、AT 以及TT 函数分别实现了伸缩变换、旋转变换、轴向变换以及平移变换,根据给定的目标优化函数按照式(5)进行βbest的更新. 为了缩短搜索时间,根据后续的实验结果,本算法将STA 中的单次循环执行各个变换的次数改为不相同,减小了部分变换所用的次数. 同时根据实验结果发现如果对平移因子也进行迭代的话,模型精度会更高.
④得到输出权重矩阵,利用建立的模型对测试样本进行分类或拟合,根据实验结果对算法进行评价.
需要注意的是,该算法在分别处理分类和回归的问题时,使用了两套不同的优化目标函数. 在处理分类的问题时,本文利用平均交叉熵函数作为目标优化函数,如式(10)所示;在处理回归预测问题时,本文用矩阵方程的二范数代价函数作为目标优化函数,如式(11)所示.
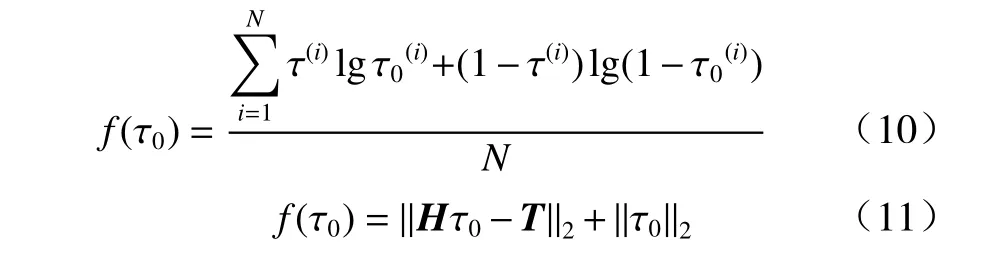
式中: τ0为当前最优解;N为训练样本个数.
本文算法通过搜索的方式可以得到比利用广义逆和迭代法更精确的解,同时也避免了搜索陷入局部最优解的情况,实验验证了该算法在各种场景下在效率和精度上都有着更好的表现.
2.2 基于状态转移的极限学习机算法复杂度分析
本文算法将基本极限学习机中的关键一步,即求解输出权重矩阵的方法做了改进,使得算法建立的模型有更高的精度. 本节将从算法改进前后的时间复杂度和空间复杂度对改进算法的代价进行评价.这里假设关键一步式(2)中的H是M×N维的,标签T是M×K维的.
传统极限学习机求解式(2)的矩阵方程利用的是M-P 广义逆的方式,这种方式底层是通过将H矩阵进行奇异值分解,得到左奇异向量UM×M、右奇异向量VN×N和一个包含奇异值的对角矩阵DM×N,再根据式(12)计算出H矩阵的广义逆H+,最后通过H+得到模型的输出权重矩阵的. 其中D+为对角矩阵D的伪逆,这里是通过将D中非零元素取倒数后再转置得到的.
分析可知,在对H进行奇异值分解的过程中,运算的时间复杂度应该为O(N3),通过式(12)求解广义逆的运算所需的时间复杂度应为O(M2×N),而最后一步通过H+求出输出权重矩阵的时间复杂度为O(M×N×K). 由此可知,基于广义逆方法的ELM 算法在求解输出权重矩阵这一步的时间复杂度为O(N3)+O(M2×N)+O(M×N×K),而需要的额外空间复杂度为O(max{M,N}2),主要是用于记录奇异值分解后的形成的矩阵.

基于STA-ELM 在求解输出权重矩阵这一步,利用了搜索的方式进行输出权重矩阵的迭代,这里假设循环的次数为G,由于每次变换并行运算SE次,故不计入时间复杂度. 对4 种变换,本文选择复杂度最高的旋转变换来考虑,得到STA-ELM 在计算输出权重时所需的时间复杂度为O(G×N2×K),所需额外空间复杂度为O(N2),主要用于记录变换中的辅助矩阵.
通过上述的复杂度分析可以知道,STA-ELM 相对于传统ELM 相关算法在提高了精度的同时,可能会以牺牲一些训练时间为代价,因为从时间复杂度来看,本文算法的复杂度貌似多了一层大循环G,但实际上通过数据集和实验效果来看,由于需要搜索的是输出权重矩阵,而该目标的维数K代表的含义是标签的特征数目,大部分情况下这个值都是1,因此可以忽略K,此时STA-ELM 的时间复杂度便低于传统ELM 算法,而在后续实验中可以发现对于循环次数G,通常设置100~500 次左右便可以有不错的效果,此时G的值往往也比训练样本的数目要小,所以此时STA-ELM 建模的效率反而要更高,通过对额外空间复杂度分析可得,STA-ELM 所需要占用的额外空间更小,因此本文算法占用的硬件资源更少.
另一方面从状态转移算法的特性也可以知道,状态转移算法设计了变换时的并行运算且在每次搜索过程中同时进行了全局最优解和局部最优解的搜索,因此保证了算法的快速性[17].
3 实 验
本节利用多组标准数据集对本文算法进行对比实验. 实验均使用硬件平台为Intel(R) Core(TM) i7-9750H CPU @2.60 GHz,内存为8 GB 的一台笔记本来完成. 本文选用的数据集均来自于UCI 数据库和MedMNIST 医学图像分析数据集[18]. 为了保证实验结果的准确性和真实性,本文中所有实验指标均重复30 次取平均值作为最终结果.
3.1 UCI 数据集分类实验测试
本节实验选取了10 组UCI 数据库中用于分类测试的经典数据集做实验对比,数据集的训练数量、测试数量、特征数量以及类别数如表1 所示.
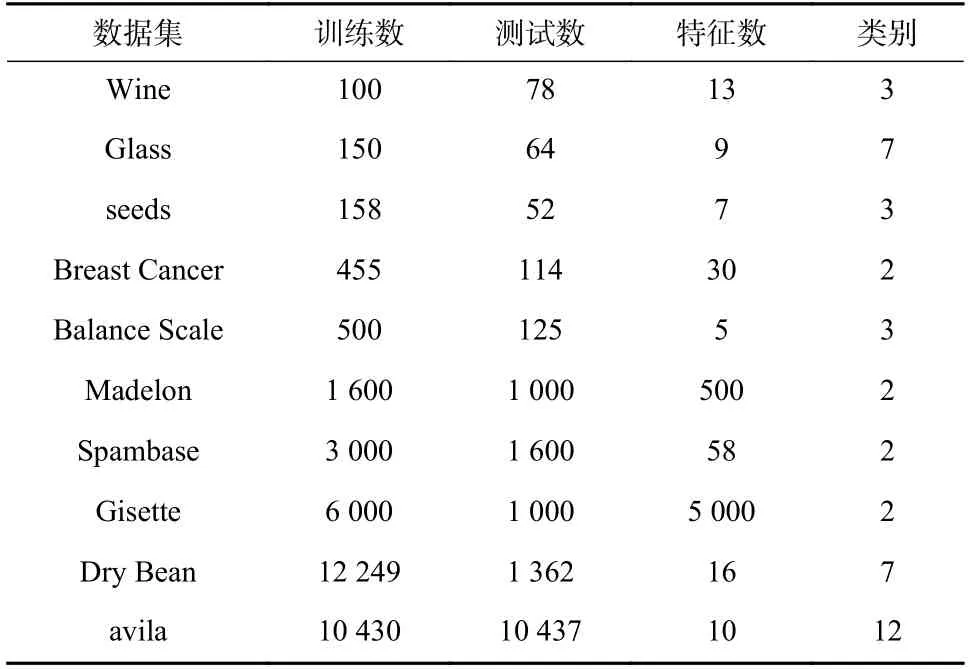
表1 10 个数据集的基本信息Tab. 1 Basic information of 10 classification data sets
为了测试不同隐藏层节点下STA-ELM 算法对ELM、RELM、基于梯度下降的Adam-ELM[18]和基于凸规划问题ADMM-ELM[19]几种主流的基于极限学习机的算法的性能提升,这里对每个数据集设置隐藏层节点数目N的区间为[10,100],在区间上均匀选择10 个不同的节点数对5 种算法的分类准确率进行对比,依据文献[17]中给出的默认参数,参考实验效果和2.1 节中提到的4 种搜索变换算子的本质作用,对STA-ELM 算法迭代次数G设置为200,参数设置为fc=2,k=0,α=αmax=1,αmin=1×10-4, β=γ=δ=1,SE0=10,SE1=1,SE2=30,SE3=30;对Adam-ELM 的学习率设置为0.001,超参数 β1、 β2和稳定性常数 σ分别设置为0.09、0.99 和1×10-6,迭代次数设置为200;算法的隐藏层的激活函数均选用sigmoid函数;对比结果如图1 所示,这里选择了Breast Cancer、Spambase、Dry Bean、Avila 4 组有代表性的数据集. 这里的测试精度代表测试集样本准确率,即测试集中正确分类的样本数/测试样本数.
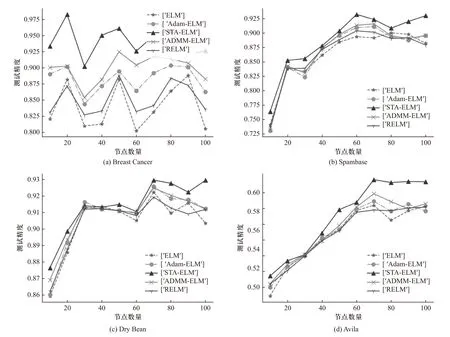
图1 不同隐藏层节点数的实验结果Fig. 1 The experimental results of different number of hidden nodes
从上图的实验结果分析可得,5 种基于极限学习机的算法在相同隐藏层节点的情况下, STA-ELM 算法训练出来的模型在对各个数据集的分类准确上普遍都有更好的表现. STA-ELM 算法只在部分数据集的部分节点的情况下精度会略低于ADMM-ELM 算法. 对每组数据集来说,分类精度最高的模型都是由STA-ELM 实现的. 同时可以发现,随着隐藏层节点数量的增多,STA-ELM 算法相比于其余几种算法在分类精度上的优势就越明显.
在此基础上,本文加入了BLS(宽度学习)[20]算法对10 组数据集进行实验,BLS 同样是一种输入层到中间层随机产生权重偏置的算法,它的输出权重偏置也是通过广义逆得到的,与ELM 不同的是,BLS的输入层与输出层有连接,且输入层直接输入的是特征. 实验中参数选择与上一实验一致. 在每个数据集的实验上对STA-ELM、ELM、RELM、Adam-ELM 和ADMM-ELM 均设置多组不同的隐藏层节点数,并分别记录精度最高的那组节点数. 实验结果如表2 所示.Acc(%)表示算法的测试准确率,即测试集正确分类的样本数/测试样本数×100%;N表示隐藏层节点数.
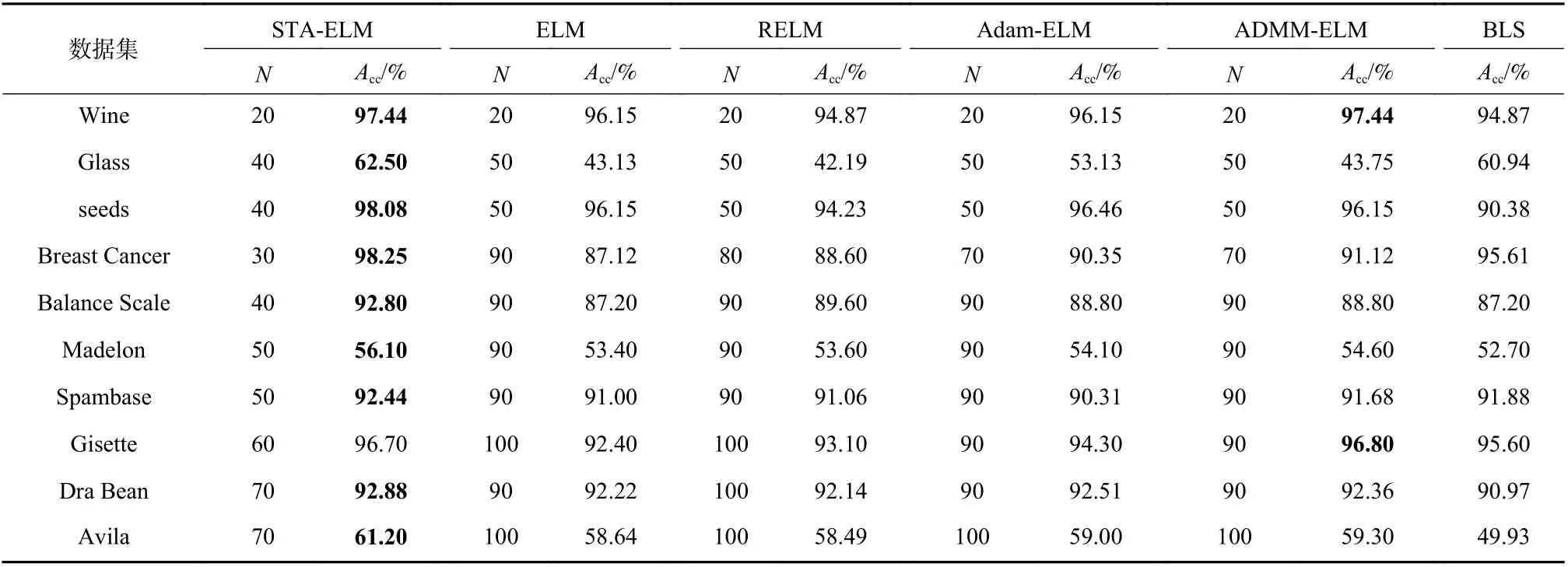
表2 基于各算法的数据集综合训练结果Tab. 2 Comprehensive training results based on data sets of various algorithms
通过实验结果分析可得,本文算法相比于ELM、RELM 与Adam-ELM 在各个数据集上的精度表现都要更好,这说明通过改进STA 算法求解输出权重矩阵的方法得到的结果会更加精准. 相较于ADMMELM,本文算法在大多数数据集上的测试精度表现都会更好,在个别数据集上只比ADMM-ELM 算法低了不到1%. 而相较于BLS 算法,STA-ELM 算法在所有数据集的精度和效率上都更好. 从隐藏层节点数的角度来看,在对大部分数据集的训练中,STAELM 算法相较于其余4 种基于ELM 的算法来说,可以用更少的隐藏层节点数训练出测试精度更好的模型.
3.2 MedMNIST 医疗图像数据集分类实验
本节实验选择MedMNIST 数据集[18]中4 个具有代表性的数据集BreastMNIST、RetinaMNIST、Derma MNIST 和PathMNIST 进行实验. 算法相关参数与上节保持一致. 表3 列出了上述4 个数据集的基本特征.
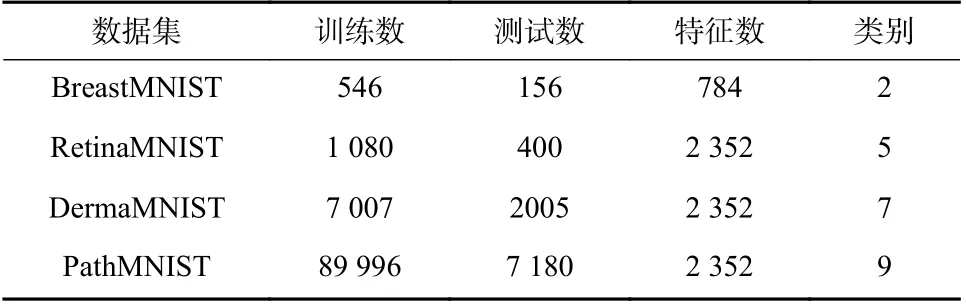
表3 4 个数据集的基本信息Tab. 3 Basic information of 4 classification data sets
首先来验证STA-ELM 算法在以上4 个数据集中通过状态转移算法的搜索情况. 通过每一次迭代优化函数和分类精度的对比可以动态地展现算法的搜索和模型建立的过程. 图2 展示了其中两个有代表性的数据集在几千次迭代过程中优化目标函数不断单调递减且分类测试精度不断提升的过程.
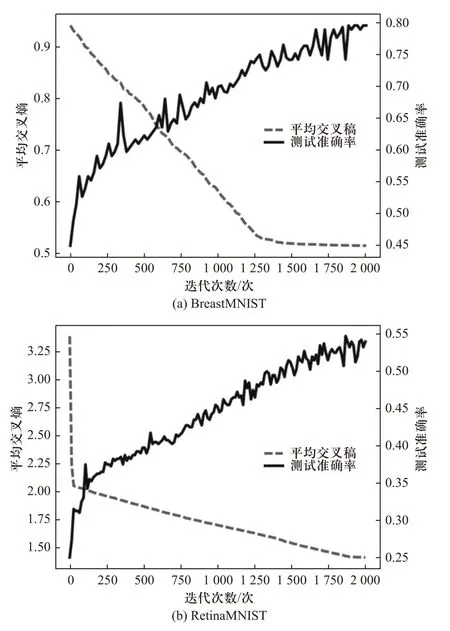
图2 平均交叉熵和测试准确率随迭代次数的变化曲线Fig. 2 Average cross entropy and test accuracy rate with the change curve of the number of iterations
从实验结果分析可得,STA-ELM 算法在计算模型的输出权重矩阵时是不断向着优化目标靠拢的,通过搜索不断使平均交叉熵函数缩小来求得更为准确的输出权重矩阵. 在这一过程中,随着每次迭代输出权重矩阵的精度不断提高,分类的测试精度在趋势上也不断提升,最终模型趋于一个较为稳定的状态.
为了测试算法的泛化性能,实验用STA-ELM、ELM 和Adam-ELM 3 种算法对以上两组数据集在不同隐藏层节点数下进行泛化性能对比. 实验结果如图3 所示,实验中利用数据集的训练精度与测试精度之比作为泛化性能的判断标准. 比值接近1 说明算法泛化性能较理想,比值离1 差距较大的时候说明模型出现欠拟合或者过拟合的情况.
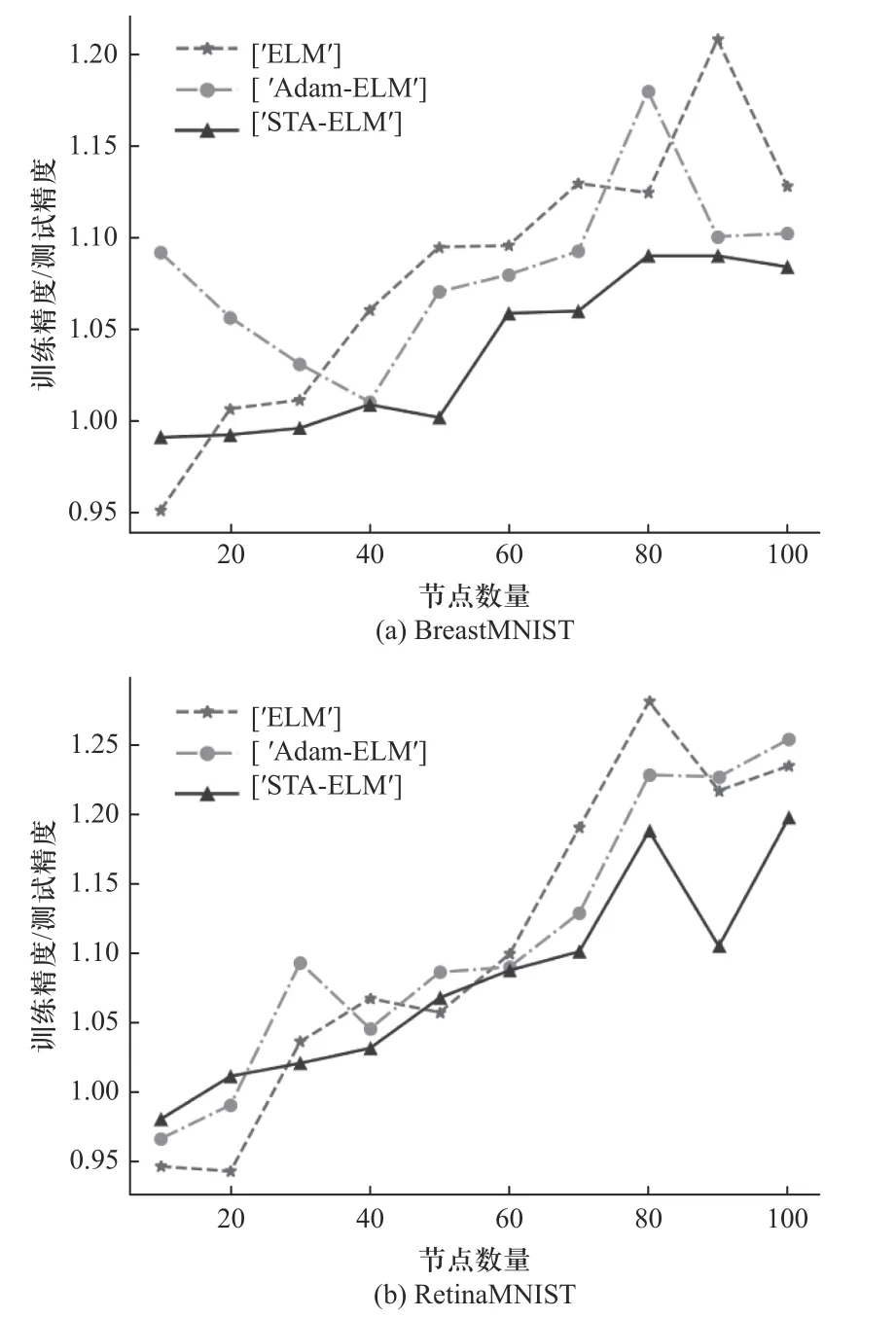
图3 3 种算法的泛化性能随节点数变化曲线Fig. 3 The generalization performance of the three algorithms varies with the number of nodes
根据图3 实验结果可知,STA-ELM 算法在泛化性能上的表现要强于ELM 和Adam-ELM 算法. 在节点数较小的情况下,STA-ELM 算法的训练精度与测试精度之比要更接近1,不会产生欠拟合现象,而在节点数较大的情况下,ELM 与Adam-ELM 在个别节点数下会出现过拟合现象,而STA-ELM 在图中数据集上基本可以将比值稳定在1.1 和1.2 以内,可以看出本文算法的泛化性能较好.
随后在4 组数据集上分别用STA-ELM 算法与ELM、SVM、ResNet[18]以及ResNet[50]进行医疗图像分类方面的性能对比. 在对BreastMNIST 和RetinaMNIST 数据集上,均设置STA-ELM 算法的迭代次数为2 500 次;在对DermaMNIST 数据集上,STAELM 迭代次数选择3 000 次;在对PathMNIST 数据集上,STA-ELM 迭代次数选择5 000. 同时,在本节所有实验中,算法SVM 均选用线性核函数,ResNet[18]和ResNet[50]均选用SGD 优化器,学习率设置为0.1.其余参数与之前保持一致. 表4 给出了5 种算法在4组数据集上测试准确率的表现. 其中ELM 和STAELM 算法分别给出了在实验结果最理想情况下对应的节点数N,T表示算法建立模型所花费的时间.
从表4 实验结果可以看出,在对前3 组数据集的建模分类上,本文提出的STA-ELM 算法在5 种算法里具有最高的精度,并且相比于主流的神经网络ResNet[50]在精度上基本有2%~6%的提升. 虽然在PathMNIST 数据集上表现不如ResNet[50],但是训练花费时间却极大的减少了. 与传统ELM 相比,STAELM 对MedMNIST 中大部分数据集在精度上有10%~20%的提升,在PathMNIST 上提升较明显,有48.83%的提升,且在所有测试数据集上,STA-ELM达到最优训练效果时需要的隐藏层节点数都要更少.在建模耗费时间上,STA-ELM 只有在对小样本量数据集训练时建模效率会略低于ELM,但随着样本量增加,STA-ELM 的建模速率的优势逐渐体现出来,这个同时也验证了2.2 节对算法复杂度分析的结论.因此可以看出,本文算法在处理医疗图像数据集时,与传统机器学习算法相比,在精度上均有大幅度提升,而与一些主流的神经网络算法相比,本文算法在极大算短建模时间的基础上也拥有良好表现.

表4 基于各算法的MedMNIST 数据集综合训练结果Tab. 4 Comprehensive training results of MedMNIST data sets based on various algorithms
3.3 基于STA-ELM 算法的回归预测分析
本节实验用STA-ELM、ELM、RELM、Adam-ELM和ADMM-ELM 算法分别对4 组UCI 数据库中的数据集进行回归预测, 4 组数据集的训练数、测试数和特征数如表5 所示.

表5 4 个数据集的基本信息Tab. 5 Basic information of 4 classification data sets
在每组数据集的实验中分别对5 种算法设置区间为[10∶10∶100]的隐藏层节点数目,分别记录每种算法在不同节点下对测试样本的均方根误差. 实验结果如图4 所示.
从图4 实验结果分析可知,5 种基于ELM 的算法在相同数据集上设置相同节点的情况下,STAELM 算法的均方根误差都是最小的,并且可以看出,在节点较少的情况下,STA-ELM 算法仍有不错的拟合效果,而另外4 种算法会有较大的误差. 同时可以观察得出5 种算法在每个数据集上达到最小误差的时候,STA-ELM 所用隐藏层节点数是最小的.
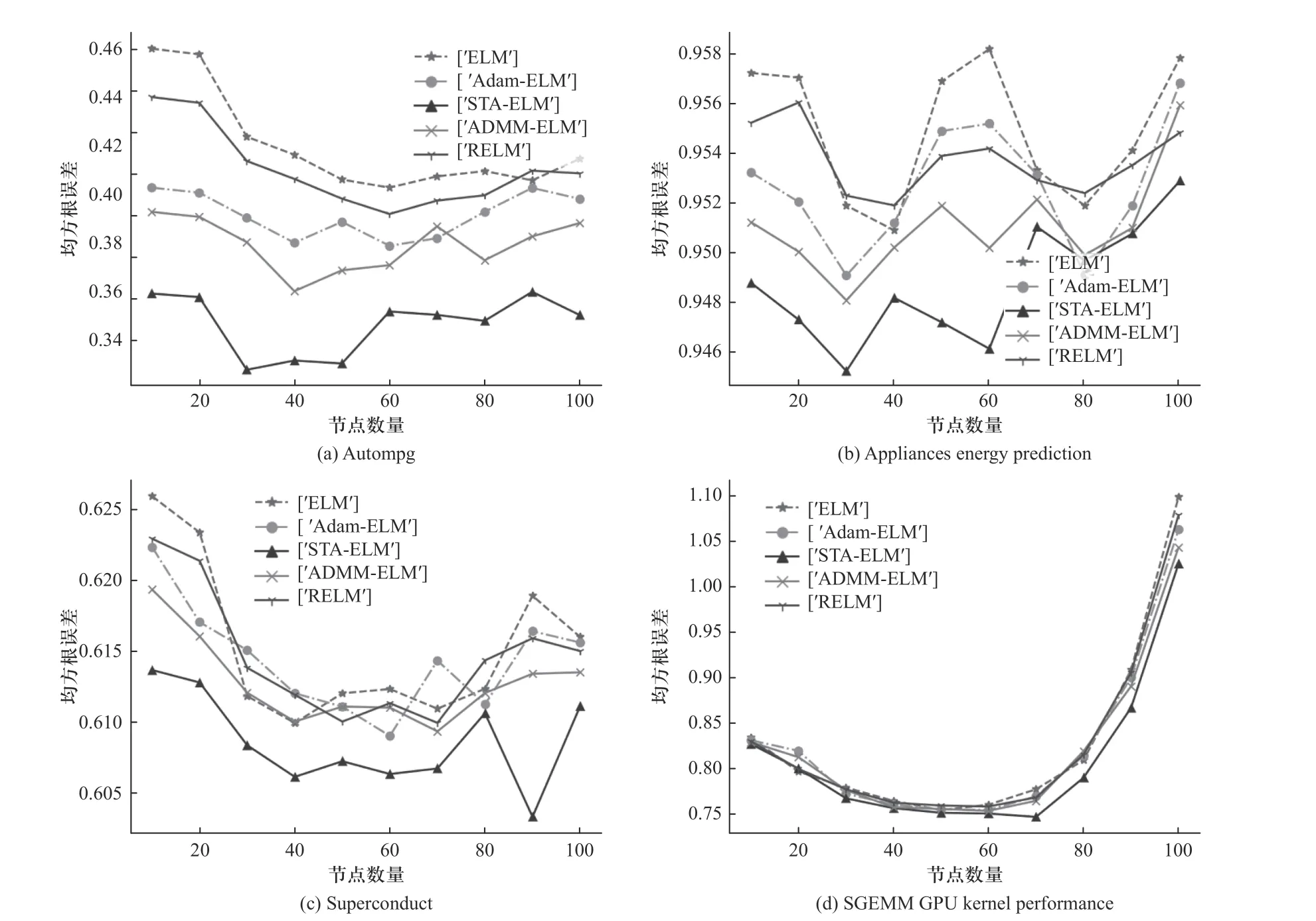
图4 5 种算法在不同隐藏层节点数下的实验结果Fig. 4 Experimental results of the five algorithms under different numbers of hidden layer nodes
4 结 论
本文提出一种基于状态转移算法的极限学习机,该算法从精准求解ELM 输出权重矩阵的角度出发,利用STA 算法进行搜索,即保留ELM 网络结构和随机性的优点,同时解决了ELM 建立模型精度较低的问题. 通过对10 组UCI 数据集的对比实验,证明了该算法相较于部分主流机器学习算法可以有效提高模型的测试精度,通过对MedMNIST 数据集的实验可知,该算法可以获得比现有较为先进的算法ResNet[50]更优秀的建模精度,且极大地提升了建模的效率. 在对4 组UCI 数据集的回归实验中,该算法可以利用很少的隐藏层节点训练出误差较小的模型,做到了较为精准的预测拟合,体现了STA-ELM 算法的优秀学习建模性能.
猜你喜欢
心理学报(2022年5期)2022-05-16
保健与生活(2022年10期)2022-05-06
华文教学与研究(2022年1期)2022-04-27
社会科学战线(2022年2期)2022-03-16
文萃报·周五版(2021年30期)2021-09-05
当代陕西(2020年17期)2020-10-28
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
